
【項目復現上新】突破推理瓶頸!LightLLM輕量化部署新范式,打造高性能法律智能體
當前大語言模型(LLM)雖能力突飛猛進,卻難逃“知識靜態滯后”與“專業內容幻覺”兩大痛點。在法律、醫療等強合規場景中,這幾乎是“致命缺陷。而 RAG(檢索增強生成)框架雖能通過融合外部知識庫破解此困,卻在落地時遭遇新瓶頸:有限硬件資源下,如何實現高效、低延遲推理?
在此背景下,以LightLLM 為代表的高效推理框架展現出關鍵價值:其聚焦于輕量化部署與?推理優化?,通過高效內存管理與算子融合技術,顯著提升模型運行速度,并具備良好的擴展性以支持多種模型規模與量化策略。
掌握LightLLM 不僅有助于深入理解?RAG 中檢索與生成的協同機制?,更可培養在資源受限環境下優化、部署AI 系統的核心能力,為教學實驗、中小企業及個人開發者提供穩定、高效的底層支持,具有重要的實踐必要性與應用前景。
今天,我們就以大模型實驗室Lab4AI 為載體,揭秘如何用?LightLLM+LlamaIndex ** ?快速搭建?“??實時檢索+ 精準推理?”的??法律智能體**?,讓AI 在專業場景真正“能用且好用”。
為何選擇LightLLM?
?GitHub 地址?:https://github.com/ModelTC/LightLLM
作為純Python 開發的大語言模型推理與服務框架,?LightLLM 堪稱“集百家之長”?——整合了 FasterTransformer、vLLM、FlashAttention 等開源方案的優勢,卻以“?輕量、易擴、高性能?”站穩腳跟,成為開發者眼中的“高效推理利器”。
其核心特性,每一個都精準戳中部署痛點:
?多進程協同?:輸入文本編碼、語言模型推理、視覺模型推理、輸出解碼等工作異步進行,大幅提高GPU 利用率。
?跨進程請求對象共享?:通過共享內存,實現跨進程請求對象共享,降低進程間通信延遲。
?高效的調度策略?:帶預測的峰值顯存調度策略,最大化GPU 顯存利用率的同時,降低請求逐出。
?高性能的推理后端?:高效的算子實現,多種并行方式支持(張量并行,數據并行以及專家并行),動態kv 緩存,豐富的量化支持(int8,fp8,int4),結構化輸出以及多結果預測。
零配置速玩!LightLLM 的 3 步實戰
GitHub 倉庫提供了 LightLLM 項目的源代碼,并且給出了項目所需的所有 Python 依賴包。除此之外,Conda 環境中還需要安裝 LlamaIndex 庫用于構建基于私有數據的檢索增強生成(RAG)應用,安裝 Streamlit 庫用于快速創建交互式數據可視化網頁應用,安裝 LightLLM 運行所需的計算機視覺處理庫和 WebSocket 通信支持依賴包,安裝 LlamaIndex 框架對 HuggingFace 本地嵌入模型的支持包。
乍一聽,有這么多前期工作需要準備。
您別慌,大模型實驗室Lab4AI 已為你備好全套依賴,直接“拎包上車”體驗 LightLLM的強悍!
