
【項目復現(xiàn)上新】Karpathy大神開源GitHub高分項目NanoChat!僅用100美元+8000行代碼手搓ChatGPT
 10月13日,AI領域大神AndrejKarpathy發(fā)布了自己的最新開源項目。截至當前,GitHub項目上已經達到29.1KStar。
10月13日,AI領域大神AndrejKarpathy發(fā)布了自己的最新開源項目。截至當前,GitHub項目上已經達到29.1KStar。
The best ChatGPT that $100 can buy.
10 月 13 日,AI 領域大神 AndrejKarpathy 發(fā)布了自己的最新開源項目。截至當前,?GitHub 項目上已經達到 29.1KStar?。
nanochat 是什么
nanochat 是 AI 領域專家 AndrejKarpathy 發(fā)布的開源項目,該項目包含從數(shù)據(jù)準備、預訓練、中期訓練、監(jiān)督微調(SFT)、強化學習(RL)到推理部署的完整流程,約?8000 行代碼?,其以極低成本和高效流程訓練小型語言模型,?實現(xiàn)類似ChatGPT 的對話功能?。
AndrejKarpathy 表示,像 nanochat 這樣的模型訓練成本大概在 100 到 1000 美元之間,而 100 美元級別的模型的參數(shù)量只有GPT-3 的千分之一,只需使用 8??張H100GPU 訓練不到 4 小時?,就可以訓練出一個能夠寫故事/詩歌、回答簡單問題的模型。
如果將預算增加到?1000 美元?,只需要訓練約41.6 小時就能使模型性顯著提升,能解決簡單數(shù)學/代碼問題并參與多項選擇題測試。

?GitHub 鏈接?:
https://github.com/karpathy/nanochat
?Lab4AI 鏈接?:
https://www.lab4ai.cn/project/detail?utm_source=jssq_&id=f19f6e05f51a454d82383cc1ba250dde&type=project
| nanochat 的主要功能
雖然代碼量只有8000 行,但是它也實現(xiàn)了以下功能:
?全新Rust 分詞器(Tokenizer)訓練?:使用Rust 語言實現(xiàn)訓練分詞器;
?在FineWeb 數(shù)據(jù)集上預訓練?:在FineWeb 數(shù)據(jù)集上對 Transformer 架構的大語言模型進行預訓練,并在多個指標上評估 CORE 分數(shù);
?中期訓練?:在SmolTalk 用戶-助手對話數(shù)據(jù)集、多項選擇題數(shù)據(jù)集、工具使用數(shù)據(jù)集上進行中期訓練;
?監(jiān)督微調(SFT)?:在世界知識多項選擇題數(shù)據(jù)集(ARC-E/C、MMLU)、數(shù)學數(shù)據(jù)集(GSM8K)、代碼數(shù)據(jù)集(HumanEval)上進行監(jiān)督微調;
