
102302104劉璇-數(shù)據(jù)采集與融合技術(shù)實(shí)踐作業(yè)1
作業(yè)1:
要求:用requests和BeautifulSoup庫(kù)方法定向爬取給定網(wǎng)站(http://www.shanghairanking.cn/rankings/bcur/2020 )的數(shù)據(jù),屏幕打印爬取的大學(xué)排名信息。
輸出信息:
| 排名 | 學(xué)校名稱 | 省市 | 學(xué)校類型 | 總分 |
|---|---|---|---|---|
| 1 | 清華大學(xué) | 北京 | 綜合 | 852.5 |
| 2 | .... | .... | .... | .... |
核心代碼設(shè)計(jì)邏輯:
??基于對(duì)網(wǎng)頁(yè)結(jié)構(gòu)的觀察,首先我注意到目標(biāo)數(shù)據(jù)以表格形式規(guī)整地呈現(xiàn)在網(wǎng)頁(yè)上,這讓我決定采用分層提取的策略即從定位整個(gè)表格開(kāi)始,逐步深入到行和單元格的層面。在數(shù)據(jù)清洗的時(shí)候,我發(fā)現(xiàn)學(xué)校名稱字段中混雜了數(shù)字和特殊字符,所以我使用正則表達(dá)式來(lái)精準(zhǔn)提取中文字符。
核心代碼:
點(diǎn)擊查看代碼
def crawl_university_ranking():
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table", class_="rk-table")
data_rows = table.find("tbody").find_all("tr")[:30]
for row in data_rows:
cols = row.find_all("td")[:5]
rank = cols[0].get_text(strip=True)
