
【論文復現上新】NeurIPS 2023! 經典論文! DPO:你的語言模型,其實就是個獎勵模型 | 強化學習 | 微調策略
01 論文概述

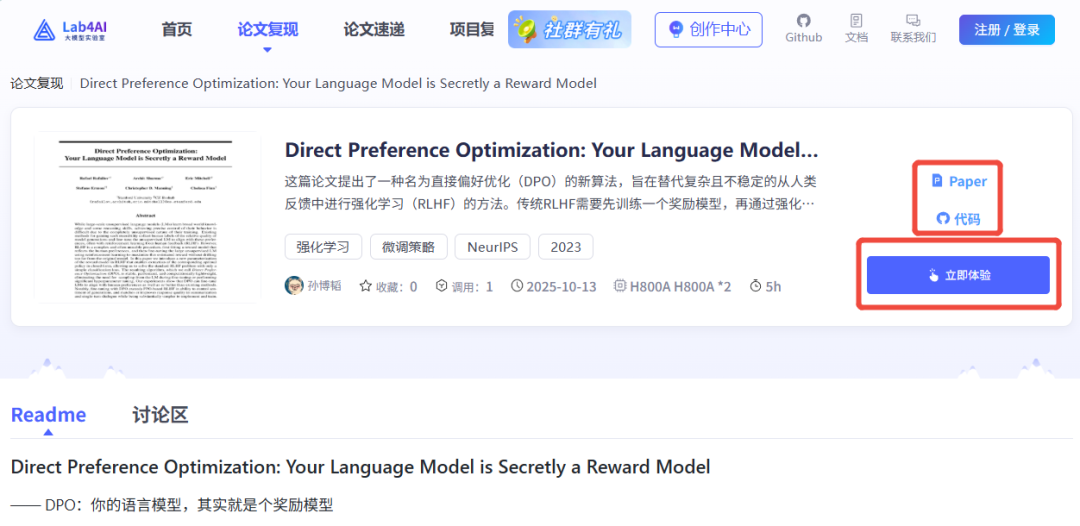
論文名稱:
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
—— DPO:你的語言模型,其實就是個獎勵模型
論文鏈接:https://arxiv.org/pdf/2305.18290
??Lab4AI 鏈接:
?? 簡介
在大型語言模型(LLM)的對齊技術中,基于人類反饋的強化學習(RLHF)曾是黃金標準。然而,RLHF 流程極其復雜:它需要先訓練一個獨立的獎勵模型(Reward Model)來學習人類偏好,然后再使用強化學習(如 PPO)來微調語言模型以最大化這個獎勵。這個過程不僅計算昂貴,而且訓練過程極不穩定。
于 2023 年發布的 "直接偏好優化" (Direct Preference Optimization, DPO) 論文提出了一種顛覆性的、更簡單的對齊范式。DPO 的核心洞見是:?我們完全不需要一個顯式的獎勵模型,也不需要強化學習?。通過一個精妙的數學推導,作者證明了可以直接利用人類偏好數據(即“選擇的”和“拒絕的”回答對),通過一個簡單的分類損失函數來直接優化語言模型本身。這篇論文揭示了,在優化的過程中,語言模型自身就隱式地充當了獎勵模型的角色,從而極大地簡化了對齊過程。
?? 優勢
- 極致簡化DPO 將 RLHF 復雜的“獎勵建模 -> 強化學習”兩階段流程,簡化為一步式的、類似監督微調(SFT)的直接優化過程。
- 穩定高效完全摒棄了強化學習,從而避免了其訓練不穩定、超參數敏感等問題。DPO 的訓練過程像常規微調一樣穩定,且計算成本更低。
