
【Github熱門項目】DeepSeek-OCR項目上線即突破7k+星!突破10倍無損壓縮,重新定義文本-視覺信息處理
 DeepSeek團隊于10月20日開源的DeepSeek-OCR,以“上下文光學壓縮”為核心突破,重新定義了OCR(光學字符識別)的效率邊界。
DeepSeek團隊于10月20日開源的DeepSeek-OCR,以“上下文光學壓縮”為核心突破,重新定義了OCR(光學字符識別)的效率邊界。
當“8000 行代碼手搓 ChatGPT”的熱度還未褪去,大模型領域又迎來新驚喜——DeepSeek 團隊于 10 月 20 日開源的DeepSeek-OCR,以“上下文光學壓縮”為核心突破,重新定義了 OCR(光學字符識別)的效率邊界。這款僅 30 億參數量的模型,不僅能以 100 個視覺 token 超越傳統模型 256 個 token 的性能,更在單張 A100-40G 顯卡上實現每日 20 萬頁文檔處理能力,為長文本壓縮與大模型效率優化提供了全新思路。
?論文標題?:DeepSeek-OCR:ContextsOpticalCompression
?項目地址?:https://github.com/deepseek-ai/DeepSeek-OCR
?論文地址?:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
?HuggingFace?:https://huggingface.co/deepseek-ai/DeepSeek-OCR
??Lab4AI 閱讀地址:文末點擊閱讀原文,直達官網
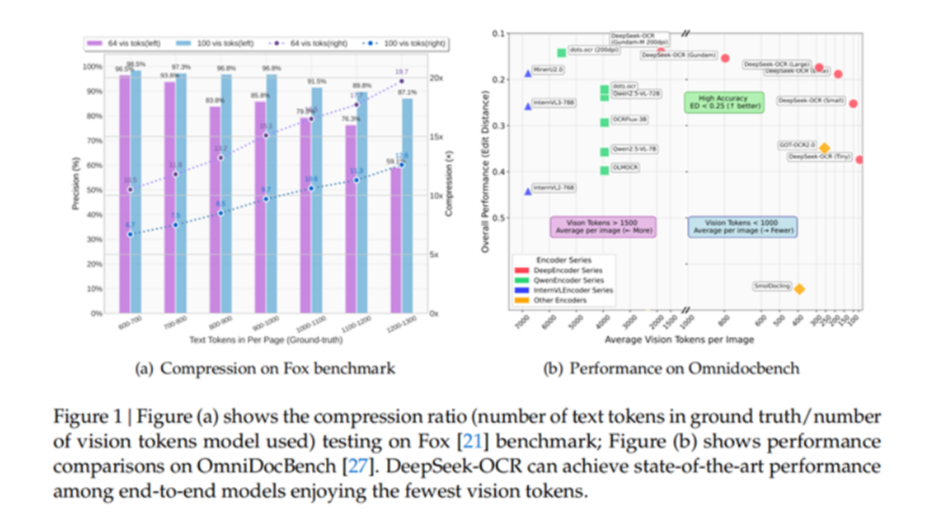
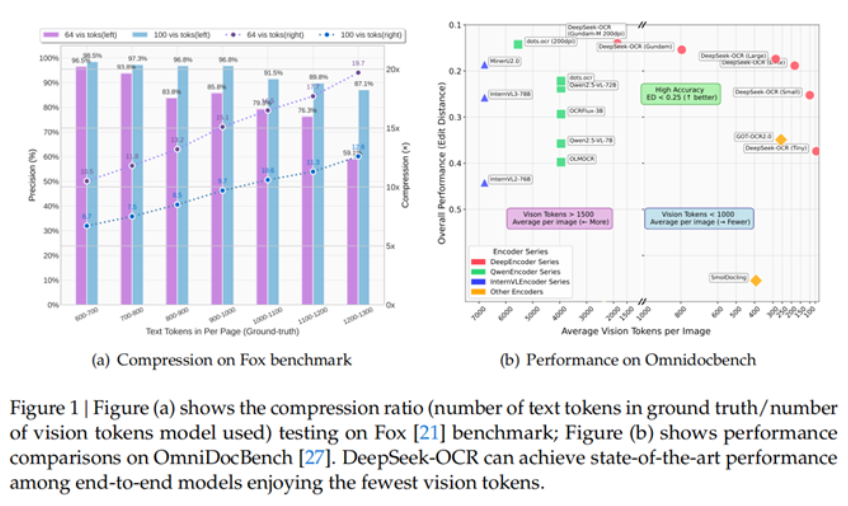
DeepSeek-OCR 的核心創新在于利用視覺模態作為文本信息的高效壓縮媒介。研究表明,一張?包含文檔文本的圖像可以用比等效文本少得多的 Token 來表示豐富信息?,這意味著通過視覺 Token 進行光學壓縮可以實現極高的壓縮率。
其核心表現可概括為兩組關鍵數據:
- 壓縮比與精度的平衡:當文本 token 數量是視覺 token 的 10 倍以內(即壓縮比 <10×)時,OCR 解碼精度高達 97%;即便壓縮比提升至 20×,精度仍能維持在 60% 左右,遠超行業同類模型的衰減速度。
- 極致的 token效率:在 OmniDocBench 基準測試中,它僅用 100 個視覺 token 就超越了需 256 個 token 的 GOT-OCR2.0;面對 MinerU2.0 平均每頁 6000+token 的消耗,它用不到 800 個 token 就能實現更優性能——相當于將文本處理的“token 成本”降低了 7-20 倍。
這種突破的價值不僅在于 OCR 本身:對于受限于“長上下文處理能力”的大模型而言,DeepSeek-OCR 提供了一種新解法——將超長文本轉化為視覺圖像后壓縮輸入,可大幅減少 LLM 的 token 消耗,為處理百萬字級文檔、歷史上下文記憶等場景打開了通道。
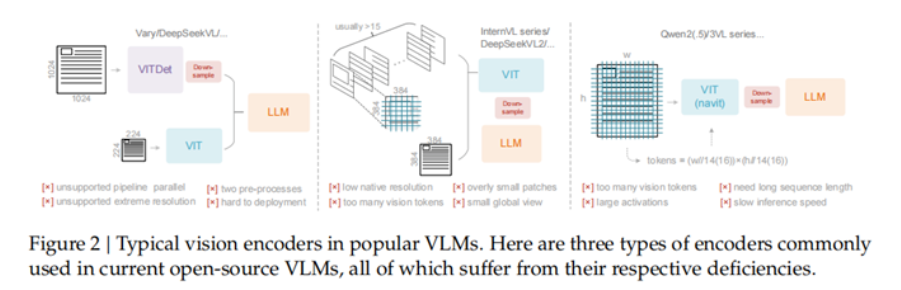
DeepEncoder:編碼器 +MoE 解碼器
為實現“高壓縮比、低資源消耗”的目標,DeepSeek-OCR 采用了“DeepEncoder(編碼器)+DeepSeek3B-MoE(解碼器)”的端到端架構,兩者各司其職又高度協同。
1. DeepEncoder
作為模型的“壓縮核心”,DeepEncoder 需同時滿足“高分辨率處理、低激活開銷、少 token 輸出”三大需求,其架構設計暗藏巧思:
- 雙組件串聯:由 8000 萬參數的SAM-base(視覺感知)和 3 億參數的CLIP-large(視覺知識)串聯而成。SAM-base 用“窗口注意力”處理高分辨率圖像細節,CLIP-large 用“全局注意力”提取語義關聯,兼顧精度與全局理解。
- 16 倍 token 壓縮:在雙組件之間,通過2 層卷積模塊對視覺 token 進行 16 倍下采樣。例如,1024×1024 的圖像先被劃分為 4096 個 patchtoken,經壓縮后僅保留 256 個有效 token,既控制了內存消耗,又不丟失關鍵信息。
- 多分辨率適配:
支持 Tiny(512×512)、Small(640×640)、Base(1024×1024)、Large(1280×1280)四種原生分辨率。還能通過“Gundam 模式”實現超高分辨率輸入(如報紙圖像)的瓦片化處理,單個模型即可覆蓋從手機截圖到大幅文檔的全場景需求。
2. DeepSeek3B-MoE
解碼器采用混合專家(MoE)架構,在“性能與效率”間找到了平衡點:
- 參數激活策略:雖然總參數量為 3B,但推理時僅激活 64 個“路由專家”中的 6 個,外加 2 個“共享專家”,實際參與計算的參數僅 5.7 億——相當于用“500M 模型的資源消耗”,獲得了 3B 模型的表達能力。
- 快速文本重建:從 DeepEncoder 輸出的壓縮視覺 token 中,解碼器能精準重建原始文本,甚至支持 markdown 格式轉換、圖表結構化提取等復雜任務,無需額外的后處理模塊。
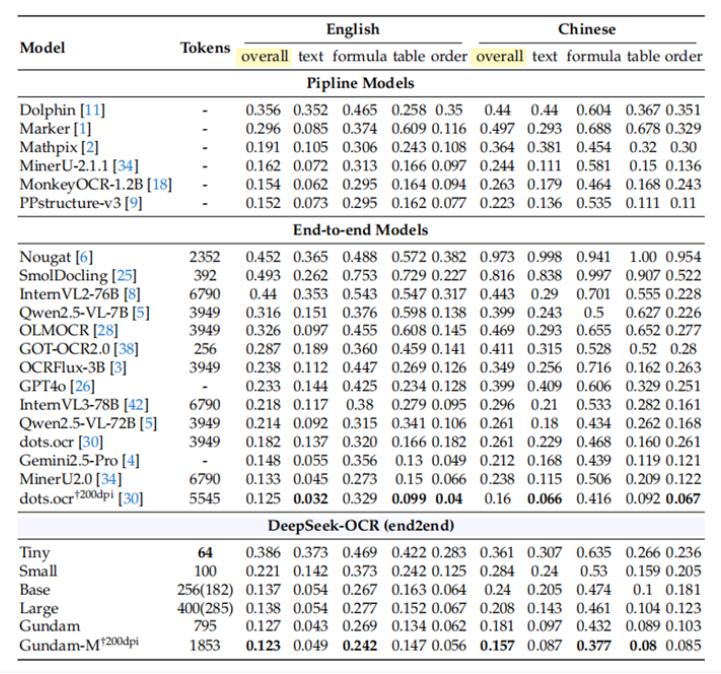
性能表現
實驗數據令人印象深刻:當文本 Token 數量在視覺 Token 的 10 倍以內(壓縮率 <10×)時,模型的解碼精度可達 97%;即使在壓縮率達到 20× 的情況下,OCR 準確率仍保持在約 60%。
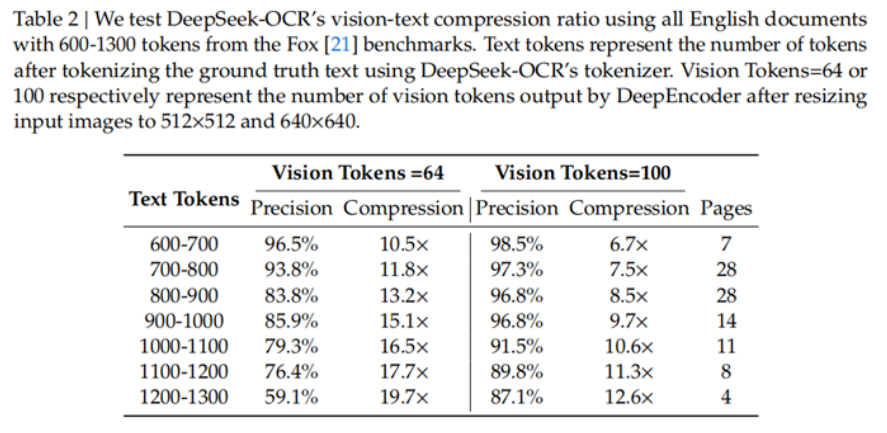
在實際應用層面,DeepSeek-OCR 展現出驚人效率:在 OmniDocBench 基準測試中,僅使用100 個視覺 Token 就超過了 GOT-OCR2.0(每頁 256 個 Token)的表現;使用不到 800 個視覺 Token 就優于 MinerU2.0(平均每頁超過 6000 個 Token)。
大模型實驗室 Lab4AI
值得一提的是,大模型技術社區「大模型實驗室 Lab4AI」已經第一時間上架了DeepSeek-OCR 論文及相關技術資料。該社區的技術團隊正在積極復現論文中的創新方法,驗證其在實際場景中的表現。
大模型實驗室作為專注于 AI 前沿技術的內容社區,將持續跟蹤 DeepSeek-OCR 的最新進展,并分享更多實踐案例和技術分析。歡迎各位開發者關注社區動態,共同探索這一創新技術的更多應用可能。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號