
InterV 5:數據庫與nosql
一、Mysql
1. 各個數據庫存儲引擎區別
mysql的存儲引擎是針對表進行設置的,一個庫的不同表可以設置不同的存儲引擎,mysql默認支持多種存儲引擎,以適用不同領域的數據庫應用需要,主要的幾個數據庫引擎如下:
MyISAM存儲引擎:
5.5之前默認的存儲引擎,不支持事務、不支持外鍵,表級鎖,內存和硬盤空間占用率低,其優勢是訪問速度快,對事務完整性沒有要求,以select、insert為主的應用基本上都可以使用這個引擎;
InnoDB存儲引擎:
5.5之后默認的存儲引擎,提供了具有提交、回滾和崩潰恢復能力的事務安全,支持外鍵并提供了行級鎖,其劣勢在于寫的處理效率相對較低,并且會占用更多的磁盤空間以保留數據和索引;
MEMORY存儲引擎:
使用存于內存中的內容來創建表,MEMORY類型的表數據存于內存訪問非常的快,默認使用HASH索引,一旦數據庫服務重啟或關閉,表中的數據就會丟失;
MERGE存儲引擎:
MERGE存儲引擎是一組MyISAM表組合,這些MyISAM表結構完全相同。MERGE表本身沒有數據,對MERGE表的CRUD操作都是通過內部的MyISAM表進行的;
2. 提高sql語句效率的技巧
大批量插入數據:
大批量數據插入空表,可將表設置成為MyISAM,并通過disable keys將唯一索引關閉;
大批量數據插入非空Innodb表,可采取如下措施提高效率:
1. 導入數據時按照主鍵順序排列;
2. 關閉唯一性校驗,導入后恢復,導入數據前使用set UNIQUE_CHECKS=0;
3. 關閉自動提交,導入后恢復,如果使用了自動提交,建議在導入前執行SET AUTOCOMMIT=0;
優化INSERT語句:
盡量一次插入多條數據,降低連接、關閉的消耗;
將索引文件和數據文件分在不同的磁盤上存放;
從一個文本文件裝入一個表時,使用LOAD DATA INFLIE ,比一般的insert語句快20倍;
查詢優化:
盡量減少額外的排序,通過索引直接返回有序數據;
where條件和order by使用相同的索引,并且order by的順序與索引順序相同,并且order by的字段都是升序或者都是降序;
盡量只選擇必要的字段,提高sql性能;
能用關聯查詢的不要用子查詢;
對于包含or的查詢語句,如果要利用索引,則or之間的每個條件都必須用到索引,否則應該考慮增加索引;
優化分頁:
在索引上完成排序分頁的操作,然后根據主鍵關聯回原表查詢所需的其他列
把limit查詢轉換為某個位置的查詢;
注意不使用索引的情況:
如果MySQL估計使用索引比全表掃描更慢,則不使用索引。
用or分隔開的條件,如果or前的條件中的列有索引,而后面的列沒有索引,那么涉及到的索引都不會被用到;
復合索引,如果索引列不是復合索引的第一部分,則不使用索引(即不符合最左前綴;
如果like是以’%’開始的,則該列上的索引不會被使用。
如果列為字符串,則where條件中必須將字符常量值加引號,否則即使該列上存在索引,也不會被使用;
not in 、 not exists 、 (<> 不等于 !=)這些操作符不走索引
不要在 where 子句中的"="左邊進行函數、算術運算或其他表達式運算,否則系統將可能無法正確使用索引;
3. 怎么樣做執行計劃分析
通過explain命令獲取mysql如何執行select語句的信息,包括在select語句執行過程中表如何連接和連接的順序;explain分析后的結果解析:
EXPLAIN SELECT * from tbl_notices

執行計劃的各列說明:
1.Id,SQL執行的順序的標識,SQL從大到小的執行.
2. select_type,就是查詢的類型,可以有以下幾種:
2.1、SIMPLE,簡單查詢
2.2、PRIMARY,主查詢(多個表關聯時)
2.3、UNION,聯合查詢
2.4、DEPENDENT UNION,子查詢中的聯合查詢
2.5、UNION RESULT,聯合的結果集
2.6、SUBQUERY,第一個子查詢
2.7、 DEPENDENT SUBQUERY,子查詢中第一句
2.8、DERIVED,派生表
3.Table,顯示這一行的數據是關于哪張表的.
4.Type,這列很重要,顯示了連接使用了哪種類別,有無使用索引.從最好到最差的連接類型為const、eq_ref、ref、range、index和ALL
4.1、system, const聯接類型的一個特例。表僅有一行滿足條件
4.2、const,表最多有一個匹配行,它將在查詢開始時被讀取。因為僅有一行,在這行的列值可被優化器剩余部分認為是常數。const表很快,因為它們只讀取一次!
4.3、eq_ref,對于每個來自于前面的表的行組合,從該表中讀取一行。這可能是最好的聯接類型,除了const類型。它用在一個索引的所有部分被聯接使用并且索引是UNIQUE或PRIMARY KEY。eq_ref可以用于使用= 操作符比較的帶索引的列。
比較值可以為常量或一個使用在該表前面所讀取的表的列的表達式。
4.4、ref,對于每個來自于前面的表的行組合,所有有匹配索引值的行將從這張表中讀取。如果聯接只使用鍵的最左邊的前綴,或如果鍵不是UNIQUE或PRIMARY KEY(換句話說,如果聯接不能基于關鍵字選擇單個行的話),則使用ref。
如果使用的鍵僅僅匹配少量行,該聯接類型是不錯的。ref可以用于使用=或<=>操作符的帶索引的列。
4.5、 ref_or_null,該聯接類型如同ref,但是添加了MySQL可以專門搜索包含NULL值的行。在解決子查詢中經常使用該聯接類型的優化。
4.6、index_merge,該聯接類型表示使用了索引合并優化方法。在這種情況下,key列包含了使用的索引的清單,key_len包含了使用的索引的最長的關鍵元素。
4.7、unique_subquery,該類型替換了下面形式的IN子查詢的ref。value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一個索引查找函數,可以完全替換子查詢,效率更高。
4.8、index_subquery,該聯接類型類似于unique_subquery。可以替換IN子查詢
4.9、range、只檢索給定范圍的行,使用一個索引來選擇行。key列顯示使用了哪個索引。key_len包含所使用索引的最長關鍵元素。在該類型中ref列為NULL。
4.10、index、該聯接類型與ALL相同,除了只有索引樹被掃描。這通常比ALL快,因為索引文件通常比數據文件小。
4.11、ALL,對于每個來自于先前的表的行組合,進行完整的表掃描。如果表是第一個沒標記const的表,這通常不好,并且通常在它情況下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中 的常數值或列值被檢索出。
結果值從好到壞依次是:
system > const > eq_ref > ref > range > index > ALL
一般來說,好的sql查詢至少達到range級別,最好能達到ref;
5.possible_keys,possible_keys列指出MySQL可能使用哪個索引在該表中找到行。
6. Key,key列顯示MySQL實際使用的鍵(索引)。
7.key_len,使用的索引的長度。在不損失精確性的情況下,長度越短越好
8. Ref,ref列顯示使用哪個列或常數與key一起從表中選擇行。
9. Rows,rows列顯示MySQL認為它執行查詢時必須檢查的行數。
10. Extra,該列包含MySQL解決查詢的詳細信息,下面詳細。
Extra,這個列可以顯示的信息非常多,有幾十種。常用如下:
10.1. Distinct, 一旦MYSQL找到了與行相聯合匹配的行,就不再搜索了
10.2. Not exists ,使用了反連接,先查詢外表,再查詢內表
10.3. Range checked for each Record(index map:#) 沒有找到理想的索引,因此對于從前面表中來的每一個行組合,MYSQL檢查使用哪個索引,并用它來從表中返回行。這是使用索引的最慢的連接之一
10.4. Using filesort 看到這個的時候,查詢需要優化。MYSQL需要進行額外的步驟來發現如何對返回的行排序。它根據連接類型以及存儲排序鍵值和匹配條件的全部行的行指針來排序全部行
10.5. Using index 列數據是從僅僅使用了索引中的信息而沒有讀取實際的行動的表返回的,這發生在對表的全部的請求列都是同一個索引的部分的時候
10.6. Using temporary 看到這個的時候,查詢需要優化。這里,MYSQL需要創建一個臨時表來存儲結果,這通常發生在對不同的列集進行ORDER BY上,而不是GROUP BY上
10.7. Using where 使用了WHERE從句來限制哪些行將與下一張表匹配或者是返回給用戶。如果不想返回表中的全部行,并且連接類型ALL或index,這就會發生,或者是查詢有問題
10.8. firstmatch(tb_name):5.6.x開始引入的優化子查詢的新特性之一,常見于where字句含有in()類型的子查詢。如果內表的數據量比較大,就可能出現這個.
