
Redis筆記
Redis入門
概述
Redis是什么?
Redis(Remote Dictionary Server ),即遠(yuǎn)程字典服務(wù),是一個開源的使用ANSI C語言編寫、支持網(wǎng)絡(luò)、可基于內(nèi)存亦可持久化的日志型、Key-Value數(shù)據(jù)庫,并提供多種語言的API。
與memcached一樣,為了保證效率,數(shù)據(jù)都是緩存在內(nèi)存中。區(qū)別的是redis會周期性的把更新的數(shù)據(jù)寫入磁盤或者把修改操作寫入追加的記錄文件,并且在此基礎(chǔ)上實現(xiàn)了master-slave(主從)同步。
Redis能該干什么?
- 內(nèi)存存儲、持久化,內(nèi)存是斷電即失的,所以需要持久化(RDB、AOF)
- 高效率、用于高速緩沖
- 發(fā)布訂閱系統(tǒng)
- 地圖信息分析
- 計時器、計數(shù)器(eg:瀏覽量)
核心特性
- 多樣的數(shù)據(jù)類型
- 持久化
- 集群
- 事務(wù)
基礎(chǔ)知識
Redis是一個字典結(jié)構(gòu)的存儲服務(wù)器,一個Redis實例提供了多個用來存儲數(shù)據(jù)的字典,客戶端可以指定將這數(shù)據(jù)存儲在哪個字典中,這與在一個關(guān)系型數(shù)據(jù)庫實例(以MySQL為例)中可以創(chuàng)建多個數(shù)據(jù)庫類似,可以將其中的每個字典都理解成一個獨立的數(shù)據(jù)庫。
16個數(shù)據(jù)庫分別為:DB 0~DB 15,默認(rèn)使用DB 0 ,可以使用select n切換到DB n,dbsize可以查看當(dāng)前數(shù)據(jù)庫的大小,與key數(shù)量相關(guān)。
127.0.0.1:6379> config get databases # 命令行查看數(shù)據(jù)庫數(shù)量databases
1) "databases"
2) "16"
127.0.0.1:6379> select 8 # 切換數(shù)據(jù)庫 DB 8
OK
127.0.0.1:6379[8]> dbsize # 查看數(shù)據(jù)庫大小
(integer) 0
# 不同數(shù)據(jù)庫之間 數(shù)據(jù)是不能互通的,并且dbsize 是根據(jù)庫中key的個數(shù)。
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> SELECT 8
OK
127.0.0.1:6379[8]> get name # db8中并不能獲取db0中的鍵值對。
(nil)
127.0.0.1:6379[8]> DBSIZE
(integer) 0
127.0.0.1:6379[8]> SELECT 0
OK
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "name"
4) "key:__rand_int__"
5) "myset:__rand_int__"
127.0.0.1:6379> DBSIZE # size和key個數(shù)相關(guān)
(integer) 5
keys * :查看當(dāng)前數(shù)據(jù)庫中所有的key。
flushdb:清空當(dāng)前數(shù)據(jù)庫中的鍵值對。
flushall:清空所有數(shù)據(jù)庫的鍵值對。
keys *這個命令需要慎重使用,如果數(shù)據(jù)庫中的鍵過多可能會造成卡頓,生產(chǎn)環(huán)境中應(yīng)該使用dbsize
保存中文
redis-cli --raw
五大數(shù)據(jù)類型
Redis是一個開源(BSD許可),內(nèi)存存儲的數(shù)據(jù)結(jié)構(gòu)服務(wù)器,可用作數(shù)據(jù)庫,高速緩存和消息隊列代理。它支持字符串、哈希表、列表、集合、有序集合,位圖,hyperloglogs等數(shù)據(jù)類型。內(nèi)置復(fù)制、Lua腳本、LRU收回、事務(wù)以及不同級別磁盤持久化功能,同時通過Redis Sentinel提供高可用,通過Redis Cluster提供自動分區(qū)。
Redis-key
在redis中無論什么數(shù)據(jù)類型,在數(shù)據(jù)庫中都是以key-value形式保存,通過進行對Redis-key的操作,來完成對數(shù)據(jù)庫中數(shù)據(jù)的操作。
下面學(xué)習(xí)的命令:
exists key:判斷鍵是否存在del key:刪除鍵值對move key db:將鍵值對移動到指定數(shù)據(jù)庫expire key second:設(shè)置鍵值對的過期時間type key:查看value的數(shù)據(jù)類型
127.0.0.1:6379> keys * # 查看當(dāng)前數(shù)據(jù)庫所有key
(empty list or set)
127.0.0.1:6379> set name qinjiang # set key
OK
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> move age 1 # 將鍵值對移動到指定數(shù)據(jù)庫
(integer) 1
127.0.0.1:6379> EXISTS age # 判斷鍵是否存在
(integer) 0 # 不存在
127.0.0.1:6379> EXISTS name
(integer) 1 # 存在
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> keys *
1) "age"
127.0.0.1:6379[1]> del age # 刪除鍵值對
(integer) 1 # 刪除個數(shù)
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> EXPIRE age 15 # 設(shè)置鍵值對的過期時間
(integer) 1 # 設(shè)置成功 開始計數(shù)
127.0.0.1:6379> ttl age # 查看key的過期剩余時間
(integer) 13
127.0.0.1:6379> ttl age
(integer) 11
127.0.0.1:6379> ttl age
(integer) 9
127.0.0.1:6379> ttl age
(integer) -2 # -2 表示key過期,-1表示key未設(shè)置過期時間
127.0.0.1:6379> get age # 過期的key 會被自動delete
(nil)
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> type name # 查看value的數(shù)據(jù)類型
string
關(guān)于TTL命令
Redis的key,通過TTL命令返回key的過期時間,一般來說有3種:
- 當(dāng)前key沒有設(shè)置過期時間,所以會返回-1.
- 當(dāng)前key有設(shè)置過期時間,而且key已經(jīng)過期,所以會返回-2.
- 當(dāng)前key有設(shè)置過期時間,且key還沒有過期,故會返回key的正常剩余時間.
關(guān)于重命名RENAME和RENAMENX
RENAME key newkey修改 key 的名稱RENAMENX key newkey僅當(dāng) newkey 不存在時,將 key 改名為 newkey 。
更多命令學(xué)習(xí):Redis命令大全
實際上每種數(shù)據(jù)結(jié)構(gòu)都有自己底層的內(nèi)部編碼實現(xiàn),而且是多種實現(xiàn),這樣Redis會在合適的場景選擇合適的內(nèi)部編碼
Redis這樣設(shè)計有兩個好處:
- 可以改進內(nèi)部編碼,而對外的數(shù)據(jù)結(jié)構(gòu)和命令沒有影響,這樣一旦開發(fā)出更優(yōu)秀的內(nèi)部編碼,無需改動外部數(shù)據(jù)結(jié)構(gòu)和命令
- 多種內(nèi)部編碼實現(xiàn)可以在不同場景下發(fā)揮各自的優(yōu)勢
String(字符串)
普通的set、get直接略過。
應(yīng)用場景
1、緩存功能:String字符串是最常用的數(shù)據(jù)類型,不僅僅是redis,各個語言都是最基本類型,因此,利用redis作為緩存,配合其它數(shù)據(jù)庫作為存儲層,利用redis支持高并發(fā)的特點,可以大大加快系統(tǒng)的讀寫速度、以及降低后端數(shù)據(jù)庫的壓力。
2、計數(shù)器:許多系統(tǒng)都會使用redis作為系統(tǒng)的實時計數(shù)器,可以快速實現(xiàn)計數(shù)和查詢的功能。而且最終的數(shù)據(jù)結(jié)果可以按照特定的時間落地到數(shù)據(jù)庫或者其它存儲介質(zhì)當(dāng)中進行永久保存。
3、統(tǒng)計多單位的數(shù)量:eg,uid:gongming count:0 根據(jù)不同的uid更新count數(shù)量。
4、共享用戶session:用戶重新刷新一次界面,可能需要訪問一下數(shù)據(jù)進行重新登錄,或者訪問頁面緩存cookie,這兩種方式做有一定弊端,1)每次都重新登錄效率低下 2)cookie保存在客戶端,有安全隱患。這時可以利用redis將用戶的session集中管理,在這種模式只需要保證redis的高可用,每次用戶session的更新和獲取都可以快速完成。大大提高效率。
| 命令 | 描述 | 示例 |
|---|---|---|
| APPEND key value | 向指定的key的value后追加字符串 | 127.0.0.1:6379> set msg hello OK 127.0.0.1:6379> append msg " world" (integer) 11 127.0.0.1:6379> get msg “hello world” |
| DECR/INCR key | 將指定key的value數(shù)值進行+1/-1(僅對于數(shù)字) | 127.0.0.1:6379> set age 20 OK 127.0.0.1:6379> incr age (integer) 21 127.0.0.1:6379> decr age (integer) 20 |
| INCRBY/DECRBY key n | 按指定的步長對數(shù)值進行加減 | 127.0.0.1:6379> INCRBY age 5 (integer) 25 127.0.0.1:6379> DECRBY age 10 (integer) 15 |
| INCRBYFLOAT key n | 為數(shù)值加上浮點型數(shù)值 | 127.0.0.1:6379> INCRBYFLOAT age 5.2 “20.2” |
| STRLEN key | 獲取key保存值的字符串長度 | 127.0.0.1:6379> get msg “hello world” 127.0.0.1:6379> STRLEN msg (integer) 11 |
| GETRANGE key start end | 按起止位置獲取字符串(閉區(qū)間,起止位置都取) | 127.0.0.1:6379> get msg “hello world” 127.0.0.1:6379> GETRANGE msg 3 9 “l(fā)o worl” |
| SETRANGE key offset value | 用指定的value 替換key中 offset開始的值 | 127.0.0.1:6379> SETRANGE msg 2 hello (integer) 7 127.0.0.1:6379> get msg “tehello” |
| GETSET key value | 將給定 key 的值設(shè)為 value ,并返回 key 的舊值(old value)。 | 127.0.0.1:6379> GETSET msg test “hello world” |
| SETNX key value | 僅當(dāng)key不存在時進行set | 127.0.0.1:6379> SETNX msg test (integer) 0 127.0.0.1:6379> SETNX name sakura (integer) 1 |
| SETEX key seconds value | set 鍵值對并設(shè)置過期時間 | 127.0.0.1:6379> setex name 10 root OK 127.0.0.1:6379> get name (nil) |
| MSET key1 value1 [key2 value2..] | 批量set鍵值對 | 127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3 OK |
| MSETNX key1 value1 [key2 value2..] | 批量設(shè)置鍵值對,僅當(dāng)參數(shù)中所有的key都不存在時執(zhí)行 | 127.0.0.1:6379> MSETNX k1 v1 k4 v4 (integer) 0 |
| MGET key1 [key2..] | 批量獲取多個key保存的值 | 127.0.0.1:6379> MGET k1 k2 k3 1) “v1” 2) “v2” 3) “v3” |
| PSETEX key milliseconds value | 和 SETEX 命令相似,但它以毫秒為單位設(shè)置 key 的生存時間, | |
| getset key value | 如果不存在值,則返回nil,如果存在值,獲取原來的值,并設(shè)置新的值 |
String類似的使用場景:value除了是字符串還可以是數(shù)字,用途舉例:
- 計數(shù)器
- 統(tǒng)計多單位的數(shù)量:uid:123666:follow 0
- 粉絲數(shù)
- 對象存儲緩存
List(列表)
Redis列表是簡單的字符串列表,按照插入順序排序。你可以添加一個元素到列表的頭部(左邊)或者尾部(右邊),一個列表最多可以包含 232 - 1 個元素 (4294967295, 每個列表超過40億個元素)。
應(yīng)用場景
1、消息隊列:reids的鏈表結(jié)構(gòu),可以輕松實現(xiàn)阻塞隊列,可以使用左進右出的命令組成來完成隊列的設(shè)計。比如:數(shù)據(jù)的生產(chǎn)者可以通過Lpush命令從左邊插入數(shù)據(jù),多個數(shù)據(jù)消費者,可以使用BRpop命令阻塞的“搶”列表尾部的數(shù)據(jù)。
2、文章列表或者數(shù)據(jù)分頁展示的應(yīng)用。比如,我們常用的博客網(wǎng)站的文章列表,當(dāng)用戶量越來越多時,而且每一個用戶都有自己的文章列表,而且當(dāng)文章多時,都需要分頁展示,這時可以考慮使用redis的列表,列表不但有序同時還支持按照范圍內(nèi)獲取元素,可以完美解決分頁查詢功能。大大提高查詢效率。
| 命令 | 描述 |
|---|---|
LPUSH/RPUSH key value1[value2..] |
從左邊/右邊向列表中PUSH值(一個或者多個)。 |
LRANGE key start end |
獲取list 起止元素(索引從左往右 遞增) |
LPUSHX/RPUSHX key value |
向已存在的列名中push值(一個或者多個) |
| `LINSERT key BEFORE | AFTER pivot value` |
LLEN key |
查看列表長度 |
LINDEX key index |
通過索引獲取列表元素 |
LSET key index value |
通過索引為元素設(shè)值 |
LPOP/RPOP key |
從最左邊/最右邊移除值 并返回 |
RPOPLPUSH source destination |
將列表的尾部(右)最后一個值彈出,并返回,然后加到另一個列表的頭部 |
LTRIM key start end |
通過下標(biāo)截取指定范圍內(nèi)的列表 |
LREM key count value |
List中是允許value重復(fù)的 count > 0:從頭部開始搜索 然后刪除指定的value 至多刪除count個 count < 0:從尾部開始搜索… count = 0:刪除列表中所有的指定value。 |
BLPOP/BRPOP key1[key2] timout |
移出并獲取列表的第一個/最后一個元素, 如果列表沒有元素會阻塞列表直到等待超時或發(fā)現(xiàn)可彈出元素為止。 |
BRPOPLPUSH source destination timeout |
和RPOPLPUSH功能相同,如果列表沒有元素會阻塞列表直到等待超時或發(fā)現(xiàn)可彈出元素為止。 |
---------------------------LPUSH---RPUSH---LRANGE--------------------------------
127.0.0.1:6379> LPUSH mylist k1 # LPUSH mylist=>{1}
(integer) 1
127.0.0.1:6379> LPUSH mylist k2 # LPUSH mylist=>{2,1}
(integer) 2
127.0.0.1:6379> RPUSH mylist k3 # RPUSH mylist=>{2,1,3}
(integer) 3
127.0.0.1:6379> get mylist # 普通的get是無法獲取list值的
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> LRANGE mylist 0 4 # LRANGE 獲取起止位置范圍內(nèi)的元素
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> LRANGE mylist 0 2
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> LRANGE mylist 0 1
1) "k2"
2) "k1"
127.0.0.1:6379> LRANGE mylist 0 -1 # 獲取全部元素
1) "k2"
2) "k1"
3) "k3"
---------------------------LPUSHX---RPUSHX-----------------------------------
127.0.0.1:6379> LPUSHX list v1 # list不存在 LPUSHX失敗
(integer) 0
127.0.0.1:6379> LPUSHX list v1 v2
(integer) 0
127.0.0.1:6379> LPUSHX mylist k4 k5 # 向mylist中 左邊 PUSH k4 k5
(integer) 5
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k5"
2) "k4"
3) "k2"
4) "k1"
5) "k3"
---------------------------LINSERT--LLEN--LINDEX--LSET----------------------------
