
CFS任務的負載均衡(load balance)
前言
我們描述CFS任務負載均衡的系列文章一共三篇,第一篇是框架部分,第二篇描述了task placement和active upmigration兩個典型的負載均衡場景。本文是第三篇,主要是分析各種負載均衡的觸發和具體的均衡邏輯過程。
本文出現的內核代碼來自Linux5.10.61,為了減少篇幅,我們盡量刪除不相關代碼,如果有興趣,讀者可以配合代碼閱讀本文。
一、幾種負載均衡的概述
整個Linux的負載均衡器有下面的幾個類型:
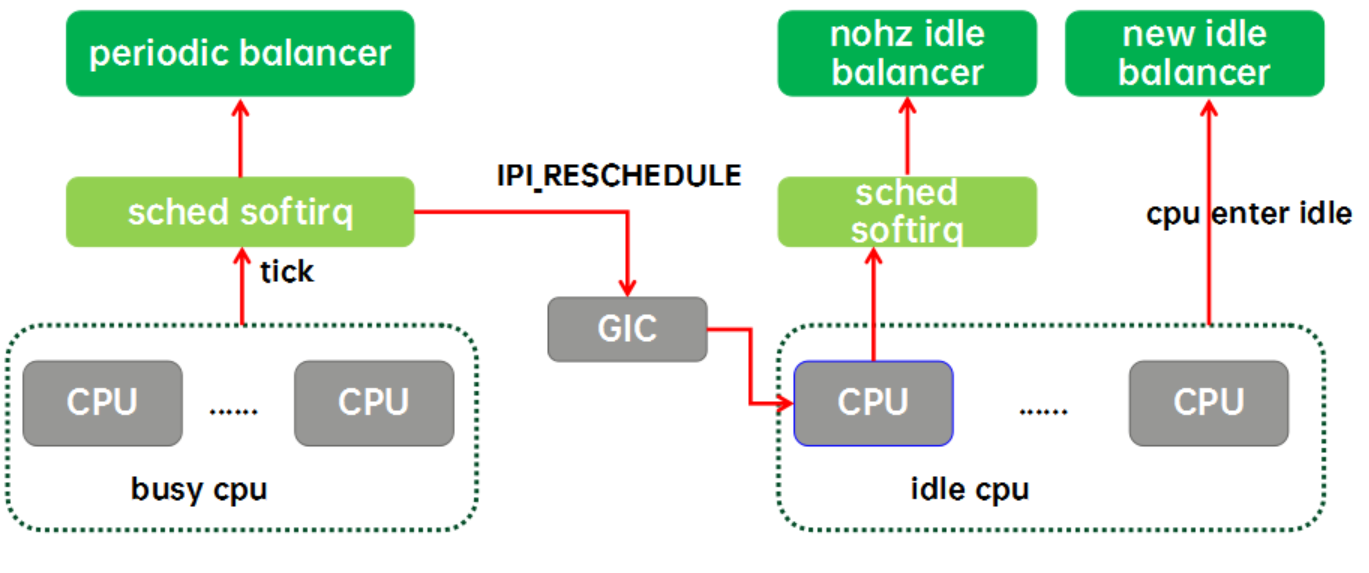
實際上內核的負載均衡器(本文都是特指CFS任務的)有兩種,一種是為繁忙CPU們準備的periodic balancer,用于CFS任務在busy cpu上的均衡。還有一種是為idle cpu們準備的idle balancer,用于把繁忙CPU上的任務均衡到idle cpu上來。idle balancer有兩種,一種是nohz idle balancer,另外一種是new idle balancer。
周期性負載均衡(periodic load balance或者tick load balance)是指在tick中,周期性的檢測系統的負載均衡狀況。周期性負載均衡是一個自底向上的均衡過程。即從該CPU對應的base sched domain開始,向上直到頂層sched domain,在各個level的domain上進行負載均衡。具體在某個特定的domain上進行負載均衡是比較簡單,找到domain中負載最重的group和CPU,將其上的runnable任務拉到本CPU以便讓該domain上各個group的負載處于均衡的狀態。由于Linux上的負載均衡僅支持任務拉取,周期性負載均衡只能在busy cpu之間均衡,不能把任務push到其他空閑CPU上,要想讓系統中的idle cpu“燥起來”就需要借助idle load balance。
