你說說RPC的一個請求的流程是怎么樣的?
前言
面試的時候經常被問到RPC相關的問題,例如:你說說RPC實現原理、讓你實現一個RPC框架應該考慮哪些地方、RPC框架基礎上發起一個請求是怎樣一個流程等等。所以這次我就總結一波RPC的相關知識點,提前說明一下,本篇文章只是為了回答一些面試問題,所以只是解釋原理,并不會深入挖掘細節。
注冊中心
RPC(Remote Procedure Call)翻譯成中文就是遠程過程調用。RPC框架起到的作用就是為了實現,調用遠程方法時,能夠做到和調用本地方法一樣,讓開發人員更專注于業務開發,不用去考慮網絡編程等細節。
RPC框架怎么就實現不讓開發人員關注網絡編程等細節呢?
首先我們區分兩個角色一個服務提供方,一個是服務調用方。服務調用方其實是通過動態代理、負載均衡、網絡調用等機制去服務提供方的機器上去執行對應的方法。服務提供方將方法執行完成后,將執行結果再通過網絡傳輸返回到服務調用方。
大致過程如下:
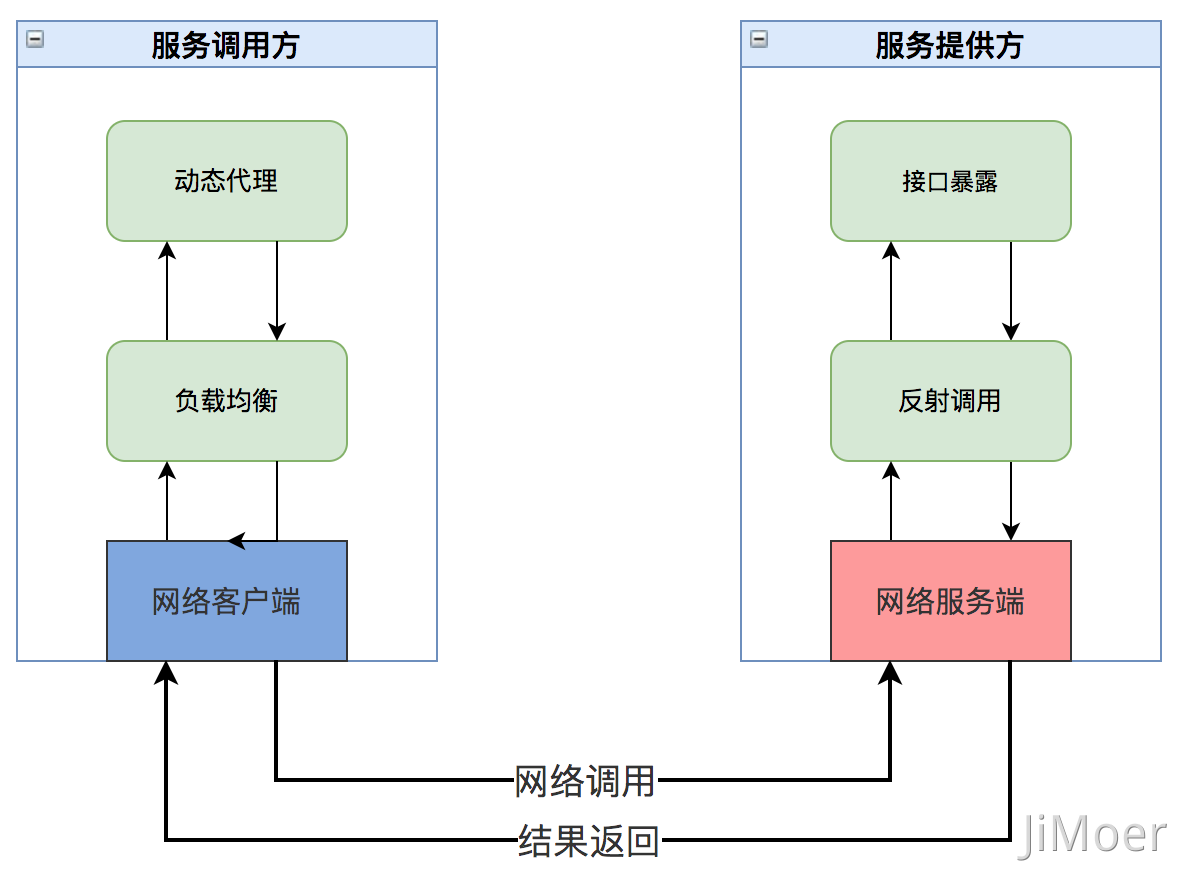
但是現在的服務都是集群部署,那么服務調用方怎么應該實時的知道服務提供方的集群中的變化,例如服務提供方的IP地址變了,或者是服務重啟時怎么能夠及時的切換流量呢?
