敏感詞過濾 + 限流
社交場景設計
本文我們來做一個小場景:
【注意,本文借鑒內容偏多,引用的內容較多,如果想看原文,可以點擊參考里面的鏈接查看原文】
1.引入
場景一:社交平臺實時評論審核
- 用戶在帖子下發表評論,內容需實時審核是否包含敏感詞;
- 為了防止刷屏或惡意評論,需對每個用戶或 IP 做限流。
這個時候我們要做一下:
- 入口限流
- 在網關層或前端 API 服務,應用令牌桶(Token Bucket)或漏桶(Leaky Bucket)算法,對單個用戶(或單個 IP)做 QPS/TPS 限制。
- DFA 過濾
- 請求通過限流后,進入文本審核模塊。
- 利用 DFA 構建一棵敏感詞自動機,對評論文字做單次掃描,時間復雜度 O(n)。
- 若檢測到敏感詞,則返回“含違規內容”,同時可記錄復審日志。
場景二:評論/私信接口防刷與內容合規
-
電商平臺的商品評論、賣家私信接口,既要防止機器刷單,又要保證留言內容不違規。
-
接口調用量巨大,對審核時延和吞吐都有嚴格要求。
還有平時我們發彈幕,發得太快了,系統會提示你 “發得太頻繁了”【限流降級一下】,如果你還有違禁詞,還會給你變成 星星處理【敏感詞處理】。
...... 等等等
我相信大家都或多或少遇到過該情況的。那么本文就來探討一下限流 和 敏感詞過濾
2.限流算法
限流,也稱流量控制。是指系統在面臨高并發,或者大流量請求的情況下,限制新的請求對系統的訪問,從而保證系統的穩定性。限流會導致部分用戶請求處理不及時或者被拒,這就影響了用戶體驗。所以一般需要在系統穩定和用戶體驗之間平衡一下。
比如說秒殺搶購,保護自身系統和下游系統不被巨型流量沖垮等
①固定窗口限流
將時間切分為等長的固定窗口(如每秒、每分鐘),對每個窗口內的請求計數,超過閾值即拒絕。
這種算法實現簡單,計數操作開銷低;適用于對“平均速率”要求不高的場景。
但是要想一下這種問題,那就是邊界問題:窗口邊界突刺:如限 100 次/分鐘,59 秒內 100 次 + 新窗口開始(第61秒) 100 次,這三秒內瞬間可達 200 次。
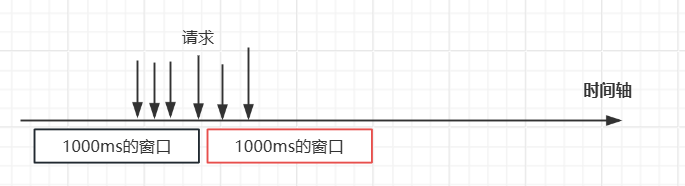
如上圖所示,加入每一秒的請求數最多四個的話,在窗口的邊界,上圖可以看到這六個請求都是被放行的。
public class FixedWindowLimit implements Limit {
private final ConcurrentHashMap<String, Pair> resourceMap = new ConcurrentHashMap<>(2);
// 默認每個資源每秒訪問50次
@Override
public synchronized boolean isAccess(Resource resource) {
long now = System.currentTimeMillis();
Pair pair = resourceMap.computeIfAbsent(resource.getName(), k -> new Pair(50, 1000, System.currentTimeMillis()));
long start = pair.getWindowStart();
int windowSize = pair.getWindowSize();
if (now - start >= windowSize) { // 超過窗口時間,重置窗口
pair.setInit(now);
return true;
} else {
pair.add();
// 超過窗口內最大請求數,拒絕
return pair.getCount().get() <= pair.getMaxCount();
}
}
@Data
private static class Pair {
private int maxCount; // 窗口內最大請求數
private int windowSize; // 窗口大小,單位毫秒
private Long windowStart; // 窗口開始時間
private AtomicInteger count; // 窗口內請求數
public Pair( int maxCount, int windowSize, Long windowStart) {
this.maxCount = maxCount; this.windowSize = windowSize;
this.windowStart = windowStart; this.count = new AtomicInteger(0);
}
public void add() {
this.count.incrementAndGet();
}