NOHZ load balance是指其他的cpu已經進入idle(錯過new idle balance),本CPU任務太重,需要通過ipi將其他idle的CPUs喚醒來進行負載均衡。為什么叫NOHZ load balance呢?那是因為這個balancer只有在內核配置了NOHZ(即tickless mode)下才會生效。如果CPU進入idle之后仍然有周期性的tick,那么通過tick load balance就能完成負載均衡了,不需要IPI來喚醒idle的cpu。和周期性均衡一樣,NOHZ idle load balance也是通過busy cpu上tick驅動的,如果需要kick idle load balancer,那么就會通過GIC發送一個ipi中斷給選中的idle cpu,讓它代表系統所有的idle cpu們進行負載均衡。NOHZ load balance具體均衡的方式和tick balance類似,也是自底向上,在整個sched domain hierarchy進行均衡的過程,不同的是NOHZ load balance會在多個CPU上執行這個均衡過程。
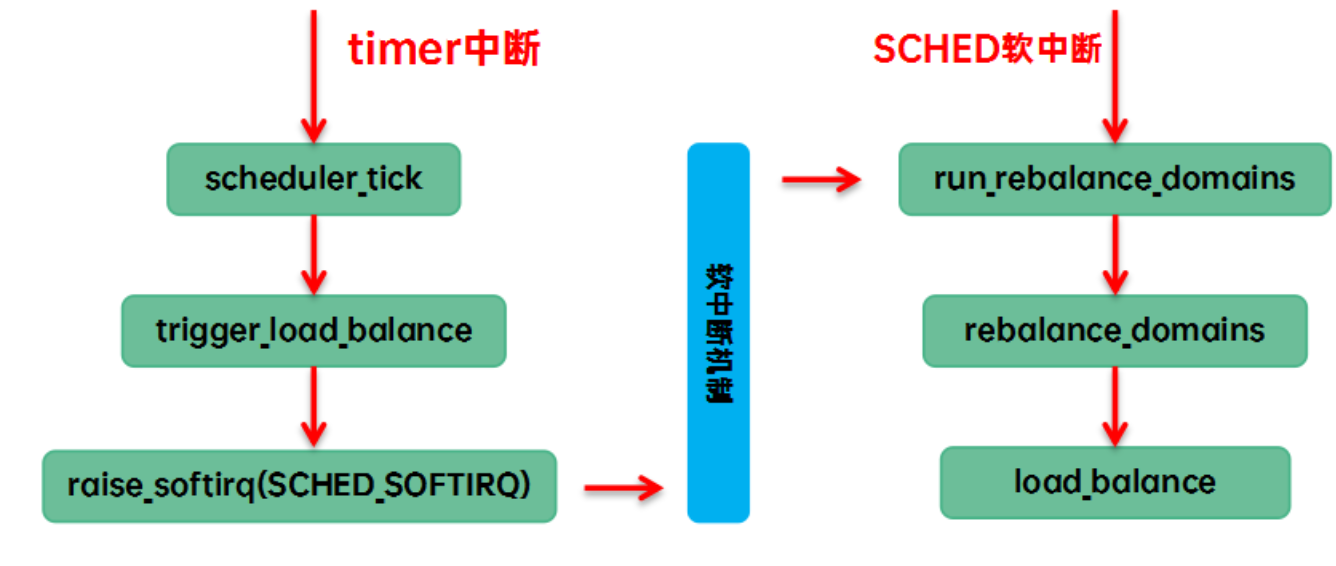
(1)在tick中觸發load balance。我們稱之tick load balance或者periodic load balance。具體的代碼執行路徑是:
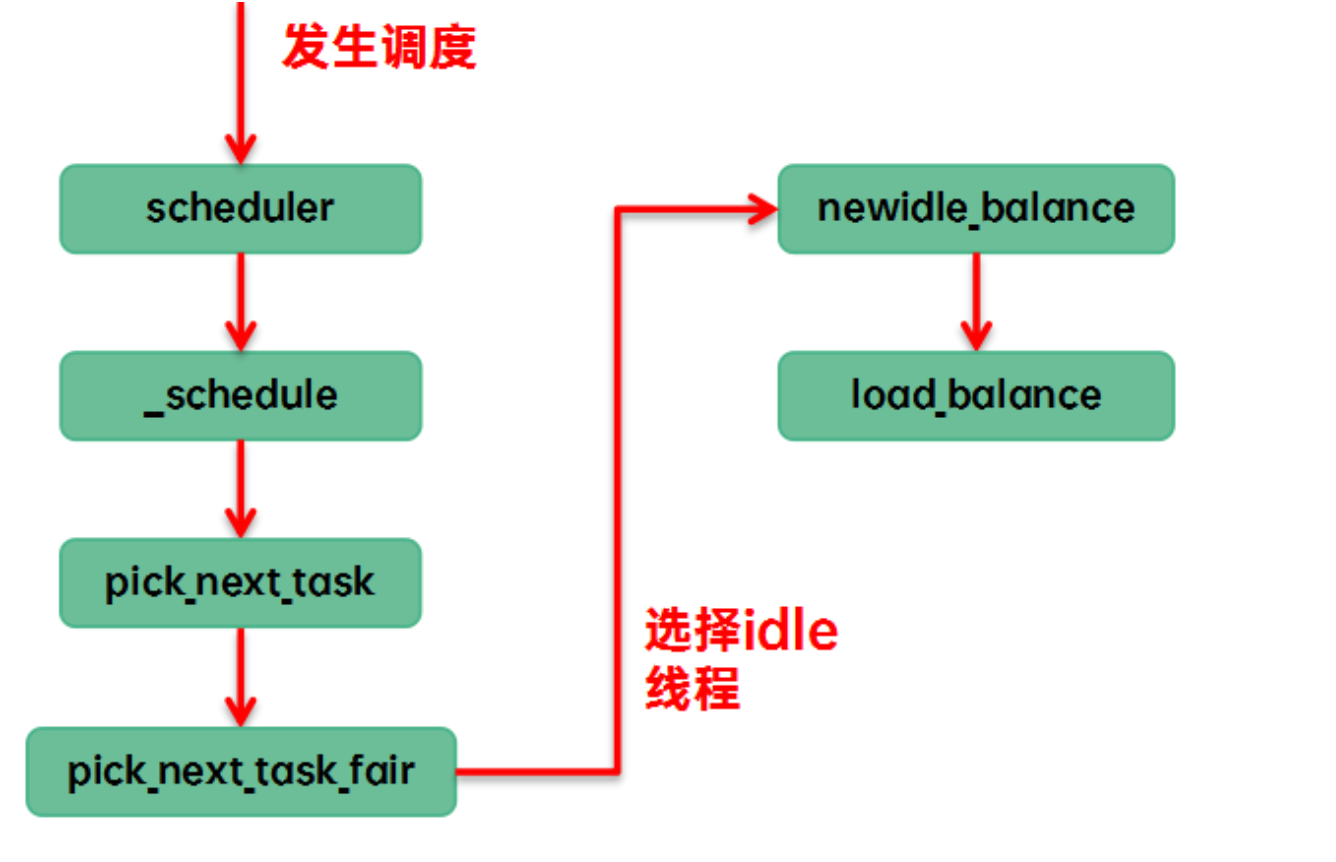
(2)調度器在pick next的時候,當前cfs runque中沒有runnable,只能執行idle線程,讓CPU進入idle狀態。我們稱之new idle load balance。具體的代碼執行路徑是:
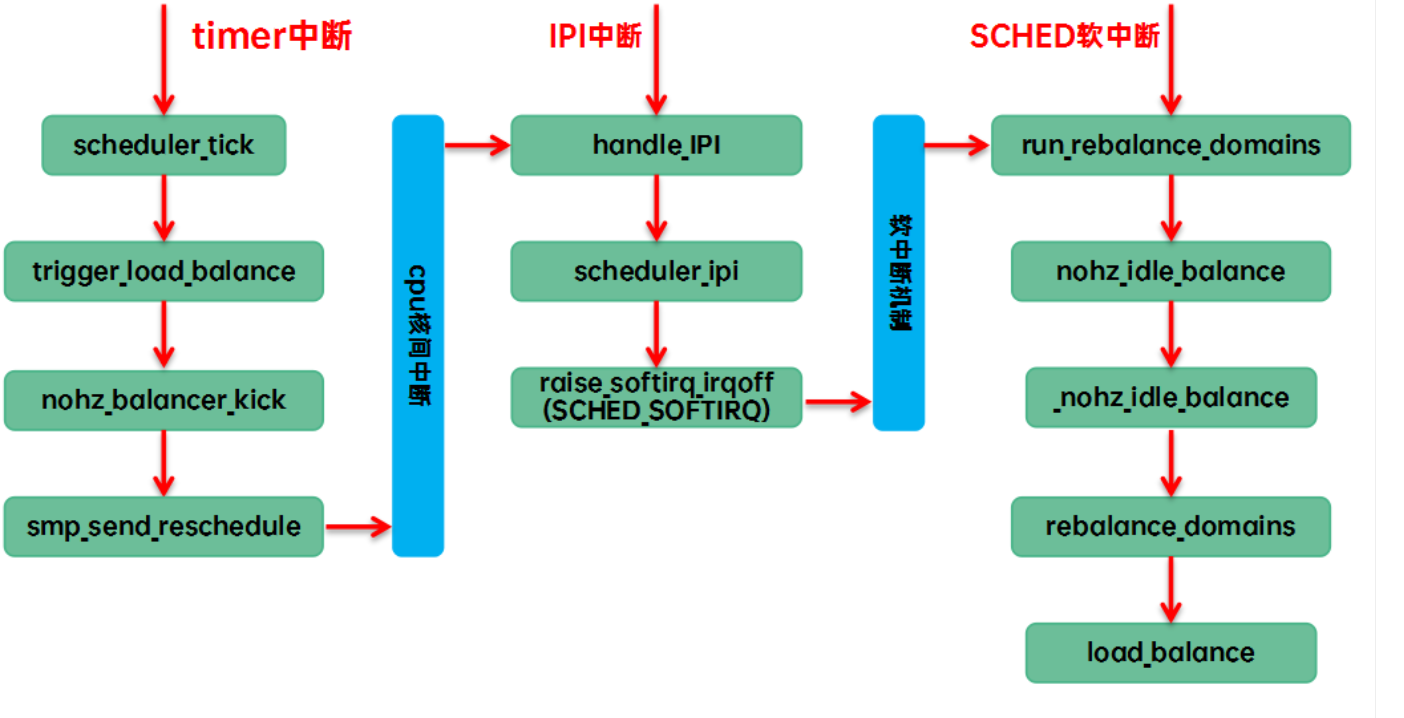
(3)其他的cpu已經進入idle,本CPU任務太重,需要通過ipi將其idle的cpu喚醒來進行負載均衡。我們稱之nohz idle load banlance,具體的代碼執行路徑是:
1. 周期性負載均衡 (Periodic / Tick Load Balance)
- 觸發場景:
- CPU處于busy狀態,周期性tick觸發。
- 目標:在busy CPU之間均衡CFS任務。
- 特點:
- 自底向上遍歷
sched_domain。 - 只支持任務拉取(pull),不能主動push到idle CPU。
- 自底向上遍歷