這就需要注冊中心起作用了,我們可以把注冊中心看作服務端,然后每個服務都看成客戶端,每個客戶端都需要將自己注冊到注冊中心,然后一個服務調用方要調用另一個服務時,需要從注冊中心獲取服務提供方的信息,主要是獲取服務提供方的服務器IP地址列表和端口信息。
服務調用方獲取到這些信息后緩存到自己本地,并且跟注冊中心保持一個長連接當服務提供方有任何變化時,注冊中心能夠實時的通知給服務調用方,調用方能夠及時更新自己本地緩存的信息(也可以采用定時輪詢的方式)。
服務調用方獲取到服務器IP地址信息后,根據自己的負載均衡策略選擇一個IP地址然后發起網絡調用的請求。
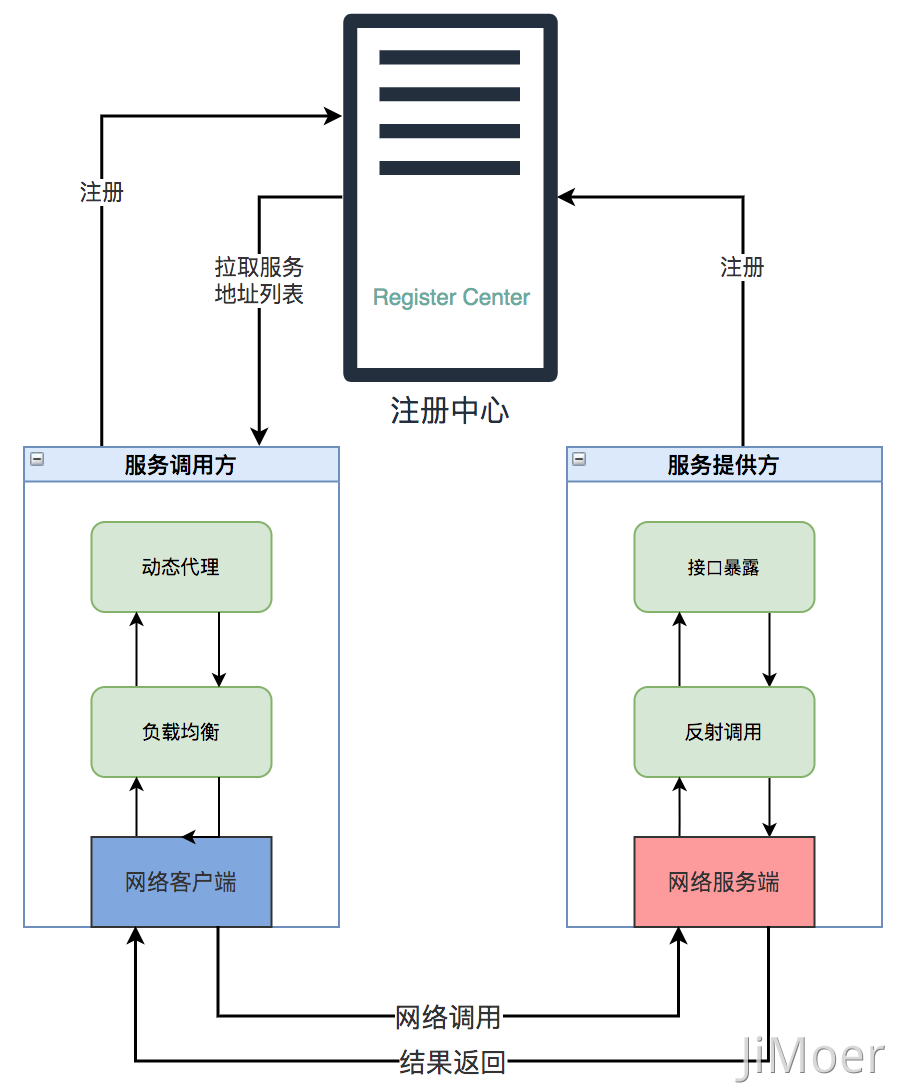
那么網絡客戶端是通過什么發起的網絡調用呢?
