
Elasticsearch 備份:snapshot 鏡像使用篇
 本文是 ES 備份的鏡像使用篇,主要介紹了 snapshot 的備份恢復原理和使用細節。
本文是 ES 備份的鏡像使用篇,主要介紹了 snapshot 的備份恢復原理和使用細節。
上一篇文章中,我們簡要的列舉了 Elasticsearch 備份 主要的幾個方案,比對了一下各個方案的實現原理、優缺點和適用的場景。現在我們來看看 ES 自帶的鏡像備份方案。
1. 鏡像備份
在開始研究鏡像備份之前,我先拋三個問題:
- ES 鏡像備份是怎么實現增量備份的?
- 歷史鏡像清理維護是怎么做到保存完整數據的?
- 增量恢復要怎么操作的?
2. 鏡像的準備條件
在做鏡像備份之前,先要為 ES 注冊一個鏡像倉庫,即 repository。目前 ES 支持的倉庫類型有:
| Respository | 配置類型 |
|---|---|
| Shared file system | "type" : "fs" |
| Read-only URL | "type": "url" |
| S3 | "type": "s3" |
| HDFS | "type": "hdfs" |
| Azure | "type": "azure" |
| Google Cloud Storage | "type": "gcs" |
注意: S3, HDFS, Azure and GCS 需要安裝相應的插件。
那我們注冊一個 S3 插件并使用 MinIO 來做倉庫進行測試吧。
MinIO 的安裝配置在這里簡略了,從安裝插件開始。
# 插件安裝 在elasticsearch/bin目錄下
./bin/elasticsearch-plugin install repository-s3
# 添加訪問賬號,并reload
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
POST /_nodes/{node_id}/reload_secure_settings
# 注冊 repository
PUT _snapshot/my-minio-repository
{
"type": "s3",
"settings": {
"bucket": "es-bucket",
"endpoint": "http://127.0.0.1:9002",
"compress": true
}
}
3. 備份流程
現在我們來看看整個鏡像備份的流程,在這里我們使用 sample_data_flights 進行備份測試(為了方便測試比對,我們將該索引主分片設置為 1)。
