
CFS任務(wù)的負(fù)載均衡(任務(wù)放置)
一、前言
負(fù)載均衡的系列文章共分為三篇,第一篇為框架篇,描述負(fù)載均衡的相關(guān)原理、場景和框架。本篇作為該系列文章第二篇,主要通過對(duì)任務(wù)放置場景(task placement)的均衡分布進(jìn)行分析,加深對(duì)內(nèi)核調(diào)度器實(shí)現(xiàn)任務(wù)均衡分布的理解。
本文基于linux-5.4.24分析,由于涉及較多代碼的講解,建議結(jié)合源碼閱讀。另外,瀏覽本文前,建議先閱讀負(fù)載均衡系列文章第一篇:CFS任務(wù)的負(fù)載均衡(概述) 。當(dāng)然,部分已經(jīng)提及的基本概念,在本文中也會(huì)進(jìn)行簡單回顧。
二、任務(wù)放置場景
2.1 什么是任務(wù)放置(task placement)
linux內(nèi)核為每個(gè)CPU都配置一個(gè)cpu runqueue,用以維護(hù)當(dāng)前CPU需要運(yùn)行的所有線程,調(diào)度器會(huì)按一定的規(guī)則從runqueue中獲取某個(gè)線程來執(zhí)行。如果一個(gè)線程正掛在某個(gè)CPU的runqueue上,此時(shí)它處于就緒狀態(tài),尚未得到cpu資源,調(diào)度器會(huì)適時(shí)地通過負(fù)載均衡(load balance)來調(diào)整任務(wù)的分布;當(dāng)它從runqueue中取出并開始執(zhí)行時(shí),便處于運(yùn)行狀態(tài),若該狀態(tài)下的任務(wù)負(fù)載不是當(dāng)前CPU所能承受的,那么調(diào)度器會(huì)將其標(biāo)記為misfit task,周期性地觸發(fā)主動(dòng)遷移(active upmigration),將misfit task布置到更高算力的CPU。
上面提到的場景,都是線程已經(jīng)被分配到某個(gè)具體的CPU并且具備有效的負(fù)載。如果一個(gè)任務(wù)線程還未被放置到任何一個(gè)CPU上,即處于阻塞狀態(tài),又或者它是剛創(chuàng)建、剛開始執(zhí)行的,此時(shí)調(diào)度器又是何如做均衡分布的呢?這便是今天我們要花點(diǎn)篇幅來介紹的任務(wù)放置場景。
內(nèi)核中,task placement場景發(fā)生在以下三種情況:
(1)進(jìn)程通過fork創(chuàng)建子進(jìn)程;
(2)進(jìn)程通過sched_exec開始執(zhí)行;
(3)阻塞的進(jìn)程被喚醒。
2.2 調(diào)度域(sched domain)及其標(biāo)志位(sd flag)
如果你正在使用智能手機(jī)閱讀本文,那你或許知道,目前的手機(jī)設(shè)備往往具備架構(gòu)不同的8個(gè)CPU core。我們?nèi)匀灰?小核+4大核的處理器結(jié)構(gòu)為例進(jìn)行說明。4個(gè)小核(cpu0-3)組成一個(gè)little cluster,另外4個(gè)大核(cpu4-7)組成big cluster,每個(gè)cluster的CPU架構(gòu)相同,它們之間使用同一個(gè)調(diào)頻策略,并且頻率調(diào)節(jié)保持一致。大核相對(duì)小核而言,具備更高的算力,但也會(huì)帶來更多的能量損耗。
對(duì)于多處理器均衡(multiprocessor balancing)而言,sched domain是極為重要的概念。內(nèi)核中以結(jié)構(gòu)體struct sched_domain對(duì)其進(jìn)行定義,將CPU core從下往上按層級(jí)劃分,對(duì)系統(tǒng)所有CPU core進(jìn)行管理,本系列文章第一篇已進(jìn)行過較為詳細(xì)的描述。little cluster和big cluster各自組成底層的MC domain,包含各自cluster的4個(gè)CPU core,頂層的DIE domian則覆蓋系統(tǒng)中所有的CPU core。
內(nèi)核調(diào)度器依賴sched domain進(jìn)行均衡,為了方便地對(duì)各種均衡狀態(tài)進(jìn)行識(shí)別,內(nèi)核定義了一組sched domain flag,用來標(biāo)識(shí)當(dāng)前sched domain具備的均衡屬性。表中,我們可以看到task placement場景常見的三種情況對(duì)應(yīng)的flag。
| 屬性 | 標(biāo)識(shí)位 | 含義 |
