
【設計經驗】5、Verilog對數據進行四舍五入(round)與飽和(saturation)截位
一、軟件平臺與硬件平臺
軟件平臺:
操作系統:Windows 8.1 64-bit
開發套件:Vivado2015.4.2 Matlab2016a
仿真工具:Vivado自帶仿真器
二、引言
在利用Verilog寫數字信號處理相關算法的過程中往往涉及到對數據的量化以及截位處理。而在實際項目中,一種比較精確的處理方式就是先對截位后的數據進行四舍五入(round),如果在四舍五入的過程中由于進位導致數據溢出,那么我們一般會對信號做飽和(saturation)處理。所謂飽和處理就是如果計算結果超出了要求的數據格式能存儲的數據的最大值,那么就用最大值去表示這個數據,如果計算結果超出了要求的數據格式能存儲的數據的最最小值,那么就用最小值去表示這個數據。這里先不給例子,下文會詳細描述這種情況。
為了敘述方便,本文先做如下規定:如果一個有符號數的總位寬為32位(其中最高位為符號位),小數位寬為16位,那么這個有符號數的數據格式記為32Q16。依次類推,10Q8表示這個數是一個有符號數(最高位為符號位),且總位寬為10位,小數位寬為8位。16Q13表示這個數是一個有符號數(最高位為符號位),且總位寬為16位,小數位寬為13位。總而言之,下文如果定義一個數據為mQn(m和n均為正整數且m>n)格式,那么我們可以得到三個重要的信息:
1、mQn是一個有符號數,最高位為符號位
2、mQn數據的總位寬為m
3、mQn數據的小數位寬為n
三、Verilog中有符號數據的補位與截位
3.1 有符號數與無符號數
顧名思義,有符號數指的就是帶有符號位的數據,其中最高位就是符號位(如果最高位為0,那么表示是正數,如果最高位為1,那么表示是負數);無符號數就是不帶有符號位的數據。
考慮一個4位的整數4’b1011.如果它是一個無符號數據,那么它表示的值為:1*23+0*22+1*21+1*20 = 11.如果它是一個有符號數,那么它表示的值為:1*(-23)+0*22+1*21+1*20 = -5.所以相同的二進制數把它定義為有符號數和無符號數表示的數值大小有可能是不同的。同時,這里也告訴大家,有符號數和無符號數轉化為10進制表示的時候唯一的區別就是最高位的權重不同,拿上例來說,無符號數最高位的權重是23而有符號數最高位的權重是-23。
正因為有符號數和無符號數最高位的權重不同,所以他們所表示的數據范圍也是不同的。比如,一個4位的無符號整數的數據范圍為0~15,分別對應二進制4’b0000~4’b1111,而一個4位的有符號整數的數據范圍為-8~7,分別對應二進制4’b1000~4’b0111.
擴展到一般情況,一個位寬為m的無符號整數的數據范圍為0~2m-1,而一個位寬為m的有符號整數的數據范圍為-2(m-1)~2(m-1)-1。
3.2 有符號整數的符號位擴展
問題:如何把一個4位的有符號整數擴展成6位的有符號整數。
假設一個4位的有符號整數為4’b0101,顯然由于最高位為0,所以它是一個正數,如果要把它擴展成6位,那么只需要在最前面加2個0即可,擴展之后的結果為:6’b000101。
在看另外一個例子,假設一個4位的有符號整數為4’b1011,顯然由于最高位為1,所以它是一個負數,如果要把它擴展成6位,那么這里要千萬注意了,前面不是添2個0,而是添2個1,擴展之后的結果為:6’b111011。為了確保數據擴位以后沒有發生錯誤,這里做一個簡單的驗證:
4’b1011 = 1*(-23)+0*22+1*21+1*20 = -8 + 0 + 2 + 1 = -5
6’b111011 = 1*(-25)+1*24+1*23+0*22+1*21+1*20 = -32+16+8+2+1=-5
顯然擴位以后數據大小并未發生變化。
綜上得出結論:對一個有符號整數進行擴位的時候為了保證數據大小不發生變化,擴位的時候應該添加的是符號位。
3.3 有符號小數
有了前面兩小節的基礎以后接下來研究一下有符號小數。前面已經規定了有符號小數的記法。
假設一個有符號小數為4’b1011,它的數據格式為4Q2,也就是說它的小數位為2位。那么看看這個數表示的10進制數是多少
