
7.Spark SQL
1.分析SparkSQL出現(xiàn)的原因,并簡述SparkSQL的起源與發(fā)展。
Spark SQL是Spark用來處理結(jié)構(gòu)化數(shù)據(jù)的一個模塊,它提供了一個叫作Data Frame的編程抽象結(jié)構(gòu)數(shù)據(jù)模型(即帶有Schema信息的RDD),Spark SQL作為分布式SQL查詢引擎,讓用戶可以通過SQL、DataFrame APl和DatasetAPI三種方式實現(xiàn)對結(jié)構(gòu)化數(shù)據(jù)的處理。但無論是哪種API或者是編程語言,都是基于同樣的執(zhí)行引擎,因此可以在不同的API之間隨意切換。
SparkSOL的前身是SharkShark最初是美國加州大學(xué)伯克利分校的實驗室開發(fā)的Snark生態(tài)系統(tǒng)的組件之一 它運行在Snark系統(tǒng)之上,Shark重用了Hive的工作機制,并直接繼承了Hive的各個組件,Shark將SQL語句的轉(zhuǎn)換從MapReduce作業(yè)替換成了Spark作業(yè),雖然這樣提高了計算效率,但由于Shark過于依賴Hive,因此在版本迭代時很難添加新的優(yōu)化策略,從而限制了Spak的發(fā)展,在2014年,伯克利實驗室停止了對Shark的維護,轉(zhuǎn)向SparkSQL的開發(fā)。
2. 簡述RDD 和DataFrame的聯(lián)系與區(qū)別。
兩者聯(lián)系:
RDD和DataFrame的共同特征是不可性、內(nèi)存運行、彈性、分布式計算能力。它允許用戶將結(jié)構(gòu)強加到分布式數(shù)據(jù)集合上。因此提供了更高層次的抽象。
都是spark平臺下的分布式彈性數(shù)據(jù)集,為處理超大型數(shù)據(jù)提供便利。
都有惰性機制,在進行創(chuàng)建、轉(zhuǎn)換,如map方法時,不會立即執(zhí)行,只有在遇到Action才會運算。
都會根據(jù)spark的內(nèi)存情況自動緩存運算,這樣即使數(shù)據(jù)量很大,也不用擔(dān)心會內(nèi)存溢出。
都有partition的概念。
有許多共同的函數(shù),如filter,排序等。
區(qū)別:
RDD是彈性分布式數(shù)據(jù)集,數(shù)據(jù)集的概念比較強一點。容器可以裝任意類型的可序列化元素(支持泛型);
RDD的缺點是無從知道每個元素的【內(nèi)部字段】信息。意思是下圖不知道Person對象的姓名、年齡等;
DataFrame也是彈性分布式數(shù)據(jù)集,但是本質(zhì)上是一個分布式數(shù)據(jù)表,因此稱為分布式表更準(zhǔn)確。DataFrame每個元素不是泛型對象,而是Row對象。
DataFrame的缺點是Spark SQL DataFrame API 不支持編譯時類型安全,因此,如果結(jié)構(gòu)未知,則不能操作數(shù)據(jù);同時,一旦將域?qū)ο筠D(zhuǎn)換為Data frame ,則域?qū)ο蟛荒苤貥?gòu)。
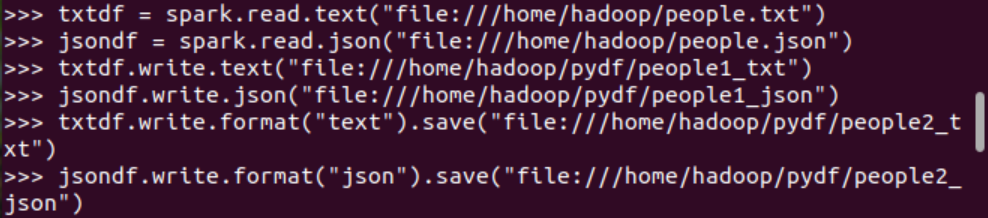
