運行期優化--逃逸分析
在《深入理解Java虛擬機中》關于Java堆內存有這樣一段對逃逸分析的描述:
那么究竟怎么理解逃逸分析?我們先來看一個例子
運行期優化示例
兩層循環,內層循環創建1000次對象,外層循環對內層循環進行計時統計。



public class JIT1 { public static void main(String[] args) { for (int i = 0; i < 200; i++) { long start = System.nanoTime(); for (int j = 0; j < 1000; j++) { new Object(); } long end = System.nanoTime(); System.out.printf("%d\t%d\n",i,(end - start)); } } }
運行結果
運行時間隨著次數不斷下降,最終到達三位數。

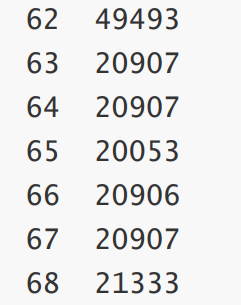

然后可以使用 -XX:- DoEscapeAnalysis 關閉逃逸分析,再運行剛才的示例觀察結果,會發現在100多次后運行時間達不到3位數。
原因是什么呢?
JVM 將執行狀態分成了 5 個層次:
0 層,解釋執行(Interpreter)
1 層,使用 C1 即時編譯器編譯執行(不帶 profiling)
2 層,使用 C1 即時編譯器編譯執行(帶基本的 profiling)
3 層,使用 C1 即時編譯器編譯執行(帶完全的 profiling)
4 層,使用 C2 即時編譯器編譯執行
profiling 是指在運行過程中收集一些程序執行狀態的數據,例如【方法的調用次數】,【循環的 回邊次數】等
即時編譯器(JIT)與解釋器的區別
(1)解釋器是將字節碼解釋為機器碼,下次即使遇到相同的字節碼,仍會執行重復的解釋。
(2)JIT 是將一些字節碼編譯為機器碼,并存入 Code Cache,下次遇到相同的代碼,直接執行,無需 再編譯。
(3)解釋器是將字節碼解釋為針對所有平臺都通用的機器碼。
(4)JIT 會根據平臺類型,生成平臺特定的機器碼。
對于占據大部分的不常用的代碼,我們無需耗費時間將其編譯成機器碼,而是采取解釋執行的方式運行;另一方面,對于僅占據小部分的熱點代碼,我們則可以將其編譯成機器碼,以達到理想的運行速度。 執行效率上簡單比較一下 Interpreter < C1 < C2,總的目標是發現熱點代碼(hotspot名稱的由 來),剛才的一種優化手段稱之為【逃逸分析】,發現新建的對象是否逃逸。可以使用 -XX:- DoEscapeAnalysis 關閉逃逸分析,再運行剛才的示例觀察結果。
參考資料:https://docs.oracle.com/en/java/javase/12/vm/java-hotspot-virtual-machine-performance-enhancements.html#GUID-D2E3DC58-D18B-4A6C-8167-4A1DFB4888E4
JIT(即時編譯)的出現
在Java的編譯體系中,一個Java的源代碼文件變成計算機可執行的機器指令的過程中,需要經過兩段編譯:
第一段編譯,指前端編譯器把*.java文件轉換成*.class文件(字節碼文件)。編譯器產品可以是JDK的Javac、Eclipse JDT中的增量式編譯器。
第二編譯階段,JVM 通過解釋字節碼將其翻譯成對應的機器指令,逐條讀入,逐條解釋翻譯。很顯然,經過解釋執行,其執行速度必然會比可執行的二進制字節碼程序慢很多。這就是傳統的JVM的解釋器(Interpreter)的功能。為了解決這種效率問題,引入了JIT(即時編譯器,Just In Time Compiler)技術。
引入了 JIT 技術后,Java程序還是通過解釋器進行解釋執行,當JVM發現某個方法或代碼塊運行特別頻繁的時候,就會認為這是“熱點代碼”(Hot Spot Code)。然后JIT會把部分“熱點代碼”翻譯成本地機器相關的機器碼,并進行優化,然后再把翻譯后的機器碼緩存起來,以備下次使用。其中有一部分優化的目的就是減少內存堆分配壓力,其中JIT優化中一種重要的技術叫做逃逸分析。
逃逸分析?
逃逸分析(Escape Analysis)是目前Java虛擬機中比較前沿的優化技術。這是一種可以有效減少Java 程序中同步負載和內存堆分配壓力的跨函數全局數據流分析算法。通過逃逸分析,Java Hotspot編譯器能夠分析出一個新的對象的引用的使用范圍從而決定是否要將這個對象分配到堆上。
逃逸分析的基本原理是:分析對象動態作用域,當一個對象在方法里面被定義后,它可能被外部方法所引用,例如作為調用參數傳遞到其他方法中,這種稱為方法逃逸;示例:
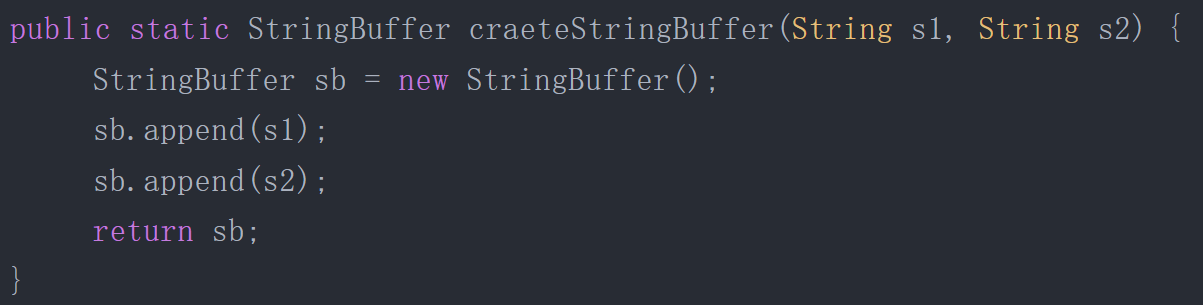
StringBuffer sb是一個方法內部變量,上述代碼中直接將sb返回,這樣這個StringBuffer有可能被其他方法所改變,這樣它的作用域就不只是在方法內部,雖然它是一個局部變量,稱其逃逸到了方法外部。甚至還有可能被外部線程訪問到,譬如賦值給類變量或可以在其他線程中訪問的實例變量,稱為線程逃逸。
上述代碼如果想要StringBuffer sb不逃出方法,可以這樣寫:
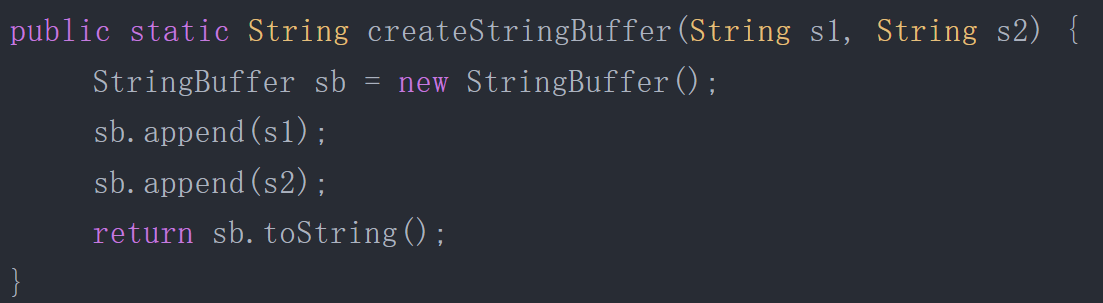
不直接返回 StringBuffer,那么StringBuffer將不會逃逸出方法。從不逃逸、方法逃逸到線程逃逸,稱為對象由低到高的不同逃逸程度。如果能證明一個對象不會逃逸到方法或線程之外(換句話說是別的方法或線程無法通過任何途徑訪問到這個對象),或者逃逸程度比較低(只逃逸出方法而不會逃逸出線程),則可能為這個對象實例采取不同程度的優化。
使用逃逸分析,編譯器可以對代碼做如下優化:
一、同步省略。如果一個對象被發現只能從一個線程被訪問到,那么對于這個對象的操作可以不考慮同步。
二、將堆分配轉化為棧分配。如果一個對象在子程序中被分配,要使指向該對象的指針永遠不會逃逸,對象可能是棧分配的候選,而不是堆分配。
三、分離對象或標量替換。有的對象可能不需要作為一個連續的內存結構存在也可以被訪問到,那么對象的部分(或全部)可以不存儲在內存,而是存儲在CPU寄存器中。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號