4’b10.11 = 1*(-21)+0*20+1*2-1+1*2-2 = -2 + 0 + 0.5 + 0.25 = -1.25
顯然,小數的計算方法實際上和整數的計算方法是一樣的,只不過我們要根據小數點的位置來確定對應的權重。
接下來看看有符號小數的數據范圍。就拿4Q2格式的數據來說,它的數據范圍為-2~(2-1/22),分別對應二進制4’b1000~4’b0111.擴展到一般情況,mQn格式數據的數據范圍為-2(m-n-1)~2(m-n-1)-1/2n。
最后再來看看有符號小數的數據擴展。假設一個有符號小數為4’b1011,它的數據格式為4Q2,現在要把這個數據用6Q3格式的數據存儲。顯然需要把整數部分和小數部分分別擴一位,整數部分采用上一節提到的符號位擴展,小數部分則在最后面添一個0,擴展以后的結果為6’b110110,接下來仍然做一個驗證
4’b10.11 = 1*(-21)+0*20+1*2-1+1*2-2 = -2 + 0 + 0.5 + 0.25 = -1.25
6’b110.110 = 1*(-22)+1*21+0*20+1*2-1+1*2-2 +0*2-3= -4 + 2 + 0 + 0.5 + 0.25 + 0 = -1.25
顯然,擴位以后數據大小并未發生變化。
總結:有符號小數進行擴位時整數部分進行符號位擴展,小數部分在末尾添0.
3.4 兩個有符號數的和
兩個有符號數相加,為了保證和不溢出,首先應該把兩個數據進行擴展使小數點對齊,然后把擴展后的數據繼續進行一位的符號位擴展,這樣相加的結果才能保證不溢出。
舉例:現在要把5Q2的數據5’b100.01和4Q3的數據4’b1.011相加。
Step1、由于5Q2的數據小數位只有2位,而4Q3的數據小數點有3位,所以先把5Q2的數據5’b100.01擴位為6Q3的數據6’b100.010,使它和4Q3數據的小數點對齊
Step2、小數點對齊以后,然后把4Q3的數據4’b1.011進行符號位擴展成6Q3的數據6’b111.011
Step3、兩個6Q3的數據相加,為了保證和不溢出,和應該用7Q3的數據來存儲。所以需要先把兩個6Q3的數據進行符號位擴展成7Q3的數據,然后相加,這樣才能保證計算結果是完全正確的。
以上就是兩個有符號數據相加需要做的一系列轉化。回過頭來思考為什么兩個6Q3的數據相加必須用7Q3的數據才能準確的存儲他們的和。因為6Q3格式數據的數據范圍為-4~4-1/23;那么兩個6Q3格式的數據相加和的范圍為-8~8-1/22;顯然如果和仍然用6Q3來存一定會溢出,而7Q3格式數據的數據范圍為-8~8-1/23,因此用7Q3格式的數據來存2個6Q3格式數據的和一定不會溢出。
結論:在用Verilog做加法運算時,兩個加數一定要對齊小數點并做符號位擴展以后相加,和才能保證不溢出。
3.5 兩個有符號數的積
兩個有符號數相乘,為了保證積不溢出,積的總數據位寬為兩個有符號數的總位寬之和,積的小數數據位寬為兩個有符號數的小數位寬之和。簡單來說,兩個4Q2數據相乘,要想保證積不溢出,積應該用8Q4格式來存。這是因為4Q2格式數據的范圍為:-2~(2-1/22),那么兩個4Q2數據相乘積的范圍為:(-4+1/2)~4,而8Q4格式的數據范圍為:-8~(8-1/24),一定能準確的存放兩個4Q2格式數據的積。
結論: mQn和aQb數據相乘,積應該用(m+a)Q(n+b)格式的數據進行存儲。
3.6 四舍五入(round)
前面講的都是對數據進行擴位,這一節說的是對數據截位時如何進行四舍五入以提高截位后數據的精度。
假設一個9Q6格式的數據為:9’b011.101101,現在只想保留3位小數位,顯然必須把最后三位小數位截掉,但是不能直接把數據截成6’b011.101,這樣是不精確的,工程上一般也不允許這么做,正確的做法是先看這個數據是正數還是負數,因為9’b011.101101的最高位為0,所以它是一個正數,然后再看截掉部分(此例中截掉部分是最末尾的101)的最高位是0還是1,在數據是正數的情況下,如果截掉部分的最高位為1,那么是需要產生進位的,所以,最終9’b011.101101應該被截成6’b011.110.
