曾經(jīng)風光無限的 Oracle DBA 已經(jīng)落伍了嗎?
2025-06-12 00:50 AlfredZhao 閱讀(2461) 評論(17) 收藏 舉報先講一個殘酷的事實,Oracle DBA,若仍停留在純粹的運維方向,未來的路將會越走越窄,尤其是在國內(nèi)的特殊環(huán)境下,可以說是前途渺茫,舉步維艱。
既然如此,那Oracle DBA們應該如何破局呢?
- Part1.回顧DBA歷史
- Part2.走進AI時代
- Part3.如何破局重生?
Part1:回顧DBA歷史
國內(nèi)最早期從事Oracle DBA崗位的人,如今基本已經(jīng)退休或接近退休狀態(tài),這些前輩們,除去混日子的不算,其中運氣好的早已實現(xiàn)財務自由,運氣差的也基本能達到中產(chǎn)水平,那一代人是充分享受到了屬于那個時代的紅利。
不過,真正的一名合格運維DBA所付出的辛苦絕對遠高于IT行業(yè)各技術(shù)崗的平均水平,無論是在他們漫長技術(shù)積累的學習之路上,還是從無數(shù)個深夜中熬著心血去保障、值守、救火的身影中,都可以了解到他們的高回報并不是純時代紅利,也是實實在在的付出了太多代價換來的。
無奈時代變化太快,后面的故事就是,看到這行表面光鮮的從業(yè)者越來越多,各種水平參差不齊的培訓機構(gòu)泛濫成災,導致供大于求,加之市場上同時出現(xiàn)很多專業(yè)做這方面服務的公司,同時Oracle數(shù)據(jù)庫本身也變得越來越穩(wěn)定,在各種因素綜合影響之下,讓Oracle DBA不再是傳奇,最終紅利徹底消失,已和其他普通崗位沒啥區(qū)別,有時還會被同行戲謔曾經(jīng)省吃儉用花大幾萬塊考下來的OCM認證早已沒了含金量。
所以,這么多年來苦心專研Oracle是都白學了?曾經(jīng)風光無限的 Oracle DBA 已經(jīng)落伍了嗎?
Part2:走進AI時代
現(xiàn)如今,整個社會都開始走進了AI時代。不過別擔心,Oracle DBA 傳統(tǒng)運維方向有可能不再景氣,但Oracle技術(shù)本身可并不落伍,而且一直都是引領技術(shù)前沿的。
這不,最近大火的AI,Oracle也是有全套解決方案與之匹配的。掌握了這些技能,不僅能讓你瞬間領悟Oracle的Vector Search等新的技能,還能讓自身緊跟AI相關(guān)技術(shù)前沿。
之前和一些從事Oracle DBA的朋友們閑聊,發(fā)現(xiàn)最難轉(zhuǎn)變的是一些使用習慣。很多老的觀念還是把Oracle作為純粹的老牌關(guān)系型數(shù)據(jù)庫,對其多模融合的相關(guān)技術(shù)置若罔聞,更別提什么AI相關(guān)技術(shù)。
所以導致有些小伙伴雖然早已聽聞Oracle 23ai和AI的緊密結(jié)合,但是具體到落地究竟怎么用,實在是丈二和尚摸不著頭腦。
Part3:如何破局重生?
紙上得來終覺淺,絕知此事要躬行。
如果沒有特別的境遇,最好的起步指導材料依然來源于Oracle官方文檔,關(guān)于AI,可以看下《Oracle AI Vector Search User's Guide》這本書。書中有一章節(jié),就非常適合AI新手來快速體驗到Oracle的AI到底能做些啥,它就是:
- SQL Quick Start Using a Vector Embedding Model Uploaded into the Database
https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/sql-quick-start-using-vector-embedding-model-uploaded-database.html
該文章提供了一組實際可操作的命令,幫助我們快速了解最核心的Oracle AI VECTOR Search。現(xiàn)在就帶大家一起體驗下這個過程,一起輕松踏入AI的浪潮之中。
文章說我們需要準備三個類似于以下內(nèi)容的文件:
- 1.Embedding Model
- 2.json-relational-duality-developers-guide.pdf
- 3.oracle-database-23ai-new-features-guide.pdf
其實就是一個Embedding模型,兩個PDF文件用于測試。
而在這個剛開始的階段,你完全不必折騰什么onnx的模型轉(zhuǎn)換,也無需關(guān)注其是否支持中文,更不必花心思去挑選什么測試材料,甚至連具體要執(zhí)行的命令都不需要修改太多,就先按照文檔的示例一步步做,感受過之后在進階階段或具體項目中實踐時,再去考慮所有細節(jié)項。
上面提到的每個文件都貼心的提供了對應下載地址,這都是官方文檔中直接給出的安全地址,你可以直接wget下載,筆者已親測均可正常下載:
- https://adwc4pm.objectstorage.us-ashburn-1.oci.customer-oci.com/p/VBRD9P8ZFWkKvnfhrWxkpPe8K03-JIoM5h_8EJyJcpE80c108fuUjg7R5L5O7mMZ/n/adwc4pm/b/OML-Resources/o/all_MiniLM_L12_v2_augmented.zip
- https://docs.oracle.com/en/database/oracle/oracle-database/23/jsnvu/json-relational-duality-developers-guide.pdf
- https://docs.oracle.com/en/database/oracle/oracle-database/23/nfcoa/oracle-database-23ai-new-features-guide.pdf
其中下載下來的這個zip包,解壓unzip all-MiniLM-L12-v2_augmented.zip后,會發(fā)現(xiàn)有一個README-ALL_MINILM_L12_V2-augmented.txt ,這個說明文件還非常詳細的給出了整個onnx模型加載到Oracle庫內(nèi)的操作步驟,大多命令都可以稍加修改直接使用。