可以自己使用JDK原生的BIO活NIO來實現一套網絡通信模塊,但是這里我們建議直接使用強大的網絡通信框架Netty。它是基于NIO的網絡通信框架,支持高并發,封裝完善,而且性能好傳輸快。
Netty不是我們本文的主要內容,這里就不展開說了。
客戶端調用過程
因為我們知道數據在網絡中傳輸的時候都是以二進制的形式的,所以在調用方將調用的參數進行傳遞的時候是需要進行序列化的。服務提供方在接收到參數時也是需要進行反序列化的。
網絡協議
調用方既然需要序列化,服務提供方又要進行反序列化,這樣雙方就要確定好一個協議,調用方傳輸什么參數,服務提供方就按照這個協議去進行解析,而且在返回結果的時候也是按照這個協議進行結果解析。
那么這個協議應該是怎么樣的結構,都是什么樣子的呢?
因為這個協議可以自定義,我們為了方便就以JSON的形式給舉個例子:
{
"interfaces": "interface=com.jimoer.rpc.test.producer.TestService;method=printTest;parameter=com.jiomer.rpc.test.producer.TestArgs",
"requestId": "3",
"parameter": {
"com.jiomer.rpc.test.producer.TestArgs": {
"age": 20,
"name": "Jimoer"
}
}
}
首先第一個參數interfaces是,我們要讓服務提供方知道調用方要調用哪個接口,以及接口中的哪個方法,并且方法的參數是什么類型的。
第二個參數是當前一次請求的一個唯一標識,在多個線程同時請求一個方法時,用這個id來進行區分,以后無論是做鏈路追蹤還是日志管理都可以以此id為依據。
第三個參數就是 實際的調用方法中的參數值。具體是什么類型的,每個屬性值都是什么。
調用
下面也是舉一個簡單的例子來說明一下調用的過程。我們一部分采用代碼的形式一部分采用文字的形式來將整個調用過程串起來。
// 定義請求的URL
String tcpURL = "tcp://testProducer/TestServiceImpl";
// 定義接口請求
TestService testService = ProxyFactory.create(TestService.class, tcpURL);
// 組裝請求參數
TestArgs testArgs = new TestArgs(20,"Jimoer");
// 通過動態代理執行請求
String result = testService.printTest(testArgs);
通過查看上面的代碼我們可以看到整個調用過程最核心的地方在ProxyFactory.create()方法里,這個方法里面主要的過程是,動態代理生成接口的實際代理對象,然后使用Netty的接口發起網絡請求。
Proxy.newProxyInstance(getClass().getClassLoader(), interfaces.getClass().getInterfaces(), new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 第一步:獲取調用服務的地址列表
ListregistryInfos = interfacesMethodRegistryList.get(clazz);
if (registryInfos == null) {
throw new RuntimeException("無法找到服務提供者");
}
// 第二步: 通過自身的負載均衡策略選擇一個地址
RegistryInfo registryInfo = loadBalancer.choose(registryInfos);
// 第三步:Netty的網絡請求處理
ChannelHandlerContext ctx = channels.get(registryInfo);
// 第四步:根據接口類的全路徑名和方法生成唯一標識
