
Mysql筆記
MySQL環(huán)境
環(huán)境安裝
# 查看Linux服務(wù)器上是否安裝過MySQL
rpm -qa | grep -i mysql # 查詢出所有mysql依賴包
# 1、拉取鏡像
docker pull mysql:5.7
# 2、創(chuàng)建實(shí)例并啟動
docker run -p 3306:3306 --name mysql \
-v /root/mysql/log:/var/log/mysql \
-v /root/mysql/data:/var/lib/mysql \
-v /root/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=333 \
-d mysql:5.7
# 3、mysql配置 /root/mysql/conf/my.conf
[client]
#mysqlde utf8字符集默認(rèn)為3位的,不支持emoji表情及部分不常見的漢字,故推薦使用utf8mb4
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
#設(shè)置client連接mysql時的字符集,防止亂碼
init_connect='SET collation_connection = utf8_general_ci'
init_connect='SET NAMES utf8'
#數(shù)據(jù)庫默認(rèn)字符集
character-set-server=utf8
#數(shù)據(jù)庫字符集對應(yīng)一些排序等規(guī)則,注意要和character-set-server對應(yīng)
collation-server=utf8_general_ci
# 跳過mysql程序起動時的字符參數(shù)設(shè)置 ,使用服務(wù)器端字符集設(shè)置
skip-character-set-client-handshake
# 禁止MySQL對外部連接進(jìn)行DNS解析,使用這一選項可以消除MySQL進(jìn)行DNS解析的時間。但需要注意,如果開啟該選項,則所有遠(yuǎn)程主機(jī)連接授權(quán)都要使用IP地址方式,否則MySQL將無法正常處理連接請求!
skip-name-resolve
# 4、重啟mysql容器
docker restart mysql
# 5、進(jìn)入到mysql容器
docker exec -it mysql /bin/bash
# 6、查看修改的配置文件
cat /etc/mysql/my.conf
安裝位置
Docker容器就是一個小型的Linux環(huán)境,進(jìn)入到MySQL容器中。
docker exec -it mysql /bin/bash
Linux環(huán)境下MySQL的安裝目錄。
| 路徑 | 解釋 |
|---|---|
/var/lib/mysql |
MySQL數(shù)據(jù)庫文件存放位置 |
/usr/share/mysql |
錯誤消息和字符集文件配置 |
/usr/bin |
客戶端程序和腳本 |
/etc/init.d/mysql |
啟停腳本相關(guān) |
修改字符集
# 1、進(jìn)入到mysql數(shù)據(jù)庫并查看字符集
# show variables like 'character%';
# show variables like '%char%';
mysql> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
mysql> show variables like '%char%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.01 sec)
MySQL5.7配置文件位置是/etc/my.cnf或者/etc/mysql/my.cnf,如果字符集不是utf-8直接進(jìn)入配置文件修改即可。
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
# 設(shè)置client連接mysql時的字符集,防止亂碼
init_connect='SET NAMES utf8'
init_connect='SET collation_connection = utf8_general_ci'
# 數(shù)據(jù)庫默認(rèn)字符集
character-set-server=utf8
#數(shù)據(jù)庫字符集對應(yīng)一些排序等規(guī)則,注意要和character-set-server對應(yīng)
collation-server=utf8_general_ci
# 跳過mysql程序起動時的字符參數(shù)設(shè)置 ,使用服務(wù)器端字符集設(shè)置
skip-character-set-client-handshake
# 禁止MySQL對外部連接進(jìn)行DNS解析,使用這一選項可以消除MySQL進(jìn)行DNS解析的時間。但需要注意,如果開啟該選項,則所有遠(yuǎn)程主機(jī)連接授權(quán)都要使用IP地址方式,否則MySQL將無法正常處理連接請求!