梳理關(guān)鍵命令,比如就按照我的測試環(huán)境修改如下:
sqlplus / as sysdba;
alter session set container=ALFRED;
SQL> GRANT DB_DEVELOPER_ROLE, CREATE MINING MODEL TO TPCH;
SQL> CREATE OR REPLACE DIRECTORY DM_DUMP AS '/home/oracle';
SQL> GRANT READ ON DIRECTORY DM_DUMP TO TPCH;
SQL> GRANT WRITE ON DIRECTORY DM_DUMP TO TPCH;
SQL> exit
使用tpch測試用戶導入ONNX的Embedding模型:
--使用TPCH用戶登錄
sqlplus tpch/tpch@alfred
--刪除模型(可選)
exec DBMS_VECTOR.DROP_ONNX_MODEL(model_name => 'ALL_MINILM_L12_V2', force => true);
--加載導入模型:
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL(
directory => 'DM_DUMP',
file_name => 'all_MiniLM_L12_v2.onnx',
model_name => 'ALL_MINILM_L12_V2',
metadata => JSON('{"function" : "embedding", "embeddingOutput" : "embedding", "input": {"input": ["DATA"]}}'));
END;
/
--查詢導入的EMBEDDING模型:
select model_name, algorithm, mining_function from user_mining_models where model_name='ALL_MINILM_L12_V2';
--測試EMBEDDING模型可用,可以正常返回向量化結(jié)果
SELECT VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'The quick brown fox jumped' as DATA) AS embedding;
到此,是不是沒有任何難度?
我們就已經(jīng)體驗了Oracle庫內(nèi)Embedding Model的導入,以后你需要其他Embedding模型,也是同樣方法導入,只是有些需要格式轉(zhuǎn)換下才可以,目前模型大小限制是不可超過1G。
接下來創(chuàng)建測試表,插入測試數(shù)據(jù):
注意這里測試表只有兩個字段,一個是正常的ID列,另一個是BLOB數(shù)據(jù)類型的data列。
而提到BLOB(Binary Large Object),不得不說,傳統(tǒng)運維DBA對這個是敏感的,認為這種二進制大對象非結(jié)構(gòu)化的數(shù)據(jù)一定不要存在數(shù)據(jù)庫中,但時代在變化,如果你希望數(shù)據(jù)完全由數(shù)據(jù)庫管理而非文件系統(tǒng),BLOB反而是不二之選。
--如果存在此測試表就先刪除
--drop table documentation_tab purge;
--創(chuàng)建測試表documentation_tab
create table documentation_tab (id number, data blob);
--插入測試數(shù)據(jù)
insert into documentation_tab values(1, to_blob(bfilename('DM_DUMP', 'json-relational-duality-developers-guide.pdf')));
insert into documentation_tab values(2, to_blob(bfilename('DM_DUMP', 'oracle-database-23ai-new-features-guide.pdf')));
commit;
select dbms_lob.getlength(data) from documentation_tab;
我們看到,這里將之前的兩個PDF文件分別插入到表中的兩行,通過查詢BLOB的數(shù)據(jù)長度也可以了解占用空間的大小(單位是字節(jié))。

接下來,創(chuàng)建一個關(guān)系表來存儲非結(jié)構(gòu)化的chunk以及相關(guān)向量。
注意,這里這張表的設計,有文檔ID,有Chunk ID, 有chunk原文數(shù)據(jù),有chunk向量化后的數(shù)據(jù)。
chunk簡單理解就相當于是將這里的每個PDF文件分解成小段。至于chunk的好處大家感興趣可以自行搜索了解下,總之,這個做法算是最佳實踐。
--drop table doc_chunks purge;
create table doc_chunks (doc_id number, chunk_id number, chunk_data varchar2(4000), chunk_embedding vector);
--一條SQL語句就可以完成操作:
--The INSERT statement reads each PDF file from DOCUMENTATION_TAB, transforms each PDF file into text, chunks each resulting text, then finally generates corresponding vector embeddings on each chunk that is created. All that is done in one single INSERT SELECT statement.
