
Striving for Simplicity and Performance in Off-Policy DRL: Output Normalization and Non-Uniform Sampling

發表時間:2020(ICML 2020)
文章要點:這篇文章基于SAC做簡單并且有效的改進來提升效果。作者首先認為SAC里面的entropy是為了解決action saturation due to the bounded nature of the action spaces,這個意思就是說動作空間假如約束到[0-1],動作通常會在0和1兩個端點處,而加了entropy可以很好緩解這個問題。然后作者提出了一個streamlined algorithm with a simple normalization scheme or with inverted gradients,可以在沒有entropy的情況下達到SAC一樣的效果。接著又提出了一個新的experience replay方法來重點采recent的樣本(ERE),整個算法叫做Streamlined Off Policy with Emphasizing Recent Experience。
對于Bounded Action Spaces,通常的做法是用clip
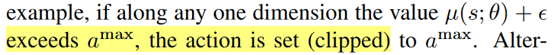
或者是用tanh作為最后一層,然后再放縮
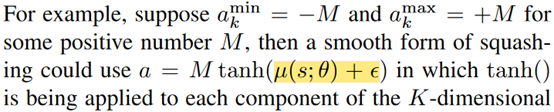
DDPG和TD3用的前者,SAC用的后者。作者想說,這兩種方式都會有可能造成動作太接近兩個端點值,并且由于tanh,如果網絡輸出的μ一開始比較大的話,其實很難再回到一個合理的范圍內

作者把這個問題叫做squashing exploration problem。作者提出了一個簡單的方法來緩解這個問題,就是對輸出的均值\(\mu\)先做歸一化

另一個改進是Inverting Gradients,就是不去歸一化均值,而是在計算梯度的時候根據均值的量級來調整梯度大小

最后一個改進就是Emphasizing Recent Experience,大致思路就是在采batch的時候,第一個batch從所有樣本里采,后面的batch的采樣范圍逐漸縮小到最近的樣本

看起來效果都很一般
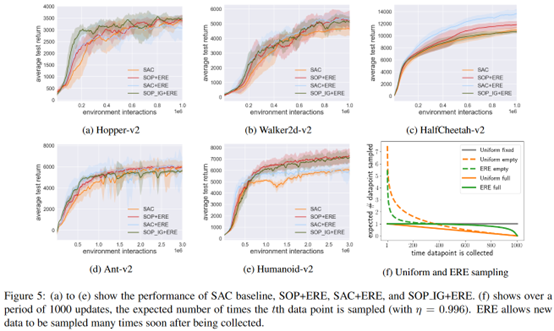
總結:拼湊的痕跡挺重的,而且感覺就沒有啥提升,不知道為啥就能中。
疑問:ERE里面假設會采樣很多個mini-batch,但是同時不是每個step就采一個batch更新嗎,從偽代碼里看的話應該是每個episode更新一下,而不是每個step更新。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號