
《Hive編程指南》讀書筆記
前言:
最近剛接觸寫Hive SQL,卻發現許多查詢的執行速度遠不如預期。為了提升查詢效率,我去閱讀了《Hive編程指南》,希望通過理解其底層機制來找到優化的方式,并為未來能編寫出高效的SQL奠定基礎。謹以此文做個記錄。
一、Hive因何而生
先有Hadoop再有Hive
Hadoop實現了一個計算模型——MapReduce,它可以將計算任務分割成多個處理單元然后分散到一群家用的或服務器級別的硬件機器上,從而降低計算成本并提供水平可伸縮性。但是這套編程模型對于大多數數據分析分析師較為復雜和地銷,即便是Java開發編寫MapReduce程序也需要很多時間和精力。基于此,Hive提供了基于SQL的查詢語言(HiveQL),這邊能夠讓擁有SQL知識的用戶能夠輕松使用Hadoop進行大數據分析,因為Hive的底層會自動將這些查詢轉換為MapReduce任務。
二、Hive組成模塊
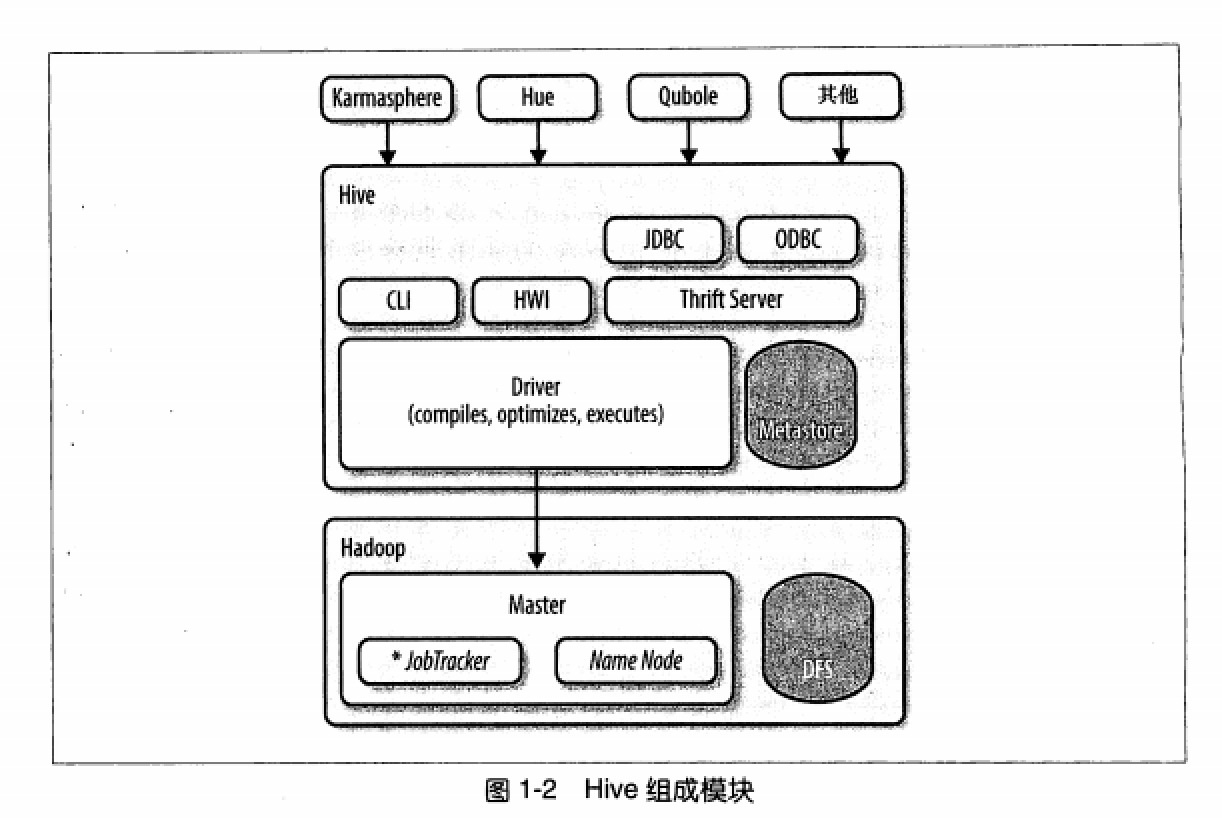
所有的命令和查詢都會進入Driver,通過該模塊對輸入進行解析編譯,對需求的計算進行優化,然后按照指定的步驟執行。
Hive通過JobTracker通信來初始化MapReduce任務,需要處理的數據文件是存儲在HDFS中的,而HDFS是由NameNode進行管理的。
Metastore(元數據存儲)是一個獨立的關系型數據庫,Hive會在其中保存表模式和其他系統元數據。
三、HQL執行流程
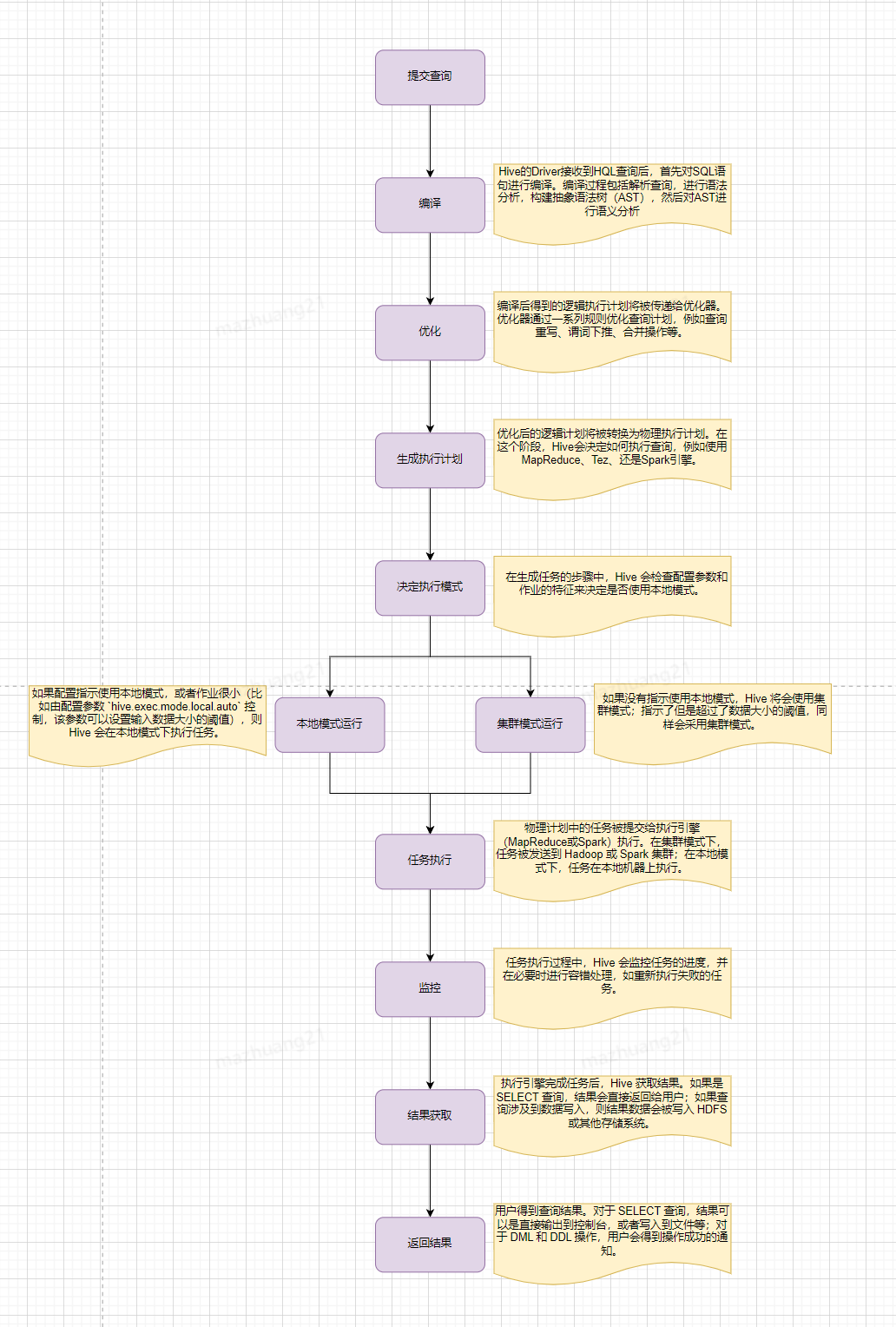
簡單來說,Hive會從Hadoop分布式文件系統(HDFS)中讀取原始數據,然后根據查詢定義,在單節點(本地模式)或者Hadoop集群上(集群模式)執行數據處理。處理完成后,Hive會將結果輸出到HDFS或者其他指定的存儲位置。
那么,Hive的執行時間主要花費在哪兒呢?我們可優化的部分是哪部分?