public void setInit( long newTime) {
this.count.set(1);
this.windowStart = newTime;
}
}
}
②滑動窗口限流
基本思想
- 時間窗口動態滑動:將時間劃分為多個小的時間片段(如1秒分為10個100ms的格子),窗口隨著時間推移向前滑動。
- 統計窗口內請求數:僅統計當前時間點向前滑動一個完整窗口時長內的請求數量,超出閾值則拒絕請求。
為了平滑限流,將時間窗口動態滑動,通過兩個相鄰固定窗口的加權計數來近似當前窗口內請求數。
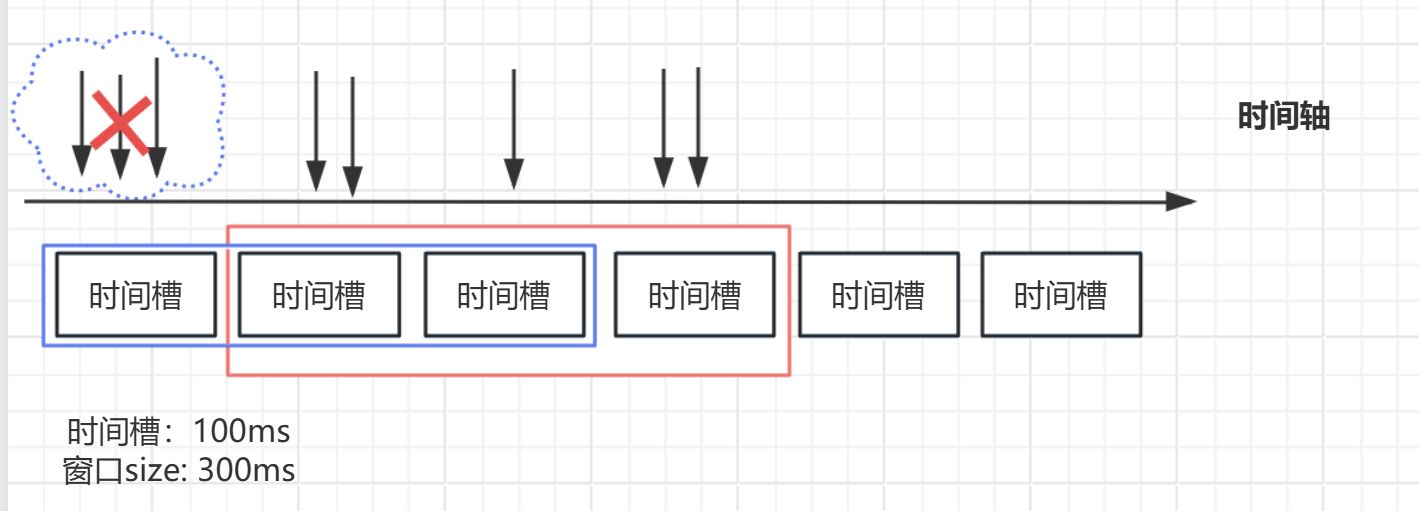
如上圖所示,滑動窗口將窗口劃分為了多個小的時間片段,只統計當前窗口內的請求數就可以了,窗口移動的時候,將前面的時間槽丟棄掉。
- 限流精準:避免固定窗口的邊界問題,流量控制更平滑。
- 靈活調整:時間片粒度可調(越細越精準,但開銷越大)。
public class SlidingWindowLimit implements Limit {
private static final ConcurrentHashMap<String, Pair> map = new ConcurrentHashMap<>(2);
@Override
public synchronized boolean isAccess(Resource resource) {
long now = System.currentTimeMillis();
Pair pair = map.computeIfAbsent(resource.getName(), k -> new Pair(100, 1000, 10));
pair.refreshSlot(now);
// 窗口內計數器總和超過閾值,則丟棄后續請求
if (pair.getSum() >= pair.getMaxCount()) {
return false;
} else {
pair.add();
return true;
}
}
@Data
private static class Pair {
private int maxCount; // 閾值
private int windowSize; // 窗口大小[毫秒]
private int slotCount; // 窗口內區間個數
private int slotSize; // 區間大小[毫秒] windowSize/slotCount
private long lastRefreshTime;
private Queue<Integer> slots; // 區間計數器隊列
public Pair( int maxCount, int windowSize, int slotCount) {
this.maxCount = maxCount;
this.windowSize = windowSize;
this.slotCount = slotCount;
this.slotSize = windowSize/slotCount;
this.slots = new LinkedList<>();
for (int i = 0; i < slotCount; i++) {
slots.offer(0);
}
this.lastRefreshTime = System.currentTimeMillis();
}
public void add() {
Integer poll = slots.poll();
poll = poll == null ? 0 : poll;
slots.offer(poll + 1);
}
public int getSum() {
return this.slots.stream().mapToInt(Integer::intValue).sum();
}
public void refreshSlot( long now ) {
long timePassed = now - lastRefreshTime; // 已流逝的時間
if ( timePassed >= slotSize ) { // 超過區間時間 -- 說明要移動窗口
int goAhead = (int) timePassed / slotSize; // 需要往前移動幾個區間
int end = Math.min(slotCount, goAhead);
for (int i = 0; i < end; ++i ) {
// 移除窗口
slots.poll();
slots.offer(0); // 添加區間
}
lastRefreshTime += (long) goAhead * slotSize;
}
}
}
}
他有什么缺點呢?