3.1 首次備份
鏡像快照是基于快照開始時間的數據文件備份。
snapshot 備份速度的主要影響參數是 max_snapshot_bytes_per_sec,是單節點數據備份的最快速度,默認為每秒 40mb,可以結合集群磁盤性能在倉庫注冊時做調整。
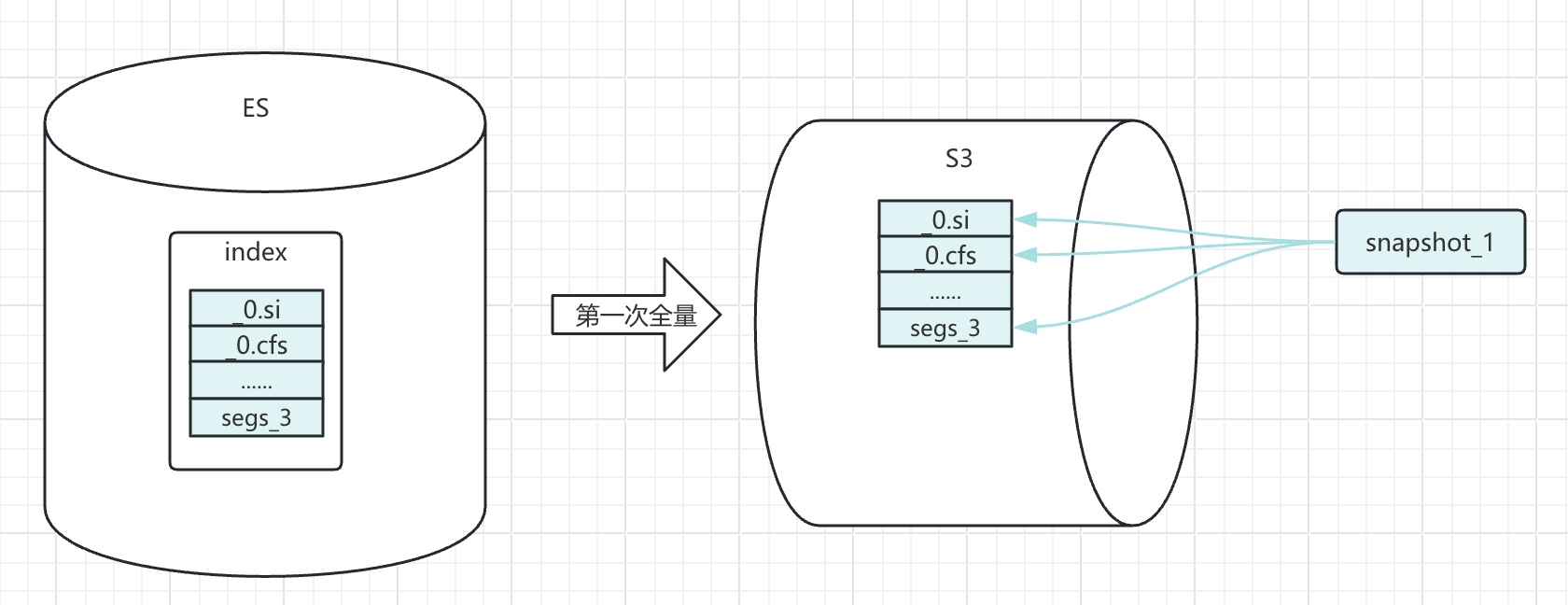
這里就是將 sample_data_flights 數據文件完整的放入 MinIO 存儲中。可以查看系統上的文件進行驗證。
操作命令:
# 第一次鏡像名稱設置為 snapshot_1
PUT _snapshot/minio-repository/snapshot_1
{
"indices": "sample_data_flights",
"ignore_unavailable": true,
"include_global_state": false,
"partial": false
}
在 data 目錄下去尋找索引的 uuid 能找到對應的數據文件
# pwd
/data/nodes/0/indices/cv8DxU5BTfKB5SnI0ubVtQ/0/index
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Aug 17 13:17 write.lock
-rw-rw-r-- 1 infini infini 395 Aug 17 13:25 _0.si
-rw-rw-r-- 1 infini infini 5.7M Aug 17 13:25 _0.cfs
-rw-rw-r-- 1 infini infini 405 Aug 17 13:25 _0.cfe
-rw-rw-r-- 1 infini infini 321 Aug 17 13:30 segments_3
而在 MinIO 中,我們也可以找到大小相應的數據文件,注意一下這里的文件時間是備份的時間點。
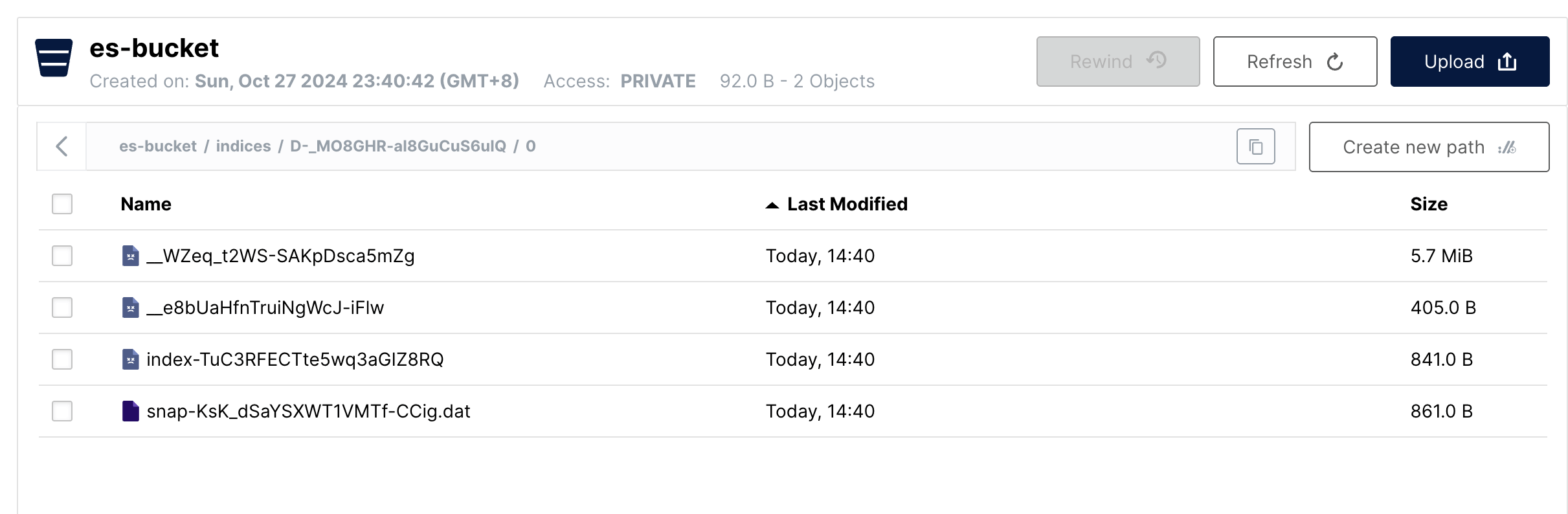
簡化理解,我們把快照備份開始后的數據文件變化認為不會在本次快照備份之內。
3.2 增量備份
在同一備份倉庫中為同一索引創建第二次快照時,Elasticsearch 并不會復制所有數據,而是通過校驗和精準識別出哪些文件發生了變化,僅備份這些增量文件。該機制的巧妙之處在于,每次快照并非簡單追加文件,而是會維護一個獨立的文件關系映射,構成該時間點完整數據所需的全部文件(包括來自之前快照的未變文件),從而保證了每次快照的獨立性和可恢復性。
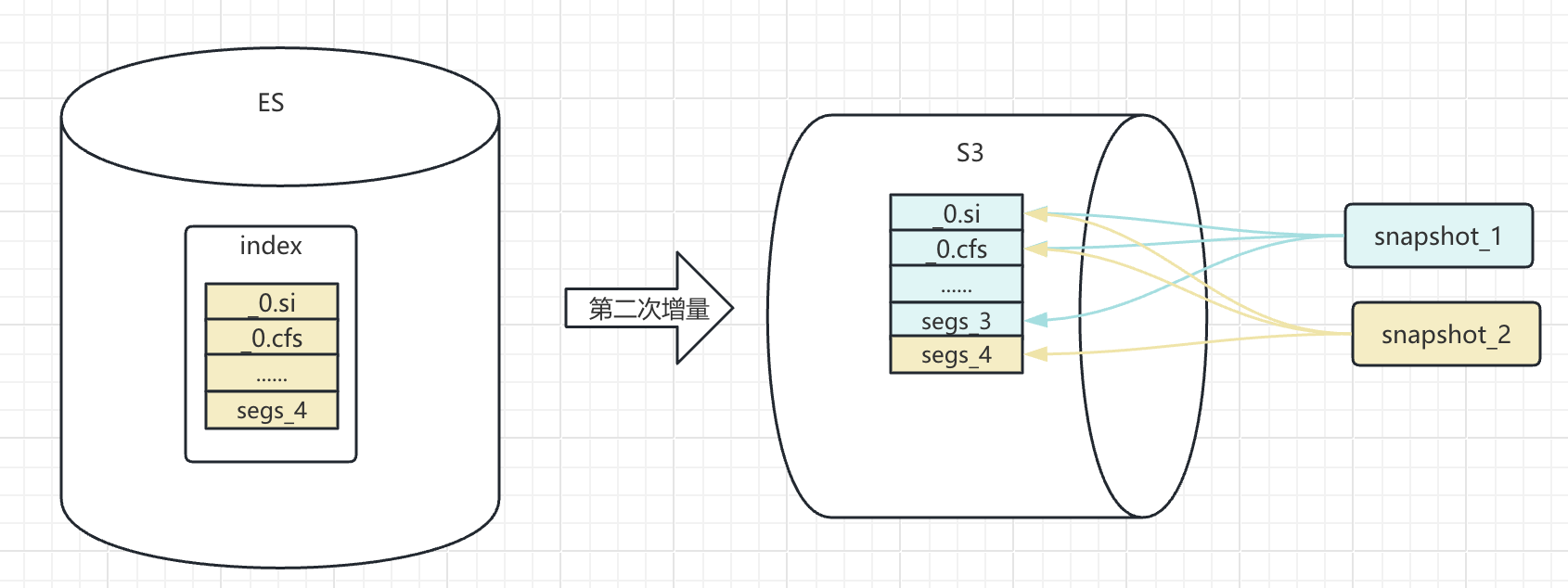