school_name = re.sub(r'[^\u4e00-\u9fa5]', '', cols[1].get_text(strip=True))
province = cols[2].get_text(strip=True)
school_type = cols[3].get_text(strip=True)
total_score = cols[4].get_text(strip=True)
print(f"{rank}\t{school_name}\t{province}\t{school_type}\t{total_score}")
if __name__ == "__main__":
crawl_university_ranking()
運(yùn)行結(jié)果:

心得體會(huì):
??首先在數(shù)據(jù)提取階段,我發(fā)現(xiàn)學(xué)校名稱字段中混雜了各類非中文字符,所以我采用正則表達(dá)式精準(zhǔn)過(guò)濾出純中文內(nèi)容,由于中英文字符寬度差異,簡(jiǎn)單的制表符無(wú)法實(shí)現(xiàn)完美的列對(duì)齊,經(jīng)過(guò)反復(fù)試驗(yàn)格式化字符串的寬度參數(shù),才找到各列最合適的顯示比例。在最開(kāi)始寫完運(yùn)行的時(shí)候,當(dāng)網(wǎng)頁(yè)結(jié)構(gòu)發(fā)生微小變動(dòng)時(shí),程序就會(huì)直接崩潰。所以后續(xù)我為每個(gè)DOM查詢操作都添加了健壯性檢查,確保在頁(yè)面結(jié)構(gòu)發(fā)生變化時(shí)能夠優(yōu)雅降級(jí)而非徹底失效。
作業(yè)2:
要求:用requests和re庫(kù)方法設(shè)計(jì)某個(gè)商城(自已選擇)商品比價(jià)定向爬蟲,爬取該商城,以關(guān)鍵詞“書包”搜索頁(yè)面的數(shù)據(jù),爬取商品名稱和價(jià)格。
輸出信息:
| 序號(hào) | 價(jià)格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | .... | .... |
