
CDP 技術(shù)系列(二):ClickHouse+Bitmap 實現(xiàn)海量數(shù)據(jù)標簽及群體組合計算
一、背景介紹
上一篇文章介紹了CDP中,面對單個標簽或群體數(shù)十億的數(shù)據(jù)如何存儲
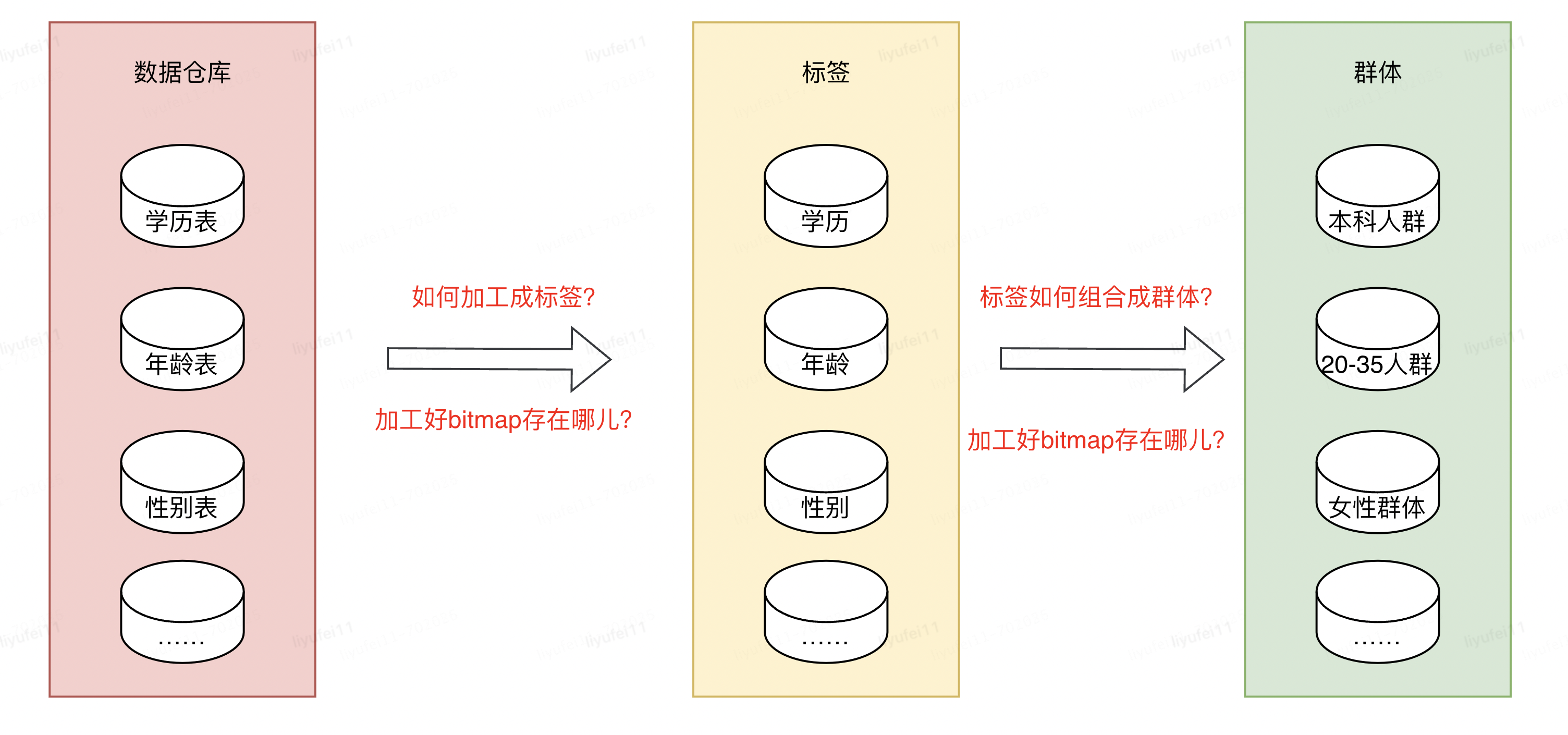
我們都知道數(shù)據(jù)倉庫的概念,它的里邊存儲了我們所有的數(shù)據(jù),其中就包含了標簽或群體所依賴的數(shù)據(jù),但是這些數(shù)據(jù)并不能直接拿來使用,想要變成業(yè)務需要的標簽或群體數(shù)據(jù),還需要進行加工。
數(shù)據(jù)工程師將數(shù)倉里的原始數(shù)據(jù),經(jīng)過一些列的數(shù)據(jù)作業(yè)加工成業(yè)務用戶需要的源表,比如性別表,學歷表,年齡表,購買行為表等等。
有了這些相對規(guī)整的源表,接下來就是如何利用這些表,去組合成我們需要的群體,然后通過群體再去做營銷,推廣等。
本篇要討論的主要就是使用什么方式快速圈選出人群。
二、問題描述
上文已經(jīng)講到有了標簽的存儲方式和源表,并且當前CDP平臺已經(jīng)有幾千+標簽,2W+群體,這其中涉及到的源表會非常多且大。
我們遇到的第一個問題,是如何將這么多張源表,加工成對應標簽的bitmap?