- 性能卓越實驗證明,DPO 不僅在實現上更簡單,其最終模型的性能通常能與甚至超越經過復雜 RLHF 調優的模型。
- 理論優雅為偏好學習提供了堅實的理論基礎,清晰地揭示了語言模型策略與隱式獎勵函數之間的直接關系。
??? 核心技術
- ?偏好模型的重新參數化 (Reparameterization of the Reward Model)?DPO 的理論基石。它首先基于 Bradley-Terry 等偏好模型建立獎勵函數與最優策略(LLM)之間的關系。
- 從獎勵優化到直接偏好優化通過數學推導,DPO 將最大化獎勵的目標函數,巧妙地轉換為了一個直接在偏好數據上進行優化的損失函數。這個損失函數的形式類似于一個簡單的二元分類任務。
- ?隱式獎勵函數 (Implicit Reward Function)?推導出的 DPO 損失函數表明,優化過程實際上是在最大化一個由當前策略(被優化的 LLM)和參考策略(初始 SFT 模型)的比值所定義的?隱式獎勵?。這意味著語言模型自身的變化直接反映了獎勵的變化,無需外部獎勵模型。
- ?類似 SFT 的實現 (SFT-like Implementation)?DPO 的最終損失函數非常簡潔,可以直接用于微調語言模型。訓練數據是
(prompt, chosen_response, rejected_response)三元組,模型的目標是最大化chosen_response的概率,同時最小化rejected_response的概率。
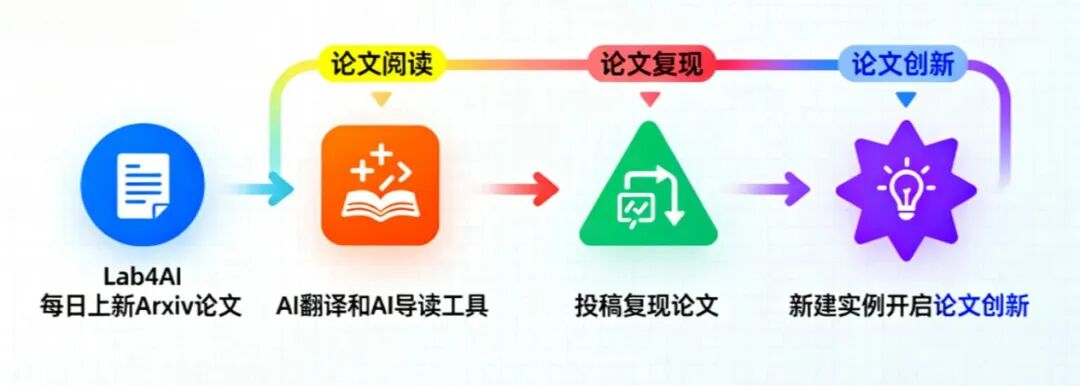
02 論文原文閱讀
您可以跳轉到Lab4AI.cn上進行查看。?? 文末點擊閱讀原文,即可跳轉至對應論文頁面~
-
Lab4AI.cn 提供免費的AI 翻譯和AI 導讀工具輔助論文閱讀;
-
