LZW數據壓縮算法的原理分析
我希望通過本文的介紹,能給那些目前不太了解lzw算法和該算法在gif圖像中應用,但渴望了解它的人一些啟發和幫助。拋磚引玉而已,更希望園子里面兄弟提出寶貴的意見。
1.LZW的全稱是什么?
Lempel-Ziv-Welch (LZW).
2. LZW的簡介和壓縮原理是什么?
LZW壓縮算法是一種新穎的壓縮方法,由Lemple-Ziv-Welch 三人共同創造,用他們的名字命名。它采用了一種先進的串表壓縮,將每個第一次出現的串放在一個串表中,用一個數字來表示串,壓縮文件只存貯數字,則不存貯串,從而使圖象文件的壓縮效率得到較大的提高。奇妙的是,不管是在壓縮還是在解壓縮的過程中都能正確的建立這個串表,壓縮或解壓縮完成后,這個串表又被丟棄。
LZW算法中,首先建立一個字符串表,把每一個第一次出現的字符串放入串表中,并用一個數字來表示,這個數字與此字符串在串表中的位置有關,并將這個數字存入壓縮文件中,如果這個字符串再次出現時,即可用表示它的數字來代替,并將這個數字存入文件中。壓縮完成后將串表丟棄。如"print" 字符串,如果在壓縮時用266表示,只要再次出現,均用266表示,并將"print"字符串存入串表中,在圖象解碼時遇到數字266,即可從串表中查出266所代表的字符串"print",在解壓縮時,串表可以根據壓縮數據重新生成。
3.在詳細介紹算法之前,先列出一些與該算法相關的概念和詞匯
1)'Character': 字符,一種基礎數據元素,在普通文本文件中,它占用1個單獨的byte,而在圖像中,它卻是 一種代表給定像素顏色的索引值。
2)'CharStream':數據文件中的字符流。
3)'Prefix':前綴。如這個單詞的含義一樣,代表著在一個字符最直接的前一個字符。一個前綴字符長度可以為0,一個prefix和一個character可以組成一個字符串(string),
4)'Suffix': 后綴,是一個字符,一個字符串可以由(A,B)來組成,A是前綴,B是后綴,當A長度為0的時候,代表Root,根
5)'Code:碼,用于代表一個字符串的位置編碼
6)'Entry',一個Code和它所代表的字符串(string)
4.壓縮算法的簡單示例,不是完全實現LZW算法,只是從最直觀的角度看lzw算法的思想
對原始數據ABCCAABCDDAACCDB進行LZW壓縮
原始數據中,只包括4個字符(Character),A,B,C,D,四個字符可以用一個2bit的數表示,0-A,1-B,2-C,3-D,從最直觀的角度看,原始字符串存在重復字符:ABCCAABCDDAACCDB,用4代表AB,5代表CC,上面的字符串可以替代表示為:45A4CDDAA5DB,這樣是不是就比原數據短了一些呢!
5.LZW算法的適用范圍
為了區別代表串的值(Code)和原來的單個的數據值(String),需要使它們的數值域不重合,上面用0-3來代表A-D,那么AB就必須用大于3的數值來代替,再舉另外一個例子,原來的數值范圍可以用8bit來表示,那么就認為原始的數的范圍是0~255,壓縮程序生成的標號的范圍就不能為0~255(如果是0-255,就重復了)。只能從256開始,但是這樣一來就超過了8位的表示范圍了,所以必須要擴展數據的位數,至少擴展一位,但是這樣不是增加了1個字符占用的空間了么?但是卻可以用一個字符代表幾個字符,比如原來255是8bit,但是現在用256來表示254,255兩個數,還是劃得來的。從這個原理可以看出LZW算法的適用范圍是原始數據串最好是有大量的子串多次重復出現,重復的越多,壓縮效果越好。反之則越差,可能真的不減反增了。
6.LZW算法中特殊標記
隨著新的串(string)不斷被發現,標號也會不斷地增長,如果原數據過大,生成的標號集(string table)會越來越大,這時候操作這個集合就會產生效率問題。如何避免這個問題呢?Gif在采用lzw算法的做法是當標號集足夠大的時候,就不能增大了,干脆從頭開始再來,在這個位置要插入一個標號,就是清除標志CLEAR,表示從這里我重新開始構造字典,以前的所有標記作廢,開始使用新的標記。
這時候又有一個問題出現,足夠大是多大?這個標號集的大小為比較合適呢?理論上是標號集大小越大,則壓縮比率就越高,但開銷也越高。 一般根據處理速度和內存空間連個因素來選定。GIF規范規定的是12位,超過12位的表達范圍就推倒重來,并且GIF為了提高壓縮率,采用的是變長的字長。比如說原始數據是8位,那么一開始,先加上一位再說,開始的字長就成了9位,然后開始加標號,當標號加到512時,也就是超過9為所能表達的最大數據時,也就意味著后面的標號要用10位字長才能表示了,那么從這里開始,后面的字長就是10位了。依此類推,到了2^12也就是4096時,在這里插一個清除標志,從后面開始,從9位再來。
GIF規定的清除標志CLEAR的數值是原始數據字長表示的最大值加1,如果原始數據字長是8,那么清除標志就是256,如果原始數據字長為4那么就是16。另外GIF還規定了一個結束標志END,它的值是清除標志CLEAR再加1。由于GIF規定的位數有1位(單色圖),4位(16色)和8位(256色),而1位的情況下如果只擴展1位,只能表示4種狀態,那么加上一個清除標志和結束標志就用完了,所以1位的情況下就必須擴充到3位。其它兩種情況初始的字長就為5位和9位。此處參照了http://blog.csdn.net/whycadi/
7.用lzw算法壓縮原始數據的示例分析
輸入流,也就是原始的數據為:255,24,54,255,24,255,255,24,5,123,45,255,24,5,24,54..................
