
大數據處理框架:Hadoop、Spark、Flink的比較與選擇
轉載自博客:https://baijiahao.baidu.com/s?id=1775390148620128027&wfr=spider&for=pc
隨著大數據時代的到來,處理海量數據成為了各個領域的關鍵挑戰之一。為了應對這一挑戰,多個大數據處理框架被開發出來,其中最知名的包括Hadoop、Spark和Flink。本文將對這三個大數據處理框架進行比較,以及在不同場景下的選擇考慮。
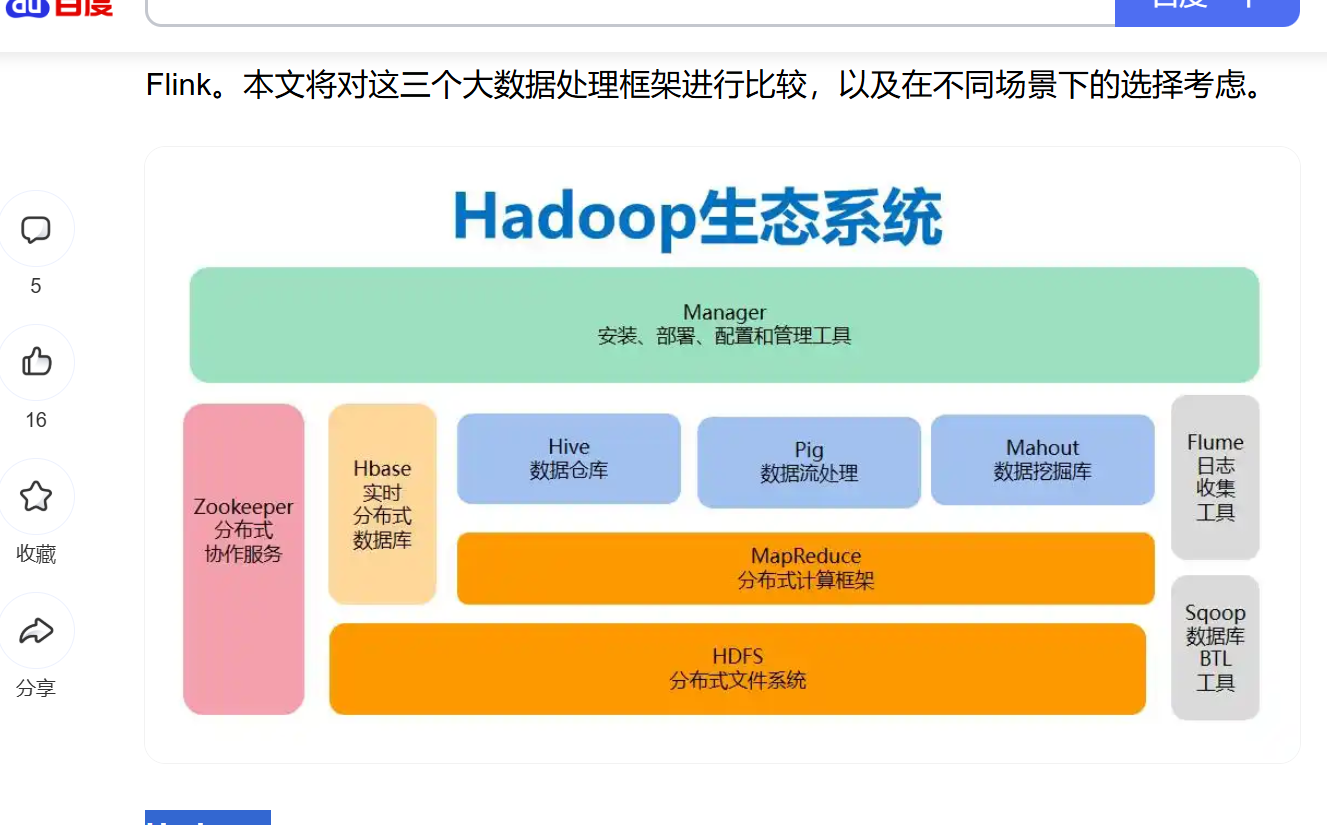
Hadoop
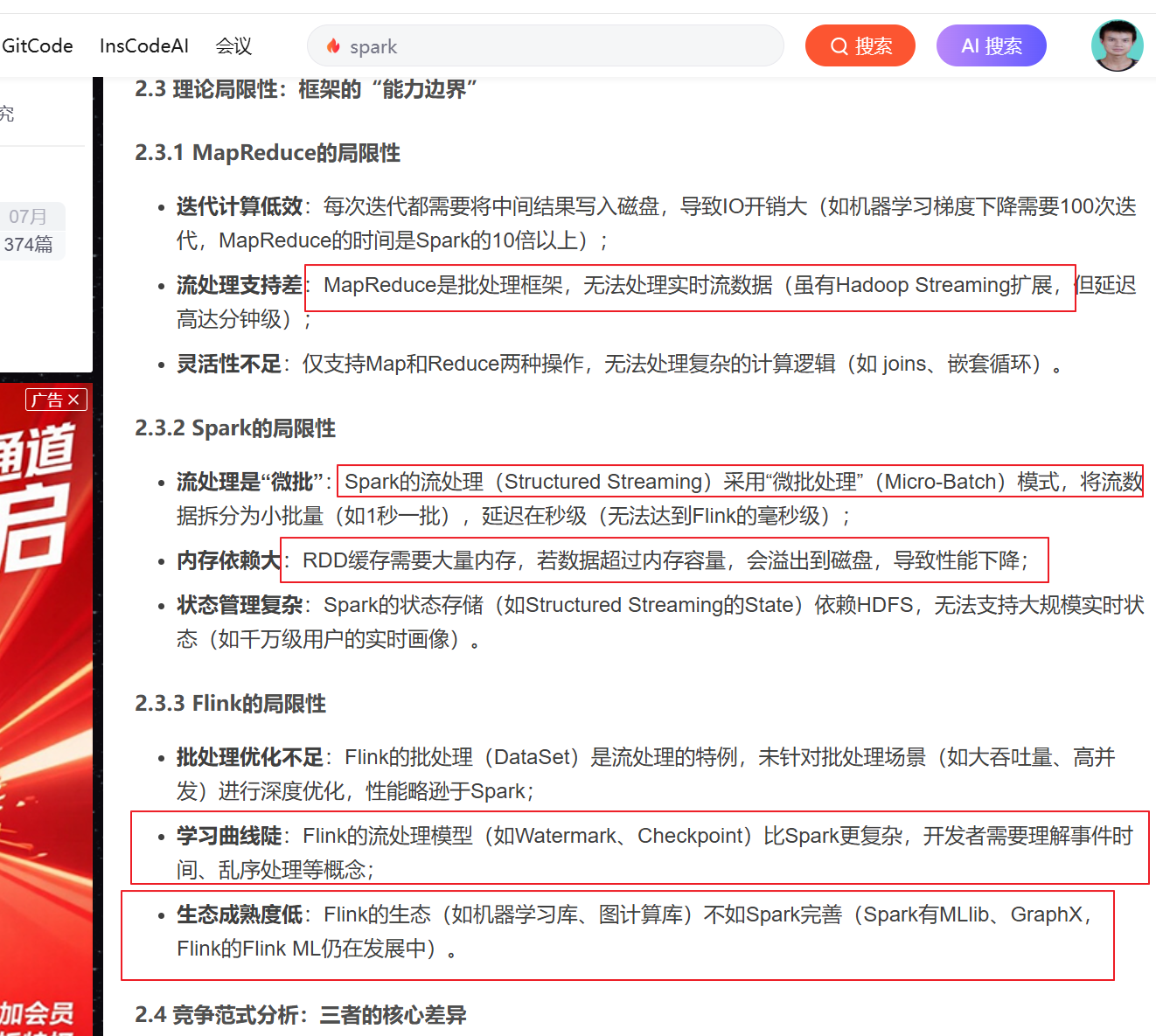
Hadoop是大數據處理領域的先驅,其核心組件包括Hadoop Distributed File System(HDFS)和MapReduce。HDFS負責將大數據分布式存儲在多臺服務器上,而MapReduce則負責將數據分成小塊進行并行處理。Hadoop適用于批處理任務,但在實時數據處理方面表現不佳。

