
Spark JVM參數優化設置及Sparkstreaming優化和反壓機制
1.Spark JVM參數優化設置
Spark JVM的參數優化設置適用于Spark的所有模塊,包括SparkSQL、SparkStreaming、SparkRdd及SparkML,主要設置以下幾個值:
spark.yarn.driver.memoryOverhead #driver端最大的堆內存,設置為driverMemory*0.1,不小于384m
spark.yarn.excutor.memoryOverhead #excutor端最大的堆內存,設置為executorMemory* 0.1, 不小于384m
spark.driver.extraJavaOptions #driver端一系列額外的JVM選項,這個可以自行設置
spark.executor.extraJavaOptions #executor端一系列額外的JVM選項,這個可以自行設置
現在假設基礎的driver,excutor內存配置如下
driver_memory=10g
spark_executor_memory=30g
那么相對于的JVM優化參數配置如下
SparkConf conf = new SparkConf().setAppName("My-test");
conf.set("spark.yarn.driver.memoryOverhead","1g");
conf.set("spark.yarn.excutor.memoryOverhead","3g");
conf.set("spark.driver.extraJavaOptions","-XX:MaxPermSize=2g -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:ConcGCThreads=8 -XX:+CMSParallelRemarkEnabled");
conf.set("spark.executor.extraJavaOptions","-Xmn2g -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:ConcGCThreads=8 -XX:+CMSParallelRemarkEnabled -XX:-UseGCOverheadLimit");
說明:
a.如上spark.driver.extraJavaOptions設置的值的解釋
-XX:MaxPermSize=2g #指非堆區最大內存分配上限為2g
-XX:+UseConcMarkSweepGC #并行并發CMS垃圾回收器
-XX:+CMSConcurrentMTEnabled #當該標志被啟用時,并發的CMS階段將以多線程執行
-XX:ConcGCThreads=8 #執行GC的線程數為8個
-XX:+CMSParallelRemarkEnabled #降低標記停頓
-XX:-UseGCOverheadLimit #限制GC的運行時間。如果GC耗時過長,就拋OOM
-Xmn2g #設置年輕代大小為2G
Spark JVM的基礎優化平時開發中注意以上幾個參數優化在一般的業務中夠用了。但并不僅僅是這些參數的優化,詳細的參數請參照官網(http://spark.apache.org/docs/latest/configuration.html), 當然這個也需要同時結合JDK JVM的優化
2.Sparkstreaming參數優化設置
Sparksql的一些優化在Spark基礎參數和Spark JVM的基礎上就差不多了,但還是需要一些特定的優化,之前有專門寫過,可以參考之前的博客(http://www.rzrgm.cn/jiashengmei/p/11678440.html), 而Sparkstreaming還需要如下幾個參數的特定優化
spark.streaming.kafka.maxRatePerPartition #從kafka每個分區讀取數據的最大紀錄數
