ComfyUI 基礎教程(二) —— Stable Diffusion 文生圖基礎工作流及模型、常用節點介紹
 本文通過 ComfyUI 的基礎文生圖工作流,講解了 ComfyUI 的最基礎核心節點,以及對不同類型的模型和常用節點進行了介紹。
本文通過 ComfyUI 的基礎文生圖工作流,講解了 ComfyUI 的最基礎核心節點,以及對不同類型的模型和常用節點進行了介紹。
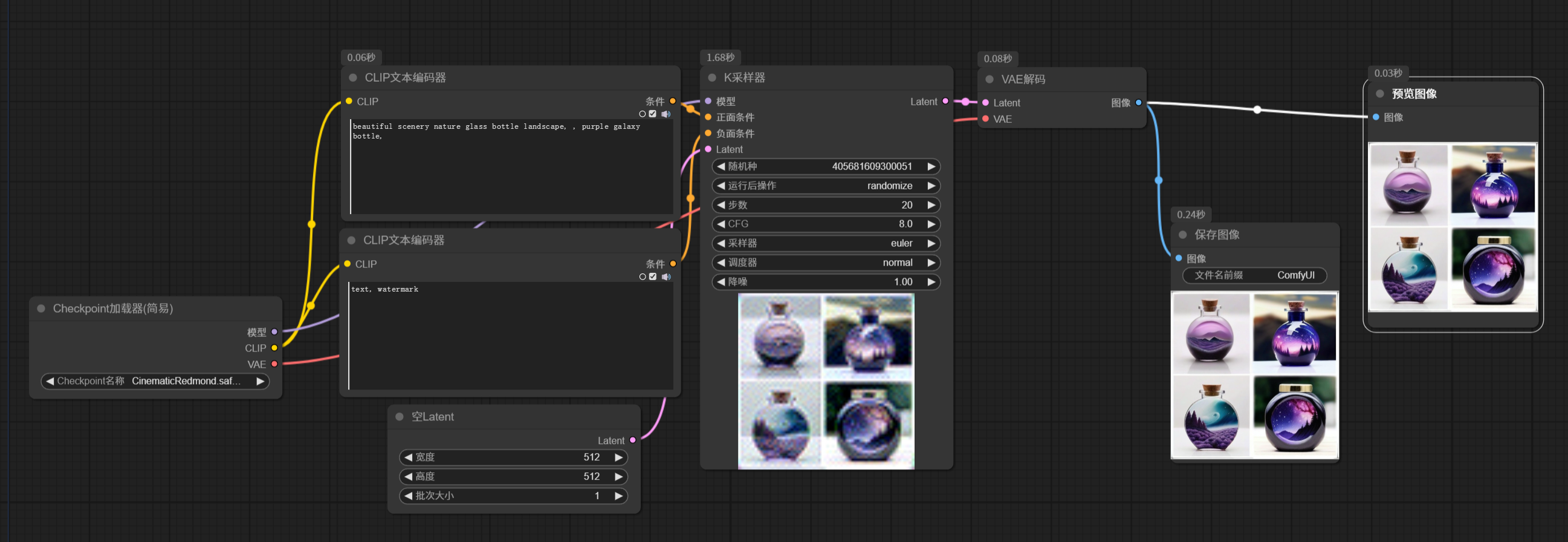
上一篇文章講解述首次啟動 ComfyUI 會自動打開一個最基礎的文生圖工作流。實際上,后續我們可以通過菜單選項,或者快捷鍵 ctrl + D來打開這個默認工作流。默認工作流如下:
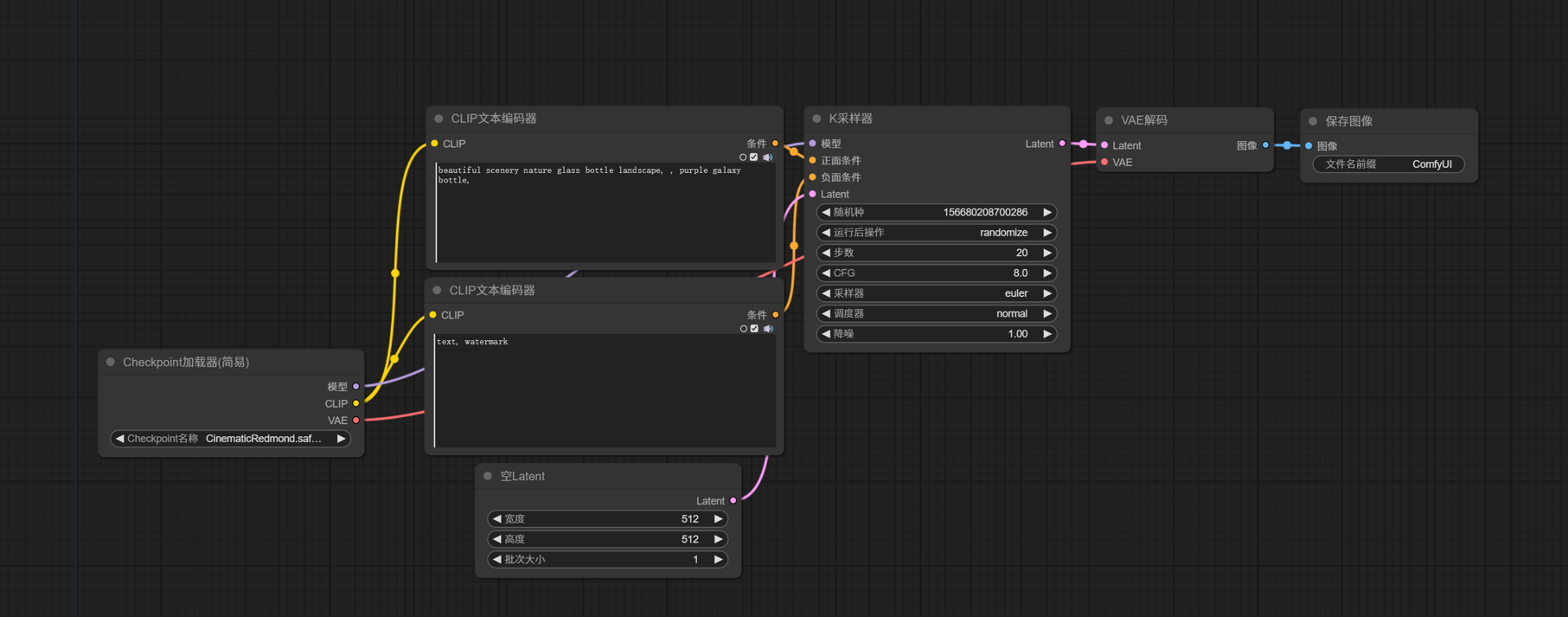
這是一個最基礎的文生圖工作流,本文通過對這個工作流的講解,讓大家對 ComfyUI 工作流有一個基本的認識。
一、文生圖工作流核心節點
前面入坑鋪墊這篇文章有推薦秋葉大佬的原理講解視頻,如果不了解也還沒有看過的朋友,推薦去看看,傳送門 B站秋葉大佬的視頻。
對原理有個大概了解的朋友應該知道,大模型是在潛空間處理圖像的,人能識別的渲染出來的圖片成為像素圖。輸入的條件信息,經過編碼,傳入潛空間,在潛空間里采樣器去除噪波,最后在經過解碼,輸出像素圖像。所以采樣器是生成圖片的最核心節點之一,下面就從采樣器開始,依次介紹默認工作流中的節點。
1.1 【K采樣器】
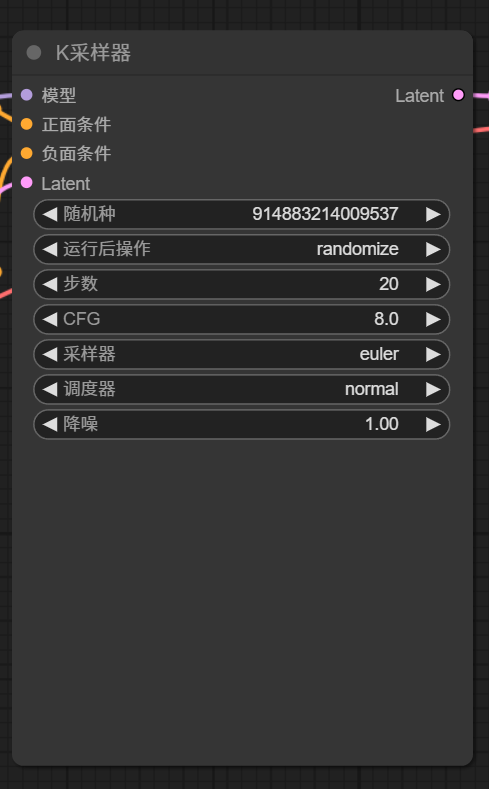
采樣器節點有多種,默認工作流中d是最簡單的 KSample。下面說說 K采樣器的參數:
- 隨機種子:每生成一張圖就會顯示該圖的數值,默認為 0;可選項有每次隨機、固定、每次遞增、每次遞減。
