并發編程--下篇
Java并發探索--下篇
承接上文:
博客園【上篇】:http://www.rzrgm.cn/jackjavacpp/p/18852416
csdn:【上篇】:https://blog.csdn.net/okok__TXF/article/details/147595101
1. AQS實現鎖
網址:http://www.rzrgm.cn/jackjavacpp/p/18787832
1) aqs分析
AQS 的核心原理是通過一個 int 類型的狀態變量 state 來表示同步狀態,使用一個 FIFO 隊列來管理等待的線程。通過 CAS 操作來保證狀態的原子性更新,同時提供了獨占模式和共享模式的獲取與釋放方法。子類可以通過重寫 tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared 等方法來實現具體的同步邏輯。
// 關鍵的屬性:
// 同步狀態,0 表示未鎖定,大于 0 表示已鎖定[>1表示可重入鎖的重入次數]
private volatile int state;
// 隊列的頭節點
private transient volatile Node head;
// 隊列的尾節點
private transient volatile Node tail;
// 其中Node的重要變量
//節點已取消: 表示該節點關聯的線程已放棄等待(如超時、被中斷),需從隊列中移除
static final int CANCELLED = 1;
//需喚醒后繼節點: 當前節點的線程釋放鎖或取消時,必須喚醒其后繼節點。
//節點入隊后需確保前驅節點的waitStatus為SIGNAL,否則需調整前驅狀態。
static final int SIGNAL = -1;
//節點在條件隊列中: 表示節點處于條件隊列(如Condition的等待隊列),而非同步隊列(CLH隊列)。
//狀態轉換:當調用Condition.signal()時,節點從條件隊列轉移到同步隊列,狀態重置為0
static final int CONDITION = -2;
//共享模式下喚醒需傳播: 在共享鎖(如Semaphore)釋放時,確保喚醒動作傳播給所有后續節點。
static final int PROPAGATE = -3;
//通過狀態值控制線程的阻塞、喚醒和隊列管理
volatile int waitStatus;
aqs獨占鎖、共享鎖的獲取和釋放分析
- 獨占鎖
獨占鎖的獲取:
// AbstractQueuedSynchronizer.java
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire:嘗試直接獲取鎖,這是一個需要子類實現的方法, 嘗試直接獲取鎖(如CAS修改state)。【非公平鎖:直接嘗試CAS搶占資源;公平鎖:先檢查隊列中是否有等待線程(hasQueuedPredecessors()),避免插隊】
如果第一步返回false, 則進入第二步: addWaiter:將當前線程封裝成一個 Node 節點,并添加到等待隊列的尾部。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 嘗試快速插入到隊列尾部
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 快速插入失敗,使用 enq 方法插入
enq(node);//enq 方法會通過循環和 CAS 操作確保節點成功插入到隊列尾部。
return node;
}
private Node enq(final Node node) {
// 死循環
for (;;) {
Node t = tail;
if (t == null) {
// 使用CAS設置頭結點 -- 這里是設置了一個普通的node
// 下次循環才會把傳進來的node放到隊列尾部
if (compareAndSetHead(new Node()))
// 首尾指向同一個節點
tail = head;
} else { // 尾部tail不為空,說明隊列中有節點
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
然后,結點添加到隊列尾部之后,acquireQueued:讓當前線程在同步隊列中阻塞,然后在被其他線程喚醒時去獲取鎖;【讓線程在同步隊列中阻塞,直到它成為頭節點的下一個節點,被頭節點對應的線程喚醒,然后開始獲取鎖,若獲取成功才會從方法中返回】。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 獲取當前線程節點的前一個節點
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {// 前驅是頭節點且獲取鎖成功
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
// 說明前驅節點會在釋放鎖時喚醒當前節點,當前線程可以安全地阻塞
return true;
// 如果前驅節點的等待狀態大于 0,即 CANCELLED 狀態
if (ws > 0) {
// 前驅節點已取消,需要跳過這些已取消的節點
do {
// 將當前節點的前驅節點指向前驅節點的前驅節點
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
// 更新跳過已取消節點后的前驅節點的后繼節點為當前節點
pred.next = node;
} else {
// 前驅節點的等待狀態為 0 或 PROPAGATE,將其狀態設置為 SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
// 當前線程不應該被阻塞,需要再次嘗試獲取鎖
return false;
}
shouldParkAfterFailedAcquire():確保前驅節點的waitStatus為SIGNAL(表示會喚醒后繼節點),否則清理已取消的節點;它通過檢查前驅節點的等待狀態,決定當前線程在獲取鎖失敗后是否應該被阻塞。它處理了前驅節點的不同狀態,確保等待隊列的正確性和線程的正確阻塞與喚醒,
parkAndCheckInterrupt() :讓當前線程阻塞,并且在被喚醒之后檢查該線程是否被中斷 【里面用到了LockSupport,見后面并發工具】
獨占鎖的釋放:
public final boolean release(int arg) {
//調用tryRelease【子類里面實現】
//嘗試修改state釋放鎖,若成功,將返回true,否則false
if (tryRelease(arg)) {
Node h = head;
// 檢查頭節點不為空且頭節點的等待狀態不為 0
if (h != null && h.waitStatus != 0)
// 喚醒頭節點的后繼節點
unparkSuccessor(h);
return true; // 釋放成功,返回 true
}
return false;// 釋放失敗,返回 false
}
private void unparkSuccessor(Node node) {
// 獲取節點的等待狀態
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 獲取節點的后繼節點
Node s = node.next;
// 如果后繼節點為空或者后繼節點的等待狀態大于 0(已取消)
if (s == null || s.waitStatus > 0) {
s = null;
// 從隊列尾部開始向前查找,找到第一個等待狀態小于等于 0 的節點
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 如果找到了合適的后繼節點,喚醒該節點對應的線程
if (s != null)
LockSupport.unpark(s.thread);
}
- 共享鎖
共享鎖的獲取
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)//這個方法子類實現
//若返回值小于0,表示獲取共享鎖失敗,則線程需要進入到同步隊列中等待
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED); // 以SHARED加入一個結點
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) { // 獲取共享鎖成功
setHeadAndPropagate(node, r); // 傳播給其他線程