Hive的執行時間主要花費在以下幾個階段:
通常,MapReduce 作業的執行時間(尤其是 Shuffle 和 Reduce 階段)以及數據的讀寫操作是 Hive 查詢中最耗時的部分,也是我們優化過程中主要關注的部分,接下來我們看下有哪些常見的優化方式。
四、Hive常見的優化方式
本地模式
-- 開啟本地模式,默認為false
hive.exec.mode.local.auto=true
原理:有時Hive的輸入數據量是非常小的。在這種情況下,為查詢觸發執行任務的時間消耗可能會比實際job的執行時間要多得多。對于大多數這種情況,Hive可以通過本地模式在單臺機器上處理所有的任務。對于小數據集,執行時間可以明顯被縮短。用戶可以通過設計屬性
hive.exec.mode.local.auto的值為true,來讓Hive在適當的時候自動啟動這個優化。實踐有效,但如果并行執行的SQL過多,容易造成本地內存溢出。
map-side JOIN優化
#-- Hive v0.7之前需要通過添加標記 /*+ MAPJOIN(X) */ 觸發,如下圖
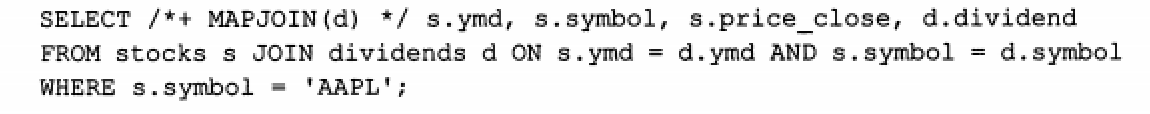
-- Hive v0.7版本開始之后,通過設置hive.auto.convert.JOIN的值為true開啟
set hive.auto.convert.JOIN=true
-- 設置小表的大下,單位為字節
set hive.mapjoin.smalltable.filesize=25000000
原理:如果所有表中有一個表足夠得小,是可以完成載入內存中的,那么這時Hive可以執行一個map-side JOIN,將小表完全放到內存,Hive便可以直接和內存中的小表進行逐一匹配,從而減少所需要的reduce過程,有時甚至可以減少某些map task任務。
并發執行
-- 通過設置參數hive.exec.parallel值為true,開啟并發執行,默認為false
set hive.exec.parallel=true
原理:Hive會將一個查詢轉化成一個或者多個階段。這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段等。默認情況下,Hive一次只會執行一個階段。但是有些階段并非完全互相依賴的,也就是說這些階段是可以并行執行的,這樣可以使得整個job的執行時間縮短。
通過設置參數hive.exec.parallel值為true,就可以開啟并發執行。
動態分區調整
-- 啟用動態分區,默認為false;
SET hive.exec.dynamic.partition=true;
-- 啟用動態分區模式為非嚴格模式。開啟嚴格模式時們必須保證至少有一個分區時靜態的。
SET hive.exec.dynamic.partition.mode=nonstrict;
-- 設置在一個動態分區插入操作中可以創建的最大分區數量
SET hive.exec.max.dynamic.partitions=1000;
-- 設置每個節點可以創建的最大分區數量
SET hive.exec.max.dynamic.partitions.pernode=100;
當執行查詢時,如果查詢條件包含分區鍵,Hive可以僅掃描相關分區的數據,從而減少了掃描的數據量,提高查詢效率;在執行動態分區的插入時,這些分區也可以并行寫入,從而提高了數據寫入的并行度和性能。通過以上參數,可更好的使用動態分區。
合并小文件
--是否和并Map輸出文件,默認true
SET hive.merge.mapfiles=true;
--是否合并 Reduce 輸出文件,默認false
SET hive.merge.mapredfiles=true;
-- 設置合并文件的大小閾值
SET hive.merge.size.per.task=256000000;
-- 設置小文件的平均大小閾值
SET hive.merge.smallfiles.avgsize=128000000;
由于一些小批量的寫入、MapReduce作業切割、數據傾斜等原因,Hive中可能會產生大量小文件,通過以上參數可進行小文件合并以減少讀取文件時的開銷、降低NameNode壓力,提升查詢效率。
數據傾斜優化
數據傾斜指的是在分布式處理過程中,數據不均勻地分配給各個節點處理,導致部分節點負載過重,而其他節點負載輕松,從而影響整體計算效率。數據傾斜出現的原因主要如下:
主要解決方案有:
最后就是我們關系型數據庫常用的優化方式同樣也適用與Hive。例如通過使用小表關聯大表的方式減少查詢數據量,提高查詢效率;Hive同樣也有索引的概念,通過建立索引減少MapReduce的輸入數據量,但同樣和關系型數據庫一樣,是否使用索引需要進行仔細評估,因為維護索引也需要額外的存儲空間,而且創建索引同樣消耗計算資源;Hive同樣也有EXPLAIN關鍵字,用于查詢Hive時如何將查詢轉化為MapReduce任務的,使用EXPLAIN EXTENDED語句可以產生更多的輸出信息,有興趣大家可自行查看。
總體而言,這本書對于剛入門學習寫HQL的我來說收獲很大,讓我初步對Hive有了基本的認知,也讓我對我寫的SQL有了更深入的了解。但是該書中的Hive應該版本比較低了,和我們現在所使用的可能有所偏差,不過入個門足夠了。本文除了書中內容還有些我個人理解,如有錯誤,歡迎指正。
作者: 馬壯
來源:京東云開發者社區 轉載請注明來源

 浙公網安備 33010602011771號
浙公網安備 33010602011771號