- 步數:是指潛空間里的去除噪波迭代步數,一般設置為 25-40 左右。這個越大,所生成的圖細節越多,但是生成圖片需要的時間越長,并且一般超過 35 以后,則效果不是太明顯,步數設置太小,則生成的圖片一般質量越差。需要不斷嘗試,以確定每個大模型最適合的值。
- CFG: 提示詞相關性。參數越大,圖片效果越接近提示詞。參數越小,AI 發揮空間越大,圖片效果與提示詞差異越大。一般設置在 10 左右就好,默認為 8。
- 采樣器與調度器:采樣器是與調度器結合一起使用的,采樣器一般使用優化后/最新的采樣器:euler_ancestral (簡稱 euler a)、dpmpp_2m 系列、dpmpp_3m 系列,調度器一般選擇 normal 或 Karras
- 降噪:降噪:和步數有關系,1 就是我們 100% 的按照上方輸入的步數去完成,0.1 就是 10%,一般不用懂,默認填 1 就行。
1.2 【主模型加載器】
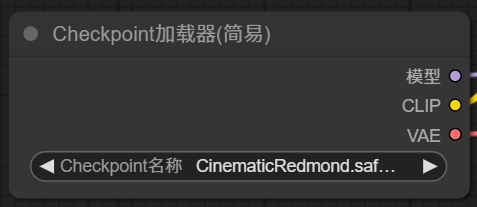
K采樣器節點左邊輸入項,需要輸入模型,所以需要添加一個主模型加載器,Load Checkpoint,。
主模型加載器只有一個參數,設置一個主模型。主模型的好壞決定了出圖的整體質量,主要風格。
主模型加載器有三個輸出項目,其中模型輸出,就是 K 采樣器的模型輸入,需要把這兩個點用線連接起來。
1.3 【Clip文本編碼器】
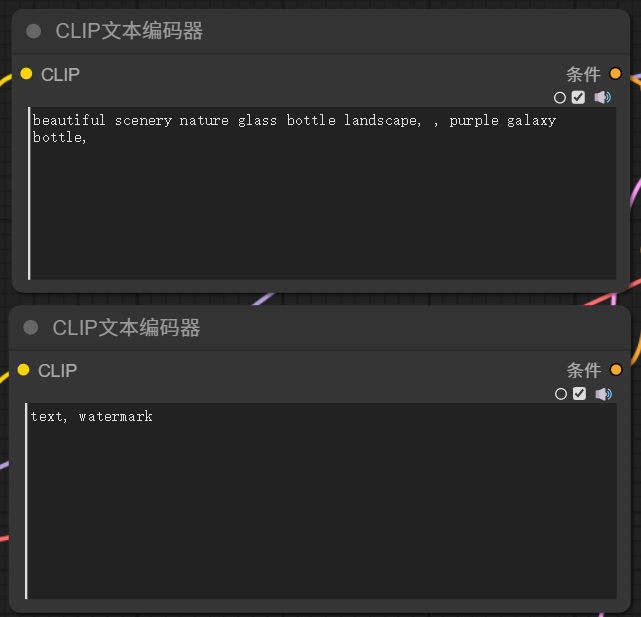