--注意修改model名字為ALL_MINILM_L12_V2
insert into doc_chunks
select dt.id doc_id, et.embed_id chunk_id, et.embed_data chunk_data, to_vector(et.embed_vector) chunk_embedding
from
documentation_tab dt,
dbms_vector_chain.utl_to_embeddings(
dbms_vector_chain.utl_to_chunks(dbms_vector_chain.utl_to_text(dt.data), json('{"normalize":"all"}')),
json('{"provider":"database", "model":"ALL_MINILM_L12_V2"}')) t,
JSON_TABLE(t.column_value, '$[*]' COLUMNS (embed_id NUMBER PATH '$.embed_id', embed_data VARCHAR2(4000) PATH '$.embed_data', embed_vector CLOB PATH '$.embed_vector')) et;
commit;
這里使用一條SQL就實現(xiàn)了從 documentation_tab 表中讀取文檔數(shù)據(jù) (dt.data)、將文檔轉(zhuǎn)換為文本、將文本分割成多個塊 (chunks)、為每個文本塊生成嵌入向量 (embeddings)、將結(jié)果插入到 doc_chunks 表中的整個流程,最終成功插入了1377條數(shù)據(jù):

然后,生成用于similarity查詢檢索的query_vector:
ACCEPT text_input CHAR PROMPT 'Enter text: '
--different methods of backup and recovery
VARIABLE text_variable VARCHAR2(1000)
VARIABLE query_vector VECTOR
BEGIN
:text_variable := '&text_input';
SELECT vector_embedding(ALL_MINILM_L12_V2 using :text_variable as data) into :query_vector;
END;
