DDD領域驅動設計的理解
前言
領域驅動設計(DDD,Domain-Driven Design)是一套以業務領域知識為中心、以統一語言和模型為驅動的復雜軟件系統設計方法學。
它的核心思想是:把技術實現與業務知識深度融合,讓代碼成為業務概念的忠實映射,從而持續交付真正解決業務問題的軟件。
領域驅動設計相關概念
領域模型
領域模型是業務概念在程序中的一種表達方式。
領域模型可以用來設計和理解整個軟件結構。面向對象設計中的類概念是領域模型的一種表達方式。與此類似,UML的建模方法也可以應用在對領域模型的表達上。
但是要區分的一點就是,領域模型≠數據模型。
領域模型的組成元素:實體、值對象、聚合、領域服務、領域事件
實體(Entity)
實體通常指具有唯一標識的具體對象或事物。
實體通常具有自己的生命周期,可以被創建、修改和刪除。
在數據庫中,實體通常對應著數據庫表的一行記錄,每個實體具有唯一的標識符(通常是主鍵)。
在代碼模型中,實體的表現形式是實體類,這個類包含了實體的屬性和方法,通過這些方法實現實體自身的業務邏輯。
值對象(Value Object)
值對象(Value Object)是通過對象屬性值來識別的對象,它將多個相關屬性組合為一個概念整體。
實體可以使用 ID 標識,但是值對象是用屬性標識,值對象通常不可變,一旦創建就不能修改,只能通過創建新的值對象來替換原來的值對象。
在數據庫中,值對象通常對應著數據庫表的一組字段,每個值對象不具有唯一的標識符而是通過一組字段來描述其屬性。
值對象在代碼中有這樣兩種形態。
- 如果值對象是單一屬性,則直接定義為實體類的屬性;
- 如果值對象是屬性集合,則把它設計為 Class 類,Class 將具有整體概念的多個屬性歸集到屬性集合,這樣的值對象沒有 ID,會被實體整體引用。
聚合
聚合(Aggregate)是由一個或多個強關聯的實體和值對象組成的集合。