|---|---|---|
| SD_LOAD_BALANCE | 0x0001 | 允許負(fù)載均衡 |
| SD_BALANCE_NEWIDLE | 0x0002 | 進(jìn)入idle時(shí)進(jìn)行均衡 |
| SD_BALANCE_EXEC | 0x0004 | exec時(shí)進(jìn)行均衡 |
| SD_BALANCE_FORK | 0x0008 | fork時(shí)進(jìn)行均衡 |
| SD_BALANCE_WAKE | 0x0010 | 任務(wù)喚醒時(shí)進(jìn)行均衡 |
| SD_WAKE_AFFINE | 0x0020 | 任務(wù)喚醒時(shí)放置到臨近CPU |
| … | … | … |
在構(gòu)建CPU拓?fù)浣Y(jié)構(gòu)時(shí),會(huì)為各個(gè)sched domain配置初始的標(biāo)識(shí)位,如果是異構(gòu)系統(tǒng),會(huì)設(shè)置SD_BALANCE_WAKE:

2.3 task placement均衡代碼框架
linux內(nèi)核的調(diào)度框架是高度抽象、模塊化的,所有的線程都擁有各自所屬的調(diào)度類(sched class),比如大家所熟知的實(shí)時(shí)線程屬于rt_sched_class,CFS線程屬于fair_sched_class,不同的調(diào)度類采用不同的調(diào)度策略。上面提到的task placement的三種場景,最終的函數(shù)入口都是core.c中定義的select_task_rq()方法,之后會(huì)跳轉(zhuǎn)至調(diào)度類自己的具體實(shí)現(xiàn)。本文以CFS調(diào)度類為分析對(duì)象,因?yàn)樵撜{(diào)度類的線程在整個(gè)系統(tǒng)中占據(jù)較大的比重。有興趣的朋友可以了解下其它調(diào)度類的select_task_rq()實(shí)現(xiàn)。
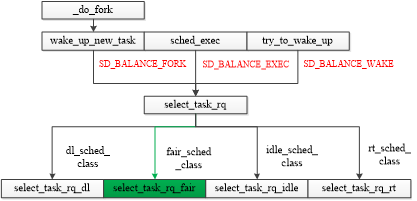
2.4 select_task_rq_fair()方法
CFS調(diào)度類的線程進(jìn)行task placement時(shí),會(huì)通過core.c的select_task_rq()方法跳轉(zhuǎn)至select_task_rq_fair(),該方法聲明如下:
static int select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
sd_flag參數(shù):傳入sched domain標(biāo)識(shí)位,目前一共有三種:SD_BALANCE_WAKE、SD_BALANCE_FORK、SD_BALANCE_EXEC,分別對(duì)應(yīng)task placement的三種情形。調(diào)度器只會(huì)在設(shè)置有相應(yīng)標(biāo)識(shí)位的sched domain中進(jìn)行CPU的選擇。
wake_flags參數(shù):特地為SD_BALANCE_WAKE提供的喚醒標(biāo)識(shí)位,一共有三種類型:

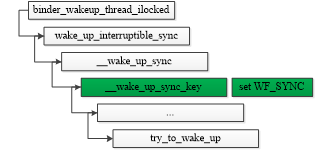
select_task_rq_fair()內(nèi)僅對(duì)WF_SYNC進(jìn)行處理,若傳入該標(biāo)識(shí)位,說明喚醒線程waker在被喚醒線程wakee喚醒后,將進(jìn)入阻塞狀態(tài),調(diào)度器會(huì)傾向于將wakee放置到waker所在的CPU。這種場景使用相當(dāng)頻繁,比如用戶空間兩個(gè)進(jìn)程進(jìn)行非異步binder通信,Server端喚醒一個(gè)binder線程處理事務(wù)時(shí),調(diào)用的接口如下:
select_task_rq_fair()中涉及到三個(gè)重要的選核函數(shù):find_energy_efficient_cpu(),find_idlest_cpu(),select_idle_sibling(),它們分別代表任務(wù)放置過程中的三條路徑。task placement的各個(gè)場景,根據(jù)不同條件,最終都會(huì)進(jìn)入其中某一條路徑,得到任務(wù)放置CPU并結(jié)束此次的task placement過程。現(xiàn)在讓我們來理一理這三條路徑的常見進(jìn)入條件以及基本的CPU選擇考量:
(1)EAS選核路徑find_energy_efficient_cpu()。當(dāng)傳入?yún)?shù)sd_flag為SD_BALANCE_WAKE,并且系統(tǒng)配置key值sched_energy_present(即考慮性能和功耗的均衡),調(diào)度器就會(huì)進(jìn)入EAS選核路徑進(jìn)行CPU的查找。這里涉及到內(nèi)核中Energy Aware Scheduling(EAS)機(jī)制,我們稍后將在第三節(jié)中詳細(xì)描述。總之,EAS路徑在保證任務(wù)能正常運(yùn)行的前提下,為任務(wù)選取使系統(tǒng)整體能耗最小的CPU。通常情況下,EAS總是能如愿找到符合要求的CPU,但如果當(dāng)前平臺(tái)不是異構(gòu)系統(tǒng),或者系統(tǒng)中存在超載(Over-utilization)的CPU,EAS就直接返回-1,不能在這次調(diào)度中大展拳腳。
當(dāng)EAS不能在這次調(diào)度中發(fā)揮作用時(shí),分支的走向取決于該任務(wù)是否為wake affine類型的任務(wù),這里讓我們先來簡單了解下該類型的任務(wù)。
用戶場景有時(shí)會(huì)出現(xiàn)一個(gè)主任務(wù)(waker)喚醒多個(gè)子任務(wù)(wakee)的情況,如果我們將其作為wake affine類型處理,將wakee打包在臨近的CPU上(如喚醒CPU、上次執(zhí)行的CPU、共享cache的CPU),即可以提高cache命中率,改善性能,又能避免喚醒其它可能正處于idle狀態(tài)的CPU,節(jié)省功耗。看起來這樣的處理似乎非常完美,可惜的是,往往有些wakee對(duì)調(diào)度延遲非常敏感,如果將它們打包在一塊,CPU上的任務(wù)就變得“擁擠”,調(diào)度延遲就會(huì)急劇上升,這樣的場景下,所謂的cache命中率、功耗,一切的誘惑都變得索然無味。
對(duì)于wake affine類型的判斷,內(nèi)核主要通過wake_wide()和wake_cap()的實(shí)現(xiàn),從wakee的數(shù)量以及臨近CPU算力是否滿足任務(wù)需求這兩個(gè)維度進(jìn)行考量。
(2)慢速路徑find_idlest_cpu()。有兩種常見的情況會(huì)進(jìn)入慢速路徑:傳入?yún)?shù)sd_flag為SD_BALANCE_WAKE,且EAS沒有使能或者返回-1時(shí),如果該任務(wù)不是wake affine類型,就會(huì)進(jìn)入慢速路徑;傳入?yún)?shù)sd_flag為SD_BALANCE_FORK、SD_BALANCE_EXEC時(shí),由于此時(shí)的任務(wù)負(fù)載是不可信任的,無法預(yù)測其對(duì)系統(tǒng)能耗的影響,也會(huì)進(jìn)入慢速路徑。慢速路徑使用find_idlest_cpu()方法找到系統(tǒng)中最空閑的CPU,作為放置任務(wù)的CPU并返回。基本的搜索流程是:
首先確定放置的target domain(從waker的base domain向上,找到最底層配置相應(yīng)sd_flag的domain),然后從target domain中找到負(fù)載最小的調(diào)度組,進(jìn)而在調(diào)度組中找到負(fù)載最小的CPU。
這種選核方式對(duì)于剛創(chuàng)建的任務(wù)來說,算是一種相對(duì)穩(wěn)妥的做法,開發(fā)者也指出,或許可以將新創(chuàng)建的任務(wù)放置到特殊類型的CPU上,或者通過它的父進(jìn)程來推斷它的負(fù)載走向,但這些啟發(fā)式的方法也有可能在一些使用場景下造成其他問題。
(3)快速路徑select_idle_sibling()。傳入?yún)?shù)sd_flag為SD_BALANCE_WAKE,但EAS又無法發(fā)揮作用時(shí),若該任務(wù)為wake affine類型任務(wù),調(diào)度器就會(huì)進(jìn)入快速路徑來選取放置的CPU,該路徑在CPU的選擇上,主要考慮共享cache且idle的CPU。在滿足條件的情況下,優(yōu)先選擇任務(wù)上一次運(yùn)行的CPU(prev cpu),hot cache的CPU是wake affine類型任務(wù)所青睞的。其次是喚醒任務(wù)的CPU(wake cpu),即waker所在的CPU。當(dāng)該次喚醒為sync喚醒時(shí)(傳入?yún)?shù)wake_flags為WF_SYNC),對(duì)wake cpu的idle狀態(tài)判定將會(huì)放寬,比如waker為wake cpu唯一的任務(wù),由于sync喚醒下的waker很快就進(jìn)入阻塞狀態(tài),也可當(dāng)做idle處理。