/
PRINT query_vector
使用下面SQL進行相似性檢索,在你的書中,找到與備份恢復最相關(guān)的前4個chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
--如果你想找指定哪本書,還可以通過where條件來指定:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
WHERE doc_id=1
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
使用EXPLAIN PLAN 命令確定優(yōu)化器是如何執(zhí)行的,目前沒有索引,肯定是全表掃:
EXPLAIN PLAN FOR
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
select plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
運行多向量相似性檢索,找前兩本最相關(guān)的書中,前4個最相關(guān)的塊:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 2 PARTITIONS BY doc_id, 4 ROWS ONLY;
創(chuàng)建向量索引:
--創(chuàng)建HNSW類型的向量索引(提前需要確認設置:vector_memory_size)
--alter system set vector_memory_size=1G scope=spfile;
create vector index docs_hnsw_idx on doc_chunks(chunk_embedding)
organization inmemory neighbor graph
distance COSINE
with target accuracy 95;
--如果23ai版本過低,可能還沒有INDEX_SUBTYPE字段
SELECT INDEX_NAME, INDEX_TYPE, INDEX_SUBTYPE
FROM USER_INDEXES;
--如果OK,正常顯示如下:
INDEX_NAME INDEX_TYPE INDEX_SUBTYPE
------------- ---------------- ---------------------------