10.9. loosescan(m..n):5.6.x之后引入的優化子查詢的新特性之一,在in()類型的子查詢中,子查詢返回的可能有重復記錄時,就可能出現這個
重要:執行計劃的各列說明里面標紅的項都是我們在做SQL執行計劃分析時應該重點關注的項
4. mysql主從復制的原理
mysql 主從復制原理:
1). master 將操作記錄到二進制日志(binary log)中;
2). slave IO 線程 將master的binary log events讀寫到它的中繼日志(relay log);
3). slave SQL線程讀取中繼日志,將重做記錄數據到數據庫中。
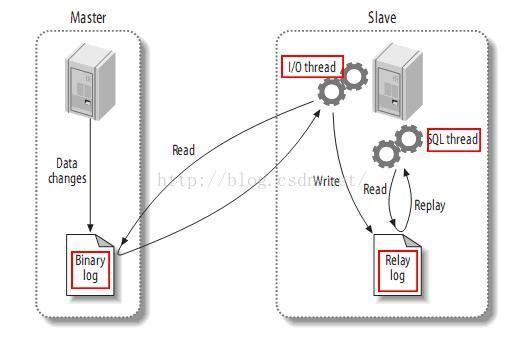
MySQL的主從同步是一個很成熟的架構,優點為:
1) 在從服務器可以執行查詢工作(即我們常說的讀功能),降低主服務器壓力;
2) 在從主服務器進行備份,避免備份期間影響主服務器服務;
3) 當主服務器出現問題時,可以切換到從服務器。
5. 樂觀鎖和悲觀鎖
樂觀鎖:
樂觀鎖( Optimistic Locking ) 相對悲觀鎖而言,樂觀鎖假設認為數據一般情況下不會造成沖突,所以在數據進行提交更新的時候,才會正式對數據的沖突與否進行檢測,如果發現沖突了,則讓返回用戶錯誤的信息,讓用戶決定如何去做
相對于悲觀鎖,在對數據庫進行處理的時候,樂觀鎖并不會使用數據庫提供的鎖機制。一般的實現樂觀鎖的方式就是記錄數據版本。
實現數據版本有兩種方式,第一種是使用版本號,第二種是使用時間戳。
備注:
數據版本,為數據增加的一個版本標識。當讀取數據時,將版本標識的值一同讀出,數據每更新一次,同時對版本標識進行更新。當我們提交更新的時候,判斷數據庫表對應記錄的當前版本信息與第一次取出來的版本標識進行比對,如果數據庫表當前版本號與第一次取出來的版本標識值相等,則予以更新,否則認為是過期數據。
使用版本號實現樂觀鎖
使用版本號時,可以在數據初始化時指定一個版本號,每次對數據的更新操作都對版本號執行+1操作。并判斷當前版本號是不是該數據的最新的版本號。
1 1.查詢出商品信息
2 select (status,status,version) from t_goods where id=#{id}
3 2.根據商品信息生成訂單
4 3.修改商品status為2
5 update t_goods
6 set status=2,version=version+1
7 where id=#{id} and version=#{version};
樂觀鎖優點與不足
樂觀并發控制相信事務之間的數據競爭(data race)的概率是比較小的,因此盡可能直接做下去,直到提交的時候才去鎖定,所以不會產生任何鎖和死鎖。但如果直接簡單這么做,還是有可能會遇到不可預期的結果,例如兩個事務都讀取了數據庫的某一行,經過修改以后寫回數據庫,這時就遇到了問題。
悲觀鎖:
悲觀鎖,正如其名,它指的是對數據被外界(包括本系統當前的其他事務,以及來自外部系統的事務處理)修改持保守態度(悲觀),因此,在整個數據處理過程中,將數據處于鎖定狀態。 悲觀鎖的實現,往往依靠數據庫提供的鎖機制 (也只有數據庫層提供的鎖機制才能真正保證數據訪問的排他性,否則,即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改數據)
在數據庫中,悲觀鎖的流程如下:
在對任意記錄進行修改前,先嘗試為該記錄加上排他鎖(exclusive locking)。
如果加鎖失敗,說明該記錄正在被修改,那么當前查詢可能要等待或者拋出異常。 具體響應方式由開發者根據實際需要決定。
如果成功加鎖,那么就可以對記錄做修改,事務完成后就會解鎖了。
其間如果有其他對該記錄做修改或加排他鎖的操作,都會等待我們解鎖或直接拋出異常。
在查詢語句后面增加LOCK IN SHARE MODE,Mysql會對查詢結果中的每行都加共享鎖,當沒有其他線程對查詢結果集中的任何一行使用排他鎖時,可以成功申請共享鎖,否則會被阻塞。其他線程也可以讀取使用了共享鎖的表,而且這些線程讀取的是同一個版本的數據。
MySQL InnoDB中使用悲觀鎖
要使用悲觀鎖,我們必須關閉mysql數據庫的自動提交屬性,因為MySQL默認使用autocommit模式,也就是說,當你執行一個更新操作后,MySQL會立刻將結果進行提交。set autocommit=0;
1 //0.開始事務 2 begin;/begin work;/start transaction; (三者選一就可以) 3 //1.查詢出商品信息 4 select status from t_goods where id=1 for update; 5 //2.根據商品信息生成訂單 6 insert into t_orders (id,goods_id) values (null,1); 7 //3.修改商品status為2 8 update t_goods set status=2; 9 //4.提交事務 10 commit;/commit work;
悲觀鎖優點與不足
悲觀并發控制實際上是“先取鎖再訪問”的保守策略,為數據處理的安全提供了保證。但是在效率方面,處理加鎖的機制會讓數據庫產生額外的開銷,還有增加產生死鎖的機會;另外,在只讀型事務處理中由于不會產生沖突,也沒必要使用鎖,這樣做只能增加系統負載;還有會降低了并行性,一個事務如果鎖定了某行數據,其他事務就必須等待該事務處理完才可以處理那行數
知識拓展:
1.排他鎖
排他鎖又稱寫鎖,如果事務T對數據A加上排他鎖后,則其他事務不能再對A加任任何類型的封鎖。獲準排他鎖的事務既能讀數據,又能修改數據。
用法:
SELECT ... FOR UPDATE;
在查詢語句后面增加FOR UPDATE,Mysql會對查詢結果中的每行都加排他鎖,當沒有其他線程對查詢結果集中的任何一行使用排他鎖時,可以成功申請排他鎖,否則會被阻塞。
2. 共享鎖
共享鎖又稱讀鎖,是讀取操作創建的鎖。其他用戶可以并發讀取數據,但任何事務都不能對數據進行修改(獲取數據上的排他鎖),直到已釋放所有共享鎖。
如果事務T對數據A加上共享鎖后,則其他事務只能對A再加共享鎖,不能加排他鎖。獲準共享鎖的事務只能讀數據,不能修改數據。
用法:
SELECT ... LOCK IN SHARE MODE;
在查詢語句后面增加LOCK IN SHARE MODE,Mysql會對查詢結果中的每行都加共享鎖,當沒有其他線程對查詢結果集中的任何一行使用排他鎖時,可以成功申請共享鎖,否則會被阻塞。其他線程也可以讀取使用了共享鎖的表,而且這些線程讀取的是同一個版本的數據。
樂觀鎖:修改數據庫記錄前,給數據庫的記錄加上一個版本號version,修改時把版本號加1,兩個人如果同時修改數據,第一個人已經把version加1了,第二個人就不能再修改了,并發數比較少時用數據庫的樂觀鎖和悲觀鎖即可滿足需求,并發數比較大時就redis的隊列來解決
6. 一條sql語句在mysql中如何執行的
在分析之前我會先帶著你看看 MySQL 的基礎架構,知道了 MySQL 由那些組件組成已經這些組件的作用是什么,可以幫助我們理解和解決這些問題。
6.1 MySQL 基礎架構分析
下圖是 MySQL 的一個簡要架構圖,從下圖你可以很清晰的看到用戶的 SQL 語句在 MySQL 內部是如何執行的。
先簡單介紹一下下圖涉及的一些組件的基本作用幫助大家理解這幅圖,在 1.2 節中會詳細介紹到這些組件的作用。
- 連接器: 身份認證和權限相關(登錄 MySQL 的時候)。
- 查詢緩存: 執行查詢語句的時候,會先查詢緩存(MySQL 8.0 版本后移除,因為這個功能不太實用)。
- 分析器: 沒有命中緩存的話,SQL 語句就會經過分析器,分析器說白了就是要先看你的 SQL 語句要干嘛,再檢查你的 SQL 語句語法是否正確。
- 優化器: 按照 MySQL 認為最優的方案去執行。
- 執行器: 執行語句,然后從存儲引擎返回數據。
簡單來說 MySQL 主要分為 Server 層和存儲引擎層:
- Server 層:主要包括連接器、查詢緩存、分析器、優化器、執行器等,所有跨存儲引擎的功能都在這一層實現,比如存儲過程、觸發器、視圖,函數等,還有一個通用的日志模塊 binglog 日志模塊。
- 存儲引擎: 主要負責數據的存儲和讀取,采用可以替換的插件式架構,支持 InnoDB、MyISAM、Memory 等多個存儲引擎,其中 InnoDB 引擎有自有的日志模塊 redolog 模塊。現在最常用的存儲引擎是 InnoDB,它從 MySQL 5.5.5 版本開始就被當做默認存儲引擎了。
1) 連接器
連接器主要和身份認證和權限相關的功能相關,就好比一個級別很高的門衛一樣。
主要負責用戶登錄數據庫,進行用戶的身份認證,包括校驗賬戶密碼,權限等操作,如果用戶賬戶密碼已通過,連接器會到權限表中查詢該用戶的所有權限,之后在這個連接里的權限邏輯判斷都是會依賴此時讀取到的權限數據,也就是說,后續只要這個連接不斷開,即時管理員修改了該用戶的權限,該用戶也是不受影響的。
2) 查詢緩存(MySQL 8.0 版本后移除)
查詢緩存主要用來緩存我們所執行的 SELECT 語句以及該語句的結果集。
連接建立后,執行查詢語句的時候,會先查詢緩存,MySQL 會先校驗這個 sql 是否執行過,以 Key-Value 的形式緩存在內存中,Key 是查詢預計,Value 是結果集。如果緩存 key 被命中,就會直接返回給客戶端,如果沒有命中,就會執行后續的操作,完成后也會把結果緩存起來,方便下一次調用。當然在真正執行緩存查詢的時候還是會校驗用戶的權限,是否有該表的查詢條件。
MySQL 查詢不建議使用緩存,因為查詢緩存失效在實際業務場景中可能會非常頻繁,假如你對一個表更新的話,這個表上的所有的查詢緩存都會被清空。對于不經常更新的數據來說,使用緩存還是可以的。
所以,一般在大多數情況下我們都是不推薦去使用查詢緩存的。
MySQL 8.0 版本后刪除了緩存的功能,官方也是認為該功能在實際的應用場景比較少,所以干脆直接刪掉了。
3) 分析器
MySQL 沒有命中緩存,那么就會進入分析器,分析器主要是用來分析 SQL 語句是來干嘛的,分析器也會分為幾步:
第一步,詞法分析,一條 SQL 語句有多個字符串組成,首先要提取關鍵字,比如 select,提出查詢的表,提出字段名,提出查詢條件等等。做完這些操作后,就會進入第二步。
第二步,語法分析,主要就是判斷你輸入的 sql 是否正確,是否符合 MySQL 的語法。
完成這 2 步之后,MySQL 就準備開始執行了,但是如何執行,怎么執行是最好的結果呢?這個時候就需要優化器上場了。
4) 優化器
優化器的作用就是它認為的最優的執行方案去執行(有時候可能也不是最優,這篇文章涉及對這部分知識的深入講解),比如多個索引的時候該如何選擇索引,多表查詢的時候如何選擇關聯順序等。
可以說,經過了優化器之后可以說這個語句具體該如何執行就已經定下來。
5) 執行器
當選擇了執行方案后,MySQL 就準備開始執行了,首先執行前會校驗該用戶有沒有權限,如果沒有權限,就會返回錯誤信息,如果有權限,就會去調用引擎的接口,返回接口執行的結果。
6.2 語句分析
6.2.1 查詢語句
說了以上這么多,那么究竟一條 sql 語句是如何執行的呢?其實我們的 sql 可以分為兩種,一種是查詢,一種是更新(增加,更新,刪除)。我們先分析下查詢語句,語句如下:
select * from tb_student A where A.age='18' and A.name=' 張三 ';
結合上面的說明,我們分析下這個語句的執行流程:
-
先檢查該語句是否有權限,如果沒有權限,直接返回錯誤信息,如果有權限,在 MySQL8.0 版本以前,會先查詢緩存,以這條 sql 語句為 key 在內存中查詢是否有結果,如果有直接緩存,如果沒有,執行下一步。
-
通過分析器進行詞法分析,提取 sql 語句的關鍵元素,比如提取上面這個語句是查詢 select,提取需要查詢的表名為 tb_student,需要查詢所有的列,查詢條件是這個表的 id='1'。然后判斷這個 sql 語句是否有語法錯誤,比如關鍵詞是否正確等等,如果檢查沒問題就執行下一步。
-
接下來就是優化器進行確定執行方案,上面的 sql 語句,可以有兩種執行方案:
a.先查詢學生表中姓名為“張三”的學生,然后判斷是否年齡是 18。 b.先找出學生中年齡 18 歲的學生,然后再查詢姓名為“張三”的學生。那么優化器根據自己的優化算法進行選擇執行效率最好的一個方案(優化器認為,有時候不一定最好)。那么確認了執行計劃后就準備開始執行了。
-
進行權限校驗,如果沒有權限就會返回錯誤信息,如果有權限就會調用數據庫引擎接口,返回引擎的執行結果。
6.2.2 更新語句
以上就是一條查詢 sql 的執行流程,那么接下來我們看看一條更新語句如何執行的呢?sql 語句如下:
update tb_student A set A.age='19' where A.name=' 張三 ';
我們來給張三修改下年齡,在實際數據庫肯定不會設置年齡這個字段的,不然要被技術負責人打的。其實條語句也基本上會沿著上一個查詢的流程走,只不過執行更新的時候肯定要記錄日志啦,這就會引入日志模塊了,MySQL 自帶的日志模塊式 binlog(歸檔日志) ,所有的存儲引擎都可以使用,我們常用的 InnoDB 引擎還自帶了一個日志模塊 redo log(重做日志),我們就以 InnoDB 模式下來探討這個語句的執行流程。流程如下:
- 先查詢到張三這一條數據,如果有緩存,也是會用到緩存。
- 然后拿到查詢的語句,把 age 改為 19,然后調用引擎 API 接口,寫入這一行數據,InnoDB 引擎把數據保存在內存中,同時記錄 redo log,此時 redo log 進入 prepare 狀態,然后告訴執行器,執行完成了,隨時可以提交。
- 執行器收到通知后記錄 binlog,然后調用引擎接口,提交 redo log 為提交狀態。
- 更新完成。
這里肯定有同學會問,為什么要用兩個日志模塊,用一個日志模塊不行嗎?
這是因為最開始 MySQL 并沒與 InnoDB 引擎( InnoDB 引擎是其他公司以插件形式插入 MySQL 的) ,MySQL 自帶的引擎是 MyISAM,但是我們知道 redo log 是 InnoDB 引擎特有的,其他存儲引擎都沒有,這就導致會沒有 crash-safe 的能力(crash-safe 的能力即使數據庫發生異常重啟,之前提交的記錄都不會丟失),binlog 日志只能用來歸檔。
并不是說只用一個日志模塊不可以,只是 InnoDB 引擎就是通過 redo log 來支持事務的。那么,又會有同學問,我用兩個日志模塊,但是不要這么復雜行不行,為什么 redo log 要引入 prepare 預提交狀態?這里我們用反證法來說明下為什么要這么做?
