記錄一次線上服務OOM排查
 外面,陽光明媚,一切正好。
就在我歡天喜地準備迎來愉快的雙休時,忽然之間,天塌了。
剛上線一小時的服務內存異常OOM了!
外面,陽光明媚,一切正好。
就在我歡天喜地準備迎來愉快的雙休時,忽然之間,天塌了。
剛上線一小時的服務內存異常OOM了!
外面,陽光明媚,一切正好。
就在我歡天喜地準備迎來愉快的雙休時,忽然之間,天塌了。
剛上線一小時的服務內存異常OOM了!
老實說,在我印象里OOM問題只存在于網上案例中,練習編碼時常兩年半,還是第一次遇到。不過既然遇到了,那就要盡快排查問題并解決掉,不然真要和群里大哥說的一樣:要領盒飯了。
問題
下午兩點新版本上線,其中一個消費者服務的內存增長速度異常迅速,在短短五分鐘內就用完了2G內存并自動重啟了pod,之后又在五分鐘內OOM了,在四十分鐘內服務的pod已經重啟了八十幾次,要知道我們之前這個消費者服務正常運行時候只用了不到500M。
分析
首先進行初步分析,這是一個消費者服務并且新版本的需求中并沒有新增消費topic,并且業務量也沒有大的波動,不存在是業務訪問量驟增導致OOM,所以極大概率會是代碼問題。當然,每一個版本的新代碼都非常多,需求也比較龐雜,直接去看代碼肯定是不行的,這時候就要麻煩部門的運維大佬了,讓他給我們dump一下,給出一個內存溢出時的性能記錄文件,通過這個文件可以分析內存分配、線程創建、CPU使用、阻塞、程序詳細跟蹤信息等。
我這里使用的Go語言開發,一般用pprof文件進行分析,運維給出的文件有以下6個:
- main-1-trace-1227152939.pprof:記錄程序執行的詳細跟蹤信息,包括函數調用、Goroutine 的創建和調度等
- main-1-threadcreate-1227152939.pprof:記錄線程創建的剖析數據,幫助分析線程創建的頻率和開銷。
- main-1-mutex-1227152939.pprof:記錄互斥鎖(mutex)的使用情況,幫助分析鎖競爭和鎖等待的開銷。
- main-1-mem-1227152939.pprof:記錄內存分配的剖析數據,幫助分析內存使用的熱點和分配情況。
- main-1-cpu-1227152939.pprof:記錄 CPU 使用的剖析數據,幫助分析 CPU 時間的消耗情況。
- main-1-block-1227152939.pprof:記錄阻塞操作的剖析數據,幫助分析阻塞操作的頻率和開銷。
內存OOM,那最重要的當然是mem文件,也就是內存分配剖析數據,不過很不幸,服務重啟速度太快了,運維大佬dump的時候正好處于服務剛重啟的時候,所以mem文件中顯示的內存才占用不到20M,并且占比上也沒看出有什么問題。想讓運維再幫忙dump一下內存快要OOM的時候,但是為了線上服務的穩定性版本已經回退了,無法重新dump,只能從其他幾個文件中查找問題了。

除了內存占用分析,在性能問題分析中CPU占用分析也是極為重要的一環,這一查看就有意思了,CPU總的使用率雖然不高,但是這個占比就比較奇怪了。第一占比的runtime.step是Go的運行時系統負責管理內存分配、垃圾回收、調度goroutine等底層操作,這個暫且不管,占比第二的居然是runtime.selectgo,這個就非常詭異了,select一般用于channel的非阻塞調用,但是問題是新增代碼中沒有地方顯示地調用了select,那可以初步判斷是底層源碼中某處一直在調用select函數,不過目前還不知道是誰觸發的這個調用,還需要繼續查看其他文件。
之后繼續查看互斥鎖的情況,其實這個文件在目前這種情況下排查的價值已經不大了,因為出現問題的是內存溢出而不是CPU占用率,并且CPU占用率確實不是很高,而且Go中是有檢索死鎖的機制,大部分死鎖是能夠被Go發現并報一個deadlock錯誤,打開文件之后發現果然沒有死鎖發生。
接下來查看阻塞操作的分析情況,從解析結果中可以看出,select的阻塞時間遙遙領先,select出現這種情況只會是存在case但是沒有default的時候,當所有case不符合的時候,負責這個select的goroutine會阻塞住直到存在符合的case出現才會喚醒繼續走下去,當時我看到這我滿腦子問號,誰家好人select不加default啊?