核心代碼設(shè)計(jì)邏輯:
??寫這個(gè)爬蟲的時(shí)候,首先我觀察了當(dāng)當(dāng)網(wǎng)的頁(yè)面結(jié)構(gòu),發(fā)現(xiàn)商品名稱都包含在title屬性里,而且搜索"書包"的結(jié)果頁(yè)面中,所有相關(guān)商品的title都帶有"書包"這個(gè)關(guān)鍵詞,所以可以直接用正則匹配包含"書包"的title就能精準(zhǔn)抓取到商品名稱。對(duì)于價(jià)格提取,我注意到頁(yè)面里價(jià)格都有統(tǒng)一的CSS類名price_n,而且價(jià)格格式很規(guī)范,都是¥后面跟著數(shù)字,這樣就可以直接爬取出來(lái)價(jià)格了。且根據(jù)網(wǎng)頁(yè)可以看出名稱和價(jià)格在頁(yè)面中的出現(xiàn)順序是對(duì)應(yīng)的,所以直接用zip配對(duì)就能保持?jǐn)?shù)據(jù)的一致性,不需要復(fù)雜的映射關(guān)系。
核心代碼:
點(diǎn)擊查看代碼
def crawl_dangdang():
url = "https://search.dangdang.com/?key=書包&act=input"
response = urllib3.PoolManager().request('GET', url)
html = response.data.decode('gbk')
#提取商品名稱和價(jià)格
names = re.findall(r'title="([^"]*書包[^"]*)"', html)
names = [name.strip() for name in names][:60]
prices = re.findall(r'<span class="price_n">¥([\d.]+)</span>', html)
prices = [f"¥{p}" for p in prices][:60]