- 先寫 redo log 直接提交,然后寫 binlog,假設寫完 redo log 后,機器掛了,binlog 日志沒有被寫入,那么機器重啟后,這臺機器會通過 redo log 恢復數據,但是這個時候 bingog 并沒有記錄該數據,后續進行機器備份的時候,就會丟失這一條數據,同時主從同步也會丟失這一條數據。
- 先寫 binlog,然后寫 redo log,假設寫完了 binlog,機器異常重啟了,由于沒有 redo log,本機是無法恢復這一條記錄的,但是 binlog 又有記錄,那么和上面同樣的道理,就會產生數據不一致的情況。
如果采用 redo log 兩階段提交的方式就不一樣了,寫完 binglog 后,然后再提交 redo log 就會防止出現上述的問題,從而保證了數據的一致性。那么問題來了,有沒有一個極端的情況呢?假設 redo log 處于預提交狀態,binglog 也已經寫完了,這個時候發生了異常重啟會怎么樣呢? 這個就要依賴于 MySQL 的處理機制了,MySQL 的處理過程如下:
- 判斷 redo log 是否完整,如果判斷是完整的,就立即提交。
- 如果 redo log 只是預提交但不是 commit 狀態,這個時候就會去判斷 binlog 是否完整,如果完整就提交 redo log, 不完整就回滾事務。
這樣就解決了數據一致性的問題。
6.3 總結
- MySQL 主要分為 Server 層和引擎層,Server 層主要包括連接器、查詢緩存、分析器、優化器、執行器,同時還有一個日志模塊(binlog),這個日志模塊所有執行引擎都可以共用,redolog 只有 InnoDB 有。
- 引擎層是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
- 查詢語句的執行流程如下:權限校驗(如果命中緩存)---》查詢緩存---》分析器---》優化器---》權限校驗---》執行器---》引擎
- 更新語句執行流程如下:分析器----》權限校驗----》執行器---》引擎---redo log(prepare 狀態---》binlog---》redo log(commit狀態)
6.4 參考
- 《MySQL 實戰45講》
- MySQL 5.6參考手冊:https://dev.MySQL.com/doc/refman/5.6/en/
7. 事務隔離級別
什么是事務?
事務是邏輯上的一組操作,要么都執行,要么都不執行。
事務最經典也經常被拿出來說例子就是轉賬了。假如小明要給小紅轉賬1000元,這個轉賬會涉及到兩個關鍵操作就是:將小明的余額減少1000元,將小紅的余額增加1000元。萬一在這兩個操作之間突然出現錯誤比如銀行系統崩潰,導致小明余額減少而小紅的余額沒有增加,這樣就不對了。事務就是保證這兩個關鍵操作要么都成功,要么都要失敗。
事物的特性(ACID)
- 原子性: 事務是最小的執行單位,不允許分割。事務的原子性確保動作要么全部完成,要么完全不起作用;
- 一致性: 執行事務前后,數據保持一致,多個事務對同一個數據讀取的結果是相同的;
- 隔離性: 并發訪問數據庫時,一個用戶的事務不被其他事務所干擾,各并發事務之間數據庫是獨立的;
- 持久性: 一個事務被提交之后。它對數據庫中數據的改變是持久的,即使數據庫發生故障也不應該對其有任何影響。
并發事務帶來的問題
在典型的應用程序中,多個事務并發運行,經常會操作相同的數據來完成各自的任務(多個用戶對統一數據進行操作)。并發雖然是必須的,但可能會導致以下的問題。
- 臟讀(Dirty read): 當一個事務正在訪問數據并且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時另外一個事務也訪問了這個數據,然后使用了這個數據。因為這個數據是還沒有提交的數據,那么另外一個事務讀到的這個數據是“臟數據”,依據“臟數據”所做的操作可能是不正確的。即讀取到了還未提交到數據庫的數據
- 丟失修改(Lost to modify): 指在一個事務讀取一個數據時,另外一個事務也訪問了該數據,那么在第一個事務中修改了這個數據后,第二個事務也修改了這個數據。這樣第一個事務內的修改結果就被丟失,因此稱為丟失修改。 例如:事務1讀取某表中的數據A=20,事務2也讀取A=20,事務1修改A=A-1,事務2也修改A=A-1,最終結果A=19,事務1的修改被丟失。即兩個事物同時修改一條數據,只有一個事物的修改生效
- 不可重復讀(Unrepeatableread): 指在一個事務內多次讀同一數據。在這個事務還沒有結束時,另一個事務也訪問該數據。那么,在第一個事務中的兩次讀數據之間,由于第二個事務的修改導致第一個事務兩次讀取的數據可能不太一樣。這就發生了在一個事務內兩次讀到的數據是不一樣的情況,因此稱為不可重復讀。即同一條件讀取數據,兩次獲取的數據不一樣
- 幻讀(Phantom read): 幻讀與不可重復讀類似。它發生在一個事務(T1)讀取了幾行數據,接著另一個并發事務(T2)插入了一些數據時。在隨后的查詢中,第一個事務(T1)就會發現多了一些原本不存在的記錄,就好像發生了幻覺一樣,所以稱為幻讀。即同一條件讀取數據,兩次讀取的數據多了或者少了
不可重復度和幻讀區別:
不可重復讀的重點是修改,幻讀的重點在于新增或者刪除。
例1(同樣的條件, 你讀取過的數據, 再次讀取出來發現值不一樣了 ):事務1中的A先生讀取自己的工資為 1000的操作還沒完成,事務2中的B先生就修改了A的工資為2000,導 致A再讀自己的工資時工資變為 2000;這就是不可重復讀。
例2(同樣的條件, 第1次和第2次讀出來的記錄數不一樣 ):假某工資單表中工資大于3000的有4人,事務1讀取了所有工資大于3000的人,共查到4條記錄,這時事務2 又插入了一條工資大于3000的記錄,事務1再次讀取時查到的記錄就變為了5條,這樣就導致了幻讀。
事務隔離級別
SQL 標準定義了四個隔離級別:
- READ-UNCOMMITTED(讀取未提交): 最低的隔離級別,允許讀取尚未提交的數據變更,可能會導致臟讀、幻讀或不可重復讀。
- READ-COMMITTED(讀取已提交): 允許讀取并發事務已經提交的數據,可以阻止臟讀,但是幻讀或不可重復讀仍有可能發生。
- REPEATABLE-READ(可重復讀): 對同一字段的多次讀取結果都是一致的,除非數據是被本身事務自己所修改,可以阻止臟讀和不可重復讀,但幻讀仍有可能發生。
- SERIALIZABLE(可串行化): 最高的隔離級別,完全服從ACID的隔離級別。所有的事務依次逐個執行,這樣事務之間就完全不可能產生干擾,也就是說,該級別可以防止臟讀、不可重復讀以及幻讀。
| 隔離級別 | 臟讀 | 不可重復讀 | 幻影讀 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL InnoDB 存儲引擎的默認支持的隔離級別是 REPEATABLE-READ(可重讀)。我們可以通過SELECT @@tx_isolation;命令來查看
mysql> SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
這里需要注意的是:與 SQL 標準不同的地方在于InnoDB 存儲引擎在 **REPEATABLE-READ(可重讀)事務隔離級別下使用的是Next-Key Lock 鎖算法,因此可以避免幻讀的產生,這與其他數據庫系統(如 SQL Server)是不同的。所以說InnoDB 存儲引擎的默認支持的隔離級別是 REPEATABLE-READ(可重讀) 已經可以完全保證事務的隔離性要求,即達到了 SQL標準的SERIALIZABLE(可串行化)**隔離級別。
因為隔離級別越低,事務請求的鎖越少,所以大部分數據庫系統的隔離級別都是READ-COMMITTED(讀取提交內容):,但是你要知道的是InnoDB 存儲引擎默認使用 **REPEATABLE-READ(可重讀)**并不會有任何性能損失。
InnoDB 存儲引擎在 分布式事務 的情況下一般會用到**SERIALIZABLE(可串行化)**隔離級別。
實際情況演示
在下面我會使用 2 個命令行mysql ,模擬多線程(多事務)對同一份數據的臟讀問題。
MySQL 命令行的默認配置中事務都是自動提交的,即執行SQL語句后就會馬上執行 COMMIT 操作。如果要顯式地開啟一個事務需要使用命令:START TARNSACTION。
我們可以通過下面的命令來設置隔離級別。
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
我們再來看一下我們在下面實際操作中使用到的一些并發控制語句:
START TARNSACTION|BEGIN:顯式地開啟一個事務。COMMIT:提交事務,使得對數據庫做的所有修改成為永久性。ROLLBACK:回滾會結束用戶的事務,并撤銷正在進行的所有未提交的修改。
臟讀(讀未提交)
實例.jpg)
避免臟讀(讀已提交)

不可重復讀
還是剛才上面的讀已提交的圖,雖然避免了讀未提交,但是卻出現了,一個事務還沒有結束,就發生了 不可重復讀問題。

可重復讀

防止幻讀(可重復讀)
.jpg)
一個事務對數據庫進行操作,這種操作的范圍是數據庫的全部行,然后第二個事務也在對這個數據庫操作,這種操作可以是插入一行記錄或刪除一行記錄,那么第一個是事務就會覺得自己出現了幻覺,怎么還有沒有處理的記錄呢? 或者 怎么多處理了一行記錄呢?
