
【每日Arxiv熱文】還在為視頻編輯發愁?港科大&螞蟻集團提出Ditto框架刷新SOTA!

【01 論文概述】
論文標題:ScalingInstruction-BasedVideoEditingwithaHigh-QualitySyntheticDataset
作者團隊:香港科大、螞蟻集團、浙江大學、東北大學
發布時間:2025 年 10 月 17 日
論文鏈接:https://arxiv.org/pdf/2510.15742
Lab4AI 大模型實驗室鏈接:
1. 研究背景
l 指令驅動編輯的模態差距:指令驅動圖像編輯已實現高精度(如InstructPix2Pix、FLUX.1Kontext 等模型),但視頻編輯顯著滯后——視頻編輯需同時保證內容修改與跨幀時間一致性,而現有技術難以平衡這一需求。
l 核心瓶頸:數據稀缺:端到端視頻編輯模型依賴大規模、高質量的“源視頻-指令-編輯后視頻”配對數據,但人工標注成本極高;現有合成數據方法存在固有缺陷:要么依賴高成本逐視頻優化(如 Qin 等人 2024 年方法),要么采用無訓練的圖像-視頻傳播技術(如 Yu 等人 2025 年 VEGGIE),均難以兼顧編輯多樣性、時間一致性、視覺質量與可擴展性。
l 現有數據的局限性:已有的指令驅動視頻數據集(如InsViE-1M)在分辨率(1024×576)、幀數(25 幀)、視覺質量篩選等方面存在不足,且缺乏對編輯任務關鍵的“高美學價值”和“自然運動”內容優化。
2. 研究目的
l 構建一套可擴展、低成本、高質量的指令驅動視頻編輯數據生成框架,解決數據稀缺這一核心瓶頸。
l 生成百萬級高質量數據集(Ditto-1M),覆蓋全局(風格轉換、場景改造)與局部(物體替換、添加/刪除)編輯任務,為模型訓練提供充足數據支撐。
l 訓練一款純指令驅動的視頻編輯模型(Editto),通過模態適配策略實現從“視覺引導編輯”到“文本指令編輯”的過渡,達到指令跟隨與時間一致性的最優性能,建立該領域新基準。
3. 本文核心貢獻
(1)提出 Ditto 數據生成框架
· 突破現有方法的“成本-質量-多樣性”權衡:融合先進圖像編輯器的視覺先驗與上下文視頻生成器(VACE),結合模型蒸餾與量化技術,將計算成本降至原始高保真方法的 20%,同時保證時間一致性與編輯質量。
· 自動化流程:通過視覺語言模型(VLM)實現指令生成與質量篩選,無需人工干預,支撐大規模數據生產。
(2)構建 Ditto-1M 數據集
· 規模與質量:包含100 萬“源視頻-指令-編輯后視頻”三元組,分辨率 1280×720(超現有數據集),每段 101 幀、20FPS,覆蓋 70% 全局編輯(風格、場景)與 30% 局部編輯(物體操作)。
· 數據篩選嚴格:源視頻來自專業平臺(Pexels),經去重、運動篩選、VLM 質量控制,確保高美學價值與自然運動特性。
(3)提出 Editto 模型與模態課程學習
· Editto 模型:基于上下文視頻生成器 VACE 改進,在 Ditto-1M 上訓練后,在指令跟隨、時間一致性、視覺質量上超越現有基線,成為指令驅動視頻編輯的新 SOTA。
· 模態課程學習(MCL):通過“逐步移除視覺引導”的訓練策略,解決從“視覺 + 文本引導”到“純文本指令引導”的模態鴻溝,提升模型對抽象指令的理解能力。
(4)驗證框架有效性
· 實驗證明Ditto 框架生成的數據可支撐模型泛化至真實場景(sim2real 能力),且 Editto 模型性能隨數據規模增長而穩定提升,驗證了大規模高質量數據的核心價值。
4.研究方法
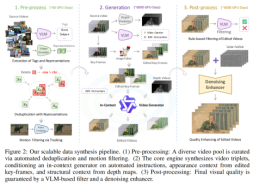
(1)Ditto 數據生成框架:三階段 pipeline
階段1:源視頻預處理(約 60GPU 天)
· 近重復移除:用DINOv2 視覺編碼器提取視頻特征,計算 pairwise 相似度,過濾超閾值的冗余視頻,保證數據多樣性。
· 運動篩選:用CoTracker3 跟蹤視頻網格點軌跡,計算平均累積位移作為“運動分數”,過濾低動態視頻(如固定鏡頭、靜態場景),保留具備時間變化的內容。
· 標準化:將通過篩選的視頻統一resize 至 1280×720,幀速率轉換為 20FPS,簡化后續訓練流程。
階段2:核心生成(約 6000GPU 天)
· 指令生成(VLM 兩步法):
- 第一階段:VLM 接收源視頻,生成包含內容、主體、場景的詳細描述(如“畫面中有一對情侶在人行道上行走,背景是城市街道”);
- 第二階段:將源視頻與描述輸入VLM,生成上下文相關的編輯指令(如“添加一盞發光的復古街燈,在情侶附近的人行道上投射溫暖的黃色光暈”),覆蓋全局與局部任務。
· 視覺上下文準備:
- 關鍵幀編輯:從源視頻中選關鍵幀,用Qwen-Image 等先進圖像編輯器按指令生成編輯后關鍵幀(作為外觀引導);
- 深度視頻預測:用VideoDepthAnything 模型從源視頻提取深度視頻(作為時空結構約束),保證場景幾何與運動一致性。
· 上下文視頻生成:
o 采用VACE 作為基礎生成器,輸入“深度視頻(結構約束)+ 編輯后關鍵幀(外觀引導)+ 指令(語義引導)”,生成編輯后視頻;
o 效率優化:通過模型量化(減少內存占用)與知識蒸餾(Yin 等人 2025 年方法),將生成成本降至原始高保真模型的 20%,支持大規模生產。
階段3:后處理(約 6000GPU 天)
· VLM 質量篩選:用 Qwen2.5-VL 評估三元組,篩選標準包括:指令忠實度(編輯是否匹配指令)、源語義保留(是否保留原視頻主體與運動)、視覺質量(無失真/偽影)、安全性(無違規內容),過濾低質量樣本。
· 去噪增強:用Wan2.2 模型的精細去噪器(MoE 架構),通過 4 步反向過程移除細微偽影、提升紋理細節,同時保證編輯內容的語義一致性(不引入新偏差)。
(2)Editto 模型訓練:模態課程學習
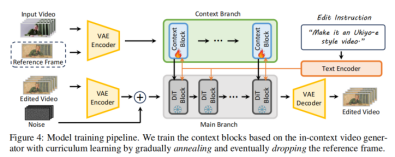
模型架構
· 基于VACE 改進,包含兩大分支:
- 上下文分支:提取源視頻與參考幀的時空特征,提供結構與外觀約束;
- 主分支:基于DiT(Transformer-based 擴散模型),融合文本指令嵌入與上下文特征,生成編輯后視頻。
· 訓練策略:凍結VACE 預訓練參數,僅微調上下文塊的線性投影層,減少過擬合風險。
模態課程學習(MCL)
· 初始階段:輸入“文本指令 + 編輯后參考幀”,以視覺引導作為“腳手架”,幫助模型理解編輯目標;
· 中間階段:逐步降低參考幀的輸入概率(退火策略),迫使模型依賴文本指令;
· 最終階段:完全移除參考幀,模型實現純指令驅動編輯。
?訓練目標?:采用流匹配(FlowMatching)損失
5.研究成果
研究通過定量比較、用戶研究和定性分析驗證了方法的有效性。
?定量結果?:在CLIP-T(指令跟隨)、CLIP-F(時間一致性)和 VLM 評分等自動指標上,本文提出的 Editto 模型均顯著優于現有方法。用戶研究也顯示,在指令跟隨準確性、時間一致性和整體質量方面,Editto 獲得了最高的用戶偏好。
?定性結果?:如圖5 所示,對于復雜的風格化轉換和局部屬性編輯,Editto 能生成視覺上更優、更符合指令要求且時間一致性更好的結果,而基線方法則容易出現模糊、不一致或編輯不準確的問題。
?附加結果與消融研究?:研究還展示了模型從合成數據到真實領域的轉換能力,并且通過消融實驗證實了大規模訓練數據和模態課程學習策略對于模型性能提升的關鍵作用。

