
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning
https://arxiv.org/pdf/2303.11366
https://github.com/noahshinn024/reflexion
https://zhuanlan.zhihu.com/p/659486595
這篇文章主要研究如何通過自我反思來增強語言模型的強化學習能力,本文提出了一種名為Reflexion的替代方法,該方法使用口頭強化來幫助agent從之前的失敗中學習。 Reflexion將環境中的二進制或標量反饋轉換為文本摘要形式的口頭反饋,然后將其作為下一個episode中LLM agent的附加上下文添加。這種自我反思的反饋通過提供具體的改進方向來充當“語義”梯度信號,幫助它從以前的錯誤中學習以更好地完成任務。
Reflexion具有以下優點:
- 輕量化,不需要微調語言模型。
- 支持細致的反饋形式,不僅有標量獎勵。
- 具有明確的記憶機制,可以積累經驗episode,為后續episode提供更明確的行動提示。
- 引入自我反思步驟,可以識別錯誤并自我推理如何改進。
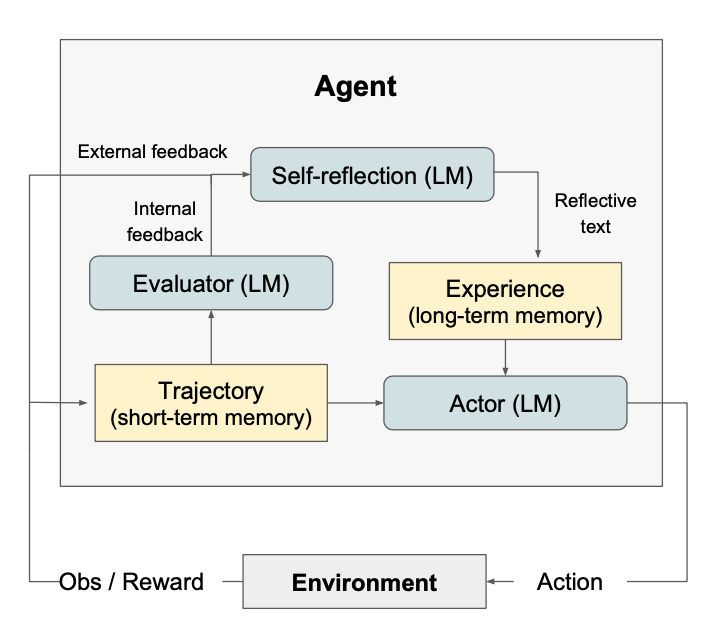
Reflexion包含三個模塊:Actor(行動者)、Evaluator(評估器)和Self-Reflection
(自我反思)。
Actor
Actor是建立在大型語言模型(LLM)之上的,它專門通過特定Prompt生成所需的文本和動作,這些Prompt是基于狀態觀察條件的。類似于傳統基于策略的RL設置,從當前策略πθ在時間t采樣一個動作或生成at,并從環境ot中接收一個觀察值。
文章探索了各種Actor模型,包括Chain of Thought
和ReAct。這些不同的生成模型使我們能夠在Reflexion框架內探索文本和動作生成的不同方面,提供有關其性能和有效性的寶貴見解。
此外,我們還添加了一個內存組件mem,為該Agent提供了額外的上下文信息。
Evaluator
Evaluator組件主要是在評估Actor生成的輸出質量方面發揮著至關重要的作用。它將生成的軌跡<s0,a0,s1,a1,.....,sn,an>作為輸入,并計算反映其在給定任務上表現的獎勵分數。對于不同的任務使用了不同的需要設計不同語義空間的有效價值和獎勵函數。
對于推理任務,探索基于精確匹配(EM)評分的獎勵函數,確保生成的輸出與預期解決方案緊密對齊。
在決策任務中,我們使用預定義的啟發式函數,這些函數適用于特定的評估標準。
此外,我們嘗試使用LLM的不同實例本身作為Evaluator,為決策和編程任務生成獎勵。
這種多方面的Evaluator設計方法使我們能夠檢查評分生成輸出的不同策略,提供有關它們在各種任務中的有效性和適用性的見解。
Self-reflection
Self-Reflection在Reflexion框架中發揮著至關重要的作用,通過生成口頭自我反思為未來的試驗提供有價值的反饋。鑒于稀疏的獎勵信號,如二進制成功狀態(成功/失敗)、當前軌跡及其持久性內存mem,自我反思模型生成微妙而具體的反饋。這種比標量獎勵更具信息量的反饋隨后存儲在內存(mem)中。