幻讀和不可重復讀有些相似之處 ,但是不可重復讀的重點是修改,幻讀的重點在于新增或者刪除。
參考
- 《MySQL技術內幕:InnoDB存儲引擎》
- https://dev.mysql.com/doc/refman/5.7/en/
- Mysql 鎖:靈魂七拷問
- Innodb 中的事務隔離級別和鎖的關系
8. 搞定數據庫索引就是這么簡單

為什么索引能提高查詢速度
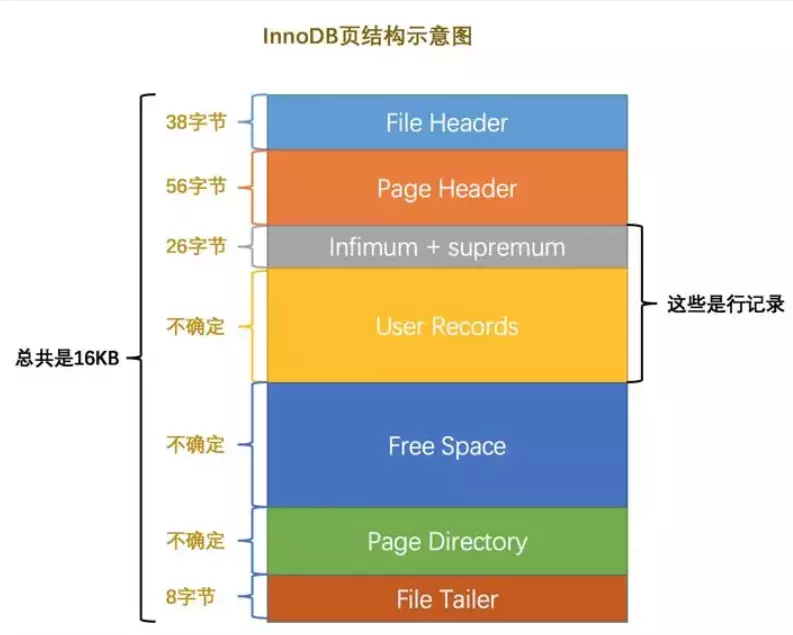
先從 MySQL 的基本存儲結構說起
MySQL的基本存儲結構是頁(記錄都存在頁里邊):
- 各個數據頁可以組成一個雙向鏈表
- 每個數據頁中的記錄又可以組成一個單向鏈表
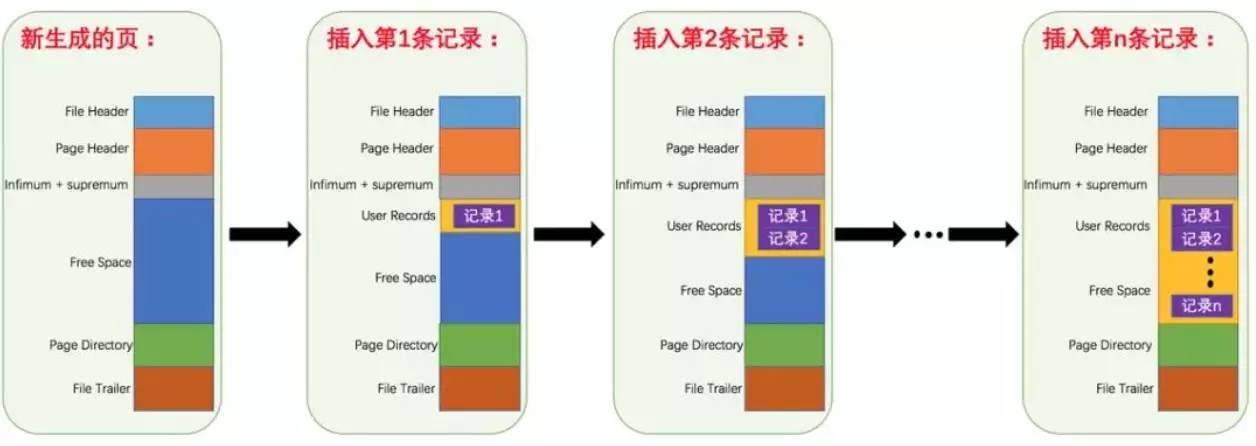
- 每個數據頁都會為存儲在它里邊兒的記錄生成一個頁目錄,在通過主鍵查找某條記錄的時候可以在頁目錄中使用二分法快速定位到對應的槽,然后再遍歷該槽對應分組中的記錄即可快速找到指定的記錄
- 以其他列(非主鍵)作為搜索條件:只能從最小記錄開始依次遍歷單鏈表中的每條記錄。
所以說,如果我們寫select * from user where indexname = 'xxx'這樣沒有進行任何優化的sql語句,默認會這樣做:
- 定位到記錄所在的頁:需要遍歷雙向鏈表,找到所在的頁
- 從所在的頁內中查找相應的記錄:由于不是根據主鍵查詢,只能遍歷所在頁的單鏈表了
很明顯,在數據量很大的情況下這樣查找會很慢!這樣的時間復雜度為O(n)。
使用索引之后
索引做了些什么可以讓我們查詢加快速度呢?其實就是將無序的數據變成有序(相對):
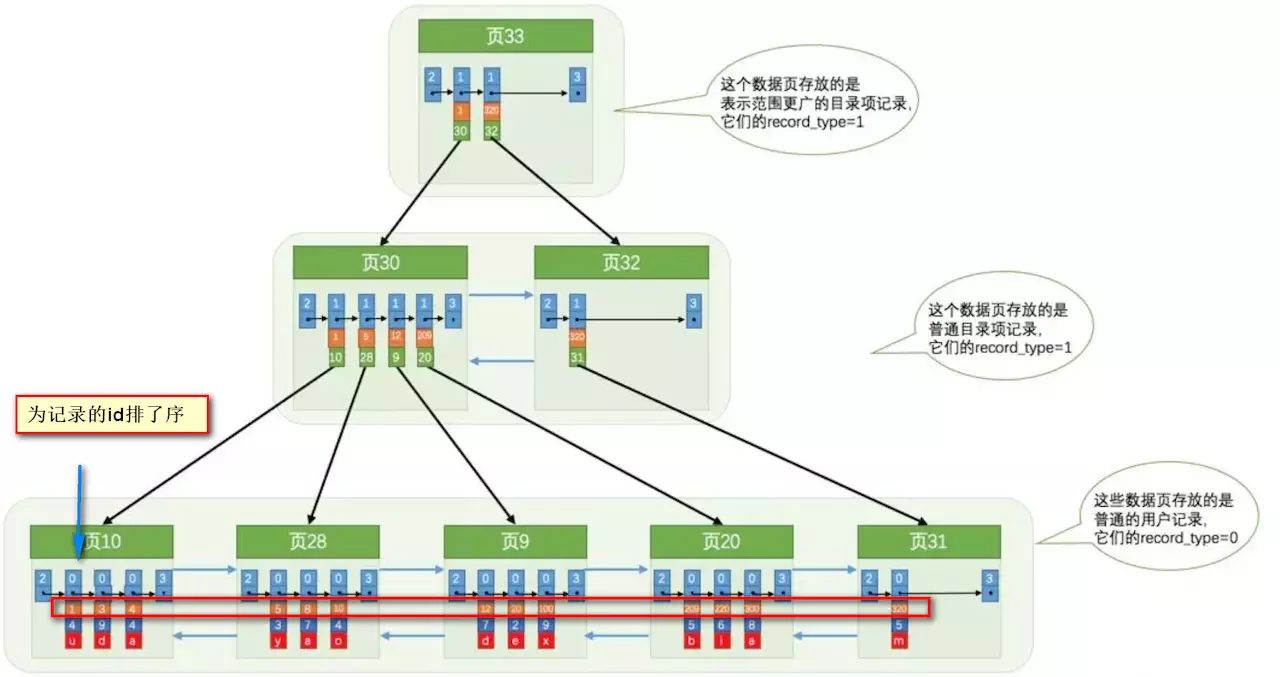
要找到id為8的記錄簡要步驟:
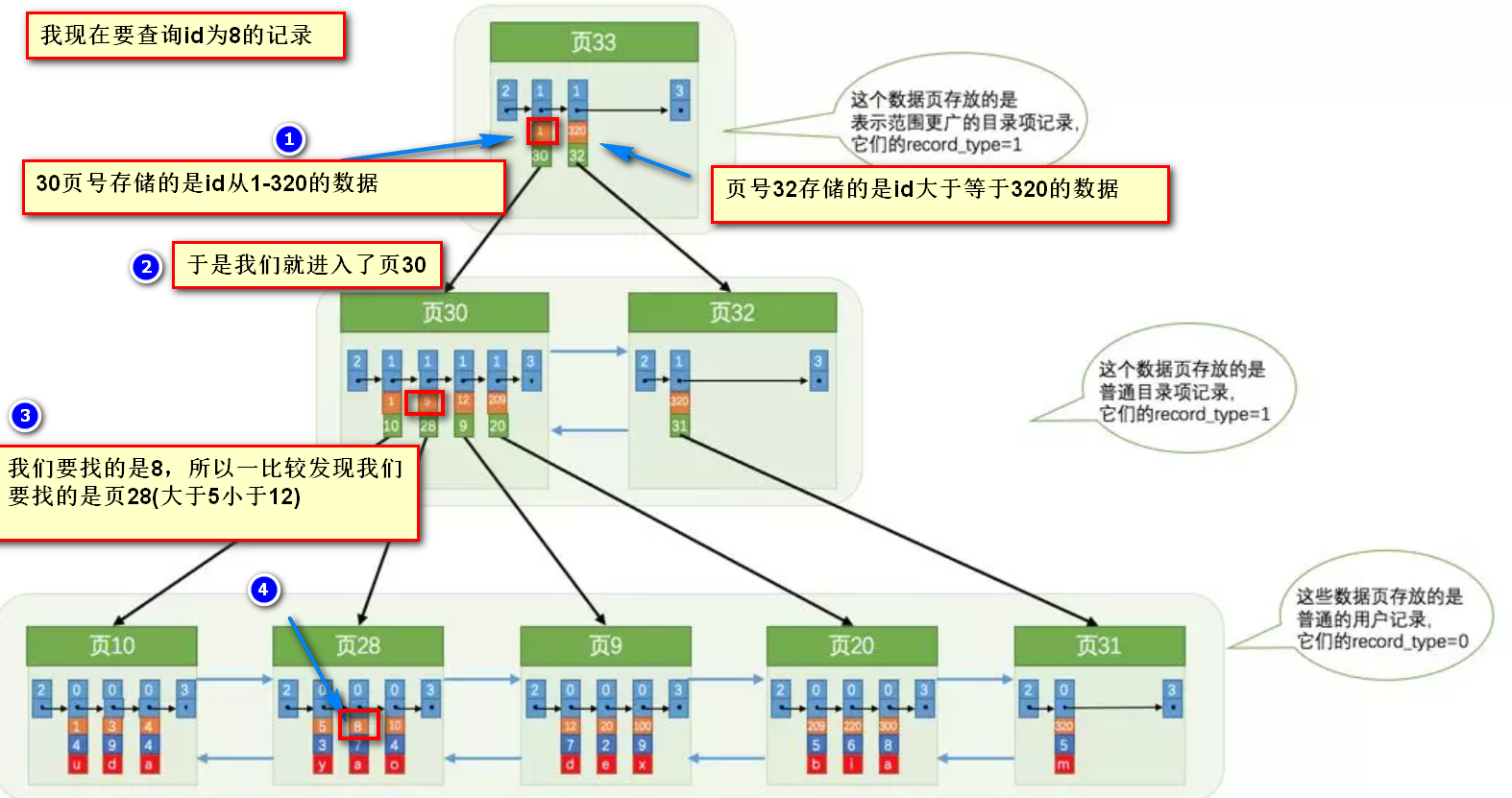
很明顯的是:沒有用索引我們是需要遍歷雙向鏈表來定位對應的頁,現在通過 “目錄” 就可以很快地定位到對應的頁上了!(二分查找,時間復雜度近似為O(logn))
其實底層結構就是B+樹,B+樹作為樹的一種實現,能夠讓我們很快地查找出對應的記錄。
關于索引其他重要的內容補充
最左前綴原則
MySQL中的索引可以以一定順序引用多列,這種索引叫作聯合索引。如User表的name和city加聯合索引就是(name,city),而最左前綴原則指的是,如果查詢的時候查詢條件精確匹配索引的左邊連續一列或幾列,則此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 無法命中索引
這里需要注意的是,查詢的時候如果兩個條件都用上了,但是順序不同,如 city= xx and name =xx,那么現在的查詢引擎會自動優化為匹配聯合索引的順序,這樣是能夠命中索引的。
由于最左前綴原則,在創建聯合索引時,索引字段的順序需要考慮字段值去重之后的個數,較多的放前面。ORDER BY子句也遵循此規則。
注意避免冗余索引
冗余索引指的是索引的功能相同,能夠命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )這兩個索引就是冗余索引,能夠命中后者的查詢肯定是能夠命中前者的 在大多數情況下,都應該盡量擴展已有的索引而不是創建新索引。
MySQLS.7 版本后,可以通過查詢 sys 庫的 schema_redundant_indexes 表來查看冗余索引
Mysql如何為表字段添加索引???