3.DataFrame的創(chuàng)建與保存
3.1 PySpark-DataFrame創(chuàng)建:

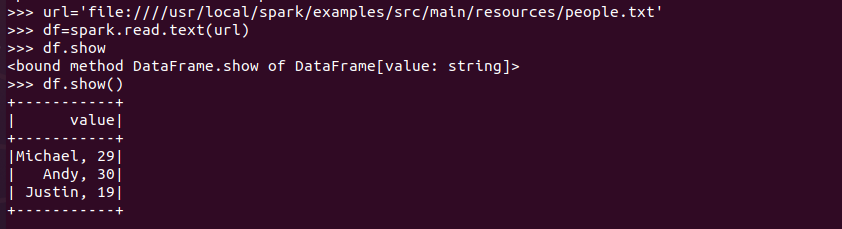
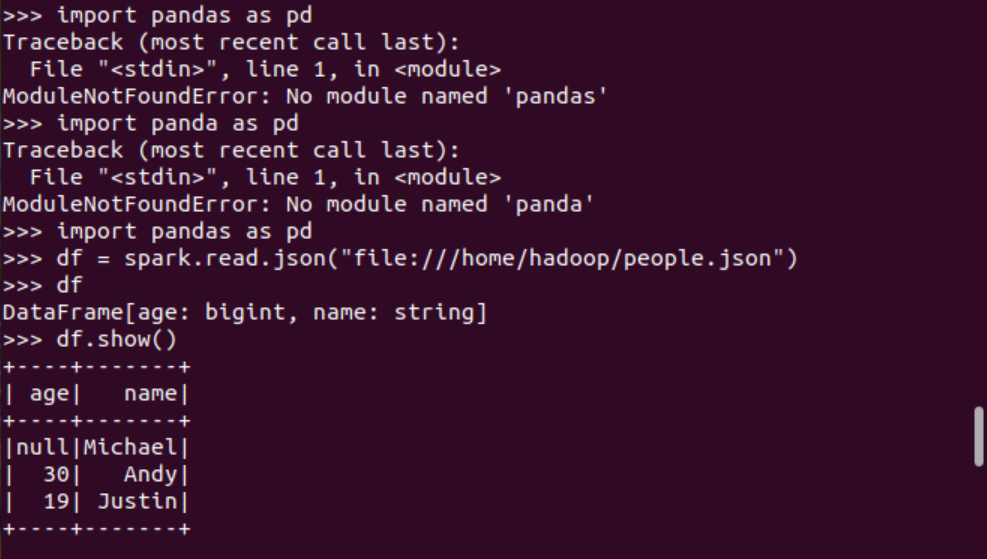
spark.read.text(url)
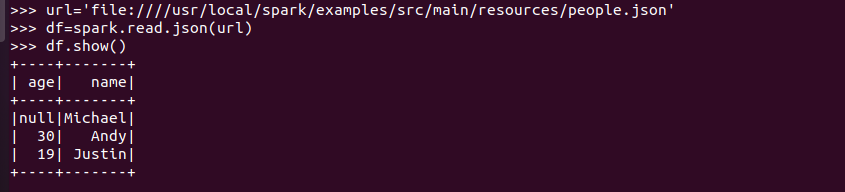
spark.read.json(url)
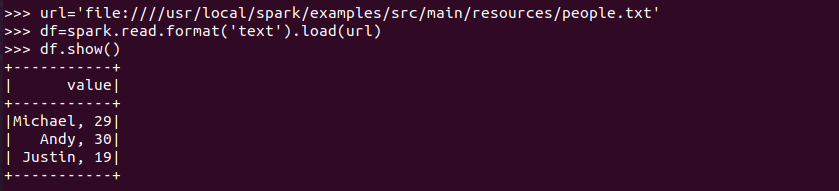
spark.read.format("text").load("people.txt")
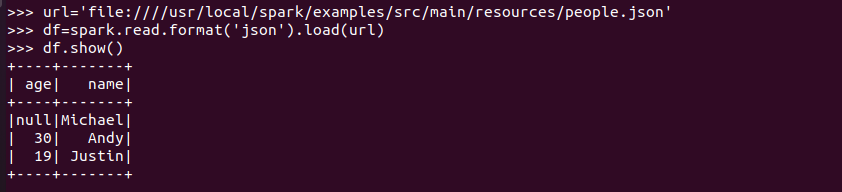
spark.read.format("json").load("people.json")
描述從不同文件類型生成DataFrame的區(qū)別。
答:讀取text文件,Spark不能識別文件內(nèi)容,生成關(guān)系表
讀取json文件,Spark可以識別文件內(nèi)容,生成對應(yīng)的關(guān)系表,還能根據(jù)不同字段的內(nèi)容判斷對應(yīng)的數(shù)據(jù)類型。
用相同的txt或json文件,同時創(chuàng)建RDD,比較RDD與DataFrame的區(qū)別。
rdd將直接存儲讀取到的數(shù)據(jù),不對數(shù)據(jù)進行處理,DataFrame將讀取到的數(shù)據(jù)轉(zhuǎn)為結(jié)構(gòu)信息。
