PyTorch從入門到放棄之數據模塊
Dataset 和 DataLoader 都 是 用 來 幫 助 我 們 加 載 數 據 集 的 兩 個 重 要 工 具類。 Dataset 用來構造支持索引的數據集。
在訓練時需要在全部樣本中拿出小批量數據參與每次的訓練,因此我們需要使用 DataLoader ,即 DataLoader 是用來在 Dataset 里取出一組數據 (mini-batch)供訓練時快速使用的。
Dataset簡介及用法
Dataset 本質上就是一個抽象類,可以把數據封裝成 Python 可以識別的數據結構。Dataset 類不能實例化,所以在使用 Dataset 的時候,我們需要定義自己的數據集類,也是 Dataset 的子類,來繼承 Dataset 類的屬性和方法。Dataset 可作為 DataLoader 的參數傳入 DataLoader ,實現基于張量的數據預處理。Dataset 主要有兩種類型,分別為 Map-style datasets 和 Iterable-style datasets 。
Map-style datasets類型
該類型實現了 getitem() 和 len() 方法,它代表數據的索引到真正數據樣本的映射。也就是說,使用這種方式讀取的數據并非直接直接把所有數據讀取出來,而是讀取數據的索引或者鍵值。其中,列表或者數組類型的數據讀取的就是索引,而字典類型的數據讀取的就是鍵值。在訪問時,用dataset[idx]訪問idx對應的真實數據。這種類型的數據也是使用最多的類型。
Iterable-style datasets類型
該類型實現了 iter() 方法,與上述類型不同之處在于,他會將真實的數據全部載入,然后在整個數據集上進行迭代。如果隨機讀取的情況不能實現或者代價太大就用這種讀取方式。這種讀取數據的方式比較適合處理流數據
Dataset 作為一個抽象類,需要定義其子類來實例化。所以需要自己定義其子類或者使用已經定義好的子類。
(1)自定義子類
- 必須要繼承已經內置的抽象類 dataset
- 必須要重寫其中的 init() 方法、 getitem() 方法和 len() 方法
- 其中 getitem() 方法實現通過給定的索引遍歷數據樣本, len() 方法實現返回數據的條數
定義一個MyDataset類繼承Dataset抽象類,其中pass為占位符,并且改寫其中的三個方法
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
這里定義了一個MyDataset類繼承Dataset抽象類,并且改寫其中的三個方法。在創建的dataset類中可根據用戶本身的需求對數據進行處理。可獨立編寫的數據處理函數,在__getitem__()函數中進行調用;或者直接將數據處理方法寫在__getitem__()函數中或者__init__()函數中,但__getitem__()函數必須根據index返回響應的值,該值會通過index傳到DataLoader中進行厚涂的Batch批量處理。
在創建的dataset類中可根據自己的需求對數據進行處理,以時間序列使用為示例,輸入3個時間步,輸出1個時間步,batch_size=5
import torch
from torch.utils.data import Dataset
class GetTrainTestData(Dataset):
def __init__(self, input_len, output_len, train_rate, is_train=True):
super().__init__()
# 使用sin函數返回10000個時間序列,如果不自己構造數據,就使用numpy,pandas等讀取自己的數據為x即可。
# 以下數據組織這塊既可以放在init方法里,也可以放在getitem方法里
self.x = torch.sin(torch.arange(0, 1000, 0.1))
self.sample_num = len(self.x)
self.input_len = input_len
self.output_len = output_len
self.train_rate = train_rate
self.src, self.trg = [], []
if is_train:
for i in range(int(self.sample_num*train_rate)-self.input_len-self.output_len):
self.src.append(self.x[i:(i+input_len)])
self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])
else:
for i in range(int(self.sample_num*train_rate), self.sample_num-self.input_len-self.output_len):
self.src.append(self.x[i:(i+input_len)])
self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])
print(len(self.src), len(self.trg))
def __getitem__(self, index):
return self.src[index], self.trg[index]
def __len__(self):
return len(self.src) # 或者return len(self.trg), src和trg長度一樣
實例化定義好的Dataset子類GetTrainTestData
data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True)
data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False)

(2)已經定義好的內置子類
除了自己定義子類繼承Dataset外,還可以使用PyTorch提供的已經被定義好的子類,如TensorDataset和IterableDataset。
對 于 給 定 的 tensor 數 據 , TensorDataset 是 一 個 包 裝 了 Tensor 的Dataset 子類,傳入的參數就是張量,每個樣本都可以通過 Tensor 第一個維度的索引獲取,所以傳入張量的第一個維度必須一致。
PyTorch官方給出的TensorDataset類的定義:
class TensorDataset(Dataset[Tuple[Tensor, ...]]):
r"""Dataset wrapping tensors.
Each sample will be retrieved by indexing tensors along the first dimension.
Args:
*tensors (Tensor): tensors that have the same size of the first dimension.