第二個問題,加工好這些bitmap文件之后,存儲在什么地方才能方便后續(xù)的使用?
第三個問題,存儲好這些標簽的bitmap之后,如何快速的進行組合計算,加工成用戶需要的群體?
比如我有三個標簽:學歷,年齡和性別,如何圈出:具有本科學歷的,年齡在20到35歲之間的女性群體。
三、解決方案
1)ClickHouse簡介
針對以上問題,我們使用了ClickHouse(以下簡稱CK),一個由俄羅斯Yandex在2016年年開源的?性能分析型SQL數(shù)據(jù)庫,是一個用于聯(lián)機分析處理(OLAP)的列式數(shù)據(jù)庫管理系統(tǒng)(columnar DBMS)。
它具有以下特點:
1、完備的數(shù)據(jù)庫管理功能,包括DML(數(shù)據(jù)操作語言)、DDL(數(shù)據(jù)定義語言)、權(quán)限控制、數(shù)據(jù)備份與恢復、分布式計算和管理。
2、列式存儲與數(shù)據(jù)壓縮: 數(shù)據(jù)按列存儲,在按列聚合的場景下,可有效減少查詢時所需掃描的數(shù)據(jù)量。同時,按列存儲數(shù)據(jù)對數(shù)據(jù)壓縮有天然的友好性(列數(shù)據(jù)的同類性),降低網(wǎng)絡(luò)傳輸和磁盤 IO 的壓力。
3、關(guān)系模型與SQL: ClickHouse使用關(guān)系模型描述數(shù)據(jù)并提供了傳統(tǒng)數(shù)據(jù)庫的概念(數(shù)據(jù)庫、表、視圖和函數(shù)等)。與此同時,使用標準SQL作為查詢語言,使得它更容易理解和學習,并輕松與第三方系統(tǒng)集成。
4、數(shù)據(jù)分片與分布式查詢: 將數(shù)據(jù)橫向切分,分布到集群內(nèi)各個服務器節(jié)點進行存儲。與此同時,可將數(shù)據(jù)的查詢計算下推至各個節(jié)點并行執(zhí)行,提高查詢速度。
更多特性可查看官方文檔:https://clickhouse.com/docs/zh/introduction/distinctive-features
除了上文CK的特性之外,它還具有分析數(shù)據(jù)高性能,開發(fā)流程簡便,開源社區(qū)活躍度高,并且支持壓縮位圖等優(yōu)勢。
有了這些之后,就可以利用它的這些特性和優(yōu)勢,來解決上文提出的問題。
2)解決數(shù)據(jù)存儲問題
針對數(shù)據(jù)存儲問題,其實包含兩個方面:一個是源數(shù)據(jù)的存儲,另一個是標簽群體bitmap的數(shù)據(jù)存儲。
由上文可以看出,當前數(shù)據(jù)源表存儲在數(shù)倉中,但是處在它之上的查詢和管理工具,比如hive,spark,presto等,并不能滿足我們的計算需求。行式存儲示例:
| Row | user_id | 學歷 | 年齡 | 性別 |
| #0 | id1 | 本科 | 24 | 女 |
| #1 | id2 | 本科 | 25 | 男 |
| #2 | id3 | 碩士 | 26 | 女 |
| #3 | id4 | 碩士 | 27 | 男 |
CK在列式存儲與數(shù)據(jù)壓縮方面的優(yōu)勢是我們選擇它的原因,它被設(shè)計成可以工作在傳統(tǒng)磁盤上,能提供每GB更低的存儲成本,并且如果可以使用SSD和內(nèi)存,它也會合理的利用這些資源。列式存儲示例:
| Row: | #0 | #1 | #2 | #3 |
| user_id | id1 | id2 | id3 | id4 |
| 學歷 | 本科 | 本科 | 碩士 | 碩士 |
| 年齡 | 20-24 | 20-24 | 25-28 | 25-28 |
| 性別 | 女 | 男 | 女 | 男 |
| offset | 1 | 2 | 3 | 4 |
為什么列式存儲查詢更有效率,主要包含以下方面:
針對第二個問題bitmap數(shù)據(jù)存儲,CK本身并沒有這種類型,而是通過參數(shù)化的數(shù)據(jù)類型AggregateFunction(name, types_of_arguments…)來實現(xiàn),建表示例:
CREATE
TABLE cdp.tag ON CLUSTER DEFAULT
(
`code` String,
`value` String,
`version` String,
`offset_bitmap` AggregateFunction(groupBitmap, UInt64)
)