這樣的設計也保證了 snapshot 恢復的效率,減少不必要的文件備份,只備份必要的數據文件。
在增量備份測試中,我們修改一部分數據,并執行 refresh,讓這個索引的數據文件發生改變。
# 標記目標城市為 Sydney的數據 status 為 update
POST sample_data_flights/_update_by_query?refresh=true
{
"script": {
"source": "ctx._source.status = 'update'"
},
"size": 1000,
"query": {"term": {
"DestCityName": {
"value": "Sydney"
}
}
}
}
再去查看數據文件,可以看到已經發生了改變。
注:因為測試環境限制,也為了展示直觀,索引體量較小,不太能復現索引文件部分更新的狀態。
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Aug 17 13:17 write.lock
-rw-rw-r-- 1 infini infini 395 Aug 17 13:25 _0.si
-rw-rw-r-- 1 infini infini 5.7M Aug 17 13:25 _0.cfs
-rw-rw-r-- 1 infini infini 405 Aug 17 13:25 _0.cfe
-rw-rw-r-- 1 infini infini 321 Aug 17 13:30 segments_3
-rw-rw-r-- 1 infini infini 395 Sep 30 14:44 _1.si
-rw-rw-r-- 1 infini infini 132K Sep 30 14:44 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 14:44 _1.cfe
-rw-rw-r-- 1 infini infini 160 Sep 30 14:44 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 623 Sep 30 14:44 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 14:44 _0_1.fnm
可以看到 sample_data_flights 的數據文件有一部分已經變化了。
# 增量備份鏡像名稱設置為 snapshot_2
PUT _snapshot/minio-repository/snapshot_2
