APEX實戰第5篇:利用APEX程序直觀體驗向量近似檢索能力
2025-09-29 08:14 AlfredZhao 閱讀(120) 評論(0) 收藏 舉報在圈內朋友看來,Oracle 數據庫的 多模能力 已經不是什么新鮮話題。它不僅在關系型數據管理方面獨樹一幟,還能夠在同一個數據庫引擎中,支持幾乎所有主流的數據模型 —— 從 JSON、XML、時序、空間,到圖數據、區塊鏈,再到如今最火的向量數據與 AI。
利用 Oracle APEX,可以更簡單、高效地展示數據庫的多模能力。本文將通過一個 簡明示例,演示如何使用 APEX 程序 直觀地體驗向量近似檢索(Approximate Nearest Neighbor, ANN) 的能力,從而讓多模數據的操作與查詢可視化、易上手。
APEX實現功能:文本內容的近似最近鄰檢索(ANN) 功能。
- 1.庫內Embedding模型準備
- 2.APEX簡明示例
- 3.其他細節信息參考
1.庫內Embedding模型準備
我們知道,Oracle 23ai數據庫原生支持向量數據類型的存儲,可以支持直接在任意數據庫表對象上增加一個或多個vector數據類型的列,專門用于存儲向量數據格式。
具體如何存儲向量化的數據呢?
- 首先我們需要一個Embedding模型,可以對指定的內容向量化,然后將向量化后的結果直接存儲到vector數據類型的字段中;
如果還沒有Embedding模型可用,不必折騰,Oracle本身支持庫內加載onnx模型,具體可以參考之前文章《曾經風光無限的 Oracle DBA 已經落伍了嗎?》中提到過的方法,唯一需要注意,當時是直接使用了官方文檔介紹的all_MiniLM_L12_v2.onnx模型,這里筆者實際測試發現其對中文的匹配效果并不理想,所以換用另一個Embedding模型bge-base-zh-v1.5.onnx,為了方便大家動手操作,這里貼出導入此模型的關鍵步驟:
--刪除模型(可選)
exec DBMS_VECTOR.DROP_ONNX_MODEL(model_name => 'BGE_BASE', force => true);
--加載導入模型:
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL(
directory => 'DM_DUMP',
file_name => 'bge-base-zh-v1.5.onnx',
model_name => 'BGE_BASE',
metadata => JSON('{"function" : "embedding", "embeddingOutput" : "embedding", "input": {"input": ["DATA"]}}'));
END;
/
--查詢導入的EMBEDDING模型:
select model_name, algorithm, mining_function from user_mining_models where model_name='BGE_BASE';
--測試EMBEDDING模型可用,可以正常返回向量化結果
SELECT VECTOR_EMBEDDING(BGE_BASE USING 'Hi, Alfred' as DATA) AS embedding;