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
// 判斷是否阻塞,喚醒后是否被中斷--同上
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // 記錄舊的頭節點
setHead(node); // 將當前節點設置為新的頭節點
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
setHeadAndPropagate(node, r); 先把當前獲取到同步狀態的節點設置為新的頭節點,接著根據不同條件判斷是否要將共享狀態的獲取傳播給后續節點。要是滿足傳播條件,就會調用 doReleaseShared 方法去喚醒后續等待的共享節點。
共享鎖的釋放
public final boolean release(int arg) {
// 調用tryRelease:【子類實現】
if (tryRelease(arg)) {
// 若釋放鎖成功,需要將當前線程移出同步隊列
Node h = head;
// 若head不是null,且waitStatus不為0,表示它是一個裝有線程的正常節點,
// 在之前提到的addWaiter方法中,若同步隊列為空,則會創建一個默認的節點放入head
// 這個默認的節點不包含線程,它的waitStatus就是0,所以不能釋放鎖
if (h != null && h.waitStatus != 0)
// 若head是一個正常的節點,則調用unparkSuccessor喚醒它的下一個節點所對應的線程
unparkSuccessor(h);
// 釋放成功
return true;
}
// 釋放鎖失敗
return false;
}
2) 自定義鎖
- 自定義一個讀寫鎖
學一下jdk源碼,寫一個內置的Sync同步器,低位16位記錄寫鎖重入次數,高位16位記錄讀鎖獲取次數
// 內置同步器
private static class Sync extends AbstractQueuedSynchronizer {
static final int SHARED_SHIFT = 16;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 寫鎖方法(tryAcquire/tryRelease)-- 獨占
protected boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int state = getState();
int writeCount = getWriteCount(state);
// 如果存在讀鎖或寫鎖(且持有者不是當前線程),獲取失敗
if (state != 0) {
// writeCount是0,但是state不是0,說明有線程獲取到了讀鎖
if (writeCount == 0 || current != getExclusiveOwnerThread())
return false;
}
// 檢查是否超過最大重入次數(低16位是否溢出)
if (writeCount + acquires > EXCLUSIVE_MASK)
throw new Error("超出最大重入次數");
// CAS更新寫鎖狀態
if (compareAndSetState(state, state + acquires)) {
setExclusiveOwnerThread(current);
return true;
}
return false;
}
protected boolean tryRelease(int releases) {
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
int newState = getState() - releases;
boolean free = (getWriteCount(newState) == 0);
if (free)
setExclusiveOwnerThread(null);
setState(newState);
return free;
}
// 讀鎖方法(tryAcquireShared/tryReleaseShared)
protected int tryAcquireShared(int acquires) {
Thread current = Thread.currentThread();
int state = getState();
// 如果有其他線程持有寫鎖,且不是當前線程(允許鎖降級),則獲取失敗
if (getWriteCount(state) != 0 && getExclusiveOwnerThread() != current)
return -1;
// 計算讀鎖數量
int readCount = getReadCount(state);
if (readCount == (1 << SHARED_SHIFT) - 1)
throw new Error("超出最大讀鎖數量");
// CAS增加讀鎖計數(高16位)
if (compareAndSetState(state, state + (1 << SHARED_SHIFT))) {
return 1; // 成功獲取讀鎖
}
return -1; // 需要進入隊列等待
}
protected boolean tryReleaseShared(int releases) {
for (;;) {
int state = getState();
int readCount = getReadCount(state);
if (readCount == 0)
throw new IllegalMonitorStateException();
// CAS減少讀鎖計數
int newState = state - (1 << SHARED_SHIFT);
if (compareAndSetState(state, newState)) {
return readCount == 1; // 最后一個讀鎖釋放時可能觸發喚醒
}
}
}
// 其他輔助方法
int getReadCount(int state) { return state >>> SHARED_SHIFT; }
int getWriteCount(int state) { return state & EXCLUSIVE_MASK; }
}
上面的同步器中,需要注意的點如下:
高16位和低16位是啥情況?
1. 從state獲取寫重入次數 和 讀鎖持有數====================
先說低16位,我們都知道int是32位的整數,用低16位的二進制位表示寫鎖的重入次數,如下:
32位二進制:
[高位16位]11111111 11111111 | [低位16位]11111111 11111111
16位二進制全部是1,那么其表示的數字就是 2^16 - 1 = 65535【也就是說最大可重入次數是65535次】
既然現在是用的state的低位16位來記錄的寫鎖重入次數,我們要怎么獲取state的低位16位表示的數字呢?
很明顯: state & ( 65535 ) 就行了: 也就是上面的 state & EXCLUSIVE_MASK
高位16位呢?【讀鎖獲取的次數】
是不是state無符號右移16位就行了,剩下的不就是高位的16位了嗎
也就是上面的:state >>> SHARED_SHIFT
2. 增加/減少重入次數 和 讀鎖持有數====================
寫鎖的話,直接state加減就可以了,因為直接加減就是從最低位開始的;
讀呢? 因為需要把數字加到高位部分的那16位去,所以把需要加的數左移16位就好了;減的話同理。
知道了這些然后就好理解了
public class TReadWriteLock {
private final Sync sync;
private final ReadLock readLock;
private final WriteLock writeLock;
public TReadWriteLock() {
sync = new Sync();
readLock = new ReadLock(sync);
writeLock = new WriteLock(sync);
}
// 對外暴露讀寫鎖
public Lock readLock() {return readLock;}
public Lock writeLock() {return writeLock;}
// 同步器Sync
....