spark.streaming.blockInterval #spark流式接收器接收到的數據在存儲到Spark中之前被分塊到數據塊中的時間間隔。建議最小值為50毫秒。
spark.streaming.duration #每個批次的間隔時間
現在假設基礎的driver,excutor配置如下
driver_memory=10g
spark_executor_memory=30g
num_executors=6
executor_cores=1
配置sparkstreaming獨有的配置如下:
streaming_kafka_maxRatePerPartition=1000
streaming_blockInterval=1000
streaming_duration=60
現在假設kafka的分區數是3,那么Spark在一個batch里面處理的條數一定不超6*3*1000*10=18000。如果不設置會怎樣?現在假設要寫入的topic在Sparkstreaming未啟動就寫入了1億條數據,如果不進行這樣的甚至會導致程序一啟動,第一個batch直接拉取這一億條數據,一個批次處理一億條數據最終必然導致內存溢出等錯誤導致程序停止。下圖展示的是sparkstreaming程序未啟動已經寫入幾十萬條數據batch的數據狀態
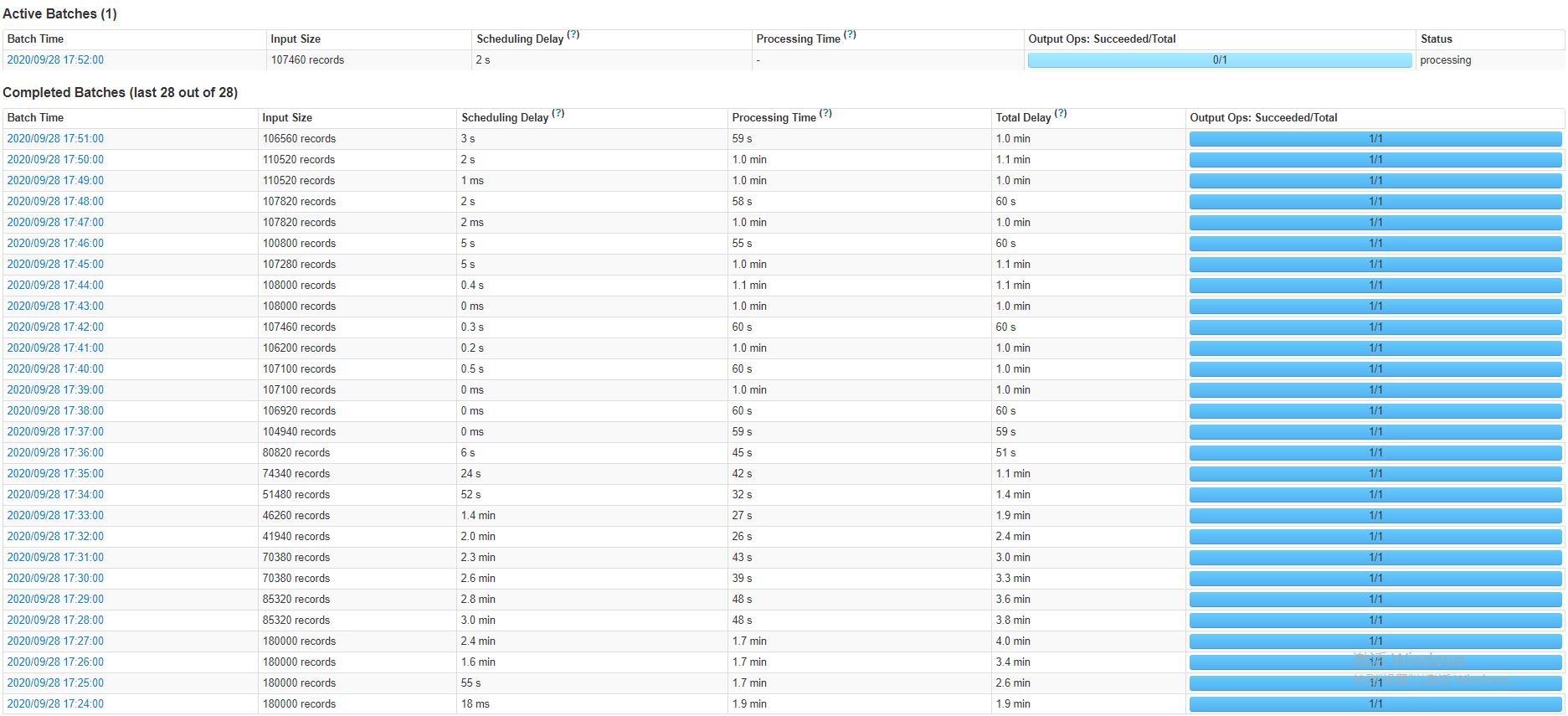
可以看出程序啟動發現數據太多,按最大的拉取,等消費差不多后。根據實際數據量拉取,但是拉取的總不會超過最大值。
3.Spark反壓機制
因特殊業務場景,如大促、秒殺活動與突發熱點事情等業務流量在短時間內劇增,形成巨大的數據流入的速度遠高于數據處理的速度,對流處理系統構成巨大的負載壓力,如果不能正確處理,可能導致集群資源耗盡最終集群崩潰,因此有效的反壓機制(backpressure)對保障流處理系統的穩定至關重要。可以簡單總結為對于spark的反壓機制是對于某些數據洪峰的應對策略,可以根據處理效率動態調整攝入速率。
反壓機制可以根據參數設置開啟,同時也可以自定呀反壓策略,這里不舉例自定義反壓策略。值說明反壓的作用和如何配置
SparkConf conf = new SparkConf().setAppName(parameterParse.getSpark_app_name());
//啟用反壓
conf.set("spark.streaming.backpressure.enabled","true")
//最小攝入條數控制
conf.set("spark.streaming.backpressure.pid.minRate","1")
//最大攝入條數控制
conf.set("spark.streaming.kafka.maxRatePerPartition","1000")
JavaSparkContext sc = new JavaSparkContext(conf);
//每個批次的間隔時間
JavaStreamingContext ssc = new JavaStreamingContext(sc, Seconds.apply(Long.parseLong(5000)));
關于反壓機制的詳細概念解釋這邊博客講得比較全面(http://www.rzrgm.cn/lenmom/p/12022277.html), 關于反壓機制自定義策略后面有時間會結合Flink的反壓機制統一給出
4.注意
在sparkstreaming里面不建議使用repartition,如下
JavaInputDStream<ConsumerRecord<String, String>> dStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent(), ConsumerStrategies.Subscribe(topicsSet, kafkaParamsConsumer));
dStream.repartition().foreachRDD(rdd -> {//邏輯處理})

 浙公網安備 33010602011771號
浙公網安備 33010602011771號