127.0.0.1:6379> LINSERT mylist after k2 ins_key1 # 在k2元素后 插入ins_key1
(integer) 6
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k5"
2) "k4"
3) "k2"
4) "ins_key1"
5) "k1"
6) "k3"
127.0.0.1:6379> LLEN mylist # 查看mylist的長度
(integer) 6
127.0.0.1:6379> LINDEX mylist 3 # 獲取下標(biāo)為3的元素
"ins_key1"
127.0.0.1:6379> LINDEX mylist 0
"k5"
127.0.0.1:6379> LSET mylist 3 k6 # 將下標(biāo)3的元素 set值為k6
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k5"
2) "k4"
3) "k2"
4) "k6"
5) "k1"
6) "k3"
---------------------------LPOP--RPOP--------------------------
127.0.0.1:6379> LPOP mylist # 左側(cè)(頭部)彈出
"k5"
127.0.0.1:6379> RPOP mylist # 右側(cè)(尾部)彈出
"k3"
---------------------------RPOPLPUSH--------------------------
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k4"
2) "k2"
3) "k6"
4) "k1"
127.0.0.1:6379> RPOPLPUSH mylist newlist # 將mylist的最后一個值(k1)彈出,加入到newlist的頭部
"k1"
127.0.0.1:6379> LRANGE newlist 0 -1
1) "k1"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k4"
2) "k2"
3) "k6"
---------------------------LTRIM--------------------------
127.0.0.1:6379> LTRIM mylist 0 1 # 截取mylist中的 0~1部分
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k4"
2) "k2"
# 初始 mylist: k2,k2,k2,k2,k2,k2,k4,k2,k2,k2,k2
---------------------------LREM--------------------------
127.0.0.1:6379> LREM mylist 3 k2 # 從頭部開始搜索 至多刪除3個 k2
(integer) 3
# 刪除后:mylist: k2,k2,k2,k4,k2,k2,k2,k2
127.0.0.1:6379> LREM mylist -2 k2 #從尾部開始搜索 至多刪除2個 k2
(integer) 2
# 刪除后:mylist: k2,k2,k2,k4,k2,k2
---------------------------BLPOP--BRPOP--------------------------
mylist: k2,k2,k2,k4,k2,k2
newlist: k1
127.0.0.1:6379> BLPOP newlist mylist 30 # 從newlist中彈出第一個值,mylist作為候選
1) "newlist" # 彈出
2) "k1"
127.0.0.1:6379> BLPOP newlist mylist 30
1) "mylist" # 由于newlist空了 從mylist中彈出
2) "k2"
127.0.0.1:6379> BLPOP newlist 30
(30.10s) # 超時了
127.0.0.1:6379> BLPOP newlist 30 # 我們連接另一個客戶端向newlist中push了test, 阻塞被解決。
1) "newlist"
2) "test"
(12.54s)
小結(jié):
- list實際上是一個鏈表,before Node after , left, right 都可以插入值
- 如果key不存在,則創(chuàng)建新的鏈表
- 如果key存在,新增內(nèi)容
- 如果移除了所有值,空鏈表,也代表不存在
- 在兩邊插入或者改動值,效率最高!修改中間元素,效率相對較低
應(yīng)用:
- 消息排隊
- 消息隊列(Lpush Rpop)
- 棧(Lpush Lpop)
Set(集合)
Redis的Set是string類型的無序集合。集合成員是唯一的,這就意味著集合中不能出現(xiàn)重復(fù)的數(shù)據(jù)。Redis中集合是通過哈希表實現(xiàn)的,所以添加,刪除,查找的復(fù)雜度都是O(1),集合中最大的成員數(shù)為 232 - 1 (4294967295, 每個集合可存儲40多億個成員)。
應(yīng)用場景
1、標(biāo)簽:比如我們博客網(wǎng)站常常使用到的興趣標(biāo)簽,把一個個有著相同愛好,關(guān)注類似內(nèi)容的用戶利用一個標(biāo)簽把他們進行歸并。
2、共同好友功能,共同喜好,或者可以引申到二度好友之類的擴展應(yīng)用。
3、統(tǒng)計網(wǎng)站的獨立IP。利用set集合當(dāng)中元素不唯一性,可以快速實時統(tǒng)計訪問網(wǎng)站的獨立IP。
數(shù)據(jù)結(jié)構(gòu)
set的底層結(jié)構(gòu)相對復(fù)雜寫,使用了intset和hashtable兩種數(shù)據(jù)結(jié)構(gòu)存儲,intset可以理解為數(shù)組。
| 命令 | 描述 |
|---|---|
SADD key member1[member2..] |
向集合中無序增加一個/多個成員 |
SCARD key |
獲取集合的成員數(shù) |
SMEMBERS key |
返回集合中所有的成員 |
SISMEMBER key member |
查詢member元素是否是集合的成員,結(jié)果是無序的 |
SRANDMEMBER key [count] |
隨機返回集合中count個成員,count缺省值為1 |
SPOP key [count] |
隨機移除并返回集合中count個成員,count缺省值為1 |
SMOVE source destination member |
將source集合的成員member移動到destination集合 |
SREM key member1[member2..] |
移除集合中一個/多個成員 |
SDIFF key1[key2..] |
返回所有集合的差集 key1- key2 - … |
SDIFFSTORE destination key1[key2..] |
在SDIFF的基礎(chǔ)上,將結(jié)果保存到集合中(覆蓋)。不能保存到其他類型key噢! |
SINTER key1 [key2..] |
返回所有集合的交集 |
SINTERSTORE destination key1[key2..] |
在SINTER的基礎(chǔ)上,存儲結(jié)果到集合中。覆蓋 |
SUNION key1 [key2..] |
返回所有集合的并集 |
SUNIONSTORE destination key1 [key2..] |
在SUNION的基礎(chǔ)上,存儲結(jié)果到及和張。覆蓋 |
SSCAN KEY [MATCH pattern] [COUNT count] |
在大量數(shù)據(jù)環(huán)境下,使用此命令遍歷集合中元素,每次遍歷部分 |
---------------SADD--SCARD--SMEMBERS--SISMEMBER--------------------
127.0.0.1:6379> SADD myset m1 m2 m3 m4 # 向myset中增加成員 m1~m4
(integer) 4
127.0.0.1:6379> SCARD myset # 獲取集合的成員數(shù)目
(integer) 4
127.0.0.1:6379> smembers myset # 獲取集合中所有成員
1) "m4"
2) "m3"
3) "m2"
4) "m1"
127.0.0.1:6379> SISMEMBER myset m5 # 查詢m5是否是myset的成員
(integer) 0 # 不是,返回0
127.0.0.1:6379> SISMEMBER myset m2
(integer) 1 # 是,返回1
127.0.0.1:6379> SISMEMBER myset m3
(integer) 1
---------------------SRANDMEMBER--SPOP----------------------------------
127.0.0.1:6379> SRANDMEMBER myset 3 # 隨機返回3個成員
1) "m2"
2) "m3"
3) "m4"
127.0.0.1:6379> SRANDMEMBER myset # 隨機返回1個成員
"m3"
127.0.0.1:6379> SPOP myset 2 # 隨機移除并返回2個成員
1) "m1"
2) "m4"
# 將set還原到{m1,m2,m3,m4}
---------------------SMOVE--SREM----------------------------------------
127.0.0.1:6379> SMOVE myset newset m3 # 將myset中m3成員移動到newset集合
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "m4"
2) "m2"
3) "m1"
127.0.0.1:6379> SMEMBERS newset
1) "m3"
127.0.0.1:6379> SREM newset m3 # 從newset中移除m3元素
(integer) 1
127.0.0.1:6379> SMEMBERS newset
(empty list or set)
# 下面開始是多集合操作,多集合操作中若只有一個參數(shù)默認(rèn)和自身進行運算
# setx=>{m1,m2,m4,m6}, sety=>{m2,m5,m6}, setz=>{m1,m3,m6}
-----------------------------SDIFF------------------------------------
127.0.0.1:6379> SDIFF setx sety setz # 等價于setx-sety-setz
1) "m4"
127.0.0.1:6379> SDIFF setx sety # setx - sety
1) "m4"
2) "m1"
127.0.0.1:6379> SDIFF sety setx # sety - setx
1) "m5"
-------------------------SINTER---------------------------------------
# 共同關(guān)注(交集)
127.0.0.1:6379> SINTER setx sety setz # 求 setx、sety、setx的交集
1) "m6"
127.0.0.1:6379> SINTER setx sety # 求setx sety的交集
1) "m2"
2) "m6"
-------------------------SUNION---------------------------------------
127.0.0.1:6379> SUNION setx sety setz # setx sety setz的并集
1) "m4"
2) "m6"
3) "m3"
4) "m2"
5) "m1"
6) "m5"
127.0.0.1:6379> SUNION setx sety # setx sety 并集
1) "m4"
2) "m6"
3) "m2"
4) "m1"
5) "m5"
Hash(哈希)
Redis hash 是一個string類型的field和value的映射表,hash特別適合用于存儲對象,Set就是一種簡化的Hash,只變動key,而value使用默認(rèn)值填充。可以將一個Hash表作為一個對象進行存儲,表中存放對象的信息。
應(yīng)用場景
1、由于hash數(shù)據(jù)類型的key-value的特性,用來存儲關(guān)系型數(shù)據(jù)庫中表記錄,是redis中哈希類型最常用的場景。一條記錄作為一個key-value,把每列屬性值對應(yīng)成field-value存儲在哈希表當(dāng)中,然后通過key值來區(qū)分表當(dāng)中的主鍵。
2、經(jīng)常被用來存儲用戶相關(guān)信息。優(yōu)化用戶信息的獲取,不需要重復(fù)從數(shù)據(jù)庫當(dāng)中讀取,提高系統(tǒng)性能。
| 命令 | 描述 |
|---|---|
HSET key field value |
將哈希表 key 中的字段 field 的值設(shè)為 value 。重復(fù)設(shè)置同一個field會覆蓋,返回0 |
HMSET key field1 value1 [field2 value2..] |
同時將多個 field-value (域-值)對設(shè)置到哈希表 key 中。 |
HSETNX key field value |
只有在字段 field 不存在時,設(shè)置哈希表字段的值。 |
HEXISTS key field |
查看哈希表 key 中,指定的字段是否存在。 |
HGET key field value |
獲取存儲在哈希表中指定字段的值 |
HMGET key field1 [field2..] |
獲取所有給定字段的值 |
HGETALL key |
獲取在哈希表key 的所有字段和值 |
HKEYS key |
獲取哈希表key中所有的字段 |
HLEN key |
獲取哈希表中字段的數(shù)量 |
HVALS key |
獲取哈希表中所有值 |
HDEL key field1 [field2..] |
刪除哈希表key中一個/多個field字段 |
HINCRBY key field n |
為哈希表 key 中的指定字段的整數(shù)值加上增量n,并返回增量后結(jié)果 一樣只適用于整數(shù)型字段 |
HINCRBYFLOAT key field n |
為哈希表 key 中的指定字段的浮點數(shù)值加上增量 n。 |
HSCAN key cursor [MATCH pattern] [COUNT count] |
迭代哈希表中的鍵值對。 |
------------------------HSET--HMSET--HSETNX----------------
127.0.0.1:6379> HSET studentx name sakura # 將studentx哈希表作為一個對象,設(shè)置name為sakura
(integer) 1
127.0.0.1:6379> HSET studentx name gyc # 重復(fù)設(shè)置field進行覆蓋,并返回0
(integer) 0
127.0.0.1:6379> HSET studentx age 20 # 設(shè)置studentx的age為20
(integer) 1
127.0.0.1:6379> HMSET studentx sex 1 tel 15623667886 # 設(shè)置sex為1,tel為15623667886
OK
127.0.0.1:6379> HSETNX studentx name gyc # HSETNX 設(shè)置已存在的field
(integer) 0 # 失敗
127.0.0.1:6379> HSETNX studentx email 12345@qq.com
(integer) 1 # 成功
----------------------HEXISTS--------------------------------
127.0.0.1:6379> HEXISTS studentx name # name字段在studentx中是否存在
(integer) 1 # 存在
127.0.0.1:6379> HEXISTS studentx addr
(integer) 0 # 不存在
-------------------HGET--HMGET--HGETALL-----------
127.0.0.1:6379> HGET studentx name # 獲取studentx中name字段的value
"gyc"
127.0.0.1:6379> HMGET studentx name age tel # 獲取studentx中name、age、tel字段的value
1) "gyc"
2) "20"
3) "15623667886"
127.0.0.1:6379> HGETALL studentx # 獲取studentx中所有的field及其value
1) "name"
2) "gyc"
3) "age"
4) "20"
5) "sex"
6) "1"
7) "tel"
8) "15623667886"
9) "email"
10) "12345@qq.com"
--------------------HKEYS--HLEN--HVALS--------------
127.0.0.1:6379> HKEYS studentx # 查看studentx中所有的field
1) "name"
2) "age"
3) "sex"
4) "tel"
5) "email"
127.0.0.1:6379> HLEN studentx # 查看studentx中的字段數(shù)量
(integer) 5
127.0.0.1:6379> HVALS studentx # 查看studentx中所有的value
1) "gyc"
2) "20"
3) "1"
4) "15623667886"
5) "12345@qq.com"
-------------------------HDEL--------------------------
127.0.0.1:6379> HDEL studentx sex tel # 刪除studentx 中的sex、tel字段
(integer) 2
127.0.0.1:6379> HKEYS studentx
1) "name"
2) "age"
3) "email"
-------------HINCRBY--HINCRBYFLOAT------------------------
127.0.0.1:6379> HINCRBY studentx age 1 # studentx的age字段數(shù)值+1
(integer) 21
127.0.0.1:6379> HINCRBY studentx name 1 # 非整數(shù)字型字段不可用
(error) ERR hash value is not an integer
127.0.0.1:6379> HINCRBYFLOAT studentx weight 0.6 # weight字段增加0.6
"90.8"
Hash變更的數(shù)據(jù)user name age,尤其是用戶信息之類的,經(jīng)常變動的信息!Hash更適合于對象的存儲,Sring更加適合字符串存儲!