- 主要函數:
scheduler_tick()→trigger_load_balance()→rebalance_domains()→load_balance()
2. New Idle Load Balance
- 觸發場景:
- 某CPU剛進入idle狀態(調度器發現沒有任務)。
- 目標:嘗試從其他CPU拉取任務,讓自己忙起來。
- 特點:
- 只在CPU剛變idle時執行一次。
- 如果沒有拉到任務,就不再繼續。
- 主要函數:
newidle_balance()→load_balance()
3. NOHZ Idle Load Balance
- 觸發場景:
- 系統開啟NOHZ(tickless模式)。
- 有CPU已經idle且錯過了new idle balance。
- busy CPU發現負載過重,需要kick idle CPU來幫忙均衡。
- 特點:
- busy CPU通過IPI喚醒一個idle CPU執行均衡。
- 也是自底向上遍歷
sched_domain。
- 主要函數:
nohz_balancer_kick()→nohz_idle_balance()→rebalance_domains()→load_balance()
總結對比
| 類型 | 觸發條件 | 目標 | 關鍵函數鏈路 |
|---|---|---|---|
| Periodic | tick周期性觸發 | busy CPU之間均衡 | scheduler_tick() → rebalance_domains() |
| New Idle | CPU剛進入idle | 拉任務到idle CPU | newidle_balance() |
| NOHZ Idle | tickless模式,busy CPU kick idle CPU | idle CPU幫忙均衡 | nohz_idle_balance |
二、周期性負載均衡
1、觸發
當tick到來的時候,在scheduler_tick函數中會調用trigger_load_balance來觸發周期性負載均衡,相關的代碼如下:
// Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing.