K采樣器左邊的輸入項需要正面條件和負面條件,所謂的正面條件就是通過指令,告訴采樣器,我要生成的圖包含什么元素,負面條件就是通過指令告訴采樣器,我要生成的圖不包含什么樣的元素。既然是文生圖,當然是通過輸入文字提示詞發送指令,注意這里的提示詞必須是英文,(英文水平不好的同學也不要著急,后面會講解翻譯節點)。但是,正常輸入的文字,不能直接被采樣器識別使用,需要經過編碼,轉換成采樣器能識別的指令。這里就是通過 CLIP Text Encode (Prompt) conditioning 進行編碼。這里的兩個 Clip 文本編碼器作用是一樣的,文本編碼器,需要針對模型配合使用的,所以這里它的輸入端,應該連接到主模型輸出項的 Clip 點。Clip 文本編碼器輸出的條件,分別連接到 K 采樣器輸入端的正面條件和負面條件。
1.4 【空 Latent】
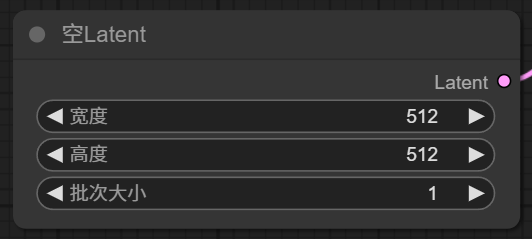
現在 K 采樣器輸入項還差一個 Latent, 這里有一個空 Latent 作為輸入項。
Empty Latent Image 節點有三個參數,寬度、高度指定了潛空間生成圖像的寬高,注意這里是單位是像素。批次大小,意思是一次生成多少張圖片。
1.5 【VAE 解碼】
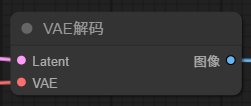
K 采樣器的左邊輸入項和參數都填完了,那 K 采樣器生成圖片之后需要輸出結果,前面提到,潛空間里的圖像是數字信號的形式,需要經過解碼,轉換成像素圖像,這里就需要用到 VAE Decode。
VAE 解碼器有兩個輸入項, Latent 輸入點連接到 K 采樣器的輸出點。
另一個 AVE 用到的模型,一般主模型都嵌入了VAE模型,連接到主模型即可,默認工作流中,就是直接連接到主模型加載器輸出項的VAE。當然也可以自己主動加載額外的 VAE 模型。
1.6 【保存圖像】
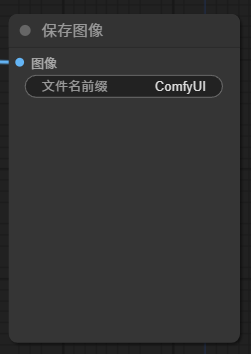