如果是負數則正好相反。假設一個9Q6格式的數據為:9’b100.101101,由于最高位是1,所以這個數是一個負數,然后再看截斷部分的最高位以及除最高位的其他位是否有1,此例中截斷部分(截斷部分為末尾的101)的最高位為1,而且除最高位以外的其他位也有為1的情況,由于負數最高位的權重是(-22),所以對于這種情況是不需要進位的,與正數不同的是,負數不進位是需要加1的。因此最終9’b100.101101應該被截成6’b100.110。
假設a是一個9Q6格式的數據,要求把小數位截成3位。下面是Verilog代碼:
assign carry_bit = a[8] ? ( a[2] & ( |a[1:0] ) ) : a[2] ;
assign a_round = {a[8], a[8:3]} + carry_bit ;
上面的代碼第一行是通過判斷符號位a[8]和截斷部分數據特征來確定是否需要進位,如果a[8]是0,計算得到的carry_bit為1,則表示是a是正數,且截斷是需要進位;如果a[8]是1,計算得到的carry_bit為1,則表示是a是負數,且截斷是不需要進位的,負數不進位需要加1。代碼第二行為了保證進位后數據不溢出,所以擴展了一位符號位。
3.7 飽和(saturation)截位
所謂飽和處理就是如果計算結果超出了要求的數據格式能存儲的數據的最大值,那么就用最大值去表示這個數據,如果計算結果超出了要求的數據格式能存儲的數據的最最小值,那么就用最小值去表示這個數據。
例1:有一個6Q3的數據為6’b011.111,現在要求用4Q2格式的數據去存儲它,顯然6’b011.111轉化為10進制如下:
6’b011.111 = 1*21+1*20+1*2-1+1*2-2+1*2-3 = 3.875
而4Q2格式的數據能表示的數據的最大值為4’b01.11,轉化為10進制為1.75,因此4Q2格式的數據根本無法準確的存放3.875這個數據,這樣就是所謂的飽和情況。在這種情況下,飽和處理就是把超過了1.75的所有數據全部用1.75來表示,也就是說,6Q3的數據為6’b011.111如果非要用4Q2格式的數據來存儲的話,在進行飽和處理的情況下最終的存儲結果為:4’b01.11。
例2:有一個6Q3的數據為6’b100.111,現在要求用4Q2格式的數據去存儲它,顯然6’b100.111轉化為10進制如下:
6’b100.111 = 1*(-22)+1*2-1+1*2-2+1*2-3 = -4 + 0.5 + 0.25 + 0.125 = -3.125
而4Q2格式的數據能表示的數據的最小值為4’b10.00,轉化為10進制為-2,因此4Q2格式的數據根本無法準確的存放-3.125這個數據,這是另一種飽和情況。在這種情況下,飽和處理就是把小于-2的所有數據全部用-2來表示,也就是說,6Q3的數據為6’b100.111如果非要用4Q2格式的數據來存儲的話,在進行飽和處理的情況下最終的存儲結果為:4’b10.00。
四、實例演示(a + b * c)
4.1 題目要求
假設a的數據格式為16Q14,b的數據格式為16Q14,c的數據格式為16Q15,請計算s=a+b*c的值,其中s的數據格式為16Q14。在截位的過程中利用四舍五入(round)的方式保證數據精度,如果有數據溢出的情況,請用飽和截位的方式進行處理。編寫完Verilog代碼以后利用Matlab產生a、b、c的數據對寫的Verilog代碼進行仿真,并保證Matlab運算得到的數據和Verilog運算得到的數據全部相同。最后,有條件的利用VCS統計代碼覆蓋率(Code Coverage),確保條件覆蓋率(Condition Coverage)達到100%。
4.2 要求分析
1、先分析b*c。由于b的數據格式為16Q14,c的數據格式為16Q15,所以為了保證b*c的乘積不溢出,那么b*c的乘積的數據格式為(16+16)Q(14+15),即32Q29。
2、再分析加法。由于a的數據格式為16Q14,而b*c的積的數據格式為32Q29,所以相加之前要先把a擴展成32Q29格式的數據,又為了保證相加的結果不溢出,相加之前還要把兩個32Q29格式的數據進行1位符號位擴展成33Q29格式的數據以后再相加,相加得到的和的數據格式為33Q29.