String identify = InvokeUtils.buildInterfaceMethodIdentify(clazz, method);
String requestId;
// 第五步:通過加鎖的方式保證生成的requestId的唯一性
synchronized (ApplicationContext.this) {
requestIdWorker.increment();
requestId = String.valueOf(requestIdWorker.longValue());
}
// 第六步: 組織參數
JSONObject jsonObject = new JSONObject();
jsonObject.put("interfaces", identify);
jsonObject.put("parameter", param);
jsonObject.put("requestId", requestId);
System.out.println("發送給服務端JSON為:" + jsonObject.toJSONString());
// $$ 多條消息之間的分隔符
String msg = jsonObject.toJSONString() + "$$";
ByteBuf byteBuf = Unpooled.buffer(msg.getBytes().length);
byteBuf.writeBytes(msg.getBytes());
// 第七步:這里發起調用
ctx.writeAndFlush(byteBuf);
// 這里會將線程進行阻塞,知道服務提供方將請求處理好之后返回結果,再喚醒。
waitForResult();
return result;
}
});
執行過程大致分為這幾步:
- 獲取調用服務的地址列表。
- 通過自身的負載均衡策略選擇一個地址。
- Netty的網絡請求處理(選擇一個渠道Channel)。
- 根據接口類的全路徑名和方法生成唯一標識。
- 通過加鎖的方式保證生成的requestId的唯一性。
- 組織請求參數。
- 發起調用。
- 線程阻塞,直到服務提供方返回結果。
- 填充返回結果,返回到調用方。
服務端處理過程
上面也說了,服務調用方發起網絡請求后,會阻塞住,直到服務提供方返回數據,所以服務提供方處理完調用方法的邏輯后,還是要喚醒阻塞的調用線程的。
服務提供方在處理請求時也是先通過Netty獲取到數據,然后再進行反序列化,然后再根據協議獲取到需要調用的方法,然后通過反射去進行調用。
Netty的返回入口在下面這部分邏輯里
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
try {
String message = (String) msg;
if (messageCallback != null) {
// 將接收到的消息放到回調方法中
messageCallback.onMessage(message);
}
} finally {
ReferenceCountUtil.release(msg);
}
}
Netty的client接收到響應的消息后,先將結果返回到調用方,處理完成之后再去釋放之前的阻塞調用線程。
client.setMessageCallback(message -> {
// 這里收單服務端返回的消息,先壓入隊列
RpcResponse response = JSONObject.parseObject(message, RpcResponse.class);
System.out.println("收到一個響應:" + response);
String interfaceMethodIdentify = response.getInterfaceMethodIdentify();
String requestId = response.getRequestId();
// 設定唯一標識
String key = interfaceMethodIdentify + "#" + requestId;
