
重新認識Elasticsearch-一體化矢量搜索引擎
前言
2023 哪個網絡詞最熱?我投“生成式人工智能”一票。過去一年大家都在擁抱大模型,所有的行業都在做自己的大模型。就像冬日里不來件美拉德色系的服飾就會跟不上時代一樣。這不前段時間接入JES,用上好久為碰的RestHighLevelClient包。心血來潮再次訪問Elasticsearch官網,發現風格又變了!很驚艷,不信你看
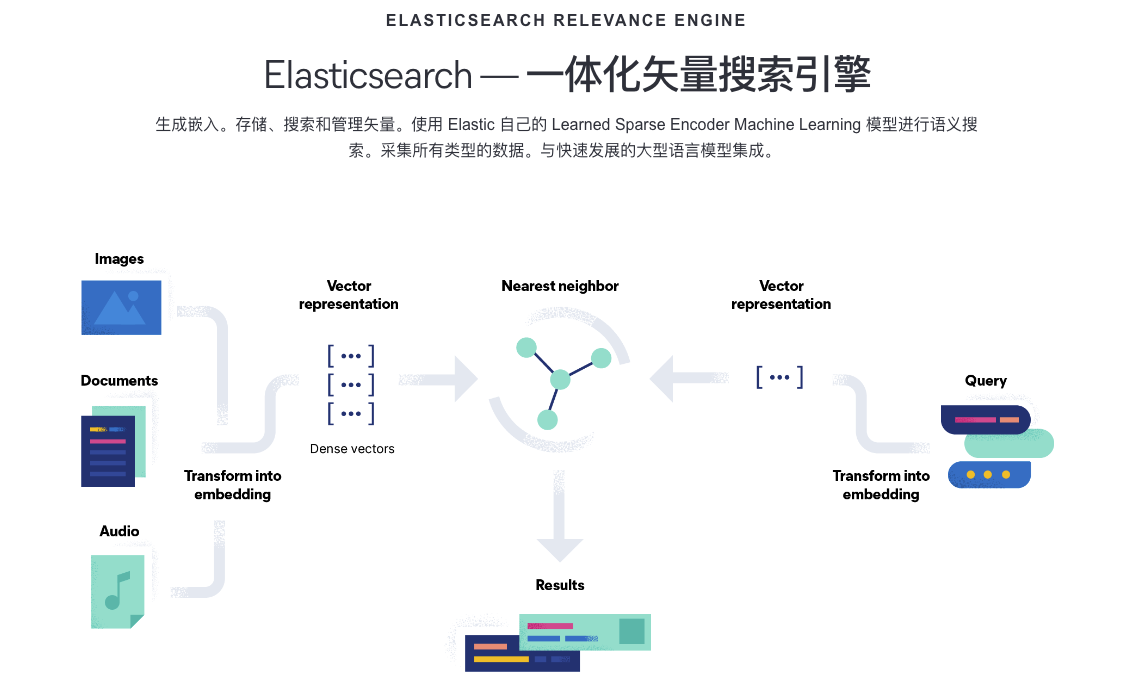
很久沒有上Elasticsearch官網。以前的Elasticsearch是以全文搜索引擎為主打的。去年還在想RediSearch會不會撼動Elasticsearch的地位。現在來看它找到內卷焦慮的方子-換個戰場去卷別人!所以我就很好奇看看他是如何卷的?決定一探究竟。那么今天就來看下生成式AI和Elasticsearch Relevance Engine(ESRE)最后學習下Elasticsearch作為向量數據如何使用。
一、什么是生成式AI
生成式 AI 是人工智能的一個分支,其核心是能夠生成原創內容的計算機模型。通過利用大型語言模型、神經網絡和機器學習的強大功能,生成式 AI 能夠模仿人類創造力生成新穎的內容。這些模型使用大型數據集和深度學習算法進行訓練,從而學習數據中存在的底層結構、關系和模式。根據用戶的輸入提示,生成新穎獨特的輸出結果,包括圖像、視頻、代碼、音樂、設計、翻譯、問題回答和文本。
流行的生成式AI有哪些
1.ChatGPT ChatGPT 是由 OpenAI 開發的一個大型語言模型,自 2022 年 11 月公開發布以來取得了巨大成功。它使用對話式聊天界面與用戶互動,并對輸出結果進行微調。它旨在理解文本提示,并生成類似于人的回復,而且它已展示出了參與對話交流、回答相關問題,甚至展現幽默感的能力。
據說,最初向用戶免費提供的 ChatGPT-3 版本是根據互聯網上超過 45 TB 的文本數據進行訓練的。不久之后,Microsoft 將 GPT 的一個版本集成到了 Bing 搜索引擎中。OpenAI 的升級版、基于訂閱的 ChatGPT-4 是于 2023 年 3 月推出的。
ChatGPT 采用最先進的轉換器架構。GPT 是“Generative Pre-trained Transformer”(生成式預訓練轉換器)的縮寫,轉換器架構為自然語言處理 (NLP) 領域帶來了革命性的變化。