"""
tensors: Tuple[Tensor, ...]
def __init__(self, *tensors: Tensor) -> None:
assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors), "Size mismatch between tensors"
self.tensors = tensors
def __getitem__(self, index):
return tuple(tensor[index] for tensor in self.tensors)
def __len__(self):
return self.tensors[0].size(0)
所以這個類的實例化有兩個參數,分別為data_tensor(Tensor)樣本數據和target_tensor(Tensor)樣本標簽。
使用TensorDataset:
import torch
from torch.utils.data import TensorDataset
src = torch.sin(torch.arange(1, 1000, 0.1))
trg = torch.cos(torch.arange(1, 1000, 0.1))
于是可以直接實例化已定義好的Dataset子類TensorDataset
data = TensorDataset(src, trg)
DataLoader簡介及用法
Dataset 和 DataLoader 是一起使用的,在模型訓練的過程中不斷為模型提供數據,同時,使用 Dataset 加載出來的數據集也是
DataLoader 的第一個參數。所以, DataLoader 本質上就是用來將已經加載好的數據以模型能夠接收的方式輸入到即將訓練的模型中去。
幾個深度學習模型訓練時涉及的參數:
(1)Data_size:所有數據的樣本數量。
(2)Batch_size:每個Batch加載多少個樣本。
(3)Batch:每一批放進module訓練的樣本叫一個Batch。
(4)Epoch:模型把所有樣本訓練完畢一次叫做一個Epoch。
(5)Iteration:所有數據共分成了幾個Batch,即訓練幾次才能夠便利所有樣本/數據。
(6)Shuffle:在抽取Batch之前是否將樣本全部打亂順序。
數據的輸入過程如下圖所示。

Data_size=10 , Batch_size=3 ,一次 Epoch 需要四次 Iteration ,第一列為所有樣本,第二列為打亂之后的所有樣本,由于 Batch_size=3 ,所以通過 DataLoader輸入了 4 個 batch ,包括最后一個數量已經不夠 3 個的 Batch4 ,里邊只包含sample3
官方給出的DataLoader定義:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None,*, prefetch_factor=2,
persistent_workers=False)
參數說明:
dataset: 通過Dataset加載進來的數據集。
batch_size:每個Batch加載多少個樣本。
shuffle: 是否打亂輸入數據的順序,設置為True時,調用RandomSample進行隨機索引。
sampler: 定義從數據集中提取樣本的策略,若指定,就不能用shuffle函數隨機索引,其取值必須為False。
batch_sampler: 批量采樣,每次返回一個Batch大小的索引,默認設置為None,和batch_size、shuffle等參數是互斥的。
num_workers: 用多少子進程加載數據。0表示數據將在主進程中加載,根據自己的計算資源配置選定。
collate_fn: 將一小段數據合并成數據列表以形成一個Batch。
pin_memory:是否在將張量返回之前將其復制到Cuda固定的內存中。
drop_last: 設置了batch_size的數目后,最后一批數據未必是設置的數目,有可能會小一些,這時需要丟棄這些數據。
timeout:設置數據表讀取的超時時間,但超過這個時間還沒讀取到數據就會報錯,不能為負。
worker_init_fn:是否在數據導入前和步長結束后根據工作子進程的ID逐個按照順序導入數據,默認為None。
prefetch_factor:每個worker提前加載的Sample數量。
persistent_workers: 如果為True,DataLoader將不會終值worker進程,直到dataset迭代完成。
將Dataset讀取的數據輸入到DataLoader中。
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
class GetTrainTestData(Dataset):
def __init__(self, input_len, output_len, train_rate, is_train=True):
super().__init__()
# 使用sin函數返回10000個時間序列,如果不自己構造數據,就使用numpy,pandas等讀取自己的數據為x即可。
# 以下數據組織這塊既可以放在init方法里,也可以放在getitem方法里
self.x = torch.sin(torch.arange(1, 1000, 0.1))
self.sample_num = len(self.x)
self.input_len = input_len
self.output_len = output_len
self.train_rate = train_rate
self.src, self.trg = [], []
if is_train:
for i in range(int(self.sample_num*train_rate)-self.input_len-self.output_len):
self.src.append(self.x[i:(i+input_len)])
self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])
else:
for i in range(int(self.sample_num*train_rate), self.sample_num-self.input_len-self.output_len):
self.src.append(self.x[i:(i+input_len)])
self.trg.append(self.x[(i+input_len):(i+input_len+output_len)])
print(len(self.src), len(self.trg))
def __getitem__(self, index):
return self.src[index], self.trg[index]
def __len__(self):
return len(self.src) # 或者return len(self.trg), src和trg長度一樣
data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True)
data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False)
data_loader_train = DataLoader(data_train, batch_size=5, shuffle=False)
data_loader_test = DataLoader(data_test, batch_size=5, shuffle=False)
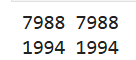
for idx, train in enumerate(data_loader_train):
print(idx, train)
break
文章推薦
| NumPy從入門到放棄 | https://mp.weixin.qq.com/s/EocThNWhQlI2zeLcUApsQQ |
|---|---|
| Pandas從入門到放棄 | https://mp.weixin.qq.com/s/mSkA5KvL1390Js8_1ZBiyw |
| SciPy從入門到放棄 | https://mp.weixin.qq.com/s/MulhzVRvWbaDUjfNPHN8qA |
| Scikit-learn從入門到放棄 | https://mp.weixin.qq.com/s/L0tKz9JFnsgrzSCXDswbRA |
| PyTorch從入門到放棄之張量模塊 | http://www.rzrgm.cn/kohler21/p/18392248 |
歡迎關注公眾號:愚生淺末。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號