Invoker invoker = inProgressInvoker.remove(key);
// 將結果設置到代理對象中
invoker.setResult(response.getResult());
// 加鎖再釋放之前的阻塞線程。
synchronized (ApplicationContext.this) {
ApplicationContext.this.notifyAll();
}
});
setResult()方法
@Override
public void setResult(String result) {
synchronized (this) {
this.result = JSONObject.parseObject(result, returnType);
notifyAll();
}
}
上面的步驟就是這樣,按照之前請求的唯一標識放入到返回的信息中,然后將結果設置到代理對象中,再通過返回結果,然后喚醒之前的調用阻塞線程。
總結
其實整個RPC的請求過程就是如下(不含異步調用):
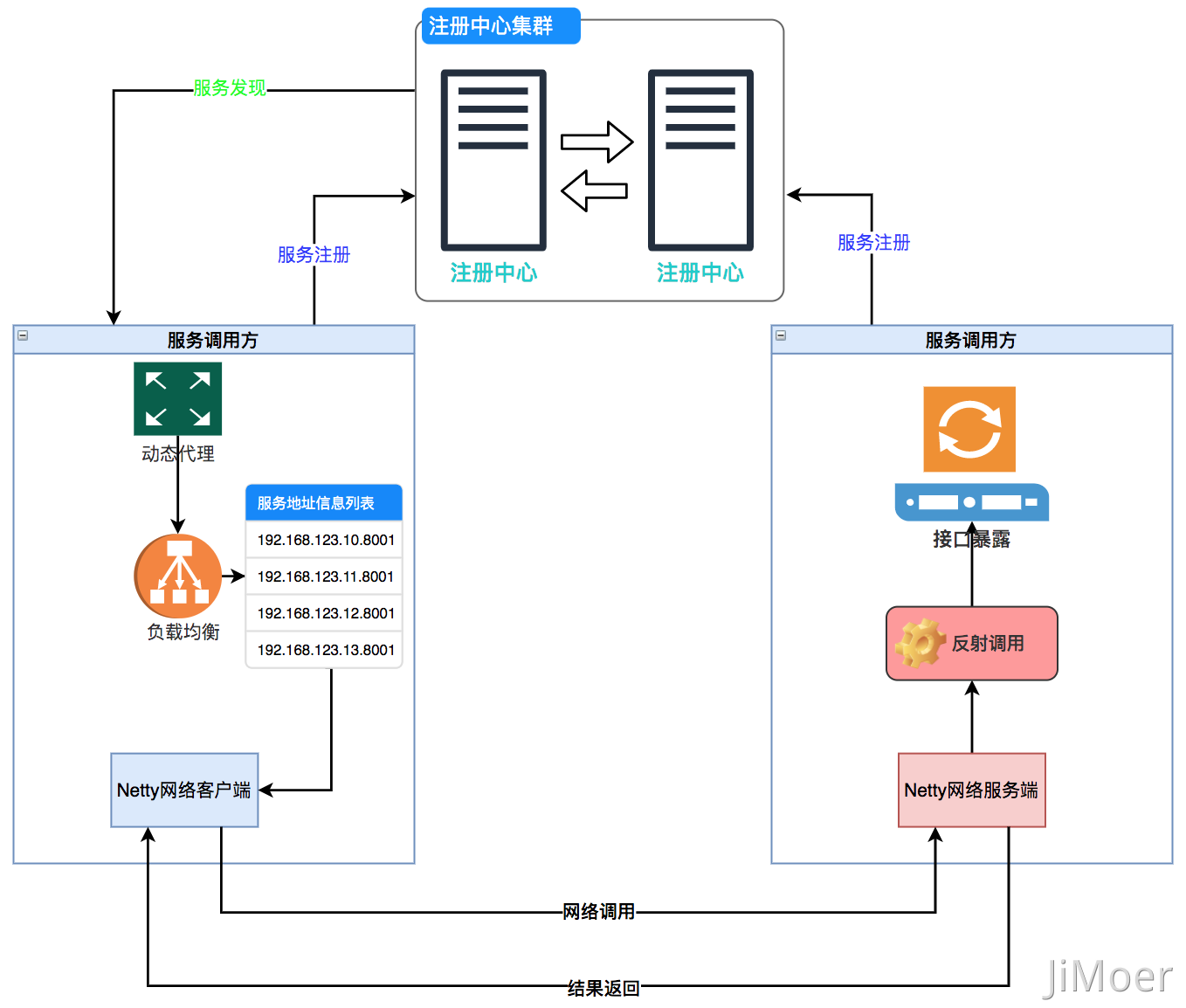
做一個總結,用大白話把一個RPC請求流程描述出來:
首先無論是調用方還是服務提供方都要注冊到注冊中心;
- 服務調用方把請求參數對象序列化成二進制數據,通過動態代理生成代理對象,通過代理對象,使用Netty選擇一個從注冊中心拉取到的服務提供方的地址,然后發起網絡請求。
- 服務提供方從TCP通道中接收到二進制數據,根據定義的RPC網絡協議,從二進制數據中反序列化后,分割出接口地址和參數對象,再通過反射找到接口執行調用。
- 然后服務提供方再把調用執行結果序列化后,回傳到TCP通道中。
- 服務調用方獲取到應答二進制數據后,再反序列化成結果對象。
這樣就完成了一次RPC網絡調用,其實后面框架擴展后,還要考慮限流、熔斷、服務降級、序列化多樣性擴展,服務監控、鏈路追蹤等等功能。這些就要后面再擴展的講了,這次就先到這了。
后補語:
最近在面試的時候遇到一個問題,被提問道:一個RPC請求是一個TCP的長連接還是短連接?
我一時沒有回答上來,畢竟計算機網絡編程是我的弱點??。
面試結束后,趕緊總結了一下,TCP連接的RPC請求一般都是使用的TCP的長連接,而長連接比短連接更節省資源,效率更高,例如dubbo、gRPC等。
那這里也說一下TCP的長連接和短連接的區別
TCP短連接: client向server發起請求,server接收到請求,然后建立連接。client向server發送消息,server回應client,這樣一次讀寫就完成了。一般是client端發起close操作。TCP短連接的優點是:管理起來比較簡單,存在的連接都是有用的連接。
TCP長連接:client向server發起請求連接,server接收到client的請求,建立連接。client與server完成一次請求后,并不會關閉連接,后面的讀寫操作都會繼續使用這個連接。
由于TCP長連接一直不關閉,若是客戶端以及不存在了,那么這個連接就會處于一個半關閉的狀態。TCP的保活功能就是用來檢測這種連接,但是如果長連接一直未關閉,當客戶端越來越多,server早晚抗不住的,所以server會采取一些措施降低損耗,如關閉一些長時間沒有讀寫事件發生的連接,還有做的更好的會以客戶端為粒度,限制單個客戶端的 最大鏈接數。
長連接多用于頻繁操作,點對點的通信,而且連接數不能太多的情況。
短連接一般用于web網站的http服務,http應用層的短連接本質依賴的就是TCP的短連接。
作者:紀莫
歡迎任何形式的轉載,但請務必注明出處。
限于本人水平,如果文章和代碼有表述不當之處,還請不吝賜教。
歡迎掃描二維碼關注公眾號:Jimoer
文章會同步到公眾號上面,大家一起成長,共同提升技術能力。
聲援博主:如果您覺得文章對您有幫助,可以點擊文章右下角【推薦】一下。
您的鼓勵是博主的最大動力!


 浙公網安備 33010602011771號
浙公網安備 33010602011771號