這也是大模型實驗室Lab4AI 的優勢和特色:通過低門檻實踐場景+ 算力無縫銜接,形成“算力 + 實驗平臺 + 社區”的深度融合模式,幫助您節省 80% 環境配置時間,讓您專注于創新。
項目指路: https://www.lab4ai.cn/project/detail?utm_source=jssq_bky&id=b417085ae8cd4dd0bef7161c3d583b15&type=project
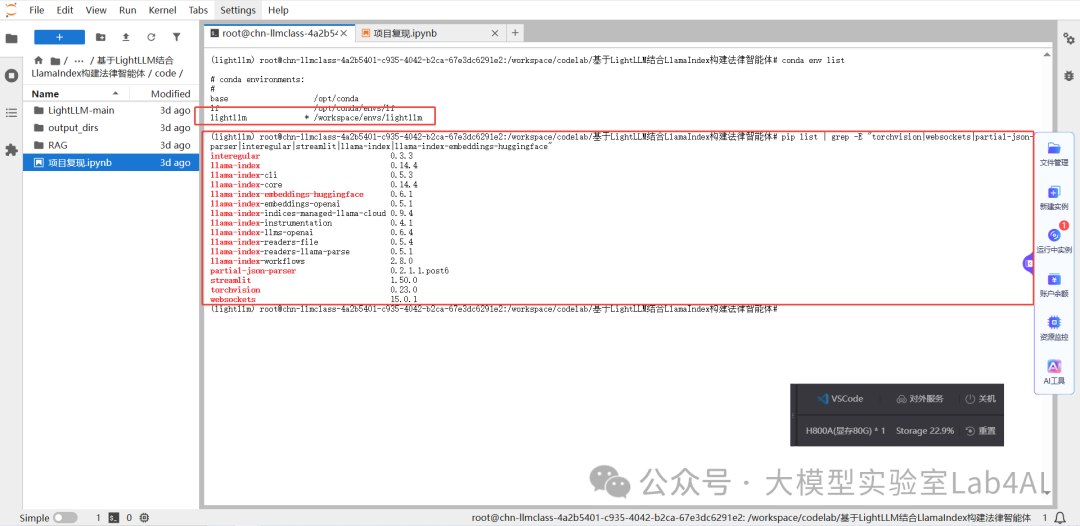
今天,我們將基于大模型實驗室Lab4AI,構建 LightLLM+LlamaIndex 法律的智能體。
登錄Lab4AI.cn。
在“項目復現”中找到“?構建LightLLM+LlamaIndex 法律智能體?”。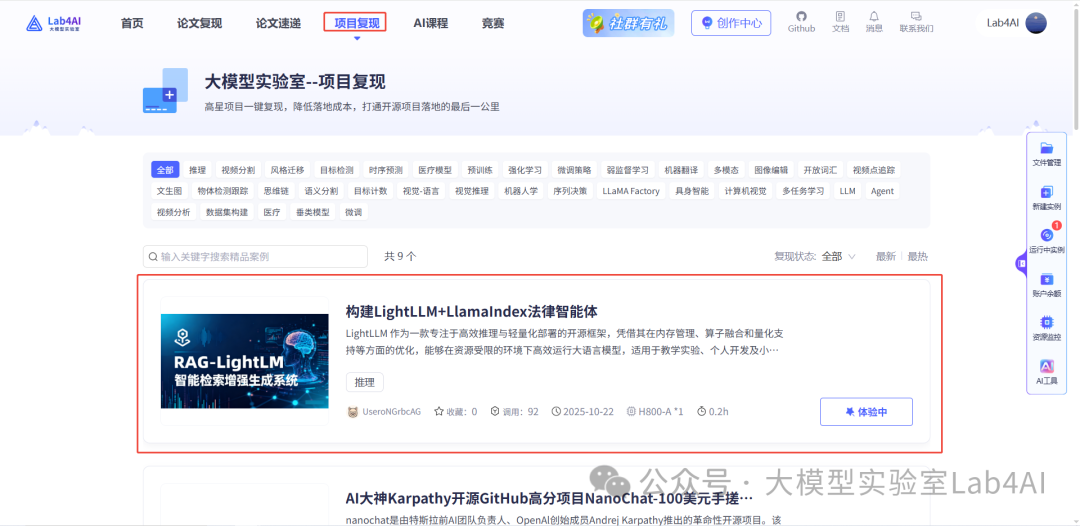
Step1:部署 LLM 服務。
%%script bash
mkdir-p./output_dirs/logsLOG_FILE="./output_dirs/logs/lightllm_$(date+'%Y%m%d_%H%M%S').log"
nohup python -m lightllm.server.api_server --enable_fa3 --model_dir /workspace/codelab/基于 LightLLM 結合 LlamaIndex 構建法律智能體/model/Qwen3-8B > "$LOG_FILE" 2>&1 &執行如下代碼測試