Zset(有序集合)
不同的是每個元素都會關(guān)聯(lián)一個double類型的分?jǐn)?shù)(score)。redis正是通過分?jǐn)?shù)來為集合中的成員進行從小到大的排序。score相同:按字典順序排序,有序集合的成員是唯一的,但分?jǐn)?shù)(score)卻可以重復(fù)。
應(yīng)用場景
1、 排行榜:有序集合經(jīng)典使用場景。例如視頻網(wǎng)站需要對用戶上傳的視頻做排行榜,榜單維護可能是多方面:按照時間、按照播放量、按照獲得的贊數(shù)等。
2、用Sorted Sets來做帶權(quán)重的隊列,比如普通消息的score為1,重要消息的score為2,然后工作線程可以選擇按score的倒序來獲取工作任務(wù)。讓重要的任務(wù)優(yōu)先執(zhí)行。
| 命令 | 描述 |
|---|---|
ZADD key score member1 [score2 member2] |
向有序集合添加一個或多個成員,或者更新已存在成員的分?jǐn)?shù) |
ZCARD key |
獲取有序集合的成員數(shù) |
ZCOUNT key min max |
計算在有序集合中指定區(qū)間score的成員數(shù) |
ZINCRBY key n member |
有序集合中對指定成員的分?jǐn)?shù)加上增量 n |
ZSCORE key member |
返回有序集中,成員的分?jǐn)?shù)值 |
ZRANK key member |
返回有序集合中指定成員的索引 |
ZRANGE key start end |
通過索引區(qū)間返回有序集合成指定區(qū)間內(nèi)的成員 |
ZRANGEBYLEX key min max |
通過字典區(qū)間返回有序集合的成員 |
ZRANGEBYSCORE key min max |
通過分?jǐn)?shù)返回有序集合指定區(qū)間內(nèi)的成員-inf 和 +inf分別表示最小最大值,只支持開區(qū)間() |
ZLEXCOUNT key min max |
在有序集合中計算指定字典區(qū)間內(nèi)成員數(shù)量 |
ZREM key member1 [member2..] |
移除有序集合中一個/多個成員 |
ZREMRANGEBYLEX key min max |
移除有序集合中給定的字典區(qū)間的所有成員 |
ZREMRANGEBYRANK key start stop |
移除有序集合中給定的排名區(qū)間的所有成員 |
ZREMRANGEBYSCORE key min max |
移除有序集合中給定的分?jǐn)?shù)區(qū)間的所有成員 |
ZREVRANGE key start end |
返回有序集中指定區(qū)間內(nèi)的成員,通過索引,分?jǐn)?shù)從高到底 |
ZREVRANGEBYSCORRE key max min |
返回有序集中指定分?jǐn)?shù)區(qū)間內(nèi)的成員,分?jǐn)?shù)從高到低排序 |
ZREVRANGEBYLEX key max min |
返回有序集中指定字典區(qū)間內(nèi)的成員,按字典順序倒序 |
ZREVRANK key member |
返回有序集合中指定成員的排名,有序集成員按分?jǐn)?shù)值遞減(從大到小)排序 |
ZINTERSTORE destination numkeys key1 [key2 ..] |
計算給定的一個或多個有序集的交集并將結(jié)果集存儲在新的有序集合 key 中,numkeys:表示參與運算的集合數(shù),將score相加作為結(jié)果的score |
ZUNIONSTORE destination numkeys key1 [key2..] |
計算給定的一個或多個有序集的交集并將結(jié)果集存儲在新的有序集合 key 中 |
ZSCAN key cursor [MATCH pattern\] [COUNT count] |
迭代有序集合中的元素(包括元素成員和元素分值) |
-------------------ZADD--ZCARD--ZCOUNT--------------
127.0.0.1:6379> ZADD myzset 1 m1 2 m2 3 m3 # 向有序集合myzset中添加成員m1 score=1 以及成員m2 score=2..
(integer) 2
127.0.0.1:6379> ZCARD myzset # 獲取有序集合的成員數(shù)
(integer) 2
127.0.0.1:6379> ZCOUNT myzset 0 1 # 獲取score在 [0,1]區(qū)間的成員數(shù)量
(integer) 1
127.0.0.1:6379> ZCOUNT myzset 0 2
(integer) 2
----------------ZINCRBY--ZSCORE--------------------------
127.0.0.1:6379> ZINCRBY myzset 5 m2 # 將成員m2的score +5
"7"
127.0.0.1:6379> ZSCORE myzset m1 # 獲取成員m1的score
"1"
127.0.0.1:6379> ZSCORE myzset m2
"7"
--------------ZRANK--ZRANGE-----------------------------------
127.0.0.1:6379> ZRANK myzset m1 # 獲取成員m1的索引,索引按照score排序,score相同索引值按字典順序順序增加
(integer) 0
127.0.0.1:6379> ZRANK myzset m2
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 1 # 獲取索引在 0~1的成員
1) "m1"
2) "m3"
127.0.0.1:6379> ZRANGE myzset 0 -1 # 獲取全部成員
1) "m1"
2) "m3"
3) "m2"
#testset=>{abc,add,amaze,apple,back,java,redis} score均為0
------------------ZRANGEBYLEX---------------------------------
127.0.0.1:6379> ZRANGEBYLEX testset - + # 返回所有成員
1) "abc"
2) "add"
3) "amaze"
4) "apple"
5) "back"
6) "java"
7) "redis"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 0 3 # 分頁 按索引顯示查詢結(jié)果的 0,1,2條記錄
1) "abc"
2) "add"
3) "amaze"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 3 3 # 顯示 3,4,5條記錄
1) "apple"
2) "back"
3) "java"
127.0.0.1:6379> ZRANGEBYLEX testset (- [apple # 顯示 (-,apple] 區(qū)間內(nèi)的成員
1) "abc"
2) "add"
3) "amaze"
4) "apple"
127.0.0.1:6379> ZRANGEBYLEX testset [apple [java # 顯示 [apple,java]字典區(qū)間的成員
1) "apple"
2) "back"
3) "java"
-----------------------ZRANGEBYSCORE---------------------
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 10 # 返回score在 [1,10]之間的的成員
1) "m1"
2) "m3"
3) "m2"
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 5
1) "m1"
2) "m3"
--------------------ZLEXCOUNT-----------------------------
127.0.0.1:6379> ZLEXCOUNT testset - +
(integer) 7
127.0.0.1:6379> ZLEXCOUNT testset [apple [java
(integer) 3
------------------ZREM--ZREMRANGEBYLEX--ZREMRANGBYRANK--ZREMRANGEBYSCORE--------------------------------
127.0.0.1:6379> ZREM testset abc # 移除成員abc
(integer) 1
127.0.0.1:6379> ZREMRANGEBYLEX testset [apple [java # 移除字典區(qū)間[apple,java]中的所有成員
(integer) 3
127.0.0.1:6379> ZREMRANGEBYRANK testset 0 1 # 移除排名0~1的所有成員
(integer) 2
127.0.0.1:6379> ZREMRANGEBYSCORE myzset 0 3 # 移除score在 [0,3]的成員
(integer) 2
# testset=> {abc,add,apple,amaze,back,java,redis} score均為0
# myzset=> {(m1,1),(m2,2),(m3,3),(m4,4),(m7,7),(m9,9)}
----------------ZREVRANGE--ZREVRANGEBYSCORE--ZREVRANGEBYLEX-----------
127.0.0.1:6379> ZREVRANGE myzset 0 3 # 按score遞減排序,然后按索引,返回結(jié)果的 0~3
1) "m9"
2) "m7"
3) "m4"
4) "m3"
127.0.0.1:6379> ZREVRANGE myzset 2 4 # 返回排序結(jié)果的 索引的2~4
1) "m4"
2) "m3"
3) "m2"
127.0.0.1:6379> ZREVRANGEBYSCORE myzset 6 2 # 按score遞減順序 返回集合中分?jǐn)?shù)在[2,6]之間的成員
1) "m4"
2) "m3"
3) "m2"
127.0.0.1:6379> ZREVRANGEBYLEX testset [java (add # 按字典倒序 返回集合中(add,java]字典區(qū)間的成員
1) "java"
2) "back"
3) "apple"
4) "amaze"
-------------------------ZREVRANK------------------------------
127.0.0.1:6379> ZREVRANK myzset m7 # 按score遞減順序,返回成員m7索引
(integer) 1
127.0.0.1:6379> ZREVRANK myzset m2
(integer) 4
# mathscore=>{(xm,90),(xh,95),(xg,87)} 小明、小紅、小剛的數(shù)學(xué)成績
# enscore=>{(xm,70),(xh,93),(xg,90)} 小明、小紅、小剛的英語成績
-------------------ZINTERSTORE--ZUNIONSTORE-----------------------------------
127.0.0.1:6379> ZINTERSTORE sumscore 2 mathscore enscore # 將mathscore enscore進行合并 結(jié)果存放到sumscore
(integer) 3
127.0.0.1:6379> ZRANGE sumscore 0 -1 withscores # 合并后的score是之前集合中所有score的和
1) "xm"
2) "160"
3) "xg"
4) "177"
5) "xh"
6) "188"
127.0.0.1:6379> ZUNIONSTORE lowestscore 2 mathscore enscore AGGREGATE MIN # 取兩個集合的成員score最小值作為結(jié)果的
(integer) 3
127.0.0.1:6379> ZRANGE lowestscore 0 -1 withscores
1) "xm"
2) "70"
3) "xg"
4) "87"
5) "xh"
6) "93"
應(yīng)用案例:
- set排序 存儲班級成績表 工資表排序!
- 普通消息,1.重要消息 2.帶權(quán)重進行判斷
- 排行榜應(yīng)用實現(xiàn),取Top N測試
三種特殊數(shù)據(jù)類型
Geospatial(地理位置)
使用經(jīng)緯度定位地理坐標(biāo)并用一個有序集合zset保存,所以zset命令也可以使用。
| 命令 | 描述 |
|---|---|
geoadd key longitud(經(jīng)度) latitude(緯度) member [..] |
將具體經(jīng)緯度的坐標(biāo)存入一個有序集合 |
geopos key member [member..] |
獲取集合中的一個/多個成員坐標(biāo) |
geodist key member1 member2 [unit] |
返回兩個給定位置之間的距離。默認(rèn)以米作為單位。 |
| `georadius key longitude latitude radius m | km |
GEORADIUSBYMEMBER key member radius... |
功能與GEORADIUS相同,只是中心位置不是具體的經(jīng)緯度,而是使用結(jié)合中已有的成員作為中心點。 |
geohash key member1 [member2..] |
返回一個或多個位置元素的Geohash表示。使用Geohash位置52點整數(shù)編碼。 |
有效經(jīng)緯度
- 有效的經(jīng)度從-180度到180度。
- 有效的緯度從-85.05112878度到85.05112878度。
指定單位的參數(shù) unit 必須是以下單位的其中一個:
- m 表示單位為米。
- km 表示單位為千米。
- mi 表示單位為英里。
- ft 表示單位為英尺。
關(guān)于GEORADIUS的參數(shù)
通過
georadius就可以完成 附近的人功能withcoord:帶上坐標(biāo)
withdist:帶上距離,單位與半徑單位相同
COUNT n : 只顯示前n個(按距離遞增排序)
----------------georadius---------------------
127.0.0.1:6379> GEORADIUS china:city 120 30 500 km withcoord withdist # 查詢經(jīng)緯度(120,30)坐標(biāo)500km半徑內(nèi)的成員
1) 1) "hangzhou"
2) "29.4151"
3) 1) "120.20000249147415"
2) "30.199999888333501"
2) 1) "shanghai"
2) "205.3611"
3) 1) "121.40000134706497"
2) "31.400000253193539"
------------geohash---------------------------
127.0.0.1:6379> geohash china:city yichang shanghai # 獲取成員經(jīng)緯坐標(biāo)的geohash表示
1) "wmrjwbr5250"
2) "wtw6ds0y300"
Hyperloglog(基數(shù)統(tǒng)計)
Redis HyperLogLog 是用來做基數(shù)(數(shù)據(jù)集中不重復(fù)的元素的個數(shù))統(tǒng)計的數(shù)據(jù)結(jié)構(gòu),HyperLogLog 的優(yōu)點是,在輸入元素的數(shù)量或者體積非常非常大時,計算基數(shù)所需的空間總是固定的、并且是很小的。
花費 12 KB 內(nèi)存,就可以計算接近 2^64 個不同元素的基數(shù)。
因為 HyperLogLog 只會根據(jù)輸入元素來計算基數(shù),而不會儲存輸入元素本身,所以 HyperLogLog 不能像集合那樣,返回輸入的各個元素。
應(yīng)用場景:網(wǎng)頁的訪問量(UV),一個用戶多次訪問,也只能算作一個人。
傳統(tǒng)實現(xiàn),存儲用戶的id,然后每次進行比較。當(dāng)用戶變多之后這種方式及其浪費空間,而我們的目的只是計數(shù),Hyperloglog就能幫助我們利用最小的空間完成。
| 命令 | 描述 |
|---|---|
PFADD key element1 [elememt2..] |
添加指定元素到 HyperLogLog 中 |
PFCOUNT key [key] |
返回給定 HyperLogLog 的基數(shù)估算值。 |
PFMERGE destkey sourcekey [sourcekey..] |
將多個 HyperLogLog 合并為一個 HyperLogLog |
----------PFADD--PFCOUNT---------------------
127.0.0.1:6379> PFADD myelemx a b c d e f g h i j k # 添加元素
(integer) 1
127.0.0.1:6379> type myelemx # hyperloglog底層使用String
string
127.0.0.1:6379> PFCOUNT myelemx # 估算myelemx的基數(shù)
(integer) 11
127.0.0.1:6379> PFADD myelemy i j k z m c b v p q s
(integer) 1
127.0.0.1:6379> PFCOUNT myelemy
(integer) 11
----------------PFMERGE-----------------------
127.0.0.1:6379> PFMERGE myelemz myelemx myelemy # 合并myelemx和myelemy 成為myelemz
OK
127.0.0.1:6379> PFCOUNT myelemz # 估算基數(shù)
(integer) 17
如果允許容錯,那么一定可以使用Hyperloglog !
如果不允許容錯,就使用set或者自己的數(shù)據(jù)類型即可 !
BitMaps(位圖)
使用位存儲,信息狀態(tài)只有 0 和 1,Bitmap是一串連續(xù)的2進制數(shù)字(0或1),每一位所在的位置為偏移(offset),在bitmap上可執(zhí)行AND,OR,XOR,NOT以及其它位操作。
應(yīng)用場景:簽到統(tǒng)計、狀態(tài)統(tǒng)計
| 命令 | 描述 |
|---|---|
setbit key offset value |
為指定key的offset位設(shè)置值 |
getbit key offset |
獲取offset位的值 |
bitcount key [start end] |
統(tǒng)計字符串被設(shè)置為1的bit數(shù),也可以指定統(tǒng)計范圍按字節(jié) |
bitop operration destkey key[key..] |
對一個或多個保存二進制位的字符串 key 進行位元操作,并將結(jié)果保存到 destkey 上。 |
BITPOS key bit [start] [end] |
返回字符串里面第一個被設(shè)置為1或者0的bit位。start和end只能按字節(jié),不能按位 |
------------setbit--getbit--------------
127.0.0.1:6379> setbit sign 0 1 # 設(shè)置sign的第0位為 1
(integer) 0
127.0.0.1:6379> setbit sign 2 1 # 設(shè)置sign的第2位為 1 不設(shè)置默認(rèn) 是0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> type sign
string
127.0.0.1:6379> getbit sign 2 # 獲取第2位的數(shù)值
(integer) 1
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4 # 未設(shè)置默認(rèn)是0
(integer) 0
-----------bitcount----------------------------
127.0.0.1:6379> BITCOUNT sign # 統(tǒng)計sign中為1的位數(shù)
(integer) 4
這樣設(shè)置以后你能get到的值是:\xA2\x80,所以bitmaps是一串從左到右的二進制串
Redis事務(wù)
Redis的事務(wù)就是指一組命令的集合,Redis的單條命令是保證原子性的,但是redis事務(wù)不能保證原子性,并且Redis事務(wù)沒有隔離級別的概念。
事務(wù)中每條命令都會被序列化,執(zhí)行過程中按順序執(zhí)行,不允許其他命令進行干擾。
- 一次性
- 順序性
- 排他性
操作過程
- 開啟事務(wù)(
multi) - 命令入隊
- 執(zhí)行事務(wù)(
exec)
所以事務(wù)中的命令在加入時都沒有被執(zhí)行,直到提交時才會開始執(zhí)行(Exec)一次性完成。
127.0.0.1:6379> multi # 開啟事務(wù)
OK
127.0.0.1:6379> set k1 v1 # 命令入隊
QUEUED
127.0.0.1:6379> set k2 v2 # ..