支持投稿復現,動手復現感興趣的論文;
-
論文復現完成后,您可基于您的思路和想法,開啟論文創新。
![3.jpg]()
![4.png]()

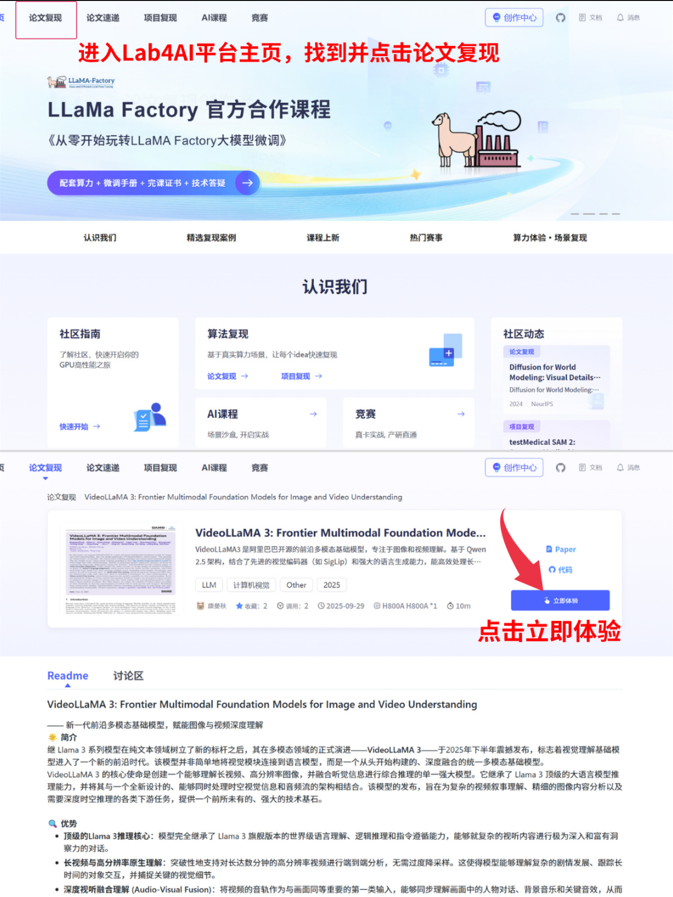
03 一鍵式論文復現
Lab4AI.cn上已上架了此篇復現案例,【登錄平臺】即可體驗論文復現。
??Lab4AI 平臺復現鏈接(或者點擊閱讀原文):
??? 實驗部署
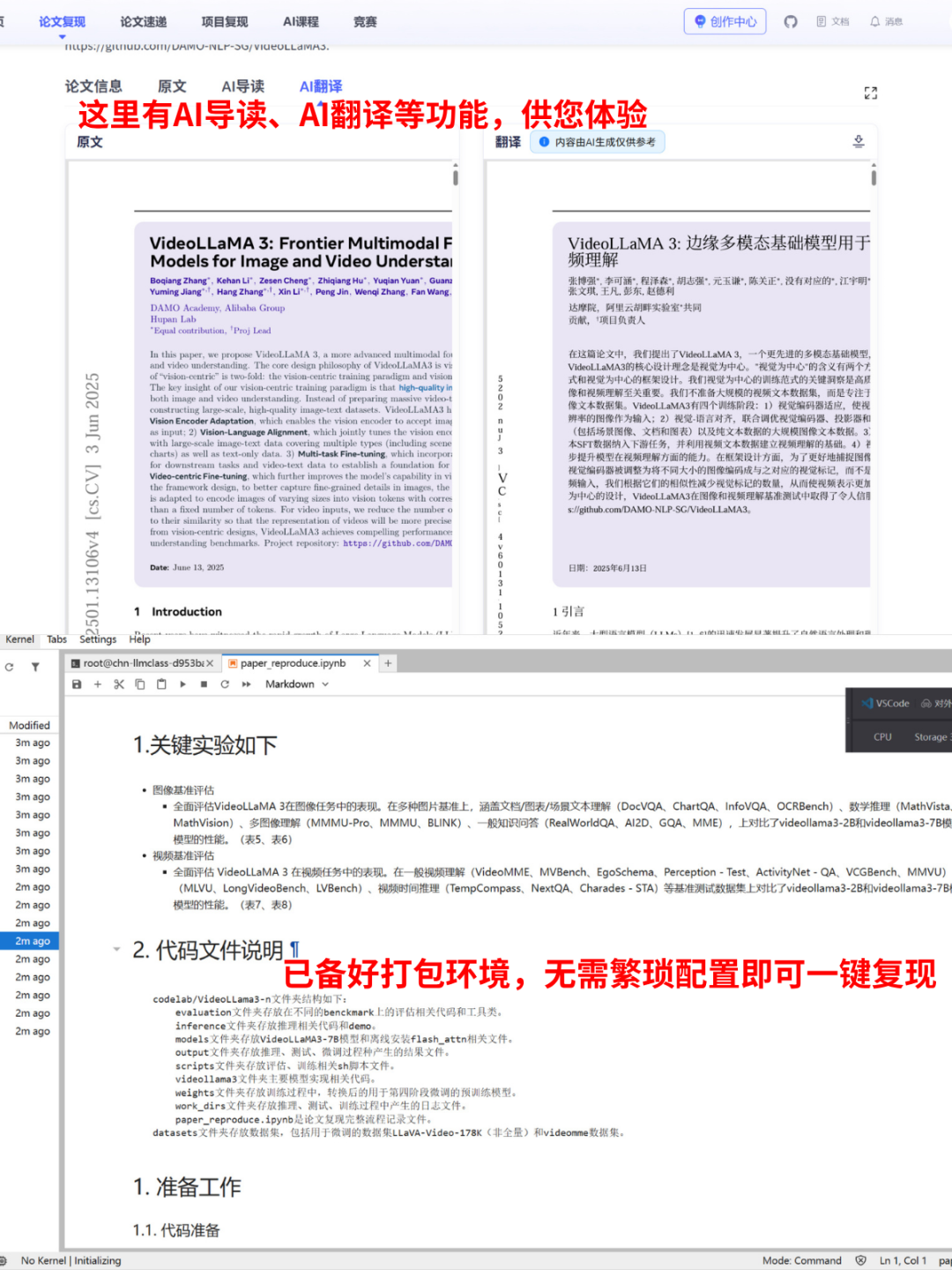
本實驗環境已為您精心配置,開箱即用。
- ?? ?代碼獲取?:項目復現代碼已存放于
/codelab/direct-preference-optimization/code文件夾中。 - ?? ?模型說明?:
/codelab/direct-preference-optimization/model文件夾中存放了用于 DPO 訓練的初始 SFT 模型。 - ?? ?數據說明?:
/codelab/direct-preference-optimization/dataset文件夾中包含了用于實驗的人類偏好數據集(如 Anthropic HH-RLHF)。 - ?? ?環境說明?:運行所需的所有依賴已預安裝在
/envs/dpo/環境中,您無需進行任何額外的環境配置。
?? 環境與內核配置
請在終端中執行以下步驟,以確保您的開發環境(如 Jupyter 或 VS Code)能夠正確使用預設的 Conda 環境。
1. 在 Jupyter Notebook/Lab 中使用您的環境
- 為了讓 Jupyter 能夠識別并使用您剛剛創建的 Conda 環境,您需要為其注冊一個“內核”。
- 首先,在您已激活的 Conda 環境中,安裝
ipykernel包:conda activate dpopip install ipykernel - 然后,執行內核注冊命令。