skip-name-resolve
注意:安裝MySQL完畢之后,第一件事就是修改字符集編碼。
配置文件
MySQL配置文件講解:http://www.rzrgm.cn/gaoyuechen/p/10273102.html
1、二進(jìn)制日志log-bin:主從復(fù)制。
# my,cnf
# 開啟mysql binlog功能
log-bin=mysql-bin
2、錯誤日志log-error:默認(rèn)是關(guān)閉的,記錄嚴(yán)重的警告和錯誤信息,每次啟動和關(guān)閉的詳細(xì)信息等。
# my,cnf
# 數(shù)據(jù)庫錯誤日志文件
log-error = error.log
3、查詢?nèi)罩?code>log:默認(rèn)關(guān)閉,記錄查詢的sql語句,如果開啟會降低MySQL整體的性能,因為記錄日志需要消耗系統(tǒng)資源。
# my,cnf
# 慢查詢sql日志設(shè)置
slow_query_log = 1
slow_query_log_file = slow.log
4、數(shù)據(jù)文件。
frm文件:存放表結(jié)構(gòu)。myd文件:存放表數(shù)據(jù)。myi文件:存放表索引。
# mysql5.7 使用.frm文件來存儲表結(jié)構(gòu)
# 使用 .ibd文件來存儲表索引和表數(shù)據(jù)
-rw-r----- 1 mysql mysql 8988 Jun 25 09:31 pms_category.frm
-rw-r----- 1 mysql mysql 245760 Jul 21 10:01 pms_category.ibd
MySQL5.7的Innodb存儲引擎可將所有數(shù)據(jù)存放于ibdata*的共享表空間,也可將每張表存放于獨(dú)立的.ibd文件的獨(dú)立表空間。
共享表空間以及獨(dú)立表空間都是針對數(shù)據(jù)的存儲方式而言的。
- 共享表空間: 某一個數(shù)據(jù)庫的所有的表數(shù)據(jù),索引文件全部放在一個文件中,默認(rèn)這個共享表空間的文件路徑在
data目錄下。 默認(rèn)的文件名為:ibdata1初始化為10M。 - 獨(dú)立表空間: 每一個表都將會生成以獨(dú)立的文件方式來進(jìn)行存儲,每一個表都有一個
.frm表描述文件,還有一個.ibd文件。 其中這個文件包括了單獨(dú)一個表的數(shù)據(jù)內(nèi)容以及索引內(nèi)容,默認(rèn)情況下它的存儲位置也是在表的位置之中。在配置文件my.cnf中設(shè)置:innodb_file_per_table。
邏輯架構(gòu)
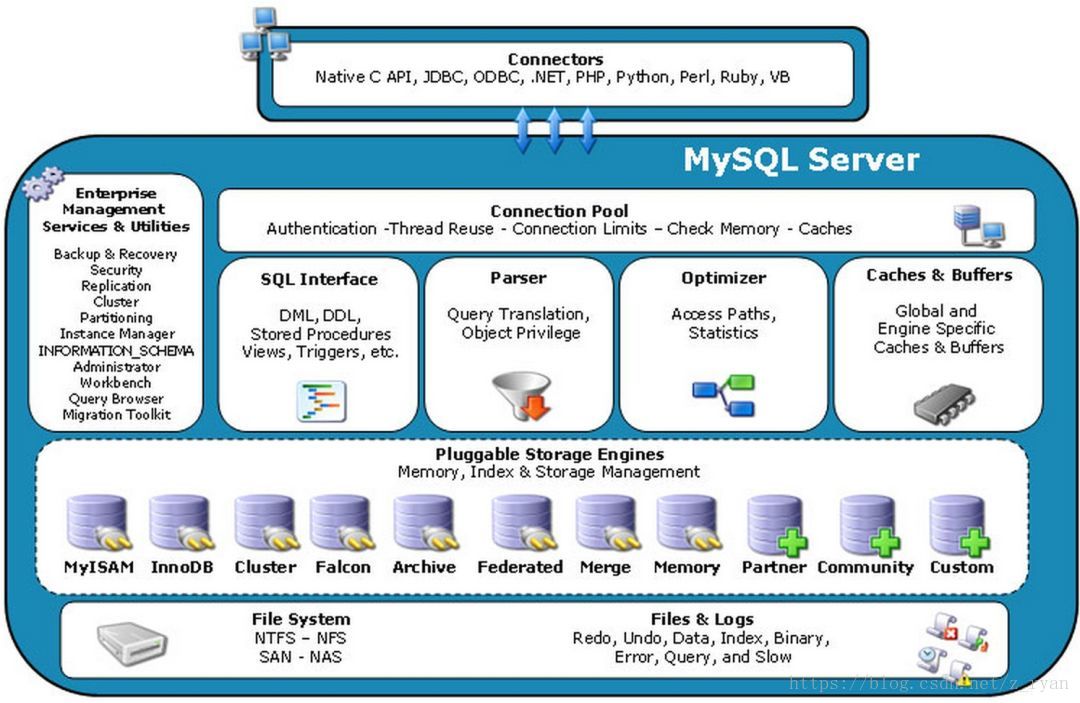
-
Connectors:指的是不同語言中與SQL的交互。 -
Connection Pool:管理緩沖用戶連接,線程處理等需要緩存的需求。MySQL數(shù)據(jù)庫的連接層。 -