3、最后,由于要求最終的結果為16Q14,所以需要把33Q29的數據截位為16Q14,如果出現數據溢出的情況,需要用飽和截位的方式進行處理。
分析完畢以后,就開始進行代碼的編寫。
4.3 Verilog代碼分析
本題的Verilog代碼如下
1 module dsp( 2 input I_clk , 3 input I_rst_n , 4 input signed [15:0] I_a , // 16Q14 5 input signed [15:0] I_b , // 16Q14 6 input signed [15:0] I_c , // 16Q15 7 output signed [15:0] O_s // 16Q14 8 ); 9 10 reg signed [15:0] R_a_16Q14 ;// 16Q14 11 reg signed [15:0] R_b_16Q14 ;// 16Q14 12 reg signed [15:0] R_c_16Q15 ;// 16Q15 13 14 wire signed [31:0] W_mult_b_c_32Q29 ; //32Q29 15 wire signed [32:0] W_s_33Q29 ; // 33Q29 16 wire signed [31:0] W_a_32Q29 ; 17 18 wire W_carry_bit ; 19 wire [18:0] W_s_19Q14_round ; 20 21 always @(posedge I_clk or negedge I_rst_n) 22 begin 23 if(!I_rst_n) 24 begin 25 R_a_16Q14 <= 16'd0 ; 26 R_b_16Q14 <= 16'd0 ; 27 R_c_16Q15 <= 16'd0 ; 28 end 29 else 30 begin 31 R_a_16Q14 <= I_a ; 32 R_b_16Q14 <= I_b ; 33 R_c_16Q15 <= I_c ; 34 end 35 end 36 37 assign W_mult_b_c_32Q29 = R_b_16Q14 * R_c_16Q15 ; 38 assign W_a_32Q29 = {R_a_16Q14[15], R_a_16Q14, {15{1'b0}}} ; 39 assign W_s_33Q29 = {W_a_32Q29[31], W_a_32Q29} + {W_mult_b_c_32Q29[31], W_mult_b_c_32Q29} ; 40 41 assign W_carry_bit = W_s_33Q29[32] ? ( W_s_33Q29[14] & (|W_s_33Q29[13:0]) ) : W_s_33Q29[14] ; 42 assign W_s_19Q14_round = {W_s_33Q29[32],W_s_33Q29[32:15]} + W_carry_bit ; 43 44 assign O_s = (W_s_19Q14_round[18:15] == 4'b0000 || W_s_19Q14_round[18:15] == 4'b1111) ? W_s_19Q14_round[15:0]:{W_s_19Q14_round[18],{15{!W_s_19Q14_round[18]}}} ; 47 48 endmodule
1、代碼第37行計算的是b*c的值,由于b的數據格式為16Q14,而c的數據格式為16Q15,所以他們的乘積定義的數據格式為32Q29,這樣可以保證乘積絕不會溢出。
2、代碼第38行把16Q14格式的數據a擴展到32Q29格式,這么做的目的是讓a和b*c的值的小數點對齊以保證做加法運算的時候不會出錯
3、代碼第39行是把a和b*c的結果進行相加,為了保證相加的結果不會溢出,那么相加前必須對兩個加數進行一位的符號位擴展。
4、第41行和第42行代碼就是對a+b*c的結果截位后進行四舍五入(round)。由于a+b*c結果的數據格式為33Q29,根據題目要求要把它變成16Q14格式的數據,所以第一步需要做的就是把33Q29格式數據的最后15位小數位(也就是要把W_s_33Q29[14:0]位截掉)截掉,但是截掉W_s_33Q29[14:0]以后,一定要判段是否需要進位,第41行的代碼就是用來產生進位的邏輯,計算出這個進位以后,然后把這個進位加到W_s_33Q29[32:15]上完成四舍五入(round)的操作,值得注意的是,為了保證加上進位的時候數據不會溢出,在加進位之前一定要對W_s_33Q29[32:15]進行1位的符號位擴展。