經過 VAE 解碼后的圖像,最后輸出到 Save Image 節點可以預覽,并保存。默認保存路徑,在 ComfyUI 安裝目錄下的 output 文件夾,
該節點有一個參數,設置保存文件名的前綴。
二、ComfyUI 模型知識
2.1 模型后綴名的區別
模型的后綴名有很多。常見的有 .ckpt、.pt、.pth、.pkl、.safetensors等。
CheckPoint 是一個概念,在模型訓練過程中,不能保證一次就訓練成功,中途可能會有各種因素導致失敗,并且訓練成功是一個偽概念,某些算法模型訓練步數也不是越多越好,過多的訓練會出現過擬合的情況。所以我們能做的是每訓練一定的步數,保存一次訓練結果,類似于存檔。一方面使用某次訓練的結果,覺得效果符合預期了,就可以停止訓練了,最后將這個模型用于發布即可。另一方面,中途訓練失敗了,可以從某個 CheckPoint 繼續開始訓練。
-
.ckpt 是 checkpoint 的單詞簡寫,僅僅是單詞簡寫,不要認為 .ckpt 后綴的模型就是主模型,它倆沒有關系。.ckpt 是 TensorFlow 中用于保存模型參數的格式。TensorFlow 是 Google 發布的深度學習框架。
-
.pt 是 PyTorch 保存模型參數的格式。PyTorch 是 Meta(facebook) 發布的深度學習框架。PyTorch 保存模型的格式,除了 .pt 之外還有.pth 和 .pkl。.pt 和 .pth 之間沒有本質區別。而 .pkl 僅僅是多了一步使用 python 進行了序列化。
-