2.DALL-E 同樣來自 OpenAI 的 DALL-E 2 專注于生成圖像。DALL-E 結合了 GAN 架構與變分自動編碼器,可基于文本提示生成高度細膩和富有想象力的視覺結果。借助 DALL-E,用戶可以描述自己心目中的圖像和風格,模型就會生成它。與 MidJourney 和新晉加入的 Adobe Firefly 等競爭對手一樣,DALL-E 和生成式 AI 正在徹底改變圖像的創建和編輯方式。隨著整個行業不斷涌現的新興能力,視頻、動畫和特效也將發生類似的轉變。
3.Google Bard 最初是基于 Google LaMDA 系列大型語言模型的一個版本構建而成,后來升級到更先進的 PaLM 2,是 Google ChatGPT 的替代品。Bard 的功能與 ChatGPT 類似,可以編碼、解決數學問題、回答問題、寫作,以及提供 Google 搜索結果。
在電商行業的應用
電子商務和零售業領域中的 AI:生成式 AI 可以利用購物者的購買模式推薦新產品,并創建更順暢的購物流程,從而幫助電子商務企業為購物者提供更具個性化的購買體驗。對于零售商和電子商務企業來說,無論從更直觀的瀏覽到使用聊天機器人支持的 AI 客戶服務功能,以及 AI 常見問題解答板塊,AI 都可以打造更好的用戶體驗。
金融服務領域中的 AI:生成式 AI 可用于市場趨勢預測、市場模式研究、投資組合優化、欺詐保護、算法交易和個性化客戶服務。模型還可以根據歷史趨勢生成合成數據,從而幫助進行風險分析和決策。
生成式 AI 模型的局限性
二、Elasticsearch Relevance Engine
是的ChatGPT 和 LLM 面臨很多挑戰。如專業領域數據的質量準確性,相關性數據缺乏過濾,維護和訓練成本,安全性和性能,可解釋性等。那接下來看下Elastic的ESRE是如何幫助他們解決問題的。
ESRE 提供了多項用于創建高度相關的 AI 搜索應用程序的新功能。ESRE 站在 Elastic 這個搜索領域的巨人肩膀之上,并基于兩年多的 Machine Learning 研發成就構建而成。Elasticsearch Relevance Engine 將 AI 的最佳實踐與 Elastic 的文本搜索進行了結合。ESRE 為開發人員提供了一整套成熟的檢索算法,并能夠與大型語言模型 (LLM) 集成。不僅如此,ESRE 還可通過已經得到 Elastic 社區信任的簡單、統一的 API 訪問,因此世界各地的開發人員都可以立即開始使用它來提升搜索相關性。