領域模型內的實體和值對象就好比個體,而能讓實體和值對象協同工作的組織就是聚合,它用來確保這些領域對象在實現共同的業務邏輯時,能保證數據的一致性。
聚合有一個聚合根和上下文邊界,這個邊界根據業務單一職責和高內聚原則,定義了聚合內部應該包含哪些實體和值對象,而聚合之間的邊界是松耦合的。按照這種方式設計出來的微服務很自然就是“高內聚、低耦合”的
聚合根
聚合根(Aggregate Root)是聚合的根實體,它不僅是實體,也是聚合的管理者,管理著聚合內其他對象的生命周期和完整性。
聚合根是聚合中的唯一標識符,是整個聚合的唯一入口點,所有的操作都是通過聚合根來進行的。
領域服務
領域服務(Domain Service)主要用于處理那些不適合放在實體(Entity)或值對象(Value Object)中的業務邏輯。
領域服務具有以下特點:
- 領域邏輯的封裝 :領域服務封裝了領域特定的業務邏輯,這些邏輯通常涉及多個領域對象的交互,這種封裝有助于保持實體和值對象的職責單一和清晰
- 無狀態:領域服務通常是無狀態的,它們不保存任何業務數據,而是操作領域對象來完成業務邏輯。這有助于保持服務的可重用性和可測試性。
- 獨立性:領域服務通常與特定的實體或值對象無關,它們提供了一種獨立于領域模型的其他部分的方式來實現業務規則
- 重用性:領域服務可以被不同的應用請求重用,例如不同的應用服務編排或領域事件處理器
- 接口清晰:領域服務的接口應該清晰的反映其提供的業務能力,參數的返回值應該是領域對象或基本數據類型
領域事件
領域事件(Domain Event)代表領域中的發生的重要事件,可以用于通知其他領域對象或跨限界上下文進行解耦和協作。
這些事件通常是由領域實體或聚合根的狀態變化觸發的。領域事件不僅僅是數據的變化,它們還承載了業務上下文和業務意圖。
領域事件具有以下特點:
- 意義明確:領域事件通常具有明確的業務含義,例如“用戶已下單”、“商品已支付”等。
- 不可變性:一旦領域事件被創建,它的狀態就不應該被改變。這有助與確保事件的一致性和可靠性。
