
State Distribution-aware Sampling for Deep Q-learning
發表時間:2018(Neural Processing Letters 2019)
文章要點:這篇文章認為之前的experience replay的方法比如PER沒有將transition的分布情況考慮在內,于是提出一個新的experience replay的方法,將occurrence frequencies of transitions和uncertainty of state-action values考慮在內。
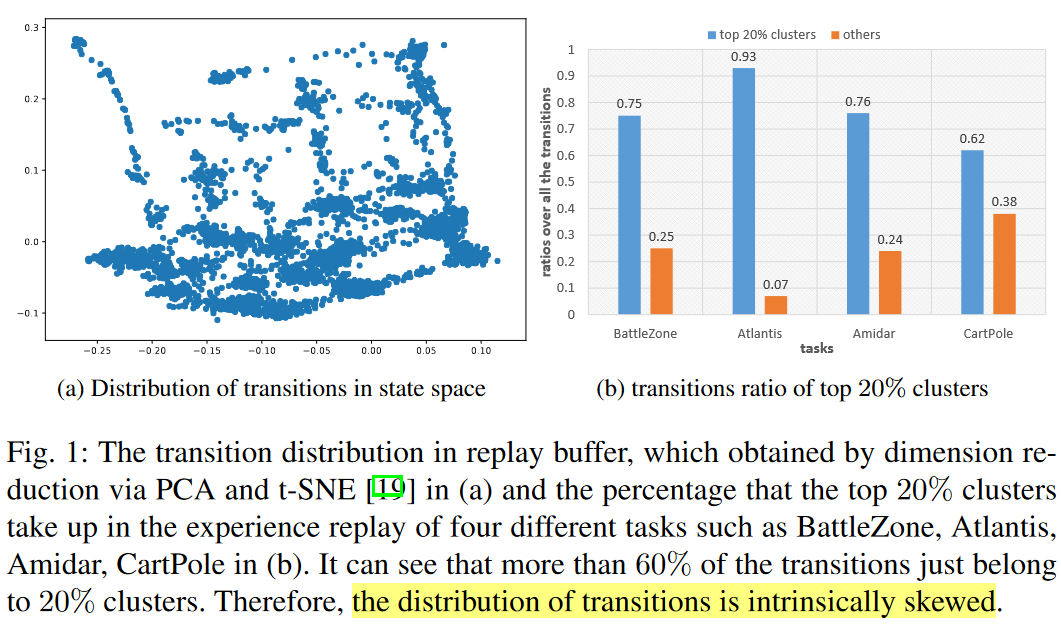
作者的出發點是,agent通常從一些初始狀態開始,所以離這些狀態越近的狀態肯定被探索的越多,這就導致buffer里的狀態是skew的,所以直接均勻采樣更像是occurrence frequencies-based sampling,對于出現少的狀態很少會更新對應的Q(s,a),這就會導致對經常出現的狀態更新過多,出現較少的狀態更新太少。