
Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
發表時間:2024
文章要點:文章對LLM增強強化學習(LLM-enhanced RL)的現有文獻進行了總結。在agent-environment交互的范式下,討論LLM對RL算法的幫助。
文章先給出LLM-enhanced RL的概念:the methods that utilize the multi-modal information processing, generating, reasoning, etc. capabilities of pre-trained, knowledge-inherent AI models to assist the RL paradigm。指的是利用預訓練好的大模型的各種能力來幫助提升強化學習范式的一類方法。LLM-enhanced RL和model-based RL的主要區別在于LLM的model是更general的,包含各種知識的模型,而不是task specific的。
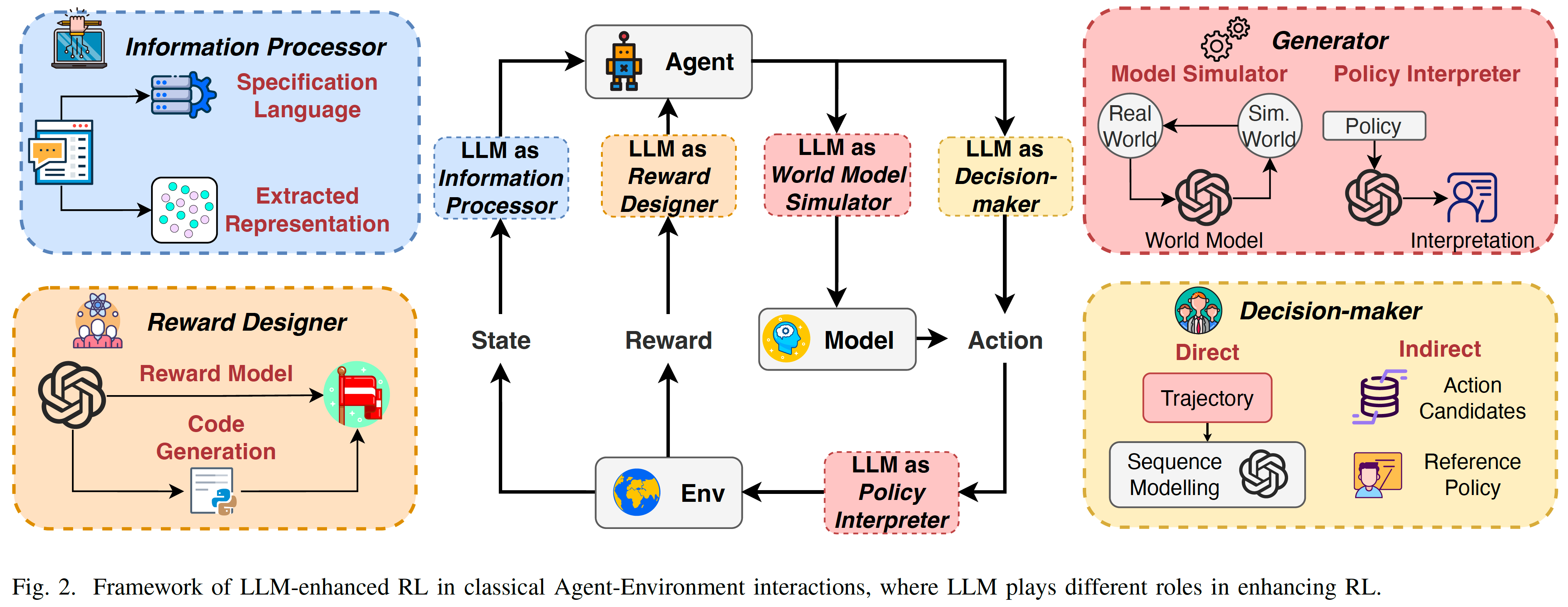