DOCS_HNSW_IDX VECTOR INMEMORY_NEIGHBOR_GRAPH_HNSW
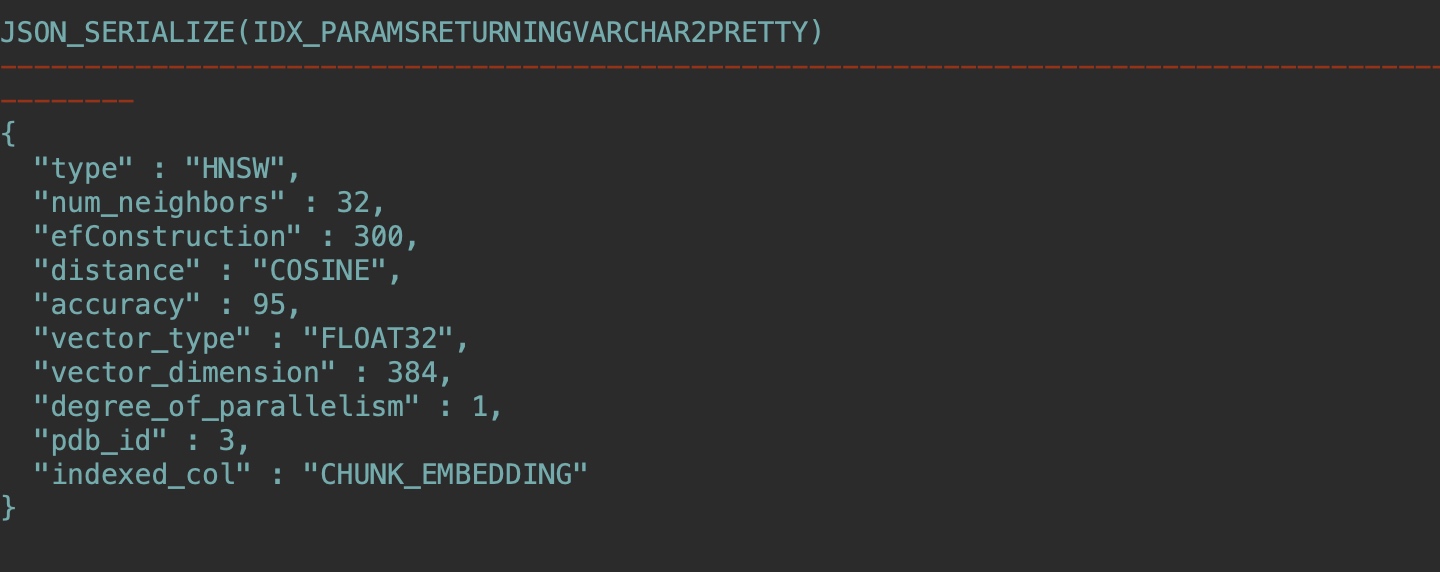
--使用JSON_SERIALIZE查詢:
SELECT JSON_SERIALIZE(IDX_PARAMS returning varchar2 PRETTY)
FROM VECSYS.VECTOR$INDEX where IDX_NAME = 'DOCS_HNSW_IDX';
--確定在 vector memory area中的內(nèi)存分配:
select CON_ID, POOL, ALLOC_BYTES/1024/1024 as ALLOC_BYTES_MB,
USED_BYTES/1024/1024 as USED_BYTES_MB
from V$VECTOR_MEMORY_POOL order by 1,2;
建好索引之后,就可以進行近似的相似性檢索(approximate similarity search),在你的書中找到前四條最相關(guān)的chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
--同樣,可以where指定第一個文檔,從第一個文檔中找到前四條最相關(guān)的chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
WHERE doc_id=1
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
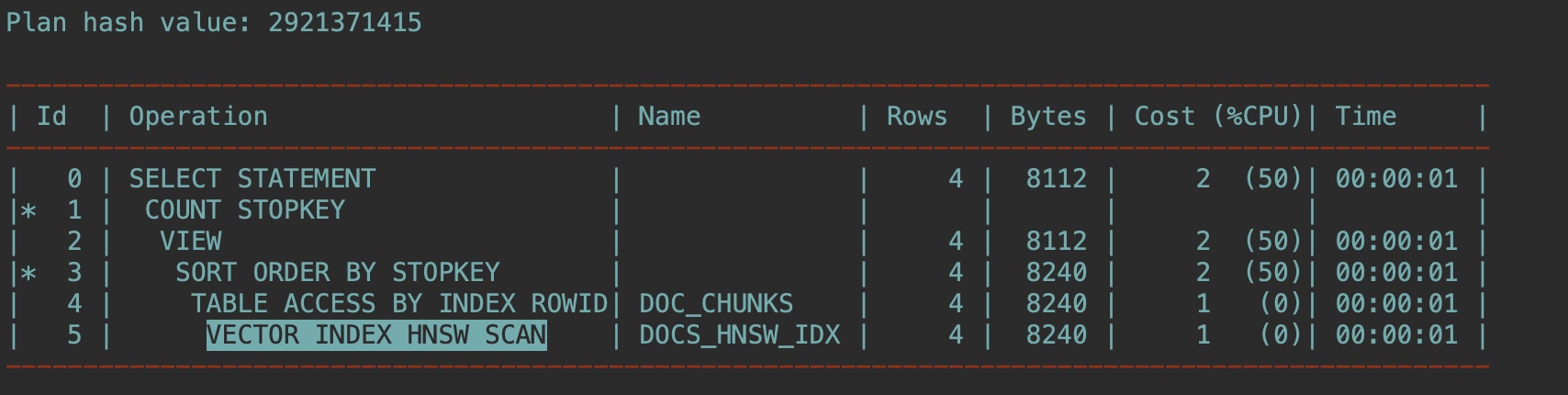
這次還是用EXPLAIN PLAN 確認優(yōu)化器如何解析此查詢:
EXPLAIN PLAN FOR
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
select plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
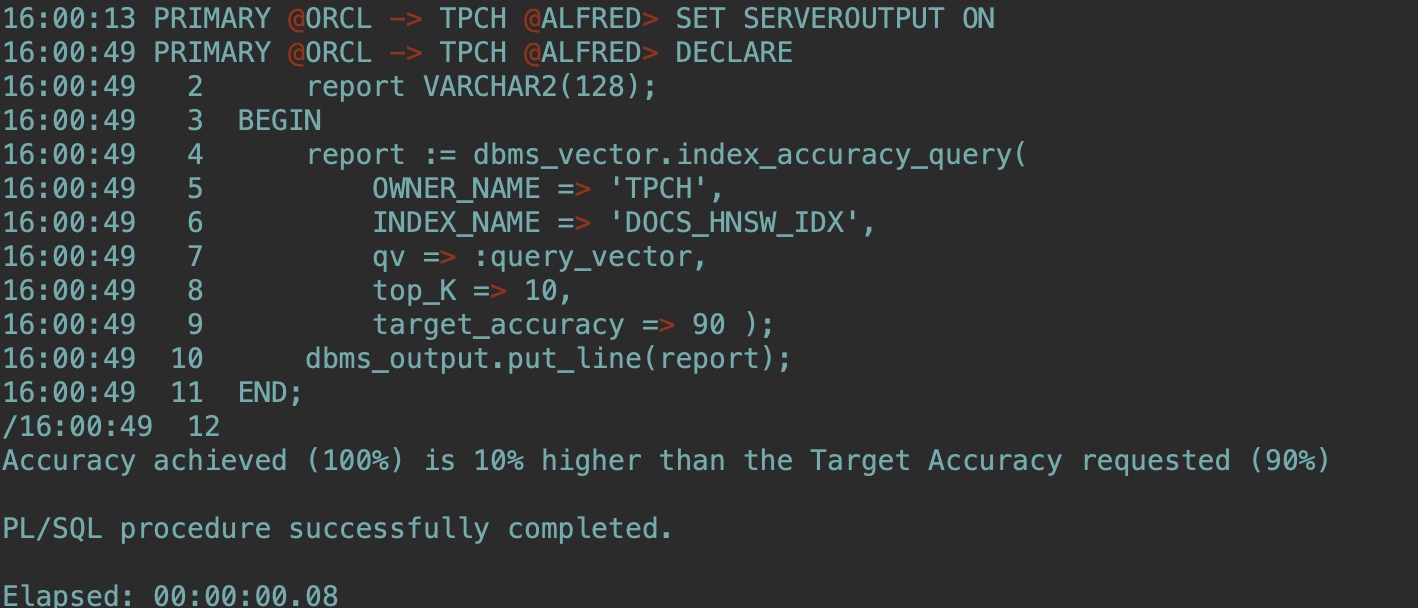
確認近似相似檢索的向量索引性能(Determine your vector index performance for your approximate similarity searches.):
--注意修改OWNER_NAME
SET SERVEROUTPUT ON
DECLARE