1.添加PRIMARY KEY(主鍵索引)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.添加FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.添加多列索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )9. 存儲引擎
MySQL常見的兩種存儲引擎:MyISAM與InnoDB的愛恨情仇
MyISAM特點
- 不支持行鎖(MyISAM只有表鎖),讀取時對需要讀到的所有表加鎖,寫入時則對表加排他鎖;
- 不支持事務
- 不支持外鍵
- 不支持崩潰后的安全恢復
- 在表有讀取查詢的同時,支持往表中插入新紀錄
- 支持BLOB和TEXT的前500個字符索引,支持全文索引
- 支持延遲更新索引,極大地提升了寫入性能
- 對于不會進行修改的表,支持 壓縮表 ,極大地減少了磁盤空間的占用
InnoDB特點
- 支持行鎖,采用MVCC來支持高并發,有可能死鎖
- 支持事務
- 支持外鍵
- 支持崩潰后的安全恢復
- 不支持全文索引
MyISAM是MySQL的默認數據庫引擎(5.5版之前)由早期的 ISAM (Indexed Sequential Access Method:有索引的順序訪問方法)所改良。雖然性能極佳,而且提供了大量的特性,包括全文索引、壓縮、空間函數等,但MyISAM不支持事務和行級鎖,而且最大的缺陷就是崩潰后無法安全恢復。5.5版本之后,MySQL引入了InnoDB(另一種數據庫引擎)。
大多數時候我們使用的都是InnoDB存儲引擎,但是在某些情況下使用 MyISAM 也是合適的,比如讀密集的情況下。(如果你不介意 MyISAM 崩潰回復問題的話)。
10. 字符集及校對規則
字符集指的是一種從二進制編碼到某類字符符號的映射。校對規則則是指某種字符集下的排序規則。Mysql中每一種字符集都會對應一系列的校對規則。
Mysql采用的是類似繼承的方式指定字符集的默認值,每個數據庫以及每張數據表都有自己的默認值,他們逐層繼承。比如:某個庫中所有表的默認字符集將是該數據庫所指定的字符集(這些表在沒有指定字符集的情況下,才會采用默認字符集) PS:整理自《Java工程師修煉之道》
詳細內容可以參考: MySQL字符集及校對規則的理解
11. 索引相關的內容(數據庫使用中非常關鍵的技術,合理正確的使用索引可以大大提高數據庫的查詢性能)
Mysql索引使用的數據結構主要有BTree索引 和 哈希索引 。對于哈希索引來說,底層的數據結構就是哈希表,因此在絕大多數需求為單條記錄查詢的時候,可以選擇哈希索引,查詢性能最快;其余大部分場景,建議選擇BTree索引。
Mysql的BTree索引使用的是B數中的B+Tree,但對于主要的兩種存儲引擎MyISAM和InnoDB的實現方式是不同的。
MyISAM: B+Tree葉節點的data域存放的是數據記錄的地址。在索引檢索的時候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其 data 域的值,然后以 data 域的值為地址讀取相應的數據記錄。這被稱為“非聚簇索引”。
InnoDB: 其數據文件本身就是索引文件。相比MyISAM,索引文件和數據文件是分離的,其表數據文件本身就是按B+Tree組織的一個索引結構,樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。這被稱為“聚簇索引(或聚集索引)”。而其余的索引都作為輔助索引,輔助索引的data域存儲相應記錄主鍵的值而不是地址,這也是和MyISAM不同的地方。在根據主索引搜索時,直接找到key所在的節點即可取出數據;在根據輔助索引查找時,則需要先取出主鍵的值,再走一遍主索引。 因此,在設計表的時候,不建議使用過長的字段作為主鍵,也不建議使用非單調的字段作為主鍵,這樣會造成主索引頻繁分裂。 PS:整理自《Java工程師修煉之道》
詳細內容可以參考:
12. 查詢緩存的使用
my.cnf加入以下配置,重啟Mysql開啟查詢緩存
query_cache_type=1
query_cache_size=600000
Mysql執行以下命令也可以開啟查詢緩存
set global query_cache_type=1;
set global query_cache_size=600000;
如上,開啟查詢緩存后在同樣的查詢條件以及數據情況下,會直接在緩存中返回結果。這里的查詢條件包括查詢本身、當前要查詢的數據庫、客戶端協議版本號等一些可能影響結果的信息。因此任何兩個查詢在任何字符上的不同都會導致緩存不命中。此外,如果查詢中包含任何用戶自定義函數、存儲函數、用戶變量、臨時表、Mysql庫中的系統表,其查詢結果也不會被緩存。
緩存建立之后,Mysql的查詢緩存系統會跟蹤查詢中涉及的每張表,如果這些表(數據或結構)發生變化,那么和這張表相關的所有緩存數據都將失效。
緩存雖然能夠提升數據庫的查詢性能,但是緩存同時也帶來了額外的開銷,每次查詢后都要做一次緩存操作,失效后還要銷毀。 因此,開啟緩存查詢要謹慎,尤其對于寫密集的應用來說更是如此。如果開啟,要注意合理控制緩存空間大小,一般來說其大小設置為幾十MB比較合適。此外,還可以通過sql_cache和sql_no_cache來控制某個查詢語句是否需要緩存:
select sql_no_cache count(*) from usr;
13. 事務機制
-
關系性數據庫需要遵循ACID規則,具體內容如下:
- 原子性: 事務是最小的執行單位,不允許分割。事務的原子性確保動作要么全部完成,要么完全不起作用;
- 一致性: 執行事務前后,數據庫從一個一致性狀態轉換到另一個一致性狀態。
- 隔離性: 并發訪問數據庫時,一個用戶的事物不被其他事務所干擾,各并發事務之間數據庫是獨立的;
- 持久性: 一個事務被提交之后。它對數據庫中數據的改變是持久的,即使數據庫 發生故障也不應該對其有任何影響。
為了達到上述事務特性,數據庫定義了幾種不同的事務隔離級別:
-
READ_UNCOMMITTED(讀取未提交數據): 最低的隔離級別,允許讀取尚未提交的數據變更,可能會導致臟讀、幻讀或不可重復讀
-
READ_COMMITTED(讀取提交數據): 允許讀取并發事務已經提交的數據,可以阻止臟讀,但是幻讀或不可重復讀仍有可能發生
-
REPEATABLE_READ(可重復讀): 對同一字段的多次讀取結果都是一致的,除非數據是被本身事務自己所修改,可以阻止臟讀和不可重復讀,但幻讀仍有可能發生。
-
SERIALIZABLE(串行): 最高的隔離級別,完全服從ACID的隔離級別。所有的事務依次逐個執行,這樣事務之間就完全不可能產生干擾,也就是說,該級別可以防止臟讀、不可重復讀以及幻讀。但是這將嚴重影響程序的性能。通常情況下也不會用到該級別。
這里需要注意的是:Mysql 默認采用的 REPEATABLE_READ隔離級別 Oracle 默認采用的 READ_COMMITTED隔離級別.
事務隔離機制的實現基于鎖機制和并發調度。其中并發調度使用的是MVCC(多版本并發控制),通過行的創建時間和行的過期時間來支持并發一致性讀和回滾等特性。
詳細內容可以參考: 可能是最漂亮的Spring事務管理詳解
14. 鎖機制與InnoDB鎖算法
MyISAM和InnoDB存儲引擎使用的鎖:
- MyISAM采用表級鎖(table-level locking)。
- InnoDB支持行級鎖(row-level locking)和表級鎖,默認為行級鎖
表級鎖和行級鎖對比:
- 表級鎖: Mysql中鎖定 粒度最大 的一種鎖,對當前操作的整張表加鎖,實現簡單,資源消耗也比較少,加鎖快,不會出現死鎖。其鎖定粒度最大,觸發鎖沖突的概率最高,并發度最低,MyISAM和 InnoDB引擎都支持表級鎖。
- 行級鎖: Mysql中鎖定 粒度最小 的一種鎖,只針對當前操作的行進行加鎖。 行級鎖能大大減少數據庫操作的沖突。其加鎖粒度最小,并發度高,但加鎖的開銷也最大,加鎖慢,會出現死鎖。
詳細內容可以參考: Mysql鎖機制簡單了解一下
InnoDB存儲引擎的鎖的算法有三種:
- Record lock:單個行記錄上的鎖
- Gap lock:間隙鎖,鎖定一個范圍,不包括記錄本身
- Next-key lock:record+gap 鎖定一個范圍,包含記錄本身
相關知識點:
- innodb對于行的查詢使用next-key lock
- Next-locking keying為了解決Phantom Problem幻讀問題
- 當查詢的索引含有唯一屬性時,將next-key lock降級為record key
- Gap鎖設計的目的是為了阻止多個事務將記錄插入到同一范圍內,而這會導致幻讀問題的產生
- 有兩種方式顯式關閉gap鎖:(除了外鍵約束和唯一性檢查外,其余情況僅使用record lock) A. 將事務隔離級別設置為RC B. 將參數innodb_locks_unsafe_for_binlog設置為1
15.大表優化
當MySQL單表記錄數過大時,數據庫的CRUD性能會明顯下降,一些常見的優化措施如下:
-
限定數據的范圍: 務必禁止不帶任何限制數據范圍條件的查詢語句。比如:我們當用戶在查詢訂單歷史的時候,我們可以控制在一個月的范圍內;
-
讀/寫分離: 經典的數據庫拆分方案,主庫負責寫,從庫負責讀;
-
垂直分區:
根據數據庫里面數據表的相關性進行拆分。 例如,用戶表中既有用戶的登錄信息又有用戶的基本信息,可以將用戶表拆分成兩個單獨的表,甚至放到單獨的庫做分庫。
簡單來說垂直拆分是指數據表列的拆分,把一張列比較多的表拆分為多張表。 如下圖所示,這樣來說大家應該就更容易理解了。
垂直拆分的優點: 可以使得列數據變小,在查詢時減少讀取的Block數,減少I/O次數。此外,垂直分區可以簡化表的結構,易于維護。
垂直拆分的缺點: 主鍵會出現冗余,需要管理冗余列,并會引起Join操作,可以通過在應用層進行Join來解決。此外,垂直分區會讓事務變得更加復雜;
-
5. 水平分區:
保持數據表結構不變,通過某種策略存儲數據分片。這樣每一片數據分散到不同的表或者庫中,達到了分布式的目的。 水平拆分可以支撐非常大的數據量。
水平拆分是指數據表行的拆分,表的行數超過200萬行時,就會變慢,這時可以把一張的表的數據拆成多張表來存放。舉個例子:我們可以將用戶信息表拆分成多個用戶信息表,這樣就可以避免單一表數據量過大對性能造成影響。
水平拆分可以支持非常大的數據量。需要注意的一點是:分表僅僅是解決了單一表數據過大的問題,但由于表的數據還是在同一臺機器上,其實對于提升MySQL并發能力沒有什么意義,所以 水平拆分最好分庫 。
水平拆分優點:水平拆分能夠 支持非常大的數據量存儲,應用端改造也少,水平拆分缺點:分片事務難以解決 ,跨節點Join性能較差,邏輯復雜。《Java工程師修煉之道》的作者推薦 盡量不要對數據進行分片,因為拆分會帶來邏輯、部署、運維的各種復雜度 ,一般的數據表在優化得當的情況下支撐千萬以下的數據量是沒有太大問題的。如果實在要分片,盡量選擇客戶端分片架構,這樣可以減少一次和中間件的網絡I/O。
-
下面補充一下數據庫分片的兩種常見方案:
- 客戶端代理: 分片邏輯在應用端,封裝在jar包中,通過修改或者封裝JDBC層來實現。 當當網的 Sharding-JDBC、阿里的TDDL是兩種比較常用的實現。
- 中間件代理: 在應用和數據中間加了一個代理層。分片邏輯統一維護在中間件服務中。 我們現在談的 Mycat 、360的Atlas、網易的DDB等等都是這種架構的實現。
詳細內容可以參考: MySQL大表優化方案
二、Redis
1. 結合項目經驗,說下 redis 應用場景
緩存:合理使用緩存加快數據訪問速度,降低后端數據源壓力
排行榜:按照熱度排名,按照發布時間排行,主要用到列表和有序集合
計數器應用:視頻網站播放數,網站瀏覽數,使用redis計數
社交網絡:贊、踩、粉絲、下拉刷新
消息隊列:發布和訂閱
(1)緩存——熱數據
熱點數據(經常會被查詢,但是不經常被修改或者刪除的數據),首選是使用redis緩存,畢竟強大到冒泡的QPS和極強的穩定性不是所有類似工具都有的,而且相比于memcached還提供了豐富的數據類型可以使用,另外,內存中的數據也提供了AOF和RDB等持久化機制可以選擇,要冷、熱的還是忽冷忽熱的都可選。
結合具體應用需要注意一下:很多人用spring的AOP來構建redis緩存的自動生產和清除,過程可能如下:
-
Select 數據庫前查詢redis,有的話使用redis數據,放棄select 數據庫,沒有的話,select 數據庫,然后將數據插入redis
-
update或者delete數據庫前,查詢redis是否存在該數據,存在的話先刪除redis中數據,然后再update或者delete數據庫中的數據
上面這種操作,如果并發量很小的情況下基本沒問題,但是高并發的情況請注意下面場景:
為了update先刪掉了redis中的該數據,這時候另一個線程執行查詢,發現redis中沒有,瞬間執行了查詢SQL,并且插入到redis中一條數據,回到剛才那個update語句,這個悲催的線程壓根不知道剛才那個該死的select線程犯了一個彌天大錯!于是這個redis中的錯誤數據就永遠的存在了下去,直到下一個update或者delete。
(2)計數器
諸如統計點擊數等應用。由于單線程,可以避免并發問題,保證不會出錯,而且100%毫秒級性能!爽。
命令:INCRBY
當然爽完了,別忘記持久化,畢竟是redis只是存了內存!
(3)隊列
-
相當于消息系統,ActiveMQ,RocketMQ等工具類似,但是個人覺得簡單用一下還行,如果對于數據一致性要求高的話還是用RocketMQ等專業系統。
-
由于redis把數據添加到隊列是返回添加元素在隊列的第幾位,所以可以做判斷用戶是第幾個訪問這種業務
-
隊列不僅可以把并發請求變成串行,并且還可以做隊列或者棧使用
(4)位操作(大數據處理)
用于數據量上億的場景下,例如幾億用戶系統的簽到,去重登錄次數統計,某用戶是否在線狀態等等。
想想一下騰訊10億用戶,要幾個毫秒內查詢到某個用戶是否在線,你能怎么做?千萬別說給每個用戶建立一個key,然后挨個記(你可以算一下需要的內存會很恐怖,而且這種類似的需求很多,騰訊光這個得多花多少錢。。)好吧。這里要用到位操作——使用setbit、getbit、bitcount命令。
原理是:
redis內構建一個足夠長的數組,每個數組元素只能是0和1兩個值,然后這個數組的下標index用來表示我們上面例子里面的用戶id(必須是數字哈),那么很顯然,這個幾億長的大數組就能通過下標和元素值(0和1)來構建一個記憶系統,上面我說的幾個場景也就能夠實現。用到的命令是:setbit、getbit、bitcount
(5)分布式鎖與單線程機制
-
驗證前端的重復請求(可以自由擴展類似情況),可以通過redis進行過濾:每次請求將request Ip、參數、接口等hash作為key存儲redis(冪等性請求),設置多長時間有效期,然后下次請求過來的時候先在redis中檢索有沒有這個key,進而驗證是不是一定時間內過來的重復提交
-
秒殺系統,基于redis是單線程特征,防止出現數據庫“爆破”
-
全局增量ID生成,類似“秒殺”
(6)最新列表
例如新聞列表頁面最新的新聞列表,如果總數量很大的情況下,盡量不要使用select a from A limit 10這種low貨,嘗試redis的 LPUSH命令構建List,一個個順序都塞進去就可以啦。不過萬一內存清掉了咋辦?也簡單,查詢不到存儲key的話,用mysql查詢并且初始化一個List到redis中就好了。
(7)排行榜
誰得分高誰排名往上。命令:ZADD(有續集,sorted set)
參考文章:http://www.rzrgm.cn/NiceCui/p/7794659.html
2. redis 支持數據類型?各有什么特點?