ENGINE = ReplicatedMergeTree
(
'/clickhouse/tables/cdp/{shard}/group_1',
'{replica}'
)
PARTITION BY(code)
ORDER BY(code)
SETTINGS storage_policy = 'default',
use_minimalistic_part_header_in_zookeeper = 1,
index_granularity = 8192;
這樣,源數(shù)據(jù)和加工后的bitmap都可以存儲在CK中,當然,數(shù)據(jù)由數(shù)倉推送到CK中還需要數(shù)據(jù)管道提供支持。
3)解決bitmap加工問題
源數(shù)據(jù)和準備好之后,則是如何將源表的數(shù)據(jù)加工成標簽的bitmap,這方面CK擁有非常多的bitmap函數(shù)支持,可以參考:https://clickhouse.com/docs/en/sql-reference/functions/bitmap-functions
在上文的列式存儲表數(shù)據(jù)中,多了一行id對應的offset,這些offset可以在數(shù)據(jù)推送過程中寫入。假設(shè)表名為tag.source,如果想生成三個標簽的bitmap,則可參考如下語句:
# 學歷標簽
INSERT INTO cdp.tag_bitmap1
SELECT
'tag_education' AS code,
value AS value,
'version1' AS version,
groupBitmapState(offset) AS offset_bitmap
FROM
tag.source
WHERE
value 有了三個標簽之后,即可計算出上文中想創(chuàng)建的,本科學歷的20-35歲的女性群體:
WITH
(
SELECT
groupBitmapOrStateOrDefault(offset_bitmap)
FROM
(
SELECT offset_bitmap FROM cdp.tag_bitmap1 WHERE value
4)解決快速加工問題
解決了數(shù)據(jù)存儲和加工問題之后,還有一個待考慮的問題,源表中的數(shù)據(jù)量過大,導致出現(xiàn)bitmap加工耗時過長,甚至出現(xiàn)加工超時的情況。
為了應對這個問題,可以采用分布式多分片的方式部署CK,每個分片保證至少有2個主備節(jié)點,來達到高性能、高可用。分片和節(jié)點之間通過Zookeeper來保存元數(shù)據(jù),以及互相通信。這樣CK本身是對Zookeeper強依賴的,所以還需要部署一個3節(jié)點的高可用Zookeeper集群。

集群的配置可以在系統(tǒng)表system.clusters中查詢:

上文CK部署架構(gòu)圖中引入了分布式表和本地表:
分布式表:是邏輯上的表、可以理解為視圖。比如要查一張表的全量數(shù)據(jù),可以查詢分布式表,在執(zhí)行時請求會分發(fā)到每一個節(jié)點,等所有節(jié)點都執(zhí)行結(jié)束,再在某一個節(jié)點上匯總到一起,因此會對單節(jié)點造成壓力。
本地表:每個節(jié)點的實際存儲數(shù)據(jù)的表,本地表每個節(jié)點都要創(chuàng)建,CK通常是會按自己的策略把數(shù)據(jù)平均寫到每一個節(jié)點的本地表,本地數(shù)據(jù)本地計算,最后再把所有節(jié)點的結(jié)果匯總到一起。
由于使用分布式表可能造成單節(jié)點的壓力,所以我們可以在應用里,通過JDBC在每個節(jié)點執(zhí)行SQL得到想要的結(jié)果后,再在應用內(nèi)進行聚合。不過,要注意的是像平均值這樣的計算,只能是通過先求SUM再求COUNT來實現(xiàn),直接使用平均值函數(shù)會得到錯誤的結(jié)果。
四、現(xiàn)狀及展望
當前CDP中所有的標簽和群體最新版本均存儲在CK中,也就是說所有的標簽和群體的組合默認使用的均是最新版本。
這其實也是為什么經(jīng)常有用戶問,我的群體之前加工成功,今天加工失敗了,還能用嗎?答案是肯定的,就是因為我們默認使用的是群體加工成功的最新版本。
作者:京東科技 黎宇飛
來源:京東云開發(fā)者社區(qū) 轉(zhuǎn)載請注明來源

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號