// 讀鎖(共享)
public static class ReadLock implements Lock {
private final Sync sync;
public ReadLock(Sync sync) { this.sync = sync; }
public void lock() { sync.acquireShared(1); }
public void unlock() { sync.releaseShared(1); }
// 其他方法(略)
}
// 寫鎖(獨占)
public static class WriteLock implements Lock {
private final Sync sync;
public WriteLock(Sync sync) { this.sync = sync; }
public void lock() { sync.acquire(1); }
public void unlock() { sync.release(1); }
// 其他方法(略)
}
}
這樣自定義了一個簡單的讀寫鎖就完成了, 然后測試一下
public class CustomLockTest {
private TReadWriteLock readWriteLock;
private Lock readLock;
private Lock writeLock;
private Map<String, String> data;
public CustomLockTest() {
readWriteLock = new TReadWriteLock();
readLock = readWriteLock.readLock();
writeLock = readWriteLock.writeLock();
data = new HashMap<>();
}
public static void main(String[] args) {
CustomLockTest obj = new CustomLockTest();
// 兩個線程寫
new Thread(() -> obj.write("key", "value"), "寫Thread-1").start();
new Thread(() -> obj.write("key", "value5"), "寫Thread-2").start();
// 4個線程讀
for (int i = 0; i < 4; i++)
new Thread(() -> System.out.println(obj.read("key")), "讀" + i).start();
try {
TimeUnit.SECONDS.sleep(5);
System.out.println("main線程結束");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public void write(String key, String value) {
writeLock.lock();
try {
System.out.println( Thread.currentThread().getName() + "寫入中~~~");
TimeUnit.SECONDS.sleep(1);
data.put(key, value);
System.out.println( Thread.currentThread().getName() + "寫入ok~~~");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
writeLock.unlock();
}
}
public String read(String key) {
readLock.lock();
try {
System.out.println( Thread.currentThread().getName() + "讀取中~~~");
TimeUnit.SECONDS.sleep(2);
System.out.println( Thread.currentThread().getName() + "讀取ok~~~" + data.get(key));
return data.get(key);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
readLock.unlock();
}
}
}
2. 探索并發工具
①ConcurrentHashMap
- jdk1.8
Java 提供了一個多線程版本的ConcurrentHashMap。不僅線程安全,還能保持一定的性能。普通版本的HashMap看這里:
普通的Map --網址:http://www.rzrgm.cn/jackjavacpp/p/18787832
本文這里主要看其put方法和get方法: 我這里就寫在注釋里面了
先看put方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 熟悉HashMap的都知道,HashMap是允許key為null的!
// 這里key、value都不能為null!!!!
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;// 用于記錄鏈表或紅黑樹中節點的數量
// 熟悉HashMap的都知道,HashMap.put東西最外層是沒有循環的
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable(); // 初始化底層table
// hash計算出的index上的位置是空的
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// cas修改這個位置--那么看到這里應該很清楚了,外面為什么會有for循環了
// 這一看就是cas的自旋鎖嘛
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // cas修改ok,就break了
}
// 如果該位置的節點的哈希值為 MOVED,說明正在進行擴容操作,當前線程協助進行擴容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else { // hash計算出的index上的位置不是空的
V oldVal = null;
// f是table[(n - 1) & hash]的元素,
// 可以理解為f表示某一個桶,這里鎖某一個桶,減小了鎖的粒度
synchronized (f) {
// 判斷一下該位置是不是被別人動過了
if (tabAt(tab, i) == f) {
// fh是f的hash值
if (fh >= 0) {
binCount = 1;
// 遍歷鏈表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 檢查當前節點的鍵是否與要插入的鍵相同
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;// 記錄舊值
if (!onlyIfAbsent)// 如果 onlyIfAbsent 為 false,更新節點的值
e.val = value;
break;
}
Node<K,V> pred = e;
// 如果遍歷到鏈表末尾,將新節點插入到鏈表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果該位置的節點是 TreeBin 類型,說明該位置是一個紅黑樹
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果 binCount 不為 0,說明已經完成插入或更新操作
if (binCount != 0) {
// 如果鏈表長度達到樹化閾值,將鏈表轉換為紅黑樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 更新元素數量并檢查是否需要擴容
addCount(1L, binCount);
return null;
}
值得注意的是:tabAt方法是以原子操作的方式獲取 ConcurrentHashMap 底層數組中指定索引位置的節點,以此保證數據的一致性和線程安全。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
從上面put元素的過程可以知道:ConcurrentHashMap的put是 synchronized鎖 + cas自旋來達到線程安全的效果的。【這是jdk1.8】
下面看jdk8的get方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); // 計算哈希值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) { // 先判空
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
可以看到get方法并沒有加鎖。
ConcurrentHashMap的新方法:
putlfAbsent(K key,Vvalue):只有當key不存在時才插入。
此外,ConcurrentHashMap中map.put(key, map.get(key) + 1);并不會保證原子性。為了保證復合操作的原子性,ConcurrentHashMap在1.8中還有HashMap里面沒有的新方法:
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) :
對 key 對應的值進行重新計算。
merge(K key, V value, BiFunction<? super V, ? super V, ?extends V> remappingFunction) : 如果 key 已存在,就用新的 value 與l日值進行合并。
@FunctionalInterface
public interface BiFunction<T, U, R> {
// 接受兩個參數,返回一個值就行了
R apply(T t, U u);
}
public static void testConcurrentHashMap() {
ConcurrentHashMap<String, Object> m = new ConcurrentHashMap<>();
m.put("1", "##");
printMap(m);
m.put("1", "2");
printMap(m);
//===================================== 【1】putIfAbsent
m.putIfAbsent("2", "3");
m.putIfAbsent("1", "3"); // 這一個并沒有覆蓋原來的喔
printMap(m);
//===================================== 【2】compute
// 把key為"1"的value變成 k + v + "hahah"
m.compute("1", (k, v) -> k + v + "hahah");
// key不存在,則添加 --- value就變成: 3nullhahah
m.compute("3", (k, v) -> k + v + "hahah");
printMap(m);
//===================================== 【3】merge
m.merge("1", "3ppp", (oldVal, newVal) -> oldVal.toString() + newVal); // oldVal:舊值 newVal:新值[傳進去的value]
m.merge("4", "3", (oldVal, newVal) -> "hahah" + oldVal + newVal); // 不存在4這個key,那么就put("4", "3")
printMap(m);
}
- jdk1.7
在 JDK 1.7 中,ConcurrentHashMap 的 put 方法實現是基于分段鎖機制的。它將整個哈希表分成多個 Segment,每個 Segment 類似于一個小的 HashMap,并且每個 Segment 都有自己的鎖,不同 Segment 之間的操作可以并發進行,從而提高了并發性能。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)//空值檢查
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;//確定 Segment 索引