3.2 DataFrame的保存
df.write.text(dir)
df.write.json(dri)
df.write.format("text").save(dir)
df.write.format("json").save(dir)
df.write.format("json").save(dir)
4. PySpark-DataFrame各種常用操作
基于df的操作:
打印數(shù)據(jù) df.show()默認打印前20條數(shù)據(jù)
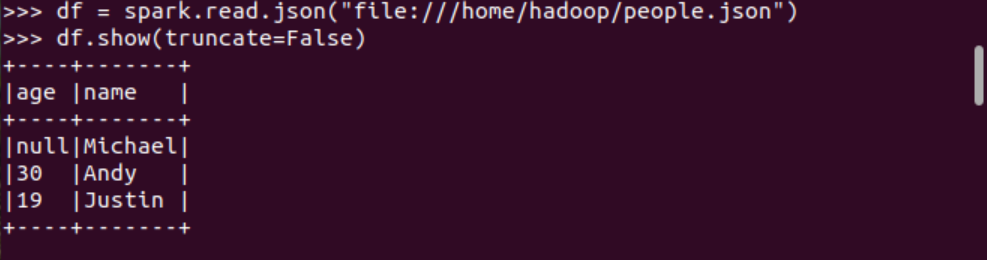
打印概要 df.printSchema()

查詢總行數(shù) df.count()

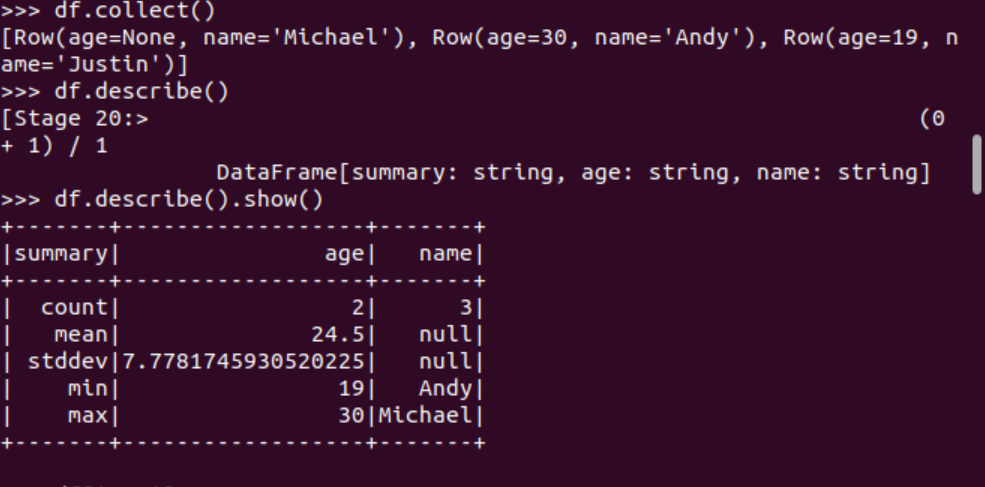
df.head(3) #list類型,list中每個元素是Row類

輸出全部行 df.collect() #list類型,list中每個元素是Row類查詢概況 df.describe().show()
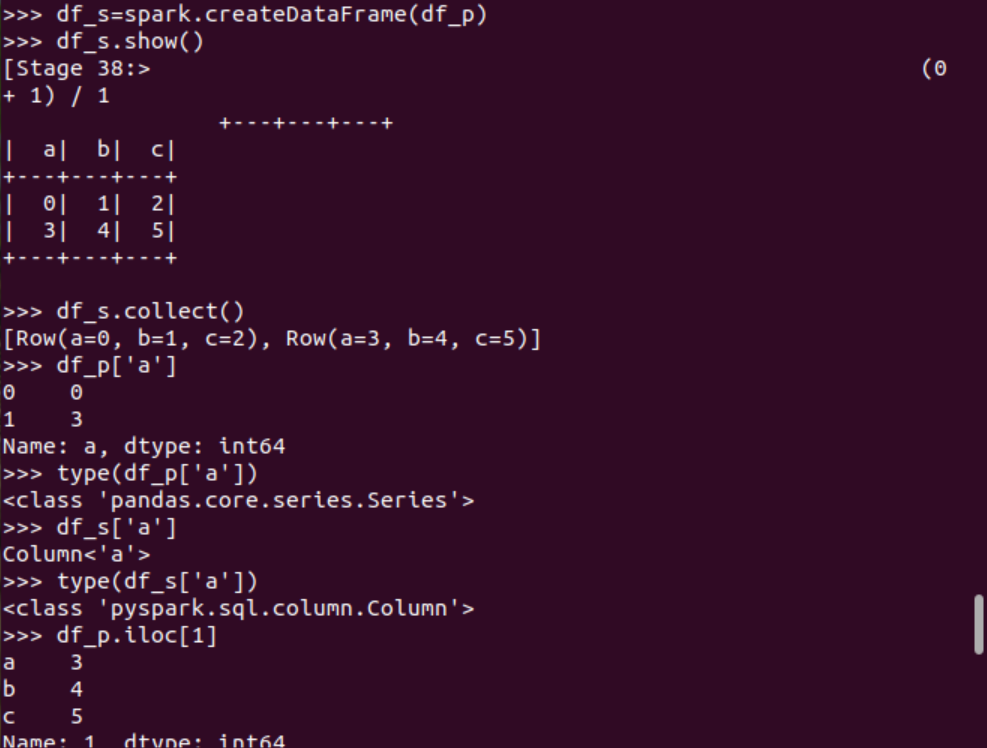
取列 df[‘name’], df.name, df[1]

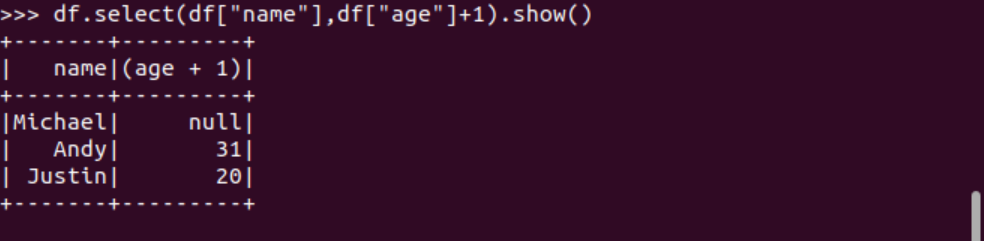
選擇 df.select() 每個人的年齡+1
篩選 df.filter() 20歲以上的人員信息

篩選年齡為空的人員信息

分組df.groupBy() 統(tǒng)計每個年齡的人數(shù)
