
ES 關于 remote_cluster 的一記小坑
最近有小伙伴找到我們說 Kibana 上添加不了 Remote Cluster,填完信息點 Save 直接跳回原界面了。具體頁面,就和沒添加前一樣。
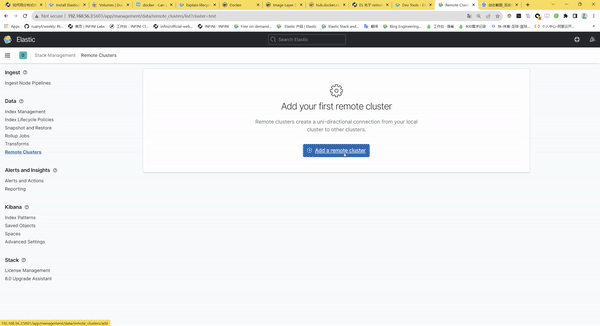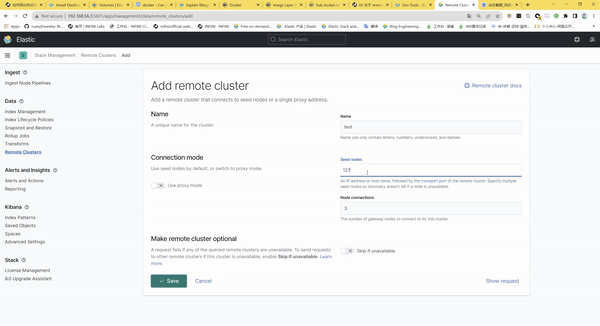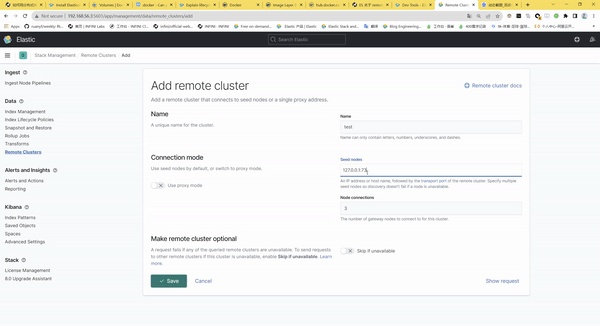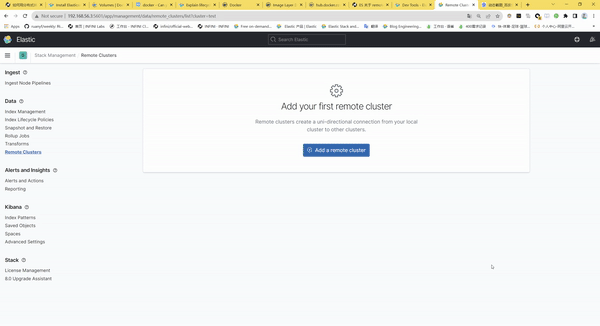
我們和小伙伴雖然隔著網線但還是進行了深入、詳細的交流,梳理出來了如下信息:
- 兩個集群:集群 A 和集群 B ,版本都是 7.10.0 ;
- 集群 A 沒區分節點角色;
- 集群 B 設置了 獨立的 master 節點、coordinator 節點和 data 節點,其中 data 節點還帶 remote_cluster_client 角色;
- 在集群 A 的 Kibana 可以添加 集群 B 為遠程集群;
- 在集群 B 添加 集群 A 就不行,Kibana 跳回之前的頁面;
- 網絡組確認已經放開策略,網絡測試也正常;
翻看了 ES 和 Kibana 的日志, ES 日志中有連接失敗的錯誤信息, Kibana 日志中無對應輸出。
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,093][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,095][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,096][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:51,099][WARN ][o.e.t.RemoteClusterService] [710-1] failed to connect to new remote cluster test within 10s
[2023-09-13T11:39:11,101][WARN ][o.e.t.SniffConnectionStrategy] [710-1] fetching nodes from external cluster [test] failed
org.elasticsearch.transport.ConnectTransportException: [][127.0.0.1:7102] handshake_timeout[30s]
at org.elasticsearch.transport.TransportHandshaker.lambda$sendHandshake$1(TransportHandshaker.java:73) ~[elasticsearch-7.10.2.jar:7.10.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684) ~[elasticsearch-7.10.2.jar:7.10.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) [?:?]
at java.lang.Thread.run(Thread.java:832) [?:?]