2.1 String(字符串)
string類型是二進制安全的。意思是redis的string可以包含任何數據。比如jpg圖片或者序列化的對象 。string類型是Redis最基本的數據類型,一個redis中字符串value最多可以是512M
對應命令:
set name lgs ex 10 //10秒后過期 px 10000 毫秒過期
setnx name lgs //不存在鍵name時才能設置,返回1設置成功;存在的話失敗0
set age 29 //存在鍵age時直接覆蓋之前的鍵值,返回1成功
場景:如果有多客戶同時執行setnx,只有一個能設置成功,可做分布式鎖
獲值命令:get age //存在則返回value, 不存在返回nil
批量設值:mset country china city beijing
批量獲取:mget country city address //返回china beigjin, address為nil
若沒有mget命令,則要執行n次get命令,從而占用網絡資源影響性能
使用mget=1次網絡請求+redis內部n次查詢,一次性返回所有查詢結果
2.2 Hash(哈希)
Redis hash 是一個鍵值對集合。Redis hash是一個string類型的field和value的映射表,hash特別適合用于存儲對象。類似Java里面的Map<String,Object>
對應命令:
hset key field value
設值:hset user:1 name lgs //成功返回1,失敗返回0
取值:hget user:1 name //返回lgs
刪值:hdel user:1 age //返回刪除的個數
批量設值:hmset user:2 name ll age 28 sex boy //返回OK
批量取值:hmget user:2 name age sex //返回三行:ll 28 boy
判斷field是否存在:hexists user:2 name //若存在返回1,不存在返回0
獲取所有field: hkeys user:2 // 返回name age sex三個field
獲取user:2所有value:hvals user:2 // 返回ll 28 boy
獲取user:2所有field與value:hgetall user:2 //name age sex ll 28 boy值
增加1:
hincrby user:2 age 1 //age+1
hincrbyfloat user:2 age 2 //浮點型加2
2.3 List(列表)
用來存儲多個有序的字符串,一個列表最多可存2的32次方減1個元素
Redis 列表是簡單的字符串列表,按照插入順序排序。你可以添加一個元素導列表的頭部(左邊)或者尾部(右邊),它的底層實際是個鏈表
對應命令:
為有序,可以通過索引下標獲取元素或某個范圍內元素列表, 列表元素可以重復

添加命令:rpush lpush linset
rpush name a b c d //從右向左插入a b c d, 返回值4
lrange name 0 -1 //從左到右獲取列表所有元素 返回 a b c d
lpush fav a b c d//從左向右插入a b c d
linsert fav before b r //在b之前插入r, after為之后,使 用lrange fav 0 -1 查看:d c r b a
查找命令:lrange lindex llen
lrange key start end //索引下標特點:從左到右為0到N-1
lindex fav -1 //返回最右末尾a,-2返回b
llen fav //返回當前列表長度 5
刪除命令:lpop rpop lrem ltrim
lpop fav //把最左邊的第一個元素d刪除
rpop fav //把最右邊的元素a刪除
lrem key count value//刪除指定元素
如:lpush test b b b b b j x z //鍵test放入z x j b b b b b
Lrange test 0 -1 //查詢結果為 z x j b b b b b
lrem test 4 b //從左右開始刪除b的元素,刪除4個,
若lrem test 8 b, 刪除8個b, 但只有5個全部刪除
lrange test 0 -1 //刪除后的結果為 b j x z
lrem test 0 b //檢索所有b全部刪除 j x z
lpush user b b b b b j x z //鍵user從左到右放入 z x j b b b b b
ltrim user 1 3 //只保留從第2到第4的元素x j b,其它全刪
lrange user 0 -1 //查詢結果為 x j b, 其它已全被刪掉
修改命令:lset
lpush user01 z y x //鍵user01從左到右放入x y z
lset user01 2 java // 把第3個元素z替換成java
lrange user01 0 -1 //查詢結果為 x y java
阻塞命令:blpop brpop
2.4 Set(集合)
Redis的Set是string類型的無序集合。它是通過HashTable實現的,
保存多元素,與列表不一樣的是不允許有重復元素,且集合是無序,一個集合最多可存2的32次方減1個元素,除了支持增刪改查,還支持集合交集、并集、差集;
對應命令:
元素操作:exists sadd smembers srem scard spop
exists user //檢查user鍵值是否存在
sadd user a b c//向user插入3個元素,返回3
sadd user a b //若再加入相同的元素,則重復無效,返回0
smembers user //獲取user的所有元素,返回結果無序
srem user a //返回1,刪除a元素
scard user //返回2,計算元素個數
sismember user a //判斷元素是否在集合存在,存在返回1,不存在0
srandmember user 2 //隨機返回2個元素,2為元素個數
spop user 2 //隨機返回2個元素a b,并將a b從集合中刪除
smembers user //此時已沒有a b, 只有c
集合交集:sinter
sadd user:1 zhangsan 24 girl
sadd user:2 james 24 boy//初始化兩個集合
sinter user:1 user:2 //求兩集合交集, 此時返回24
sadd user:3 wang 24 girl //新增第三個元素
sinter user:1 user:2 user:3 //求三個集合的交集,此時返回24
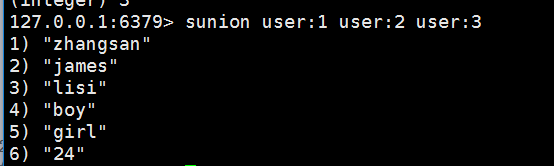
集合的并集(集合合并去重):sunion
sunion user:1 user:2 user:3 //三集合合并(并集),去重24
集合差集:sdiff
diff user:1 user:2//1和2差集,(zhangsan 24 girl)-(james 24 boy)=zhangsan girl
將集合的結果另存到隊列:sinterstore sunionstore sdiffstore
將交集(jj)、并集(bj)、差集(cj)的結果保存:
sinterstore user_jj user:1 user:2 //將user:1 user:2的交集保存到user_jj
sunionstore user_bj user:1 user:2 //將user:1 user:2的(并)合集保存user_bj
sdiffstore user_cj user:1 user:2 //將user:1-user:2的差集保存user_cj
smemebers user_cj // 返回zhangsan girl
2.5 zset(sorted set:有序集合)
Redis zset 和 set 一樣也是string類型元素的集合,且不允許重復的成員。不同的是每個元素都會關聯一個double類型的分數。redis正是通過分數來為集合中的成員進行從小到大的排序。zset的成員是唯一的,但分數(score)卻可以重復。
對應命令:
添加命令
zadd key score member [score member......]
zadd user:zan 200 james //james的點贊數1, 返回操作成功的條數1
zadd user:zan 200 james 120 mike 100 lee// 返回3
zadd test:1 nx 100 james //鍵test:1必須不存在,主用于添加
zadd test:1 xx incr 200 james //鍵test:1必須存在,主用于修改,此時為300
zadd test:1 xx ch incr -299 james //返回操作結果1,300-299=1
查看命令
zrange test:1 0 -1 withscores //查看點贊(分數)與成員名
zcard test:1 //計算成員個數, 返回1
查點贊數
zadd test:2 nx 100 james //新增一個集合
zscore test:2 james //查看james的點贊數(分數),返回100
排名:
zadd user:3 200 james 120 mike 100 lee//先插入數據
zrange user:3 0 -1 withscores //查看分數與成員
zrank user:3 james //返回名次:第3名返回2,從0開始到2,共3名
zrevrank user:3 james //返回0, 反排序,點贊數越高,排名越前
刪除命令
刪除成員:
zrem user:3 jame mike //返回成功刪除2個成員,還剩lee
增加分數:
zincrby user:3 10 lee //成員lee的分數加10
zadd user:3 xx incr 10 lee //和上面效果一樣
返回指定排名范圍的分數與成員
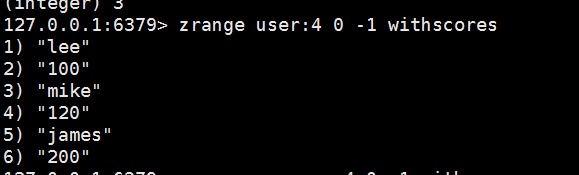
zadd user:4 200 james 120 mike 100 lee//先插入數據
zrange user:4 0 -1 withscores //返回結果如下圖
3. 有什么持久化策略?各有什么特點
redis持久化策略:
redis支持RDB和AOF兩種持久化機制,持久化可以避免因進程退出而造成數據丟失
特點:
1. RDB持久化
RDB持久化把當前進程數據生成快照(.rdb)文件保存到硬盤的過程,有手動觸發和自動觸發
手動觸發有save和bgsave兩命令
save命令:阻塞當前Redis,直到RDB持久化過程完成為止,若內存實例比較大會造成長時間阻塞,線上環境不建議用它
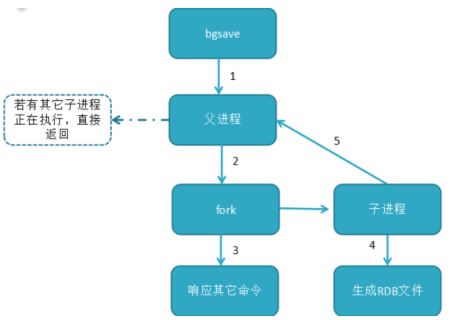
bgsave命令:redis進程執行fork操作創建子線程,由子線程完成持久化,阻塞時間很短(微秒級),是save的優化,在執行redis-cli shutdown關閉redis服務時,如果沒有開啟AOF持久化,自動執行bgsave;
顯然bgsave是對save的優化。
bgsave運行流程
RDB文件的操作
命令:config set dir /usr/local //設置rdb文件保存路徑
備份:bgsave //將dump.rdb保存到usr/local下
恢復:將dump.rdb放到redis安裝目錄與redis.conf同級目錄,重啟redis即可
優點:1. 壓縮后的二進制文文件適用于備份、全量復制,用于災難恢復
2. 加載RDB恢復數據遠快于AOF方式
缺點:1. 無法做到實時持久化,每次都要創建子進程,頻繁操作成本過高
2. 保存后的二進制文件,存在老版本不兼容新版本rdb文件的問題
2. AOF持久化
針對RDB不適合實時持久化,redis提供了AOF持久化方式來解決
開啟:redis.conf設置appendonly yes (默認不開啟,為no)
默認文件名:appendfilename "appendonly.aof"
流程說明:
1,所有的寫入命令(set hset)會append追加到aof_buf緩沖區中
2,AOF緩沖區向硬盤做sync同步生成AOF文件
3,隨著AOF文件越來越大,需定期對AOF文件rewrite重寫,達到壓縮
4,當redis服務重啟,可load加載AOF文件進行恢復
AOF持久化流程:命令寫入(append),文件同步(sync),文件重寫(rewrite),重啟加載(load)
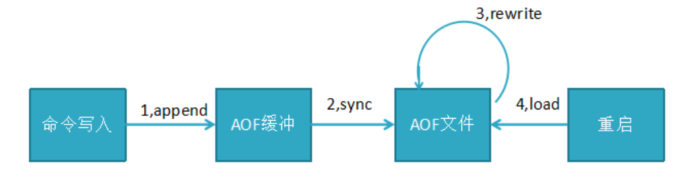
AOF配置詳解:
appendonly yes //啟用aof持久化方式
# appendfsync always //每收到寫命令就立即強制寫入磁盤,最慢的,但是保證完全的持久化,不推薦使用
appendfsync everysec //每秒強制寫入磁盤一次,性能和持久化方面做了折中,推薦
# appendfsync no //完全依賴os,性能最好,持久化沒保證(操作系統自身的同步)
no-appendfsync-on-rewrite yes //正在導出rdb快照的過程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 //aof文件大小比起上次重寫時的大小,增長率100%時,重寫
auto-aof-rewrite-min-size 64mb //aof文件,至少超過64M時,重寫
如何從AOF恢復?