.safetensors 從名字可以看出,該格式更加安全。前面提到,可以從某個 CheckPoint 恢復訓練,則需要在該 .ckpt 模型中保存了一些訓練信息,比如模型的權重,優化器的狀態,Python 代碼等等,這就容易造成信息泄露,同時容易被植入惡意代碼。所以 .ckpt 模型存在不安全因素,同時體積會比較大。.safetensors 是 huggingface 推出的新的模型存儲格式,專門為 StableDiffusion 設計的,它只包含模型權重信息,模型體積更小,更加安全,加載速度也更快,通常用于模型的最終版本。而 .ckpt 模型適合用于對模型的微調、再訓練。
2.2 模型的分類
ComfyUI 中用到的模型種類非常之多,為了方便理解和學習,我們可以對模型進行分類,大致可以分為以下幾類:
1. checkpoint 主模型、大模型、底模、基礎模型等。通過特定訓練最終形成的一個保持該領域特征的一種綜合算法合集,可以精準的匹配你的需求。比如攝影寫實模型、3D模型、二次元模型、室內設計模型等等。Checkpoint 的訓練難度大,需要的數據集大,生成的體積也較大,動則占用幾個G的磁盤空間。
2. Lora Lora 模型作為大模型的一種補充,能對生成的圖片進行單一特征的微調,比如生成的人物圖片具有相同的人臉特征、穿著特定服裝、具備特定畫風等等。Lora 模型體積較小,一般幾十幾百兆, 個人主機就可訓練自己需要的 Lora 模型。
3. VAE VAE 模型可以當作濾鏡,目前針對 Stable Diffusion 主流的 VAE 模型有兩個,二次元使用 kl-f8-anime2VAE, 寫實風格使用 vae-ft-mse-840000-ema-pruned。
4. EMBEDDING 文本嵌入模型,應用于提示詞中,是一類經過訓練的提示詞合集,主要用來提升畫質,規避一些糟糕的畫面。比如:badhandv4、Bad_picture、bad_prompt、NG_Deep Negative、EasyNegative,這些是經常用到的反向提示詞嵌入模型,可以單獨使用或者組合使用。