for i, (name, price) in enumerate(zip(names, prices), 1):
print(f"{i}\t{price}\t{name}")
if __name__ == "__main__":
crawl_dangdang()
運(yùn)行結(jié)果:
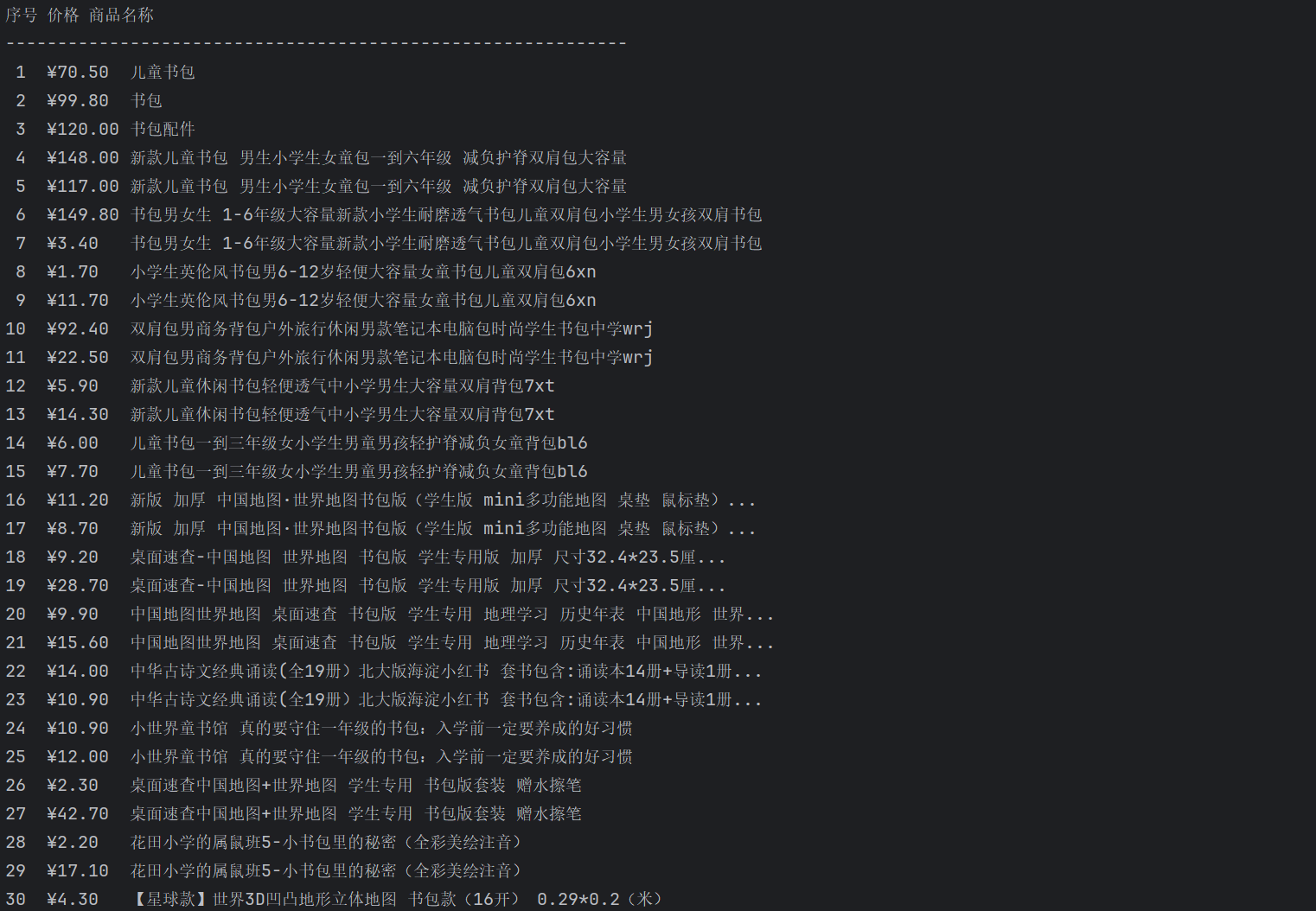
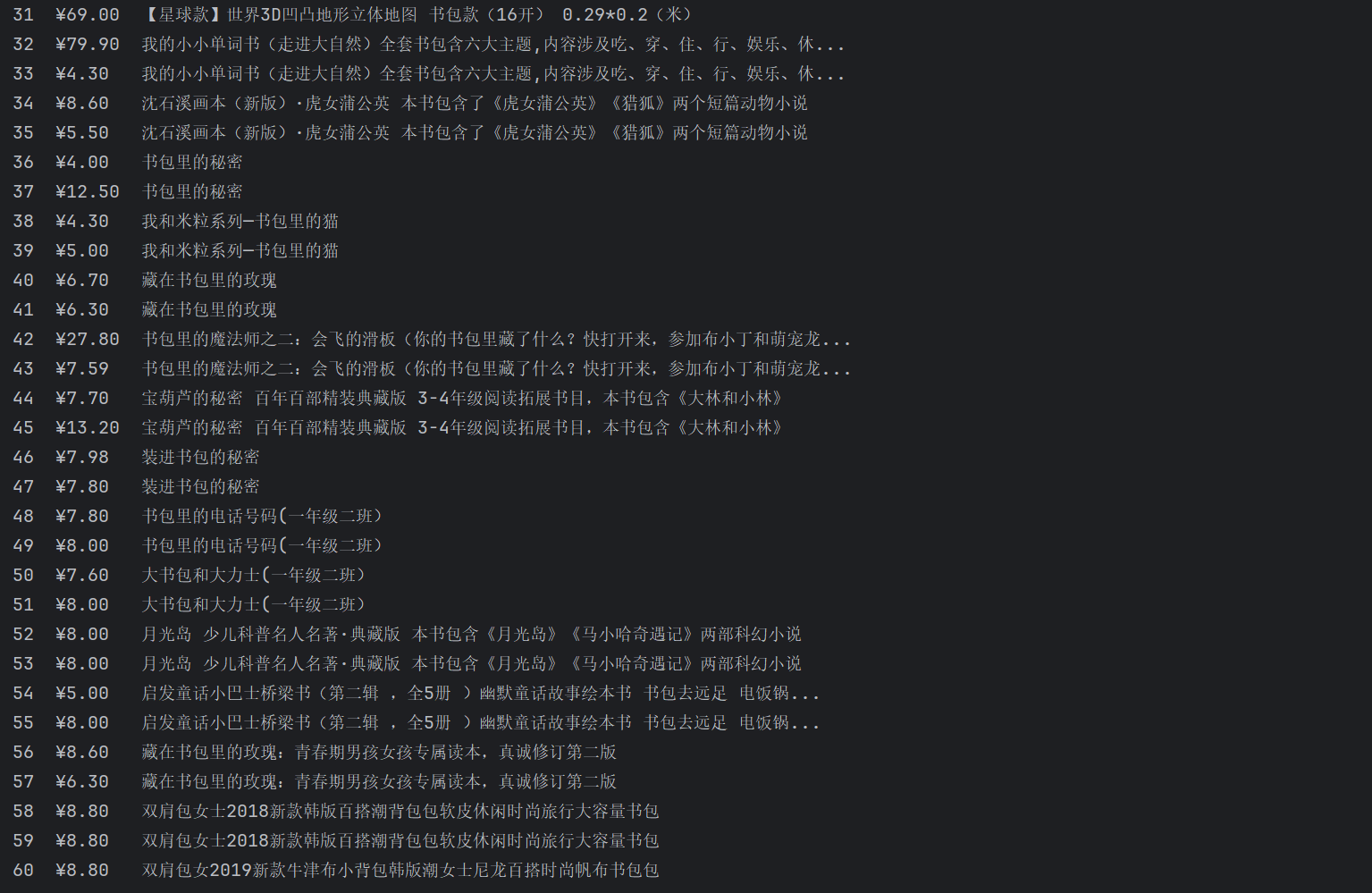
心得體會(huì):
??在項(xiàng)目技術(shù)選型過(guò)程中,我曾將淘寶、京東等主流電商平臺(tái)作為首要目標(biāo),但這些平臺(tái)均配備了完善的反爬蟲機(jī)制,需要處理復(fù)雜的Cookie動(dòng)態(tài)維護(hù)、請(qǐng)求頭全鏈路偽裝以及JavaScript動(dòng)態(tài)渲染等高級(jí)技術(shù)難題,這已超出我的技術(shù)范疇。經(jīng)過(guò)在技術(shù)社區(qū)的多方調(diào)研,我在小紅書等平臺(tái)了解到當(dāng)當(dāng)網(wǎng)采用相對(duì)寬松的反爬策略,其服務(wù)端渲染模式使得基礎(chǔ)HTTP請(qǐng)求即可獲取完整的頁(yè)面數(shù)據(jù),數(shù)據(jù)結(jié)構(gòu)清晰且穩(wěn)定。基于對(duì)自身技術(shù)能力的客觀評(píng)估和項(xiàng)目周期的現(xiàn)實(shí)考量,我最終選擇以反爬門檻較低的當(dāng)當(dāng)網(wǎng)作為數(shù)據(jù)源,在保證項(xiàng)目可行性的同時(shí),確保在有限開(kāi)發(fā)資源下實(shí)現(xiàn)數(shù)據(jù)采集的穩(wěn)定性和可維護(hù)性。
作業(yè)3:
要求:爬取一個(gè)給定網(wǎng)頁(yè)(https://news.fzu.edu.cn/yxfd.htm) 或者自選網(wǎng)頁(yè)的所有JPEG、JPG或PNG格式圖片文件
