
Large Batch Experience Replay
發(fā)表時(shí)間:2021(ICML 2022)
文章要點(diǎn):這篇文章把experience replay看做一個(gè)通過(guò)importance sampling來(lái)估計(jì)梯度的問(wèn)題,從理論上推導(dǎo)經(jīng)驗(yàn)回放的最優(yōu)采樣分布,然后提出LaBER (Large Batch Experience Replay)算法來(lái)近似這個(gè)采樣分布。
非均勻采樣mini batch可以看成一個(gè)基于replay buffer的importance sampling的問(wèn)題,梯度估計(jì)的方差越小,收斂就會(huì)越快。PER就可以看做這樣一個(gè)算法(PER is a special case of such approximations in the context of ADP, and propose better sampling schemes)。
作者首先推導(dǎo),更新Q的梯度為

所以這里的關(guān)鍵就是G,作者推出來(lái)最大化收斂速度其實(shí)就是要最小化一個(gè)和G相關(guān)的期望項(xiàng),最后就成了一個(gè)和Q的梯度有關(guān)的一個(gè)權(quán)重

PER有效的原因其實(shí)就可以認(rèn)為TD error其實(shí)就是一個(gè)和Q的梯度有關(guān)的權(quán)重

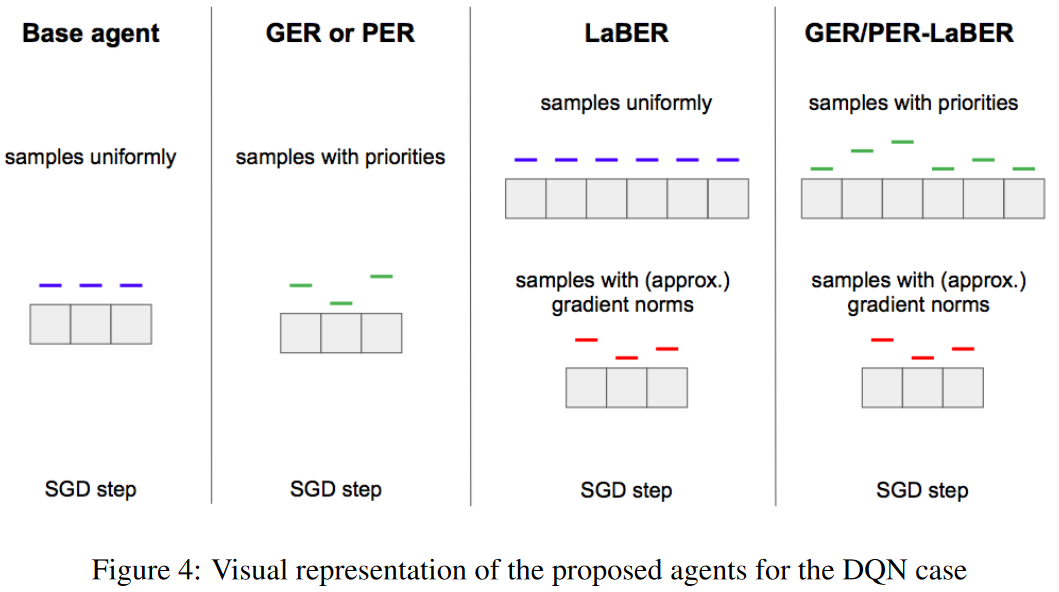
PER里面有幾個(gè)近似,一個(gè)是用TD error來(lái)近似最優(yōu)采樣分布里的Q的梯度,另一個(gè)是PER的估計(jì)是outdated,只有樣本被采到的時(shí)候才會(huì)更新,這樣來(lái)看PER的方差是沒(méi)有被控制住的。于是作者提出兩個(gè)改進(jìn)Gradient Experience Replay(GER),直接用Q的梯度的范數(shù)作為權(quán)重,不過(guò)這個(gè)梯度也是outdated的
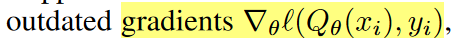
另一個(gè)改進(jìn)是Large Batch Experience Replay(LaBER),先采樣一個(gè)大的batch,計(jì)算importance sampling,再down sample成一個(gè)方差最小的mini batch來(lái)近似最優(yōu)采樣分布。這個(gè)時(shí)候的梯度估計(jì)就是最新的