這個正好可以看到是gif文件中像素數組的一部分,如何對它進行壓縮
因為原始數據可以用8bit來表示,故清除標志Clear=255+1 =256,結束標志為End=256+1=257,目前標號集為
0 1 2 3 .................................................................................255 CLEAR END
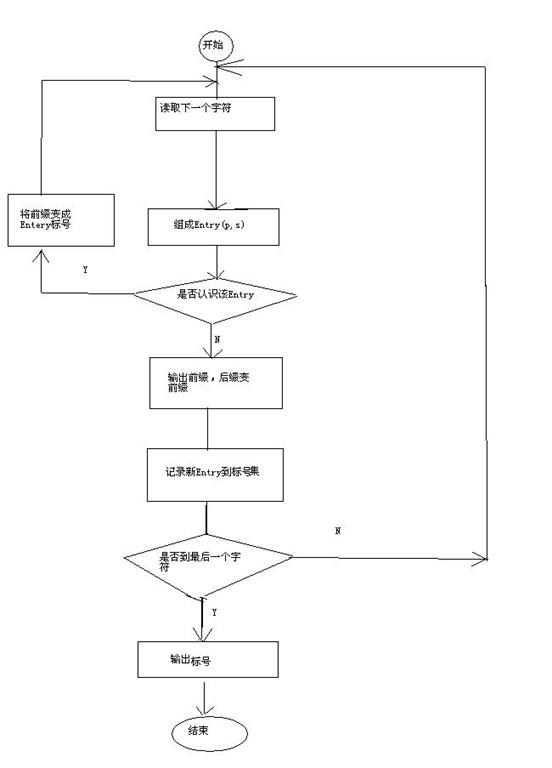
第一步,讀取第一個字符為255,在標記表里面查找,255已經存在,我們已經認識255了,不做處理
第二步,取第二個字符,此時前綴為A,形成當前的Entry為(255,24),在標記集合不存在,我們并不認識255,24好,這次你小子來了,我就記住你,把它在標記集合中標記為258,然后輸出前綴A,保留后綴24,并作為下一次的前綴(后綴變前綴)
第三步,取第三個字符為54,當前Entry(24,54),不認識,記錄(24,54)為標號259,并輸出24,后綴變前綴
第四部:取第四個字符255,Entry=(54,255),不認識,記錄(54,255)為標號260,輸出54,后綴變前綴
第五步 取第5個字符24,entry=(255,24),啊,認識你,這不是老258么,于是把字符串規約為258,并作為前綴
第六步 取第六個字符255,entry=(258,255),不認識,記錄(258,255)為261,輸出258,后綴變前綴
.......
一直處理到最后一個字符,
用一個表記錄處理過程
CLEAR=256,END=257
| 第幾步 | 前綴 | 后綴 | Entry | 認識(Y/N) | 輸出 | 標號 |
| 1 | 255 | (,255) | ||||
| 2 | 255 | 24 | (255,24) | N | 255 | 258 |
| 3 | 24 | 54 | (24,54) | N | 24 | 259 |
| 4 | 54 | 255 | (54,255) | N | 54 | 260 |
| 5 | 255 | 24 | (255,24) | Y | ||
| 6 | 258 | 255 | (258,255) | N | 258 | 261 |
| 7 | 255 | 255 | (255,255) | N | 255 | 262 |
上面這個示例有些不能完整體現,另外一個例子是
原輸入數據為:A B A B A B A B B B A B A B A A C D A C D A D C A B A A A B A B .....
采用LZW算法對其進行壓縮,壓縮過程用一個表來表述為:
注意原數據中只包含4個character,A,B,C,D
用兩bit即可表述,根據lzw算法,首先擴展一位變為3為,Clear=2的2次方+1=4; End=4+1=5;
初始標號集因該為
| 0 | 1 | 2 | 3 | 4 | 5 |
| A | B | C | D | Clear | End |
而壓縮過程為:
| 第幾步 | 前綴 | 后綴 | Entry | 認識(Y/N) | 輸出 | 標號 |
| 1 | A | (,A) | ||||
| 2 | A | B | (A,B) | N | A | 6 |
| 3 | B | A | (B,A) | N | B | 7 |
| 4 | A | B | (A,B) | Y | ||
| 5 | 6 | A | (6,A) | N | 6 | 8 |
| 6 | A | B | (A,B) | Y | ||
| 7 | 6 | A | (6,A) | Y | ||
| 8 | 8 | B | (8,B) | N | 8 | 9 |
| 9 | B | B | (B,B) | N | B | 10 |
| 10 | B | B | (B,B) | Y | ||
| 11 | 10 | A | (10,A) | N | 10 | 11 |
| 12 | A | B | (A,B) | Y |
.....
當進行到第12步的時候,標號集應該為
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| A | B | C | D | Clear | End | AB | BA | 6A | 8B | BB | 10A |
8.LZW算法的偽代碼實現
 STRING = get input character
STRING = get input character2
WHILE there are still input characters DO3
CHARACTER = get input character4
IF STRING+CHARACTER is in the string table then5
STRING = STRING+character6
ELSE7
output the code for STRING8
add STRING+CHARACTER to the string table9
STRING = CHARACTER10
END of IF11
END of WHILE12
output the code for STRING 13
9.LZW算法的流程圖
沒有安visio,畫了一個,比較難看,
上一篇關于LZW算法的文章為:lzw壓縮算法
出處:http://jillzhang.cnblogs.com/
本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號