優點:
-
良好的可伸縮性,適用于處理大規模數據。
-
成熟穩定,得到了廣泛的應用。
-
適合批處理作業,特別是離線數據分析。
缺點:
-
實時性差,適用性有限。
-
編寫MapReduce任務較為繁瑣。

Spark
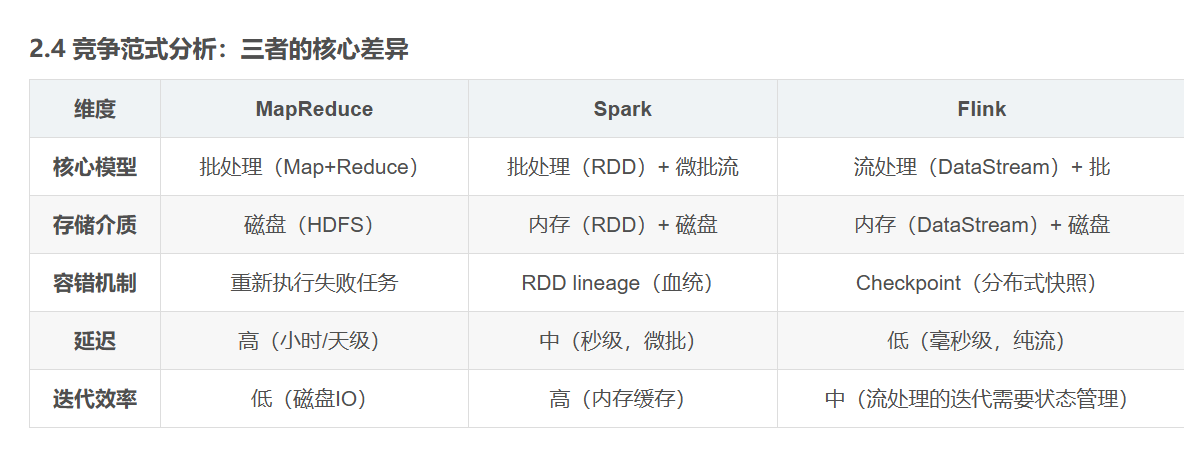
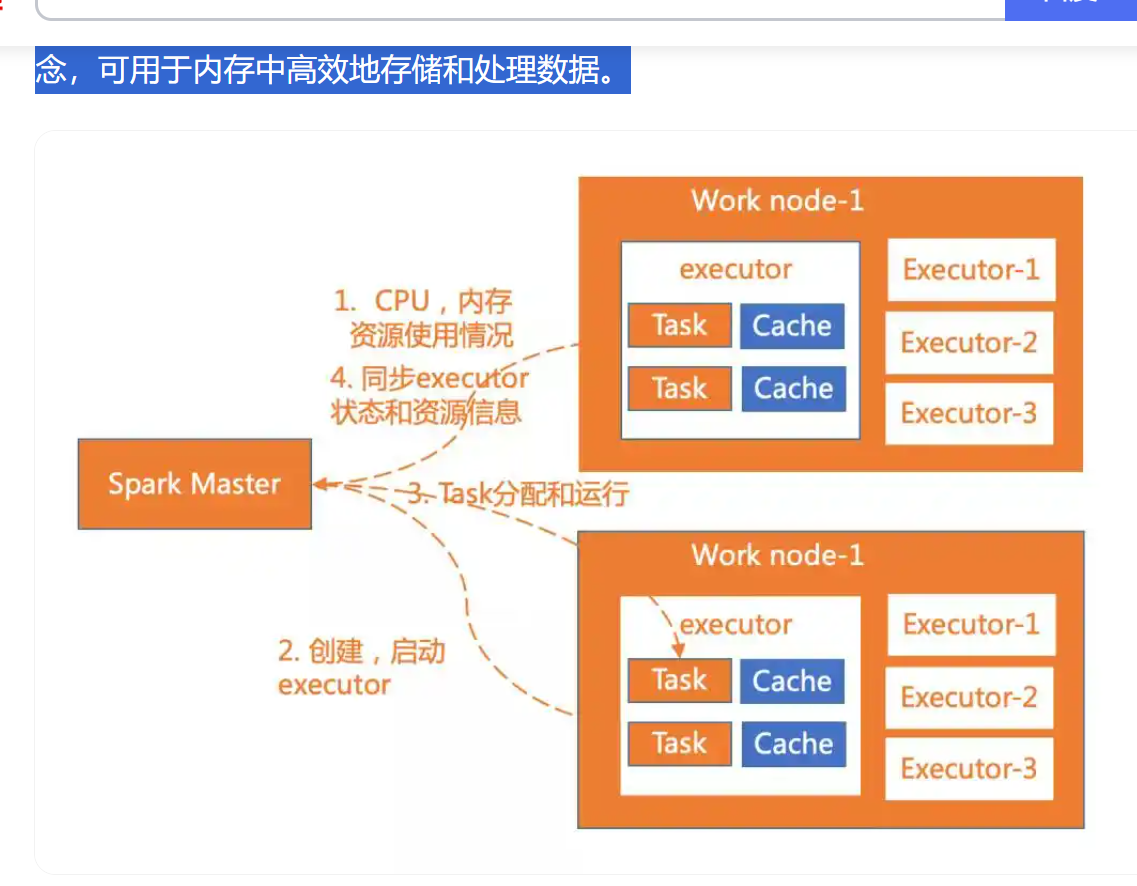
Spark是一個快速、通用的大數據處理框架,擁有比Hadoop更好的性能和更廣泛的應用領域。它支持多種編程語言(如Scala、Python、Java)和多種數據處理模式(如批處理、流處理、機器學習等)。Spark內置了彈性分布式數據集(RDD)的概念,可用于內存中高效地存儲和處理數據。