?強化學習(RL)優(yōu)化?:使用“GRPO”算法在 GSM8K 數(shù)據(jù)集上對模型進行強化學習微調;
?高效推理引擎?:實現(xiàn)高效模型推理,支持KV 緩存、簡易預填充/解碼流程、工具使用(輕量級沙箱環(huán)境中的 Python 解釋器),并通過 CLI 或類 ChatGPT 的 WebUI 與模型交互;
?自動訓練總結?:生成單一的Markdown 格式報告卡,總結整個訓練推理流程,并以“游戲化”形式展示結果。
一鍵復現(xiàn)
過去提到LLM 訓練,人們腦海里浮現(xiàn)的是動輒上百萬美元的算力成本、龐大的研發(fā)團隊和海量的數(shù)據(jù)儲備,這讓個人開發(fā)者和中小型團隊望而卻步;
而nanochat 不僅將?成本壓縮至100 美元?,大模型實驗室Lab4AI 更通過?“一鍵體驗”模式?,讓這個幾乎人人可承擔的價格真正轉化為“人人可操作”的嘗試,不再需要糾結環(huán)境配置、流程調試,普通人跟著指引就能親手搭建屬于自己的簡易版 ChatGPT,這種“?低門檻?+ 易操作”的組合,也恰好解決了學習者“紙上談兵”的痛點——以往看過無數(shù)教程卻仍不知全流程如何落地,
如今大模型實驗室Lab4AI 推出的 nanochat 體驗項目“100 美元實現(xiàn)自己的 ChatGPT”。
提供從數(shù)據(jù)準備到推理服務的“?一鍵式”全流程工具鏈?,學習者?不用再為環(huán)境搭建、代碼調試耗費精力?,只需跟著引導逐步操作,就能直觀感受模型訓練的每一個環(huán)節(jié),讓“無從下手”變成“步步有跡可循”。
Step1:登錄 Lab4AI.cn。
在“項目復現(xiàn)”中找到“?AI 大神 Karpathy 開源 GitHub 高分項目 NanoChat-100 美元手搓 ChatGPT?”。
項目內已經提供完整的復現(xiàn)NanoChat 的全流程代碼和環(huán)境,您只需配置 8 卡,即可手搓 ChatGPT。
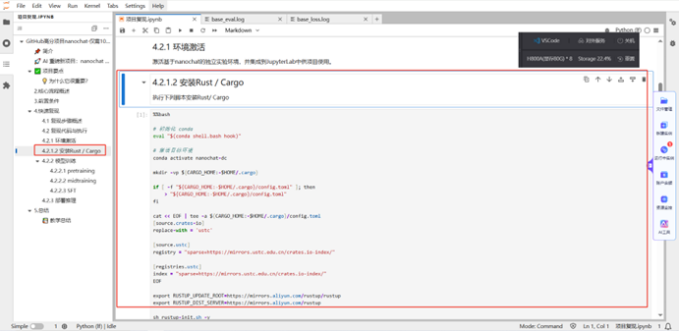
Step2:環(huán)境激活。
系統(tǒng)內已經預置可用的conda 虛擬環(huán)境,此環(huán)境可滿足后續(xù)步驟的需要。您只需執(zhí)行下列腳本安裝 Rust/Cargo。
?Step3:模型訓練?。
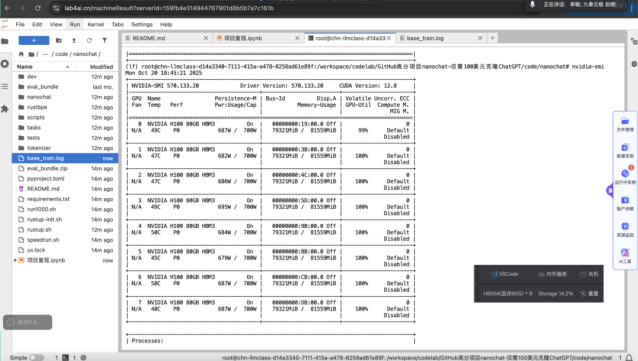
本次復現(xiàn)中,我們將訓練分為pretrain、midtrain 和 SFT 三個階段。pretrain 階段約需要 2.5-3 小時,midtrain 階段約耗時 30 分鐘內。
下方為訓練時各卡的工作狀態(tài)。從圖中看,8 塊 NVIDIAH10080GB 顯卡已經全部運行中,幾乎吃滿了所有的 GPU 算力。