已經測試過網絡是通的,開始嘗試把集群 B 的角色配置統統去掉再嘗試。
嘿,添加成功了。
接下來為了找出問題,開始一步一步給每個節點再加回原來的角色。而且如果節點原來沒有 remote_cluster_client 角色,這次也一并加上。
操作過程
- 先從 data 節點開始,恢復角色,嘗試添加遠程集群,失敗。
- 接著 coordinate 節點 , 恢復角色且新增 remote_cluster_client 角色,嘗試添加遠程集群,失敗。
- 最后 master 節點,恢復角色且新增 remote_cluster_client 角色,嘗試添加遠程集群,成功。
最終直到所有節點都有 remote_cluster_client 角色后,才成功添加遠程集群。
結論: ES 集群添加遠程集群所有節點都必須擁有 remote_cluster_client 角色。
事情到這里,似乎沒什么問題。但當我們對這個結論進行檢驗時,又有了新發現。
上面的場景忽視了一個因素 -- Kibana 。于是我們搭建了一個兩個節點的集群,其中節點 A 是全角色節點,節點 B 只是 data 節點。讓 Kibana 分別連接兩個節點進行測試。
驗證結果
- 當 Kibana 連接節點 A 時,可以正常添加。
- Kibana 連接節點 B 時,添加失敗,跳回界面。
結論:ES 集群添加遠程集群時,Kibana 連接的 ES 節點必須擁有 remote_cluster_client 角色。
很顯然,這個結論更合理。
原因分析
我們是通過 Kibana 界面操作去添加遠程集群的, Kibana 連接的節點就被當作 remote_client 。該節點要向遠程集群發起連接并執行相關調用。但這一切有個前提,該節點必須有 remote_cluster_client 角色才能向遠程集群發起連接。

引申
我們的 CCS 操作也必須發送到一個具有 remote_cluster_client 角色的節點,才能成功執行。

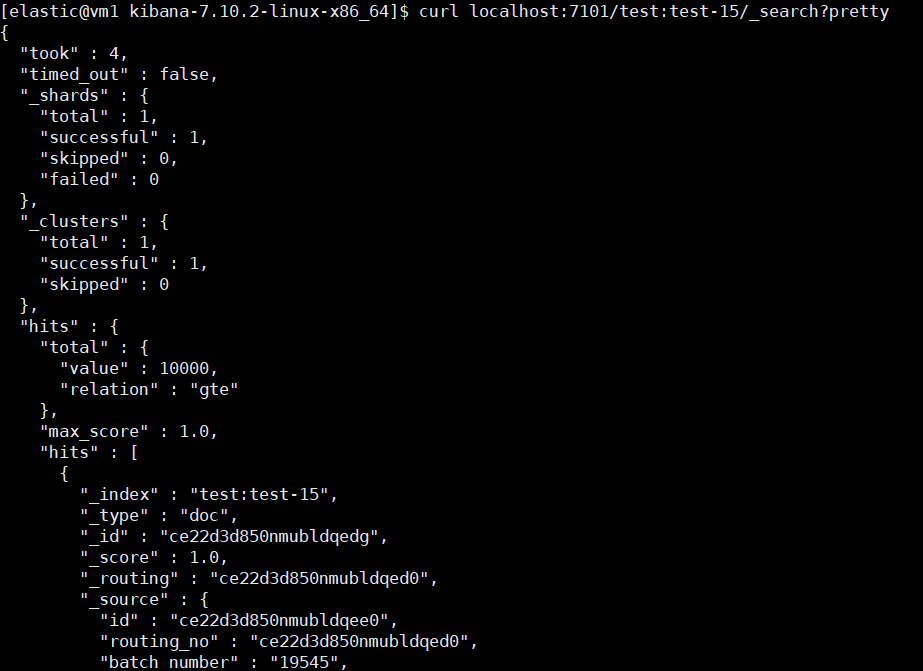
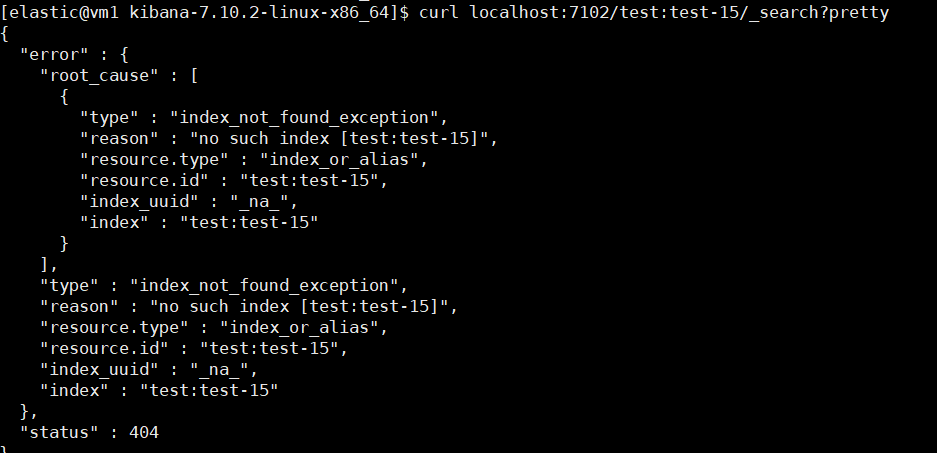
參考連接
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/modules-node.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號