
RETROFORMER: RETROSPECTIVE LARGE LANGUAGE AGENTS WITH POLICY GRADIENT OPTIMIZATION

發表時間:2024(ICLR 2024)
文章要點:文章提出Retroformer,用策略梯度的方式調優prompt,更好的利用環境的reward。大體思路是學習一個retrospective LLM,將之前的軌跡和得分作為輸入,得到一個新的prompt,這個prompt綜合分析了之前的經驗,從而提供一個更好的prompt。然后不斷和環境交互,用PPO訓練retrospective LLM。
具體的,整個架構包括Actor Model,Retrospective Model和Memory Module。
Actor Model是一個固定參數的LLM,用來輸入prompt生成動作。
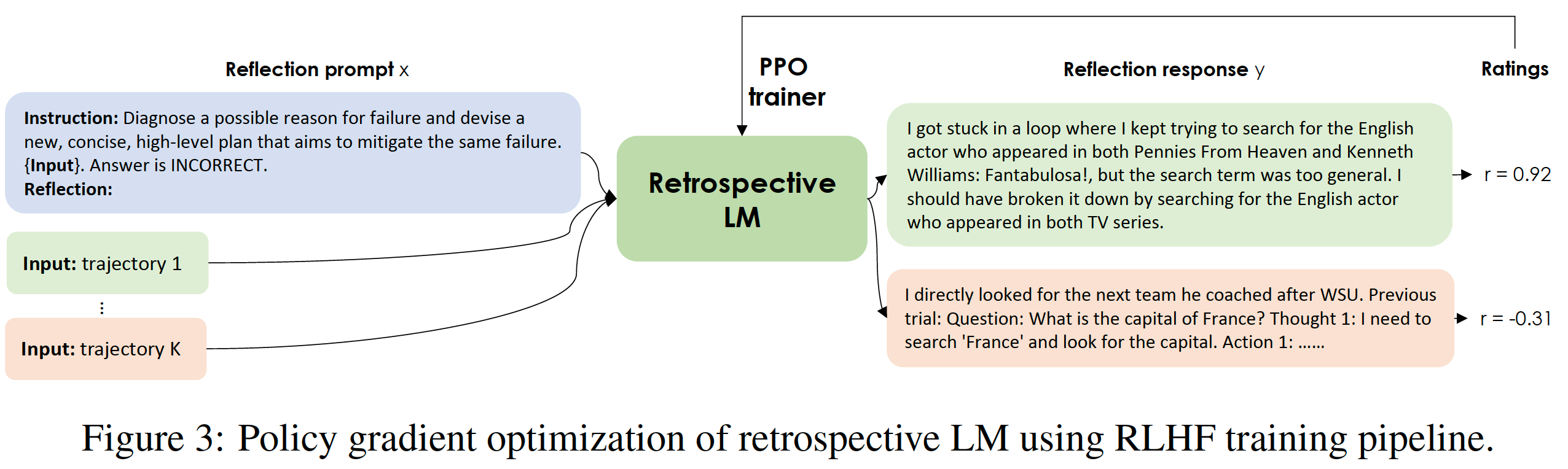
Retrospective Model用來根據之前的經驗生成新的prompt(Its primary function is to produce self-reflections, offering valuable feedback for diagnosing a possible reason for prior failure and devising a new, concise, high-level plan that aims to mitigate same failure.)。
Memory Module存儲長短時記憶。其中Short-term memory指當前episode,Long-term memory指Retrospective Model輸出的總結了之前的失敗經驗的prompt。
Retrospective Model的訓練如下圖所示,每次生成多條軌跡并打分,再用PPO訓練更新參數。
總結:還是有道理的,雖然還是在做prompt,不過總算看到一篇真正用了RL的了。
疑問:無。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號