
For SALE: State-Action Representation Learning for Deep Reinforcement Learning
發表時間:2023(NeurIPS 2023)
文章要點:這篇文章提出,在強化學習里,對于特征向量表示的任務(low-level states),而不是圖像表示的任務(image-based tasks),做表征學習也是有必要的。作者認為一個任務的困難在于底層的dynamic,而不是狀態空間的大小,對state-action做表征學習可以有效提高采樣效率(difficulty of a task is often defined by the complexity of the underlying dynamical system, rather than the size of the observation space)。作者提出TD7算法,在TD3的基礎上結合了表征學習SALE,Policy Checkpoints,prioritized experience replay(LAP),behavior cloning term for offline RL。
具體的,SALE表示state-action learned embeddings,定義一對encoders (f,g)。f編碼狀態,g編碼狀態和動作
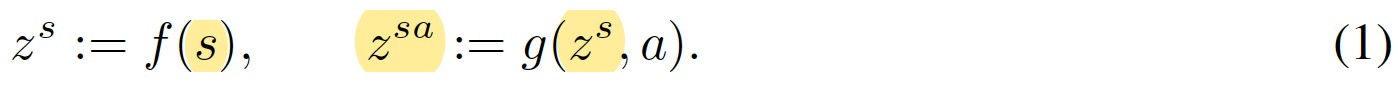
注意這里g的輸入是f的輸出結合動作,而不是原始狀態。訓練的目標是預測下一個狀態的embedding

然后value和policy的輸入就是原始狀態和embedding拼到一起
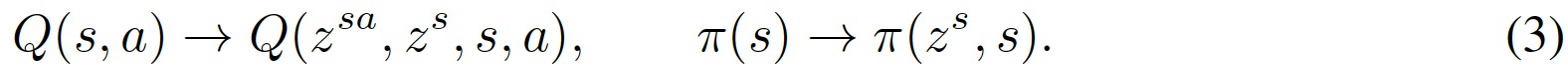
作者解釋,embedding不一定能捕獲所有相關信息,比如reward等,所以還是需要原始狀態(such as features related to the reward, current policy, or task horizon)。
(f, g)的訓練頻率和value,policy一樣,但是訓練value和policy的時候梯度不會傳到(f, g)。
此外,對狀態的embedding以及(s,a)經過線性變換后,過一個歸一化,控制一下量級
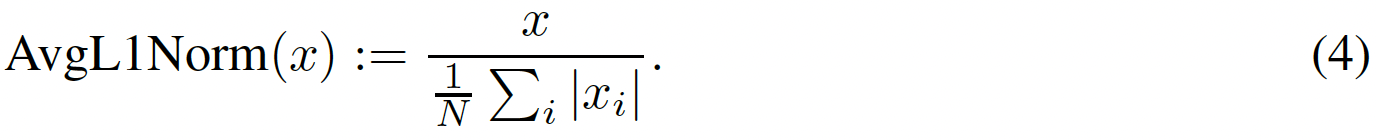