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec # 事務(wù)執(zhí)行
1) OK
2) OK
3) "v1"
4) OK
5) 1) "k3"
2) "k2"
3) "k1"
取消事務(wù)(discurd)
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> DISCARD # 放棄事務(wù)
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI # 當(dāng)前未開啟事務(wù)
127.0.0.1:6379> get k1 # 被放棄事務(wù)中命令并未執(zhí)行
(nil)
事務(wù)錯誤
代碼語法錯誤(編譯時異常)所有的命令都不執(zhí)行:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> error k1 # 這是一條語法錯誤命令
(error) ERR unknown command `error`, with args beginning with: `k1`, # 會報錯但是不影響后續(xù)命令入隊
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors. # 執(zhí)行報錯
127.0.0.1:6379> get k1
(nil) # 其他命令并沒有被執(zhí)行
當(dāng)代碼邏輯錯誤 (運行時異常) ,其他命令可以正常執(zhí)行,因此說Redis所以不保證事務(wù)原子性:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> INCR k1 # 這條命令邏輯錯誤(對字符串進行增量)
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range # 運行時報錯
4) "v2" # 其他命令正常執(zhí)行
# 雖然中間有一條命令報錯了,但是后面的指令依舊正常執(zhí)行成功了。
# 所以說Redis單條指令保證原子性,但是Redis事務(wù)不能保證原子性。
監(jiān)控
使用watch key監(jiān)控指定數(shù)據(jù),相當(dāng)于樂觀鎖加鎖。
正常執(zhí)行:
127.0.0.1:6379> set money 100 # 設(shè)置余額:100
OK
127.0.0.1:6379> set use 0 # 支出使用:0
OK
127.0.0.1:6379> watch money # 監(jiān)視money (上鎖)
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> exec # 監(jiān)視值沒有被中途修改,事務(wù)正常執(zhí)行
1) (integer) 80
2) (integer) 20
測試多線程修改值,使用watch可以當(dāng)做redis的樂觀鎖操作(相當(dāng)于getversion):
我們啟動另外一個客戶端模擬插隊線程。
線程1:
127.0.0.1:6379> watch money # money上鎖
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> # 此時事務(wù)并沒有執(zhí)行
模擬線程插隊,線程2:
127.0.0.1:6379> INCRBY money 500 # 修改了線程一中監(jiān)視的money
(integer) 600
12
回到線程1,執(zhí)行事務(wù):
127.0.0.1:6379> EXEC # 執(zhí)行之前,另一個線程修改了我們的值,這個時候就會導(dǎo)致事務(wù)執(zhí)行失敗
(nil) # 沒有結(jié)果,說明事務(wù)執(zhí)行失敗
127.0.0.1:6379> get money # 線程2 修改生效
"600"
127.0.0.1:6379> get use # 線程1事務(wù)執(zhí)行失敗,數(shù)值沒有被修改
"0"
解鎖獲取最新值,然后再加鎖進行事務(wù)。unwatch進行解鎖。注意:每次提交執(zhí)行exec后都會自動釋放鎖,不管是否成功
持久化策略
Redis支持RDB和AOF兩種持久化機制,持久化功能有效避免因進程退出造成的數(shù)據(jù)丟失問題,當(dāng)下次重啟時利用之前持久化的文件即可實現(xiàn)數(shù)據(jù)恢復(fù)。
RDB持久化
什么是RDB
RDB持久化是把當(dāng)前進程數(shù)據(jù)生成快照保存到硬盤的過程,觸發(fā)RDB持久化過程可以分為手動觸發(fā)和自動觸發(fā)。默認(rèn)情況下, Redis 將數(shù)據(jù)庫快照保存在名字為 dump.rdb的二進制文件中。文件名可以在配置文件中進行自定義。
工作原理
RDB的手動觸發(fā)分別對應(yīng)save和bgsave命令:
- save命令:阻塞當(dāng)前Redis服務(wù)器,直到RDB過程完成為止,對于內(nèi)存比較大的示例會造成長時間則色,線上環(huán)境不建議使用。
- bgsave命令:Redis進程執(zhí)行fork操作創(chuàng)建子進程,RDB持久化過程由子進程負(fù)責(zé),完成后自動結(jié)束。阻塞只發(fā)生在fork階段,一般時間很短。
顯然bgsave命令是針對save阻塞問題做的優(yōu)化。因此Redis內(nèi)部所有的涉及RDB的操作都采用bgsave的方式,而save命令已經(jīng)廢棄,因此這里不做過多介紹。
RDB的自動觸發(fā)只需要在配置文件redis.conf中開啟相關(guān)配置即可:
save 900 1:表示900 秒內(nèi)如果至少有 1 個 key 的值變化,則保存
save 300 10:表示300 秒內(nèi)如果至少有 10 個 key 的值變化,則保存
save 60 10000:表示60 秒內(nèi)如果至少有 10000 個 key 的值變化,則保存
bgsave
bgsave是異步進行,進行持久化的時候,Redis還可以將繼續(xù)響應(yīng)客戶端請求 ;
詳細(xì)具體步驟如下:
- 執(zhí)行bgsave命令,Redis父進程判斷當(dāng)前是否存在正在執(zhí)行的子進程,如RDB/AOF子進程,如果存在bgsave命令直接返回
- 父進程執(zhí)行fork操作創(chuàng)建子進程,fork操作過程中父進程會阻塞,通過
info stats命令查看latest_fork_usec選項,可以獲取最近一個fork操作的耗時,單位為微秒 - 父進程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父進程,可以繼續(xù)響應(yīng)其他命令
- 父進程創(chuàng)建RDB文件,根據(jù)父進程內(nèi)存生成臨時快照文件,完成后對原有文件進行原子替換。執(zhí)行
lastsave命令可以獲取最后一次生成RDB的時間,對應(yīng)info統(tǒng)計的rdb_last_save_time選項 - 進程發(fā)送信號給父進程表示完成,父進程更新統(tǒng)計信息
這種工作方式使得 Redis 可以從寫時復(fù)制(copy-on-write)機制中獲益(因為是使用子進程進行寫操作,而父進程依然可以接收來自客戶端的請求)。
bgsave和save對比
| 命令 | save | bgsave |
|---|---|---|
| IO類型 | 同步 | 異步 |
| 阻塞 | 是 | 是(阻塞發(fā)生在fock(),通常非常快) |
| 復(fù)雜度 | O(n) | O(n) |
| 優(yōu)點 | 不會消耗額外的內(nèi)存 | 不阻塞客戶端命令 |
| 缺點 | 阻塞客戶端命令 | 需要fork子進程,消耗內(nèi)存 |
優(yōu)點和缺點
優(yōu)點:
- 適合大規(guī)模的數(shù)據(jù)恢復(fù)
- 對數(shù)據(jù)的完整性要求不高
- Redis加載RDB恢復(fù)數(shù)據(jù)遠(yuǎn)遠(yuǎn)快于AOF的方式
缺點:
- 需要一定的時間間隔進行操作,如果redis意外宕機了,這個最后一次修改的數(shù)據(jù)就沒有了
- fork進程的時候,會占用一定的內(nèi)存空間
- RDB文件使用特定二進制格式保存,Redis版本演進過程中有多個格式的RDB版本,存在老版本Redis服務(wù)無法兼容RDB格式的問題
也可以簡單的說,RDB不適合實時持久化。
持久化AOF
AOF表示Append Only File,這種模式會將所有的命令都記錄下來,恢復(fù)的時候就把這個文件全部再執(zhí)行一遍。
以日志的形式來記錄每個寫的操作,將Redis執(zhí)行過的所有指令記錄下來(讀操作不記錄),只許追加文件但不可以改寫文件,redis啟動之初會讀取該文件重新構(gòu)建數(shù)據(jù),換言之,redis重啟的話就根據(jù)日志文件的內(nèi)容將寫指令從前到后執(zhí)行一次以完成數(shù)據(jù)的恢復(fù)工作。
什么是AOF
快照功能(RDB)并不是非常耐久(durable): 如果 Redis 因為某些原因而造成故障停機, 那么服務(wù)器將丟失最近寫入、以及未保存到快照中的那些數(shù)據(jù)。 從 1.1 版本開始, Redis 增加了一種完全耐久的持久化方式: AOF 持久化。
AOF默認(rèn)是不開啟的,需要進行配置才可以:
appendonly yes # 默認(rèn)是不開啟aof模式的,默認(rèn)是使用rdb方式持久化的,在大部分的情況下,rdb完全夠用
appendfilename "appendonly.aof"
# appendfsync always # 每次修改都會sync 消耗性能
appendfsync everysec # 每秒執(zhí)行一次 sync 可能會丟失這一秒的數(shù)據(jù)
# appendfsync no # 不執(zhí)行 sync ,這時候操作系統(tǒng)自己同步數(shù)據(jù),速度最快
優(yōu)點和缺點
優(yōu)點
- 每一次修改都會同步,文件的完整性會更加好
- 沒秒同步一次,可能會丟失一秒的數(shù)據(jù)
- 從不同步,效率最高
缺點
- 相對于數(shù)據(jù)文件來說,AOF遠(yuǎn)遠(yuǎn)大于RDB,修復(fù)速度比RDB慢
- AOF運行效率也要比RDB慢,所以我們Redis默認(rèn)的配置就是RDB持久化
RDB和AOP選擇
RDB 和 AOF 對比
| 比較項 | RDB | AOF |
|---|---|---|
| 啟動優(yōu)先級 | 低 | 高 |
| 體積 | 小 | 大 |
| 恢復(fù)速度 | 快 | 慢 |
| 數(shù)據(jù)安全性 | 丟數(shù)據(jù) | 根據(jù)策略決定 |
如何選擇使用哪種持久化方式?
一般來說, 如果想達(dá)到足以媲美 PostgreSQL 的數(shù)據(jù)安全性, 你應(yīng)該同時使用兩種持久化功能。如果你非常關(guān)心你的數(shù)據(jù), 但仍然可以承受數(shù)分鐘以內(nèi)的數(shù)據(jù)丟失, 那么你可以只使用 RDB 持久化。有很多用戶都只使用 AOF 持久化, 但并不推薦這種方式: 因為定時生成 RDB 快照(snapshot)非常便于進行數(shù)據(jù)庫備份, 并且 RDB 恢復(fù)數(shù)據(jù)集的速度也要比 AOF 恢復(fù)的速度要快。
Redis發(fā)布與訂閱
Redis 發(fā)布訂閱(pub/sub)是一種消息通信模式:發(fā)送者(pub)發(fā)送消息,訂閱者(sub)接收消息。
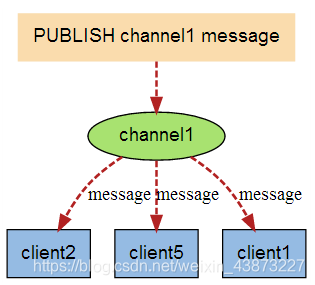
下圖展示了頻道 channel1 , 以及訂閱這個頻道的三個客戶端 —— client2 、 client5 和 client1 之間的關(guān)系:

當(dāng)有新消息通過 PUBLISH 命令發(fā)送給頻道 channel1 時, 這個消息就會被發(fā)送給訂閱它的三個客戶端:
命令
| 命令 | 描述 |
|---|---|
PSUBSCRIBE pattern [pattern..] |
訂閱一個或多個符合給定模式的頻道。 |
PUNSUBSCRIBE pattern [pattern..] |
退訂一個或多個符合給定模式的頻道。 |
PUBSUB subcommand [argument[argument]] |
查看訂閱與發(fā)布系統(tǒng)狀態(tài)。 |
PUBLISH channel message |
向指定頻道發(fā)布消息 |
SUBSCRIBE channel [channel..] |
訂閱給定的一個或多個頻道。 |
SUBSCRIBE channel [channel..] |
退訂一個或多個頻道 |
示例
------------訂閱端----------------------
127.0.0.1:6379> SUBSCRIBE sakura # 訂閱sakura頻道
Reading messages... (press Ctrl-C to quit) # 等待接收消息
1) "subscribe" # 訂閱成功的消息
2) "sakura"
3) (integer) 1
1) "message" # 接收到來自sakura頻道的消息 "hello world"
2) "sakura"
3) "hello world"
1) "message" # 接收到來自sakura頻道的消息 "hello i am sakura"
2) "sakura"
3) "hello i am sakura"
--------------消息發(fā)布端-------------------
127.0.0.1:6379> PUBLISH sakura "hello world" # 發(fā)布消息到sakura頻道
(integer) 1
127.0.0.1:6379> PUBLISH sakura "hello i am sakura" # 發(fā)布消息
(integer) 1
-----------------查看活躍的頻道------------
127.0.0.1:6379> PUBSUB channels
1) "sakura"
原理
每個 Redis 服務(wù)器進程都維持著一個表示服務(wù)器狀態(tài)的 redis.h/redisServer 結(jié)構(gòu), 結(jié)構(gòu)的 pubsub_channels 屬性是一個字典, 這個字典就用于保存訂閱頻道的信息,其中,字典的鍵為正在被訂閱的頻道, 而字典的值則是一個鏈表, 鏈表中保存了所有訂閱這個頻道的客戶端。
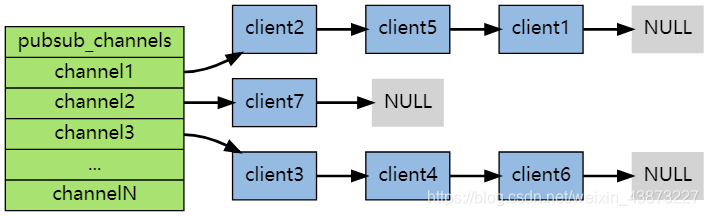
客戶端訂閱,就被鏈接到對應(yīng)頻道的鏈表的尾部,退訂則就是將客戶端節(jié)點從鏈表中移除。
缺點
- 如果一個客戶端訂閱了頻道,但自己讀取消息的速度卻不夠快的話,那么不f/斷積壓的消息會使redis輸出緩沖區(qū)的體積變得越來越大,這可能使得redis本身的速度變慢,甚至直接崩潰。