Management Serveices & Utilities:系統(tǒng)管理和控制工具。備份、安全、復(fù)制、集群等等。。 -
SQL Interface:接受用戶的SQL命令,并且返回用戶需要查詢的結(jié)果。 -
Parser:SQL語句解析器。 -
Optimizer:查詢優(yōu)化器,SQL語句在查詢之前會使用查詢優(yōu)化器對查詢進(jìn)行優(yōu)化。就是優(yōu)化客戶端請求query,根據(jù)客戶端請求的 query 語句,和數(shù)據(jù)庫中的一些統(tǒng)計信息,在一系列算法的基礎(chǔ)上進(jìn)行分析,得出一個最優(yōu)的策略,告訴后面的程序如何取得這個 query 語句的結(jié)果。For Example:select uid,name from user where gender = 1;這個select查詢先根據(jù)where語句進(jìn)行選取,而不是先將表全部查詢出來以后再進(jìn)行gender過濾;然后根據(jù)uid和name進(jìn)行屬性投影,而不是將屬性全部取出以后再進(jìn)行過濾。最后將這兩個查詢條件聯(lián)接起來生成最終查詢結(jié)果。 -
Caches & Buffers:查詢緩存。 -
Pluggable Storage Engines:存儲引擎接口。MySQL區(qū)別于其他數(shù)據(jù)庫的最重要的特點(diǎn)就是其插件式的表存儲引擎(注意:存儲引擎是基于表的,而不是數(shù)據(jù)庫)。 -
File System:數(shù)據(jù)落地到磁盤上,就是文件的存儲。
MySQL數(shù)據(jù)庫和其他數(shù)據(jù)庫相比,MySQL有點(diǎn)與眾不同,主要體現(xiàn)在存儲引擎的架構(gòu)上,插件式的存儲引擎架構(gòu)將查詢處理和其他的系統(tǒng)任務(wù)以及數(shù)據(jù)的存儲提取相分離。這種架構(gòu)可以根據(jù)業(yè)務(wù)的需求和實(shí)際需求選擇合適的存儲引擎。
邏輯架構(gòu)分層
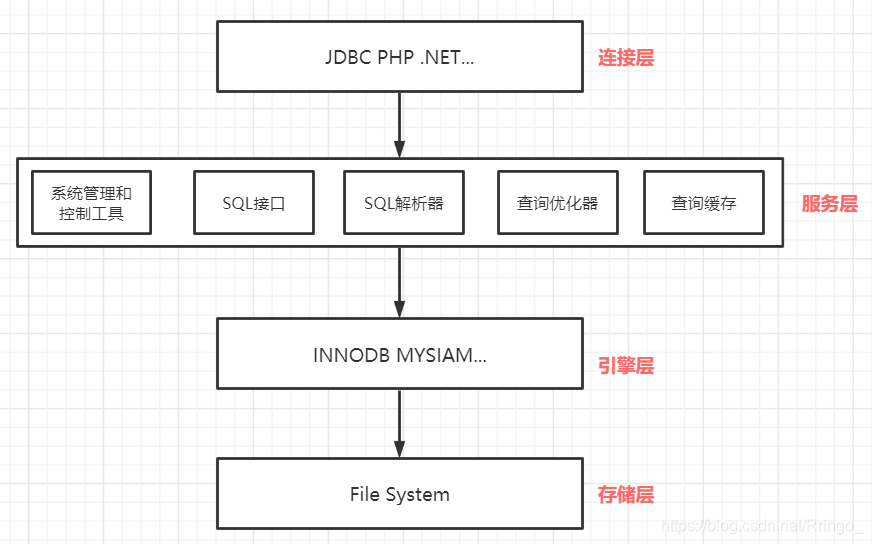
-
連接層:最上層是一些客戶端和連接服務(wù),包含本地sock通信和大多數(shù)基于客戶端/服務(wù)端工具實(shí)現(xiàn)的類似于
tcp/ip的通信。主要完成一些類似于連接處理、授權(quán)認(rèn)證、及相關(guān)的安全方案。在該層上引入了線程池的概念,為通過認(rèn)證安全接入的客戶端提供線程。同樣在該層上可以實(shí)現(xiàn)基于SSL的安全鏈接。服務(wù)器也會為安全接入的每個客戶端驗證它所具有的操作權(quán)限。 -
服務(wù)層:MySQL的核心服務(wù)功能層,該層是MySQL的核心,包括查詢緩存,解析器,解析樹,預(yù)處理器,查詢優(yōu)化器。主要進(jìn)行查詢解析、分析、查詢緩存、內(nèi)置函數(shù)、存儲過程、觸發(fā)器、視圖等,select操作會先檢查是否命中查詢緩存,命中則直接返回緩存數(shù)據(jù),否則解析查詢并創(chuàng)建對應(yīng)的解析樹。
