
原文鏈接: http://www.rzrgm.cn/jacklu/p/8379726.html
博士一年級選了這門課 SEEM 5680 Text Mining Models and Applications,記下來以便以后查閱。
1. 信息檢索的布爾模型
用0和1表示某個詞是否出現在文檔中。如下圖例子,要回答“Brutus AND Caesar but NOT Calpurnia”,我們需要對詞的向量做布爾運算,即110100 AND 110111 AND 101111=100100 對應的文檔是Antony and Cleopatra和Hamlet

然而這種方法隨著數據的增大是非常耗費空間的。比如我們有100萬個文檔,每個文檔平均有1000字,總共有50萬個不同的詞語,那么矩陣將是500 000 x 1 000 000。這個矩陣是稀疏的,1的個數一般不會超過1億個。
2. 倒排索引
倒排索引是為了解決上述布爾模型的問題。具體來說,每個詞用鏈表順序存儲文檔編號。如下圖所示:
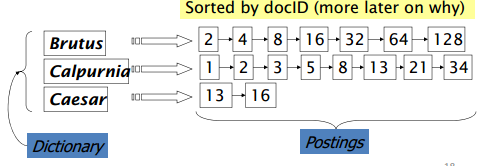
建立索引的核心是將詞按字母順序排列,合并重復詞,但是要記錄詞頻。
3. 倒排索引模型中對查詢語句(AND)的處理
1、求Brutus AND Calpurnia,即求兩個鏈表的交集。

算法思路是如果文檔號不同就移動較小的指針,偽代碼 INTERSECTION(p1, p2):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) then ADD(answer, docID(p1)) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) p1 <-next(p1) else p2<-next(p2) return answer
思考題,有兩個詞項A,B,其文檔編號鏈表長度分別為3和5,那么對A,B求交集,最少的訪問次數和最多的訪問次數分別是多少?各舉一個例子
最少訪問次數是4,比如A:1-2-3,B:3-4-5-6-7;最多訪問次數是8,比如A:1-7-8, B:3-4-5-7-9
2、思考題:求Brutus OR Calpurnia,即求兩個鏈表的并集。偽代碼 UNION(p1,p2):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) then ADD(answer, docID(p1)) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) then ADD(answer, docID(p1)) p1<-next(p1) else ADD(answer, docID(p2)) p2<-next(p2) return answer
3、思考題:求Brutus AND NOT Calpurnia。偽代碼 INTERSECTION(p1,p2, AND NOT):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) then ADD(answer, docID(p1)) p1<-next(p1) else p2<-next(p2) if p1 != NIL and P2 = NIL then ADD(answer, docID(p1)) p1<-next(p1) return answer
參考資料:http://www1.se.cuhk.edu.hk/~seem5680/

 浙公網安備 33010602011771號
浙公網安備 33010602011771號