{
"indices": "sample_data_flights",
"ignore_unavailable": true,
"include_global_state": false,
"partial": false
}
那么在 MinIO 中,可以看到會有一批新增的文件,而第一次備份的文件也在。

4. 恢復流程
snapshot 備份索引數據是基于文件的,所以恢復的時候,也是基于文件的。
snapshot 恢復速度的主要影響參數是 max_restore_bytes_per_sec,是單節點數據恢復的最快速度,默認為每秒 40mb,可以結合集群磁盤性能在倉庫注冊時做調整。
4.1 全量恢復
和備份一樣,對一個新索引名進行 restore 操作,就是全量恢復。
POST _snapshot/minio-repository/snapshot_1/_restore
{
"indices": "sample_data_flights",
"rename_pattern": "(.+)",
"rename_replacement": "restored-$1"
}
可以看到恢復出來的 restored-sample_data_flights 里面并沒有 status 為 updated 的文檔。
GET restored-sample_data_flights/_count
{
"query": {
"term": {
"status": {
"value": "update"
}
}
}
}
# 結果為 0
{
"count": 0,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
看一下 restored-sample_data_flights 的數據文件。
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:01 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:01 _0.cfe
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:01 _0.cfs
-rw-rw-r-- 1 infini infini 321 Sep 30 15:05 segments_5
基本和 snapshot_1 時候的一致。
4.2 增量恢復
現在,我們來測試增量恢復,snapshot 的增量恢復是不是和增量備份一樣,能自動檢測哪些文件是需要更新的,哪些文件是需要刪除的,來完成“增量”恢復的呢?