1. 設置appendonly yes;
2. 將appendonly.aof放到dir參數指定的目錄;
3. 啟動Redis,Redis會自動加載appendonly.aof文件。
redis重啟時恢復加載AOF與RDB順序及流程:
1,當AOF和RDB文件同時存在時,優先加載AOF
2,若關閉了AOF,加載RDB文件
3,加載AOF/RDB成功,redis重啟成功
4,AOF/RDB存在錯誤,redis啟動失敗并打印錯誤信息
Redis 4.0 對于持久化機制的優化
Redis 4.0 開始支持 RDB 和 AOF 的混合持久化(默認關閉,可以通過配置項 aof-use-rdb-preamble 開啟)。
如果把混合持久化打開,AOF 重寫的時候就直接把 RDB 的內容寫到 AOF 文件開頭。這樣做的好處是可以結合 RDB 和 AOF 的優點, 快速加載同時避免丟失過多的數據。當然缺點也是有的, AOF 里面的 RDB 部分是壓縮格式不再是 AOF 格式,可讀性較差。
5. redis主從復制
主從復制:主節點負責寫數據,從節點負責讀數據,主節點定期把數據同步到從節點保證數據的一致性
a,配置主從復制方式一、新增redis6380.conf, 加入 slaveof 192.168.152.128 6379, 在6379啟動完后再啟6380,完成配置;
b,配置主從復制方式二、redis-server --slaveof 192.168.152.128 6379 臨時生效
e,從節點建議用只讀模式slave-read-only=yes, 若從節點修改數據,主從數據不一致
主從復制原理
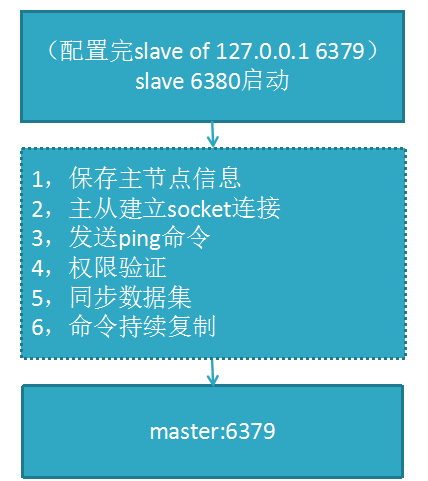
數據復制
redis 2.8版本以上使用psync命令完成同步,過程分“全量”與“部分”復制
全量復制:一般用于初次復制場景(第一次建立SLAVE后全量)
部分復制:網絡出現問題,從節點再次連接主節點時,主節點補發缺少的數據,每次數據增量同步
心跳:主從有長連接心跳,主節點默認每10S向從節點發ping命令,repl-ping-slave-period控制發送頻率
主從的缺點
a)主從復制,若主節點出現問題,則不能提供服務,需要人工修改配置將從變主
b)主從復制主節點的寫能力單機,能力有限
c)單機節點的存儲能力也有限
6. 介紹下哨兵機制
為什么要有哨兵機制?
哨兵機制的出現是為了解決主從復制的缺點的
redis sentinel是一個分布式架構,其中包含了若干個sentinal節點和Redis節點,每個sentinel節點會對數據節點和sentinel節點進行監控,當它發現節點不可達是,會對節點做下線標識。如果大部分sentinal節點認為主節點不可達,sentinal節點之間會進行“協商” ,選舉出來一個sentinal節點完成故障轉移,并同時把這個故障通知到應用方;
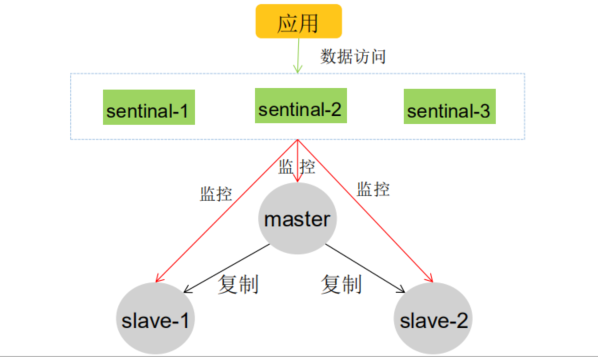
參考文章:
Redis系列八:redis主從復制和哨兵 http://www.rzrgm.cn/leeSmall/p/8398401.html
領導者哨兵選舉流程
a)每個在線的哨兵節點都可以成為領導者,當它確認(比如哨兵3)主節點下線時,會向其它哨兵發is-master-down-by-addr命令,征求判斷并要求將自己設置為領導者,由領導者處理故障轉移;
b)當其它哨兵收到此命令時,可以同意或者拒絕它成為領導者;
c)如果哨兵3發現自己在選舉的票數大于等于num(sentinels)/2+1時,將成為領導者,如果沒有超過,繼續選舉…………

7. 介紹 redis 集群方案?以及其原理
Redis集群方案:
RedisCluster是redis的分布式解決方案,在3.0版本后推出的方案,有效地解決了Redis分布式的需求,當一個服務掛了可以快速的切換到另外一個服務,當遇到單機內存、并發等瓶頸時,可使用此方案來解決這些問題
原理:
一個 redis 集群包含 16384 個哈希槽(hash slot),數據庫中的每個數據都屬于這16384個哈希槽中的一個。集群使用公式(CRC16[key]&16383)函數來計算鍵 key 屬于哪個槽。集群中的每一個節點負責處理一部分哈希槽。
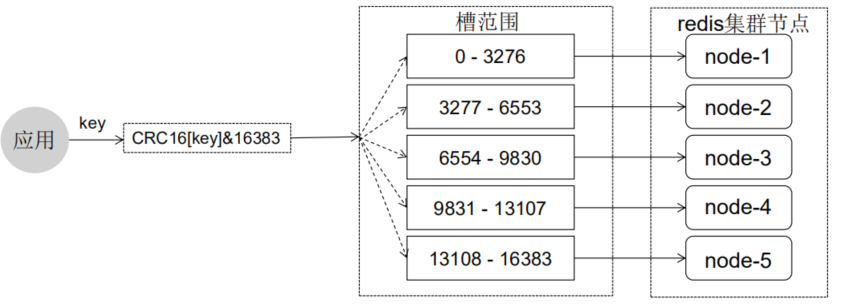
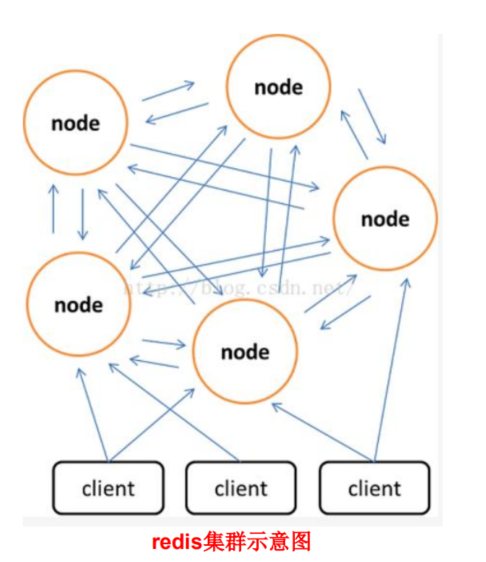
參考文章:
Redis系列九:redis集群高可用
8. redis能做讀寫分離嗎?同步策略是怎么實現的?
redis能做讀寫分離嗎?
redis提供了主從復制和哨兵機制來提高redis服務的健壯性和高可用,但是從嚴格意義上來講,redis并沒有實現讀寫分離,主從復制架構中,主節點用于響應讀寫請求,從節點用于數據備份,如果需要實現讀從從節點讀,應用需要對客戶端進行改造;但在真實場景下一般不需要做此方案,讀寫分離主要應用在磁盤IO比較大的場景,而redis是緩存級別的
同步策略:
redis 2.8版本以上使用psync命令完成同步,過程分“全量”與“部分”復制
a) 全量復制:一般用于初次復制場景(第一次建立SLAVE后全量)
b) 部分復制:網絡出現問題,從節點再次連主節點時,主節點補發缺少的數據,每次數據增量同步
9. redis 簡介
簡單來說 redis 就是一個數據庫,不過與傳統數據庫不同的是 redis 的數據是存在內存中的,所以讀寫速度非常快,因此 redis 被廣泛應用于緩存方向。
另外,redis 也經常用來做分布式鎖。redis 提供了多種數據類型來支持不同的業務場景。除此之外,redis 支持事務 、持久化、LUA腳本、LRU驅動事件、多種集群方案。
10. 為什么要用 redis/為什么要用緩存
主要從“高性能”和“高并發”這兩點來看待這個問題。
高性能:
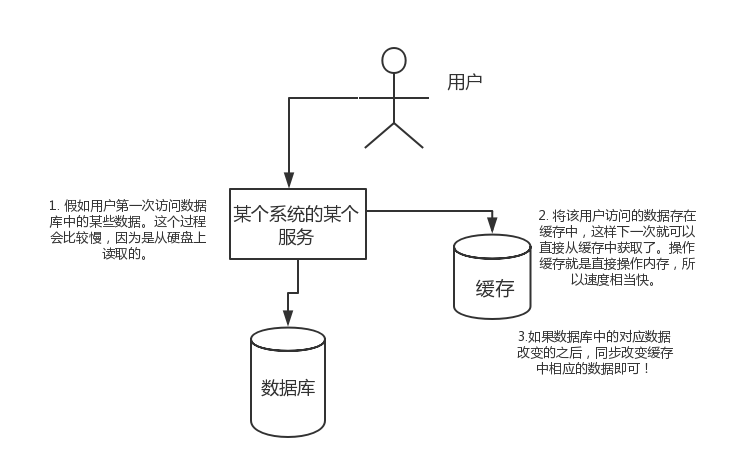
假如用戶第一次訪問數據庫中的某些數據。這個過程會比較慢,因為是從硬盤上讀取的。將該用戶訪問的數據存在數緩存中,這樣下一次再訪問這些數據的時候就可以直接從緩存中獲取了。操作緩存就是直接操作內存,所以速度相當快。如果數據庫中的對應數據改變的之后,同步改變緩存中相應的數據即可!
高并發:
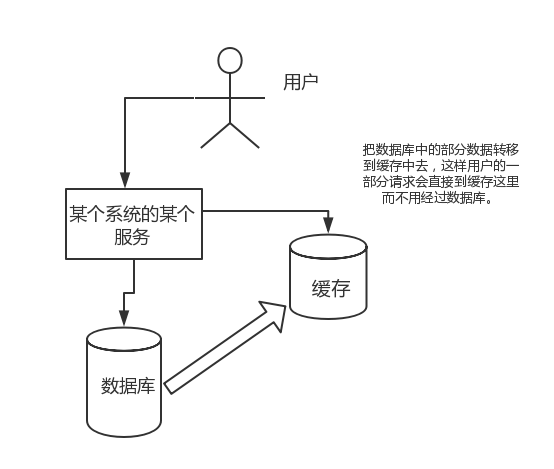
直接操作緩存能夠承受的請求是遠遠大于直接訪問數據庫的,所以我們可以考慮把數據庫中的部分數據轉移到緩存中去,這樣用戶的一部分請求會直接到緩存這里而不用經過數據庫。
11. 為什么要用 redis 而不用 map/guava 做緩存?
緩存分為本地緩存和分布式緩存。以 Java 為例,使用自帶的 map 或者 guava 實現的是本地緩存,最主要的特點是輕量以及快速,生命周期隨著 jvm 的銷毀而結束,并且在多實例的情況下,每個實例都需要各自保存一份緩存,緩存不具有一致性。
使用 redis 或 memcached 之類的稱為分布式緩存,在多實例的情況下,各實例共用一份緩存數據,緩存具有一致性。缺點是需要保持 redis 或 memcached服務的高可用,整個程序架構上較為復雜。
12. redis 和 memcached 的區別
對于 redis 和 memcached 我總結了下面四點。現在公司一般都是用 redis 來實現緩存,而且 redis 自身也越來越強大了!