void trigger_load_balance(struct rq *rq) {
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);-----觸發periodic balance
nohz_balancer_kick(rq);-----觸發nohz idle balance
}
整個代碼非常的簡單,主要的邏輯就是調用raise_softirq觸發SCHED_SOFTIRQ,當然要滿足均衡間隔時間的要求。nohz_balancer_kick用來觸發nohz idle balance的,這是后面章節要仔細描述的內容。上面的代碼片段,我特地保留了函數的注釋,這里看起似乎注釋不對,因為這個函數不但觸發的周期性均衡,也觸發了nohz idle balance。然而,其實nohz idle balance本質上也是另外一種意義上的周期性負載均衡,只是因為CPU進入idle,無法產生tick,因此讓能產生tick的busy CPU來幫忙觸發tick balance。而實際上tick balance和nohz idle balance都是通過SCHED_SOFTIRQ的軟中斷來處理,最后都是執行run_rebalance_domains這個函數,也就是說著兩種均衡本質都是一樣的。
2、均衡處理
SCHED_SOFTIRQ類型的軟中斷處理函數是run_rebalance_domains,代碼邏輯如下:
if (nohz_idle_balance(this_rq, idle))------nohz idle balance
return;
update_blocked_averages(this_rq->cpu);
rebalance_domains(this_rq, idle);-----周期性均衡
nohz idle balance和periodic load balance都是通過SCHED_SOFTIRQ類型的軟中斷來完成,也就是說它們兩個都是通過SCHED_SOFTIRQ注冊的handler函數run_rebalance_domains來完成其功能的,這時候就有一個先后順序的問題了,哪一個先執行?
從上面的代碼可見調度器優先處理nohz idle balance,畢竟nohz idle balance是一個全局的事情(代表系統所有idle cpu做均衡),而periodic load balance只是均衡自己的各階sched domain。如果先執行this cpu的均衡,那么在執行rebalance_domains有可能拉取負載到this cpu,這會導致在執行nohz_idle_balance的時候會忽略其他idle cpu而直接退出(nohz idle balance要求選中的cpu是idle的)。如果成功進行了nohz idle balance,那么就沒有必要進行周期性均衡了。
周期性負載均衡的主要代碼邏輯在rebalance_domains函數中(也是nohz idle balance的主入口函數),如下:
for_each_domain(cpu, sd) {
if (time_after(jiffies, sd->next_decay_max_lb_cost)) {-------A
sd->max_newidle_lb_cost = (sd->max_newidle_lb_cost * 253) / 256;
sd->next_decay_max_lb_cost = jiffies + HZ;
need_decay = 1;
}
max_cost += sd->max_newidle_lb_cost;
if (!continue_balancing) {--------------------B
if (need_decay) continue;
break;
}
interval = get_sd_balance_interval(sd, busy);
if (time_after_eq(jiffies, sd->last_balance + interval)) {-------------C
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
busy = idle != CPU_IDLE && !sched_idle_cpu(cpu);
}
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, busy);
}
out:
if (time_after(next_balance, sd->last_balance + interval)) {------D
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
A、max_newidle_lb_cost是sched domain上的最大newidle load balance的開銷。這個開銷會隨著時間進行衰減,每1秒衰減1%。此外,這里還匯聚了各個sched domain上的max_newidle_lb_cost,賦值給rq->max_idle_balance_cost,用來控制new idle balance的深度。具體細節后面會詳細描述。
B、這里的循環控制是從base domain直到頂層domain,但是實際上,越是上層的sched domain,其覆蓋的cpu就越多,如果每一個CPU的周期性負載均衡都對高層domain進行均衡那么高層domain被擼的遍數也太多了,所以這里通過continue_balancing控制均衡的level。這里還有一個特殊場景:需要更新runqueue的max_idle_balance_cost(need_decay等于true)的時候,這個場景仍然需要遍歷各個domain,但是僅僅是更新new idle balance開銷(把各個層級衰減的max_newidle_lb_cost體現到rq的max_idle_balance_cost)。
C、在滿足該sched domain負載均衡間隔的情況下,調用load_balance在指定的domain進行負載均衡。如果load_balance的確完成了某些任務搬移,那么需要更新this cpu的busy狀態。這里并不能直接確定this cpu的繁忙狀態,因為load_balance可能會修改dst cpu,從而導致任務搬移并非總是拉任務到本CPU。CPU繁忙狀態的變更也導致我們需要重新調用get_sd_balance_interval獲取
D、每個level的sched domain都會計算下一次均衡的時間點,這里記錄最近的那個均衡時間點(傾向性能,盡快進行均衡),并在后面賦值給rq->next_balance。這樣,在下次tick中,我們通過rq->next_balance來判斷是否需要觸發周期性負載均衡(trigger_load_balance),從而降低均衡次數,避免不必要均衡帶來的開銷。Nohz idle balance稍微復雜一些,因此還要考慮更新blocked load的場景。具體下一章描述。
rebalance_domains第二段代碼主要內容是把各個層級sched domain上的變化傳遞到runqueue上去的,具體如下:
if (need_decay) {--------------------------------------A
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