5、完成了四舍五入(round)的操作以后,那么小數部分我們已經全部處理完畢,接下來就來處理整數部分。由于完成四舍五入以后的數據W_s_19Q14_round的數據格式為19Q14,我們的目標是要把他進一步截位成16Q14的數據,所以我們需要把W_s_19Q14_round的高3位W_s_19Q14_round[18:16]截掉。如果W_s_19Q14_round[18:16]和W_s_19Q14_round[15]相同,也就是說W_s_19Q14_round[18:15]==4'b0000 或W_s_19Q14_round[18:15]==4'b1111,那么說明W_s_19Q14_round[18:16]是W_s_19Q14_round[15]位的符號位擴展,我們可以直接把高三位W_s_19Q14_round[18:16]截掉保留W_s_19Q14_round[15]位即可。但如果W_s_19Q14_round[18:16]和W_s_19Q14_round[15]不相同,也就是說W_s_19Q14_round[18:15]==4'b0000 或W_s_19Q14_round[18:15]==4'b1111不成立的情況下,那么說明W_s_19Q14_round這個數據所表示的值用16Q14格式的數據是存不下的,會發生溢出,這種情況題目要求我們用飽和截位的方式進行處理,處理方式就很簡單了,直接判斷W_s_19Q14_round的最高位W_s_19Q14_round[18],如果W_s_19Q14_round[18]為0,那么代表W_s_19Q14_round是一個正數,飽和處理就是把它變成16Q14格式數據能夠存儲的最大整數16'b0_111111111111111,如果W_s_19Q14_round[18]為1,那么代表W_s_19Q14_round是一個負數,飽和處理就是把它變成16Q14格式數據能夠存儲的最小負數16'b1_000000000000000。代碼見44行。
到此,整個代碼編寫與分析完畢。
完成代碼的編寫以后接下來就要寫一個測試文件來測試代碼的正確性。大致的思路是用Matlab產生符合條件的a、b、c的數據,然后通過Verilog系統調用$readmemh或$readmemb讀進來送給dsp.v模塊進行計算,接著把dsp.v模塊的輸出寫到另外一個.txt文件中,然后和Matlab計算的結果進行對比,如果所有的數據的每一個bit都沒有錯誤,而且你的Verilog代碼覆蓋率(Code Coverage)達到了100%(沒用過VCS的同學可以暫時先不用關系代碼覆蓋率的概念),那么才證明你寫的dsp.v模塊功能是OK的。
測試激勵文件的代碼如下所示
1 `timescale 1ns / 1ps 2 3 module tb_dsp; 4 reg I_clk ; 5 reg I_rst_n ; 6 reg [15:0] I_a ; 7 reg [15:0] I_b ; 8 reg [15:0] I_c ; 9 10 wire [15:0] O_s ; 11 12 parameter C_DATA_LENGTH = 4096 ; 13 14 reg [15:0] M_mem_a[0:C_DATA_LENGTH - 1] ; 15 reg [15:0] M_mem_b[0:C_DATA_LENGTH - 1] ; 16 reg [15:0] M_mem_c[0:C_DATA_LENGTH - 1] ; 17 reg [13:0] R_mem_addr ; 18 reg R_data_vaild ; 19 reg R_data_vaild_t ; 20 21 dsp u_dsp 22 ( 23 .I_clk, 24 .I_rst_n(I_rst_n), 25 .I_a(I_a), // 16Q14 26 .I_b(I_b), // 16Q14 27 .I_c(I_c), // 16Q15 28 .O_s(O_s) 29 ); 30 31 32 33 initial begin 34 I_clk = 0 ; 35 I_rst_n = 0 ; 36 37 #67 I_rst_n = 1 ; 38 end 39 40 initial begin 41 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/a_16Q14.txt",M_mem_a); 42 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/b_16Q14.txt",M_mem_b); 43 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/c_16Q15.txt",M_mem_c); 44 end 45 46 always #5 I_clk = ~I_clk ; 47 48 always @(posedge I_clk or negedge I_rst_n) 49 begin 50 if(!I_rst_n) 51 begin 52 I_a <= 16'd0 ; 53 I_b <= 16'd0 ; 54 I_c <= 16'd0 ; 55 R_mem_addr <= 14'd0 ; 56 R_data_vaild <= 1'b0 ; 57 end 58 else if(R_mem_addr == C_DATA_LENGTH ) 59 begin 60 R_mem_addr <= C_DATA_LENGTH ; 61 R_data_vaild <= 1'b0 ; 62 end 63 else 