
完美的統計信息直方圖只有幾個階梯數(steps)
2025-03-27 22:40 瀟湘隱者 閱讀(67) 評論(0) 收藏 舉報本文是翻譯官方博客Perfect statistics histogram in just few steps[1],如有翻譯不當或錯誤的地方,敬請指正或提醒.翻譯這篇文章,是因為它解答了我的一個困惑,為什么使用fullscan 更新統計信息后,統計信息的直方圖的階梯數反而變得更少了? 傳統觀念中,直方圖的階梯數似乎是越多越精確. 如果你也發現了這些細節現象,那么就看譯文吧!
本周,團隊兩次遇到了有關統計信息的類似問題:"為什么使用完全掃描更新統計信息會導致直方圖的階梯數/步長數比抽樣掃描(這里只指按少于100%的采樣比例更新統計信息)更新統計信息時的少呢? 答案是:直方圖階梯/步長(histogram steps)的數量可以比字段不同值(distinct values)的數量更少"。 對于具有完美分布(frequency* = 1)的直方圖,合并直方圖將少到只有三個階梯/步長,因為這是準確描繪底層數據分布所需的階梯數。
頻率(Frequency)通過將行數和密度相乘來計算(計算公式為row count * density)。 密度計算為 1/不同值計數。有關更多信息,請參閱統計信息的官方文檔[2]頁面 。
讓我們來看幾個可以觀察到這種情況的例子:使用 IDENTITY (或任何不可重復的整數)和使用 GUID(特別是 NEWID ):
創建一個以 UNIQUEIDENTIFIER 列或 IDENTITY 作為主鍵的新表。兩者在設計上都是獨一無二的。
IF NOT EXISTS (SELECT [object_id] FROM sys.objects (NOLOCK) WHERE [object_id] = OBJECT_ID(N'[CustomersTableGuid]') AND [type] IN (N'U'))
CREATE TABLE CustomersTableGuid
(
ID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
)
GO
IF NOT EXISTS (SELECT [object_id] FROM sys.objects (NOLOCK) WHERE [object_id] = OBJECT_ID(N'[CustomersTableIdent]') AND [type] IN (N'U'))
CREATE TABLE CustomersTableIdent
(
ID int IDENTITY(1,1) NOT NULL PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
)
GO
插入 100 萬條記錄。
SET NOCOUNT ON;
DECLARE @i INT = 0
WHILE (@i <= 1000000)
BEGIN
INSERT INTO CustomersTableGuid (FirstName, LastName)
VALUES ('FirstName' + CAST(@i AS VARCHAR),'LastName' + CAST(@i AS VARCHAR))
INSERT INTO CustomersTableIdent (FirstName, LastName)
VALUES ('FirstName' + CAST(@i AS VARCHAR),'LastName' + CAST(@i AS VARCHAR))
SET @i +=1
END
GO
讓我們使用 FULLSCAN 更新統計數據。
UPDATE STATISTICS CustomersTableGuid WITH FULLSCAN
GO
UPDATE STATISTICS CustomersTableIdent WITH FULLSCAN
GO
現在,讓我們查找統計信息:
驗證抽樣記錄數和直方圖階梯數/步長,每一條統計數據有3個階梯數/步長,抽樣率為100%(rows = rows_sampled)。
SELECT OBJECT_NAME(stat.[object_id]) AS [TableName], sp.stats_id, name,
last_updated, rows, rows_sampled, steps, unfiltered_rows, modification_counter
FROM sys.stats AS stat
CROSS APPLY sys.dm_db_stats_properties(stat.[object_id], stat.stats_id) AS sp
WHERE stat.[object_id] = OBJECT_ID('CustomersTableGuid')
OR stat.[object_id] = OBJECT_ID('CustomersTableIdent');
GO
注釋:原文鏈接的圖裂了,個人實驗略有區別,有一條統計信息直方圖的階梯數為4,不是3,可能跟實驗環境有關系(SQL Server 2019),如下截圖所示:

查看ID列的直方圖,我們可以看到每個統計數據都有3個階梯數。SQL Server 會將多個直方圖階梯壓縮為盡可能少的階梯/步長, 而不會損失直方圖質量。正如預期的那樣,一個完美的數據分布的全表掃描(fullscan),因此可以將直方圖壓縮為僅3個階梯數。
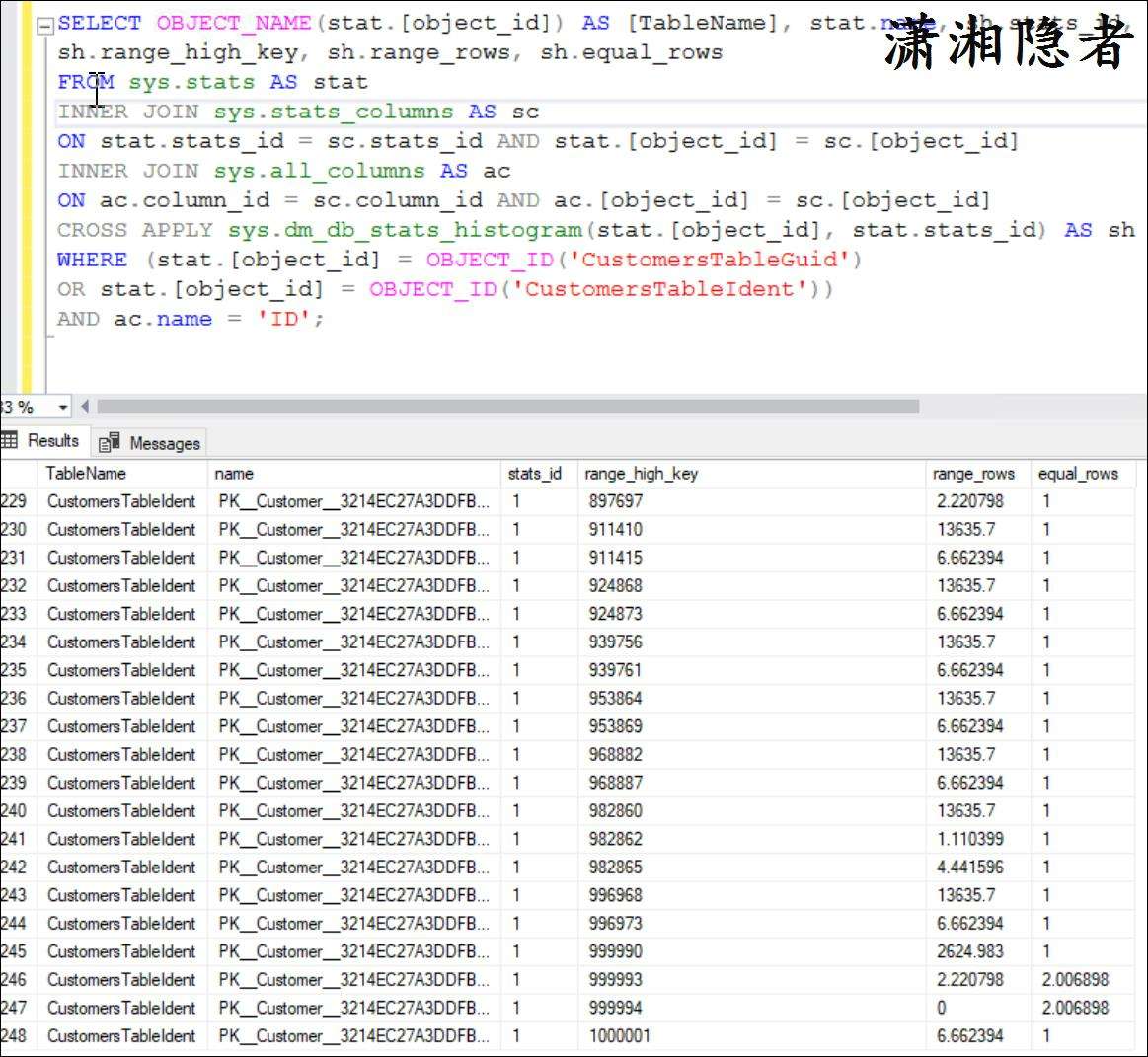
SELECT OBJECT_NAME(stat.[object_id]) AS [TableName], stat.name, sh.stats_id,
sh.range_high_key, sh.range_rows, sh.equal_rows
FROM sys.stats AS stat
INNER JOIN sys.stats_columns AS sc
ON stat.stats_id = sc.stats_id AND stat.[object_id] = sc.[object_id]
INNER JOIN sys.all_columns AS ac
ON ac.column_id = sc.column_id AND ac.[object_id] = sc.[object_id]
CROSS APPLY sys.dm_db_stats_histogram(stat.[object_id], stat.stats_id) AS sh
WHERE (stat.[object_id] = OBJECT_ID('CustomersTableGuid')
OR stat.[object_id] = OBJECT_ID('CustomersTableIdent'))
AND ac.name = 'ID';
GO
讓我們以表CustomersTableIdent的ID字段的直方圖的階梯數為例:
第一階梯(step)的值為 1;
第二階梯(step)有999,998行記錄沒有重復(它的密度為1);
第三階梯(step)的最后一行為 1,000,001。
現在讓我們用一個較小的采樣比例更新統計數據(可以嘗試任何你想要的值),并查看統計信息的數據。SQL Server 提取頁面數據,然后將其推斷為完整分布。因此,正如預期的那樣,抽樣分布只是近似的,并且作為推斷,這就是為什么我們看到的頻率接近1,但不完全是 1。
原文圖片裂了,下面是我的實驗截圖。

UPDATE STATISTICS CustomersTableGuid WITH SAMPLE 90 PERCENT
GO
UPDATE STATISTICS CustomersTableIdent WITH SAMPLE 90 PERCENT
GO
總之,我們在這里所做的是將 1,000,001 個唯一鍵插入表中。全掃描的直方圖有3個階梯/步長,反映了這種完美的數據分布。另一方面,使用采樣統計時,SQL Server會隨機抽取頁面值的數據,然后推斷其分布。
更重要的是,統計信息對象中的階梯數越多并不總是意味著有更好的鍵值覆蓋,以及更好的估計/預估。在統計信息[3]文檔頁面上的中可以找到更多信息,特別是統計信息是如何構建的。
關于GUID的一點建議:我的建議是不要將它們用作謂詞,或者用于任何需要對范圍掃描進行良好估計的地方。如果你真的必須將它們用作表的主鍵以保持唯一性,從而盡可能利用它來進行單例查找,那么GUID就足夠好了。請使用NEWSEQUENTIALID生成而不是NEWID,將主鍵創建為非聚集索引,并獲得一個可以滿足良好聚集鍵要求的替代鍵。 。
1: https://techcommunity.microsoft.com/blog/sqlserver/perfect-statistics-histogram-in-just-few-steps/385734
[2]2: https://learn.microsoft.com/en-us/sql/relational-databases/statistics/statistics?view=sql-server-ver16#densityvector
[3]3: https://learn.microsoft.com/en-us/sql/relational-databases/statistics/statistics?view=sql-server-ver16


 浙公網安備 33010602011771號
浙公網安備 33010602011771號