- 這和數(shù)據(jù)傳輸可靠性有關(guān),如果在訂閱方斷線,那么他將會丟失所有在短線期間發(fā)布者發(fā)布的消息。
應(yīng)用.消息訂閱:公眾號訂閱,微博關(guān)注等等(起始更多是使用消息‘f/隊列來進行實現(xiàn))
- 多人在線聊天室。
稍微復(fù)雜的場景,我們就會使用消息中間件MQ處理。
Redis線程IO模型
在從前的版本中,Redis是個單線程的程序,除了Redis之外,Node.js與Nginx也是單線程,但是它們都是高性能服務(wù)器的典范,不過從Redis6.0開始,增加了多線程的支持,以滿足更高的性能,具體可以參考:支持多線程的Redis 6.0終于發(fā)布了,那么Redis是如何使用單線程處理那么多的并發(fā)客戶端連接的?答案就是多路復(fù)用。
非阻塞IO
當(dāng)我們調(diào)用套節(jié)字的讀寫方法,默認(rèn)它們是阻塞的,比如read方法要傳遞進去一個參數(shù)n,表示讀取這么多字節(jié)后再返回,如果沒有讀夠線程就會卡在那里,直到新的數(shù)據(jù)刀來或者連接關(guān)閉了,read方法才會返回,線程才能繼續(xù)處理。而write方法一般來說不會阻塞,除非內(nèi)核為套接字分配的寫緩沖區(qū)已經(jīng)滿了,write方法就會阻塞,直到緩存區(qū)中有空閑空間挪出來了。
非阻塞IO在套接字對象上提供了一個線程Non_Blocking,當(dāng)這個選項打開時,讀寫方法不會阻塞,而是能讀多少讀多少,能寫多少寫多少。能讀多少取決于內(nèi)核為套接字分配的讀緩沖區(qū)內(nèi)部的數(shù)據(jù)字節(jié)數(shù),能寫多少取決于內(nèi)核為套接字分配的寫緩沖區(qū)的空閑空間字節(jié)數(shù)。讀方法和寫方法都會通過返回值來告知程序?qū)嶋H讀寫了多少字節(jié)。
有了非阻塞IO意味著線程在讀寫IO時可以不必再阻塞了,讀寫可以瞬間完成然后程序可以繼續(xù)干別的事了。
多路復(fù)用
非阻塞IO有個問題,那就是線程要讀數(shù)據(jù),結(jié)果讀了一部分就返回了,線程如何知道何時才應(yīng)該繼續(xù)。也就是當(dāng)數(shù)據(jù)到來時,線程如何得到通知。寫也是一樣,如果緩沖區(qū)滿了,寫不完,剩下的數(shù)據(jù)何時才應(yīng)該續(xù)寫,線程也應(yīng)該得到通知。
多路復(fù)用(事件輪詢)API就是用來解決這個問題的,最簡單的事件輪詢API是select函數(shù),它是操作系統(tǒng)提供給用戶程序的API。輸入是讀寫描述符列表read_fds & write_fds,輸出是與之對應(yīng)的可讀可寫事件。同時還提供了timeout參數(shù),如果沒有任何事件到來,那么久最多等待timeout時間,線程處于阻塞狀態(tài)。一旦期間有任何事情刀來,就可以立即返回。時間過了之后還是沒有任何事件到來,也會立即返回。拿到事件后,線程就可以繼續(xù)挨個處理相應(yīng)的事件。處理完了繼續(xù)過來輪詢。于是線程就進入了一個死循環(huán),我們把這個死循環(huán)稱為事件循環(huán),一個循環(huán)為一個周期。
每個客戶端套接字socket都有對應(yīng)的讀寫文件描述符。
read_events,write_events = select(read_fds,write_fds,timeout)
for event in read_events:
handle_read(event.fd)
for event in write_events:
handle_write(event.fd)
# 處理其它事情,如定時任務(wù)等
handle_others()
因為我們通過select系統(tǒng)調(diào)用同時處理多個通道描述符的讀寫事件,因此我們將這類系統(tǒng)調(diào)用稱為多路復(fù)用API。現(xiàn)代操作系統(tǒng)的多路復(fù)用API已經(jīng)不再使用使用select系統(tǒng)調(diào)用,而改用epoll(linux)和kqueue(freebsd & macosx),因為select系統(tǒng)調(diào)用的性能再描述符特別多時性能會非常差。它使用起來可能在形式上略有差異,但是本質(zhì)上都是差不多的,都可以使用上面的偽代碼邏輯進行理解。
指令隊列
Redis會將每個客戶端套接字都關(guān)聯(lián)一個指令隊列。客戶端的指令通過隊列來排隊進行順序處理,先到先服務(wù)。
響應(yīng)隊列
Redis同樣會為每個客戶端套接字關(guān)聯(lián)一個響應(yīng)隊列。Redis服務(wù)器通過響應(yīng)隊列來將指令的返回結(jié)果回復(fù)給客戶端。如果隊列為空,那么意味著連接暫時處于空閑狀態(tài),不需要去獲取寫事件,也就是可以將當(dāng)前的客戶端描述符write_fds里面移出來。等到隊列有數(shù)據(jù)了,再將描述符放進去。避免select系統(tǒng)調(diào)用立即返回寫事件,結(jié)果發(fā)現(xiàn)沒什么數(shù)據(jù)可以寫。出現(xiàn)這種情況的線程會飆高CPU。
Redis主從復(fù)制
概念
主從復(fù)制,是指將一臺Redis服務(wù)器的數(shù)據(jù),復(fù)制到其他的Redis服務(wù)器。前者稱為主節(jié)點(Master/Leader),后者稱為從節(jié)點(Slave/Follower), 數(shù)據(jù)的復(fù)制是單向的!只能由主節(jié)點復(fù)制到從節(jié)點(主節(jié)點以寫為主、從節(jié)點以讀為主)。
默認(rèn)情況下,每臺Redis服務(wù)器都是主節(jié)點,一個主節(jié)點可以有0個或者多個從節(jié)點,但每個從節(jié)點只能由一個主節(jié)點。
作用
- 數(shù)據(jù)冗余:主從復(fù)制實現(xiàn)了數(shù)據(jù)的熱備份,是持久化之外的一種數(shù)據(jù)冗余的方式。
- 故障恢復(fù):當(dāng)主節(jié)點故障時,從節(jié)點可以暫時替代主節(jié)點提供服務(wù),是一種服務(wù)冗余的方式
- 負(fù)載均衡:在主從復(fù)制的基礎(chǔ)上,配合讀寫分離,由主節(jié)點進行寫操作,從節(jié)點進行讀操作,分擔(dān)服務(wù)器的負(fù)載;尤其是在多讀少寫的場景下,通過多個從節(jié)點分擔(dān)負(fù)載,提高并發(fā)量。
- 高可用基石:主從復(fù)制還是哨兵和集群能夠?qū)嵤┑幕A(chǔ)。
為什么使用集群
- 單臺服務(wù)器難以負(fù)載大量的請求
- 單臺服務(wù)器故障率高,系統(tǒng)崩壞概率大
- 單臺服務(wù)器內(nèi)存容量有限。
環(huán)境配置
我們在講解配置文件的時候,注意到有一個replication模塊 (見Redis.conf中第8條)
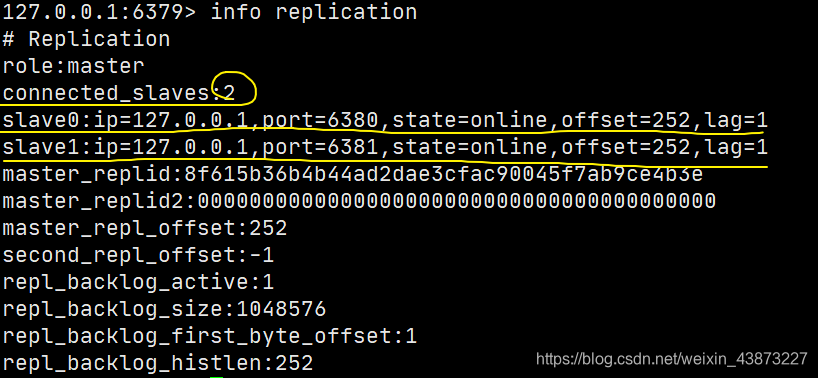
查看當(dāng)前庫的信息:info replication
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 從機數(shù)量
master_replid:3b54deef5b7b7b7f7dd8acefa23be48879b4fcff
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
既然需要啟動多個服務(wù),就需要多個配置文件。每個配置文件對應(yīng)修改以下信息:
- 端口號
- pid文件名
- 日志文件名
- rdb文件名
啟動單機多服務(wù)集群:

一主二從配置
默認(rèn)情況下,每臺Redis服務(wù)器都是主節(jié)點;我們一般情況下只用配置從機就好了!
認(rèn)老大!一主(79)二從(80,81)
使用SLAVEOF host port就可以為從機配置主機了。
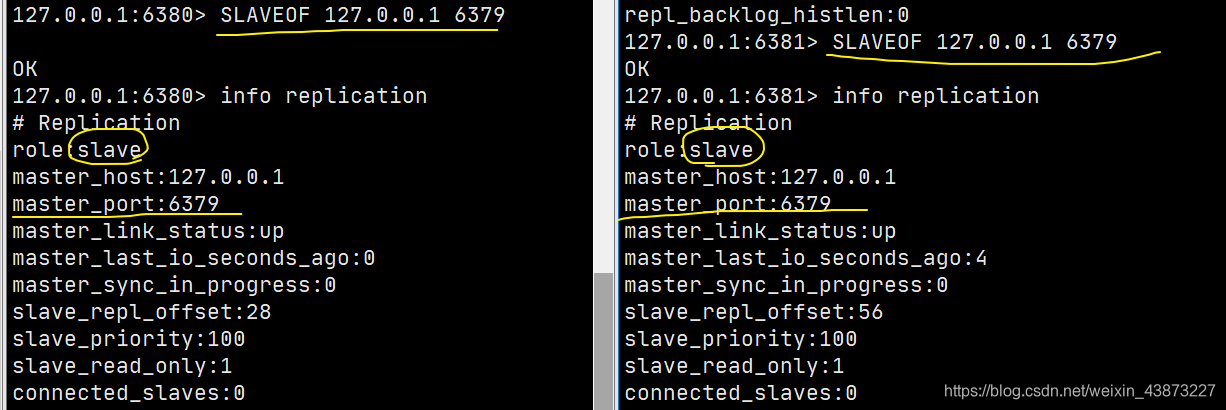
然后主機上也能看到從機的狀態(tài):
我們這里是使用命令搭建,是暫時的,真實開發(fā)中應(yīng)該在從機的配置文件中進行配置,這樣的話是永久的。

使用規(guī)則
-
從機只能讀,不能寫,主機可讀可寫但是多用于寫。
127.0.0.1:6381> set name sakura # 從機6381寫入失敗 (error) READONLY You can't write against a read only replica. 127.0.0.1:6380> set name sakura # 從機6380寫入失敗 (error) READONLY You can't write against a read only replica. 127.0.0.1:6379> set name sakura OK 127.0.0.1:6379> get name "sakura" -
當(dāng)主機斷電宕機后,默認(rèn)情況下從機的角色不會發(fā)生變化 ,集群中只是失去了寫操作,當(dāng)主機恢復(fù)以后,又會連接上從機恢復(fù)原狀。
-
當(dāng)從機斷電宕機后,若不是使用配置文件配置的從機,再次啟動后作為主機是無法獲取之前主機的數(shù)據(jù)的,若此時重新配置稱為從機,又可以獲取到主機的所有數(shù)據(jù)。這里就要提到一個同步原理。
-
第二條中提到,默認(rèn)情況下,主機故障后,不會出現(xiàn)新的主機,有兩種方式可以產(chǎn)生新的主機:
- 從機手動執(zhí)行命令
slaveof no one,這樣執(zhí)行以后從機會獨立出來成為一個主機 - 使用哨兵模式(自動選舉)
- 從機手動執(zhí)行命令
如果沒有老大了,這個時候能不能選擇出來一個老大呢?手動!
如果主機斷開了連接,我們可以使用SLAVEOF no one讓自己變成主機!其他的節(jié)點就可以手動連接到最新的主節(jié)點(手動)!如果這個時候老大修復(fù)了,那么久重新連接!
增量復(fù)制
主從服務(wù)器在完成第一次同步后,就會基于長連接進行命令傳播。
可是,網(wǎng)絡(luò)總是不按套路出牌的嘛,說延遲就延遲,說斷開就斷開。
如果主從服務(wù)器間的網(wǎng)絡(luò)連接斷開了,那么就無法進行命令傳播了,這時從服務(wù)器的數(shù)據(jù)就沒辦法和主服務(wù)器保持一致了,客戶端就可能從「從服務(wù)器」讀到舊的數(shù)據(jù)。

那么問題來了,如果此時斷開的網(wǎng)絡(luò),又恢復(fù)正常了,要怎么繼續(xù)保證主從服務(wù)器的數(shù)據(jù)一致性呢?
在 Redis 2.8 之前,如果主從服務(wù)器在命令同步時出現(xiàn)了網(wǎng)絡(luò)斷開又恢復(fù)的情況,從服務(wù)器就會和主服務(wù)器重新進行一次全量復(fù)制,很明顯這樣的開銷太大了,必須要改進一波。
所以,從 Redis 2.8 開始,網(wǎng)絡(luò)斷開又恢復(fù)后,從主從服務(wù)器會采用增量復(fù)制的方式繼續(xù)同步,也就是只會把網(wǎng)絡(luò)斷開期間主服務(wù)器接收到的寫操作命令,同步給從服務(wù)器。
網(wǎng)絡(luò)恢復(fù)后的增量復(fù)制過程如下圖:

主要有三個步驟:
- 從服務(wù)器在恢復(fù)網(wǎng)絡(luò)后,會發(fā)送 psync 命令給主服務(wù)器,此時的 psync 命令里的 offset 參數(shù)不是 -1;
- 主服務(wù)器收到該命令后,然后用 CONTINUE 響應(yīng)命令告訴從服務(wù)器接下來采用增量復(fù)制的方式同步數(shù)據(jù);
- 然后主服務(wù)將主從服務(wù)器斷線期間,所執(zhí)行的寫命令發(fā)送給從服務(wù)器,然后從服務(wù)器執(zhí)行這些命令。
那么關(guān)鍵的問題來了,主服務(wù)器怎么知道要將哪些增量數(shù)據(jù)發(fā)送給從服務(wù)器呢?
答案藏在這兩個東西里:
- repl_backlog_buffer,是一個「環(huán)形」緩沖區(qū),用于主從服務(wù)器斷連后,從中找到差異的數(shù)據(jù);
- replication offset,標(biāo)記上面那個緩沖區(qū)的同步進度,主從服務(wù)器都有各自的偏移量,主服務(wù)器使用 master_repl_offset 來記錄自己「寫」到的位置,從服務(wù)器使用 slave_repl_offset 來記錄自己「讀」到的位置。
那repl_backlog_buffer 緩沖區(qū)是什么時候?qū)懭氲哪兀?/p>
在主服務(wù)器進行命令傳播時,不僅會將寫命令發(fā)送給從服務(wù)器,還會將寫命令寫入到 repl_backlog_buffer 緩沖區(qū)里,因此 這個緩沖區(qū)里會保存著最近傳播的寫命令。
網(wǎng)絡(luò)斷開后,當(dāng)從服務(wù)器重新連上主服務(wù)器時,從服務(wù)器會通過 psync 命令將自己的復(fù)制偏移量 slave_repl_offset 發(fā)送給主服務(wù)器,主服務(wù)器根據(jù)自己的 master_repl_offset 和 slave_repl_offset 之間的差距,然后來決定對從服務(wù)器執(zhí)行哪種同步操作:
- 如果判斷出從服務(wù)器要讀取的數(shù)據(jù)還在 repl_backlog_buffer 緩沖區(qū)里,那么主服務(wù)器將采用增量同步的方式;
- 相反,如果判斷出從服務(wù)器要讀取的數(shù)據(jù)已經(jīng)不存在
repl_backlog_buffer 緩沖區(qū)里,那么主服務(wù)器將采用全量同步的方式。
當(dāng)主服務(wù)器在 repl_backlog_buffer 中找到主從服務(wù)器差異(增量)的數(shù)據(jù)后,就會將增量的數(shù)據(jù)寫入到 replication buffer 緩沖區(qū),這個緩沖區(qū)我們前面也提到過,它是緩存將要傳播給從服務(wù)器的命令。

repl_backlog_buffer 緩行緩沖區(qū)的默認(rèn)大小是 1M,并且由于它是一個環(huán)形緩沖區(qū),所以當(dāng)緩沖區(qū)寫滿后,主服務(wù)器繼續(xù)寫入的話,就會覆蓋之前的數(shù)據(jù)。
因此,當(dāng)主服務(wù)器的寫入速度遠(yuǎn)超于從服務(wù)器的讀取速度,緩沖區(qū)的數(shù)據(jù)一下就會被覆蓋。
那么在網(wǎng)絡(luò)恢復(fù)時,如果從服務(wù)器想讀的數(shù)據(jù)已經(jīng)被覆蓋了,主服務(wù)器就會采用全量同步,這個方式比增量同步的性能損耗要大很多。
因此,為了避免在網(wǎng)絡(luò)恢復(fù)時,主服務(wù)器頻繁地使用全量同步的方式,我們應(yīng)該調(diào)整下 repl_backlog_buffer 緩沖區(qū)大小,盡可能的大一些,減少出現(xiàn)從服務(wù)器要讀取的數(shù)據(jù)被覆蓋的概率,從而使得主服務(wù)器采用增量同步的方式。
那 repl_backlog_buffer 緩沖區(qū)具體要調(diào)整到多大呢?