if (likely(update_next_balance)) {----------------B
rq->next_balance = next_balance;
if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance))
nohz.next_balance = rq->next_balance;--------C
}
A、如果該cpu的任何一個level的domain衰減了idle balance cost,那么就需要更新到rq->max_idle_balance_cost,該值是匯聚了各個level的domain的new idle balance的最大開銷。
B、rq->next_balance是綜合考慮各個level上domain的下次均衡點最近的那個時間點,在這里完成更新。
C、如果本CPU處于idle狀態,那么有可能還需要更新到nohz.next_balance,用于觸發nohz idle balance,是否更新主要是看是否該cpu下次均衡時間點距離當前時間點更近。
3、Sched domain的均衡間隔控制
負載均衡執行的頻次其實是在延遲和開銷之間進行平衡。不同level的sched domain上負載均衡帶來的開銷是不一樣的。在手機平臺上,MC domain在inter-cluster之內進行均衡,對性能的影響小一點。但是DIE domain上的均衡需要在cluster之間遷移任務,對性能和功耗的影響都比較大一些(例如cache命中率,或者一個任務遷移到原來深度睡眠的大核CPU)。因此執行均衡的時間間隔應該是和domain的層級相關的。此外,負載狀況也會影響均衡的時間間隔,在各個CPU負載比較重的時候,均衡的時間間隔可以拉大,畢竟大家都忙,讓子彈先飛一會,等塵埃落定之后在執行均衡也不遲。
struct sched_domain中和均衡間隔控制相關的數據成員包括:
| 成員 | 描述 |
|---|---|
| last_balance | 最近在該sched domain上執行均衡操作的時間點。判斷sched domain是否需要進行均衡的標準是對比當前jiffies值和last_balance+interval這里的interval是get_sd_balance_interval實時獲取的 |
| min_intervalmax_interval | 做均衡也是需要開銷的,我們不能時刻去檢查調度域的均衡狀態,這兩個參數定義了檢查該sched domain均衡狀態的時間間隔的范圍。min_interval缺省設定為sd weight,即sched domain內CPU的個數。max_interval等于2倍的min_interval。 |
| balance_interval | 定義了該sched domain均衡的基礎時間間隔,一方面,該值和sched domain所處的層級有關,層級越高,覆蓋的CPU越多,balance_interval越大。另外一方面,在調用load_balance的時候,會根據實際的均衡情況對其進行加倍或者保持原值。 |
| busy_factor | 正常情況下,balance_interval定義了均衡的時間間隔,如果cpu繁忙,那么均衡要時間間隔長一些,即時間間隔定義為busy_factor x balance_interval。缺省值是32 |
具體控制均衡間隔的函數是get_sd_balance_interval,代碼如下:
unsigned long interval = sd->balance_interval;-----------------A
if (cpu_busy)------------------------B
interval *= sd->busy_factor;
interval = msecs_to_jiffies(interval);
if (cpu_busy)-----------------------C
interval -= 1;
interval = clamp(interval, 1UL, max_load_balance_interval);
A、sd->balance_interval是均衡間隔的基礎值。balance_interval是一個不斷跟隨sched domain的不均衡程度而變化的值。初值一般從min_interval開始,如果sched domain仍然處于不均衡狀態,那么sd->balance_interval保持min_interval,隨著不均衡的狀況在變好,無任務可以搬移,需要通過主動遷移來完成均衡,這時候balance_interval會逐漸變大,從而讓均衡的間隔變大,直到max_interval。對于一個4+4的手機平臺,在MC domain上,小核和大核cluster的min_interval都是4ms,而max_interval等于8ms。而在DIE domain層級上,由于CPU個數是8,其min_interval是8ms,而max_interval等于16ms。
B、由于各個cpu上的tick大約是同步到來,因此自下而上的周期性均衡在各個CPU上幾乎是同時觸發。如果sched domain覆蓋更多的cpu,那么它的均衡由于要收集更多的信息而會稍稍慢一些。這樣就會產生這樣的一種現象:低階的sched domain剛剛完成遷移的任務就會被高階的sched domain選中被拉到其他CPU上去。為了降低這種低階和高階domain的均衡同步效應,調頻間隔減去一,使得高階sched domain和低階sched domain的interval不是整數倍數的關系。此外,調頻間隔最大也不能超過100ms。
最后強調一下,這一小節的內容適用于periodic balance和nozh idle balance。
三、nohz idle balance
1、Nohz idle均衡的觸發條件
nohz idle均衡的觸發上一章已經描述了部分過程:scheduler_tick函數中調用trigger_load_balance函數,最終通過nohz_balancer_kick函數來觸發,具體代碼邏輯如下:
if (unlikely(rq->idle_balance))----------------------A
return;
nohz_balance_exit_idle(rq);------------------------B
if (likely(!atomic_read(&nohz.nr_cpus)))---------C
return;
if (READ_ONCE(nohz.has_blocked) &&
time_after(now, READ_ONCE(nohz.next_blocked)))
flags = NOHZ_STATS_KICK;------------------D
if (time_before(now, nohz.next_balance))-----------E
goto out;
A、nohz idle balance是本cpu繁忙,需求其他idle cpu來協助,這里如果本CPU也是空閑的,那么也就沒有必要觸發nohz idle balance了。
B、當CPU從idle狀態醒來,第一個tick會更新全局變量nohz的狀態以及sched domain的cpu busy狀態。雖然nohz idle balance本質上是tick balance,但是它會發IPI,會喚醒idle的cpu,帶來額外的開銷,所以還是要控制觸發nohz idle balance的頻次。為了方便控制觸發nohz idle balance,調度器定義了一個nohz的全局變量,其數據結構如下:
| 成員 | 描述 |
|---|---|
| idle_cpus_mask | 統中哪些cpu進入了idle狀態 |
| nr_cpus | 多少個cpu進入了idle狀態 |
| has_blocked | 這些idle的CPUs是否需要更新blocked load |
| next_balance | 下一次觸發nohz idle balance的時間 |
| next_blocked | 下一次更新blocked load的時間點 |
在nohz_balance_exit_idle函數中,我們會更新nr_cpus和idle_cpus_mask這兩個成員。
C、nr_cpus和idle_cpus_mask這兩個成員可以讓調度器了解當前系統idle CPU的情況,從而選擇合適的CPU來執行nohz idle balance。如果系統中根本沒有idle cpu,那么也就沒有必要觸發nohz idle load balance了。
D、nohz idle balance有兩部分的功能:
(1)更新idle cpu上的blocked load
(2)負載均衡。可以只更新blocked load,但是負載均衡必須要包括更新blocked load功能。如果當前idle的cpu上有需要衰減的負載,那么標記之。負載更新不是本文的內容,不再詳述。
E、next_balance是用來控制觸發nohz idle balance的時間點,這個時間點應該是和系統中所有idle cpu的rq->next_balance相關的,也就是說,如果系統中所有idle cpu都還沒有到達均衡時間點,那么根本也就沒有必要觸發nohz idle balance。在執行nohz idle balance的時候,調度器實際上會遍歷idle cpu找到rq->next_balance最小的(即最近需要均衡的)賦值給nohz.next_balance,這個值作為觸發nohz idle balance的時間點。
上面是一些基本條件的判斷,下面會根據cpu runqueue的任務情況進行判定:
if (rq->nr_running >= 2) {---------------------------A
flags = NOHZ_KICK_MASK; goto out;
}
sd = rcu_dereference(rq->sd);-------------------B
if (sd) {
if (rq->cfs.h_nr_running >= 1 && check_cpu_capacity(rq, sd)) {
flags = NOHZ_KICK_MASK; goto unlock;
}
}
sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, cpu));
if (sd) {
if (check_misfit_status(rq, sd)) {------------------C
flags = NOHZ_KICK_MASK; goto unlock;
}
goto unlock;----------------------D
}
sds = rcu_dereference(per_cpu(sd_llc_shared, cpu));
if (sds) {
nr_busy = atomic_read(&sds->nr_busy_cpus);-------------E
if (nr_busy > 1) {
flags = NOHZ_KICK_MASK;
goto unlock;
}
}
A、要觸發nohz idle balance之前,需要保證自己有可以被拉取的任務。本cpu runqueue上如果有大于等于2個以上的任務,那么就基本確定可以發起nohz idle balance了
B、雖然本cpu runqueue上只有1個cfs任務,但是這個CPU用于cfs任務的算力已經已經衰減到一定程度了(由于rt任務或者irq等的影響),這時候也需要發起nohz idle balance
C、在異構系統中,我們還需要考慮misfit task。當本CPU上有misfit task,即便只有一個任務也是需要發起nohz idle balance
D、對于異構系統,我們忽略了LLC check,這是因為功耗的考量。小核cluster有busy的CPU并不說明需要進行均衡,只要小核CPU有足夠的算力能夠容納當前運行的任務,那么沒有必要發起nohz idle balance把大核給搞起來,增加額外的功耗。
E、在同構系統中,我們還是期望負載能夠在各個LLC domain上進行均衡(畢竟可以增加整個系統的cache使用率),同時,我們也希望在LLC domain內部的CPU上能夠任務均布。不過我們也不知道其他LLC domain的情況,因此只要有2個及以上的CPU處于busy,那么就發起nohz idle balance。
一旦確定要進行nohz idle balance,我們就會調用kick_ilb函數來選擇一個適合的CPU作為代表,來進行負載均衡。
2、選擇哪一個CPU?
kick_ilb函數代碼邏輯大致如下:
if (flags & NOHZ_BALANCE_KICK)
nohz.next_balance = jiffies+1;------------------A
ilb_cpu = find_new_ilb();----------------------B
if (ilb_cpu >= nr_cpu_ids)
return;
flags = atomic_fetch_or(flags, nohz_flags(ilb_cpu));--------C
if (flags & NOHZ_KICK_MASK)
return;
smp_call_function_single_async(ilb_cpu, &cpu_rq(ilb_cpu)->nohz_csd);--------D
A、如果是需要做均衡(而不是僅僅更新負載),那么我們需要更新nohz.next_balance到下一個jiffies。更新之后,其他的CPU的tick(同一個jiffies)將不會再觸發nohz balance的檢查。如果nohz idle balance順利完成,那么nohz.next_balance會響應的進行更新,如果nohz idle balance被中斷(參考下一節_nohz_idle_balance函數中的B段代碼),那么這里可以確保在下一個tick可以繼續完成之前未完的nohz idle balance。
B、如果不考慮功耗,那么從所有的idle cpu中選擇一個就OK了,然而,在異構系統中(例如手機環境),我們要考慮更多。例如:如果大核CPU和小核CPU都處于idle狀態,那么選擇喚醒大核CPU還是小核CPU?大核CPU雖然算力強,但是功耗高。如果選擇小核,雖然能省功耗,但是提供的算力是否足夠。此外,發起idle balance請求的CPU在那個cluster?是否首選同一個cluster的cpu來執行nohz idle balance?還有cpu idle的深度如何?很多思考點,不過本文就不詳述了,畢竟標準內核選擇的最簡單的算法:選擇nohz全局變量idle cpu mask中的第一個。