5. 其它 比如 controlnet模型、ipadapter模型、faceswap 模型、放大模型等等
對于 Stable Diffusion 的模型,現在也有了眾多版本。常見版本有 SD1.5、SD2.0/2.1、 SDXL,其中 SDXL 模型生成的圖片質量最高,相應地對硬件要求也相對高一點,而 SD1.5 生態最完善,這兩個版本使用的最多。
需要強調的一點是:使用時,不同類型模型的版本需要對應上,比如主模型選擇的是 SDXL 版本,Lora 使用 SD1.5 模型是無法正常運行的。
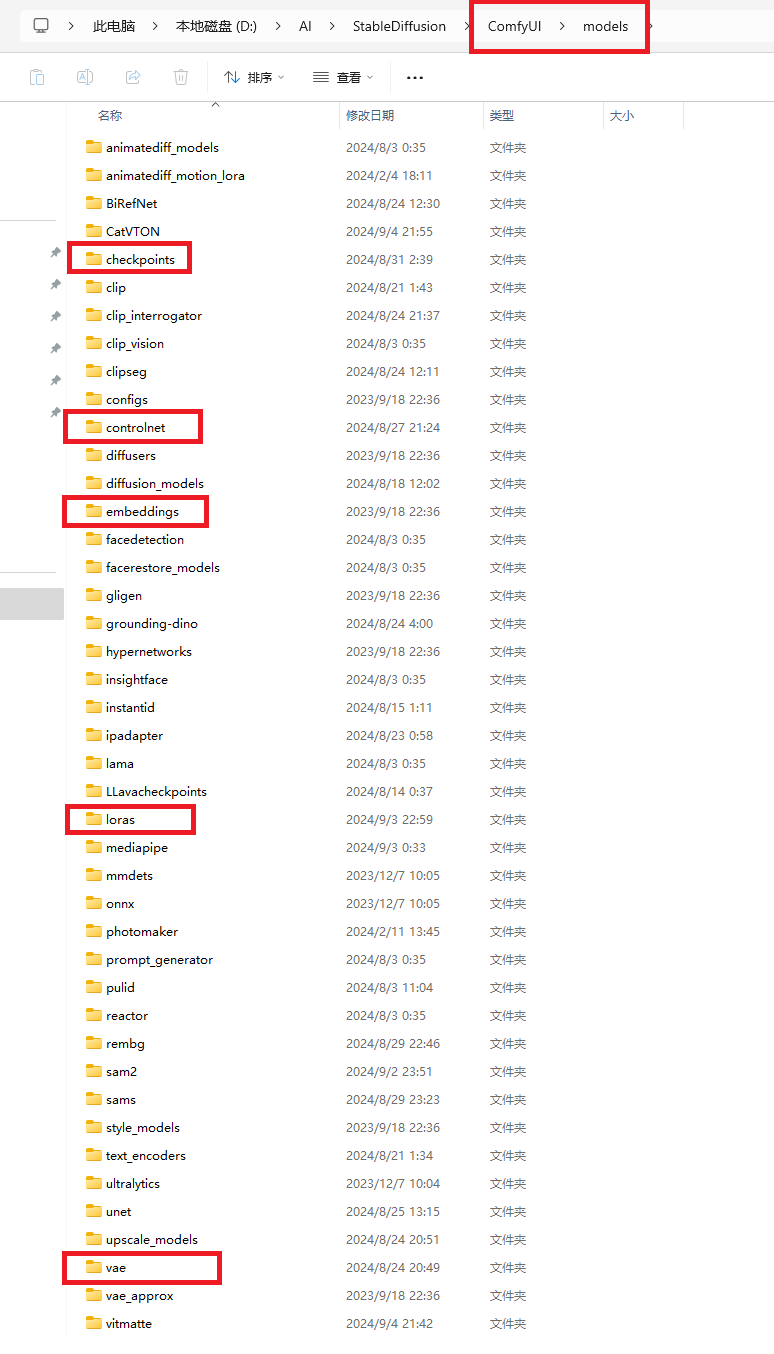
2.3 模型的存放路徑
ComfyUI 的安裝目錄中有專門存放模型的文件夾。只需要將下載下來的模型放到對應的文件夾下。
2.4 模型的下載地址
推薦兩個主流的模型下載地址:
C 站: https://civitai.com/
抱臉: https://huggingface.co/
這兩個網站中能下載到任何你想要的模型。
C 站查找模型可以過濾分類
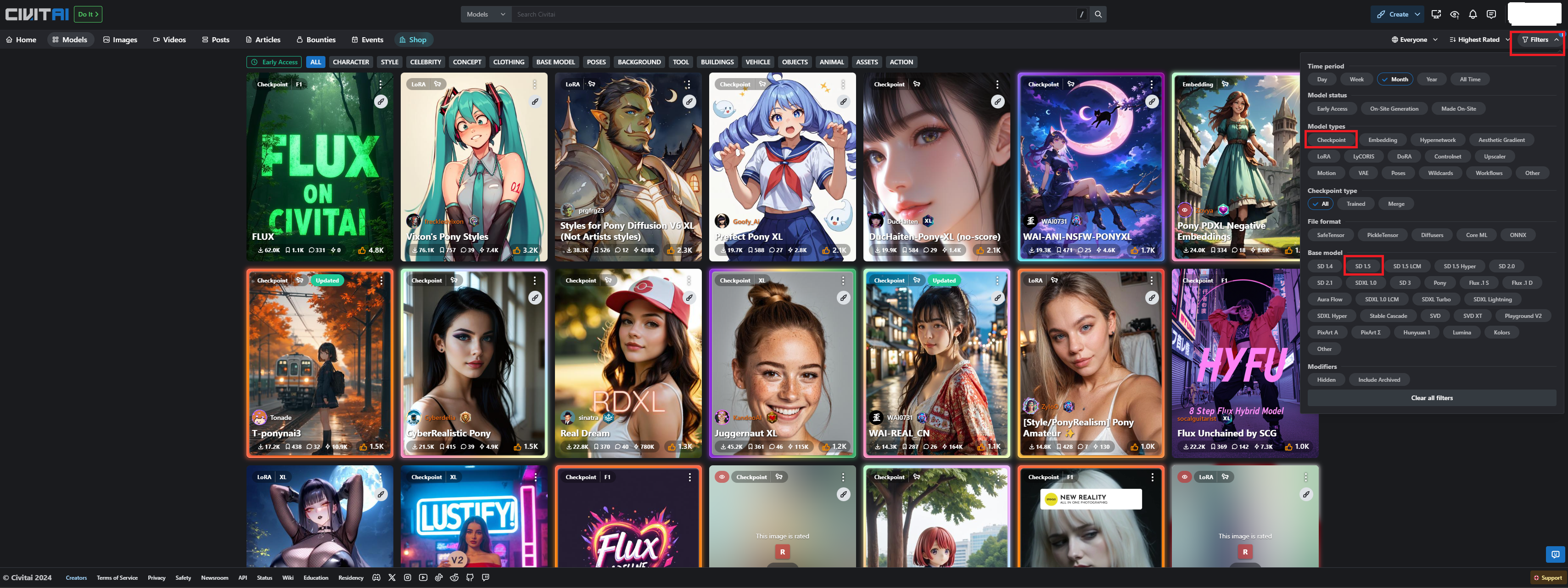
2.5 模型的架構
常見的的模型的架構分類:
Latent Diffusion 模型架構分類
| 文本編碼 | 去噪擴散 | 編碼解碼 | 變體 | |
|---|---|---|---|---|
| SD1.5 | CLIP | UNET | VAE | |
| SDXL | ClipL/ClipG | UNET | VAE | Kolors/Pony/Playground |
| SD3 | ClipL/ClipG/T5 | Dit | VAE | DIT混元/AuraFlow/Flux |