- 實現復雜:需維護多個時間片的計數器和滑動邏輯。
- 資源消耗高:時間片越多,內存和計算開銷越大。
實際上我們可以借助Redis的zset來輔助實現滑動窗口的限流:
Redis ZSET 特性:
- 用
ZSET存儲請求的時間戳(score)和唯一標識(member)。 - 通過
ZREMRANGEBYSCORE刪除過期的請求,通過ZCOUNT統計當前窗口內的請求數。
主要是下面兩個命令:
ZREVRANGEBYSCORE key min max 移除有序集合中給定的分數區間的所有成員
ZCARD key 獲取有序集合的成員數
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ZSetOperations;
import java.util.concurrent.TimeUnit;
public class SlidingWindowLimiter {
private final RedisTemplate<String, String> redisTemplate;
private final String keyPrefix; // 限流Key前綴(如 "rate_limit:api1")
private final long windowMillis; // 時間窗口長度(毫秒)
private final int maxRequests; // 窗口內允許的最大請求數
public SlidingWindowLimiter(RedisTemplate<String, String> redisTemplate, String keyPrefix,
long windowMillis, int maxRequests) {
this.redisTemplate = redisTemplate;
this.keyPrefix = keyPrefix;
this.windowMillis = windowMillis;
this.maxRequests = maxRequests;
}
/**
* 檢查是否允許請求
* @param userId 用戶標識(用于區分不同用戶)
* @return true: 允許;false: 拒絕
*/
public boolean allowRequest(String userId) {
String key = keyPrefix + ":" + userId;
long now = System.currentTimeMillis();
long windowStart = now - windowMillis;
// Lua腳本保證原子性操作
String luaScript =
"local key = KEYS[1]\n" +
"local now = tonumber(ARGV[1])\n" +
"local windowStart = tonumber(ARGV[2])\n" +
"local maxRequests = tonumber(ARGV[3])\n" +
"local member = ARGV[4]\n" +
"\n" +
"-- 刪除窗口外的舊數據\n" +
"redis.call('ZREMRANGEBYSCORE', key, 0, windowStart)\n" +
"\n" +
"-- 獲取當前窗口內的請求總數\n" +
"local count = redis.call('ZCARD', key)\n" +
"\n" +
"-- 判斷是否超過閾值\n" +
"if count >= maxRequests then\n" +
" return 0\n" +
"else\n" +
" -- 添加當前請求\n" +
" redis.call('ZADD', key, now, member)\n" +
" -- 設置Key的過期時間(避免冷數據長期占用內存)\n" +
" redis.call('PEXPIRE', key, windowMillis + 1000)\n" +
" return 1\n" +
"end";
// 執行Lua腳本
Long result = redisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
List.of(key),
String.valueOf(now),
String.valueOf(windowStart),
String.valueOf(maxRequests),
String.valueOf(now) + ":" + UUID.randomUUID() // 唯一標識
);
return result != null && result == 1;
}
}
/*
(1) 原子性保障
Lua腳本:將 ZREMRANGEBYSCORE(清理舊數據)、ZCARD(統計請求數)、ZADD(記錄新請求)合并為原子操作,避免并發問題。
(2) 內存管理
自動過期:通過 PEXPIRE 設置 Key 的過期時間(窗口長度 + 緩沖時間),防止長期不用的 Key 占用內存。
*/
③令牌桶限流
令牌桶算法的原理是系統會以一個恒定的速度往桶里放入令牌,而如果請求需要被處理,則需要先從桶里獲取一個令牌,當桶里沒有令牌可取時,則拒絕服務。【引用的參考鏈接1中的圖片】