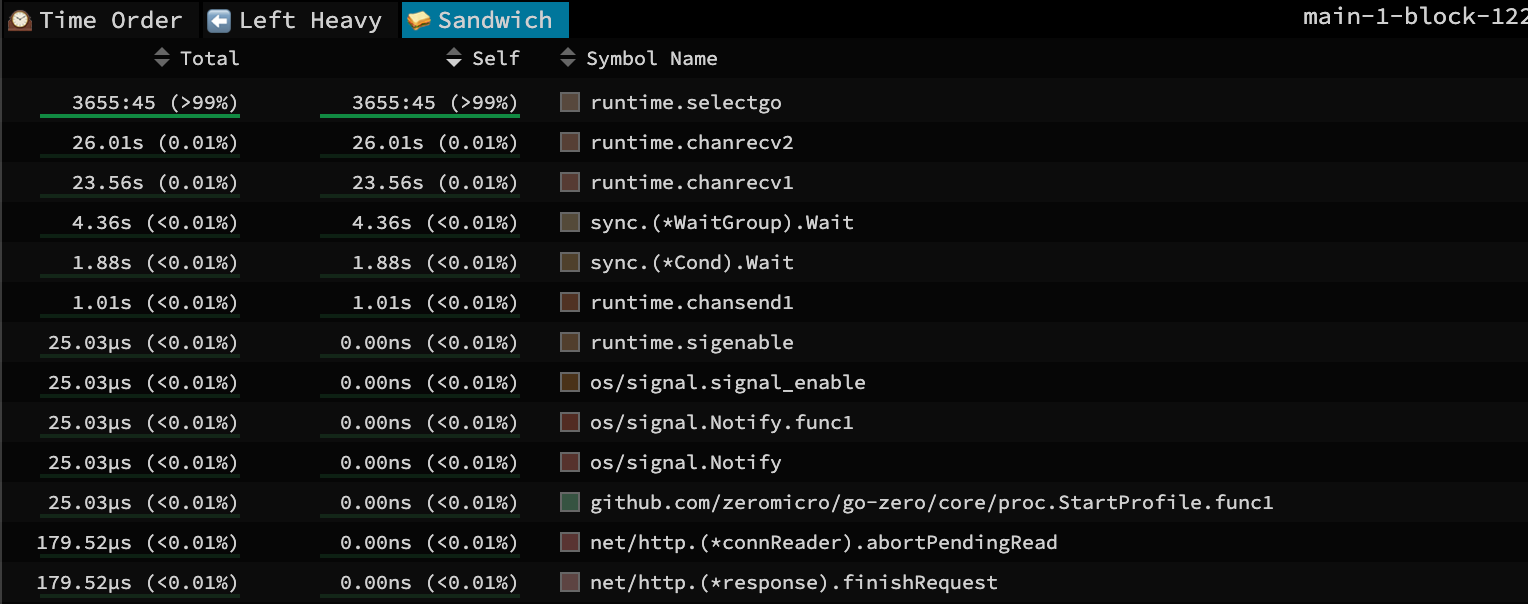
再查看線程創建情況,由于pod剛啟動不久,所以這個文件也看不出什么東西,很正常的線程創建。

看到這里還是沒能定位到問題所在,但是別急,我們還有最重要的文件還沒看,那就是trace文件,它可以記錄程序執行的詳細跟蹤信息,包括函數調用、Goroutine 的創建和調度,使用go自帶的pprof分析工具打開trace文件
go tool trace main-1-trace-1227102939.pprof
會出現以下本地頁面:
在Goroutine分析中,可以鎖定真正的問題所在了,在go-zero的core包下的collection文件在不到一秒內創建了兩萬多的Goroutine,雖然兩萬多數量不多,但是這個速度十分異常,最重