-
引擎層:存儲引擎層,存儲引擎真正的負(fù)責(zé)了MySQL中數(shù)據(jù)的存儲和提取,服務(wù)器通過API與存儲引擎進(jìn)行通信。不同的存儲引擎具有的功能不同,這樣我們可以根據(jù)自己的實(shí)際需要進(jìn)行選取。
-
存儲層:數(shù)據(jù)存儲層,主要是將數(shù)據(jù)存儲在運(yùn)行于裸設(shè)備的文件系統(tǒng)之上,并完成與存儲引擎的交互。
存儲引擎
show engines;命令查看MySQL5.7支持的存儲引擎。
mysql> show engines;
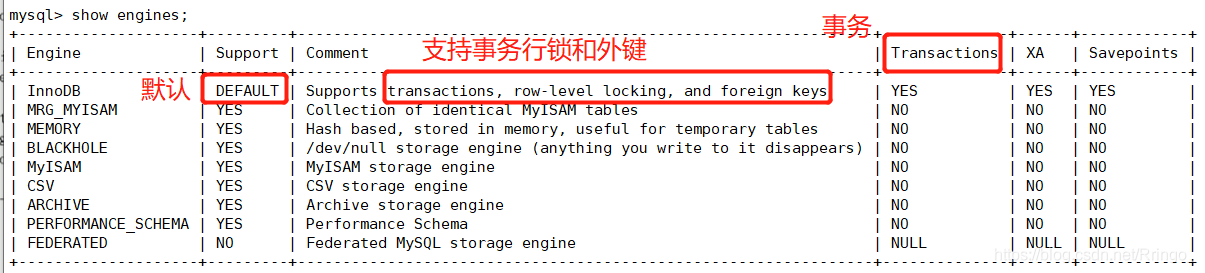
show variables like 'default_storage_engine%';查看當(dāng)前數(shù)據(jù)庫正在使用的存儲引擎。
mysql> show variables like 'default_storage_engine%';
+------------------------+--------+
| Variable_name | Value |
+------------------------+--------+
| default_storage_engine | InnoDB |
+------------------------+--------+
1 row in set (0.01 sec)
InnoDB和MyISAM對比
| 對比項 | MyISAM | InnoDB |
|---|---|---|
| 主外鍵 | 不支持 | 支持 |
| 事務(wù) | 不支持 | 支持 |
| 行表鎖 | 表鎖,即使操作一條記錄也會鎖住整張表,不適合高并發(fā)操作 | 行鎖,操作時只鎖某一行,不對其他行有影響,適合高并發(fā)操作 |
| 緩存 | 只緩存索引,不緩存真實(shí)數(shù)據(jù) | 不僅緩存索引還要緩存真實(shí)數(shù)據(jù),対內(nèi)存要求較高,而且內(nèi)存大小対性能有決定性影響 |
| 表空間 | 小 | 大 |
| 關(guān)注點(diǎn) | 性能 | 事務(wù) |
| 默認(rèn)安裝 | Y | Y |
SQL性能下降的原因
- 查詢語句寫的差。
- 索引失效:索引建了,但是沒有用上。是否是最優(yōu)索引
- 關(guān)聯(lián) 查詢太多
join(設(shè)計缺陷或者不得已的需求)。 - 表中數(shù)據(jù)是否過多,是否進(jìn)行分庫分表
- 是否查詢了多余的字段
- 服務(wù)器調(diào)優(yōu)以及各個參數(shù)的設(shè)置(緩沖、線程數(shù)等)。
SQL執(zhí)行順序
select # 5
...