優點
- 支持突發:令牌在空閑時累積,請求可一次性消耗多枚令牌,應對短時高峰
- 平均速率可控:長期看,令牌生成速率決定了整體吞吐上限,既可平滑亦可靈活
缺點
- 需令牌維護:要定期“填充”令牌,并維護當前令牌數狀態,帶來額外邏輯開銷
- 可能延遲突發處理:如果令牌已被消耗,突發請求仍然會被拒絕或延后處理
public class TokenBucketLimit implements Limit {
private static final int MAX_TOKEN = 50; // 每個桶最大50個
private static final int FILL_RATE = 5; // 每秒往桶中放5個令牌
private final ConcurrentHashMap<String, Pair> limitMap;
public TokenBucketLimit() {
limitMap = new ConcurrentHashMap<>(2);
}
@Override
public synchronized boolean isAccess(Resource resource) {
long now = System.currentTimeMillis();
String name = resource.getName();
Pair pair = limitMap.get(name);
if (pair == null) { // 說明該接口沒有被訪問過
limitMap.put(name, new Pair(now, MAX_TOKEN));
return true;
} else {
// 1.先放令牌
addToken(now, pair);
// 2.取令牌
if (pair.getToken().get() > 0) {
pair.getToken().decrementAndGet();
return true;
}
}
return false;
}
private void addToken(long now, Pair pair) {
long during = now - pair.lastFillTime;
int v = (int) (during * 1.0 / 1000 * FILL_RATE);
if (v > 0) {
pair.setToken(Math.min(MAX_TOKEN, pair.getToken().get() + v));
pair.lastFillTime = now;
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
private static class Pair {
private long lastFillTime; // 上一次填充令牌的時間戳
private AtomicInteger token; // 令牌桶
public Pair(long lastFillTime, int token) {
this.lastFillTime = lastFillTime;
this.token = new AtomicInteger(token);
}
public void setToken(int token) {
this.token.set(this.token.get() + token);
}
}
}
④漏桶
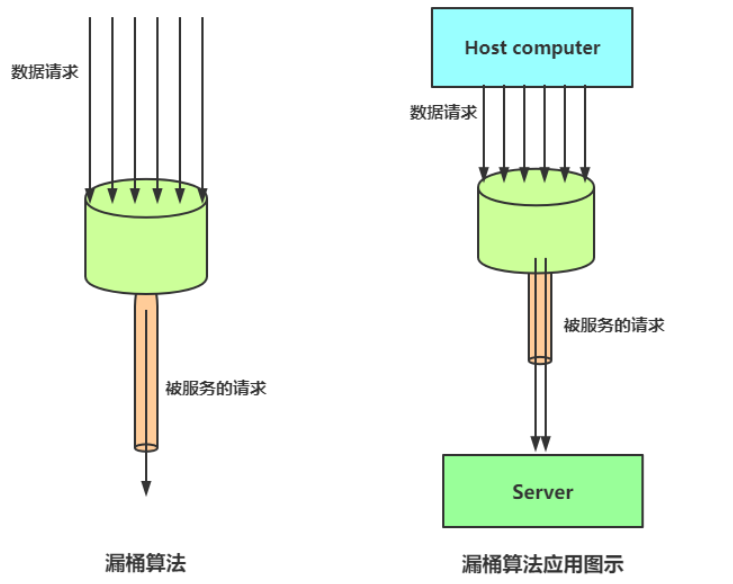
漏桶算法是一種經典的流量整形(Traffic Shaping)和限流(Rate Limiting)算法,通過固定速率處理請求,無論請求的到達速率如何波動,系統的處理速率始終保持恒定,從而平滑突發流量,保護下游系統不被壓垮。其核心思想類似于“水桶漏水”——無論水流多快,漏水的速率是固定的。
- 漏桶容器:
- 所有請求先進入漏桶隊列(桶的容量固定)。
- 若桶已滿,新請求被拒絕(溢出)。
- 恒定漏水速率:
- 漏桶以固定速率(如每秒10次)處理隊列中的請求,無論請求的到達速率多快。如下圖【引用的參考鏈接1中的圖片】
- 隊列版漏桶
我發現它相較于上面三個限流算法,有一個很不一樣的點,那就是中間有一個緩沖區,假設它的容量是k,然后漏水的速率也就是請求放行的速率是v,客戶端發送過來的請求速率是v1。如果v1 > v的話,緩沖區就會緩存任務,該請求會存在等待的行為。這就是它區別于上述其他三種限流算法的一點。所以,我認為它嚴格平滑輸出(恒定服務速率),適用于能夠接受一定排隊延遲的場景。
public class LeakyBucketLimiter {
private final Queue<Request> bucket; // 漏桶隊列
private final int capacity; // 漏桶容量
private final int leakRate; // 漏水速率(請求/秒)
private final ScheduledExecutorService scheduler;
public LeakyBucketLimiter(int capacity, int leakRate) {
this.capacity = capacity;
this.leakRate = leakRate;