要的是這個定時輪就很奇怪,這個項目中根本沒有定時任務,接下來就很容易查詢了,只要查找這次提交的代碼中哪里使用到了collection包。
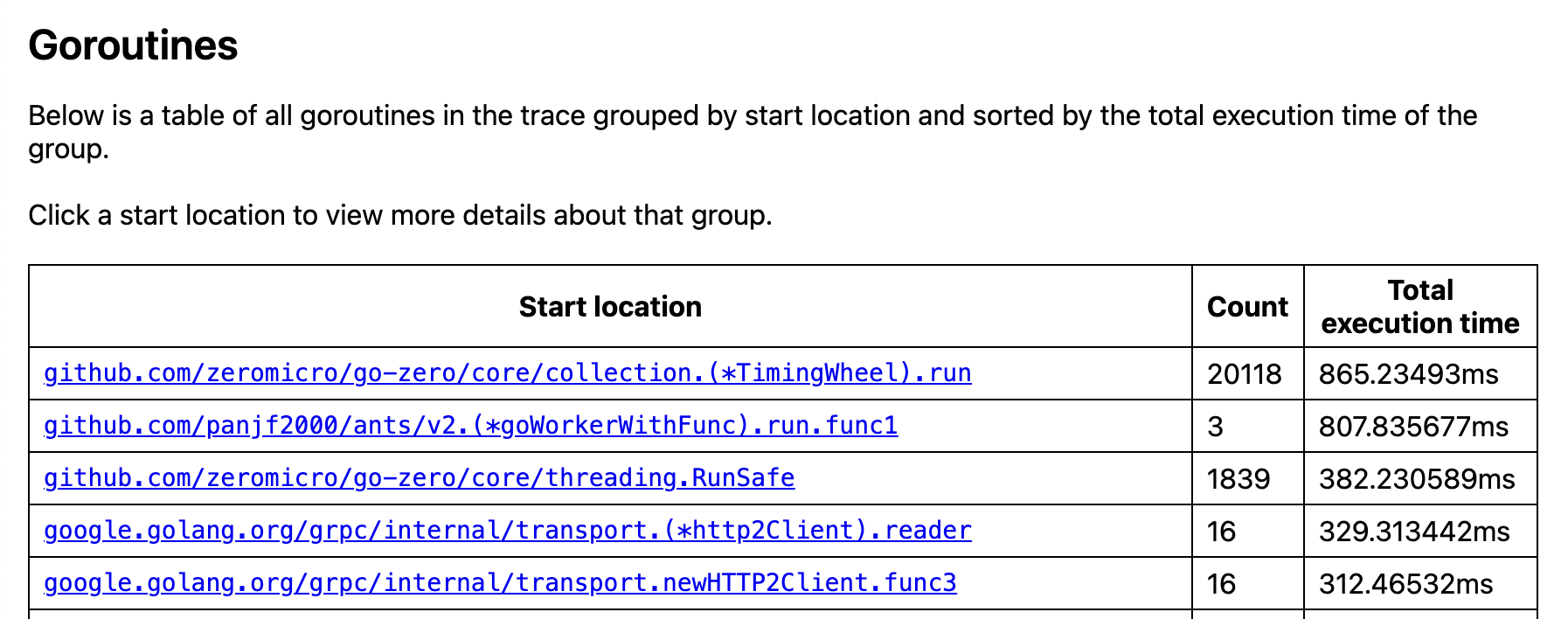
經過一番全局搜索后,最終確定了問題代碼:
func NewXXXLogic(svcCtx *svc.ServiceContext, ctx context.Context) *XXXLogic {
cache, _ := collection.NewCache(30 * time.Second)
return &XXXLogic{
Logger: logx.WithContext(ctx),
svcCtx: svcCtx,
ctx: ctx,
localCache: cache,
}
}