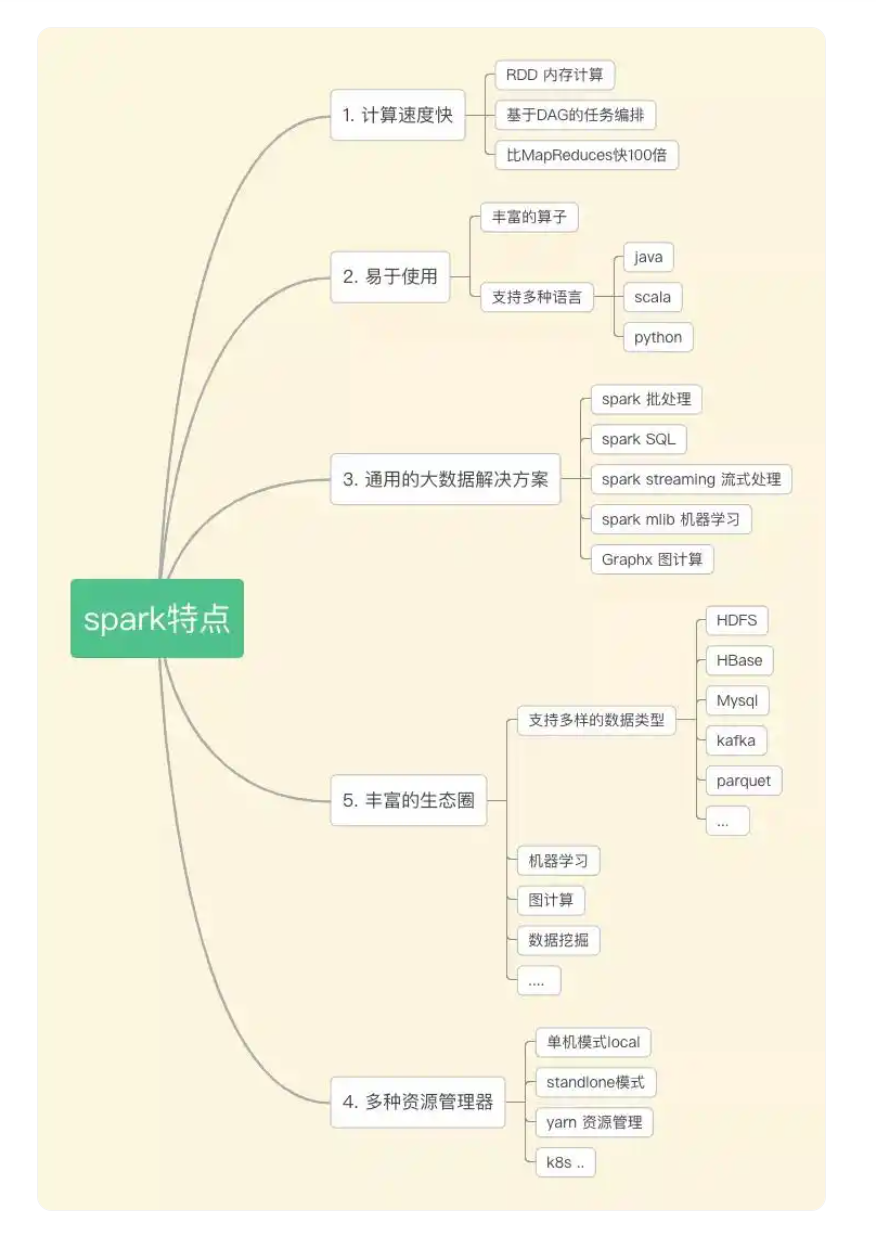
Flink
Flink是一個強大的流式處理框架,能夠實現低延遲的實時數據處理。與Spark相比,Flink專注于流處理,可以提供更好的事件處理和狀態管理。它還支持批處理任務,因此在一些情況下可以替代Hadoop和Spark。

優點: 低延遲的實時數據處理,適用于需要實時反饋的應用。 支持流處理和批處理,具有更好的事件處理和狀態管理能力。 適用于復雜的事件處理和數據流分析。 缺點: 相對較新,相比Hadoop和Spark社區規模較小。 對于某些特定的批處理任務,性能可能不如Spark。
如何選擇?
選擇適合的大數據處理框架取決于項目的需求和目標:

Hadoop: 如果你主要需要處理離線的大規模批處理任務,Hadoop可能是一個不錯的選擇。 Spark: 如果你需要在大規模數據上進行快速的數據分析和處理,而且希望有更好的編程靈活性,Spark可能是更好的選擇。 Flink: 如果你需要低延遲的實時數據處理,尤其是對于事件處理和流分析,Flink是一個優秀的選擇。

posted on 2025-10-26 21:53 luzhouxiaoshuai 閱讀(27) 評論(0) 收藏 舉報


 浙公網安備 33010602011771號
浙公網安備 33010602011771號