this.bucket = new LinkedBlockingQueue<>(capacity);
this.scheduler = Executors.newScheduledThreadPool(1);
// 啟動漏水任務(固定速率處理)
scheduler.scheduleAtFixedRate(this::leak, 0, 1000 / leakRate, TimeUnit.MILLISECONDS);
}
/** 嘗試將請求放入漏桶 */
public boolean tryAccept(Request request) {
if (bucket.size() >= capacity) {
return false; // 桶已滿,拒絕請求
}
return bucket.offer(request);
}
/** 漏水(處理請求) */
private void leak() {
if (!bucket.isEmpty()) {
Request request = bucket.poll();
processRequest(request); // 實際處理請求的方法
}
}
private void processRequest(Request request) {
// 實際業務邏輯(如調用下游API)
System.out.println("處理請求: " + request.getId() + " at " + System.currentTimeMillis());
}
/** 關閉限流器 */
public void shutdown() {
scheduler.shutdown();
}
/** 請求對象示例 */
static class Request {
private final String id;
public Request(String id) { this.id = id; }
public String getId() { return id; }
}
public static void main(String[] args) {
LeakyBucketLimiter limiter = new LeakyBucketLimiter(10, 5); // 容量10,速率5請求/秒
// 模擬請求
for (int i = 0; i < 20; i++) {
System.out.println("請求 " + i + " 是否被接受: " + limiter.tryAccept(new Request("req-" + i)));
}
}
}
- 計量版漏桶
該版本不維護顯式隊列,只用一個計數器(桶水位)和固定的泄漏速率來判定請求是否合規:每次到來請求前,先按漏桶速率“泄漏”令水位下降;若水位加上該請求的水量仍不超過桶容量,則通過并累加水量,否則立即拒絕。【但是這個我覺得不是很符合漏桶算法的模型,并且這個很像令牌桶,令牌桶是先放令牌,再拿走令牌;這里是先漏水,再加水】
public class LeakyBucketLimiter2 {
// 最大容量(可接受的最大突發量)
private final double capacity;
// 泄漏速率:每毫秒可泄漏的“水量”
private final double leakRatePerMillis;
// 當前桶中“水位”
private double water;
// 上次執行泄漏操作的時間戳(毫秒)
private long lastTime;
public LeakyBucketMeter(double capacity, double leakRatePerSecond) {
this.capacity = capacity;
this.leakRatePerMillis = leakRatePerSecond / 1000.0;
this.water = 0.0;
this.lastTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire() {
leak(); // 先按速率泄漏舊水
if (water + 1.0 <= capacity) {
water += 1.0;
return true; // 請求合規
}
return false; // 請求超限,直接拒絕
}
private void leak() {
long now = System.currentTimeMillis();
double leaked = (now - lastTime) * leakRatePerMillis;
// 水位不能低于0
water = Math.max(0.0, water - leaked);
lastTime = now;
}
}
⑤ 其他
單機場景:優先選擇Guava RateLimiter(簡單)
分布式微服務:推薦Sentinel(功能全面、見后續文章)或Redisson(與Redis深度集成)
網關層防護:Nginx或Spring Cloud Gateway內置限流模塊,結合黑白名單策略
3.敏感詞過濾
敏感詞過濾旨在從用戶生成內容(如社交媒體、聊天室、評論區)中識別并移除涉及暴力、色情、政治敏感、隱私泄露等違規詞匯或表達。
現在了解到的比較好的方案大致如下:
-
機器學習與深度學習:結合自然語言處理(NLP)技術分析上下文語義,減少誤判(如區分“蘋果”作為水果或品牌);