Elasticsearch Relevance Engine 的可配置功能可用于通過以下方式幫助提高相關性:
?應用包括 BM25f(這是混合搜索的關鍵組成部分)在內的高級相關性排序功能
?使用 Elastic 的矢量數據庫創建、存儲和搜索密集嵌入
?使用各種自然語言處理 (NLP) 任務和模型處理文本
?讓開發人員在 Elastic 中管理和使用自己的轉換器模型,以適應業務特定的上下文
?通過 API 與第三方轉換器模型(如 OpenAI 的 GPT-3 和 4)集成,以根據客戶在 Elasticsearch 部署中整合的數據存儲,檢索直觀的內容摘要
?使用 Elastic 開箱即用型的 Learned Sparse Encoder 模型,無需訓練或維護模型,就能實現 ML 支持的搜索,從而在各種域提供高度相關的語義搜索
?使用倒數排序融合 (RRF) 輕松組合稀疏和密集檢索;倒數排序融合是一種混合排名方法,讓開發人員能夠自行優化 AI 搜索引擎,以符合他們獨特的自然語言和關鍵字查詢類型的組合
?與 LangChain 等第三方工具集成,以幫助構建復雜的數據管道和生成式 AI 應用程序
三、Elasticsearch 向量庫適合用在哪
Elasticsearch 支持的信息檢索方法:
Elasticsearch 如何緩解 LLM 問題:
Elasticsearch 作為向量數據庫的優勢:
Elasticsearch和LLM結合有三種方式:
方式一:Elasticsearch和LLM
使用 Elasticsearch 作為向量存儲并與 LLM 集成
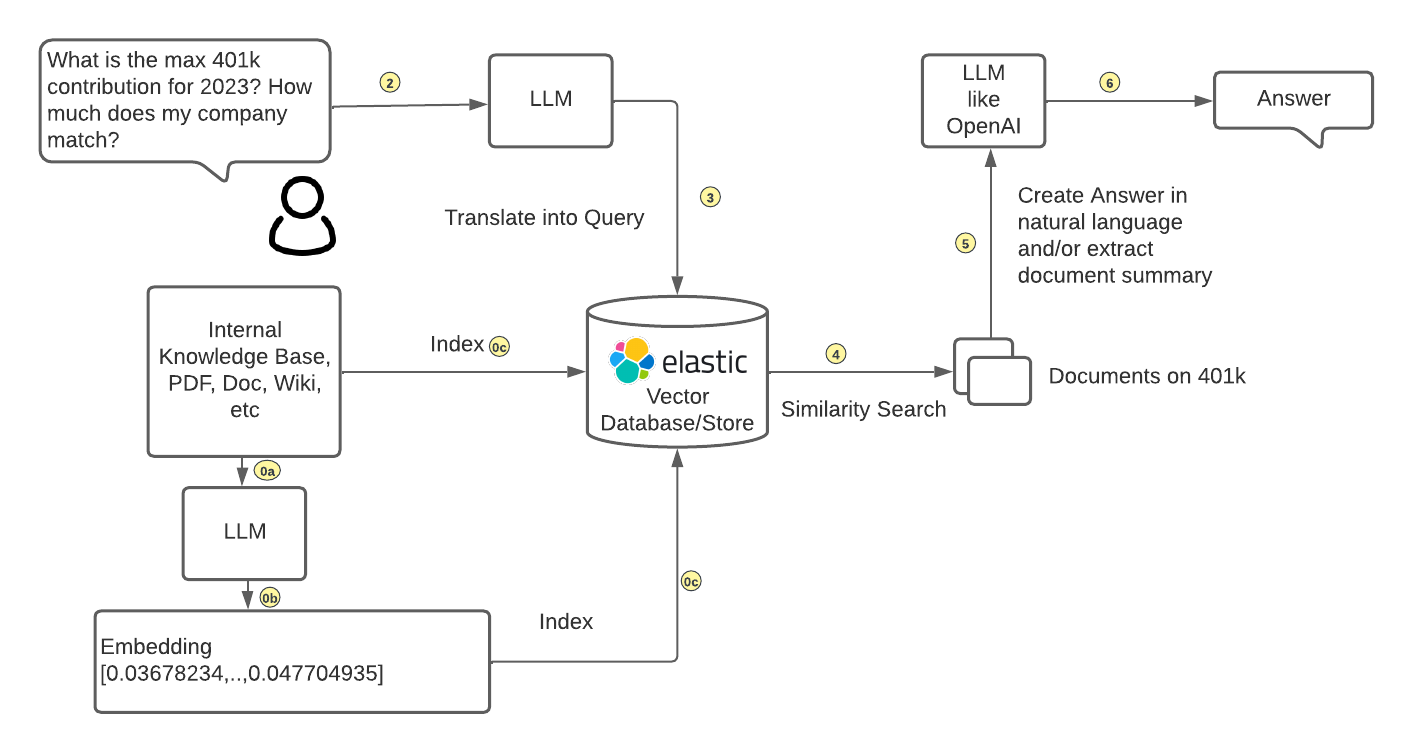
用戶將問題數據和生成的嵌入向量一起導入 Elasticsearch。Elasticsearch 會存儲和索引這些數據(用戶問題的上下文),以便進行高效的檢索。當用戶提出問題時,用戶可以使用 Elasticsearch 的近似最近鄰 (KNN) 搜索功能,根據用戶的查詢在數據集中找到最相似的嵌入向量。這一步驟可以快速找到與用戶問題相關的潛在答案。最后Elasticsearch 將搜索結果(包含相關數據的上下文信息)傳遞給 ChatGPT 或其他 LLM。LLM 會利用這些上下文信息,生成更加準確、流暢和自然的自然語言回答,并返回給用戶。