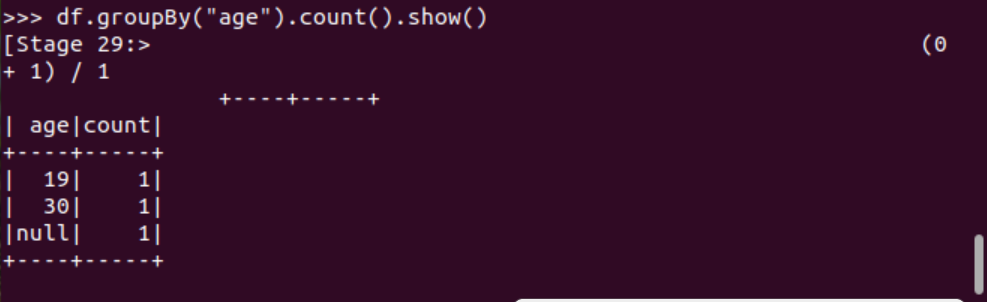
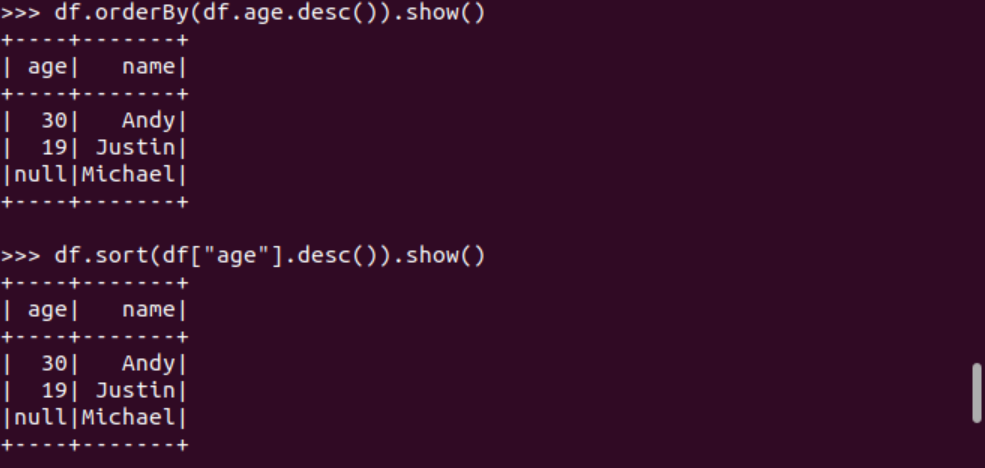
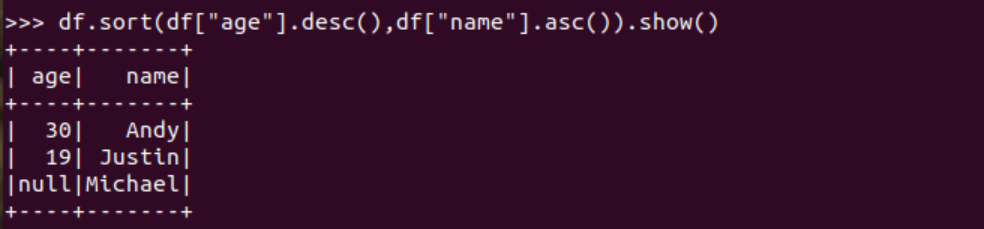
排序df.sortBy() 按年齡進行排序
基于spark.sql的操作:
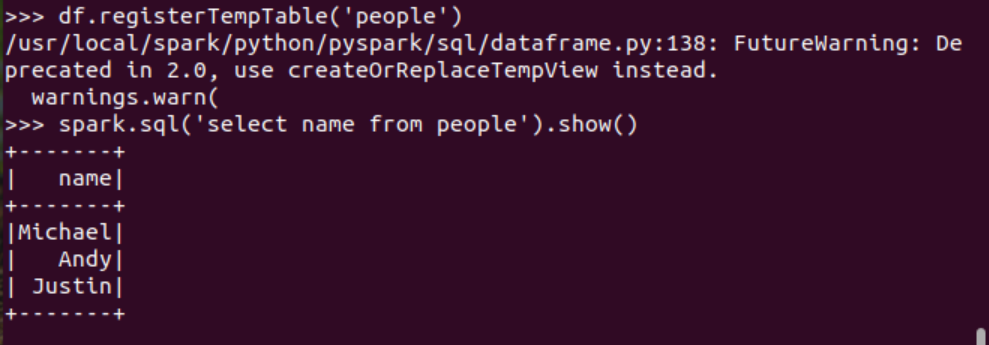
創(chuàng)建臨時表虛擬表 df.registerTempTable('people')
spark.sql執(zhí)行SQL語句 spark.sql('select name from people').show()
5. Pyspark中DataFrame與pandas中DataFrame
分別從文件創(chuàng)建DataFrame
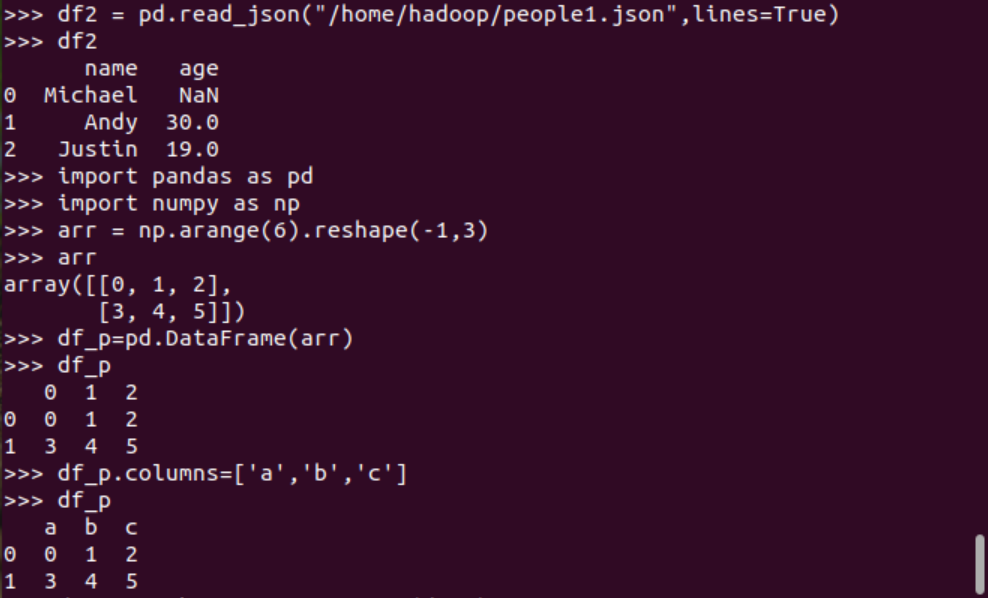
比較兩者的異同
pandas中DataFrame轉(zhuǎn)換為Pyspark中DataFrame
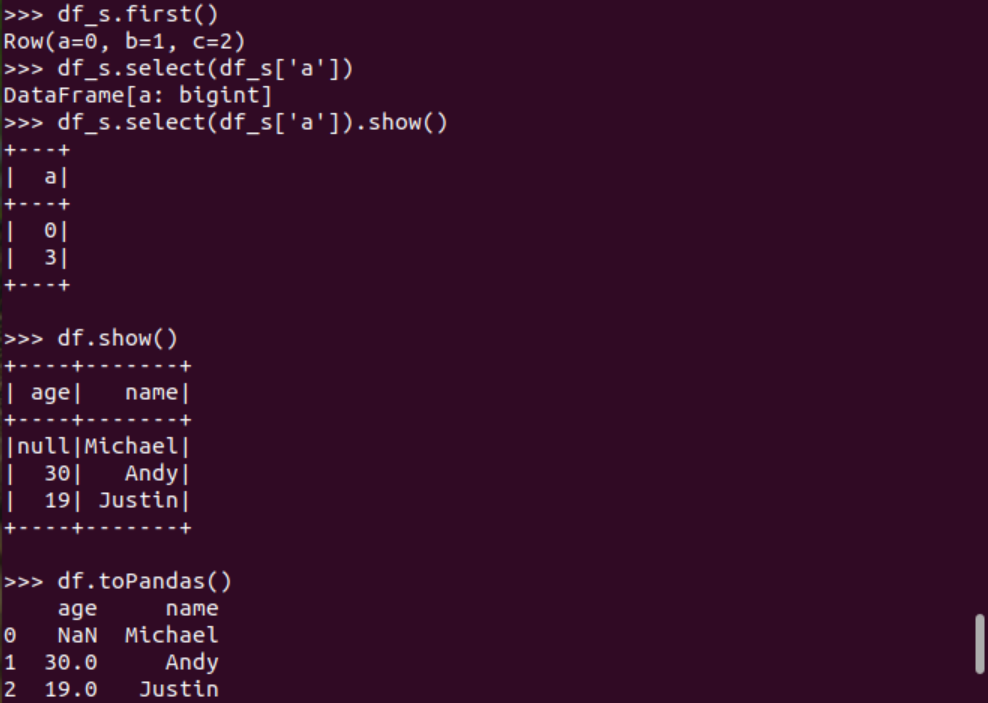
Pyspark中DataFrame轉(zhuǎn)換為pandas中DataFrame
6.從RDD轉(zhuǎn)換得到DataFrame
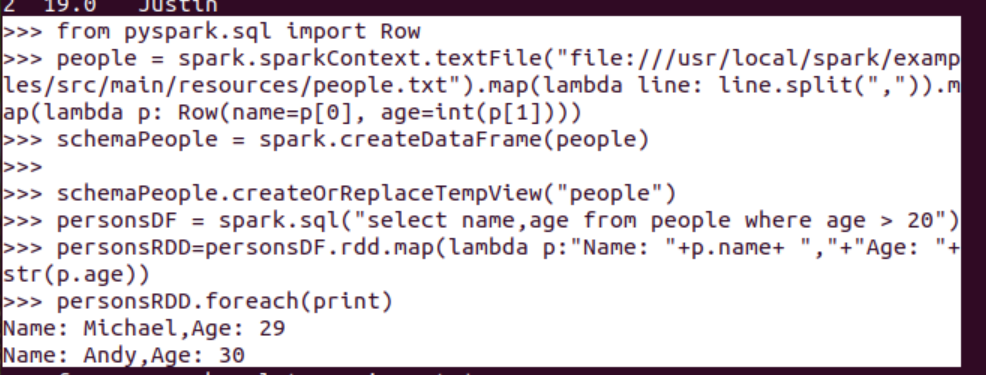
6.1 利用反射機制推斷RDD模式
創(chuàng)建RDD sc.textFile(url).map(),讀文件,分割數(shù)據(jù)項