2.APEX簡明示例
隨便找一張表,對其中任意一個想做近似檢索的文本列字段,針對該表增加一個向量列。然后使用上一步配置好的庫內Embedding模型進行向量化處理。
我這里就以之前的Demo為基礎,針對t_history表中 content列的內容進行向量化,結果存儲到表中列v中,數據類型是vector。
關鍵步驟:
--1.向量字段存儲向量化后的內容,只是測試下模型可用
UPDATE t_history
SET v = VECTOR_EMBEDDING(BGE_BASE USING content AS DATA)
where username = 'test';
--2.分批處理更新,向量字段存儲向量化后的內容,可配置到APEX頁面中前臺調用
DECLARE
CURSOR c_history IS
SELECT rowid AS rid, content
FROM t_history
WHERE content is not null
and (v IS NULL or v_needs_update=1); -- 只處理未向量化和需要更新向量化的行
BEGIN
FOR r IN c_history LOOP
UPDATE t_history
SET v = VECTOR_EMBEDDING(BGE_BASE USING r.content AS DATA)
WHERE rowid = r.rid;
END LOOP;
COMMIT;
END;
/
--3.APEX可以通過報表直觀展現近似檢索功能
SELECT type, week, day, history_date, content
FROM t_history
where username = :APP_USER
ORDER BY VECTOR_DISTANCE(v, VECTOR_EMBEDDING(BGE_BASE USING :P7_SEARCH_TEXT AS DATA))
FETCH APPROX FIRST 5 ROWS ONLY;
APEX近似檢索效果:
這里首先我在表中的content列中,初始化了一些測試數據,比如針對愛情、開發等主題,模擬用戶日常操作,錄入一些與主題相關的內容,不知道該具體輸入啥內容的同學,可以直接讓LLM幫你生成哈。
然后,我們到APEX頁面上進行檢索測試。
輸入愛情,點擊搜索,就可以從該用戶歷史記錄過的所有內容中,檢索到它認為向量近似的前5個結果列出來,可以看到結果都與愛情相關,但未必都包含愛情關鍵字,比如第5條結果描述的單戀場景:

同樣,如果輸入開發,點擊搜索,結果就是這樣,很多結果并沒有開發關鍵字,但表述其實都跟軟件開發這個主題密不可分:

這也是向量近似檢索的魅力所在,歷史傳統數據庫無論是進行精確或模糊搜索,都只能基于關鍵字匹配,但如今,向量的近似檢索使其可以直接依據語義進行搜索。
3.其他細節信息參考
前面已經展示了實際效果,達成了目標,本節主要補充一些信息,方便讀者更好地理解實現細節。
我這里在對t_history表處理的過程中,針對向量列的判斷里,有寫到 (v IS NULL or v_needs_update=1); -- 只處理未向量化和需要更新向量化的行,還特別注釋說明了下,這是因為最初我只處理了未向量化的內容,但是我實際在錄入文本內容時,存在更新原內容的需求。而原內容因為已經做過向量化,向量部分不會更新,所以搜索會遇到問題,因此需要fix這個更新場景的bug,增加一列,并加入到對應的邏輯判斷中:
--fix更新bug
ALTER TABLE t_history ADD v_needs_update NUMBER(1) DEFAULT 0;
這樣,當發現有錄入或更新內容,都可以做到能提示最終用戶,需要處理新內容。
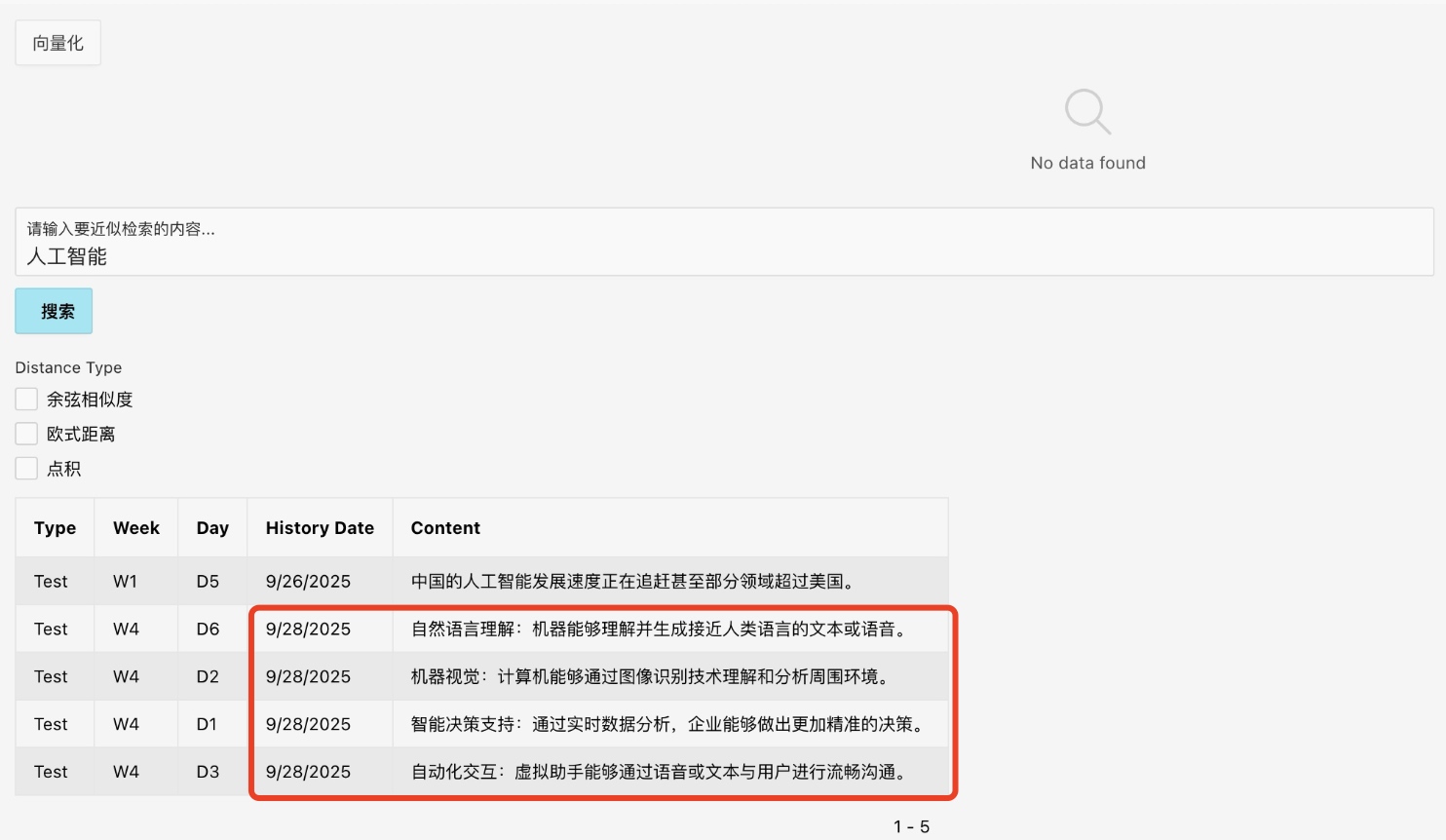
比如用戶想近似檢索人工智能相關的內容,下面紅色數字就表示,表中數據存在更新內容,但還未向量化的情況,檢索結果可能存在不準確的情況,這個例子就是如此,除了第一條記錄,其他和人工智能其實關系并不大:

此時,用戶可以手工點擊向量化,將最新更新的一些內容向量化,再次檢索,發現除了第一條結果,其他已經不一樣了,說明新的內容(這里可以通過History Date列快速識別)確實存在一些比歷史數據更匹配人工智能主題的結果:
也許看到這里,有讀者會有疑問,為何不直接設計,在更新內容時直接就向量化呢?
嗯,其實也不是不可以,看應用要求,只是我這里這樣設計更符合演示要求而已。同時也為了能讓大家直觀看到,近似檢索,實際上檢索結果就是distance的排名,如果要求展示的記錄數,本身數據集中就沒有足夠數量匹配的,也會檢索出來一些不太相干的內容。
此外,如果數據量較大,基于性能考量,建議創建HNSW(Hierarchical Navigable Small World)類型的向量索引,同時注意Top-K兩種寫法差異:
--4.創建HNSW索引
create vector index t_history_hnsw_idx on t_history(v)
organization inmemory neighbor graph
distance COSINE
with target accuracy 95;
--精確 Top-K
SELECT type, week, day, history_date, content
FROM t_history
ORDER BY VECTOR_DISTANCE(v, VECTOR_EMBEDDING(BGE_BASE USING '愛情' AS DATA))
FETCH FIRST 5 ROWS ONLY;
--近似 Top-K,增加了APPROX關鍵字:
SELECT type, week, day, history_date, content
FROM t_history
ORDER BY VECTOR_DISTANCE(v, VECTOR_EMBEDDING(BGE_BASE USING '愛情' AS DATA))
FETCH APPROX FIRST 5 ROWS ONLY;
至此,我們就利用APEX程序直觀體驗了向量近似檢索能力。
轉載請注明原文鏈接:http://www.rzrgm.cn/jyzhao/p/19118041/apex-shi-zhan-di5pian-li-yongapex-cheng-xu-zhi-gua
?? 感謝閱讀,歡迎關注我的公眾號 「趙靖宇」


 浙公網安備 33010602011771號
浙公網安備 33010602011771號