64 begin 65 I_a <= M_mem_a[R_mem_addr] ; 66 I_b <= M_mem_b[R_mem_addr] ; 67 I_c <= M_mem_c[R_mem_addr] ; 68 R_mem_addr <= R_mem_addr + 1'b1 ; 69 R_data_vaild <= 1'b1 ; 70 end 71 end 72 73 always @(posedge I_clk or negedge I_rst_n) 74 begin 75 if(!I_rst_n) 76 R_data_vaild_t <= 1'b0 ; 77 else 78 R_data_vaild_t <= R_data_vaild ; 79 end 80 81 82 integer fid ; 83 84 initial begin 85 fid = $fopen("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/s_vivado.txt" , "w"); 86 if(!fid) 87 begin 88 $display("**********************Can Not Open File*************************************"); 89 $finish; 90 end 91 else 92 begin 93 $display("**********************Open File Success*************************************"); 94 end 95 end 96 97 always @(posedge I_clk ) 98 begin 99 if(R_data_vaild_t) 100 $fdisplay(fid,"%d",$signed(O_s)); 101 else if(R_mem_addr == C_DATA_LENGTH) 102 begin 103 $fclose(fid) ; 104 $finish ; 105 end 106 end 107 108 endmodule
這段代碼需要注意一下幾點:
1、$readmemh系統調用后面文件的路徑一定要填絕對路徑,而且路徑分隔符是左斜杠"/",而不是右斜杠"\"。
2、我之所以要把R_data_valid延時一拍為R_data_valid_t是因為我在dsp.v模塊中把a、b、c三個數據都延時了一拍,這里是為了保證數據對齊。
下一小節會詳細的介紹如何產生測試激勵文件中a、b、c三個數據的方法。
4.4 利用Matlab產生a、b、c三個數據
Matlab里面有現成的量化數據的函數,它們分別是quantizer函數和quantize函數。其中quantizer函數用來產生量化格式,quantize函數用來調用quantizer函數的結果對數據進行量化,具體的用法在Matlab命令行中輸入doc quantizer和doc quantize可以查看。
產生a、b、c三個數據的Matlab代碼如下:
clear clc data_length = 4096 - 8 ; % 定義數據長度,其中排除8種邊界條件 a_min = -2 ; %a的數據格式為16Q14,所以它的最小值為-2 a_max = 2 - 1/(2^14) ; %a的數據格式為16Q14,所以它的最大值為2 - 1/(2^14) b_min = -2 ; %b的數據格式為16Q14,所以它的最小值為-2 b_max = 2 - 1/(2^14) ; %b的數據格式為16Q14,所以它的最大值為2 - 1/(2^14) c_min = -1 ; %c的數據格式為16Q15,所以它的最小值為-1 c_max = 1 - 1/(2^15) ; %c的數據格式為16Q15,所以它的最大值為1 - 1/(2^15) % 產生4088個均勻分布在a、b、c最大值與最小值之間的隨機數 a_rand = a_min + (a_max - a_min)*rand(1,data_length) ; b_rand = b_min + (b_max - b_min)*rand(1,data_length) ; c_rand = c_min + (c_max - c_min)*rand(1,data_length) ; % 產生8種邊界條件 a_boundary = [a_min a_min a_min a_min a_max a_max a_max a_max] ; b_boundary = [b_min b_min b_max b_max b_min b_min b_max b_max] ; c_boundary = [c_min c_max c_min c_max c_min c_max c_min c_max] ; % 隨機數與邊界值組合成為待量化的數據 a = [a_boundary a_rand]; b = [b_boundary b_rand]; c = [c_boundary c_rand]; % 