每個RDD元素轉(zhuǎn)換成 Row
由Row-RDD轉(zhuǎn)換到DataFrame
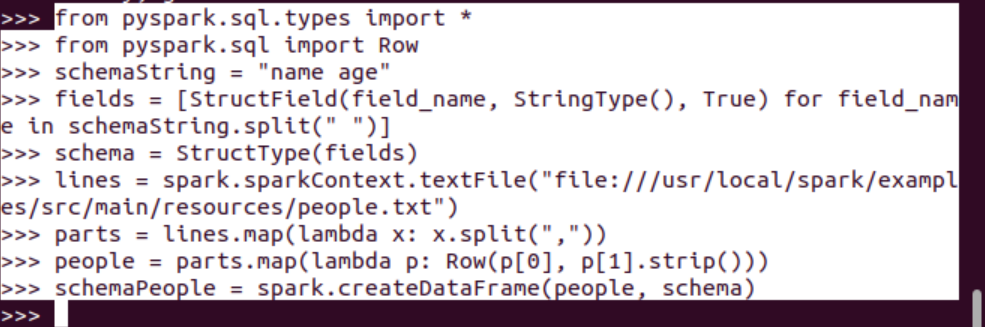
6.2 使用編程方式定義RDD模式
#下面生成“表頭”
#下面生成“表中的記錄”
#下面把“表頭”和“表中的記錄”拼裝在一起
4.選擇題
1單選(2分)?關(guān)于Shark,下面描述正確的是:C
A.Shark提供了類似Pig的功能
B.Shark把SQL語句轉(zhuǎn)換成MapReduce作業(yè)
C.Shark重用了Hive中的HiveQL解析、邏輯執(zhí)行計劃翻譯、執(zhí)行計劃優(yōu)化等邏輯
D.Shark的性能比Hive差很多
2單選(2分)?下面關(guān)于Spark SQL架構(gòu)的描述錯誤的是:D
A.在Shark原有的架構(gòu)上重寫了邏輯執(zhí)行計劃的優(yōu)化部分,解決了Shark存在的問題
B.Spark SQL在Hive兼容層面僅依賴HiveQL解析和Hive元數(shù)據(jù)
C.Spark SQL執(zhí)行計劃生成和優(yōu)化都由Catalyst(函數(shù)式關(guān)系查詢優(yōu)化框架)負責(zé)
D.Spark SQL執(zhí)行計劃生成和優(yōu)化需要依賴Hive來完成
3單選(2分)?要把一個DataFrame保存到people.json文件中,下面語句哪個是正確的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json")