方式二:Elasticsearch Relevance Engine 和LLM
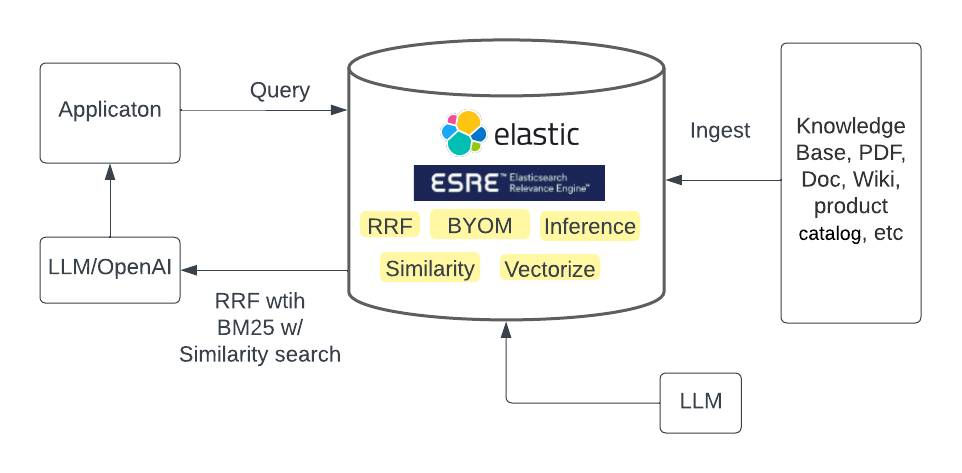
Elasticsearch Relevance Engine (ESRE) 使 BYOLLM 成為現實。此功能以前只能通過機器學習訪問,現在已經可以輕松使用。 從 8.8 版開始,可以使用熟悉的搜索 API 將 LLM 模型攝取和查詢到 Elasticsearch 中,就像任何其他數據一樣。重要的是他使用RRF進行混合檢索,將檢索結果提高了一個水平,同事降低了復雜性和運營成本。
方式三:使用內置的稀疏編碼模型
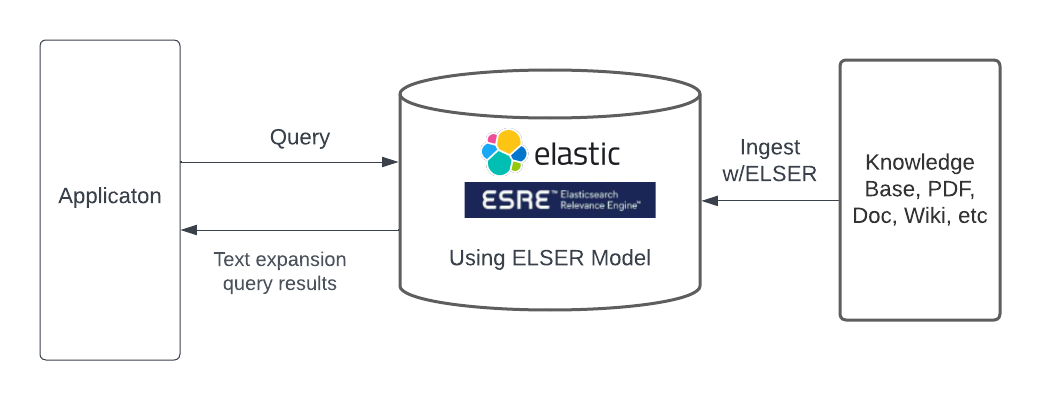
Elastic Learned Sparse Encoder 是 Elastic 開箱即用的語言模型,其性能優于 SPLADE(SParse Lexical AnD Expansion Model),而 SPLADE 本身就是最先進的模型。Elastic Learned Sparse Encoder 解決了詞匯不匹配。就像其他搜索端點一樣,可以通過text_expansion查詢訪問 Elastic Learned Sparse Encoder。Elastic Learned Sparse Encoder 使我們的用戶只需點擊一下即可開始最先進的生成式 AI 搜索并立即產生結果。Elastic Learned Sparse Encoder 也是 Elastic 的一項商業功能。
四、Elasticsearch 向量檢索
ES作為向量數據庫提供三種能力:1.存儲嵌入 2.高效搜索相鄰數據 3.將文本嵌入到向量表示。
首先將待檢索的數據轉換成向量存儲。其表現形式為128維的float數組。之后將數組索引到ES的dense_vector類型的字段中。最后基于ANN或KNN進行檢索。如下圖
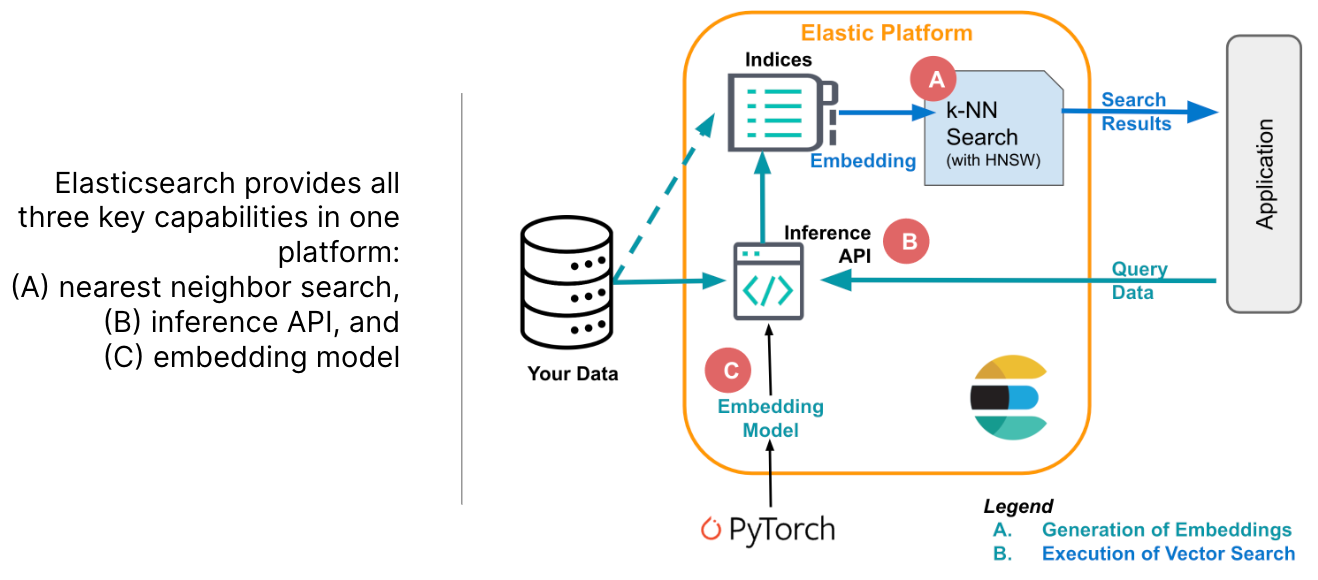
五、Elasticsearch vector search
我們來看一個ES中創建和查詢向量數據的示例
第一步我們創建一個向量索引image-index
PUT /image-index
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"file-type": {
"type": "keyword"
}
}
}
}第二步向索引image-index中批量插入數據
