
7M參數,干翻巨無霸LLM!這款超小遞歸模型(TRM),在ARC-AGI上證明了“少即是多”
 TRM僅使用一個超小的2層網絡(7M參數),通過更直接、完整的遞歸和深度監督機制,在多個基準測試上顯著超越了HRM和許多主流LLMs。其最引人注目的成果是在ARC-AGI-1上達到45%的測試準確率,超過了參數量是其數百萬倍的LLMs。
TRM僅使用一個超小的2層網絡(7M參數),通過更直接、完整的遞歸和深度監督機制,在多個基準測試上顯著超越了HRM和許多主流LLMs。其最引人注目的成果是在ARC-AGI-1上達到45%的測試準確率,超過了參數量是其數百萬倍的LLMs。
01 論文概述

論文標題:Less is More: Recursive Reasoning with Tiny Networks
作者團隊:三星AI實驗室(Samsung SAIL Montréal)
發布時間:2025年9月6日
論文鏈接:https://arxiv.org/pdf/2510.04871
??您可以跳轉到 Lab4AI 平臺上去閱讀論文原文。
Lab4AI 大模型實驗室論文閱讀鏈接:
https://www.lab4ai.cn/paper/detail/reproductionPaper?utm_source=jssq_bky&id=cffcdeb7f3174ebf9daedd9a9482a656
?? 或者文末點擊閱讀原文,即可跳轉至對應論文頁面~