輸出信息:將自選網(wǎng)頁(yè)內(nèi)的所有JPEG、JPG或PNG格式文件保存在一個(gè)文件夾中
核心代碼設(shè)計(jì)邏輯:
??寫這個(gè)代碼時(shí),我首先想到的是先找到網(wǎng)頁(yè)里所有的圖片鏈接,然后篩選出真正需要的新聞圖片。我發(fā)現(xiàn)用正則表達(dá)式匹配img標(biāo)簽的src屬性是最快的方法,過(guò)濾環(huán)節(jié)我主要想排除那些小圖標(biāo)和logo,觀察到它們的文件名通常包含"icon"或"logo"關(guān)鍵詞,所以就用他這個(gè)規(guī)則篩了一遍。
核心代碼:
點(diǎn)擊查看代碼
img_urls = re.findall(r'<img.*?src="(.*?)"', html, re.IGNORECASE)
valid_imgs = []
for src in img_urls:
if 'icon' in src.lower() or 'logo' in src.lower():
continue
full_url = urljoin(url, src)
if re.search(r'\.(jpg|jpeg|png)$', full_url, re.IGNORECASE):
valid_imgs.append(full_url)
for i, img_url in enumerate(valid_imgs):
response = requests.get(img_url, timeout=10)
with open(f'images/img_{i}{ext}', 'wb') as f:
f.write(response.content)
運(yùn)行結(jié)果:

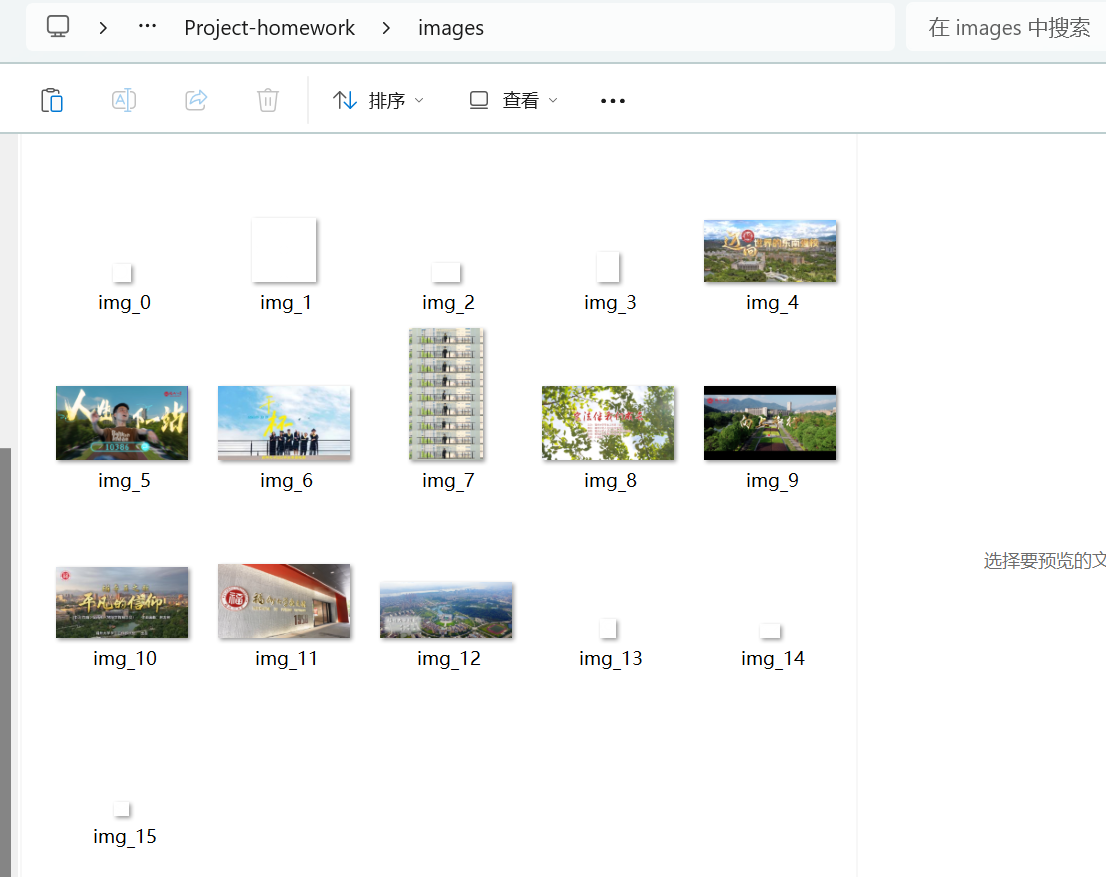

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)