- redis支持更豐富的數據類型(支持更復雜的應用場景):Redis不僅僅支持簡單的k/v類型的數據,同時還提供list,set,zset,hash等數據結構的存儲。memcache支持簡單的數據類型,String。
- Redis支持數據的持久化,可以將內存中的數據保持在磁盤中,重啟的時候可以再次加載進行使用,而Memecache把數據全部存在內存之中。
- 集群模式:memcached沒有原生的集群模式,需要依靠客戶端來實現往集群中分片寫入數據;但是 redis 目前是原生支持 cluster 模式的.
- Memcached是多線程,非阻塞IO復用的網絡模型;Redis使用單線程的多路 IO 復用模型。
13. redis 常見數據結構以及使用場景分析
1.String
常用命令: set,get,decr,incr,mget 等。
String數據結構是簡單的key-value類型,value其實不僅可以是String,也可以是數字。
使用場景:常規key-value緩存應用; 常規計數:微博數,粉絲數等。
2.Hash
常用命令: hget,hset,hgetall 等。
hash 是一個 string 類型的 field 和 value 的映射表,hash 特別適合用于存儲對象,后續操作的時候,你可以直接僅僅修改這個對象中的某個字段的值。
使用場景:比如我們可以 hash 數據結構來存儲用戶信息,商品信息等等。比如下面我就用 hash 類型存放了我本人的一些信息:
key=JavaUser293847
value={
“id”: 1,
“name”: “SnailClimb”,
“age”: 22,
“location”: “Wuhan, Hubei”
}3.List
常用命令: lpush,rpush,lpop,rpop,lrange等
list 就是鏈表,Redis list 的應用場景非常多,也是Redis最重要的數據結構之一。
使用場景:
比如微博的關注列表,粉絲列表,消息列表等功能都可以用Redis的 list 結構來實現。
Redis list 的實現為一個雙向鏈表,即可以支持反向查找和遍歷,更方便操作,不過帶來了部分額外的內存開銷。
另外可以通過 lrange 命令,就是從某個元素開始讀取多少個元素,可以基于 list 實現分頁查詢,這個很棒的一個功能,基于 redis 實現簡單的高性能分頁,可以做類似微博那種下拉不斷分頁的東西(一頁一頁的往下走),性能高。
4.Set
常用命令: sadd,spop,smembers,sunion 等
set 對外提供的功能與list類似是一個列表的功能,特殊之處在于 set 是可以自動去重的。
使用場景:
當你需要存儲一個列表數據,又不希望出現重復數據時,set是一個很好的選擇,并且set提供了判斷某個成員是否在一個set集合內的重要接口,這個也是list所不能提供的。可以基于 set 輕易實現交集、并集、差集的操作。
比如:在微博應用中,可以將一個用戶所有的關注人存在一個集合中,將其所有粉絲存在一個集合。Redis可以非常方便的實現如共同關注、共同粉絲、共同喜好等功能。這個過程也就是求交集的過程,具體命令如下:
sinterstore key1 key2 key3 將交集存在key1內5.Sorted Set
常用命令: zadd,zrange,zrem,zcard等
和set相比,sorted set增加了一個權重參數score,使得集合中的元素能夠按score進行有序排列。
使用場景:
舉例: 在直播系統中,實時排行信息包含直播間在線用戶列表,各種禮物排行榜,彈幕消息(可以理解為按消息維度的消息排行榜)等信息,適合使用 Redis 中的 Sorted Set 結構進行存儲。
14. redis 設置過期時間
Redis中有個設置時間過期的功能,即對存儲在 redis 數據庫中的值可以設置一個過期時間。
使用場景:
作為一個緩存數據庫,這是非常實用的。如我們一般項目中的 token 或者一些登錄信息,尤其是短信驗證碼都是有時間限制的,按照傳統的數據庫處理方式,一般都是自己判斷過期,這樣無疑會嚴重影響項目性能。
我們 set key 的時候,都可以給一個 expire time,就是過期時間,通過過期時間我們可以指定這個 key 可以存活的時間。
如果假設你設置了一批 key 只能存活1個小時,那么接下來1小時后,redis是怎么對這批key進行刪除的?
定期刪除+惰性刪除:
通過名字大概就能猜出這兩個刪除方式的意思了。
- 定期刪除:redis默認是每隔 100ms 就隨機抽取一些設置了過期時間的key,檢查其是否過期,如果過期就刪除。注意這里是隨機抽取的。為什么要隨機呢?你想一想假如 redis 存了幾十萬個 key ,每隔100ms就遍歷所有的設置過期時間的 key 的話,就會給 CPU 帶來很大的負載!
- 惰性刪除 :定期刪除可能會導致很多過期 key 到了時間并沒有被刪除掉。所以就有了惰性刪除。假如你的過期 key,靠定期刪除沒有被刪除掉,還停留在內存里,除非你的系統去查一下那個 key,才會被redis給刪除掉。這就是所謂的惰性刪除,也是夠懶的哈!
但是僅僅通過設置過期時間還是有問題的。我們想一下:如果定期刪除漏掉了很多過期 key,然后你也沒及時去查,也就沒走惰性刪除,此時會怎么樣?如果大量過期key堆積在內存里,導致redis內存塊耗盡了。怎么解決這個問題呢?
解決:redis 內存淘汰機制。
15. redis 內存淘汰機制(MySQL里有2000w數據,Redis中只存20w的數據,如何保證Redis中的數據都是熱點數據?)
redis 提供 6種數據淘汰策略:
- volatile-lru:從已設置過期時間的數據集(server.db[i].expires)中挑選最近最少使用的數據淘汰
- volatile-ttl:從已設置過期時間的數據集(server.db[i].expires)中挑選將要過期的數據淘汰
- volatile-random:從已設置過期時間的數據集(server.db[i].expires)中任意選擇數據淘汰
- allkeys-lru:當內存不足以容納新寫入數據時,在鍵空間中,移除最近最少使用的key(這個是最常用的)
- allkeys-random:從數據集(server.db[i].dict)中任意選擇數據淘汰
- no-eviction:禁止驅逐數據,也就是說當內存不足以容納新寫入數據時,新寫入操作會報錯。這個應該沒人使用吧!
16. redis 事務
Redis 通過 MULTI、EXEC、WATCH 等命令來實現事務(transaction)功能。事務提供了一種將多個命令請求打包,然后一次性、按順序地執行多個命令的機制,并且在事務執行期間,服務器不會中斷事務而改去執行其他客戶端的命令請求,它會將事務中的所有命令都執行完畢,然后才去處理其他客戶端的命令請求。
在傳統的關系式數據庫中,常常用 ACID 性質來檢驗事務功能的可靠性和安全性。在 Redis 中,事務總是具有原子性(Atomicity)、一致性(Consistency)和隔離性(Isolation),并且當 Redis 運行在某種特定的持久化模式下時,事務也具有持久性(Durability)。
17. 緩存雪崩和緩存穿透問題解決方案
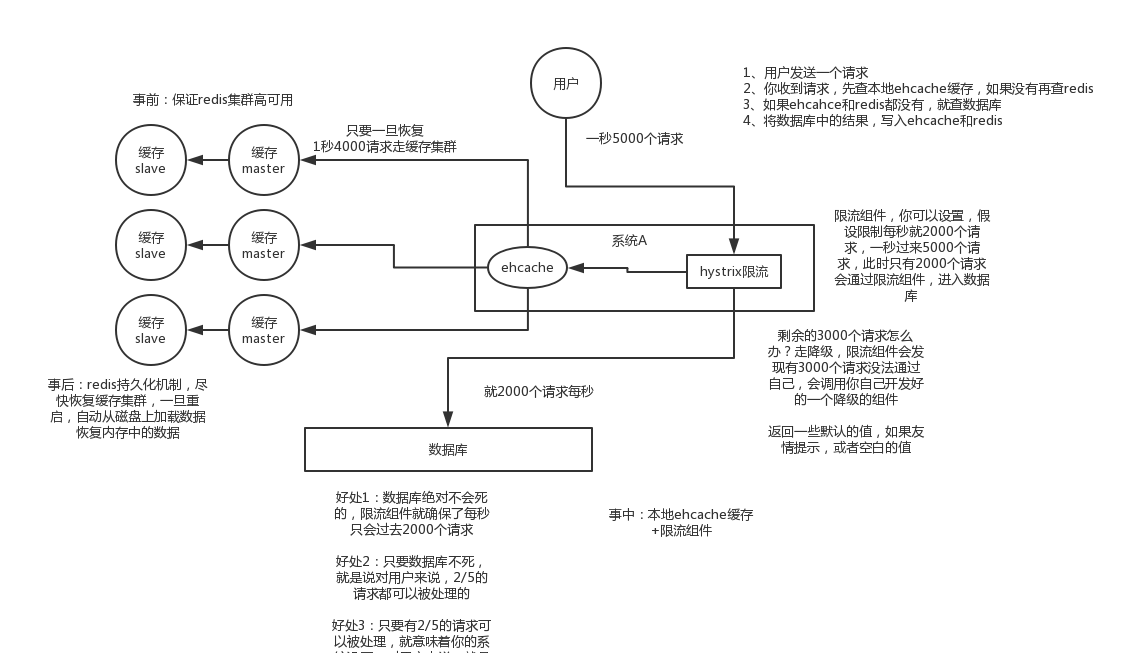
緩存雪崩:
簡介:緩存同一時間大面積的失效,所以,后面的請求都會落到數據庫上,造成數據庫短時間內承受大量請求而崩掉。
解決辦法:(中華石杉老師在他的視頻中提到過,視頻地址在最后一個問題中有提到):
- 事前:盡量保證整個 redis 集群的高可用性,發現機器宕機盡快補上。選擇合適的內存淘汰策略。
- 事中:本地ehcache緩存 + hystrix限流&降級,避免MySQL崩掉
- 事后:利用 redis 持久化機制保存的數據盡快恢復緩存
緩存穿透:
簡介:一般是黑客故意去請求緩存中不存在的數據,導致所有的請求都落到數據庫上,造成數據庫短時間內承受大量請求而崩掉。
解決辦法:
有很多種方法可以有效地解決緩存穿透問題,最常見的則是采用布隆過濾器,將所有可能存在的數據哈希到一個足夠大的bitmap中,一個一定不存在的數據會被 這個bitmap攔截掉,從而避免了對底層存儲系統的查詢壓力。
另外也有一個更為簡單粗暴的方法(我們采用的就是這種),如果一個查詢返回的數據為空(不管是數 據不存在,還是系統故障),我們仍然把這個空結果進行緩存,但它的過期時間會很短,最長不超過五分鐘。
參考:
18. 如何解決 Redis 的并發競爭 Key 問題
Redis 的并發競爭 Key 的問題:多個系統同時對一個 key 進行操作,但是最后執行的順序和我們期望的順序不同,這樣也就導致了結果的不同!
推薦一種方案:分布式鎖(zookeeper 和 redis 都可以實現分布式鎖)。(如果不存在 Redis 的并發競爭 Key 問題,不要使用分布式鎖,這樣會影響性能)
基于zookeeper臨時有序節點可以實現的分布式鎖。大致思想為:每個客戶端對某個方法加鎖時,在zookeeper上的與該方法對應的指定節點的目錄下,生成一個唯一的瞬時有序節點。 判斷是否獲取鎖的方式很簡單,只需要判斷有序節點中序號最小的一個。 當釋放鎖的時候,只需將這個瞬時節點刪除即可。同時,其可以避免服務宕機導致的鎖無法釋放,而產生的死鎖問題。完成業務流程后,刪除對應的子節點釋放鎖。
在實踐中,當然是從以可靠性為主。所以首推Zookeeper。
參考:
19. 如何保證緩存與數據庫雙寫時的數據一致性?
你只要用緩存,就可能會涉及到緩存與數據庫雙存儲雙寫,你只要是雙寫,就一定會有數據一致性的問題,那么你如何解決一致性問題?
解決方案:
讀請求和寫請求串行化,串到一個內存隊列里去,這樣就可以保證一定不會出現不一致的情況
上述方案缺點:一般來說,就是如果你的系統不是嚴格要求緩存+數據庫必須一致性的話,緩存可以稍微的跟數據庫偶爾有不一致的情況,最好不要做這個方案,串行化之后,就會導致系統的吞吐量會大幅度的降低,用比正常情況下多幾倍的機器去支撐線上的一個請求。
參考:
- Java工程師面試突擊第1季(可能是史上最好的Java面試突擊課程)-中華石杉老師。視頻地址見下面!
- 鏈接: https://pan.baidu.com/s/18pp6g1xKVGCfUATf_nMrOA
- 密碼:5i58
參考:
- redis設計與實現(第二版)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號