repl_backlog_buffer 最小的大小可以根據(jù)這面這個公式估算。

我來解釋下這個公式的意思:
- second 為從服務(wù)器斷線后重新連接上主服務(wù)器所需的平均 時間(以秒計算)。
- write_size_per_second 則是主服務(wù)器平均每秒產(chǎn)生的寫命令數(shù)據(jù)量大小。
舉個例子,如果主服務(wù)器平均每秒產(chǎn)生 1 MB 的寫命令,而從服務(wù)器斷線之后平均要 5 秒才能重新連接主服務(wù)器。
那么 repl_backlog_buffer 大小就不能低于 5 MB,否則新寫地命令就會覆蓋舊數(shù)據(jù)了。
當(dāng)然,為了應(yīng)對一些突發(fā)的情況,可以將 repl_backlog_buffer 的大小設(shè)置為此基礎(chǔ)上的 2 倍,也就是 10 MB。
關(guān)于 repl_backlog_buffer 大小修改的方法,只需要修改配置文件里下面這個參數(shù)項的值就可以。
repl-backlog-size 1mb
總結(jié)
主從復(fù)制共有三種模式:全量復(fù)制、基于長連接的命令傳播、增量復(fù)制。
主從服務(wù)器第一次同步的時候,就是采用全量復(fù)制,此時主服務(wù)器會兩個耗時的地方,分別是生成 RDB 文件和傳輸 RDB 文件。為了避免過多的從服務(wù)器和主服務(wù)器進行全量復(fù)制,可以把一部分從服務(wù)器升級為「經(jīng)理角色」,讓它也有自己的從服務(wù)器,通過這樣可以分?jǐn)傊鞣?wù)器的壓力。
第一次同步完成后,主從服務(wù)器都會維護著一個長連接,主服務(wù)器在接收到寫操作命令后,就會通過這個連接將寫命令傳播給從服務(wù)器,來保證主從服務(wù)器的數(shù)據(jù)一致性。
如果遇到網(wǎng)絡(luò)斷開,增量復(fù)制就可以上場了,不過這個還跟 repl_backlog_size 這個大小有關(guān)系。
如果它配置的過小,主從服務(wù)器網(wǎng)絡(luò)恢復(fù)時,可能發(fā)生「從服務(wù)器」想讀的數(shù)據(jù)已經(jīng)被覆蓋了,那么這時就會導(dǎo)致主服務(wù)器采用全量復(fù)制的方式。所以為了避免這種情況的頻繁發(fā)生,要調(diào)大這個參數(shù)的值,以降低主從服務(wù)器斷開后全量同步的概率。
主節(jié)點不但負(fù)責(zé)數(shù)據(jù)讀寫,還負(fù)責(zé)把寫命令同步給從節(jié)點。寫命令的發(fā)送過程是異步完成的,也就是說主節(jié)點自身處理完寫命令后直接返回給客戶端,并不等待從節(jié)點復(fù)制完成,如下圖所示:
哨兵模式
作用
主從切換技術(shù)的方法是:當(dāng)主服務(wù)器宕機后,需要手動把一臺從服務(wù)器切換為主服務(wù)器,這就需要人工干預(yù),費事費力,還會造成一段時間內(nèi)服務(wù)不可用。這不是一種推薦的方式,更多時候,我們優(yōu)先考慮哨兵模式。
單機單個哨兵
哨兵的作用:
- 通過發(fā)送命令,讓Redis服務(wù)器返回監(jiān)控其運行狀態(tài),包括主服務(wù)器和從服務(wù)器。
- 當(dāng)哨兵監(jiān)測到master宕機,會自動將slave切換成master,然后通過發(fā)布訂閱模式通知其他的從服務(wù)器,修改配置文件,讓它們切換主機。
多哨兵模式
Redis的主從復(fù)制模式可以將主節(jié)點的數(shù)據(jù)改變同步給從節(jié)點,這樣從節(jié)點就可以起到兩個作用:
- 作為主節(jié)點的備份,一旦主節(jié)點出了故障不可達(dá)的情況,從節(jié)點可以作為后備“頂上來”,并且保證數(shù)據(jù)盡量不丟失(主從復(fù)制時最終一致性)。第二,從節(jié)點可以擴展主節(jié)點的讀能力,一旦主節(jié)點不能支撐住大并發(fā)量的讀操作
- 第二,從節(jié)點可以擴展主節(jié)點的讀能力,一旦主節(jié)點不能支撐住大并發(fā)量的讀操作,從節(jié)點可以在以頂程度上幫助主節(jié)點分擔(dān)讀壓力
但是主從復(fù)制也帶來了以下問題:
- 一旦主節(jié)點出現(xiàn)故障,需要手動將一個從節(jié)點晉升為主節(jié)點,同時需要修改應(yīng)用方的主節(jié)點地址,還需要命令其他從節(jié)點去復(fù)制新的主節(jié)點,整個過程都需要人工干預(yù)
- 主節(jié)點的寫能力收到單機的限制
- 主節(jié)點的存儲能力收到單機的限制
當(dāng)主節(jié)點出現(xiàn)故障時,Redis的哨兵模式能自動完成故障發(fā)現(xiàn)和故障轉(zhuǎn)移,并通知應(yīng)用方,從而實現(xiàn)真正的高可用。Redis Sentinel是一個分布式架構(gòu),其中包含了若干個Sentinel節(jié)點和Redis數(shù)據(jù)節(jié)點,每個Sentinel節(jié)點會對數(shù)據(jù)節(jié)點和其余Sentinel節(jié)點進行監(jiān)控,當(dāng)它發(fā)現(xiàn)節(jié)點不可達(dá)時,會對節(jié)點但做下線標(biāo)識。如果被標(biāo)識的是主節(jié)點,它還會和其他Sentinel節(jié)點進行“協(xié)商”,當(dāng)大多數(shù)Sentinel節(jié)點都認(rèn)為主節(jié)點不可達(dá)時,它們會選舉出一個Sentinel節(jié)點來完成自動故障轉(zhuǎn)移的工作,同時會將這個變化實時通知給Redis應(yīng)用方。整個過程完全時自動的,不需要人工來介入,所以這套方案很有效地解決了Redis高可用的問題。
哨兵的核心配置
sentinel monitor mymaster 127.0.0.1 6379 1
- 數(shù)字1表示 :當(dāng)一個哨兵主觀認(rèn)為主機斷開,就可以客觀認(rèn)為主機故障,然后開始選舉新的主機。
測試
redis-sentinel xxx/sentinel.conf
成功啟動哨兵模式
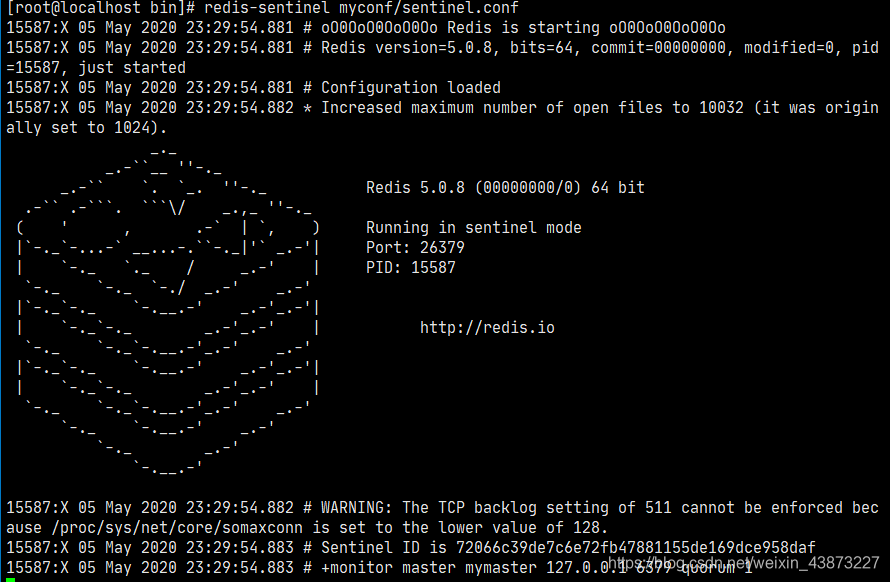
此時哨兵監(jiān)視著我們的主機6379,當(dāng)我們斷開主機后:
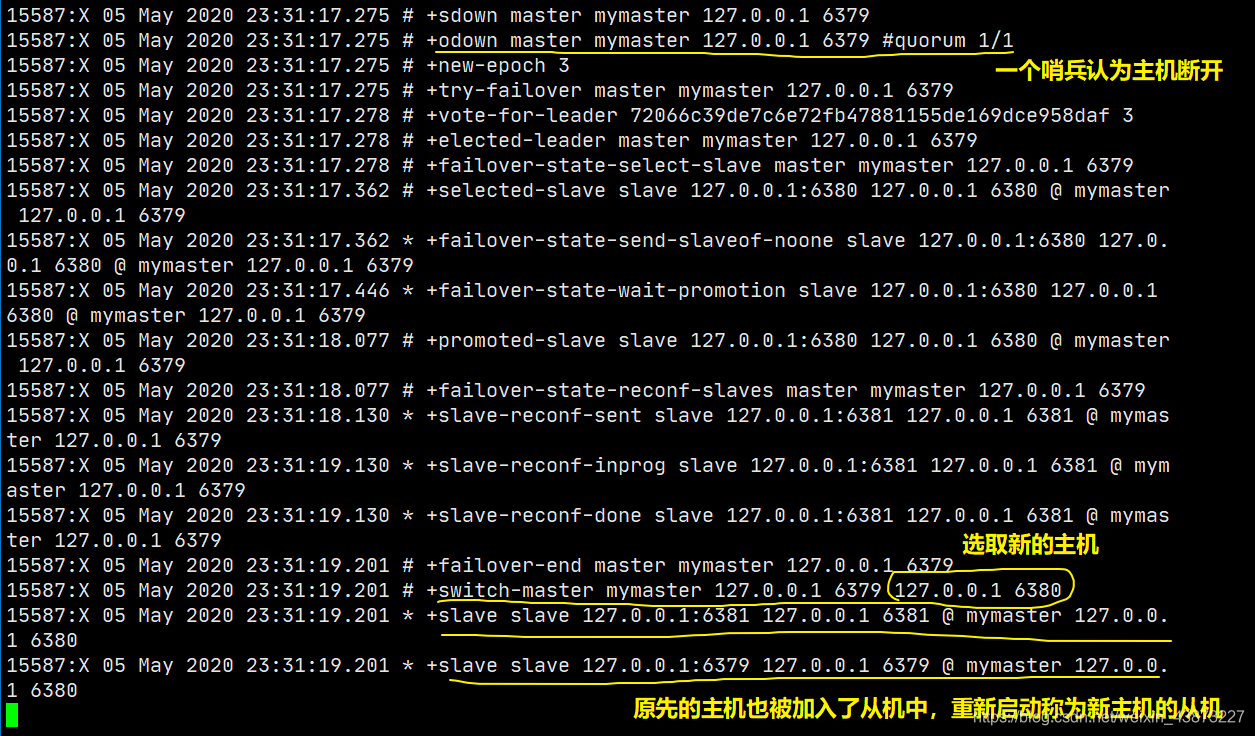
哨兵模式優(yōu)缺點
優(yōu)點
- 哨兵集群,基于主從復(fù)制模式,所有主從復(fù)制的優(yōu)點,它都有
- 主從可以切換,故障可以轉(zhuǎn)移,系統(tǒng)的可用性更好
- 哨兵模式是主從模式的升級,手動到自動,更加健壯
缺點
- Redis不好在線擴容,集群容量一旦達(dá)到上限,在線擴容就十分麻煩
- 實現(xiàn)哨兵模式的配置其實是很麻煩的,里面有很多配置項
完整的哨兵模式配置文件 sentinel.conf
# Example sentinel.conf
# 哨兵sentinel實例運行的端口 默認(rèn)26379
port 26379
# 哨兵sentinel的工作目錄
dir /tmp
# 哨兵sentinel監(jiān)控的redis主節(jié)點的 ip port
# master-name 可以自己命名的主節(jié)點名字 只能由字母A-z、數(shù)字0-9 、這三個字符".-_"組成。
# quorum 當(dāng)這些quorum個數(shù)sentinel哨兵認(rèn)為master主節(jié)點失聯(lián) 那么這時 客觀上認(rèn)為主節(jié)點失聯(lián)了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# 當(dāng)在Redis實例中開啟了requirepass foobared 授權(quán)密碼 這樣所有連接Redis實例的客戶端都要提供密碼
# 設(shè)置哨兵sentinel 連接主從的密碼 注意必須為主從設(shè)置一樣的驗證密碼
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主節(jié)點沒有應(yīng)答哨兵sentinel 此時 哨兵主觀上認(rèn)為主節(jié)點下線 默認(rèn)30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 這個配置項指定了在發(fā)生failover主備切換時最多可以有多少個slave同時對新的master進行 同步,
這個數(shù)字越小,完成failover所需的時間就越長,
但是如果這個數(shù)字越大,就意味著越 多的slave因為replication而不可用。