from # 1
...
where # 2
....
group by # 3
...
having # 4
...
order by # 6
...
limit # 7
[offset]
七種JOIN理論

/* 1 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key;
/* 2 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 3 */
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.Key = B.Key;
/* 4 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
/* 5 */
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
/* 6 */
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key;
/* MySQL不支持FULL OUTER JOIN這種語法 可以改成 1+2 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key;
/* 7 */
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL OR B.Key IS NULL;
/* MySQL不支持FULL OUTER JOIN這種語法 可以改成 4+5 */
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
UNION
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
索引
索引簡介
索引是什么?
MySQL官方對索引的定義為:索引(INDEX)是幫助MySQL高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)果。
從而可以獲得索引的本質(zhì):索引是排好序的快速查找數(shù)據(jù)結(jié)構(gòu)。
索引的目的在于提高查詢效率,可以類比字典的目錄。如果要查mysql這個這個單詞,我們肯定要先定位到m字母,然后從上往下找y字母,再找剩下的sql。如果沒有索引,那么可能需要a---z,這樣全字典掃描,如果我想找Java開頭的單詞呢?如果我想找Oracle開頭的單詞呢???
重點(diǎn):索引會影響到MySQL查找(WHERE的查詢條件)和排序(ORDER BY)兩大功能!
除了數(shù)據(jù)本身之外,數(shù)據(jù)庫還維護(hù)著一個滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式指向數(shù)據(jù),這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)的基礎(chǔ)上實(shí)現(xiàn)高級查找算法,這種數(shù)據(jù)結(jié)構(gòu)就是索引。
一般來說,索引本身也很大,不可能全部存儲在內(nèi)存中,因此索引往往以索引文件的形式存儲在磁盤上。
# Linux下查看磁盤空間命令 df -h
[root@Ringo ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 16G 23G 41% /
devtmpfs 911M 0 911M 0% /dev
tmpfs 920M 0 920M 0% /dev/shm
tmpfs 920M 480K 920M 1% /run
tmpfs 920M 0 920M 0% /sys/fs/cgroup
overlay 40G 16G 23G 41%
我們平時所說的索引,如果沒有特別指明,都是指B樹(多路搜索樹,并不一定是二叉的)結(jié)構(gòu)組織的索引。其中聚集索引,次要索引,覆蓋索引,復(fù)合索引,前綴索引,唯一索引默認(rèn)都是使用B+樹索引,統(tǒng)稱索引。當(dāng)然,除了B+樹這種數(shù)據(jù)結(jié)構(gòu)的索引之外,還有哈希索引(Hash Index)等。
索引的優(yōu)勢和劣勢
優(yōu)勢:
- 查找:類似大學(xué)圖書館的書目索引,提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫的IO成本。
- 排序:通過索引対數(shù)據(jù)進(jìn)行排序,降低數(shù)據(jù)排序的成本,降低了CPU的消耗。
劣勢:
- 實(shí)際上索引也是一張表,該表保存了主鍵與索引字段,并指向?qū)嶓w表的記錄,所以索引列也是要占用空間的。
- 雖然索引大大提高了查詢速度,但是同時會降低表的更新速度,例如對表頻繁的進(jìn)行
INSERT、UPDATE和DELETE。因為更新表的時候,MySQL不僅要保存數(shù)據(jù),還要保存一下索引文件每次更新添加的索引列的字段,都會調(diào)整因為更新所帶來的鍵值變化后的索引信息。 - 索引只是提高效率的一個因素,如果MySQL有大數(shù)據(jù)量的表,就需要花時間研究建立最優(yōu)秀的索引。
MySQL索引分類
索引分類:
- 單值索引:一個索引只包含單個列,一個表可以有多個單列索引。
- 唯一索引:索引列的值必須唯一,但是允許空值。
- 復(fù)合索引:一個索引包含多個字段。
建議:一張表建的索引最好不要超過5個!