4多選(3分)?Shark的設(shè)計導(dǎo)致了兩個問題:AC
A.執(zhí)行計劃優(yōu)化完全依賴于Hive,不方便添加新的優(yōu)化策略
B.執(zhí)行計劃優(yōu)化不依賴于Hive,方便添加新的優(yōu)化策略
C.Spark是線程級并行,而MapReduce是進程級并行,因此,Spark在兼容Hive的實現(xiàn)上存在線程安全問題,導(dǎo)致Shark不得不使用另外一套獨立維護的、打了補丁的Hive源碼分支
D.Spark是進程級并行,而MapReduce是線程級并行,因此,Spark在兼容Hive的實現(xiàn)上存在線程安全問題,導(dǎo)致Shark不得不使用另外一套獨立維護的、打了補丁的Hive源碼分支
5 多選(3分)?下面關(guān)于為什么推出Spark SQL的原因的描述正確的是:AB
A.Spark SQL可以提供DataFrame API,可以對內(nèi)部和外部各種數(shù)據(jù)源執(zhí)行各種關(guān)系操作
B.可以支持大量的數(shù)據(jù)源和數(shù)據(jù)分析算法,組合使用Spark SQL和Spark MLlib,可以融合傳統(tǒng)關(guān)系數(shù)據(jù)庫的結(jié)構(gòu)化數(shù)據(jù)管理能力和機器學(xué)習(xí)算法的數(shù)據(jù)處理能力
C.Spark SQL無法對各種不同的數(shù)據(jù)源進行整合
D.Spark SQL無法融合結(jié)構(gòu)化數(shù)據(jù)管理能力和機器學(xué)習(xí)算法的數(shù)據(jù)處理能力