report VARCHAR2(128);
BEGIN
report := dbms_vector.index_accuracy_query(
OWNER_NAME => 'TPCH',
INDEX_NAME => 'DOCS_HNSW_IDX',
qv => :query_vector,
top_K => 10,
target_accuracy => 90 );
dbms_output.put_line(report);
END;
/
現(xiàn)在我們創(chuàng)建一個新表用于混合檢索:
--
--DROP TABLE documentation_tab2 PURGE;
CREATE TABLE documentation_tab2 (id NUMBER, file_name VARCHAR2(200));
INSERT INTO documentation_tab2 VALUES(1, 'json-relational-duality-developers-guide.pdf');
INSERT INTO documentation_tab2 VALUES(2, 'oracle-database-23ai-new-features-guide.pdf');
COMMIT;
要創(chuàng)建混合向量索引,需要指定文件所在的數(shù)據(jù)存儲。在這里,我們使用存儲PDF文件的DM_DUMP目錄:
BEGIN
ctx_ddl.create_preference('DS', 'DIRECTORY_DATASTORE');
ctx_ddl.set_attribute('DS', 'DIRECTORY', 'DM_DUMP');
END;
/
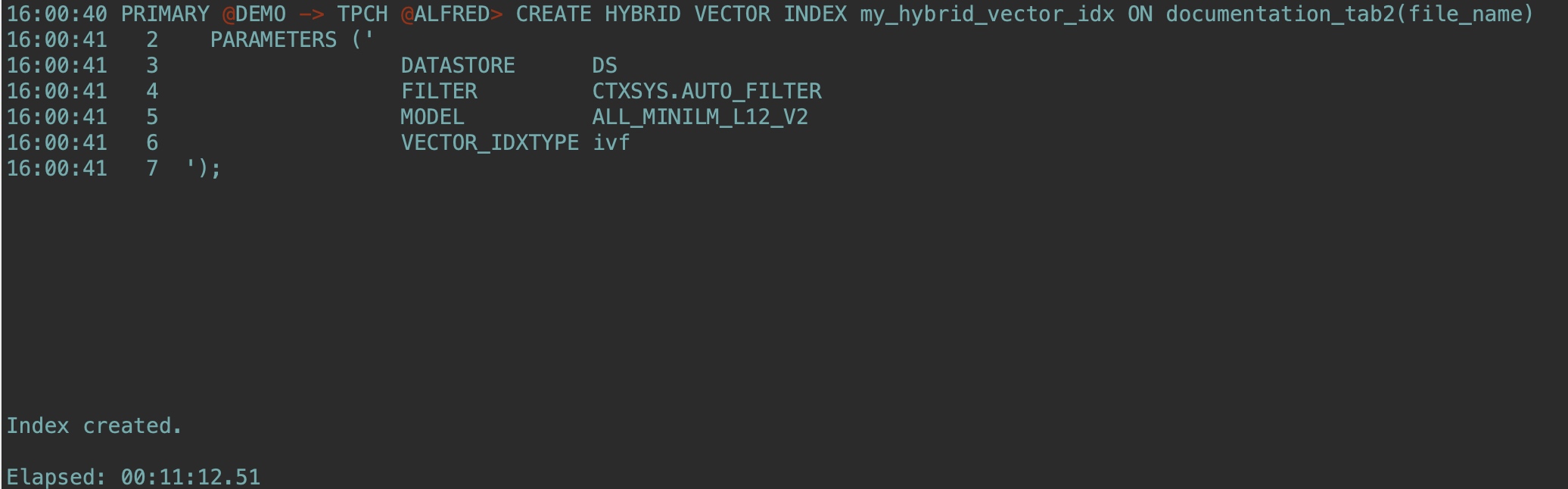
--這里23ai較低版本可能報錯,建議使用23.7或以上,創(chuàng)建時間較長耐心等待:
CREATE HYBRID VECTOR INDEX my_hybrid_vector_idx ON documentation_tab2(file_name)
PARAMETERS ('
DATASTORE DS
FILTER CTXSYS.AUTO_FILTER
MODEL ALL_MINILM_L12_V2
VECTOR_IDXTYPE ivf
');
創(chuàng)建混合向量索引后,檢查創(chuàng)建的以下內(nèi)部表:
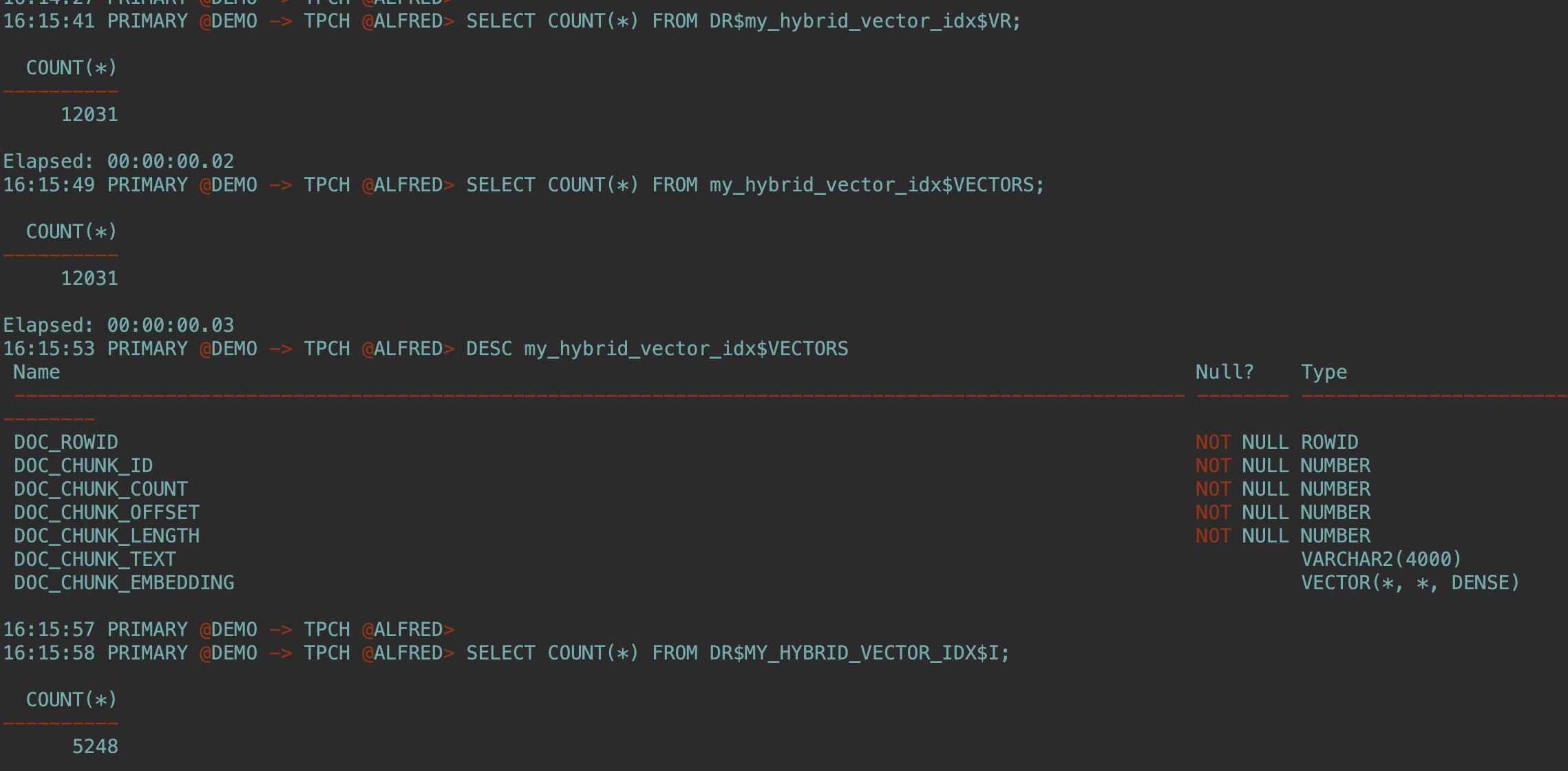