- 時間相關性:領域事件通常包括事件發生的時間戳,這有助于追蹤事件的順序和時間線
- 關聯性:領域事件可能被特定的領域實體和聚合根相關聯,者有助于完成事件上下文
- 可觀察性:領域事件可以被其他部分的系統監聽和響應,有助于實現系統間解耦
領域事件和我們常聽說的MQ中的事件不一樣,一般不會在分布式系統之間傳遞,只會在單個微服務內部傳遞。
它起到最大的好處和MQ一樣,就是解耦,通過事件的方式來解除領域之間的耦合,通過發布事件的方式進行一種松耦合的通信,而不用依賴具體的實現細節。
領域模型分層架構
DDD的分層架構是一個四層架構,從上到下依次是:用戶接口層、應用層、領域層和基礎層。
分層架構可以簡單分為兩種,即嚴格分層架構和松散分層架構。在嚴格分層架構中,某層只能與位于其直接下方的層發生耦合,而在松散分層架構中,則允許某層與它的任意下方層發生耦合。
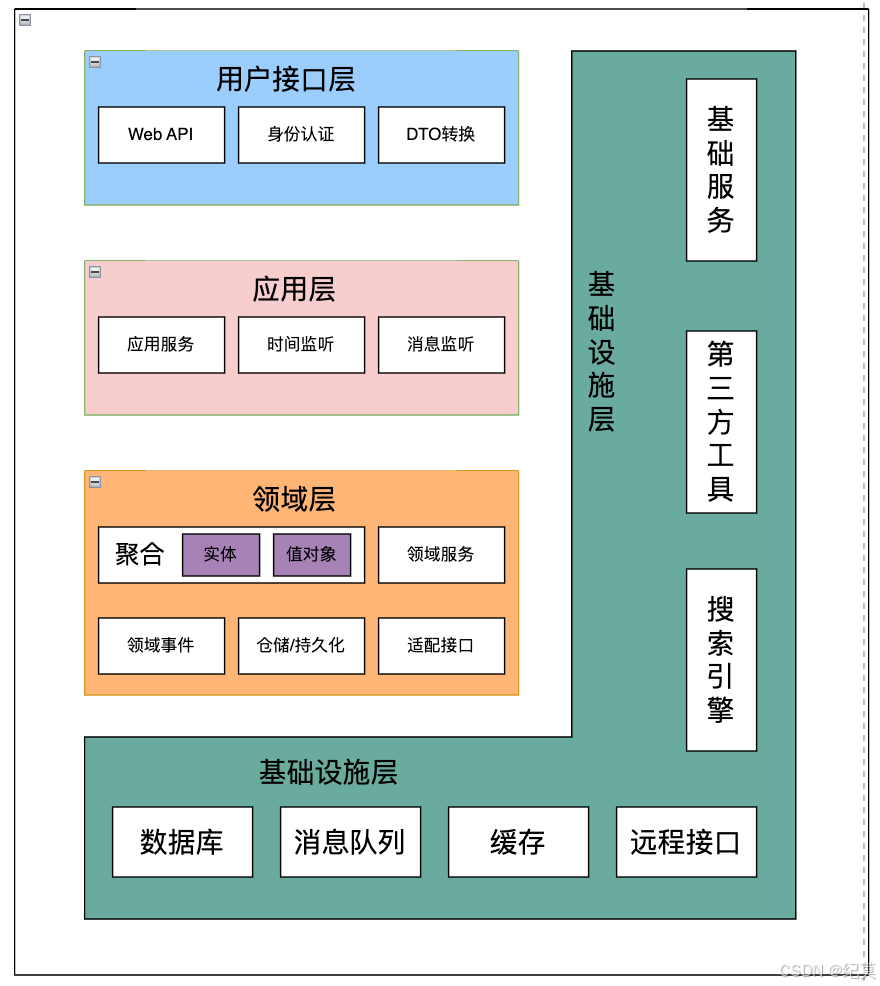
這種分層的結構的優點有:
- 開發人員可以只關注整個結構中的某一層。
- 可以很容易的用新的實現來替換原有層次的實現。
- 可以降低層與層之間的依賴。
- 有利于標準化。
- 利于各層邏輯的復用。
當然也有一定的弊端:
- 降低了系統的性能。這是顯然的,因為增加了中間層,不過可以通過緩存機制來改善。
- 可能會導致級聯的修改。這種修改尤其體現在自上而下的方向,不過可以通過依賴倒置來改善。
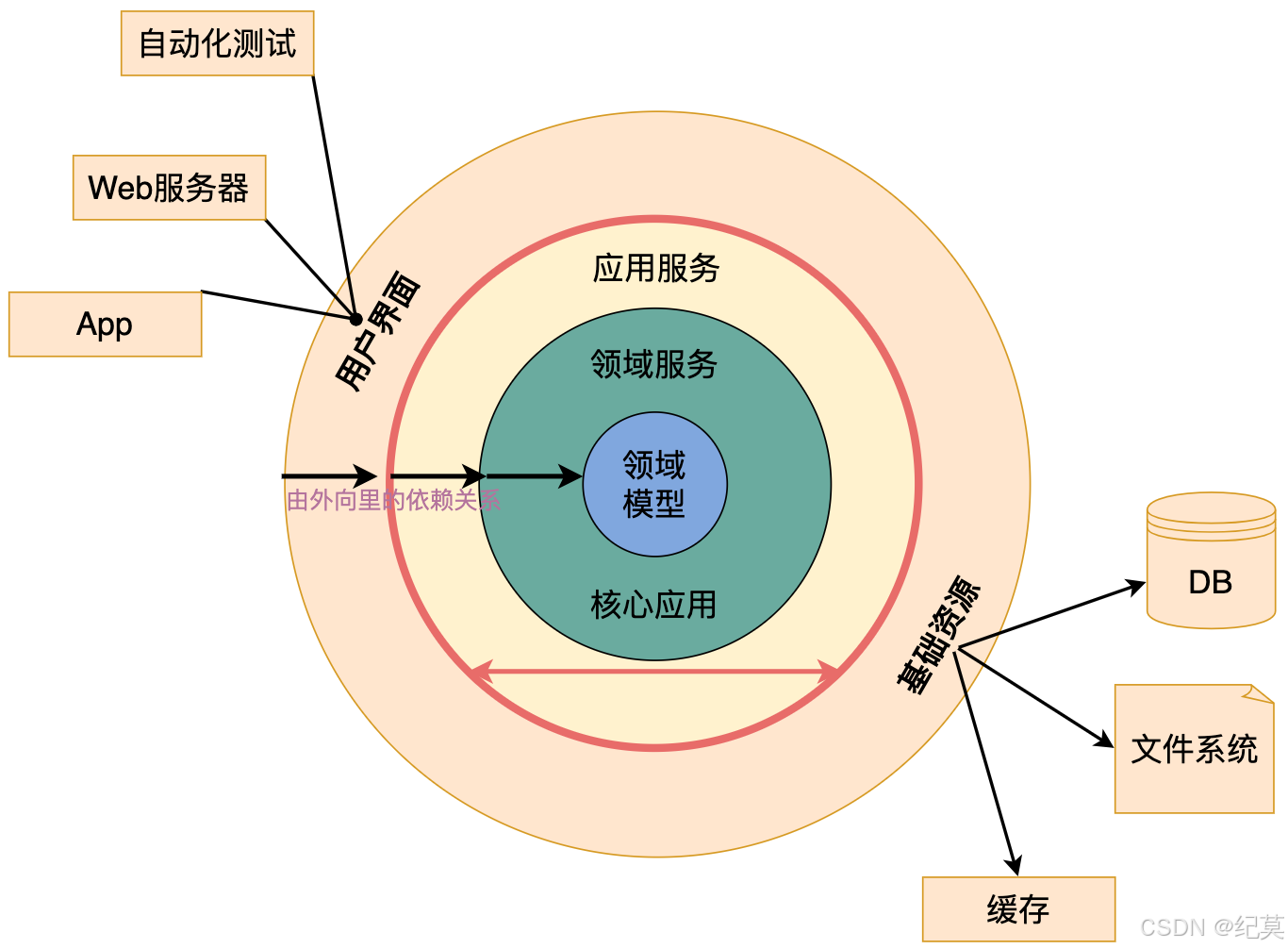
洋蔥分層架構
洋蔥架構,就是像洋蔥一樣的一層一層,從外到內的架構形式,如下圖
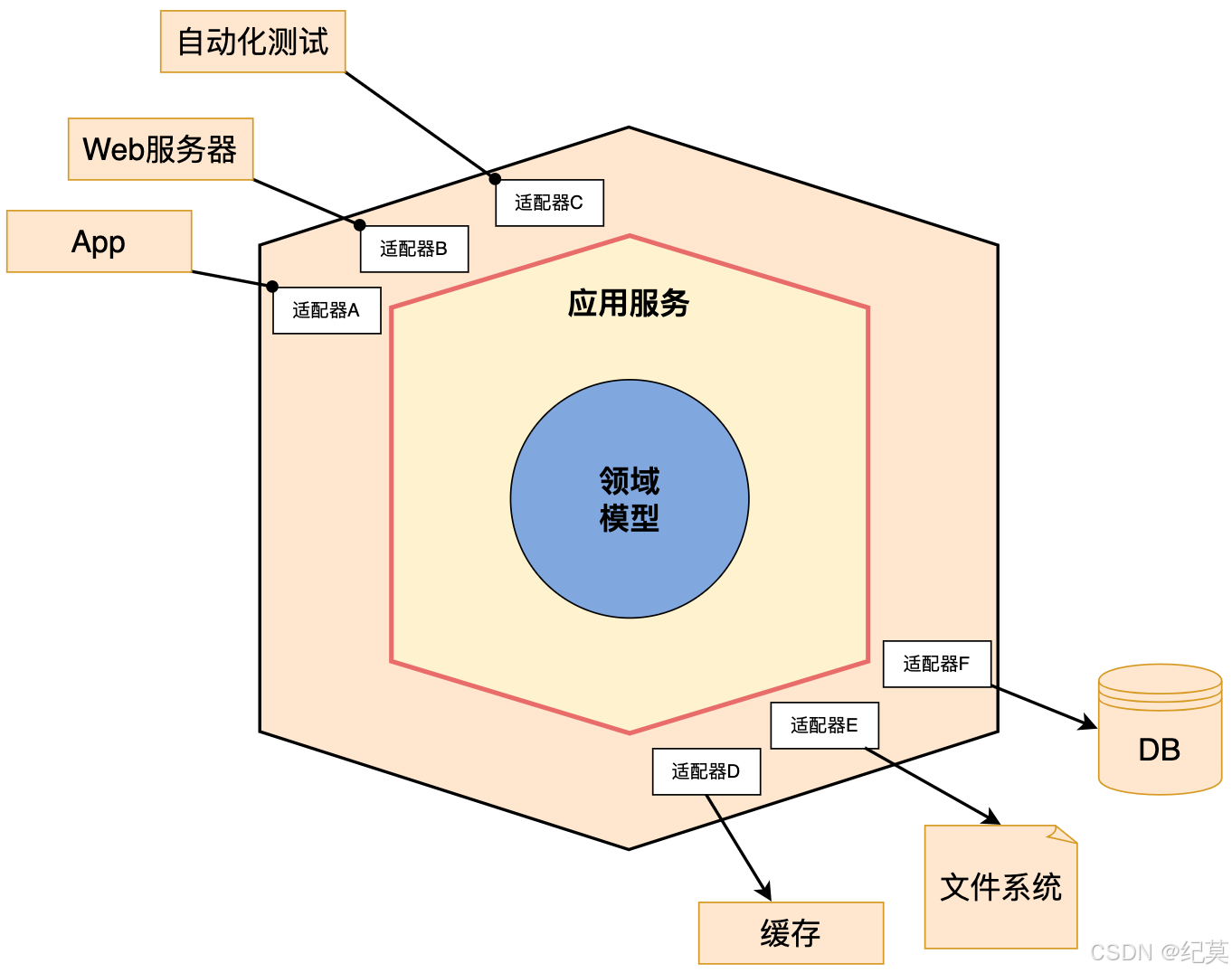
六邊形分層架構
六邊形架構是 Alistair Cockburn 在2005年提出,解決了傳統的分層架構所帶來的問題,實際上它也是一種分層架構,只不過不是上下或左右,而是變成了內部和外部。六邊形架構又名“端口-適配器架構”:
雖然 DDD 分層架構、洋蔥架構(整潔架構)、六邊形架構的架構模型表現形式不一樣,但是這三種架構模型的設計思想都是微服務架構高內聚低耦合原則的完美體現,都是以領域模型為中心的設計思想。
領域模型設計相關
倉儲
倉儲(Repository)是用于管理領域對象的創建、更新和持久化的接口。
倉儲充當領域模型和數據存儲之間的中介,隱藏了底層的數據訪問細節,提供了一致的接口和抽象,使得領域對象的訪問和持久化變得簡單和統一。
工廠
工廠(Factory)是以構建領域模型(實體或值對象)為職責的類或方法。
工廠可以利用不同的業務參數構建不同的領域模型。
對于簡單的業務邏輯實現可以不使用工廠。工廠的實現不一定是類的形式,也可以是具備工廠功能的方法。
貧血模型
貧血模型(Anemic Domain Model)則是一種將數據與行為分離的模型,其中數據由對象持有,而行為則由外部服務提供。
它的主要特征是領域對象缺乏行為,通常只包含數據屬性和簡單的 getter 和 setter 方法,而業務邏輯則被放置在服務層中。
例如下面商品
/**
* 商品類
*/
public class Goods {
private String name;
private BigDecimal price;
private int count;
public Goods(String name, BigDecimal price, int count) {
this.name = name;
this.price = price;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
商品行為
public class GoodsService {
public void updatePrice(Goods goods, BigDecimal price){
if(Objects.isNull(price) || BigDecimal.ZERO.compareTo(price) > 0){