可以通過將這個值設(shè)為 1 來保證每次只有一個slave 處于不能處理命令請求的狀態(tài)。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障轉(zhuǎn)移的超時時間 failover-timeout 可以用在以下這些方面:
#1. 同一個sentinel對同一個master兩次failover之間的間隔時間。
#2. 當(dāng)一個slave從一個錯誤的master那里同步數(shù)據(jù)開始計算時間。直到slave被糾正為向正確的master那里同步數(shù)據(jù)時。
#3.當(dāng)想要取消一個正在進行的failover所需要的時間。
#4.當(dāng)進行failover時,配置所有slaves指向新的master所需的最大時間。不過,即使過了這個超時,slaves依然會被正確配置為指向master,但是就不按parallel-syncs所配置的規(guī)則來了
# 默認(rèn)三分鐘
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置當(dāng)某一事件發(fā)生時所需要執(zhí)行的腳本,可以通過腳本來通知管理員,例如當(dāng)系統(tǒng)運行不正常時發(fā)郵件通知相關(guān)人員。
#對于腳本的運行結(jié)果有以下規(guī)則:
#若腳本執(zhí)行后返回1,那么該腳本稍后將會被再次執(zhí)行,重復(fù)次數(shù)目前默認(rèn)為10
#若腳本執(zhí)行后返回2,或者比2更高的一個返回值,腳本將不會重復(fù)執(zhí)行。
#如果腳本在執(zhí)行過程中由于收到系統(tǒng)中斷信號被終止了,則同返回值為1時的行為相同。
#一個腳本的最大執(zhí)行時間為60s,如果超過這個時間,腳本將會被一個SIGKILL信號終止,之后重新執(zhí)行。
#通知型腳本:當(dāng)sentinel有任何警告級別的事件發(fā)生時(比如說redis實例的主觀失效和客觀失效等等),將會去調(diào)用這個腳本,
#這時這個腳本應(yīng)該通過郵件,SMS等方式去通知系統(tǒng)管理員關(guān)于系統(tǒng)不正常運行的信息。調(diào)用該腳本時,將傳給腳本兩個參數(shù),
#一個是事件的類型,
#一個是事件的描述。
#如果sentinel.conf配置文件中配置了這個腳本路徑,那么必須保證這個腳本存在于這個路徑,并且是可執(zhí)行的,否則sentinel無法正常啟動成功。
#通知腳本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客戶端重新配置主節(jié)點參數(shù)腳本
# 當(dāng)一個master由于failover而發(fā)生改變時,這個腳本將會被調(diào)用,通知相關(guān)的客戶端關(guān)于master地址已經(jīng)發(fā)生改變的信息。
# 以下參數(shù)將會在調(diào)用腳本時傳給腳本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>總是“failover”,
# <role>是“l(fā)eader”或者“observer”中的一個。
# 參數(shù) from-ip, from-port, to-ip, to-port是用來和舊的master和新的master(即舊的slave)通信的
# 這個腳本應(yīng)該是通用的,能被多次調(diào)用,不是針對性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
Redis當(dāng)中使用了Raft算法實現(xiàn)領(lǐng)導(dǎo)者選舉。
緩存穿透與雪崩
緩存穿透
概念
在默認(rèn)情況下,用戶請求數(shù)據(jù)時,會先在緩存(Redis)中查找,若沒找到即緩存未命中,再在數(shù)據(jù)庫中進行查找,數(shù)量少可能問題不大,可是一旦大量的請求數(shù)據(jù)(例如秒殺場景)緩存都沒有命中的話,就會全部轉(zhuǎn)移到數(shù)據(jù)庫上,造成數(shù)據(jù)庫極大的壓力,就有可能導(dǎo)致數(shù)據(jù)庫崩潰。網(wǎng)絡(luò)安全中也有人惡意使用這種手段進行攻擊被稱為洪水攻擊。
解決方案
布隆過濾器:對所有可能查詢的參數(shù)以Hash的形式存儲,以便快速確定是否存在這個值,在控制層先進行攔截校驗,校驗不通過直接打回,減輕了存儲系統(tǒng)的壓力。
緩存空對象:一次請求若在緩存和數(shù)據(jù)庫中都沒找到,就在緩存中方一個空對象用于處理后續(xù)這個請求。
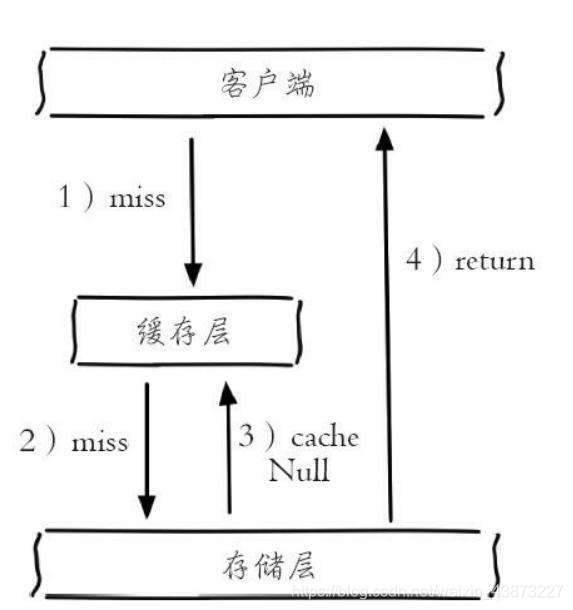
這樣做有一個缺陷:存儲空對象也需要空間,大量的空對象會耗費一定的空間,存儲效率并不高。解決這個缺陷的方式就是設(shè)置較短過期時間
即使對空值設(shè)置了過期時間,還是會存在緩存層和存儲層的數(shù)據(jù)會有一段時間窗口的不一致,這對于需要保持一致性的業(yè)務(wù)會有影響。
緩存擊穿
概念
相較于緩存穿透,緩存擊穿的目的性更強,一個存在的key,在緩存過期的一刻,同時有大量的請求,這些請求都會擊穿到DB,造成瞬時DB請求量大、壓力驟增。這就是緩存被擊穿,只是針對其中某個key的緩存不可用而導(dǎo)致?lián)舸瞧渌膋ey依然可以使用緩存響應(yīng)。
比如熱搜排行上,一個熱點新聞被同時大量訪問就可能導(dǎo)致緩存擊穿。
解決方案
-
設(shè)置熱點數(shù)據(jù)永不過期
這樣就不會出現(xiàn)熱點數(shù)據(jù)過期的情況,但是當(dāng)Redis內(nèi)存空間滿的時候也會清理部分?jǐn)?shù)據(jù),而且此種方案會占用空間,一旦熱點數(shù)據(jù)多了起來,就會占用部分空間。
-
加互斥鎖(分布式鎖)
在訪問key之前,采用SETNX(set if not exists)來設(shè)置另一個短期key來鎖住當(dāng)前key的訪問,訪問結(jié)束再刪除該短期key。保證同時刻只有一個線程訪問。這樣對鎖的要求就十分高。
緩存雪崩
概念
大量的key設(shè)置了相同的過期時間,導(dǎo)致在緩存在同一時刻全部失效,造成瞬時DB請求量大、壓力驟增,引起雪崩。
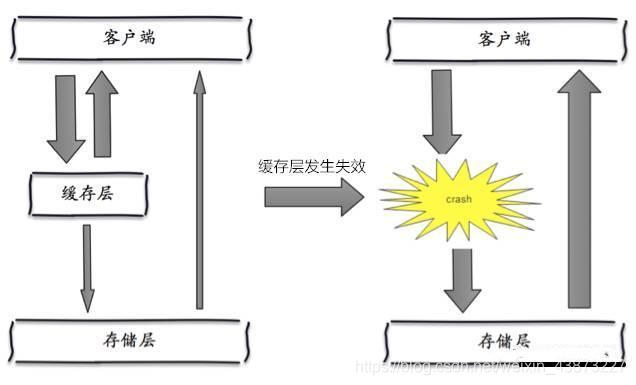
解決方案
-
redis高可用
這個思想的含義是,既然redis有可能掛掉,那我多增設(shè)幾臺redis,這樣一臺掛掉之后其他的還可以繼續(xù)工作,其實就是搭建的集群
-
限流降級
這個解決方案的思想是,在緩存失效后,通過加鎖或者隊列來控制讀數(shù)據(jù)庫寫緩存的線程數(shù)量。比如對某個key只允許一個線程查詢數(shù)據(jù)和寫緩存,其他線程等待。
-
數(shù)據(jù)預(yù)熱
數(shù)據(jù)加熱的含義就是在正式部署之前,我先把可能的數(shù)據(jù)先預(yù)先訪問一遍,這樣部分可能大量訪問的數(shù)據(jù)就會加載到緩存中。在即將發(fā)生大并發(fā)訪問前手動觸發(fā)加載緩存不同的key,設(shè)置不同的過期時間,讓緩存失效的時間點盡量均勻。
為什么需要分布式鎖
我們前面文章synchronized同步鎖的使用與原理中已經(jīng)講過了synchronized的作用及原理,知道了synchronized是一把對象鎖,當(dāng)多個線程并發(fā)操作某個對象時,可以通過synchronized來保證同一時刻只能有一個線程獲取到對象鎖進而處理synchronized關(guān)鍵字修飾的代碼塊或方法。既然已經(jīng)有了synchronized鎖,為什么這里又要引入分布式鎖呢?
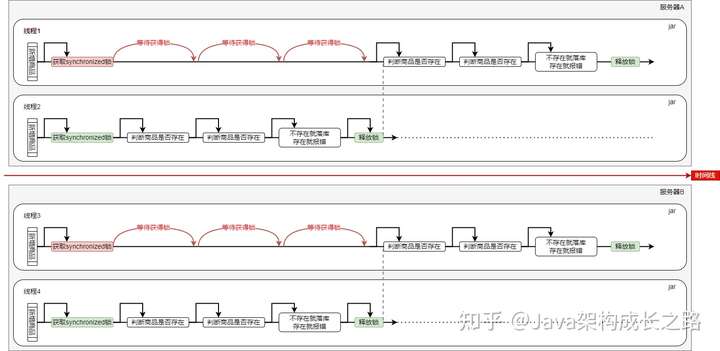
因為現(xiàn)在的系統(tǒng)基本都是分布式部署的,一個應(yīng)用會被部署到多臺服務(wù)器上,synchronized只能控制當(dāng)前服務(wù)器自身的線程安全,并不能跨服務(wù)器控制并發(fā)安全。比如下圖,同一時刻有4個線程新增同一件商品,其中兩個線程由服務(wù)器A處理,另外兩個線程由服務(wù)器B處理,那么最后的結(jié)果就是兩臺服務(wù)器各執(zhí)行了一次新增動作。這顯然不符合預(yù)期。
![img]()
而本篇文章要介紹的分布式鎖就是為了解決這種問題的。
什么是分布式鎖
分布式鎖,就是控制分布式系統(tǒng)中不同進程共同訪問同一共享資源的一種鎖的實現(xiàn)。
所謂當(dāng)局者迷,旁觀者清,先舉個生活中的例子,就拿高鐵舉例,每輛高鐵都有自己的運行路線,但這些路線可能會與其他高鐵的路線重疊,如果只讓高鐵內(nèi)部的司機操控路線,那就可能出現(xiàn)撞車事故,因為司機不知道其他高鐵的運行路線是什么。所以,中控室就發(fā)揮作用了,中控室會監(jiān)控每輛高鐵,高鐵在什么時間走什么樣的路線全部由中控室指揮。