6.總結與展望
l 本文通過Ditto 框架系統性解決了指令驅動視頻編輯的“數據稀缺”問題:該框架融合圖像編輯先驗與高效視頻生成,結合自動化質量控制,實現“低成本-高質量-可擴展”的數據生產,最終構建 Ditto-1M 數據集;
l 基于Ditto-1M 訓練的 Editto 模型,通過模態課程學習橋接視覺與文本模態,在指令跟隨、時間一致性、視覺質量上建立新 SOTA,驗證了“高質量數據 + 合理訓練策略”對視頻編輯任務的核心價值。
【02 論文原文閱讀】
您可以跳轉到Lab4AI 平臺上去閱讀論文原文。
Lab4AI大模型實驗室已經提供?該??論文?,閱讀鏈接:
https://www.lab4ai.cn/paper/detail/reproductionPaper?utm_source=jssq&_bky_dittoid=03e89d3d4c294a38a33e46328ce25993
?文末點擊閱讀原文?,即可跳轉至對應論文頁面。目前,論文的復現工作還在招募中,歡迎各位感興趣的朋友報名參與復現創作,我們提供一定額度的H800 算力作為獎勵。
·Lab4AI.cn覆蓋全周期科研支撐平臺,提供論文速遞、AI翻譯和AI導讀工具輔助論文閱讀;
·支持投稿論文復現和Github項目復現,動手復現感興趣的論文;
·論文復現完成后,您可基于您的思路和想法,開啟論文創新與成果轉化。

本文由AI 深度解讀,轉載請聯系授權。關注“大模型實驗室 Lab4AI”,第一時間獲取前沿 AI 技術解析!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號