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);//調用 Segment 的 put 方法
}
//Segment 的 put 方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);//獲取鎖
V oldValue;
try {// 查找或插入節點
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//計算 key 在 Segment 內部數組中的索引 index
HashEntry<K,V> first = entryAt(tab, index);//獲取該索引位置的第一個 HashEntry 節點 first。
for (HashEntry<K,V> e = first;;) {//遍歷鏈表
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
//如果找到相同的 key,根據 onlyIfAbsent 參數決定是否覆蓋原有的值。
if (!onlyIfAbsent) {
e.value = value;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
②流程控制
在JDK的并發包里面提供了幾個非常有用的并發工具,CountDownLatch、CyclicBarrier、Semaphore,他們提供了一種并發控制流程的手段。
1) CountDownLatch
核心功能是讓一個或多個線程等待其他線程完成操作后再繼續執行,它的使用步驟:
1.初始化計數器:創建時指定計數值(如 new CountDownLatch(3)),表示需要等待的事件數量。
2.任務完成減計數:每個線程完成任務后調用 countDown(),計數器減 1。
3.等待計數歸零:調用 await() 的線程會阻塞,直到計數器變為 0,所有等待線程被喚醒。
它的大致應用場景:
- 主線程等待子線程完成:如啟動服務時,主線程需等待多個組件初始化完成,這些組件又是并行執行的。
- 多階段任務協調:多個線程完成當前階段后,共同進入下一階段(如數據處理流水線)。
- 最大并行性控制:多個線程同時開始執行任務
下面給一個“火箭發射”的例子:
public class RocketLaunchDemo {
public static void main(String[] args) throws InterruptedException {
// 初始化計數器為3(3個檢查任務)
CountDownLatch latch = new CountDownLatch(3);
// 創建檢查線程
Thread fuelCheck = new Thread(new CheckTask(latch, "燃料檢查"), "Thread-1");
Thread engineCheck = new Thread(new CheckTask(latch, "引擎檢查"), "Thread-2");
Thread navigationCheck = new Thread(new CheckTask(latch, "導航檢查"), "Thread-3");
// 啟動檢查線程
fuelCheck.start();
engineCheck.start();
navigationCheck.start();
// 主線程等待所有檢查完成
System.out.println("等待所有檢查完成...");
latch.await(); // 阻塞直到計數器歸零
System.out.println("所有檢查完成,火箭點火發射!");
}
static class CheckTask implements Runnable {
private final CountDownLatch latch;
private final String taskName;
public CheckTask(CountDownLatch latch, String taskName) {
this.latch = latch;
this.taskName = taskName;
}
@Override
public void run() {
try {
// 模擬檢查耗時
Thread.sleep((long) (Math.random() * 2000));
System.out.println("【" + Thread.currentThread().getName() + "】" + taskName + "通過!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 無論是否異常,必須減少計數器
latch.countDown();
}
}
}
}
這好用啊!!但是需要注意的事:
- 它是一次性的【計數器歸零后無法重置,若需重復使用,需創建新實例或改用
CyclicBarrier】; - 對于
countDown()來說,盡量把它放在finally中,因為如果出現異常導致不能執行countDown(),從而計數器無法歸零,一直等待咯;所以可以使用await(long timeout, TimeUnit unit)可防止無限等待。同時,計數器值需與實際任務數一致,否則可能導致主線程提前或永久阻塞,如果上述案例中new CountDownLatch(3)變成了new CountDownLatch(4),少一個任務就會永久阻塞的。
底層原理:
其底層是基于aqs的共享模式實現的
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count); // 初始化內部的同步器
}
private static final class Sync extends AbstractQueuedSynchronizer {
Sync(int count) {
setState(count); // 設置aqs的state
}
}
// 當我們調用countDown()時:實際是同步器的releaseShared
public void countDown() {
sync.releaseShared(1);
}
// 同步器的tryReleaseShared
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
// 遞減1
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
// 調用await()的時候: 實際是sync.acquireSharedInterruptibly(1);
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted()) throw new InterruptedException();
if (tryAcquireShared(arg) < 0) // 如果小于0
doAcquireSharedInterruptibly(arg);// 就等待去吧
}
// 同步器的tryAcquireShared
protected int tryAcquireShared(int acquires) {
// 如果state不是0,說明有不能把等待的線程喚醒,那就等待吧
return (getState() == 0) ? 1 : -1;
}
2) CyclicBarrier
CyclicBarrier 是 Java 并發包中基于 ReentrantLock 和 Condition 實現的同步工具類,它的使用步驟:
1. new屏障計數器:初始化時指定參與同步的線程數(parties),每個線程調用 await() 時計數器減 1。
2. 屏障動作:當計數器歸零時,執行構造時傳入的 Runnable 任務(屏障動作),隨后所有等待線程被喚醒。
3. 可重用:屏障釋放后,計數器自動重置為初始值,支持重復使用
| 方法 | 作用 |
|---|---|
CyclicBarrier(int parties) |
初始化屏障,指定參與同步的線程數 |
CyclicBarrier(int parties, Runnable barrierAction) |
指定屏障動作(所有線程到達后執行) |
int await() |
線程等待,直到所有線程到達屏障點 |
int await(long timeout, TimeUnit unit) |
超時等待,返回超時狀態 |
void reset() |
重置屏障為初始狀態(清除已等待線程) |
boolean isBroken() |
檢查屏障是否處于損壞狀態(如線程中斷導致屏障失效) |
下面再舉一個例子:模擬 數據處理流水線
有三個階段步驟:加載數據,計算數據,存儲數據;有三個線程,每個線程里面都執行這三個階段,但是必須要等該階段所有線程執行完才能進行下一階段
public class PipelineDemo {
private static final int THREAD_COUNT = 3;
private static final CyclicBarrier barrier = new CyclicBarrier(
THREAD_COUNT,
() -> System.out.println("【階段同步完成】所有線程進入下一階段")
);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(new PipelineTask(i)).start();
}
}
static class PipelineTask implements Runnable {
private final int taskId;
public PipelineTask(int taskId) {
this.taskId = taskId;
}
@Override
public void run() {
try {
// 階段1:加載數據
System.out.println("【線程" + taskId + "】加載數據中...");
Thread.sleep((long) (Math.random() * 1000));
System.out.println("【線程" + taskId + "】數據加載完成");
// 等待其他線程完成階段1----在這里等著了,直到CyclicBarrier中parties達到了設置的3,才會喚醒
barrier.await();
// 階段2:計算
System.out.println("【線程" + taskId + "】計算中...");
Thread.sleep((long) (Math.random() * 1000));
System.out.println("【線程" + taskId + "】計算完成");
barrier.await(); // 等待其他線程完成階段2
// 階段3:存儲
System.out.println("【線程" + taskId + "】存儲中...");
Thread.sleep((long) (Math.random() * 1000));
System.out.println("【線程" + taskId + "】存儲完成");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
}
從上面可以看出來,CyclicBarrier的計數是遞增到設定值后歸零,這樣才進行下一階段的。
CyclicBarrier的構造函數第二個參數是屏障動作:在最后一個線程到達屏障時執行,常用于匯總結果或觸發下一階段(如示例中的階段同步提示)
與上一個工具比較一下:
| CyclicBarrier | CountDownLatch | |
|---|---|---|
| 線程角色 | 所有線程對等,互相等待 | 主線程等待子線程完成 |
| 重用性 | 可循環使用(自動重置) | 一次性使用 |
| 計數方向 | 也是減到0,但是會重置 | 遞減到 0 |
| 典型場景 | 多階段同步(如流水線) | 單次匯總(如等待初始化完成) |
| 屏障動作 | 支持(最后一個線程觸發) | 不支持 |
思考一下,上面的三階段例子我們用CountDownLatch也實現一下?交給讀者了
底層原理:
// 構造函數
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties; // 把parties賦值給count
this.barrierCommand = barrierAction;
}
// 調用await時
public int await() throws InterruptedException, BrokenBarrierException {
...