定義量化規則,根據題目要求量化需采用四舍五入與飽和截位的方式 quan_16Q14_pattern = quantizer('fixed','round','saturate',[16,14]); quan_16Q15_pattern = quantizer('fixed','round','saturate',[16,15]); quan_33Q29_pattern = quantizer('fixed','round','saturate',[33,29]); % 把a、b、c三個數據按照要求進行量化 a_16Q14 = quantize(quan_16Q14_pattern,a); b_16Q14 = quantize(quan_16Q14_pattern,b); c_16Q15 = quantize(quan_16Q15_pattern,c); % 計算a + b * c的值 s = a_16Q14 + b_16Q14 .* c_16Q15 ; % 根據題目要求,s的數據格式為16Q14,所以這里把s量化為16Q14格式的數據 s_16Q14 = quantize(quan_16Q14_pattern,s); % 把量化后的a、b、c變成整數方便寫入.txt文件中 a_integer = a_16Q14 * 2^14 ; b_integer = b_16Q14 * 2^14 ; c_integer = c_16Q15 * 2^15 ; s_integer = s_16Q14 * 2^14 ; % 由于在Verilog中測試激勵文件的系統調用$readmemh讀入的數據格式為16進制,所以 % 把數據寫入.txt文件中之前需要把數據轉化為補碼的格式,這樣負數才不會寫錯 a_complement = zeros(1,length(a_integer)); b_complement = zeros(1,length(b_integer)); c_complement = zeros(1,length(c_integer)); % 把量化后的a轉化為補碼 for i = 1:length(a_complement) if(a_integer(i) < 0) a_complement(i) = 2^16 + a_integer(i) ; else a_complement(i) = a_integer(i) ; end end % 把量化后的b轉化為補碼 for i = 1:length(b_complement) if(b_integer(i) < 0) b_complement(i) = 2^16 + b_integer(i) ; else b_complement(i) = b_integer(i) ; end end % 把量化后的c轉化為補碼 for i = 1:length(c_complement) if(c_integer(i) < 0) c_complement(i) = 2^16 + c_integer(i) ; else c_complement(i) = c_integer(i) ; end end % 把量化后的a的補碼寫入txt文件 fid_a = fopen('a_16Q14.txt','w'); fprintf(fid_a, '%x\n', a_complement); fclose(fid_a); % 把量化后的b的補碼寫入txt文件 fid_b = fopen('b_16Q14.txt','w'); fprintf(fid_b, '%x\n', b_complement); fclose(fid_b); % 把量化后的c的補碼寫入txt文件 fid_c = fopen('c_16Q15.txt','w'); fprintf(fid_c, '%x\n', c_complement); fclose(fid_c); % 把量化后的s以整數形式寫入txt文件,方便和vivado計算的結果進行對比 fid_s = fopen('s_matlab.txt','w'); fprintf(fid_s, '%d\n', s_integer); fclose(fid_s);
這段代碼基本都做了詳細的注釋,這里在強調幾點:
1、Matlab中的“*”表示矩陣相乘,如果要對兩個向量對于的數據進行乘法運算應該要用“.*”
2、由于有符號數都是用補碼進行存放的,所以在把數據寫入txt文件之前一定要先把數據變成補碼的格式
3、代碼運行結束后會產出一個警告,提示運算過程中出現了溢出,這個是正常的,而且是我故意設計的,溢出的情況Matlab會按照quantizer函數定義的量化Pattern進行處理,所以如果之前寫的Verilog的代碼沒問題的話,那么Matlab的運算結果和Vivado得到的結果應該是完全相同的。
4、代碼運行結束以后,在和代碼相同的目錄下會產生四個txt文件,其中a_16Q14.txt,b_16Q14.txt,c_16Q15.txt用來被testbench中的$readmemh讀進去,s_matlab.txt文件用來和s_vivado.txt進行后面的數據對比。