/* 基本語法 */
/* 1、創(chuàng)建索引 [UNIQUE]可以省略*/
/* 如果只寫一個字段就是單值索引,寫多個字段就是復(fù)合索引 */
CREATE [UNIQUE] INDEX indexName ON tabName(columnName(length));
/* 2、刪除索引 */
DROP INDEX [indexName] ON tabName;
/* 3、查看索引 */
/* 加上\G就可以以列的形式查看了 不加\G就是以表的形式查看 */
SHOW INDEX FROM tabName \G;
使用ALTER命令來為數(shù)據(jù)表添加索引
/* 1、該語句添加一個主鍵,這意味著索引值必須是唯一的,并且不能為NULL */
ALTER TABLE tabName ADD PRIMARY KEY(column_list);
/* 2、該語句創(chuàng)建索引的鍵值必須是唯一的(除了NULL之外,NULL可能會出現(xiàn)多次) */
ALTER TABLE tabName ADD UNIQUE indexName(column_list);
/* 3、該語句創(chuàng)建普通索引,索引值可以出現(xiàn)多次 */
ALTER TABLE tabName ADD INDEX indexName(column_list);
/* 4、該語句指定了索引為FULLTEXT,用于全文檢索 */
ALTER TABLE tabName ADD FULLTEXT indexName(column_list);
MySQL索引數(shù)據(jù)結(jié)構(gòu)
索引數(shù)據(jù)結(jié)構(gòu):
BTree索引。Hash索引。Full-text全文索引。R-Tree索引。
BTree索引檢索原理:
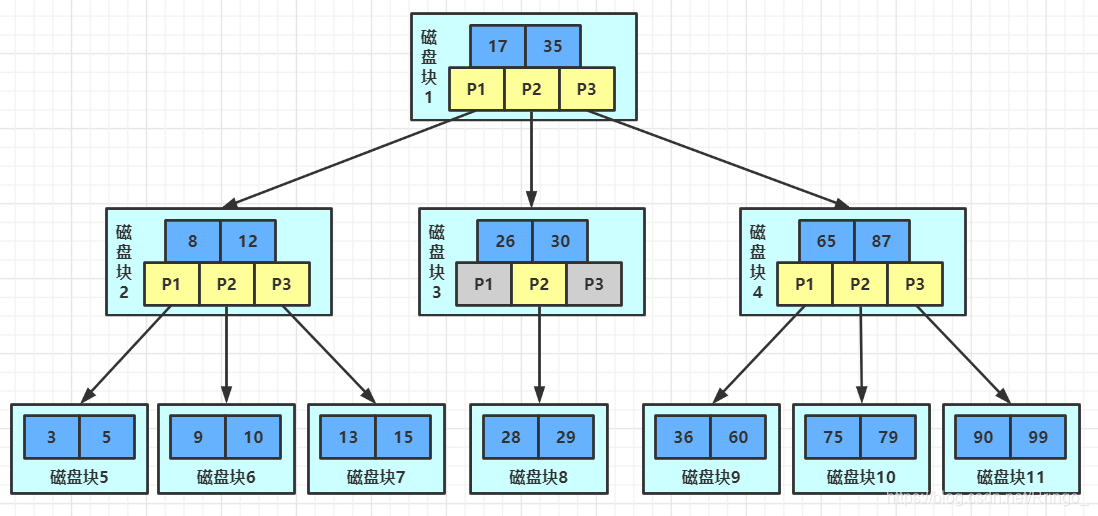
哪些情況需要建索引
- 主鍵自動建立主鍵索引(唯一 + 非空)。
- 頻繁作為查詢條件的字段應(yīng)該創(chuàng)建索引。
- 查詢中與其他表關(guān)聯(lián)的字段,外鍵關(guān)系建立索引。
- 查詢中排序的字段,排序字段若通過索引去訪問將大大提高排序速度。
- 查詢中統(tǒng)計或者分組字段(group by也和索引有關(guān))。p-
那些情況不要建索引
-
記錄太少的表。
-
經(jīng)常增刪改的表。
-
頻繁更新的字段不適合創(chuàng)建索引。
-
Where條件里用不到的字段不創(chuàng)建索引。
-
假如一個表有10萬行記錄,有一個字段A只有true和false兩種值,并且每個值的分布概率大約為50%,那么對A字段建索引一般不會提高數(shù)據(jù)庫的查詢速度。索引的選擇性是指索引列中不同值的數(shù)目與表中記錄數(shù)的比。如果一個表中有2000條記錄,表索引列有1980個不同的值,那么這個索引的選擇性就是1980/2000=0.99。一個索引的選擇性越接近于1,這個索引的效率就越高。
性能分析
EXPLAIN簡介
EXPLAIN是什么?