6多選(3分)?下面關(guān)于DataFrame的描述正確的是:ABCD
A.DataFrame的推出,讓Spark具備了處理大規(guī)模結(jié)構(gòu)化數(shù)據(jù)的能力
B.DataFrame比原有的RDD轉(zhuǎn)化方式更加簡單易用,而且獲得了更高的計算性能
C.Spark能夠輕松實現(xiàn)從MySQL到DataFrame的轉(zhuǎn)化,并且支持SQL查詢
D.DataFrame是一種以RDD為基礎(chǔ)的分布式數(shù)據(jù)集,提供了詳細的結(jié)構(gòu)信息
7多選(3分)?要讀取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json")
8單選(2分)以下操作中,哪個不是DataFrame的常用操作:D
A.printSchema()
B.select()
C.filter()
D.sendto()
9多選(3分)?從RDD轉(zhuǎn)換得到DataFrame包含兩種典型方法,分別是:AB
A.利用反射機制推斷RDD模式
B.使用編程方式定義RDD模式
C.利用投影機制推斷RDD模式
D.利用互聯(lián)機制推斷RDD模式
10多選(3分)?使用編程方式定義RDD模式時,主要包括哪三個步驟:ABD
A.制作“表頭”
B.制作“表中的記錄”
C.制作映射表
D.把“表頭”和“表中的記錄”拼裝在一起


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號