我們使用鏡像 snapshot_2 來增量恢復一下。
POST _snapshot/minio-repository/snapshot_2/_restore
{
"indices": "sample_data_flights",
"rename_pattern": "(.+)",
"rename_replacement": "restored-$1"
}
但是恢復失敗了。
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[minio-repository:snapshot_2/XbooG4TDSyubSHqGsoZUQQ] cannot restore index [restored-sample_data_flights] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name"
}
],
"type": "snapshot_restore_exception",
"reason": "[minio-repository:snapshot_2/XbooG4TDSyubSHqGsoZUQQ] cannot restore index [restored-sample_data_flights] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name"
},
"status": 500
}
難道不能增量恢復么?從備份邏輯上,是存在選擇不同版本的快照文件來實現增量恢復操作的可能啊。
技術是使用方法的探索,從報錯內容中,ES 提示可以 close 索引來規避索引同名問題。lets try it!
POST restored-sample_data_flights/_close
POST _snapshot/minio-repository/snapshot_2/_restore
{
"indices": "sample_data_flights",
"rename_pattern": "(.+)",
"rename_replacement": "restored-$1"
}
# 返回內容
# POST restored-sample_data_flights/_close
{
"acknowledged": true,
"shards_acknowledged": true,
"indices": {
"restored-sample_data_flights": {
"closed": true
}
}
}
# POST _snapshot/minio-repository/snapshot_2/_restore
{
"accepted": true
}
這次恢復成功了,那么是不是增量恢復呢?我們查詢一下有沒有 status 為 update 的文檔。
GET restored-sample_data_flights/_count
{
"query": {
"term": {
"status": {
"value": "update"
}
}
}
}
# 結果
{
"count": 269,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
但是,對應的數據文件卻是這樣的:
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:07 _0.cfe
-rw-rw-r-- 1 infini infini 623 Sep 30 15:07 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 15:07 _0_1.fnm
-rw-rw-r-- 1 infini infini 160 Sep 30 15:07 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 132K Sep 30 15:07 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 15:07 _1.cfe
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _1.si
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:07 _0.cfs
-rw-rw-r-- 1 infini infini 461 Sep 30 15:07 segments_6
雖然結果上看,仿佛這并不是一次增量恢復,但是我們去校驗一下兩次恢復共有的 _0.si 文件,會發現它們的 cksum 和 md5sum 是一致的。
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:01 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:01 _0.cfe
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:01 _0.cfs
-rw-rw-r-- 1 infini infini 321 Sep 30 15:05 segments_5
# cksum _0.si;md5sum _0.si;
4212537511 395 _0.si
8f12bb6bb50286aea4691091e8e7e0f4 _0.si
## snapshot_2 后
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:07 _0.cfe
-rw-rw-r-- 1 infini infini 623 Sep 30 15:07 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 15:07 _0_1.fnm
-rw-rw-r-- 1 infini infini 160 Sep 30 15:07 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 132K Sep 30 15:07 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 15:07 _1.cfe
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _1.si
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:07 _0.cfs
-rw-rw-r-- 1 infini infini 461 Sep 30 15:07 segments_6