EXPLAIN:SQL的執(zhí)行計劃,使用EXPLAIN關(guān)鍵字可以模擬優(yōu)化器執(zhí)行SQL查詢語句,從而知道MySQL是如何處理SQL語句的。
EXPLAIN怎么使用?
語法:explain + SQL。
mysql> explain select * from pms_category \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pms_category
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1425
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
EXPLAIN能干嘛?
可以查看以下信息:
id:表的讀取順序。select_type:數(shù)據(jù)讀取操作的操作類型。possible_keys:哪些索引可以使用。key:哪些索引被實(shí)際使用。ref:表之間的引用。rows:每張表有多少行被優(yōu)化器查詢。
EXPLAIN字段
id
id:表的讀取和加載順序。
值有以下三種情況:
id相同,執(zhí)行順序由上至下。id不同,如果是子查詢,id的序號會遞增,id值越大優(yōu)先級越高,越先被執(zhí)行。id相同不同,同時存在。永遠(yuǎn)是id大的優(yōu)先級最高,id相等的時候順序執(zhí)行。
select_type
select_type:數(shù)據(jù)查詢的類型,主要是用于區(qū)別,普通查詢、聯(lián)合查詢、子查詢等的復(fù)雜查詢。
SIMPLE:簡單的SELECT查詢,查詢中不包含子查詢或者UNION。PRIMARY:查詢中如果包含任何復(fù)雜的子部分,最外層查詢則被標(biāo)記為PRIMARY。SUBQUERY:在SELECT或者WHERE子句中包含了子查詢。DERIVED:在FROM子句中包含的子查詢被標(biāo)記為DERIVED(衍生),MySQL會遞歸執(zhí)行這些子查詢,把結(jié)果放在臨時表中。UNION:如果第二個SELECT出現(xiàn)在UNION之后,則被標(biāo)記為UNION;若UNION包含在FROM子句的子查詢中,外層SELECT將被標(biāo)記為DERIVED。UNION RESULT:從UNION表獲取結(jié)果的SELECT。
type
type:訪問類型排列。
從最好到最差依次是:system>const>eq_ref>ref>range>index>ALL。除了ALL沒有用到索引,其他級別都用到索引了。
一般來說,得保證查詢至少達(dá)到range級別,最好達(dá)到ref。
-
system:表只有一行記錄(等于系統(tǒng)表),這是const類型的特例,平時不會出現(xiàn),這個也可以忽略不計。 -
const:表示通過索引一次就找到了,const用于比較primary key或者unique索引。因為只匹配一行數(shù)據(jù),所以很快。如將主鍵置于where列表中,MySQL就能將該查詢轉(zhuǎn)化為一個常量。 -
eq_ref:唯一性索引掃描,讀取本表中和關(guān)聯(lián)表表中的每行組合成的一行,查出來只有一條記錄。除 了system和const類型之外, 這是最好的聯(lián)接類型。 -
ref:非唯一性索引掃描,返回本表和關(guān)聯(lián)表某個值匹配的所有行,查出來有多條記錄。 -
range:只檢索給定范圍的行,一般就是在WHERE語句中出現(xiàn)了BETWEEN、< >、in等的查詢。這種范圍掃描索引比全表掃描要好,因為它只需要開始于索引樹的某一點(diǎn),而結(jié)束于另一點(diǎn),不用掃描全部索引。 -
index:Full Index Scan,全索引掃描,index和ALL的區(qū)別為index類型只遍歷索引樹。也就是說雖然ALL和index都是讀全表,但是index是從索引中讀的,ALL是從磁盤中讀取的。 -
ALL:Full Table Scan,沒有用到索引,全表掃描。
possible_keys 和 key
possible_keys:顯示可能應(yīng)用在這張表中的索引,一個或者多個。查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢實(shí)際使用。
key:實(shí)際使用的索引。如果為NULL,則沒有使用索引。查詢中如果使用了覆蓋索引,則該索引僅僅出現(xiàn)在key列表中。
key_len
key_len:表示索引中使用的字節(jié)數(shù),可通過該列計算查詢中使用的索引的長度。key_len顯示的值為索引字段的最大可能長度,并非實(shí)際使用長度,即key_len是根據(jù)表定義計算而得,不是通過表內(nèi)檢索出的。在不損失精度的情況下,長度越短越好。
key_len計算規(guī)則:https://blog.csdn.net/qq_34930488/article/details/102931490
mysql> desc pms_category;
+---------------+------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+------------+------+-----+---------+----------------+
| cat_id | bigint(20) | NO | PRI | NULL | auto_increment |
| name | char(50) | YES | | NULL | |
| parent_cid | bigint(20) | YES | | NULL | |
| cat_level | int(11) | YES | | NULL | |
| show_status | tinyint(4) | YES | | NULL | |
| sort | int(11) | YES | | NULL | |
| icon | char(255) | YES | | NULL | |