這個歸一化只考慮自身的不同維度,不考慮batch的樣本。不對(s,a)的embedding做歸一化是因為它的學習目標就是s的embedding,間接約束了量級。這樣一來value和policy的輸入變為
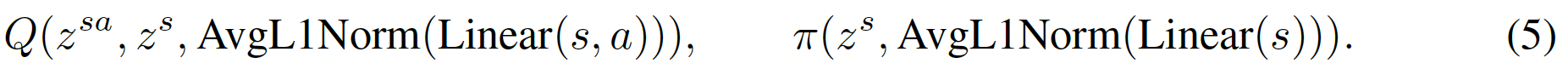
其中這里的\(z^s\)是歸一化過后的。更新變為

為了防止外推誤差(Extrapolation error),計算target的時候clip了一下
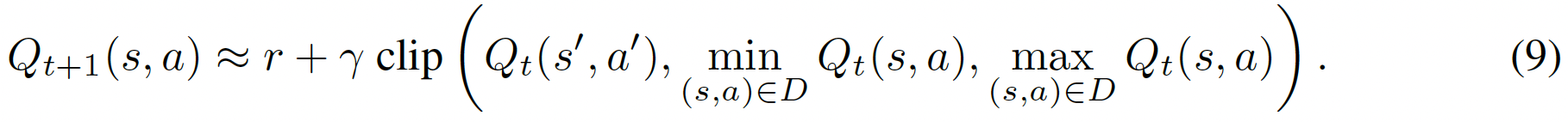
針對前面這些設計,作者做了很多不同的設計對比效果
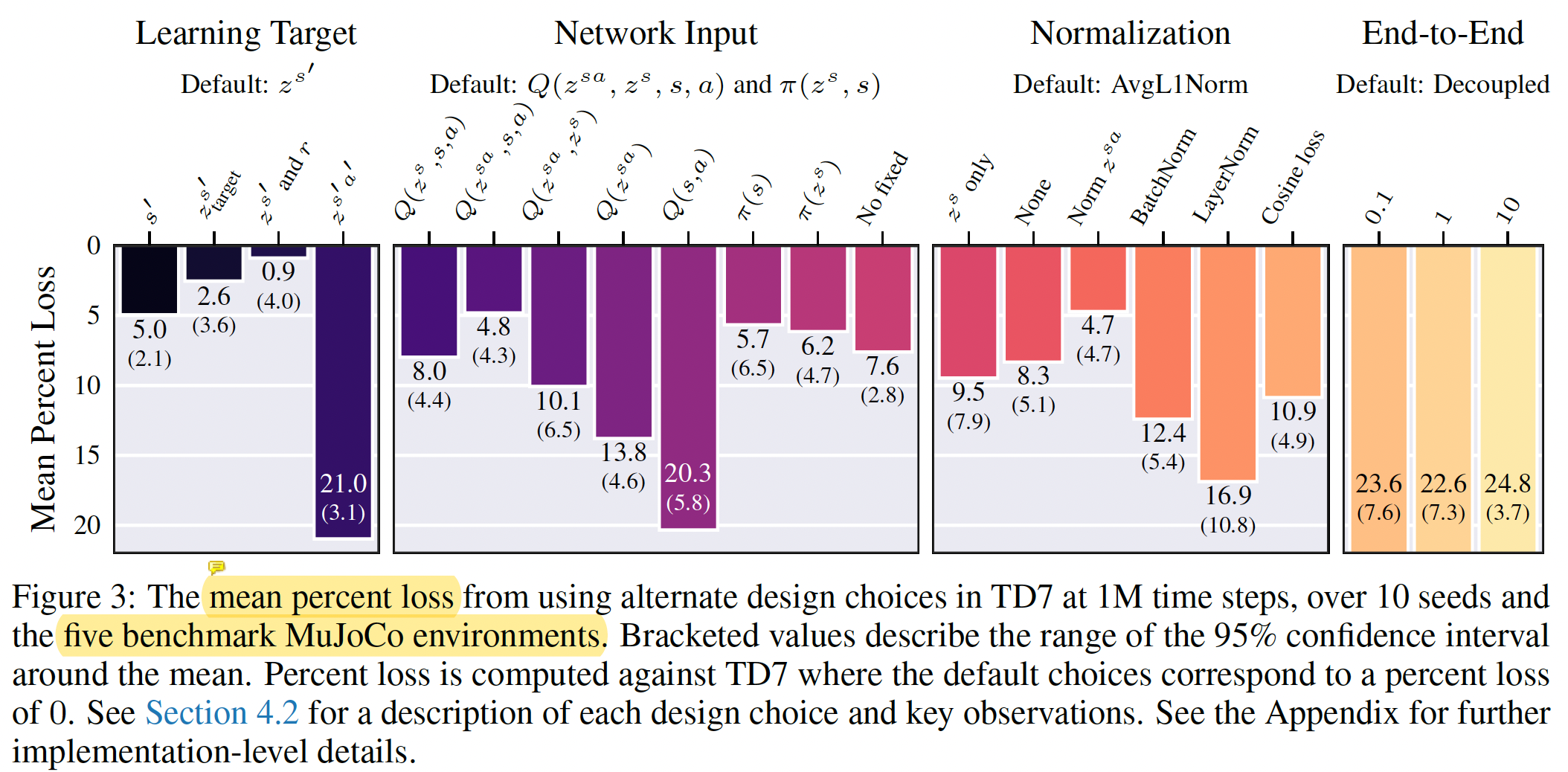
一個有意思的結論是訓練encoder的時候,target用的state的embedding,如果學習目標變為(s,a)的embedding效果會差很多,作者的解釋是因為選取a的policy是不斷變化的,對學習有影響(signal based on the non-stationary policy can harm learning)。
另外,作者End-to-End的實驗表明如果value和policy的梯度傳到encoder,效果會差很多。這和我之前在drq上得到的實驗結果恰好相反(Learning the embeddings end-to-end with the value function performs significantly worse)。
除了SALE,Policy Checkpoints是說off policy的算法都是一個step更新一次,policy在不斷變化。其實更應該用同一個policy交互一些episode,然后根據結果更新checkpoint,用這個checkpoint的結果來報告訓練結果。具體做法是
- Assess the current policy (using training episodes).
- Train the current policy (with a number of time steps equal (or proportional) to the number of time steps viewed during assessment).
- If the current policy outperforms the checkpoint policy, then update the checkpoint policy.