文章將LLM的功能分為信息處理器(information processor)、獎勵設計者(reward designer)、決策者(decision-maker)和生成器(generator),并依次討論每一部分。
LLM AS INFORMATION PROCESSOR
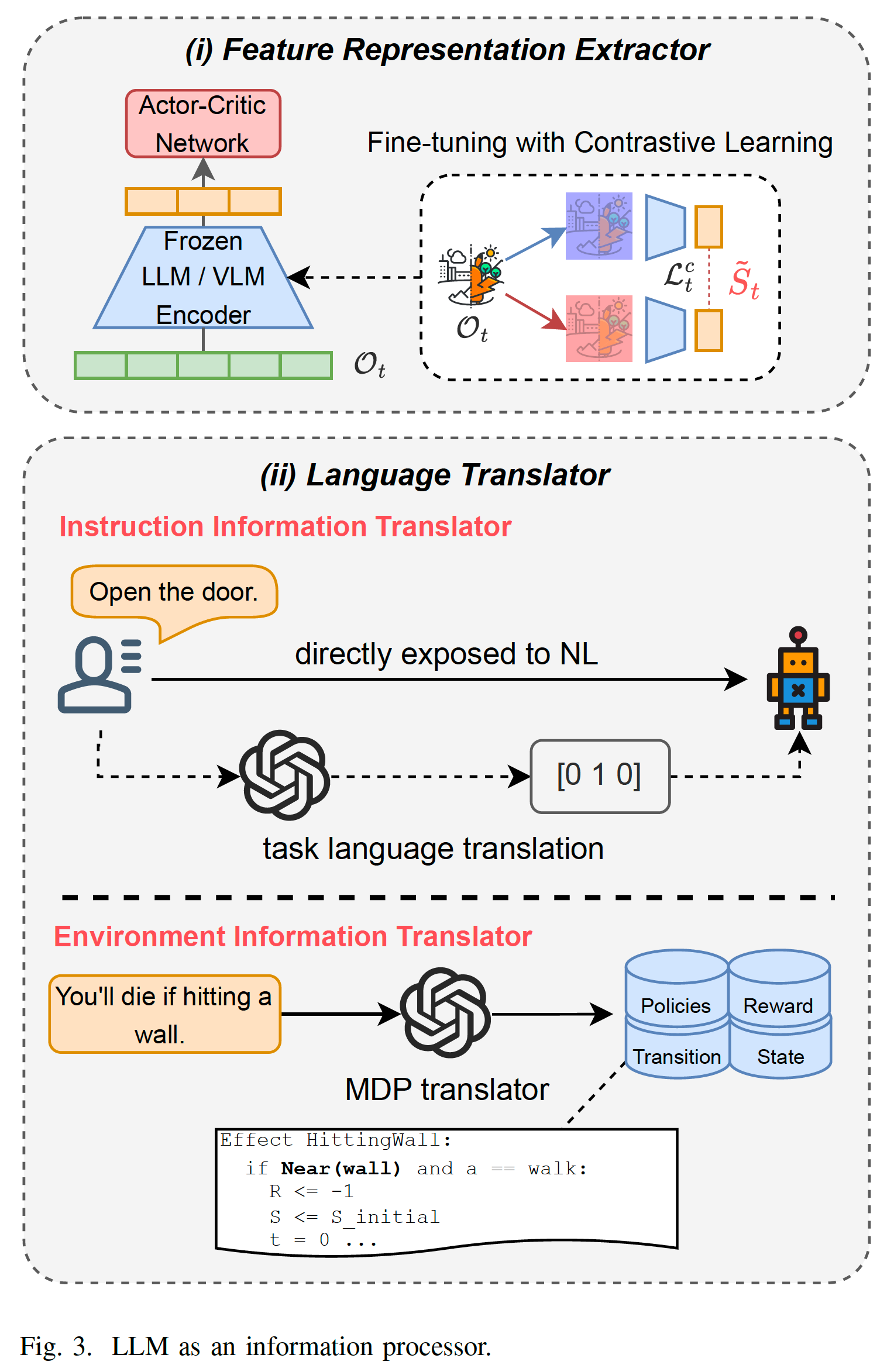
由于RL是端到端的學習范式,需要聯合信息處理和策略學習兩個方面,加大了RL學習的難度。LLM作為信息處理器(information processor)可以幫助RL提取信息,其中一個作用是相當于一個特征提取器(Feature Representation Extractor),將原始輸入轉換成特征向量再給到RL。圖Fig.3(i)所示,LLM作為encoder要么是參數固定不變的(frozen),要么是通過某個損失進一步微調的,例如圖中的contrastive learning。
LLM作為信息處理器的另一個用處是作為翻譯器(Language Translator),LLM處理各種語義信息并總結成結構化的任務相關的信息(LLM transforms the diverse and informal natural language information into formal task-specific information)。