return dowait(false, 0L);
..
}
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock; // 底層是用的lock可重入鎖-實際上還是aqs
lock.lock(); // 加鎖
try {
final Generation g = generation;
....
// count先減一
int index = --count;
if (index == 0) { // 如果減到0了
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
// 運行傳進來的runnable, 這里只是調用run方法
if (command != null) command.run();
ranAction = true;
/*
private void nextGeneration() {
// signal completion of last generation
trip.signalAll(); // 喚醒所有的
// 重置次數!!!
count = parties;
generation = new Generation();
}
*/
nextGeneration();
return 0;
} finally {
if (!ranAction) breakBarrier();
}
}
// 如果沒有減到0
for (;;) {
try {
if (!timed) trip.await(); // 等待吧
else if (nanos > 0L) nanos = trip.awaitNanos(nanos); // 有時限等待吧
} catch (InterruptedException ie) {
.....
}
....
}
} finally {
lock.unlock(); // 解鎖
}
}
3) Semaphore
Semaphore(信號量)是 Java 并發包中用于 控制并發訪問資源數量 的同步工具,他的核心機制
許可證模型:通過計數器(permits)表示可用資源數量,線程需獲取許可證(acquire())才能訪問資源,釋放時歸還許可證(release()
線程協作:當許可證耗盡時,新線程進入等待隊列,資源釋放后按策略(公平/非公平)喚醒等待線程
底層實現:基于 AbstractQueuedSynchronizer(AQS)的共享模式,通過 state 字段記錄可用許可證數量
核心 API 與參數:
| 方法/參數 | 作用 |
|---|---|
Semaphore(int permits) |
初始化信號量,指定最大并發訪問數(許可證總數) |
Semaphore(int permits, boolean fair) |
設置公平模式(true 按請求順序分配許可證) |
acquire() |
獲取許可證(阻塞直到可用) |
release() |
釋放許可證(喚醒等待線程) |
tryAcquire() |
非阻塞嘗試獲取許可證,立即返回結果 |
availablePermits() |
查詢當前可用許可證數量 |
看了出來,好像有那么個限流的意思吼,所以它的應用場景,我們可以用它
資源池管理:比如數據庫連接池限制最大連接數;限流控制:限制接口并發請求線程數;多線程分階段協作:控制同時執行任務的線程數量
下面舉個例子:停車場管理,模擬一個停車場,最多允許5輛車同時停放。車輛(線程)需獲取停車位(許可證)才能進入,離開時釋放許可證。
// 停車場管理,模擬一個停車場,最多允許5輛車同時停放。車輛(線程)需獲取停車位(許可證)才能進入,離開時釋放許可證。
public class SemaphoreTest {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(5);
// 創建幾輛車
new Thread(new Car("邁巴赫1", semaphore)).start();
new Thread(new Car("保時捷2", semaphore)).start();
new Thread(new Car("奔馳3", semaphore)).start();
new Thread(new Car("寶馬4", semaphore)).start();
new Thread(new Car("法拉利5", semaphore)).start();
new Thread(new Car("五菱6", semaphore)).start();
new Thread(new Car("本田7", semaphore)).start();
}
static class Car implements Runnable {
private final String name;
private final Semaphore semaphore;
public Car(String name, Semaphore semaphore) {
this.name = name;
this.semaphore = semaphore;
}
@Override
public void run() {
try {
System.out.println("car " + Thread.currentThread().getId() + ":" + name + " 獲取停車位中~~~");
semaphore.acquire();
System.out.println("car " + Thread.currentThread().getId() + ":" + name + " 停車了");
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
System.out.println("car " + Thread.currentThread().getId() + ":" + name + " 離開車位");
semaphore.release();
}
}
}
}
底層原理:
// 默認非公平鎖,初始化內部同步器
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
//
Sync(int permits) {
setState(permits); // 設置state
}
// 調用acquire時【嘗試將state-1】
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
// 實際上是
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires; // 嘗試減1
if (remaining < 0 ||
compareAndSetState(available, remaining))
// 1.如果小于0,就可以直接返回了
// 2.如果cas設置成功了,也直接返回[這個時候肯定是大于0的嘛]--那線程就等待去吧
return remaining;
}
}
// release【嘗試將state+1】
略過了。。讀者自行查看把
了解到上面三個工具類的實現,讀者可以自己實現上面三個類嗎?實際上通俗說就是加減state,state為正數就等待著,小于等于0就喚醒所有的等待線程了
③CompletableFuture
優雅的任務編排工具!由于這個工具用法很多,我這里只給出部分場景及使用CompletableFuture解決的方案
場景一:查詢A庫,查詢B庫,然后匯總結果
public class Test1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1.線程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(4, 10, 2,
TimeUnit.SECONDS, new LinkedBlockingQueue<>());
long start = System.currentTimeMillis();
// 第二個參數是可選的,我這里加上了線程池
CompletableFuture<String> futureA = CompletableFuture.supplyAsync(FutureJdk8Tools::queryA, pool);
CompletableFuture<String> futureB = CompletableFuture.supplyAsync(FutureJdk8Tools::queryB, pool);
// 2.合并兩個future
