
Experience Replay with Likelihood-free Importance Weights
發表時間:2020
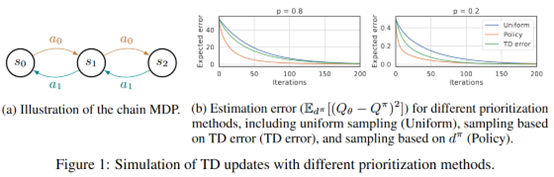
文章要點:這篇文章提出LFIW算法用likelihood作為experience的采樣權重(likelihood-free density ratio estimator),reweight experiences based on their likelihood under the stationary distribution of the current policy,這種方式鼓勵讓經常訪問的狀態有更小的誤差估計(encourage small approximation errors on the value function over frequently encountered states)。
大概思路是維護兩個buffer

Slow replay buffer存所有樣本\(d^D\),fast replay buffer存on-policy的樣本\(d^\pi\).然后采樣基于ratio \(d^\pi (s,a)/d^D (s,a)\),作者如下估計ratio

最后更新為

效果上看,在一些環境上是有效果的
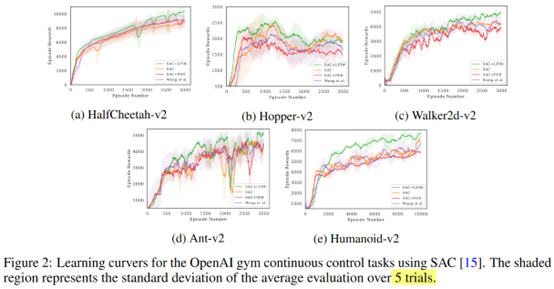
總結:思路就是盡量采on-policy的樣本,給他們賦予更高的權重。
疑問:其實不是很明白為啥這個ratio會好。
圖里看有的效果不如SAC,為啥在table里又是這個方法在所有環境上都好了,統計方法不一樣?

 浙公網安備 33010602011771號
浙公網安備 33010602011771號