C、確保選擇的cpu沒有正在進行nohz idle load balance,如果有pending的請求,那么不需要重復發生IPI,觸發nohz idle balance。
D、我們定義發起nohz idle balance的CPU叫做kicker;接收請求來執行均衡操作的CPU叫做kickee。Kicker和kickee之間的交互是這樣的:
a) Kicker通知kickee已經被選中執行nohz idle balance,具體是通過設定kickee cpu runqueue的nohz_flags成員來完成的。
b) Send ipi把kickee喚醒
c) Kickee被中斷喚醒,執行scheduler_ipi來處理這個ipi中斷。當發現其runqueue的nohz_flags成員被設定了,那么知道自己被選中,后續的流程其實和周期性均衡一樣的,都是觸發一次SCHED_SOFTIRQ類型的軟中斷。
我們再強調一下:被kick的那個idle cpu并不是負責拉其他繁忙cpu上的任務到本CPU上就完事了,kickee是為了重新均衡所有idle cpu(tick被停掉)的負載,也就是說被選中的idle cpu僅僅是一個系統所有idle cpu的代表,它被喚醒是要把系統中繁忙CPU的任務均衡到系統中所有的idle cpu們。
3、均衡處理
和tick balance一樣,nohz idle balance的SCHED_SOFTIRQ軟中斷的處理函數run_rebalance_domains,只不過在這里調用nohz_idle_balance函數完成均衡。具體執行nohz idle balance非常簡單,遍歷系統所有的idle cpu,調用rebalance_domains來完成該cpu上的各個level的sched domain的負載均衡。
均衡處理大部分在_nohz_idle_balance函數中完成,我們重點看看這個函數的代碼邏輯:
WRITE_ONCE(nohz.has_blocked, 0);------------------#
for_each_cpu(balance_cpu, nohz.idle_cpus_mask) {
if (balance_cpu == this_cpu || !idle_cpu(balance_cpu))
continue;-----------------A
if (need_resched()) {------------------B
has_blocked_load = true;
goto abort;
}
rq = cpu_rq(balance_cpu);
has_blocked_load |= update_nohz_stats(rq, true);---------C
if (time_after_eq(jiffies, rq->next_balance)) {----------D
if (flags & NOHZ_BALANCE_KICK)
rebalance_domains(rq, CPU_IDLE);
}
if (time_after(next_balance, rq->next_balance)) {-----------E
next_balance = rq->next_balance;
update_next_balance = 1;
}
}
A、暫時略過本cpu的均衡處理,完成其他idle CPU遍歷后會立刻對當前CPU進行均衡。此外,如果CPU已經不處于idle狀態了,那么也就沒有必要進行均衡了。
B、如果本CPU已經有了任務要做,那么需要放棄本次負載均衡,盡快執行自己隊列上的任務,否則其隊列上的任務會有較長的調度時延,畢竟也許后面有若干個idle cpu的各個level的sched domain需要進行均衡,都是比較耗時的操作。由于終止了nohz idle balance,那么有些idle cpu的blocked load沒有更新,我們在遍歷之前就已經假設會完成所有的均衡,因此設定了系統沒有blocked load需要更新(代碼#處)。在nohz idle balance半途而廢,只能重新標記系統仍然有blocked load要更新。
C、對該idle cpu進行blocked load的更新
D、如果達到均衡的時間間隔的要求,那么調用rebalance_domains進行具體的負載均衡
E、rebalance_domains中會根據情況修改rq->next_balance,因此這里需要跟蹤各個IDLE cpu上最近時間點的那個next_balance,后面會更新到nohz.next_balance,以便控制系統觸發nohz idle balance的頻次。
_nohz_idle_balance第二段的代碼主要是處理本CPU(即被選中的idle cpu代表)的均衡,比較簡單,不再贅述。
四、new idle load balance
1、均衡觸發
Newidle balance的主入口函數是newidle_balance,我們分段解讀其邏輯:
if (this_rq->avg_idle < sysctl_sched_migration_cost ||--------------A
!READ_ONCE(this_rq->rd->overload)) {---------------------------B
sd = rcu_dereference_check_sched_domain(this_rq->sd);
if (sd)
update_next_balance(sd, &next_balance);---------------C
nohz_newidle_balance(this_rq);--------------------------------D
goto out;
}
A、當CPU馬上進入idle狀態的時候是否要做new idle load balance主要考慮兩個因素:一個是當前cpu的cache狀態,另外一個就是當前的整機負載情況。如果該CPU平均idle時間非常短,那么當CPU重新回來執行的任務的時候,CPU cache還是熱的,如果從其他CPU上拉取任務,那么這些新的任務會破壞CPU之前任務的cache,當之前那些任務回到CPU執行的時候性能會下降,同時也有功耗的增加。
B、整機負載的overload狀態記錄在root domain中的overload成員中。一個CPU處于overload狀態就是指滿足下面的條件:
a) 大于1個runnable task,即該CPU上有等待執行的任務
b) 只有一個正在運行的任務,但是是misfit task
滿足上面的條件我們稱這個CPU是overload狀態的,如果系統中至少有一個CPU是overload狀態,那么我們認為系統是overload狀態的。如果系統沒有overload,那么也就沒有需要拉取的任務,也就必要做new idle load balance了。
C、由于不適合進行new idle balance(僅做阻塞負載更新),本cpu即將進入idle狀態,即CPU忙閑狀態發生變化,對應base domain的均衡間隔也需要進行相應的更新
D、和nohz idle balance一樣,new idle balance不僅僅要處理負載均衡,同時也要負責處理blocked load的更新。如果條件不滿足,該cpu不需要進行均衡,那么在進入idle狀態之前,還需要看看系統中的哪些idle cpu們的blocked load是否需要更新了,如果需要,那么該CPU就會執行blocked load的負載更新。其背后的邏輯是:與其在nohz idle balance過程中遍歷選擇一個idle CPU來做負載更新,還不如就讓這個即將進入idle的cpu來處理。(注意:5.10的代碼仍然使用kick_ilb選擇一個CPU發起僅負載更新的均衡,最新代碼已經修復這個issue)