throw new RuntimeException("價格不能小于0");
}
goods.setPrice(price);
}
}
充血模型
在領域驅動設計中,充血模型是一種設計模式,它強調在領域對象中封裝數據和業務邏輯。
與貧血模型相對,充血模型將數據與行為結合在一起,使領域對象不僅僅是數據的容器,還能夠包含與其狀態相關的業務邏輯。
/**
* 商品類
*/
public class Goods {
private String name;
private BigDecimal price;
private int count;
public Goods(String name, BigDecimal price, int count) {
this.name = name;
this.price = price;
this.count = count;
}
public void updatePrice(Goods goods, BigDecimal price){
if(Objects.isNull(price) || BigDecimal.ZERO.compareTo(price) > 0){
throw new RuntimeException("價格不能小于0");
}
goods.setPrice(price);
}
}
優缺點與使用場景
貧血模型的優點
- 數據與行為分離,降低了對象的復雜度。
- 可以提高代碼的重用性和可測試性。
- 可以更好地利用現有的服務和框架。
貧血模型的缺點
- 對象缺乏封裝性,易于出現耦合性和脆弱性。
- 業務邏輯被分散在多個類中,難以維護和理解。
- 過度依賴外部服務,可能導致系統的不穩定性。
充血模型的優點
- 面向對象設計,具有良好的封裝性和可維護性。
- 領域對象自包含業務邏輯,易于理解和擴展。
- 可以避免過度依賴外部服務,提高系統的穩定性。
充血模型的缺點