SD 快速模型
| LCM | Turbo | Lightning |
|---|---|---|
| Latent Consistency Models 潛在一致性模型,清華大學研發的一款新一代生成模型,圖像生成速度提升 5-10 倍,LCM-SD1.5、LCM-SDXL、LCM-Lora、Animatediff LCM、 SVD LCM | 官方在 SDXL1.0基礎上采用了新的蒸餾方案,1-4 步就可以生成高質量圖像,網絡架構與 SDXL 一致。只適用于 SDXL, SD1.5無該類型模型 | 字節跳動在 SD1.0 基礎上結合漸進式對抗蒸餾提煉出來的擴散蒸餾方法,本質上也是 SDXL 模型 |
關于模型架構的知識比較復雜,我也只是淺淺的了解。不懂這部分,對使用 ComfyUI 繪圖影響不大,但是了解這些架構信息,對模型的兼容性方面會有一定的認識,有助于解決后面在使用過程中因模型版本、兼容性導致的問題。
三、其它常用節點簡單介紹
插件的安裝方法上一篇文章已經介紹過,不清楚的可以先去看看。
3.1 漢化插件 AIGODLIKE-COMFYUI-TRANSLATION
使用秋葉整合包,默認是安裝了漢化節點的。作用是將菜單、設置等界面元素漢化。安裝完漢化節點后,重啟 ComfyUI ,然后再在設置中找到語言欄,切換為中文即可。
3.2 提示詞翻譯插件 ComfyUI_Custom_Nodes_AlekPet
前面提到,Clip 文本編碼器需要輸入英文提示詞。如果英文不好,則可以安裝提示詞翻譯插件。
使用方式:
-
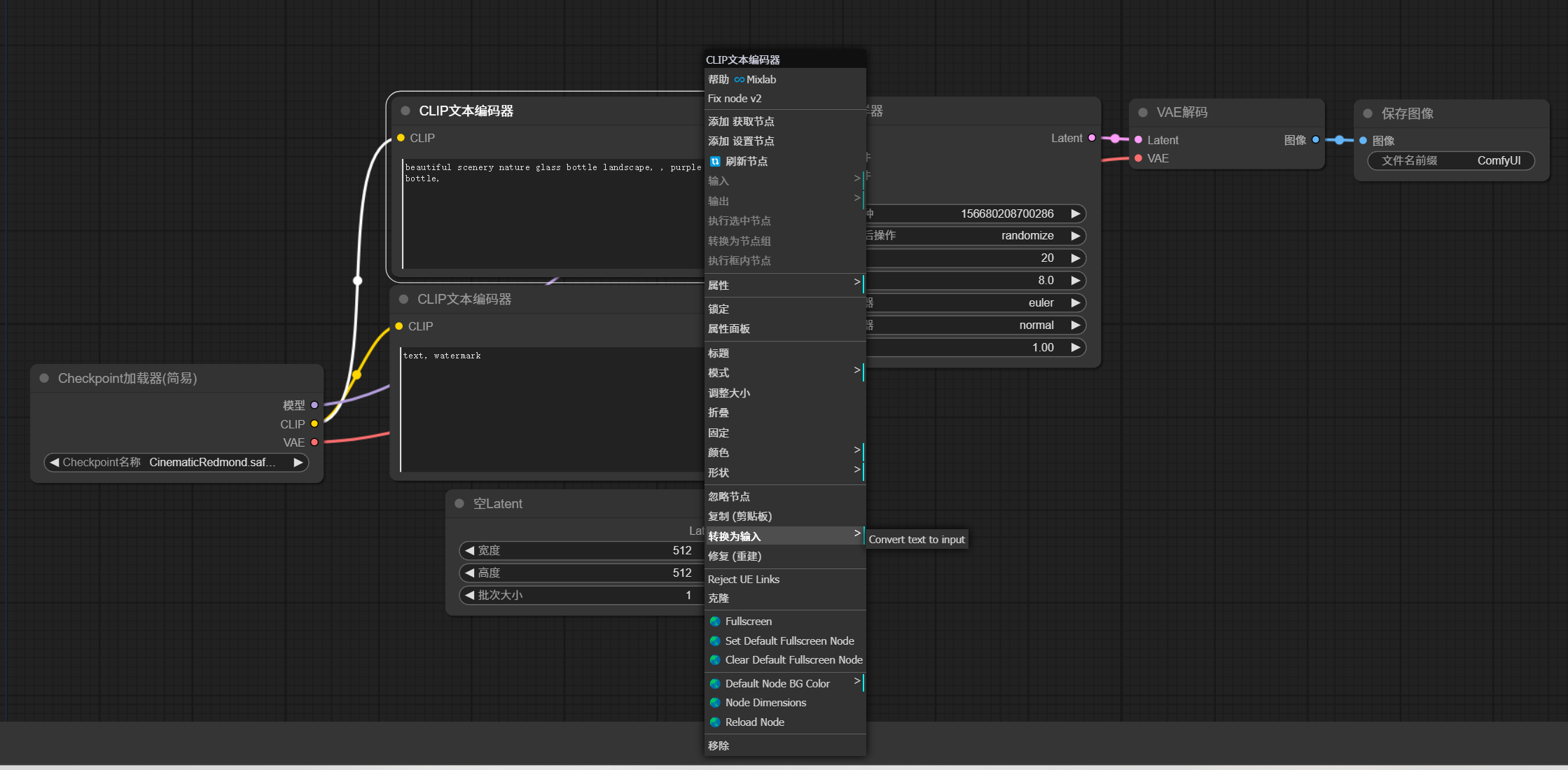
鼠標放在 Clip 文本編碼器節點上,右鍵 -> 轉換為輸入 -> Convert text to input。