POST /image-index/_bulk?refresh=true
{ "index": { "_id": "1" } }
{ "image-vector": [1, 5, -20], "title-vector": [12, 50, -10, 0, 1], "title": "moose family", "file-type": "jpg" }
{ "index": { "_id": "2" } }
{ "image-vector": [42, 8, -15], "title-vector": [25, 1, 4, -12, 2], "title": "alpine lake", "file-type": "png" }
{ "index": { "_id": "3" } }
{ "image-vector": [15, 11, 23], "title-vector": [1, 5, 25, 50, 20], "title": "full moon", "file-type": "jpg" }最后通過KNN api檢索數據
POST /image-index/_search
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}查詢結果如下
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.008547009,
"hits": [
{
"_index": "image-index",
"_id": "1",
"_score": 0.008547009,
"_source": {
"image-vector": [
1,
5,
-20
],
"title-vector": [
12,
50,
-10,
0,
1
],
"title": "moose family",
"file-type": "jpg"
},
"fields": {
"file-type": [
"jpg"
],
"title": [
"moose family"
]
}
},
{
"_index": "image-index",
"_id": "3",
"_score": 0.00061349693,
"_source": {
"image-vector": [
15,
11,
23
],
"title-vector": [
1,
5,
25,
50,
20
],
"title": "full moon",
"file-type": "jpg"
},
"fields": {
"file-type": [
"jpg"
],
"title": [
"full moon"
]
}
},
{
"_index": "image-index",
"_id": "2",
"_score": 0.00045045046,
"_source": {
"image-vector": [
42,
8,
-15
],
"title-vector": [
25,
1,
4,
-12,
2
],
"title": "alpine lake",
"file-type": "png"
},
"fields": {
"file-type": [
"png"
],
"title": [
"alpine lake"
]
}
}
]
}
}以上是作為向量數據庫的實例。ES是可以作為AI查詢。支持AI查詢的客戶端包括JavaScript,Python,Go,PHP,Ruby(沒有java)。有興趣的可以直接去github上去試跑( elasticsearch-labs )
六、總結
Elasticsearch確實卷。它的架構已經不是以前,為了實現更快的查詢而迭代。2024年Elasticsearch提出了無服務架構的理念。將存儲和計算完全分離開。無服務器架構標志著 Elasticsearch 的重大重組。它的構建是為了利用最新的云原生服務,以輕松的管理提供優化的產品體驗。它不僅具備數據湖的存儲能力,還擁有與 Elasticsearch 相媲美的快速搜索性能,同時通過無需人工干預的集群管理和擴展,實現了操作的簡便性。
七、名詞解釋
RRF:RRF 是 Elasticsearch 中新推出的一種混合搜索技術,可以將來自不同搜索方法的結果進行融合和排序,以提供更全面、更準確的搜索結果。
ANN:ANN 代表人工神經網絡 (Artificial Neural Networks)。人工神經網絡是一種計算機科學和人工智能領域的算法模型,它模仿人類大腦的神經網絡。
KNN:代表 k 近鄰。它是一種機器學習算法,用于在數據集中找到與給定查詢最相似的 k 個點。KNN 算法可用于各種任務,包括分類、回歸和聚類。
作者:京東保險 管順利
來源:京東云開發者社區 轉載請注明來源

 浙公網安備 33010602011771號
浙公網安備 33010602011771號