SELECT COUNT(*) FROM DR$my_hybrid_vector_idx$VR;
SELECT COUNT(*) FROM my_hybrid_vector_idx$VECTORS;
DESC my_hybrid_vector_idx$VECTORS
SELECT COUNT(*) FROM DR$MY_HYBRID_VECTOR_IDX$I;
可以通過指定以下參數(shù)來運行第一次混合搜索:
The hybrid vector index name
The search scorer you want to use (this scoring function is used after merging results from keyword search and similarity search)
The fusion function to use to merge the results from both searches
The search text you want for your similarity search
The search mode to use to produce the vector search results
The aggregation function to use to calculate the vector score for each document identified by your similarity search
The score weight for your vector score
The CONTAINS string for your keyword search
The score weight for your keyword search
The returned max values you want to see
The maximum number of documents and chunks you want to see in the result
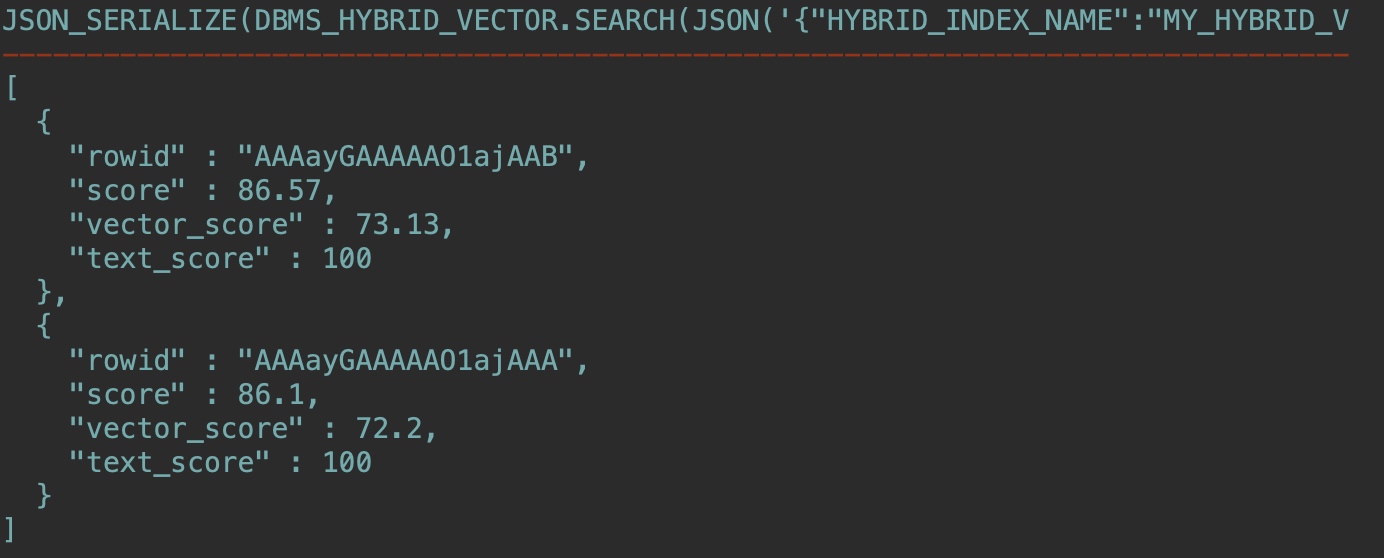
使用文檔給出的例子,官方文檔中缺少了一個冒號,下面已修正,可以直接復制使用:
SET LONG 10000
SELECT json_serialize(
DBMS_HYBRID_VECTOR.SEARCH(
JSON(
'{
"hybrid_index_name" : "my_hybrid_vector_idx",