上面的代碼已經過濾了不適合做newidle_balance的場景,代碼至此說明需要在這個CPU上執行均衡,代碼如下:
update_blocked_averages(this_cpu);-------------------------A
for_each_domain(this_cpu, sd) {
if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) {
update_next_balance(sd, &next_balance);
break;-----------------B
}
if (sd->flags & SD_BALANCE_NEWIDLE) {
t0 = sched_clock_cpu(this_cpu);
pulled_task = load_balance(this_cpu, this_rq,-----------------C
sd, CPU_NEWLY_IDLE,
&continue_balancing);
domain_cost = sched_clock_cpu(this_cpu) - t0;
if (domain_cost > sd->max_newidle_lb_cost)
sd->max_newidle_lb_cost = domain_cost;--------------D
curr_cost += domain_cost;---------------E
}
update_next_balance(sd, &next_balance);
if (pulled_task || this_rq->nr_running > 0)
break;----------------E
}
A、這段代碼主要的功能是遍歷這個即將進入idle狀態CPU的各個level的sched domain,進行均衡。在均衡之前,首先更新負載
B、上段代碼A中是從CPU視角做的決定(cache冷熱),降低了new idlebalance的次數,此外,調度器也從sched domain的角度進行檢查,進一步避免了new idlebalance發生的深度。首先我們要明確一點:做new idle load balance是有開銷的,我們辛辛苦苦找到了繁忙的CPU,從它的runqueue中拉了任務來,然而如果自己其實也沒有那么閑,可能很快就有任務放置到自己的runqueue上來,這樣,那些用于均衡的CPU時間其實都白白浪費了。怎么避免這個尷尬狀況?我們需要兩個數據:一個是當前CPU的平均idle時間,另外一個是在new idle load balance引入的開銷(max_newidle_lb_cost成員)。如果CPU的平均idle時間小于max_newidle_lb_cost+本次均衡的開銷,那么就不啟動均衡。
C、如果該sched domain支持newidle balance,那么調用load_balance啟動均衡
D、如果需要,更新該sched domain上的最大newidle balance開銷
E、累計各個層級sched domain上的開銷,用于控制new idle balance的層級深度
F、在任何一個層級的sched domain上通過均衡拉取了任務,那么new idle balance都會終止,不會進一步去更高層級上進行sched domain的均衡。同樣的,這也是為了控制new idle balance的開銷。
2、關于new idle balance的開銷
由于其他的均衡方式都是基于tick觸發的,因此均衡次數都比較容易控制住。New idle balance不一樣,每次cpu進入idle就會觸發,因此我們需要謹慎對待。目前內核中使用兩個參數來控制new idle balance的頻次:cpu的平均idle時間和new idle balance的最大開銷。本小節描述如何計算這兩個參數的。
struct sched_domain數據結構中有下面的成員記錄new idle balance的開銷:
| 成員 | 描述 |
|---|---|
| u64 max_newidle_lb_cost | 在該domain上進行newidle balance的最大時間長度(即newidle balance的開銷)。每次在該domain上進行new idle balance的時候都會記錄時長,然后把最大值記錄在這個成員中。這個值會隨著時間衰減,防止一次極值會造成永久的影響。 |
| unsigned longnext_decay_max_lb_cost | max_newidle_lb_cost會記錄最近在該sched domain上進行newidle balance的最大時間長度,這個max cost不是一成不變的,它有一個衰減過程,每秒衰減1%,這個成員就是用來控制衰減的。 |
為了控制cpu無效進入new idle load balance,struct rq數據結構中有下面的成員:
| 成員 | 描述 |
|---|---|
| idle_stamp | 記錄CPU進入idle狀態的時間點,用于計算avg_idle。在該CPU執行任務期間,該值等于0 |
| avg_idle | 記錄CPU的平均idle時間 |
| max_idle_balance_cost | 該CPU進行new idle balance的最大開銷。 |
CPU在進行new idle balance的時候需要在各個層級上執行new idle均衡,rq的max_idle_balance_cost成員就是匯聚了各個level上sched domain進行new idle balance的最大時間開銷之和,但是限制其最小值sysctl_sched_migration_cost。
avg_idle的算法非常簡單,首先在newidle_balance的時候記錄idle_stamp,第一調用ttwu_do_wakeup的時候會計算這之間的時間,得到本次的CPU處于idle狀態的時間,然后通過下面的公式計算平均idle time:
當前的avg_idle = 上次avg_idle + (本次idle time - 上次avg_idle)/8
為了防止CPU一次idle太久時間帶來的影響,我們限制了avg_idle的最大值,即計算出來avg_idle的值不能大于2倍的max_idle_balance_cost值。
五、結束語
周期性均衡和nohz idle balance都是SCHED類型的軟中斷觸發,最后都調用了rebalance_domains來執行該CPU上各個level的sched domain的均衡,具體在某個sched domain執行均衡的函數是load_balance函數。對于new idle load balance,也是遍歷該CPU上各個level的sched domain執行均衡動作,調用的函數仍然是load_balance。因此,無論哪一種均衡,最后都萬法歸宗來到load_balance。由于篇幅原因,本文不再相信分析load_balance的邏輯,想要了解細節且聽下回分解吧。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號