Instruction Information Translation針對instruction-following applications,將任務說明規范化。Environment Information Translation針對環境相關的信息,將其規范化。如圖Fig.3(ii)所示,將instruction變成one hot編碼,將環境dynamic信息集成到reward中。
LLM AS INFORMATION PROCESSOR
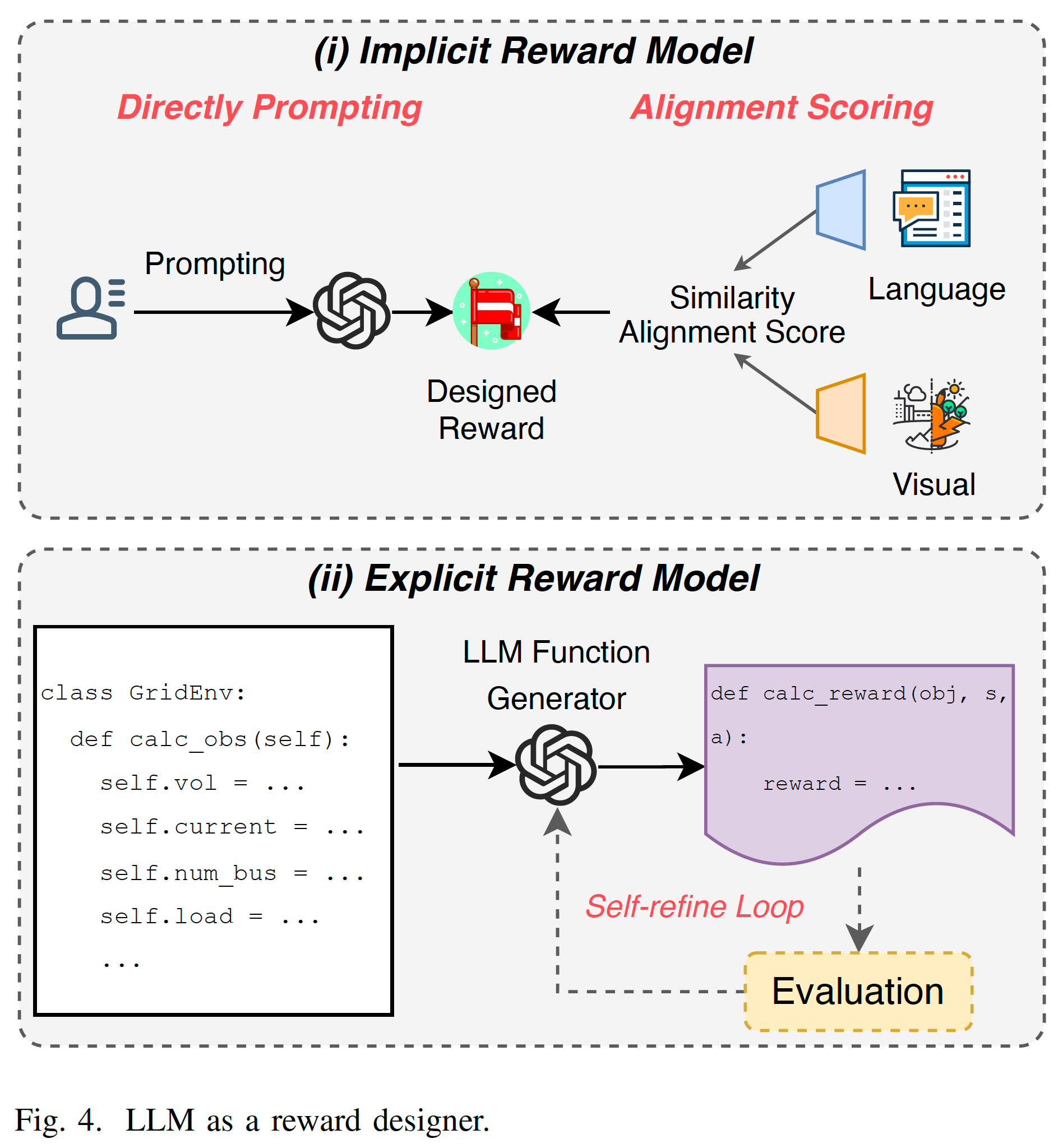
Reward 是RL學習的唯一信號,其重要性不言而喻。但是要想設計一個好的reward function是很困難的。LLM可以幫助設計或者reshape reward,包括隱式和顯式。Implicit Reward Model指通過prompt LLM給出reward,或者通過LLM設計相似度指標來打分。Explicit Reward Model比較好理解,就是讓LLM寫個reward的函數出來。兩種方式如Fig.4.所示。
LLM AS DECISION-MAKER
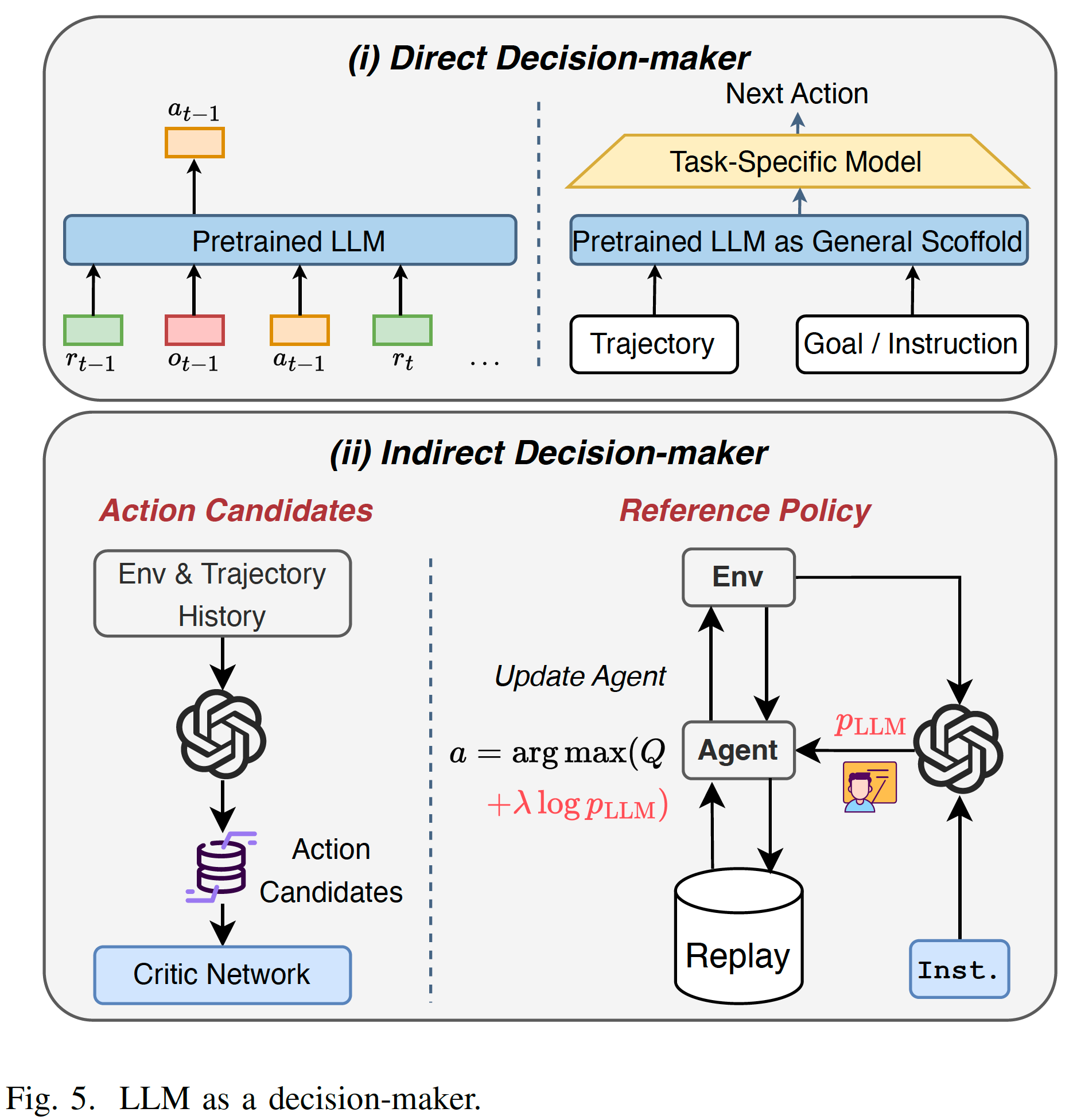