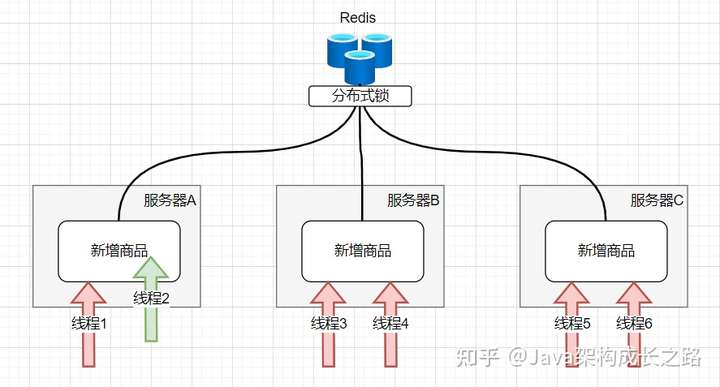
分布式鎖就是基于這種思想實現(xiàn)的,它需要在我們分布式應(yīng)用的外面使用一個第三方組件(可以是數(shù)據(jù)庫、Redis、Zookeeper等)進行全局鎖的監(jiān)控,由這個組件決定什么時候加鎖,什么時候釋放鎖。
![img]()
Redis如何實現(xiàn)分布式鎖
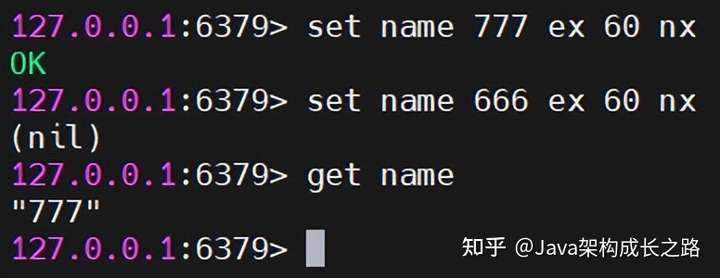
在聊Redis如何實現(xiàn)分布式鎖之前,我們要先聊一下redis的一個命令:setnx key value。我們知道,Redis設(shè)置一個key最常用的命令是:set key value,該命令不管key是否存在,都會將key的值設(shè)置成value,并返回成功:
![img]()
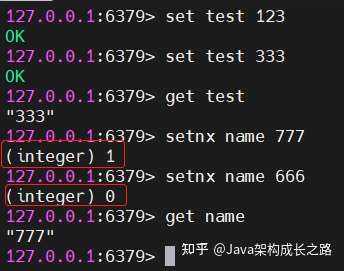
setnx key value 也是設(shè)置key的值為value,不過,它會先判斷key是否已經(jīng)存在,如果key不存在,那么就設(shè)置key的值為value,并返回1;如果key已經(jīng)存在,則不更新key的值,直接返回0:
![img]()
● 最簡單的版本:setnx key value
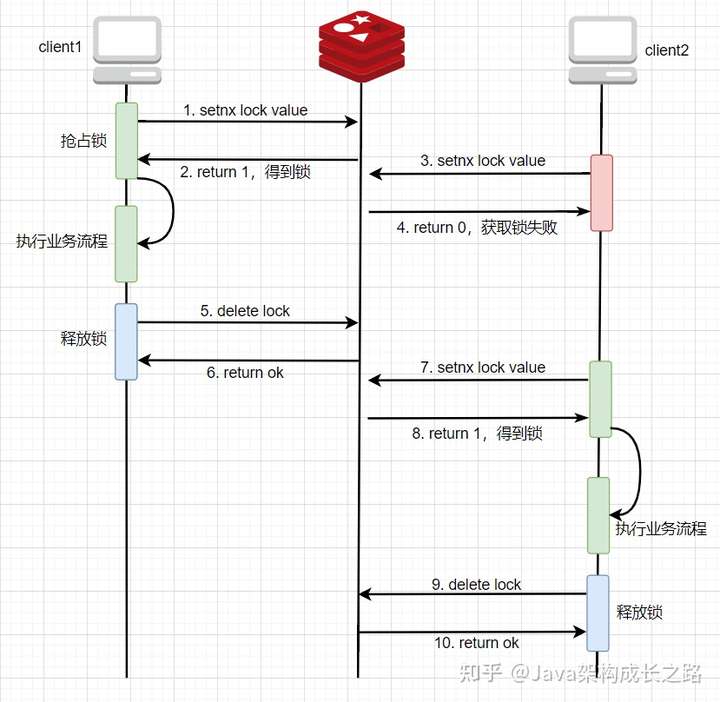
基于setnx命令的特性,我們就可以實現(xiàn)一個最簡單的分布式鎖了。我們通過向Redis發(fā)送 setnx 命令,然后判斷Redis返回的結(jié)果是否為1,結(jié)果是1就表示setnx成功了,那本次就獲得鎖了,可以繼續(xù)執(zhí)行業(yè)務(wù)邏輯;如果結(jié)果是0,則表示setnx失敗了,那本次就沒有獲取到鎖,可以通過循環(huán)的方式一直嘗試獲取鎖,直至其他客戶端釋放了鎖(delete掉key)后,就可以正常執(zhí)行setnx命令獲取到鎖。流程如下:
![img]()
這種方式雖然實現(xiàn)了分布式鎖的功能,但有一個很明顯的問題:沒有給key設(shè)置過期時間,萬一程序在發(fā)送delete命令釋放鎖之前宕機了,那么這個key就會永久的存儲在Redis中了,其他客戶端也永遠(yuǎn)獲取不到這把鎖了。
● 升級版本:設(shè)置key的過期時間
針對上面的問題,我們可以基于setnx key value的基礎(chǔ)上,同時給key設(shè)置一個過期時間。Redis已經(jīng)提供了這樣的命令:set key value ex seconds nx。其中,ex seconds 表示給key設(shè)置過期時間,單位為秒,nx 表示該set命令具備setnx的特性。效果如下:
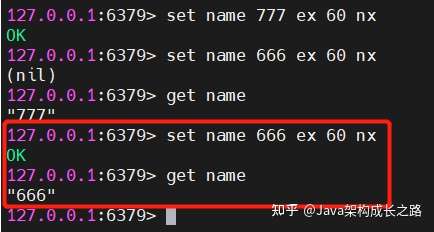
![img]()
我們設(shè)置name的過期時間為60秒,60秒內(nèi)執(zhí)行該set命令時,會直接返回nil。60秒后,我們再執(zhí)行set命令,可以執(zhí)行成功,效果如下:
![img]()
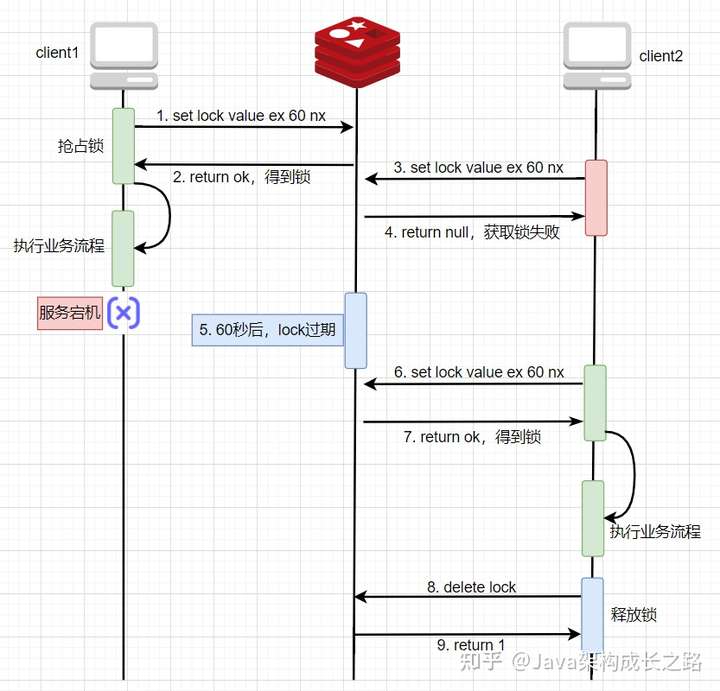
基于這個特性,升級后的分布式鎖流程如下:
![img]()
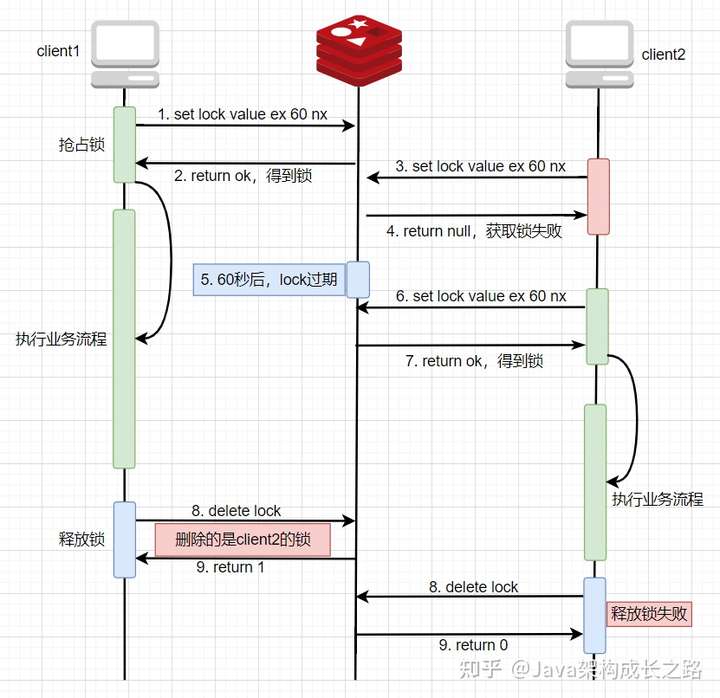
這種方式雖然解決了一些問題,但卻引來了另外一個問題:存在鎖誤刪的情況,也就是把別人加的鎖釋放了。例如,client1獲得鎖之后開始執(zhí)行業(yè)務(wù)處理,但業(yè)務(wù)處理耗時較長,超過了鎖的過期時間,導(dǎo)致業(yè)務(wù)處理還沒結(jié)束時,鎖卻過期自動刪除了(相當(dāng)于屬于client1的鎖被釋放了),此時,client2就會獲取到這把鎖,然后執(zhí)行自己的業(yè)務(wù)處理,也就在此時,client1的業(yè)務(wù)處理結(jié)束了,然后向Redis發(fā)送了delete key的命令來釋放鎖,Redis接收到命令后,就直接將key刪掉了,但此時這個key是屬于client2的,所以,相當(dāng)于client1把client2的鎖給釋放掉了:
![img]()
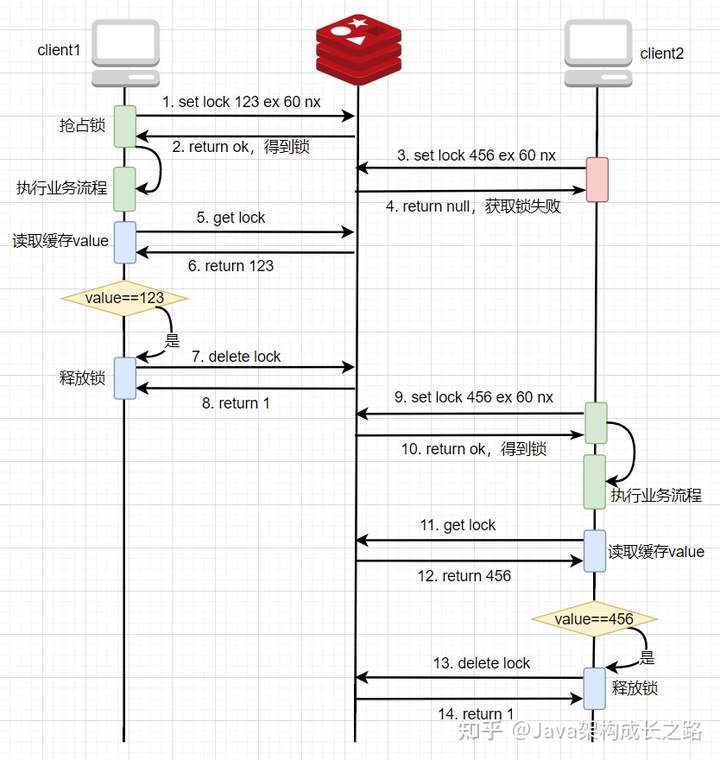
● 二次升級版本:value使用唯一值,刪除鎖時判斷value是否當(dāng)前線程的
要解決上面的問題,最省事的做法就是把鎖的過期時間設(shè)置長一點,要遠(yuǎn)大于業(yè)務(wù)處理時間,但這樣就會嚴(yán)重影響系統(tǒng)的性能,假如一臺服務(wù)器在釋放鎖之前宕機了,而鎖的超時時間設(shè)置了一個小時,那么在這一個小時內(nèi),其他線程訪問這個服務(wù)時就一直阻塞在那里。所以,一般不推薦使用這種方式。
另一種解決方法就是在set key value ex seconds nx時,把value設(shè)置成一個唯一值,每個線程的value都不一樣,在刪除key之前,先通過get key命令得到value,然后判斷value是否是自己線程生成的,如果是,則刪除掉key釋放鎖,如果不是,則不刪除key。正常流程如下:
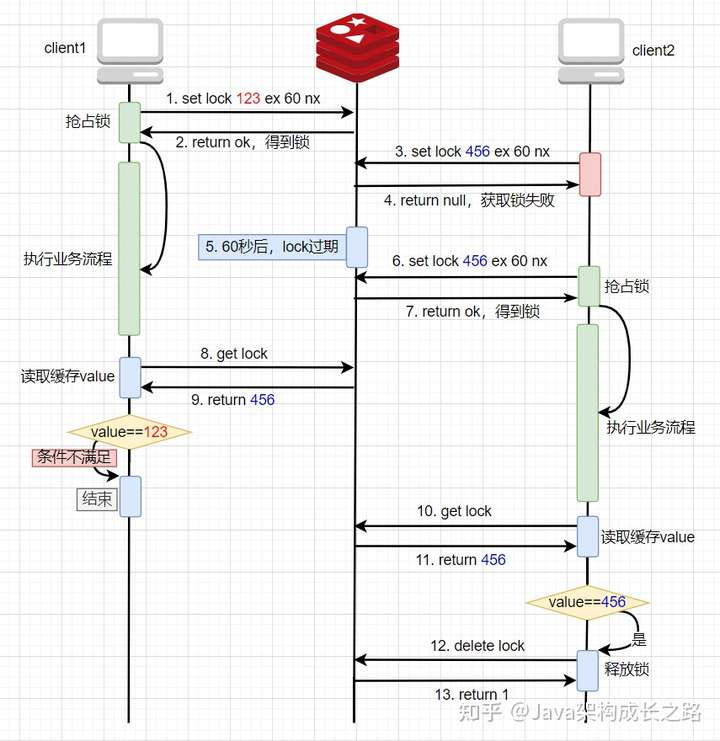
![img]()
當(dāng)業(yè)務(wù)處理還沒結(jié)束的時候,key自動過期了,也可以正常釋放自己的鎖,不影響其他線程:
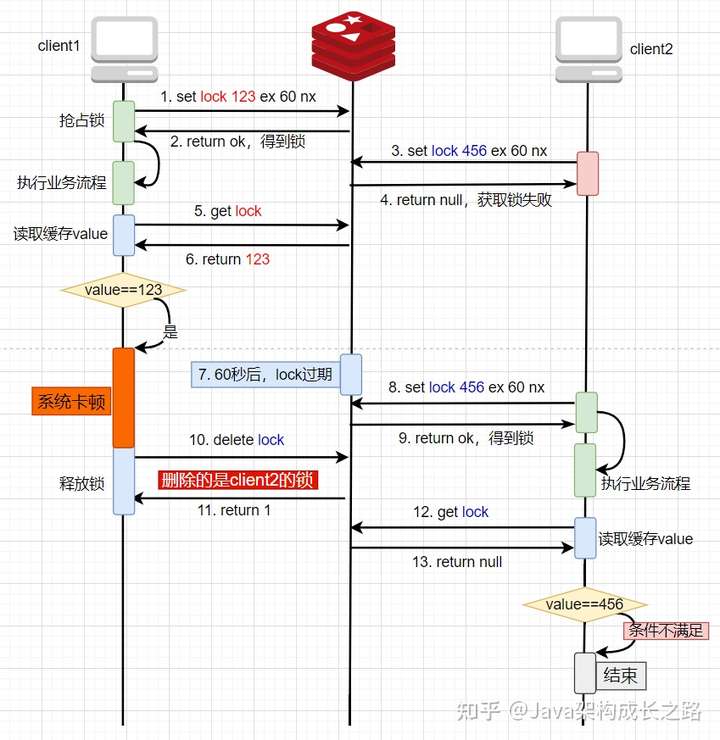
![img]()
二次升級后的方案看起來似乎已經(jīng)沒什么問題了,但其實不然。仔細(xì)分析流程后我們發(fā)現(xiàn),判斷鎖是否屬于當(dāng)前線程和釋放鎖兩個步驟并不是原子操作。正常來說,如果線程1通過get操作從Redis中得到的value是123,那么就會執(zhí)行刪除鎖的操作,但假如在執(zhí)行刪除鎖的動作之前,系統(tǒng)卡頓了幾秒鐘,恰好在這幾秒鐘內(nèi),key自動過期了,線程2就順利獲取到鎖開始執(zhí)行自己的邏輯了,此時,線程1卡頓恢復(fù)了,開始繼續(xù)執(zhí)行刪除鎖的動作,那么此時刪除的還是線程2的鎖。
![img]()
● 終極版本:Lua腳本
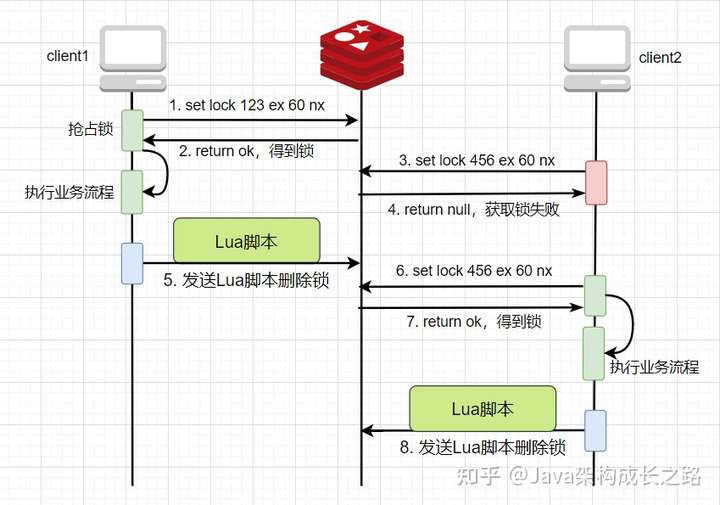
針對上述Redis原始命令無法滿足部分業(yè)務(wù)原子性操作的問題,Redis提供了Lua腳本的支持。Lua腳本是一種輕量小巧的腳本語言,它支持原子性操作,Redis會將整個Lua腳本作為一個整體執(zhí)行,中間不會被其他請求插入,因此Redis執(zhí)行Lua腳本是一個原子操作。
在上面的流程中,我們把get key value、判斷value是否屬于當(dāng)前線程、刪除鎖這三步寫到Lua腳本中,使它們變成一個整體交個Redis執(zhí)行,改造后流程如下:
![img]()
這樣改造之后,就解決了釋放鎖時取值、判斷值、刪除鎖等多個步驟無法保證原子操作的問題了。關(guān)于Lua腳本的語法可以自行學(xué)習(xí),并不復(fù)雜,很簡單,這里就不做過多講述。
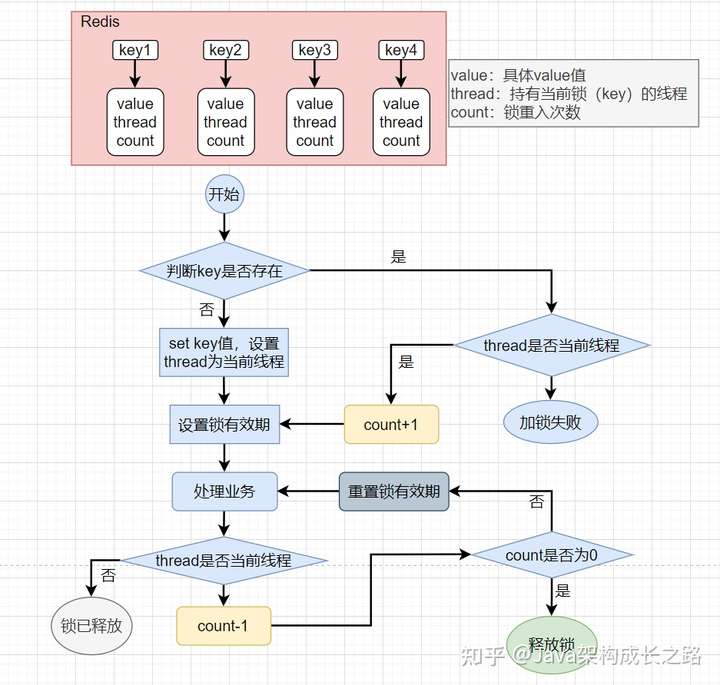
既然Lua腳本可以在釋放鎖時使用,那肯定也能在加鎖時使用,而且一般情況下,推薦使用Lua腳本,因為在使用上面set key value ex seconds nx命令加鎖時,并不能做到重入鎖的效果,也就是當(dāng)一個線程獲取到鎖后,在沒有釋放這把鎖之前,當(dāng)前線程自己也無法再獲得這把鎖,這顯然會影響系統(tǒng)的性能。使用Lua腳本就可以解決這個問題,我們可以在Lua腳本中先判斷鎖(key)是否存在,如果存在則再判斷持有這把鎖的線程是否是當(dāng)前線程,如果不是則加鎖失敗,否則當(dāng)前線程再次持有這把鎖,并把鎖的重入次數(shù)+1。在釋放鎖時,也是先判斷持有鎖的線程是否是當(dāng)前線程,如果是則將鎖的重入次數(shù)-1,直至重入次數(shù)減至0,即可刪除該鎖(key)。
![img]()
實際項目開發(fā)中,其實基本不用自己寫上面這些分布式鎖的實現(xiàn)邏輯,而是使用一些很成熟的第三方工具,當(dāng)下比較流行的就是Redisson,它既提供了Redis的基本命令的封裝,也提供了Redis分布式鎖的封裝,使用非常簡單,只需直接調(diào)用相應(yīng)方法即可。但工具雖然好用,底層原理還是要理解的,這就是本篇文章的目的。
參考文獻
[1] Redis開發(fā)與運維
[2] Raft維基百科

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號