-
DFA/Trie樹:利用確定有限狀態自動機或字典樹提升匹配效率,適用于海量敏感詞庫;
本文就不考慮深度學習了,直接看第二種,我們來手動實現一個簡易的dfa算法。
DFA(Deterministic Finite Automaton,確定有限狀態自動機)是一種高效的模式匹配算法,尤其在敏感詞過濾、文本分析和詞法解析領域應用廣泛。它的構建基于狀態轉移樹,每個狀態對應敏感詞中的一個字符,通過嵌套的哈希表或字典樹(Trie樹)實現層級關系。
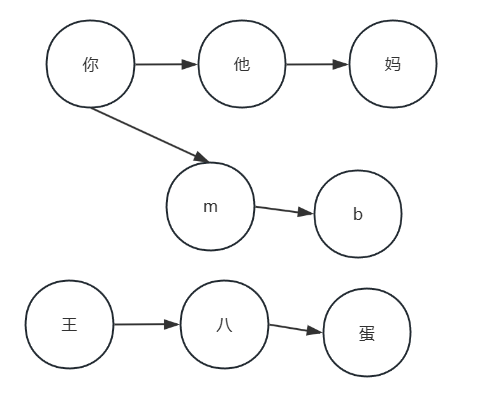
具體構建步驟:首先初始化根節點,創建一個初始狀態(根節點),通常用Map表示,作為所有敏感詞匹配的起點;然后逐字符構建狀態轉移,例如敏感詞“王八蛋”,按順序處理字符“王”→“八”→“蛋”,對每個字符檢查當前層級是否存在對應的子節點。若不存在,新建節點并標記字符,若存在則直接跳轉到該節點;最后在敏感詞的最后一個字符節點上設置結束標志(如isEnd: true),表示匹配完成。如下json表示【詞庫: ”王八“、”王八蛋“、”王八兒子“、”傻“】
{
"王": {
"isEnd": false,
"八": {
"isEnd": true,
"蛋": {
isEnd: true
},
"兒":{
isEnd: false,
"子": {
isEnd: true
}
}
}
},
"傻": {
"isEnd": true
}
}
/*
根節點
├── 王 → 八 →(結束標記)
│ ├── 蛋 →(結束標記)
│ └── 兒 → 子 →(結束標記)
└── 傻 →(結束標記)
*/
從上面結構可以看出,王八蛋和王八兒子,他們是共享的前綴,以此來節省空間。
那么,匹配是怎么做到的呢?如果來了一句話 “張三是個王八蛋”:
逐字符掃描與狀態跳轉
- 初始狀態:從根節點開始掃描文本。
- 字符“張”“三”“是”“個”:均不在Trie樹根節點的子節點中,跳過。
- 字符“王”:匹配到根節點的子節點“王”,跳轉到該節點。
- 字符“八”:繼續匹配到子節點“八”,此時路徑“王→八”已構成敏感詞“王八”(若需要最短匹配可觸發攔截)
- 字符“蛋”:繼續匹配到子節點“蛋”,路徑“王→八→蛋”觸發敏感詞“王八蛋”(最長匹配規則優先)
匹配終止與處理
- 命中規則:當路徑完整匹配敏感詞時(如到達“蛋”節點且標記為結束),觸發攔截或替換邏輯。
- 替換示例:將“王八蛋”替換為“*”,輸出結果為“張三是個*“
可以看到上述算法,只需要將目標字符串遍歷一遍就可以了,時間復雜度是O(n),在我們最開始的場景來說效率還行,反正一條評論、聊天消息或者彈幕的話,字數通常也不會太多。
public class TrieNode {
// 子節點(key是下級字符,value是對應的節點)
private final Map<Character, TrieNode> subNodes = new HashMap<>();
// 是否是關鍵詞的結尾
private boolean isKeywordEnd = false;
// 添加子節點
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 獲取子節點
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
// 判斷是否是關鍵詞結尾
public boolean isKeywordEnd() {
return isKeywordEnd;
}
// 設置關鍵詞結尾
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
}
// 過濾器
public class SensitiveWordFilter {
private final TrieNode rootNode = new TrieNode(); // 根節點
private static final char FILTER_FLAG = '*';
// 0.加載敏感詞
public void loadSensitiveWords(Set<String> sensitiveWords) {
for (String word : sensitiveWords) addWord(word);
}
// 2.過濾敏感詞
public String filter(String text) {
if (text == null || text.isEmpty()) return text;
text = normalizeText(text); // 轉換為小寫并處理全角字符
StringBuilder result = new StringBuilder(text);
// 文本長度
int length = text.length();
// 遍歷文本每個字符作為起始位置
for (int i = 0; i < length; ++i ) {
// 從當前位置開始檢查敏感詞
int sensitiveWordLength = checkSensitiveWord(text, i);
if (sensitiveWordLength > 0) {
// 替換為相同長度的*