到此為止,已經得到了符合要求的a、b、c的測試數據,接下來就需要寫一個Matlab的腳本對Matlab的計算結果s_matlab.txt與Vivado的計算結果s_vivado.txt進行對比,看是否數據完全相同。測試腳本的代碼如下:
clear clc filename1 = 's_matlab.txt' ; filename2 = 's_vivado.txt' ; % s_matlab = textread(filename1, '%d') ; % s_vivado = textread(filename2, '%d') ; % 把txt文件中的數據讀入并轉化為一維數組,上面2行注釋的代碼和下面6行代碼的作用是完全一樣的 % 由于Matlab目前的版本不推薦使用textread,所以我使用了textscan函數進行處理 fid1 = fopen(filename1, 'r'); fid2 = fopen(filename2, 'r'); s_matlab = textscan(fid1, '%d') ; s_vivado = textscan(fid2, '%d') ; s_matlab = cell2mat(s_matlab) ; s_vivado = cell2mat(s_vivado) ; count = 0 ; % 對s_vivado.txt的數據與s_matlab.txt的數據進行對比 for i = 1:length(s_vivado) if(s_vivado(i) == s_matlab(i)) msg = sprintf('s_vivado(%d) is equal s_matlab(%d), Verification Pass', i , i) ; disp(msg) ; count = count + 1 ; else msg = sprintf('s_vivado(%d) is not equal s_matlab(%d), Verification Fail', i , i) ; disp(msg) ; end end msg = sprintf('Total Pass Number is %d', count) ; disp(msg) ;
上面的代碼就是把s_vivado.txt和s_matlab.txt的數據讀進來然后做一個對比,如果數據完全相同,那么說明你用Verilog寫的四舍五入(round),截位飽和的邏輯應該是沒問題的,但是工作只完成了95%,剩下還有5%的工作我們需要進一步看代碼覆蓋率是否達到了100%(沒用過VCS的可以忽略這一步)。下面寫看一下上述代碼的運行截圖
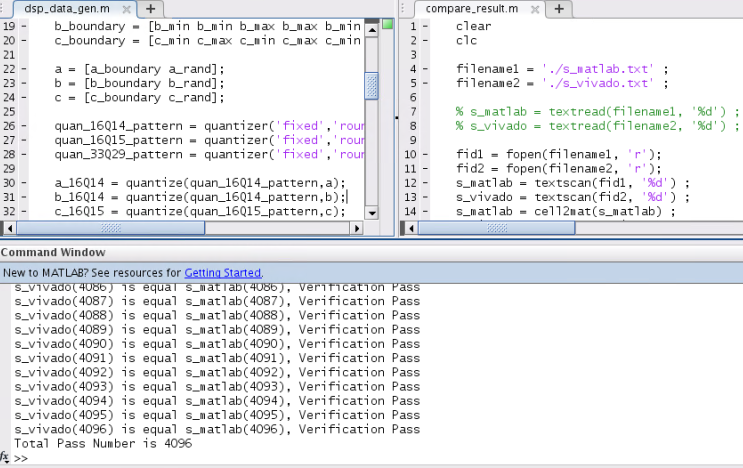
由上圖可以看出,Matlab與Vivado計算產生的4096個的數據完全相同。可初步確認邏輯基本正確,下一小節在看看代碼覆蓋率。
4.5 查看代碼覆蓋率(Code Coverage)
數字IC設計工程師用的仿真器大多是Synopsys公司的VCS和Verdi,VCS有一個非常重要的功能就是查看代碼覆蓋率(Code Coverage)。代碼覆蓋率(Code Coverage)分5種,分別為行覆蓋率(line)、切換覆蓋率(Toggle)、狀態機覆蓋率(FSM)、條件覆蓋率(Condition)以及分支覆蓋率(Branch)。針對這個例子來說,由于在dsp.v模塊中對W_a_16Q14的低15位進行了補0,所以切換覆蓋率(Toggle)不可能達到100%,這是合理的,但是條件覆蓋率(Condition)一定要達到100%,因為代碼中的每一個條件對應一種數據處理的場景,所以如果條件覆蓋率(Condition)沒達到100%,那么證明你產生的測試數據還沒有覆蓋所有的情況,需要回過頭去思考原因。由于VCS又是一個大話題,所以這一節不說細節,直接給出代碼覆蓋率(Code Coverage)的截圖如下圖所示

由上圖可知條件覆蓋率確實為100%,證明我們產生的測試數據已經覆蓋到了代碼中的每種情況,至此可以下結論:整個四舍五入、飽和截位的邏輯全部驗證完成。
五、總結
本文的數字信號處理的例子盡管非常簡單,只是一個普通的乘加結構,但是基本上涵蓋了利用Verilog做數字信號處理時需要關注的方方面面。學完本文你應該知道:
1、無符號數與有符號數的本質區別:最高位的權重不同
2、有符號數符號位擴展的原理
3、mQn格式數據的數據范圍
4、兩個有符號數相加,應該先把小數點對齊,然后做一位的符號位擴展以后才能相加
5、Verilog四舍五入(round)原理
6、飽和截位的原理
7、用Matlab產生$readmemh可讀入的數據
8、用Matlab驗證算法結果的正確性
六、參考資料
1、verilog實現 floor, round 四舍五入 和 saturation 操作。鏈接:http://bbs.21ic.com/icview-2626038-1-1.html
2、Matlab定點量化。鏈接:https://blog.csdn.net/sunlight369/article/details/42742235

 浙公網安備 33010602011771號
浙公網安備 33010602011771號