例如,在多步決策任務中,當agent收到失敗信號時,它可以推斷出特定動作ai導致了后續的不正確動作ai+1和ai+2。然后Agent可以口頭表述應該采取不同的動作a'i,這將導致a'i+1,a'i+2。在后續的試驗中,Agent可以利用過去的經驗,在時間t通過選擇動作a'i來調整其決策方法。
這種試驗、錯誤、自我反思和持久內存的迭代過程使Agent能夠利用信息豐富的反饋信號,在各種環境中快速提高其決策能力。
Memory
Reflexion過程的核心組件是短期和長期記憶的概念。在推理時,Actor基于短期和長期記憶做出決策,類似于人類記住細節,同時從長期記憶中回想起重要的經驗。在RL設置中,軌跡歷史記錄用作短期記憶,而來自Self-Reflection模型的輸出則存儲在長期記憶中。這兩個記憶組件共同提供特定的上下文信息,并受到在多次試驗中學到的教訓的影響,這是Reflexion代理相對于其他LLM行動選擇工作的一個關鍵優勢。
https://shirintahmasebi.github.io/agents/2024/reflexion/
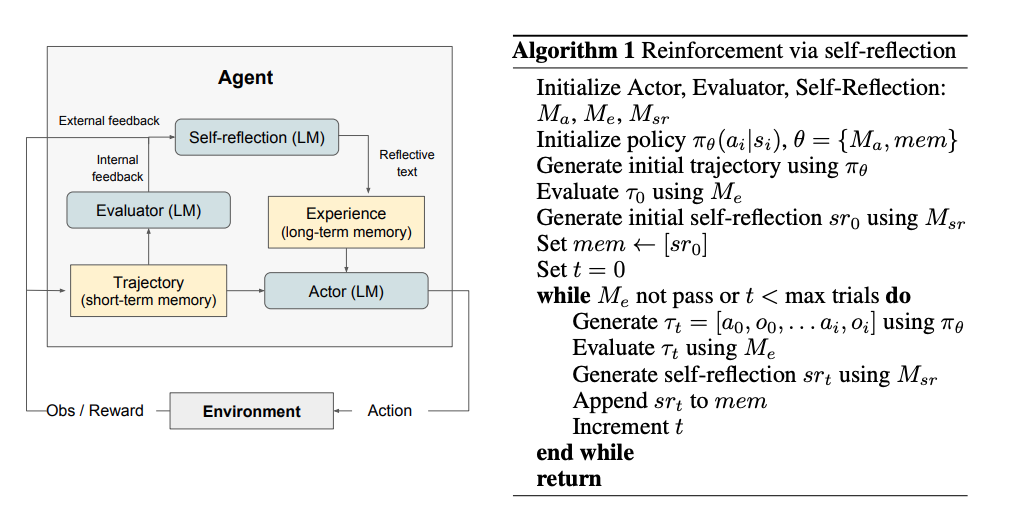
Reflexion Process:
- Generation of Initial Trajectory: The LLM (Actor) interacts with the environment to generate an initial trajectory
and reward to generate a verbal summary
- is stored in the agent’s memory. In subsequent trials, this memory provides context and guidance to the LLM, helping it to avoid past mistakes and make better decisions.
- Iterative Improvement: The process of generating trajectories, evaluating them, creating self-reflections, and updating memory continues iteratively. The agent leverages the accumulated memory to improve its performance over time.
The whole process along with the psudo-code of the alogrithm is as follows:
- .
- Evaluation: The Evaluator assesses the trajectory and produces a reward
- .
- Self-Reflection: The Self-Reflection model uses the trajectory
- . This summary captures the agent’s reflections on its performance, highlighting what went wrong and suggesting improvements.
- Updating Memory: The reflective summary

 浙公網安備 33010602011771號
浙公網安備 33010602011771號