for (int j = 0; j < sensitiveWordLength; j++) {
result.setCharAt(i + j, FILTER_FLAG);
}
// 跳過已處理的敏感詞長度
i = i + sensitiveWordLength - 1;
}
}
return result.toString();
}
// 1.添加敏感詞到Trie樹
private void addWord(String keyword) {
if (keyword == null || keyword.isEmpty()) return;
keyword = normalizeText(keyword); // 轉換為小寫并處理全角字符
TrieNode currentNode = rootNode;
for (int i = 0; i < keyword.length(); ++i) {
char c = keyword.charAt(i);
TrieNode node = currentNode.getSubNode(c);
if (node == null) {
node = new TrieNode();
currentNode.addSubNode(c, node);
}
currentNode = node;
// 設置結束標識
if (i == keyword.length() - 1) {
currentNode.setKeywordEnd(true);
}
}
}
// 3.從文本中檢查敏感詞
private int checkSensitiveWord(String text, int beginIndex) {
TrieNode currentNode = rootNode;
int length = 0;
boolean isSensitiveWord = false;
// 從beginIndex開始逐字符檢查
for (int i = beginIndex; i < text.length(); i++) {
char c = text.charAt(i);
// 過濾空格,支持如"傻 狗"這樣的敏感詞檢測
if (c == ' ') {
length++;
continue;
}
// 獲取下一級節點
currentNode = currentNode.getSubNode(c);
if (currentNode == null) {
// 沒有匹配的繼續字符,終止檢查
break;
} else {
// 匹配到一個字符,長度加1
length++;
// 如果是關鍵詞結尾,則標記為敏感詞
if (currentNode.isKeywordEnd()) {
isSensitiveWord = true;
}
}
}
// 如果不是敏感詞,返回0
if (!isSensitiveWord) length = 0;
return length;
}
// 將文本轉換為小寫并處理全角字符
private String normalizeText(String text) {
StringBuilder sb = new StringBuilder();
for (char c : text.toCharArray()) {
// 全角轉半角
if (c >= 65281 && c <= 65374) {
c = (char) (c - 65248);
}
// 統一大小寫
if (Character.isUpperCase(c)) c = Character.toLowerCase(c);
sb.append(c);
}
return sb.toString();
}
}
DFA通過Trie樹實現敏感詞的高效匹配,其核心在于公共前綴合并和逐字符狀態跳轉。實際應用中需結合詞庫動態更新、語義分析等策略提升準確性。現在我們就實現了這一種過濾方法。但是,這肯定是不足夠應對我們這些聰明的人類的,首先如果我們的詞庫里面有“黃色”,假如說有一條評論是“這個香蕉還沒有變成黃色的,不能吃”,那么上面這個dfa算法就不適用了,所以這就引入了一種上下文語境的問題。
// 測試一下
public class SensitiveTest {
public static void main(String[] args) {
SensitiveWordFilter filter = new SensitiveWordFilter();
filter.loadSensitiveWords(Set.of("傻", "王八", "王八蛋", "王八兒子", "黃色"));
String text = "張三是個大王八,真的是服了,這個黃色的香蕉是留給他的";
String str = filter.filter(text);
System.out.println(str);
}
}
// 張三是個大**,真的是服了,這個**的香蕉是留給他的
敏感詞過濾識別當然不可能會這么簡單,實際場景可能比我們想到的復雜千百倍,除了上下文語境問題,還可能會有方言、同音詞替換、用首字母罵人等等。最佳的肯定是通過人工智能與自然語言處理技術實現精準識別,結合動態規則與上下文分析降低誤判率。本文僅簡單探索一下DFA算法的實現。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號