如果prev cpu或者wake cpu無法滿足條件,那么調(diào)度器會(huì)嘗試從它們的LLC domain中去搜索idle的CPU。
快速路徑 select_idle_sibling
- 優(yōu)先考慮 緩存親和性:
- 上次運(yùn)行的 CPU(prev CPU);
- 喚醒者所在 CPU(wake CPU),
WF_SYNC時(shí)判定更寬松; - 同 LLC 內(nèi)的空閑核。
- 目標(biāo)是減少 cache miss,提升性能。
慢速路徑 find_idlest_cpu
- 基于 系統(tǒng)負(fù)載均衡:
- 找到匹配
sd_flag的調(diào)度域(通常是 LLC 或 NUMA 層); - 在該域中選負(fù)載最小的調(diào)度組;
- 在組內(nèi)選負(fù)載最小的 CPU。
- 找到匹配
- 目標(biāo)是全局均衡,避免熱點(diǎn)。
三、Energy Aware Scheduling(EAS)
系統(tǒng)中的Energy Aware Scheduling(EAS)機(jī)制被使能時(shí),調(diào)度器就會(huì)在CFS任務(wù)由阻塞狀態(tài)喚醒的時(shí)候,使用find_energy_efficient_cpu()為任務(wù)選擇合適的放置CPU。
3.1 什么是Energy Model(EM)
在了解什么是EAS之前,我們先學(xué)習(xí)下EM。EM的設(shè)計(jì)使用比較簡單,因?yàn)槲覀円苊庠趖ask placement時(shí),由于算法過于復(fù)雜導(dǎo)致調(diào)度延遲變高。理解EM的一個(gè)重點(diǎn)是理解性能域(performance domain)。與sched domain相同,內(nèi)核也有相應(yīng)的結(jié)構(gòu)體struct perf_domain來定義性能域。相同微架構(gòu)的CPU會(huì)歸屬到同一個(gè)perf domain,4大核+4小核的CPU拓?fù)湫畔⑷缦拢?/p>
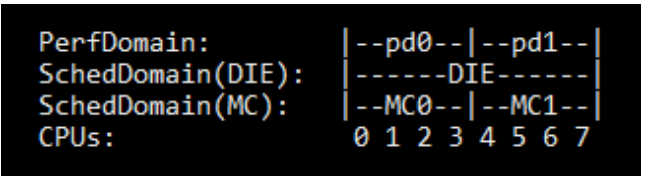
little cluster的4個(gè)CPU core組成一個(gè)perf domain,big cluster則組成另外一個(gè)。
相同perf domian內(nèi)的所有CPU core一起進(jìn)行調(diào)頻,保持著相同的頻率。CPU使用的頻點(diǎn)是分級(jí)的,各級(jí)別的頻點(diǎn)與capacity值、power值是一一映射的關(guān)系,例如:小核的4個(gè)cpu,最大capacity都是512,與之對(duì)應(yīng)的最高頻點(diǎn)為1G Hz,那么500M Hz的頻點(diǎn)對(duì)應(yīng)的capacity就是256。為了將這些信息有效的組織起來,內(nèi)核又為EM增加兩個(gè)新的結(jié)構(gòu)體struct em_perf_domain和struct em_cap_state,用于存儲(chǔ)這些信息,它們都能夠從perf domain中獲取。

3.2 什么是EAS
異構(gòu)CPU拓?fù)浼軜?gòu)(比如Arm big.LITTLE架構(gòu)),存在高性能的cluster和低功耗的cluster,它們的算力(capacity)之間存在差異,這讓調(diào)度器在喚醒場景下進(jìn)行task placement變得更加復(fù)雜,我們希望在不影響整體系統(tǒng)吞吐量的同時(shí),盡可能地節(jié)省能量,因此,EAS應(yīng)運(yùn)而生。它的設(shè)計(jì)令調(diào)度器在做CPU選擇時(shí),增加能量評(píng)估的維度,它的運(yùn)作依賴于Energy Model(EM)。
EAS對(duì)能量(energy)和功率(power)的定義與傳統(tǒng)意義并無差別,energy是類似電源設(shè)備上的電池這樣的資源,單位是焦耳,power則是每秒的能量損耗值,單位是瓦特。
EAS在非異構(gòu)系統(tǒng)下,或者系統(tǒng)中存在超載CPU時(shí)不會(huì)使能,調(diào)度器對(duì)于CPU超載的判定是比較嚴(yán)格的,當(dāng)root domain中存在CPU負(fù)載達(dá)到該CPU算力的80%以上時(shí),就認(rèn)為是超載。
3.3 EM是如何估算energy的