有了batch之后,更新的加權(quán)作者也試了幾種,
直接歸一化
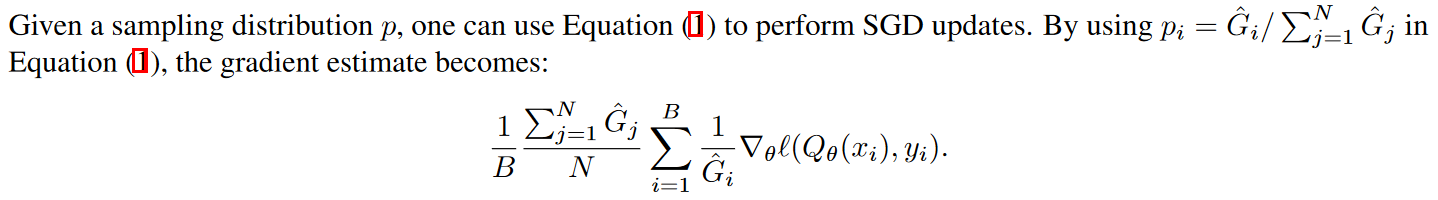
用大batch的mean歸一化
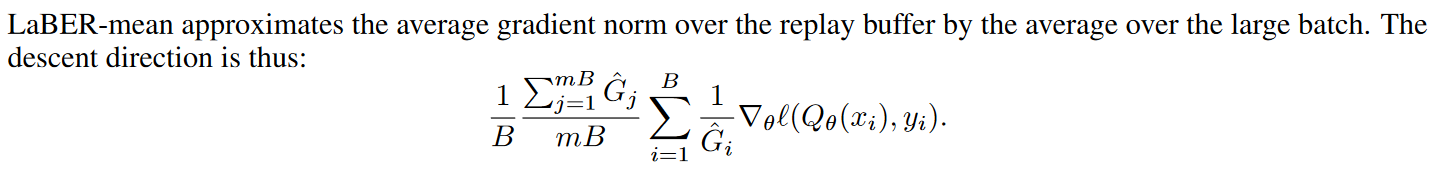
不歸一化,直接全部放到learning rate里
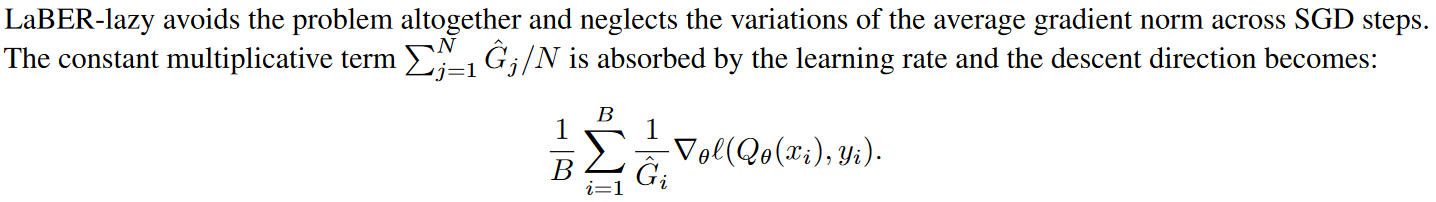
用最大權(quán)重來(lái)歸一化

從效果上看,mean要好些。最后效果如下,
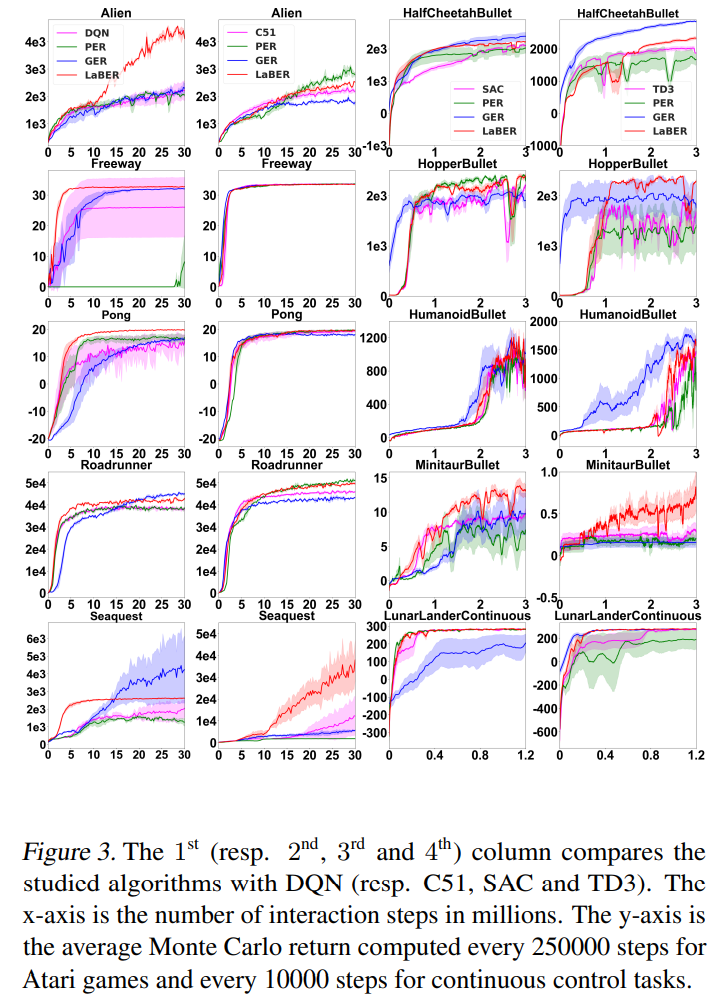
總結(jié):看起來(lái)在某些環(huán)境上是有效果的。作者開源了代碼,可以試試。
疑問(wèn):無(wú)。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)