您可以通過監(jiān)控這些指標,親眼看到模型是如何被“訓練”出來的。
Step4:模型評估。
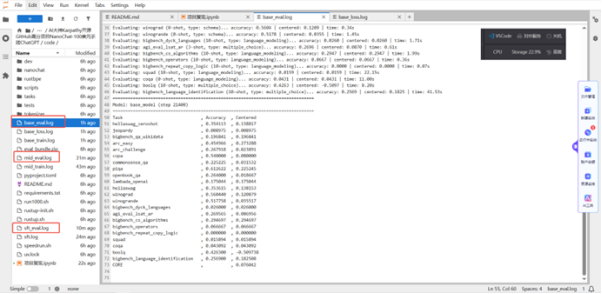
每個訓練階段有相應的評估程序輸出結構化評估結果。
以下是本次實踐的pretrain 后的評估結果,從結果得知:?模型初步掌握了世界運作的基本邏輯?。PIQA(物理互動問答):61.26%,表明模型已經初步掌握了世界運作的基本邏輯。COPA(因果推理):54.00%,表明模型開始具備初步的因果判斷能力。Winograd(指代消解):56.04%,表明模型能處理一些簡單的句法歧義。
當?面對復雜推理的閱讀理解任務能力很弱?。ARCEasy(基礎科學問答):45.50%,表明模型掌握了一些基礎的科學知識,但還不夠牢固。ARCChallenge(挑戰(zhàn)科學問答):26.79%,表明模型缺乏深度的、學科性的知識。
?面對知識密集型與復雜邏輯任務時,模型表現(xiàn)出了短板?。
Jeopardy!(知識問答):0.90%,
SQuAD(閱讀理解):1.59%,
CoQA(對話式問答):4.31%,
OpenBookQA(開卷問答):26.40%。
Step5:部署推理。
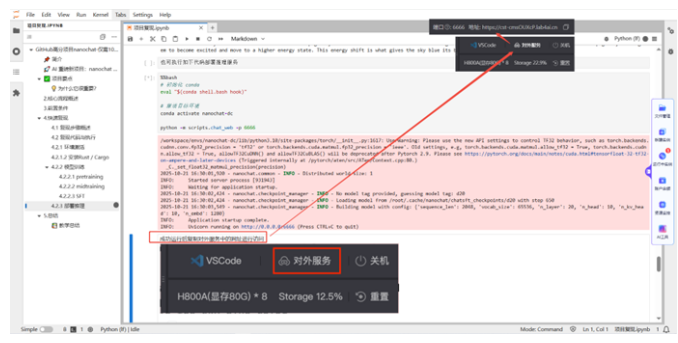
訓練完成的模型支持如下兩種推理方式:通過命令行的方式進行推理;通過WebUI 的方式進行推理。
(1)通過命令行對話,執(zhí)行后即可在下方看到推理內容。

(2)通過WebUI 執(zhí)行對話。執(zhí)行代碼后,鼠標滑過右上角的【對外服務】,將鏈接復制到瀏覽器,打開后即可對話。
Lab4AI 支撐從研究到落地
Lab4AI 提供除了一鍵復現(xiàn)之外,還提供更多的價值:
1. 如果你是科研黨
每日更新Arxiv 上的論文,支持翻譯、導讀、分析,幫你快速跟進前沿研究;還能一鍵復現(xiàn)其他大模型;若你有自己的數(shù)據(jù)集,能直接在平臺上進行代碼微調,平臺還支持使用 LLaMA-Factory 進行 WebUI 微調大模型,甚至對接投資孵化資源,把科研創(chuàng)意變成落地成果。


2.如果你是學習者
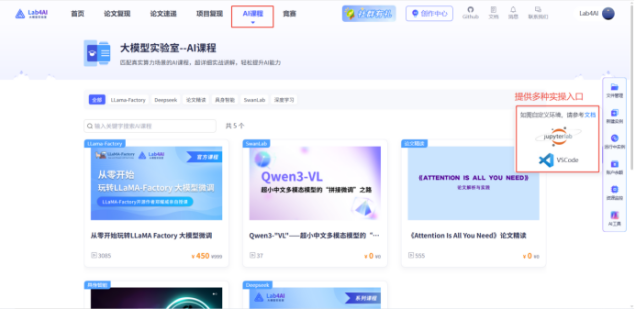
如果你想掌握大模型相關技能,Lab4AI 的優(yōu)勢更明顯:?Lab4AI 提供多種在線課程?,更有LLaMA Factory 官方合作課程,讓您理論學習和代碼實戰(zhàn)同時進行。LLaMA Factory 官方合作課程課程聚焦于當下最受歡迎的LLaMA Factory 框架,帶您從理論到實踐,一站式掌握大模型定制化的核心技能,課程還送 300 元算力、完課證書。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號