在新上線的版本中只有這一處用到了collection包,原本這里的意思是將建立一個緩存放到上下文中去傳遞,但是乍一看我沒有看出有什么問題,過期時間也設置了,按照我原有理解過期時間到了就會自動釋放掉,為什么還是會內存溢出了?但是我忽然意識到應該不是緩存引發的內存溢出,可能是協程過多引發的內存溢出,因為一個初始協程是2KB左右,如果數量過多也會造成內存不夠。
為了探究根本原因,我點進了collection包的源碼進行查看,在其中NewCache()方法中找到了造成協程數異常增加的定時輪創建方法NewTimingWheel()。
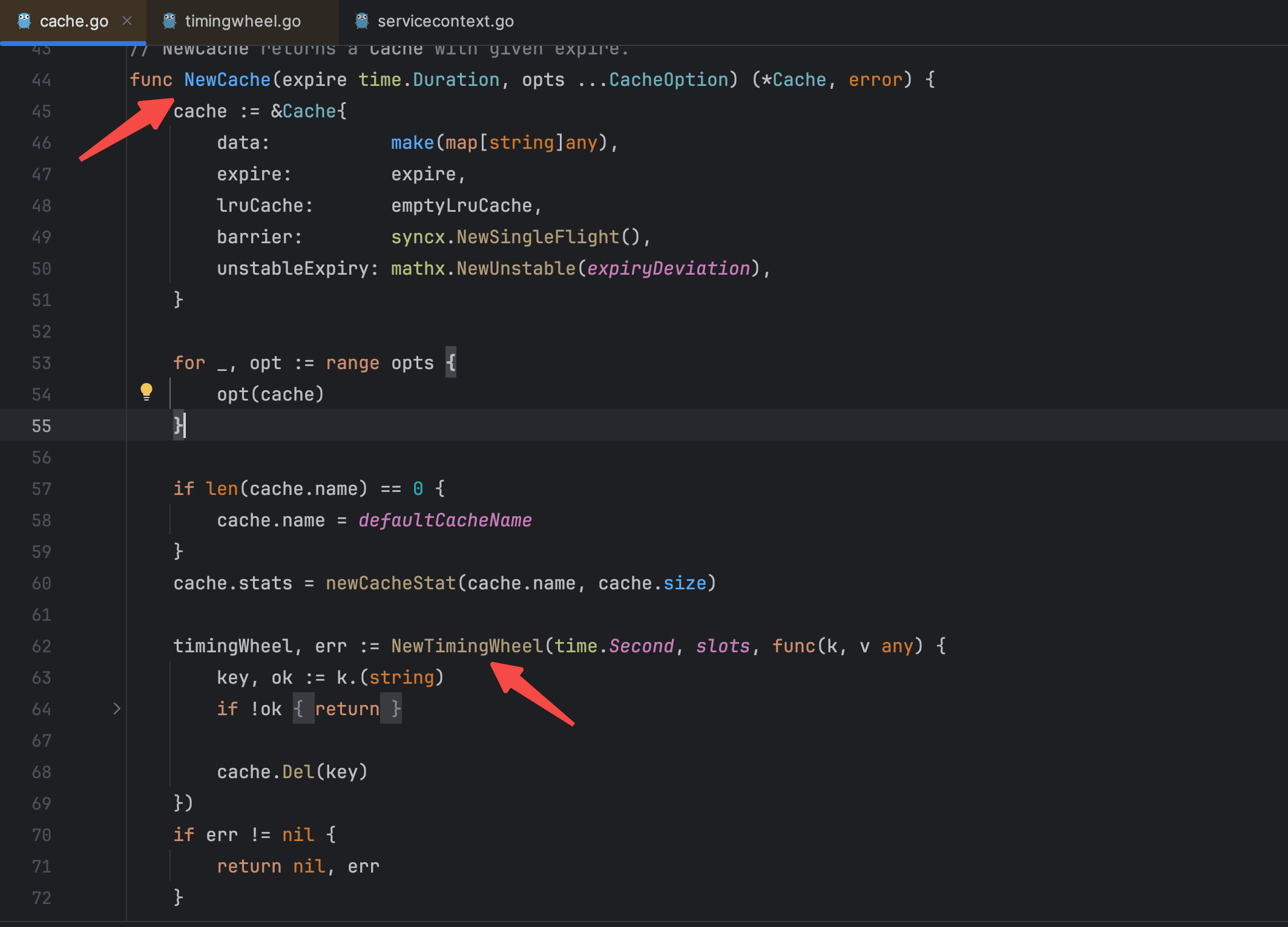
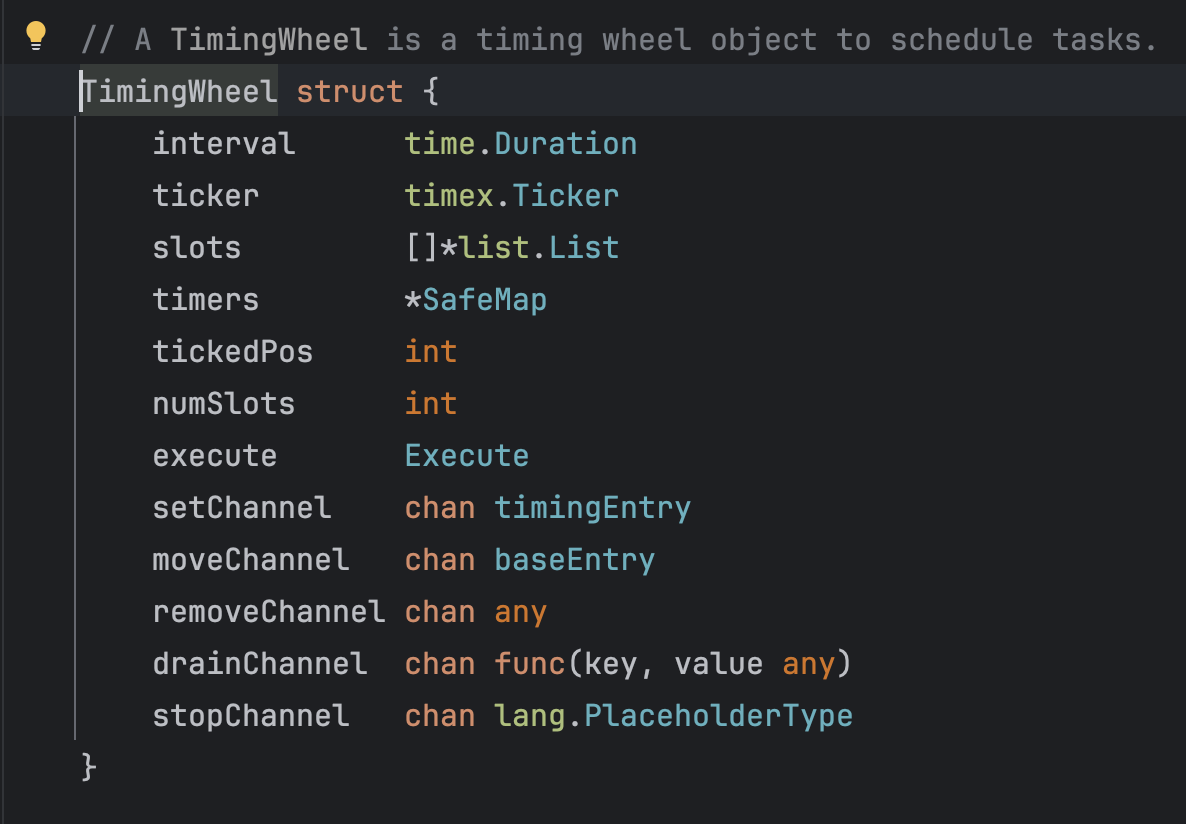