部署是否正常,服務正常啟動頁面例如下圖所示。


?Step2:部署 RAG?。
點擊鏈接下載app.py,下載后將文件拖拽至/workspace/lightllm 目錄下,然后運行如下所示命令加載 RAG 服務,加載成功后頁面例如下圖所示。
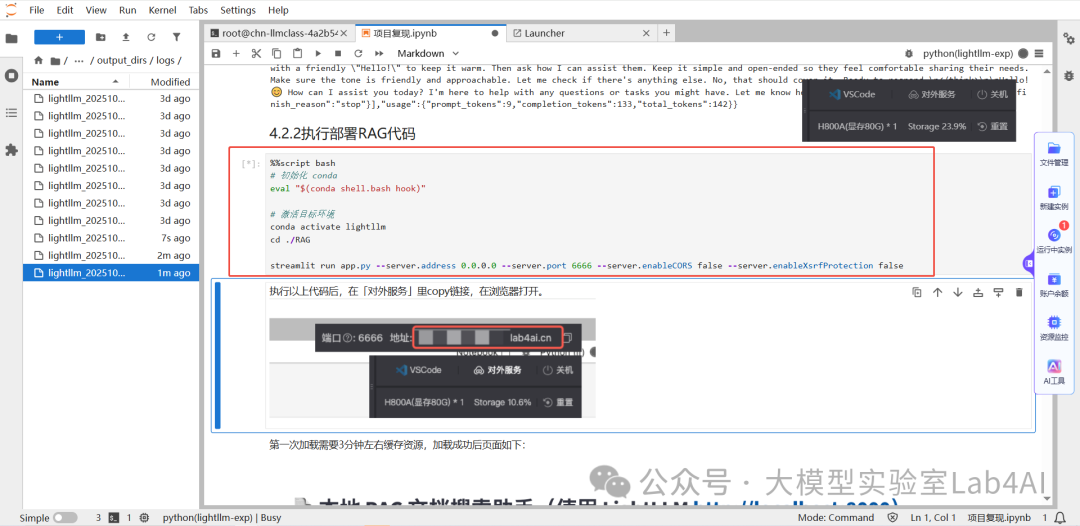
執行以上代碼后,在「對外服務」里copy 鏈接,在瀏覽器打開。點擊服務鏈接,進入本地 RAG 文檔搜索助手頁面,例如下圖所示。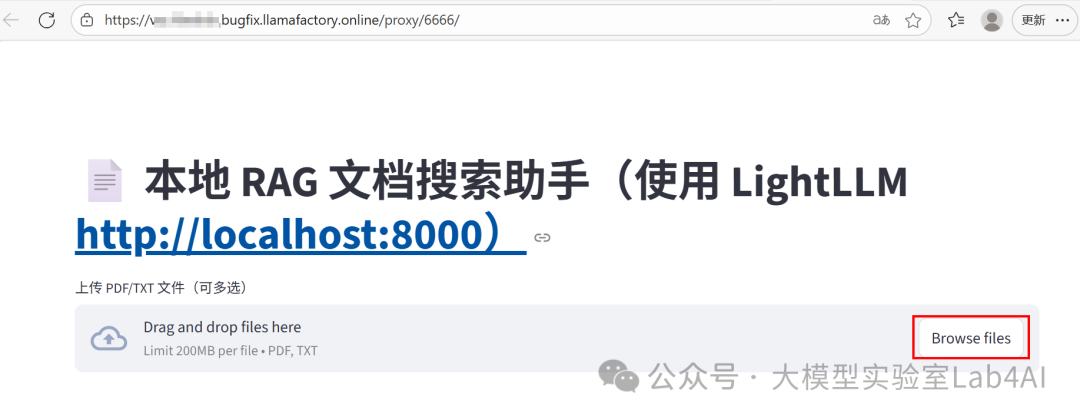
Step3:應用體驗。
服務部署完成后,用戶可自定義構建知識庫,并基于庫內信息查詢相關問題,快速獲取解決方案。
下方是我們上傳本地知識庫文件后,并輸入問題:“我有考勤記錄截圖和與領導溝通加班的微信記錄。勞動合同寫的是月薪 8000 元,但公司一直按基本工資 3000 元為基數算加班費。我主張最近一年的”。下方是問答效果:
從回復的內容可以看出:RAG 服務回復更具實戰性、對抗性和可操作性,適合作為智能法律助手的輸出標準,把用戶當作即將出庭的申請人,給予戰斗性、可執行的訴訟策略指導。
不只是Demo:從驗證到落地的全流程支撐
本方案驗證了“輕量化 RAG 技術”在實際業務環境中的可行性。通過構建外部文檔庫、數據庫或知識管理系統,讓模型在生成答案前先檢索最新且權威的資料,將檢索到的內容作為上下文輸入模型。