# 為名為 dpo 的環境注冊一個名為 "Python(dpo)" 的內核kernel_install --name dpo --display-name "Python(dpo)" - 完成以上操作后,刷新您項目中的 Jupyter Notebook 頁面。在右上角的內核選擇區域,您現在應該就能看到并選擇您剛剛創建的
"Python(dpo)"內核了。
2. 在 VS Code 中使用您的環境
- VS Code 可以自動檢測到您新創建的 Conda 環境,切換過程非常快捷。
- 第一步: 選擇 Python 解釋器
- 確保 VS Code 中已經安裝了官方的 Python 擴展。
- 使用快捷鍵
Ctrl+Shift+P(Windows/Linux) 或Cmd+Shift+P(macOS) 打開命令面板。 - 輸入并選擇
Python: Select Interpreter。
- 第二步: 選擇您的 Conda 環境
- 在彈出的列表中,找到并點擊您剛剛創建的環境(名為
dpo的 Conda 環境)。 - 選擇后,VS Code 窗口右下角的狀態欄會顯示
dpo,表示切換成功。此后,當您在 VS Code 中打開 Jupyter Notebook (.ipynb) 文件時,它會自動或推薦您使用此環境的內核。
- 在彈出的列表中,找到并點擊您剛剛創建的環境(名為
Lab4AI.cn 來送禮啦~
? 注冊有禮,注冊即送 30 元代金券
https://www.lab4ai.cn/register?utm_source=jssq/_bky立即體驗
? 入群有禮,入群即送 20 元代金券
??


 浙公網安備 33010602011771號
浙公網安備 33010602011771號