- 需要對模型的理解才能更好的開發,上手成本高
- 對象間的協作可能增加,導致設計變得復雜。
- 對象的狀態可能會變得不一致,需要特別注意。
一般來說,對于較小的應用系統或者簡單的業務流程,可以使用貧血模型;對于較大的應用系統或者復雜的業務流程,建議使用充血模型。
防腐層
防腐層,用于保護系統的內部模型和業務邏輯不受外部系統或服務的影響。
它的主要目的是提供一個清晰的界面,隔離外部系統的變化,以防止它們對內部領域模型產生腐蝕或負面影響。
例如:當某個業務模塊需要依賴第三方系統提供的數據或者功能時,我們常用的策略就是直接使用外部系統的API、數據結構。
這樣存在的問題就是,因使用外部系統,而被外部系統的質量問題影響,從而“腐化”本身設計的問題。
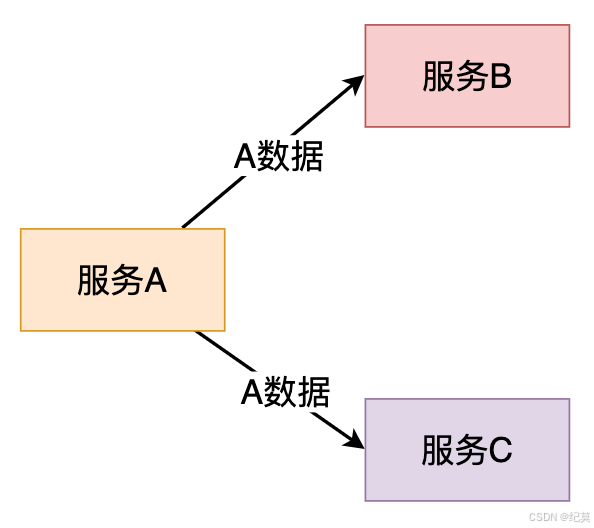
因此解決方案就是在兩個系統之間加入一個中間層,隔離第三方系統的依賴,對第三方系統進行通訊轉換和語義隔離,這個中間層,我們叫它防腐層。
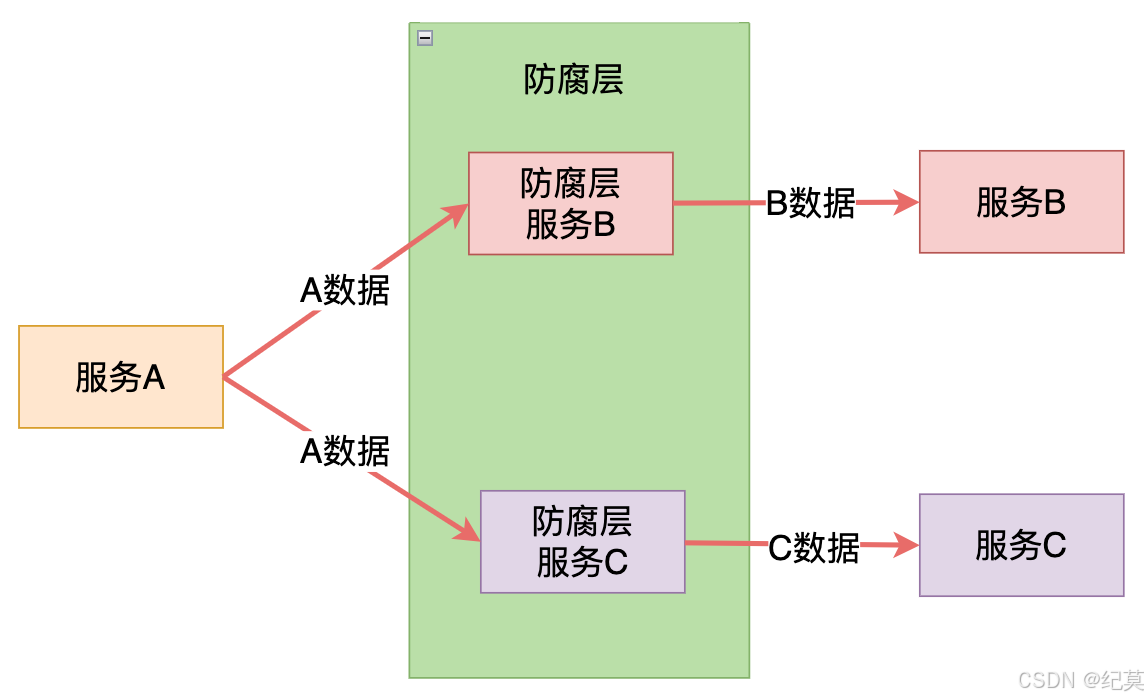
兩個系統之間加了中間層,中間層類似適配器模式,解決接口差異的對接,接口轉換是單向的(即從調用方向被調用方進行接口轉換);防腐層強調兩個子系統語義解耦,接口轉換是雙向的。
防腐層作用:
- 使兩方的系統解耦,隔離雙方變更的影響,允許雙方獨立演進。
- 防腐層允許其它的外部系統能夠在不改變現有系統的領域層的前提下,與該系統實現無縫集成,從而降低系統集成的開發工作量。
作者:紀莫
歡迎任何形式的轉載,但請務必注明出處。
限于本人水平,如果文章和代碼有表述不當之處,還請不吝賜教。
歡迎掃描二維碼關注公眾號:Jimoer
文章會同步到公眾號上面,大家一起成長,共同提升技術能力。
聲援博主:如果您覺得文章對您有幫助,可以點擊文章右下角【推薦】一下。
您的鼓勵是博主的最大動力!


 浙公網安備 33010602011771號
浙公網安備 33010602011771號