"search_scorer" : "rsf",
"search_fusion" : "UNION",
"vector":
{
"search_text" : "How to insert data in json format to a table?",
"search_mode" : "DOCUMENT",
"aggregator" : "MAX",
"score_weight" : 1,
},
"text":
{
"contains" : "data AND json",
"score_weight" : 1,
},
"return":
{
"values" : [ "rowid", "score", "vector_score", "text_score" ],
"topN" : 10
}
}'
)
) RETURNING CLOB pretty);
結(jié)果:
SELECT file_name FROM documentation_tab2 WHERE rowid='AAAayGAAAAAO1ajAAB';

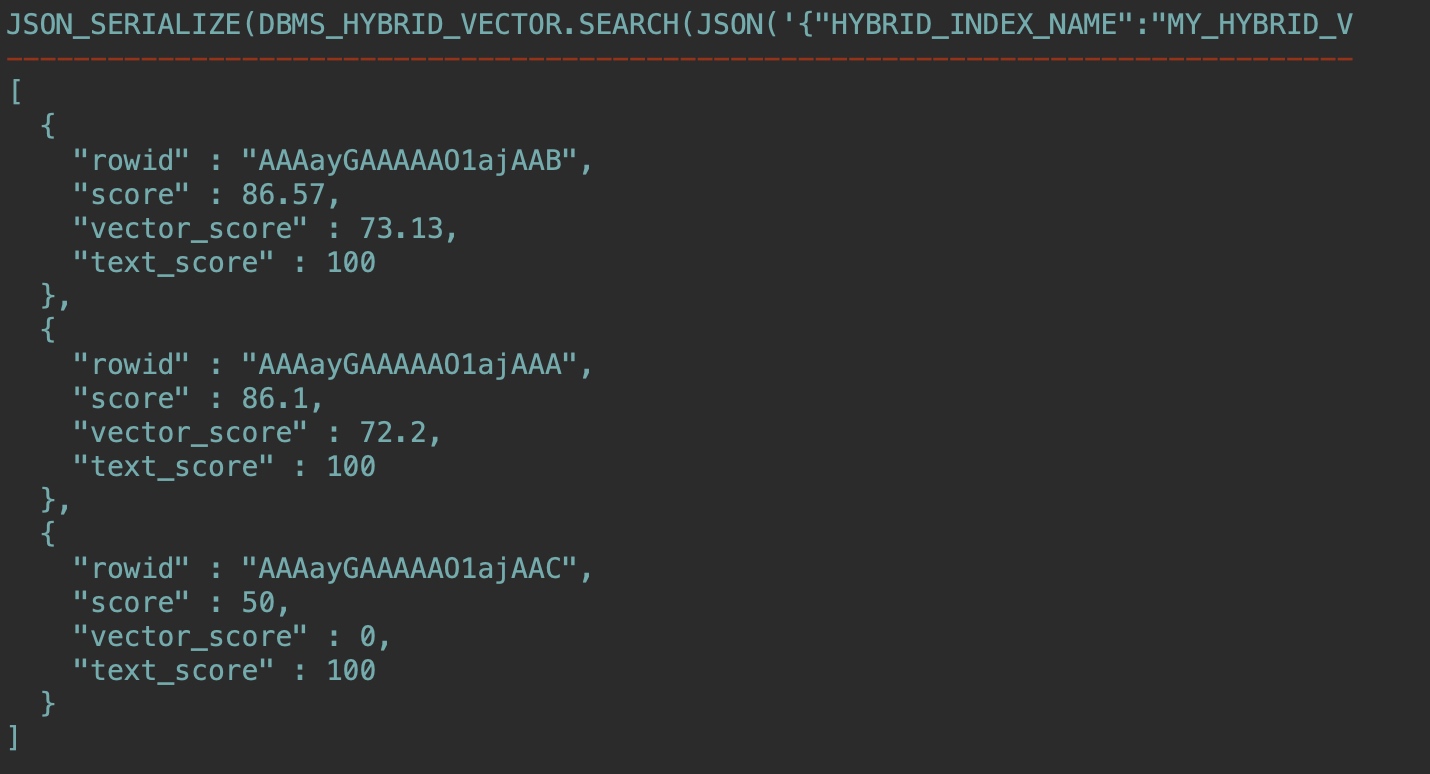
混合向量索引維護在后臺自動完成,最后測試下在基表中插入新行,并運行與上一步相同的混合搜索查詢:
INSERT INTO documentation_tab2 VALUES(3, 'json-relational-duality-developers-guide.pdf');
COMMIT;
這個文件我還沒有下載,運行同樣查詢結(jié)果已經(jīng)多了一組數(shù)據(jù):
到這里就告一段落了,我們一起快速體驗了AI Vector Search,當然很多細節(jié)還值得推敲,可以留給后面精進實踐的階段,筆者有時間也會持續(xù)跟讀者分享更多AI相關(guān)技術(shù)實踐。
最后祝Oracle DBA們在這個變幻莫測的大環(huán)境下,都能成功轉(zhuǎn)型,擁抱AI新時代,涅槃重生。
轉(zhuǎn)載請注明原文鏈接:http://www.rzrgm.cn/jyzhao/p/18924802/ceng-jing-feng-guang-wu-xian-de-oracle-dba-yi-jing
?? 感謝閱讀,歡迎關(guān)注我的公眾號 「趙靖宇」


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號