將參數轉換成輸入節點。
-
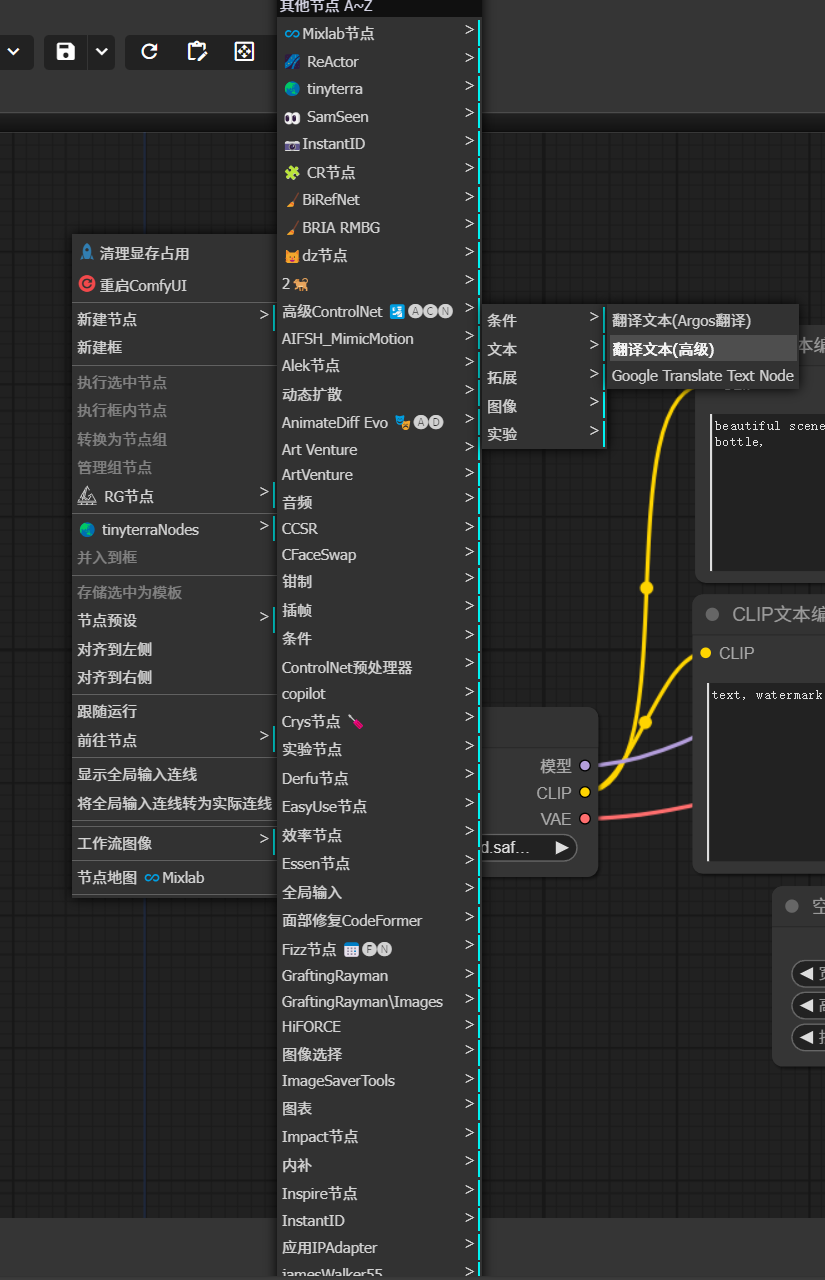
新建一個提示詞翻譯節點。
在空白處,右鍵 -> 新建節點 -> Alek 節點 -> 文本 -> 翻譯文本(高級)
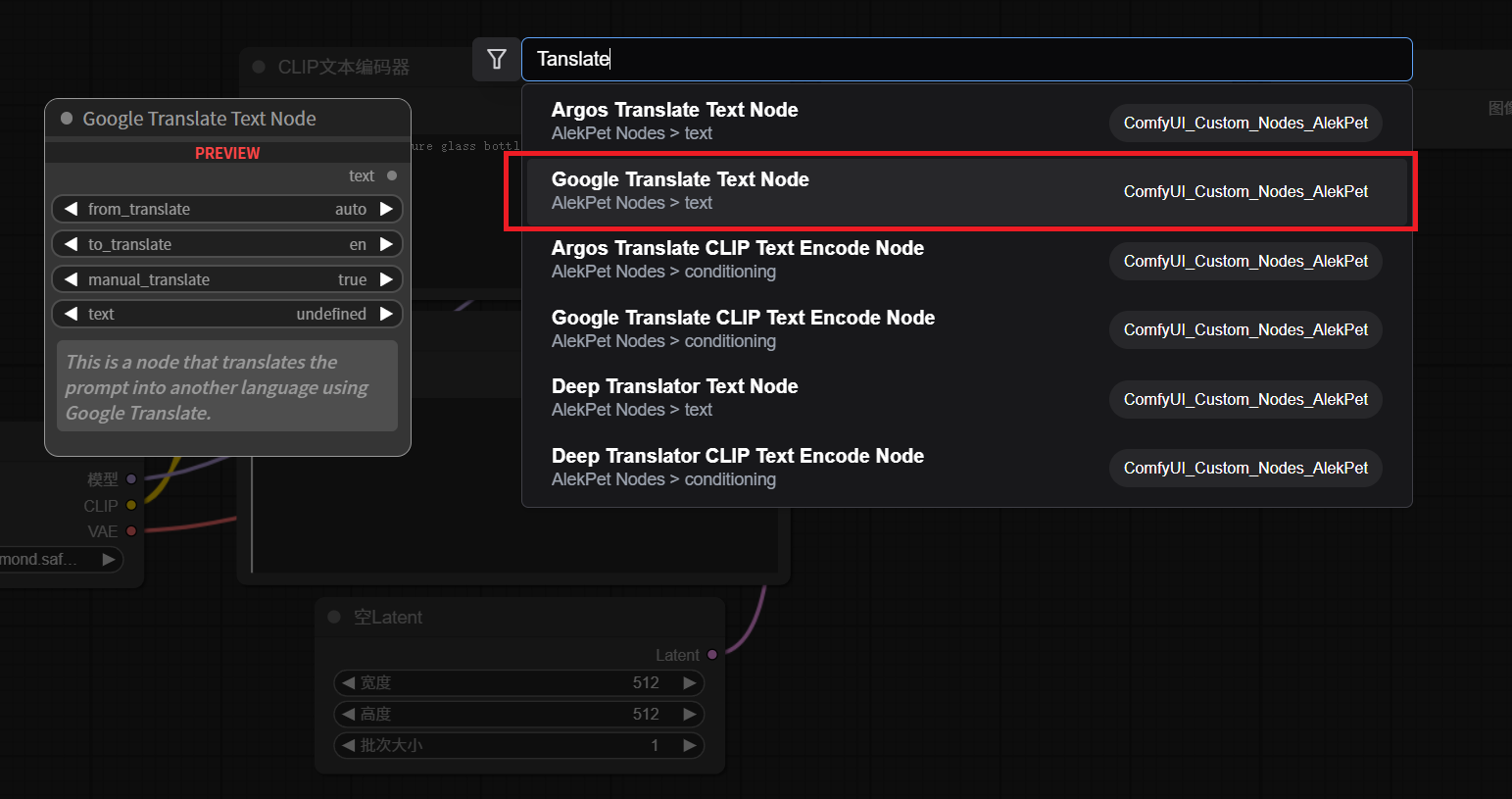
或者,在空白處雙擊左鍵,輸入
tanslate會自動匹配出節點,選擇正確的節點。
-
將提示詞翻譯節點與 Clip 文本編碼器連接起來

這樣我們就可以在在提示詞翻譯節點中填入中文提示詞。需要注意的是,該提示詞翻譯插件使用的是 Google 翻譯,需要外網環境。
使用技巧:
- 節點是可以復制粘貼的。比如需要對負面提示詞添加同樣的節點,直接復制一個就可以了。
3.3 元節點 primitive
圖中分別表示小數、文本、布爾值、整數、多行文本。
元節點,簡單來說就是把原始輸入數據原封不動輸出。那這樣有什么作用呢,最典型的就是復用。
重要說明:一個節點的輸入點只能有一個,但是輸出點可以有多個。
使用技巧:
所有節點的參數和正向節點組件輸入都是可以相互轉化的。很多時候可以把相同的參數,轉換為輸入節點,然后用共同的元組件輸入。
3.4 預覽圖像節點 Preview Image
前面說到保存圖像節點,會自動保存到 output 文件夾下面,有時候我們只是想看看圖片是什么樣,并不想保存。比如中間過程的圖片,或者不確定圖片是否使我們想要的。這時候可以使用預覽圖像節點。
后記
本文從默認文生圖工作流入手,介紹了其中的核心節點。同時介紹了 Stable Diffusion 中的模型分類。更多節點使用,將在后續文章中介紹,敬請關注。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號