之后點進去這個方法進一步查看,可以看到這個定時輪的結構體,里面包含了四個channel以及一些其他數據結構,粗略估計這一個TimingWheel結構體所占內存要達到一百字節以上,這是一個比較龐大的對象,如果無限制的創建下去很容易造成內存OOM發生。
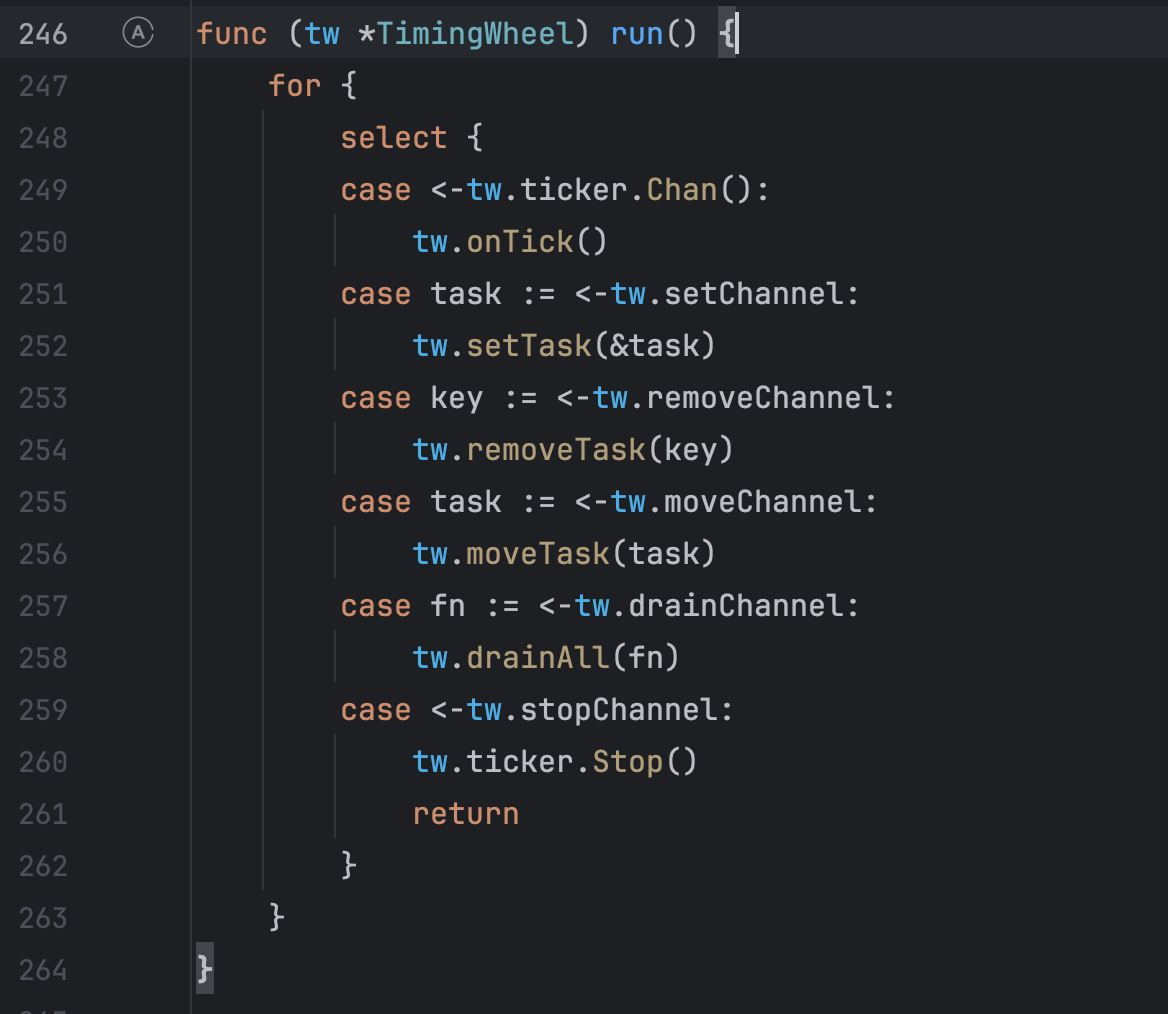
但是這個定時輪為什么會創建那么多呢?為什么不會關閉,按理說go-zero的源碼不應該會有這么大的漏洞,繼續查看這個定時輪的run()方法,終于發現了問題所在,這個定時輪中開啟了select方法,并且沒有default方法,所以之前阻塞文件那里才會顯示select阻塞時間占比達到了99%,并且唯一關閉這個定時輪的方法是接收到tw.ticker.Stop()才會停止,那么這個stop方法會在什么時候調用呢?
答案是會在程序停止運行的時候進行調用。所以如果程序仍在運行,就會有無限制的協程創建定時輪,這時候定時輪因為無法關閉所以協程也不會進行銷毀,有點類似于守護線程,所以在協程無限制的創建下最終導致了線上內存OOM了。
解決
那是不是說明go-zero的這塊源碼存在問題?其實不是的,是我們使用方法錯誤,正確的使用方法不應該將緩存創建在上下文中,而應該創建一個全局緩存,讓所有的上下文都公用這一個緩存,這樣就不會發生定時輪無限創建的問題。
后續將這塊緩存放到了全局中,之后再重新發布觀察了一小時左右,服務內存穩定在了500M以下,與以往服務消耗內存幾乎一致。
歷時兩小時戰斗,終于免于“領盒飯”了。
下班!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號