CompletableFuture<String> res = futureB
.thenCombine(futureA, (b, a) -> "A庫" + a + "--B庫" + b) // 合并兩個future的結果
.exceptionally(e -> "出現異常了"); // 處理異常
String resStr = res.get();
System.out.println("【匯總結果】" + resStr);
long end = System.currentTimeMillis();
System.out.println("耗時:" + (end - start) + "毫秒");
pool.shutdown();
}
public static String queryA() {
System.out.println(Thread.currentThread().getName() + "正在查詢A庫");
try {
Thread.sleep(1500);
// int a = 1 / 0; // 模擬一個異常
} catch (InterruptedException e) {throw new RuntimeException(e);}
System.out.println(Thread.currentThread().getName() + "查詢A庫 ok");
return "A庫信息";
}
public static String queryB() {
System.out.println(Thread.currentThread().getName() + "正在查詢B庫");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {throw new RuntimeException(e);}
System.out.println(Thread.currentThread().getName() + "查詢B庫 ok");
return "B庫信息";
}
}
supplyAsync: 執行任務,支持返回值; 當然有runAsync:執行任務,沒有返回值;
thenCombine:會將兩個任務的執行結果作為方法入參,傳遞到指定方法中,且有返回值;
當出現異常時,exceptionally 中會捕獲該異常
那么,如果不是兩個庫呢?比如說是n個庫
//====================== 查詢多個庫匯總結果
public static void queryTotal2() throws Exception {
// 1.線程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(5, 10, 2,
TimeUnit.SECONDS, new LinkedBlockingQueue<>());
ThreadPoolExecutor pool2 = new ThreadPoolExecutor(5, 10, 2,
TimeUnit.SECONDS, new LinkedBlockingQueue<>());
List<String> tasks = Arrays.asList("A庫:1000", "B庫:2000", "C庫:3000", "D庫:1500");
// 構建任務列表
List<CompletableFuture<Integer>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> queryDataBase(task), pool))
.collect(Collectors.toList());
// allOf返回這個CompletableFuture<Void>
CompletableFuture<List<Integer>> result = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
//thenApplyAsync()用于串行化另一個CompletableFuture,將任務提交到獨立線程池執行,避免阻塞當前線程鏈
//接收前序任務的結果作為輸入,返回新的 CompletableFuture 對象
.thenApplyAsync(
v -> // v: Void
futures.stream()
.mapToInt(f -> {
try {
return f.get();
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}) // intStream
.boxed() // 需要變成包裝類
.collect(Collectors.toList())
, pool2);
List<Integer> integers = result.get();
//[1000, 2000, 3000, 1500]
System.out.println(integers);
pool.shutdown();
pool2.shutdown();
}
public static Integer queryDataBase( String db ) {
String[] s1 = db.split(":");
String dbName = s1[0];
int time = Integer.parseInt(s1[1]);
try {
System.out.println(Thread.currentThread().getName() + "正在查詢" + dbName);
Thread.sleep(time);
System.out.println(Thread.currentThread().getName() + "查詢" + dbName + " ok");
} catch (InterruptedException e) {throw new RuntimeException(e);}
return time;
}
場景二:貨比多家,查詢多家商店同一商品價格,返回最便宜的
//====================== 貨比多家
public static void queryHuoBi() throws Exception {
List<String> tasks = Arrays.asList("A店:100", "B店:200", "C店:300", "D店:50"); // 每個店的價格信息
// 構建任務列表
List<CompletableFuture<Integer>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> taskComputePrice(task)))
.collect(Collectors.toList());
// 等待所有任務完成
CompletableFuture<Void> allFutures = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
allFutures.join();
// 遍歷得到最小值
int minPrice = futures.stream()
.mapToInt(future -> {
try {
return future.get();
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
})
.min()
.orElseThrow(() -> new IllegalStateException("No price found"));
System.out.println("最小價格:" + minPrice);
}
public static int taskComputePrice(String msg ) {
String[] split = msg.split(":");
String store = split[0];
int price = Integer.parseInt(split[1]);
System.out.println(Thread.currentThread().getName() + "正在查詢" + store + "價格");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {throw new RuntimeException(e);}
System.out.println(Thread.currentThread().getName() + "查詢" + store + "價格 ok");
return price;
}
allOf:等待所有任務完成
