
python技巧31[python文件的encoding和str的decode]
一 python文件的encoding
默認地,python的.py文件以標準的7位ASCII碼存儲,然而如果有的時候用戶需要在.py文件中包含很多的unicode字符,例如.py文件中需要包含中文的字符串,這時可以在.py文件的第一行或第二行增加encoding注釋來將.py文件指定為unicode格式。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
s = "中國" # String in quotes is directly encoded in UTF-8.
但是如果你的py文件是文本文件,且是unicode格式的,不指定# -*- coding: UTF-8 -*-也可以的。
(通過notepad++下的format->encode in utf-8來確保為utf-8)
如下:
print (sys.getdefaultencoding())
mystr = "test unicode 中國"
print (mystr)
還有奇怪的是好像sys.getdefaultencoding()總是返回utf-8,不管文件是ascii還是utf8的。
可以使用下面的設置python文件編碼:
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
二 str的encode
在python3以后的版本中,str默認已經(jīng)為unicode格式。當然也可以使用b''來定義bytes的string。
但是有的時候我們需要對str進行ASCII和Unicode間轉(zhuǎn)化,unicode的str的轉(zhuǎn)化bytes時使用str.encode(),bytes的str轉(zhuǎn)化為unicode時使用str.decode()。
python2和python3中str的比較:
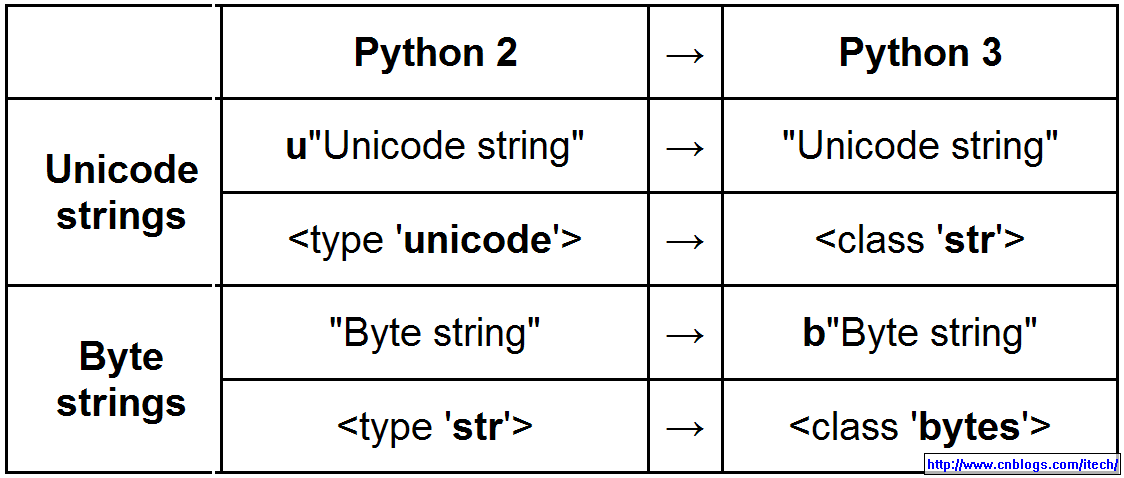
python3中的str的轉(zhuǎn)化函數(shù):

可能需要str的轉(zhuǎn)化的情況:

可能需要str的轉(zhuǎn)化的情況:

完!


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號