由于EM將系統(tǒng)中所有CPU的各級(jí)capacity、frequence、power以便捷高效的方式組織起來,計(jì)算energy的工作就變得很簡單了。內(nèi)核中某個(gè)perf domian的energy可以通過em_pd_energy()獲得,它實(shí)際上是通過假定將任務(wù)放置到某個(gè)CPU上,引起perf domain各個(gè)CPU負(fù)載變化,來估算整體energy數(shù)值。令人值得慶幸的是,該方法的實(shí)現(xiàn)代碼中,有一半以上都是注釋語句。
static inline unsigned long em_pd_energy(struct em_perf_domain *pd,
unsigned long max_util, unsigned long sum_util)
max_util參數(shù):perf domain各個(gè)CPU中的最高負(fù)載。
sum_util參數(shù):perf domain中所有CPU的總負(fù)載。
前面提到過,同個(gè)perf domian下的所有CPU使用相同的頻點(diǎn),因此,cluster選擇哪個(gè)頻點(diǎn),取決于擁有最大負(fù)載的CPU。EM首先會(huì)獲取當(dāng)前perf domain的最高頻點(diǎn)和最大算力,并將max_util映射到對(duì)應(yīng)的頻率上,找到超過該頻率的最低頻點(diǎn)及相應(yīng)的算力cs_capacity,畢竟我們要確保任務(wù)能夠正常執(zhí)行。
好了,現(xiàn)在需要的信息都齊全,只要將所有CPU的energy累加起來,就能得到整個(gè)perf domain的估計(jì)能量值。
3.4 EAS task placement
EAS在任務(wù)喚醒時(shí),通過函數(shù)find_energy_efficient_cpu()為任務(wù)選擇合適的放置CPU,它的實(shí)現(xiàn)邏輯大致如下:
(1)通過em_pd_energy()計(jì)算取得各個(gè)perf domian未放置任務(wù)的基礎(chǔ)能量值;
(2)遍歷各個(gè)perf domain,找到該domain下?lián)碛凶畲罂沼嗨懔Φ腃PU以及prev cpu,作為備選放置CPU;
(3)通過em_pd_energy()計(jì)算取得將任務(wù)放置到備選CPU引起的perf domain的energy變化值;
(4)通過比較得到令energy變化最小的備選CPU,即將任務(wù)放置到該CPU上,能得到最小的domain energy,如果相對(duì)于將任務(wù)放置到prev cpu,此次的選擇能節(jié)省6%以上的能量,則該CPU為目標(biāo)CPU。
選擇perf domain中擁有最大空余算力的CPU作為備選CPU,是因?yàn)檫@樣可以避免某個(gè)CPU負(fù)載特別高,導(dǎo)致整個(gè)cluster的頻點(diǎn)往上提。并且顧及到hot cache的prev cpu有利于提高任務(wù)運(yùn)行效率,EAS對(duì)于prev cpu還是難以割舍的,除非節(jié)能可以達(dá)到6%以上。
另外,從上面的邏輯中也可以看出為何超載情況下EAS是不使能的。我們假定little cluster中cpu3存在超載的情況,那么無論你將任務(wù)放置到哪個(gè)CPU上,little cluster總是維持最高頻點(diǎn),對(duì)于同個(gè)perf domain下?lián)碛凶畲罂沼嗨懔Φ腃PU來說,這樣預(yù)估的energy是不公平的,與EAS的設(shè)計(jì)相違背,EAS希望能通過放置任務(wù)改變cluster的頻點(diǎn)來降低功耗。
四、總結(jié)
本文作為負(fù)載均衡系列文章的第二篇,主要對(duì)CFS任務(wù)的task placement做場景分析,描述調(diào)度器在此過程中的選擇實(shí)現(xiàn)和考量,由于篇幅和精力有限,很多具體的細(xì)節(jié)還沒能呈現(xiàn)清晰,特別是對(duì)快速路徑和慢速路徑這一塊的描述,希望有興趣的朋友可以自行閱讀源碼實(shí)現(xiàn),共同學(xué)習(xí)交流。
我們可以看到,目前task placement過程中的一些啟發(fā)式算法還存在缺陷,也能看到開發(fā)者對(duì)此的不斷思考和創(chuàng)新,隨著內(nèi)核版本的不斷更新迭代,未來的調(diào)度算法一定會(huì)出現(xiàn)更多有意思的特性。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)