Lab4AI 提供 ?AI 導讀 和 AI 翻譯 ? 工具
| 研究背景與動機
當前推理模型在解決需要多步、精確推理的難題時面臨“大模型低效、小模型乏力”的矛盾。核心問題集中在大語言模型(LLMs)與層次推理模型(如 HRM)存在顯著短板:大語言模型(LLMs)是自回歸生成答案的,會因為單個錯誤導致推理的答案錯誤。而已有研究者認為依賴鏈式推理(CoT)和測試時計算(TTC)可以增加推理準確性,但這些方法需要高質量的數據且魯棒性差。
在TRM之前,有研究者提出遞歸層次推理HRM,它模仿生物大腦,使用兩個小神經網絡在不同頻率上進行遞歸思考。HRM雖然在推理任務上超越LLMs的小模型,但是它的設計復雜、依賴不動點定理且訓練不穩定。TRM應運而生,旨在以更簡單、高效的方式實現遞歸推理。
| TRM 是什么
10月6日,三星AI實驗室(Samsung SAIL Montréal)發表了名為Less is More: Recursive Reasoning with Tiny Networks 的論文。該論文提出了一種“?少即是多?”的更簡單、更高效的遞歸推理模型—Tiny Recursive Model(TRM)。
作者對HRM進行了簡化和改進。TRM僅使用一個超小的2層網絡(7M參數),通過更直接、完整的遞歸和深度監督機制,在多個基準測試上顯著超越了HRM和許多主流LLMs。其最引人注目的成果是在ARC-AGI-1上達到45%的測試準確率,超過了參數量是其數百萬倍的LLMs(如Gemini 2.5 Pro)。
| 核心架構
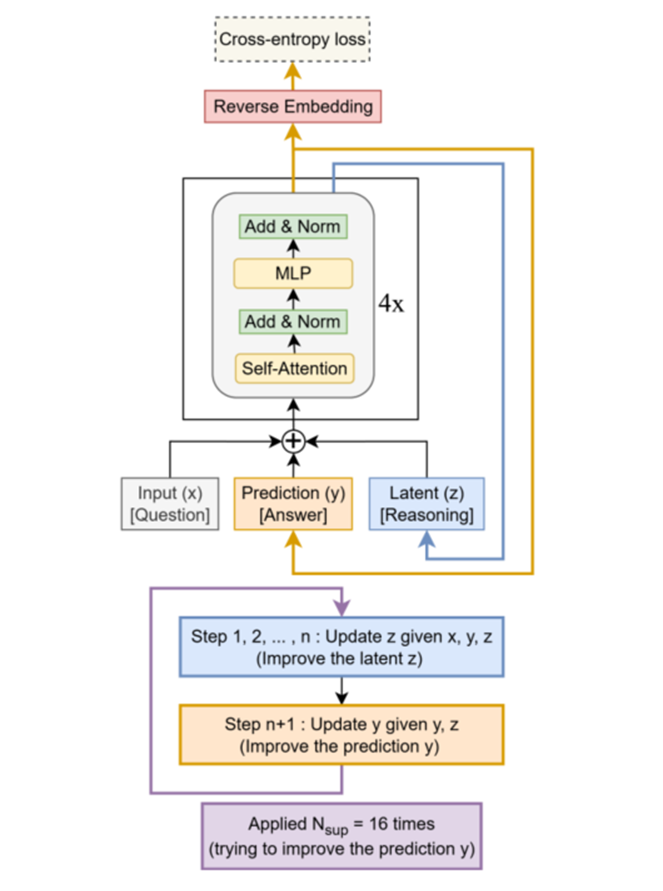
TRM的核心架構可以用以上圖表示。TRM的工作流程可以結合圖1和算法3直觀理解:
- 初始化:輸入問題、初始答案和潛在推理狀態。
- 深度監督循環:對于每個訓練樣本,模型進行最多次改進步驟。
- 潛在遞歸:在每個監督步驟中,模型執行一個“深度遞歸”過程:
(1)無梯度預熱:先進行次(如2次)完整的“潛在遞歸”,即先遞歸更新(次),再根據新的更新。此過程不計算梯度,目的是利用模型自身的計算能力初步優化答案。
(2)有梯度遞歸:最后進行1次有梯度的“潛在遞歸”,這次的反向傳播會貫穿整個遞歸過程。
- 損失計算與停止判斷:計算預測答案的損失以及停止概率的損失。如果停止概率超過閾值,則提前結束對該樣本的深度監督循環。
- 梯度更新:執行反向傳播和梯度更新,并將當前步的和截斷梯度后作為下一步的初始值。
| 核心方法與創新思路
論文的貢獻并非表面改進,而是從理論、架構、效率等層面重構遞歸推理模型。
?(1)??摒棄不動點定理,實現“完整遞歸反向傳播”
HRM的存在一個問題:僅反向傳播最后 2 步(1個+1個),依賴“不動點假設”,但實際未收斂,梯度計算不完整;
TRM針對這個問題,提出了解決方案:TRM不再假設收斂,而是直接通過整個遞歸過程(n次 latent reasoning + 1次 answer refinement)進行反向傳播。為了在深度監督中利用無梯度計算進行“預熱”,它先進行T-1次無梯度遞歸,再進行1次有梯度的遞歸。這徹底避開了IFT的理論爭議,并帶來了巨大的性能提升。
?(2)??重構 Latent ? 變量,無需分層與生物解釋
作者提出了一個更自然的解釋:其實就是當前答案的嵌入表示,而是一個純粹的中間推理狀態。因此,TRM將其重命名為(答案)和(推理狀態)。這種解釋明確了為什么需要兩個特征:用于記住當前解決方案,用于進行鏈式推理。
?(3)??單網絡替代雙網絡,參數規模減半
既然更新和更新的任務區別僅在于輸入中是否包含問題,TRM使用一個共享的微小網絡來同時完成這兩項任務。
TRM用單個2層網絡同時實現“更新(推理)”與 “更新(解優化)”,通過“輸入是否包含” 區分任務:
更新z時:輸入為(需結合問題x優化推理);
更新y時:輸入為(無需,僅基于推理優化解);
?(4)??少即是多”的規模控制
作者發現將網絡深度從4層減少到2層,同時按比例增加遞歸次數以保持總計算量,能顯著提升泛化性能。這凸顯了在小數據場景下,避免過擬合比增加模型容量更重要。
?(5)??無注意力架構用于固定短語長度的任務
對于固定且較小的上下文(如9x9數獨),TRM用應用于序列維度的MLP取代了自注意力機制,靈感來自MLP-Mixer。這在數獨任務上帶來了巨大提升,但在上下文較大的任務(如30x30網格)上,自注意力仍更有效。
(?6??)??簡化 ACT ??機制,消除額外前向傳播
TRM移除了需要額外前向傳播的Q-learning“繼續”損失,只保留一個基于答案正確性的二值交叉熵“停止”損失。
?(7)引入 EMA?,抑制小數據集過擬合
HRM在小數據集(如 1K 樣本的 Sudoku-Extreme)上易過擬合,訓練后期準確率驟降。為了在小型數據集上穩定訓練并防止過擬合,TRM采用了指數移動平均(EMA),權重更新時平滑參數(EMA decay=0.999),減少權重波動。
| 實驗設計與結果分析
論文在數獨、迷宮、ARC-AGI-1/2四個基準上的實驗結果非常令人印象深刻:
ü TRM(7M參數)全面超越了HRM(27M參數),例如在ARC-AGI-2上將性能從5.0%提升至7.8%。
ü TRM大幅超越了眾多參數量巨大的LLMs,證明了其解決復雜推理問題的巨大潛力。
這些結果強有力地支持了論文的核心理念:對于某些需要系統化推理的、數據稀缺的任務,一個參數極少但能夠進行深度遞歸計算的模型,可能比一個參數龐大但推理路徑短的模型更有效。
02 論文原文閱讀
您可以跳轉到 Lab4AI 平臺上去閱讀論文原文。
??Lab4AI 大模型實驗室論文閱讀鏈接:
??文末點擊閱讀原文,即可跳轉至對應論文頁面~
▼ AI 翻譯——對照閱讀

▼ AI 導讀——獲取核心信息

- Lab4AI.cn提供免費的AI 翻譯和AI 導讀工具輔助論文閱讀;
- 支持投稿復現,動手復現感興趣的論文;
- 論文復現完成后,您可基于您的思路和想法,開啟論文創新。
Lab4AI.cn 來送禮啦~
? 注冊有禮,注冊即送 30 元代金券
https://www.lab4ai.cn/register?utm_source=jssq_bky立即體驗
? 入群有禮,入群即送 20 元代金券
??

本文由 AI 深度解讀,轉載請聯系授權。關注“大模型實驗室 Lab4AI”,第一時間獲取前沿 AI 技術解析!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號