Outperforms的標準用的Minimum而不是mean。這樣就是如果有一局的測試更差了,就直接可以跳過不測了(This approach also means that extra assessment episodes do not need to be wasted on poorly performing policies, since training can resume early if the performance of any episode falls below the checkpoint performance.)。
然后prioritized experience replay用的LAP,一種通過給loss加權來實現PER的方式。

behavior cloning只在offline的時候用
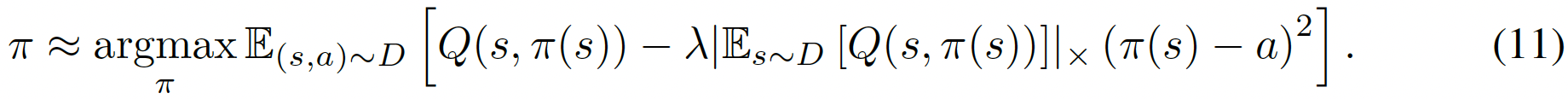
整個算法如下

效果看起來相當猛
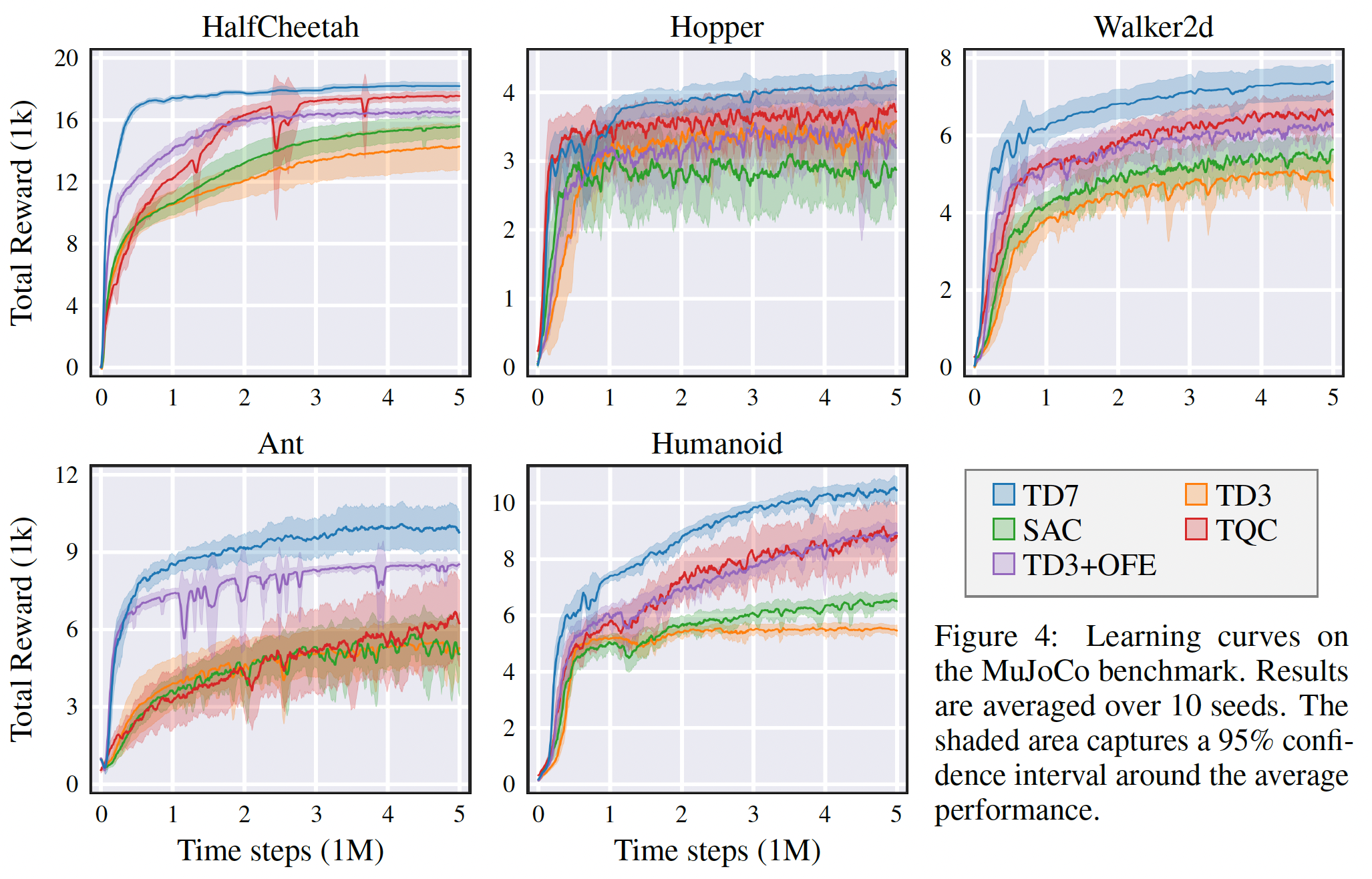
總結:文章主要偏實驗,trick比較多。不過只要效果好就ok。可以試試代碼。
從文章角度來講,這篇文章也沒有任何理論,寫的其實也很直白。個人很喜歡這類風格,但是自己寫成這樣就中不了,總是被問沒有理論,實驗環境太少不夠充分之類的,也是相當難受了。再看這篇文章rebuttal的時候,也被問了很多實驗的結果,比如dmc等等,https://openreview.net/forum?id=xZvGrzRq17,也是很不容易了。只能說,要么就文章寫fancy一點,要么就像這種實驗真的是非常非常充分。
里面可以嘗試借鑒的點:
1.checkpoint的方式做evaluation
2.target update變成了hard update
3.min max的clip的方式再結合double Q,可以嘗試
4.actor和critic實際上多了一層全連接,不知道有沒有影響
疑問:checkpoint這個算不算作弊呢,畢竟別人都是用當前的policy來evaluate,TD7卻用到目前為止最好的policy來evaluate。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號