借助 LightLLM 的高效推理與擴展能力,我們可在單機環境下支撐起專業級法律智能服務,顯著緩解模型“知識滯后”與幻覺問題。這一架構具備高可復用的特點,不僅能用于法律場景,還可快速遷移至金融、醫療、政務等強知識依賴的領域,形成穩定、可解釋、可擴展的行業解決方案。
More
作為算力驅動的AI 實踐內容生態社區,它不是普通的代碼倉庫,而是集代碼、數據、算力與實驗平臺于一體的平臺,項目中預裝虛擬環境,讓您徹底告別“環境配置一整天,訓練報錯兩小時”的窘境。
除了提供LightLLM 法律智能體的一鍵復現服務,Lab4AI 更構建了“算力 + 實驗平臺 + 社區”的全鏈條支撐體系,為不同用戶群體提供定制化價值:
1.科研黨:從“看論文”到“發論文”的全流程支持
每日同步Arxiv 前沿論文,提供翻譯、導讀、分析服務,助力快速追蹤行業動態;支持包括 LightLLM 在內的各類大模型一鍵復現,更可直接基于平臺進行數據集微調,兼容 LLaMA-FactoryWebUI 微調功能;同時對接投資孵化資源,助力科研創意轉化為實際產品。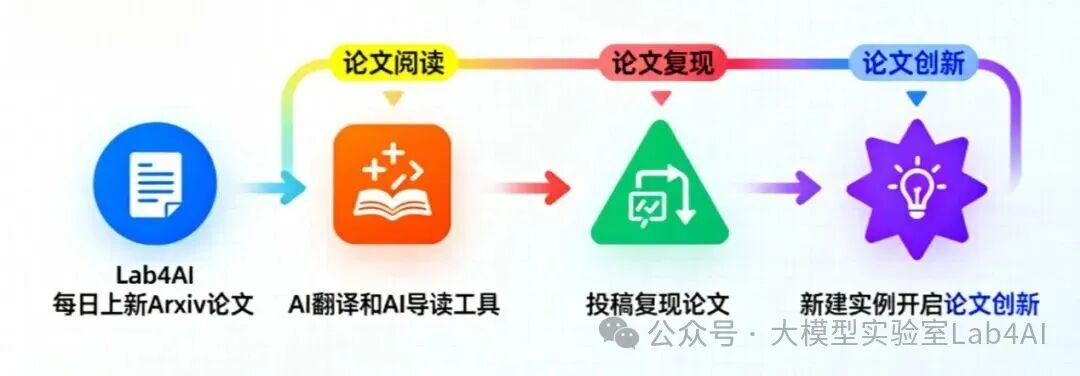
2.學習者:AI 課程支撐您邊練邊學
提供多樣化AI 在線課程,含 LLaMAFactory 官方合作課程等課程,聚焦大模型定制化核心技術,實現理論學習與代碼實操同步推進。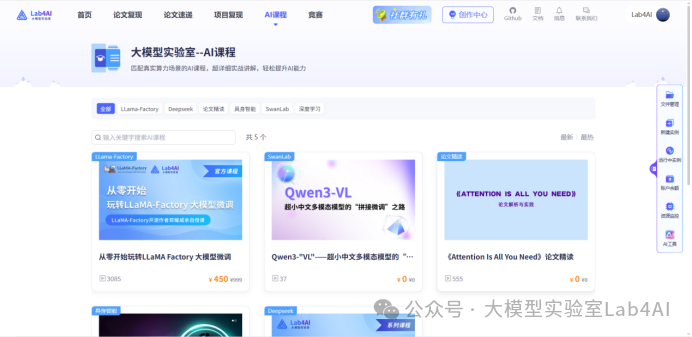

 浙公網安備 33010602011771號
浙公網安備 33010602011771號