場景三:在多個網站搜索結果,任一一個返回結果就結束
//====================== 搜索結果
public static void queryWebsite() throws Exception {
List<String> tasks = Arrays.asList("百度:1200", "CSDN:2000", "博客園:1500", "谷歌:3000");
// 構建任務列表
List<CompletableFuture<String>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> searchRes(task)))
.collect(Collectors.toList());
// 等待所有任務完成
CompletableFuture<Object> anyOf = CompletableFuture.anyOf(futures.toArray(new CompletableFuture[0]));
Object result = anyOf.get();
System.out.println(result + "最先返回了結果");
}
public static String searchRes( String webSite ) {
String[] s1 = webSite.split(":");
String webSiteName = s1[0];
int time = Integer.parseInt(s1[1]);
System.out.println(Thread.currentThread().getName() + "正在查詢" + webSite);
try {
Thread.sleep(time);
} catch (InterruptedException e) {throw new RuntimeException(e);}
System.out.println(Thread.currentThread().getName() + "查詢" + webSite + " ok");
return webSiteName;
}
anyOf:只要有一個任務完成
④volatile
在了解這個關鍵字之前,我們需要知道并發編程的三個基本概念:
分別是 原子性、可見性、有序性:
【原子性】:一個操作或者多個操作要么全部執行并且執行的過程不會被任何因素打斷,要么就都不執行
(對于基本數據類型(像 int、long 等),單個變量的讀寫操作通常具有原子性。)
(使用 synchronized 關鍵字:synchronized 關鍵字能夠保證在同一時刻只有一個線程可以執行被它修飾的代碼塊或者方法,從而確保操作的原子性。)
(原子類,例如 AtomicInteger、AtomicLong )
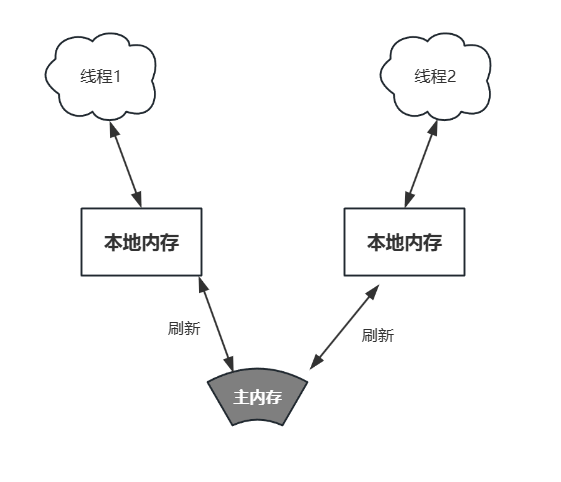
【可見性】:當一個線程修改了共享變量的值時,其他線程能夠立即得知這個修改。
在多線程環境下,每個線程都有自己的工作內存,共享變量會被存儲在主內存中。
線程在操作共享變量時,會先將變量從主內存拷貝到自己的工作內存,操作完成后再將結果寫回主內存。
這就可能導致一個線程對共享變量的修改不能及時被其他線程看到。
【有序性】:程序按照代碼的先后順序執行。
但在 Java 中,為了提高性能,編譯器和處理器可能會對指令進行重排序。
重排序分為三種類型:編譯器重排序、指令級并行重排序和內存系統重排序。
雖然重排序可以提高程序的性能,但在多線程環境下可能會導致程序出現錯誤。
volatile 是 Java 并發編程中用于 保證變量可見性和禁止指令重排序 的關鍵字,它通過內存屏障和禁止指令重排來保證線程間的正確交互, 他可以:
可見性:
- 當一個線程修改了
volatile變量的值,其他線程能立即看到該變化。 - 原理:寫操作時,JVM 會強制將變量值刷新到主內存;讀操作時,直接從主內存讀取最新值(而非線程本地緩存)
禁止指令重排序
- 編譯器和 CPU 可能對指令進行重排序以優化性能,
volatile通過插入內存屏障(Memory Barrier)阻止這種優化。
舉個例子:
int a = 0;
volatile boolean flag = false;
// 寫操作~~~
a = 1;
flag = true; // 寫volatile變量后,a=1的寫入不會被重排序到flag之后
// 讀操作
if (flag) { // 讀volatile變量時,會強制從主內存讀取a的值
System.out.println(a); // 保證輸出1
}
舉個例子:
public class VisibilityProblemDemo {
private static boolean flag = false; // 非volatile變量
// private static volatile boolean flag = false; volatile變量---這個就不會出現問題了
public static void main(String[] args) {
// 線程1:持續檢查flag是否變為 true
new Thread(() -> {
System.out.println("【線程1】開始等待flag變為true...");
while (!flag) {
// 空循環,無其他操作
}
System.out.println("【線程1】檢測到flag已變為 true,退出循環");
}).start();
// 主線程休眠1秒,確保線程1已啟動
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 線程2:修改flag為true
new Thread(() -> {
try {
Thread.sleep(500); // 模擬耗時操作
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true; // 修改共享變量
System.out.println("【線程2】已將flag設為 true");
}).start();
}
}
上述會出現線程無法停止的情況!
但是它不保證原子性!volatile 僅保證單個讀/寫操作的原子性,復合操作(如 i++)不保證原子性。【用synchronized和lock可以保證原子性,那用這倆可以保證可見性嗎?】
public class SyncVolatileCompare {
private boolean flag = false; // 非volatile變量
/*
當線程進入 synchronized 代碼塊時,會清空本地內存中所有共享變量的副本,強制從主內存重新讀取。
當線程退出 synchronized 代碼塊時,會將本地內存中修改的共享變量立即刷新到主內存。
*/
public synchronized void setFlag(boolean flag) {
this.flag = flag;
}
public synchronized boolean getFlag() {
return flag;
}
public static void main(String[] args) throws InterruptedException {
SyncVolatileCompare syncVolatileCompare = new SyncVolatileCompare();
new Thread(() -> {
System.out.println("【線程1】開始等待 flag 變為 true...");
while (!syncVolatileCompare.getFlag()) {
// ...
}
System.out.println("【線程1】檢測到 flag 已變為 true,退出循環");
}).start();
Thread.sleep(1000);
Thread thread = new Thread(() -> {
System.out.println("【線程2】開始修改 flag...");
try {
Thread.sleep(500); // 模擬耗時操作
} catch (InterruptedException e) {
e.printStackTrace();
}
syncVolatileCompare.setFlag(true);
});
thread.start();
}
}
lock也是同理,lock() 方法會清空本地內存,強制從主內存讀取共享變量。unlock() 方法會將修改的共享變量刷新到主內存。
那么,有序性呢?