所以作者用靜態哈希表將狀態聚類,然后根據類別和每類的樣本數定義采樣概率

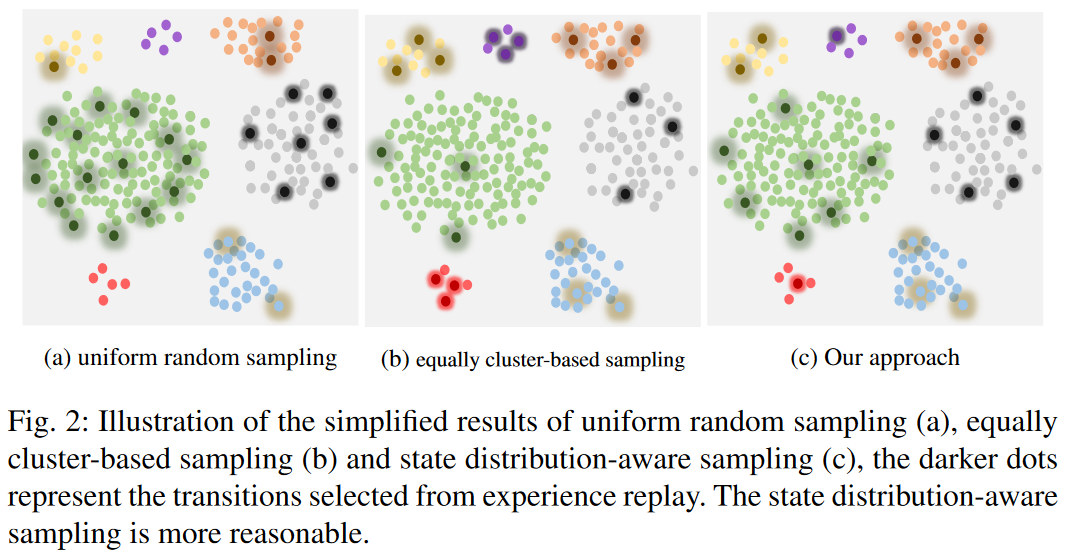
這里第一項就是完全的隨機采樣,第二項里k指k個類別,\(num_i\)表示樣本i所屬類別一共有多少個樣本。所以第二項里,如果某個類別里的樣本很多,那抽到里面某個樣本的可能性就小。下圖描述了采樣的區別,可以看到這種綜合加純隨機,同時也考慮了樣本分布的概率采樣會更加均勻
不過最后效果看起來,沒有很大的提升
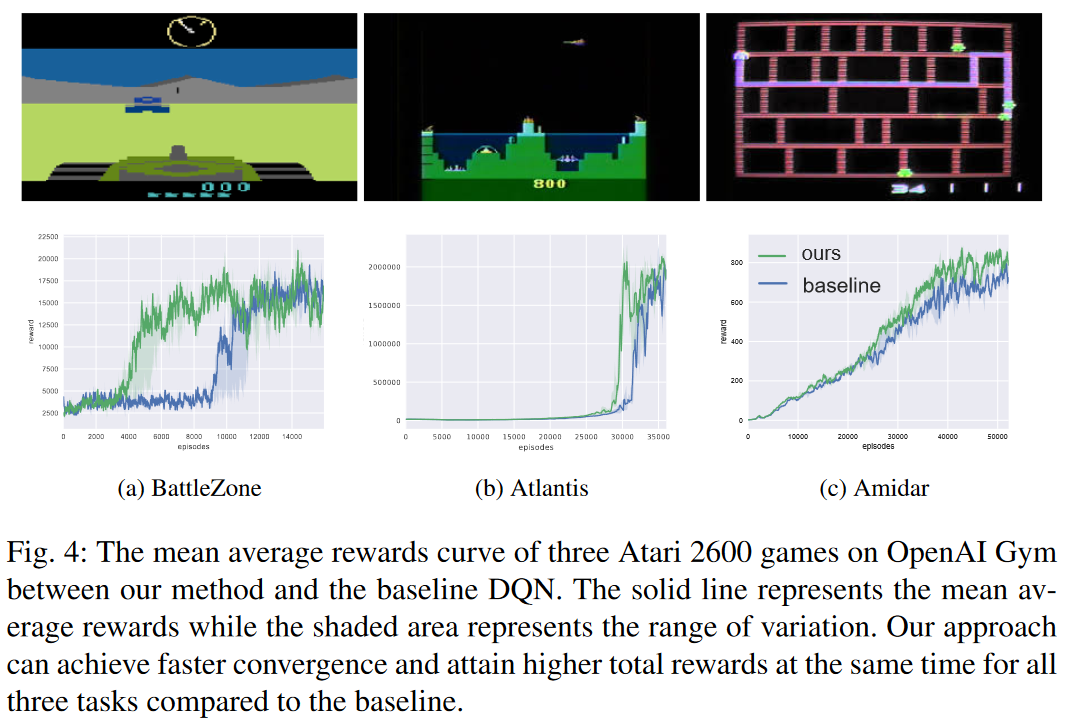
總結:道理上是make sense的,但是結果看起來也不是很明顯。
疑問:是不是其實sampling留給大家做的空間已經不大了啊,看了這么多文章,感覺提升都很小。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號