# cksum _0.si;md5sum _0.si;
4212537511 395 _0.si
8f12bb6bb50286aea4691091e8e7e0f4 _0.si
雖然從源碼角度值得深入剖析一下(源碼研究以后再鴿),但是在這里也可以去簡單高效的佐證這樣的操作是否為增量恢復。
我們可以設計一個大索引去觀測恢復時間,這樣更加直觀明了,因為增量恢復的主要意義就是減少恢復時間。這里使用了一個 4.9g 的不斷寫入的日志類索引進行測試,通過 _snapshot 和 _recovery API 去觀測恢復任務的耗時。
全量備份花費 127885 ms,增量備份花費 2021 ms。全量恢復花費了 127373 ms,增量恢復花費了 2196 ms。
除了簡單的比對恢復時間,我們也可以利用 _recovery API 去查看兩次鏡像恢復的文件細節
# 查看恢復細節命令
GET _recovery?filter_path={索引名}.shards.index.files
# 第一次全量恢復
{
"shards": [
{
"index": {
"files": {
"total": 101,
"reused": 0,
"recovered": 101,
"percent": "100.0%"
}
}
}
]
}
# 第二次增量恢復
{
"shards": [
{
"index": {
"files": {
"total": 104,
"reused": 61,## 這里 ES 標記復用了之前61個文件
"recovered": 43,
"percent": "100.0%"
}
}
}
]
}
5. 鏡像維護清理
鏡像備份的保存也不是無限的,當鏡像數據達到需求所需時間時,也可以進行過期鏡像的清理,以節省存儲空間。
不難看出,鏡像的清理也是要維護好現存鏡像與備份的數據文件之間的關系。鏡像倉庫中清理的文件是保留鏡像不需要的文件。
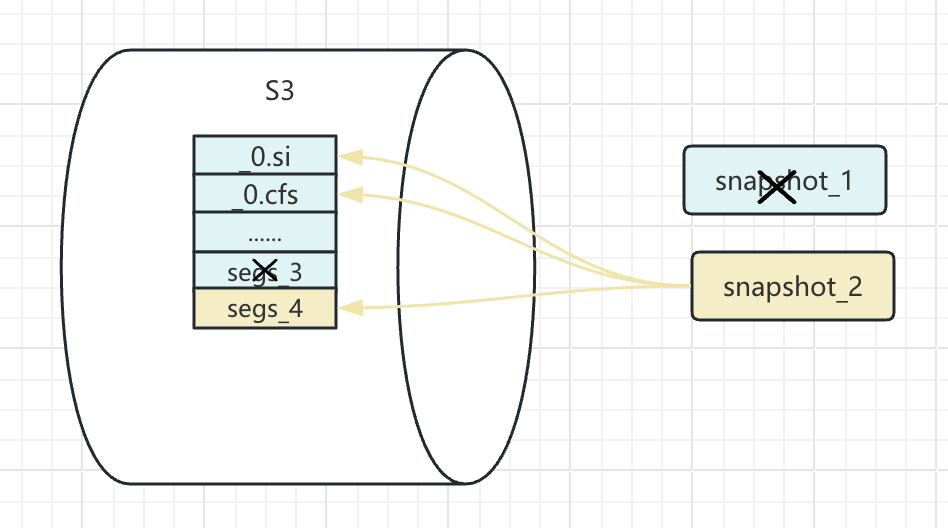
如圖所示,要清理 snapshot_1,只需要清理掉 segs_3 對應的文件,至于其他文件則是保留下來的 snapshot_2 需要的。
而在我們這次測試中,清理掉 snapshot_1 則并不會把主要的數據文件清理掉。
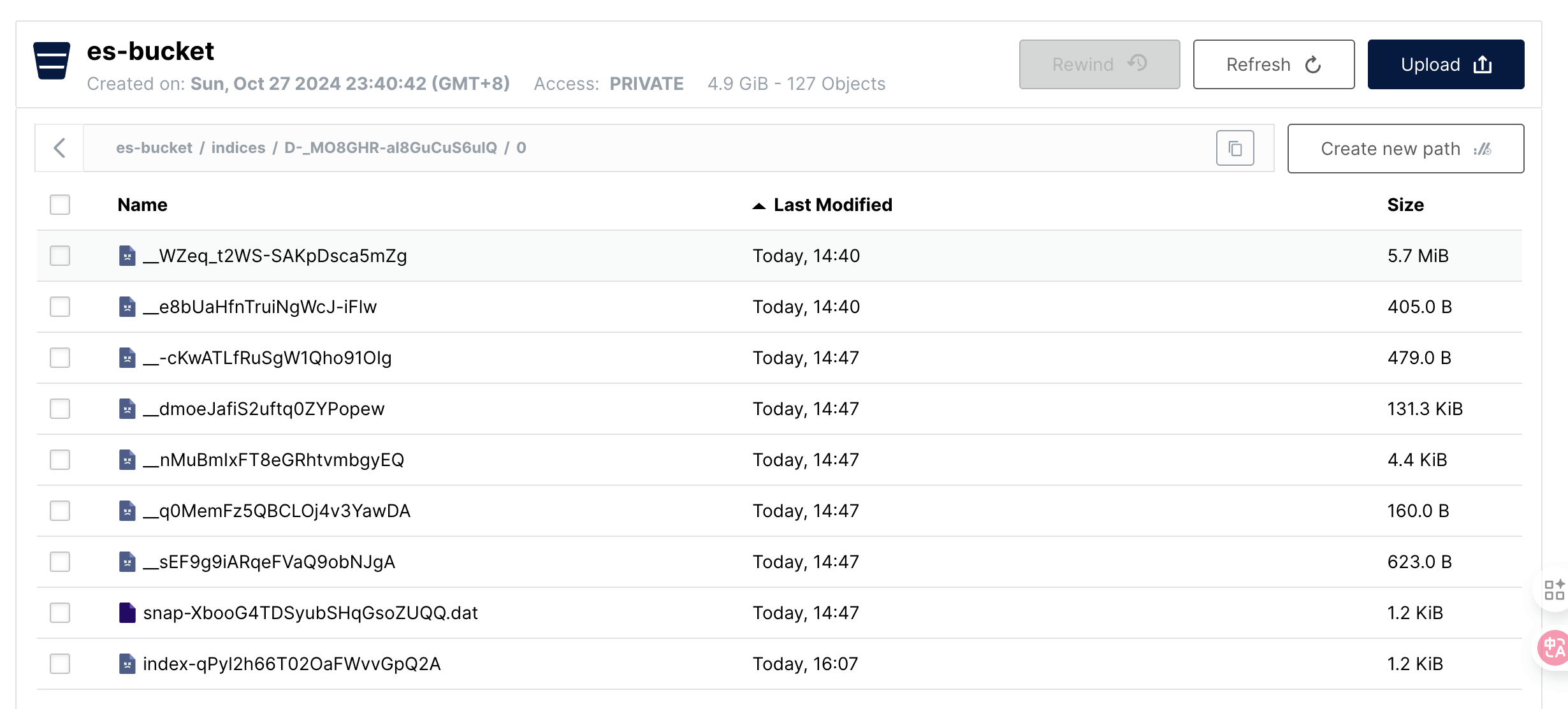
不過可以看到以 snap 開頭的文件清理掉了一個,這應該是 snapshot_1 的一個元信息文件。
6. 小結
至此,我們已經對 Elasticsearch Snapshot 備份的使用細節進行了全面梳理,并實踐了切實可行的增量恢復操作。它作為一個高效可靠的冷備方案,為數據安全提供了堅實保障。
下一篇,我們將一同探索 Elasticsearch 的熱備方案:跨集群復制(CCR)。
特別感謝:社區@張賡 提供的增量驗證方法
作者:金多安,極限科技(INFINI Labs)搜索運維專家,Elastic 認證專家,搜索客社區日報責任編輯。一直從事與搜索運維相關的工作,日常會去挖掘 ES / Lucene 方向的搜索技術原理,保持搜索相關技術發展的關注。
原文:https://infinilabs.cn/blog/2025/es-backup-snapshot/

 浙公網安備 33010602011771號
浙公網安備 33010602011771號