synchronized 的有序性保證:
synchronized 代碼塊內的代碼不會被編譯器或 CPU 指令重排,因為鎖的獲取和釋放會插入內存屏障(Memory Barrier)。
內存屏障會強制代碼按順序執行,防止重排優化。
Lock 的有序性保證:
Lock 的實現(如 ReentrantLock)在 lock() 和 unlock() 方法中會插入內存屏障,確保鎖內代碼的順序性。
鎖外的代碼可能被重排,但鎖內的代碼有序的。
原子性就不用說了。
3. 虛擬線程簡介
jdk21帶來的重磅內容就是虛擬線程(虛擬線程在jdk19 僅為預覽特性,在jdk21才轉正),它是一種輕量級線程。此前,很多語言都有類似于“虛擬線程”的技術,比如Go、C#、Erlang等,他們稱之為“協程”。
多個虛擬線程共享同一個操作系統的線程,故虛擬線程的數量是可以遠大于操作系統線程的數量的,同時資源占用極低,虛擬線程的棧空間默認KB為單位的;還是由JVM 管理,由 JVM 直接調度,無需綁定操作系統線程,突破傳統線程數量限制(可支持數百萬甚至上億虛擬線程);阻塞操作自動掛起,當虛擬線程執行 I/O(如網絡請求io、文件讀寫io)時,JVM 會將其掛起并釋放底層平臺線程,供其他任務使用。
這么牛逼嗎?下面與普通線程比較一下
| 維度 | 傳統線程(平臺線程) | 虛擬線程 |
|---|---|---|
| 資源占用 | 相比而言:高(依賴 OS 調度) | 極低(JVM 管理) |
| 并發能力 | 受限于 OS 線程數(通常數千) | 支持百萬級并發 |
| 阻塞影響 | 阻塞操作占用 OS 線程,降低吞吐量 | 阻塞時自動釋放線程,提升資源利用率 |
| 適用場景 | CPU 密集型任務 | I/O 密集型任務(如網絡請求、數據庫查詢) |
小小試用一下:
怎么創建虛擬線程呢?
public static void createVirtualThread() {
// 創建虛擬線程 -- 寫法一
Thread.startVirtualThread(() -> System.out.println("Hello, world!"));
// 創建虛擬線程 -- 寫法二
Thread.ofVirtual().start(() -> System.out.println("Hello, world!"));
// 線程工廠創建 -- 寫法三
ThreadFactory factory = Thread.ofVirtual().factory();
factory.newThread(() -> System.out.println("Hello, world!"));
// 線程池
ExecutorService service = Executors.newVirtualThreadPerTaskExecutor();
service.shutdown();
}
// 實際上
public static Builder.OfVirtual ofVirtual() {
return new ThreadBuilders.VirtualThreadBuilder();
}
// 通過VirtualThreadBuilder來創建的
// VirtualThreadBuilder.java 【內部類】
public Thread unstarted(Runnable task) {
Objects.requireNonNull(task);
var thread = newVirtualThread(scheduler, nextThreadName(), characteristics(), task);
UncaughtExceptionHandler uhe = uncaughtExceptionHandler();
if (uhe != null)
thread.uncaughtExceptionHandler(uhe);
return thread;
}
static Thread newVirtualThread(Executor scheduler,
String name,
int characteristics,
Runnable task) {
if (ContinuationSupport.isSupported()) {
// new的VirtualThread
return new VirtualThread(scheduler, name, characteristics, task);
} else {
if (scheduler != null)
throw new UnsupportedOperationException();
return new BoundVirtualThread(name, characteristics, task);
}
}
對比一下普通線程
public class TestVirtualThread {
public static void main(String[] args) {
testNormal();
testVirtual();
}
// 測試虛擬線程
public static void testVirtual() {
try (ExecutorService service = Executors.newVirtualThreadPerTaskExecutor()) {
// 開始時間
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
int finalI = i;
service.submit(() -> {
int t = finalI + 1;
});
}
// 結束時間
long end = System.currentTimeMillis();
System.out.println("虛擬線程耗時:" + (end - start));
} catch (Exception e) {
e.printStackTrace();
}
}
// 測試普通線程
public static void testNormal() {
try {
// 開始時間
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
int finalI = i;
new Thread(() -> {
int t = finalI + 1;
}).start();
}
// 結束時間
long end = System.currentTimeMillis();
System.out.println("普通線程耗時:" + (end - start));
} catch (Exception e){
e.printStackTrace();
}
}
}
/*
普通線程耗時:13989
虛擬線程耗時:389
*/
// 案例二對比
public class VirtualThreadDemo {
public static void main(String[] args) {
// 任務數量
final int TASK_COUNT = 10000;
// 使用普通線程池(固定 100 個線程)
runWithPlatformThreads(TASK_COUNT);
// 使用虛擬線程池
runWithVirtualThreads(TASK_COUNT);
}
// 普通線程池測試
private static void runWithPlatformThreads(int taskCount) {
long start = System.currentTimeMillis();
// 固定線程池(普通線程)
try (ExecutorService executor = Executors.newFixedThreadPool(100)) {
for (int i = 0; i < taskCount; i++) {
executor.submit(() -> {
Thread.sleep(1000); // 模擬 I/O 阻塞
return null;
});
}
} catch (InterruptedException e) {
e.printStackTrace();
}
long duration = System.currentTimeMillis() - start;
System.out.println("[普通線程] 總耗時: " + duration + " ms");
}
// 虛擬線程池測試
private static void runWithVirtualThreads(int taskCount) {
long start = System.currentTimeMillis();
// 虛擬線程池(每個任務一個虛擬線程)
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < taskCount; i++) {
executor.submit(() -> {
Thread.sleep(1000); // 模擬 I/O 阻塞
return null;
});
}
} catch (InterruptedException e) {
e.printStackTrace();
}
long duration = System.currentTimeMillis() - start;
System.out.println("[虛擬線程] 總耗時: " + duration + " ms");
}
}
// 為啥普通線程池不設置1萬個,你這對比不公平。。
虛擬線程限制
- CPU 密集型任務:虛擬線程無法提升計算性能,此時仍需普通線程
- 庫兼容性:部分舊庫可能未適配虛擬線程(如依賴
ThreadLocal的庫)
現在有什么好的虛擬線程應用場景呢?【多IO】
文件讀寫密集的應用(文件io)、微服務調用|數據庫查詢(網絡io)。
end. 參考
- http://www.rzrgm.cn/tuyang1129/p/12670014.html 【博客園 】
- https://blog.csdn.net/chenwendangding/article/details/99065623 【HashMap與ConcurrentHashMap工作原理、區別和總結】
- https://blog.csdn.net/weixin_46119595/article/details/139124887【ConcurrentHashMap 復合操作下丟失原子性】
- https://zhuanlan.zhihu.com/p/680274968 【知乎-】
- https://blog.csdn.net/u012723673/article/details/80682208 【csdn - volatile】
- 【微信公眾號里面的:并發合集】https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkxODI2MDMzMA==&action=getalbum&album_id=2263501677771161601

 浙公網安備 33010602011771號
浙公網安備 33010602011771號