因為RL是decision making的任務,而LLM是基于大量數據訓練的通用模型,本身具有一定的決策能力,所以可以幫助RL決策。分為直接和間接兩種形式。Direct Decision-Maker直接利用模型本身,主要指transformer結構訓練決策模型,這類任務通常不涉及RL,或者說只涉及offline RL。Indirect Decision-Maker中,LLM不是作為最終決策的policy,而是輔助RL的policy做決策。比如幫助篩選出候選動作,或者提供一個參考策略(Reference Policy)或者指導或者正則項。如Fig.5所示。
LLM AS GENERATOR
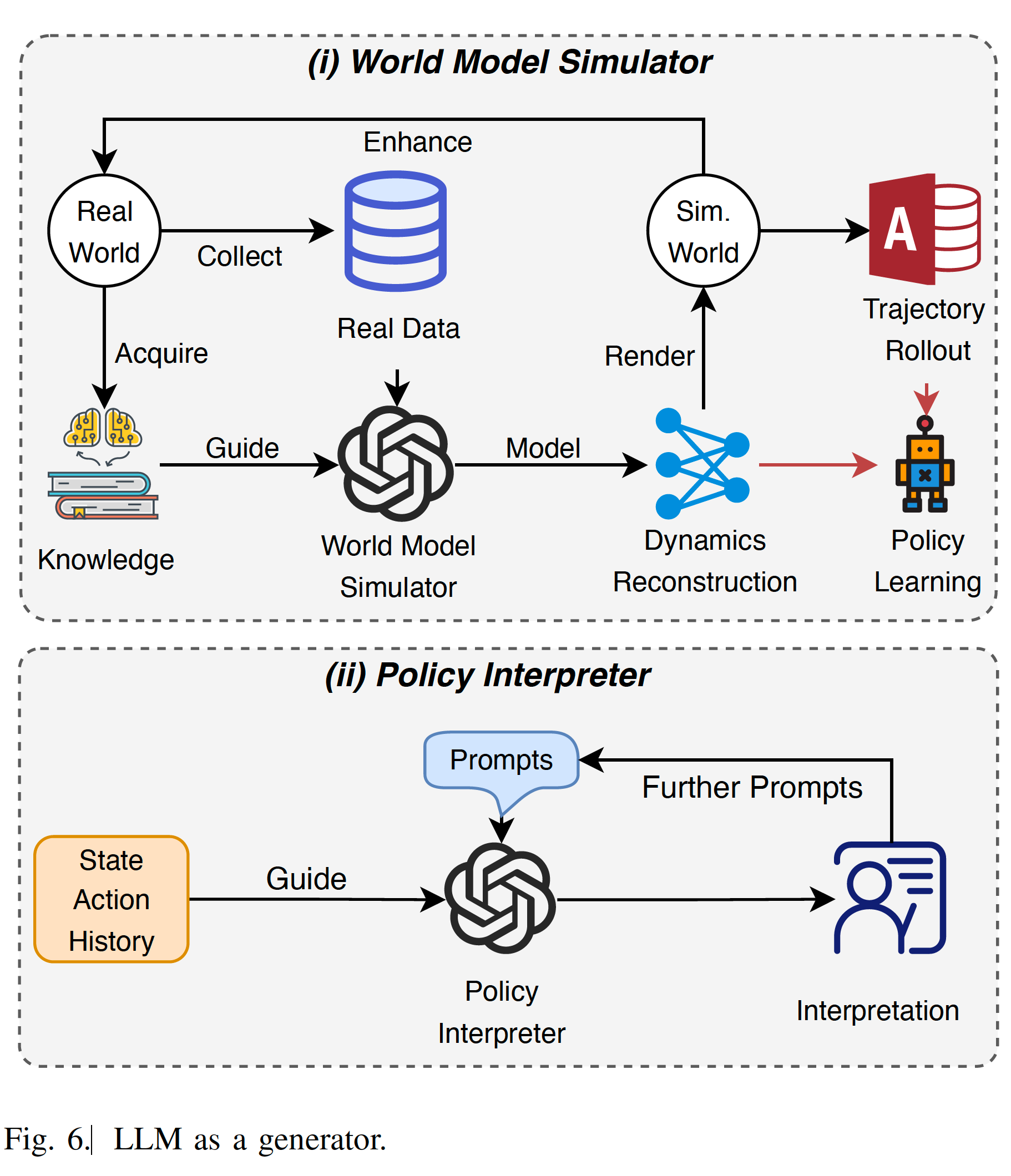
這一部分的作用比較像model-based里的model,不過功能要更豐富一些。文中分為World Model Simulator和Policy Interpreter兩個作用。其中World Model Simulator和model-based RL里的model類似,這里主要指用transformer的結構學一個world model。這個model可以用來做trajectory rollout生成更多的樣本,或者學習dynamic的表征。Policy Interpreter是說LLM可以分析或者解釋一下當前策略行為的意義,方向往可解釋性強化學習靠近(LLMs can be prompts to generate readable interpretations of current policies or situations for humans)。如Fig.6所示。
最后文章總結了應用,機會和挑戰,還是一些比較常見的話題。應用總結了機器人,自動駕駛,能源管理,健康。機會總結了LLM-Enhanced RL下的子問題,比如RL方面的multi-agent RL, safe RL, transfer RL, explainable RL,LLM方面的retrieval-augmented generation (RAG)等工具。這個基本上就是水A+B文章的套路了。挑戰提出了一些潛在的問題,比如LLM-Enhanced RL依賴LLM的能力,以及加入LLM的交互在計算開銷上會大大增加等等。
總結:總結了多個方面的作用,挺全面的。不過他這個分類的方式其實有點奇怪,邏輯不太清晰,可能一種解釋就是RL里面涉及到state,reward,model,action,對應起來就是LLM的四個功能了。
疑問:無。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號