| product_unit | char(50) | YES | | NULL | |
| product_count | int(11) | YES | | NULL | |
+---------------+------------+------+-----+---------+----------------+
9 rows in set (0.00 sec)
mysql> explain select cat_id from pms_category where cat_id between 10 and 20 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pms_category
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY # 用到了主鍵索引,通過查看表結(jié)構(gòu)知道,cat_id是bigint類型,占用8個字節(jié)
key_len: 8 # 這里只用到了cat_id主鍵索引,所以長度就是8!
ref: NULL
rows: 11
filtered: 100.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
ref
ref:顯示索引的哪一列被使用了,如果可能的話,是一個常數(shù)。哪些列或常量被用于查找索引列上的值。
rows
rows:根據(jù)表統(tǒng)計信息及索引選用情況,大致估算出找到所需的記錄需要讀取的行數(shù)。
Extra
Extra:包含不適合在其他列中顯示但十分重要的額外信息。
Using filesort:說明MySQL會對數(shù)據(jù)使用一個外部的索引排序,而不是按照表內(nèi)的索引順序進(jìn)行讀取。MySQL中無法利用索引完成的排序操作成為"文件內(nèi)排序"。
# 排序沒有使用索引
mysql> explain select name from pms_category where name='Tangs' order by cat_level \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pms_category
partitions: NULL
type: ref
possible_keys: idx_name_parentCid_catLevel
key: idx_name_parentCid_catLevel
key_len: 201
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Using index; Using filesort
1 row in set, 1 warning (0.00 sec)
#~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
# 排序使用到了索引
mysql> explain select name from pms_category where name='Tangs' order by parent_cid,cat_level\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pms_category
partitions: NULL
type: ref
possible_keys: idx_name_parentCid_catLevel
key: idx_name_parentCid_catLevel
key_len: 201
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
-
Using temporary:使用了臨時表保存中間結(jié)果,MySQL在対查詢結(jié)果排序時使用了臨時表。常見于排序order by和分組查詢group by。臨時表対系統(tǒng)性能損耗很大。 -
Using index:表示相應(yīng)的SELECT操作中使用了覆蓋索引,避免訪問了表的數(shù)據(jù)行,效率不錯!如果同時出現(xiàn)Using where,表示索引被用來執(zhí)行索引鍵值的查找;如果沒有同時出現(xiàn)Using where,表明索引用來讀取數(shù)據(jù)而非執(zhí)行查找動作。
# 覆蓋索引
# 就是select的數(shù)據(jù)列只用從索引中就能夠取得,不必從數(shù)據(jù)表中讀取,換句話說查詢列要被所使用的索引覆蓋。
# 注意:如果要使用覆蓋索引,一定不能寫SELECT *,要寫出具體的字段。
mysql> explain select cat_id from pms_category \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pms_category
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 8
ref: NULL
rows: 1425
filtered: 100.00
Extra: Using index # select的數(shù)據(jù)列只用從索引中就能夠取得,不必從數(shù)據(jù)表中讀取
1 row in set, 1 warning (0.00 sec)
Using where:表明使用了WHERE過濾。Using join buffer:使用了連接緩存。impossible where:WHERE子句的值總是false,不能用來獲取任何元組。
mysql> explain select name from pms_category where name = 'zs' and name = 'ls'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Impossible WHERE # 不可能字段同時查到兩個名字
1 row in set, 1 warning (0.00 sec)
索引分析
單表索引分析
數(shù)據(jù)準(zhǔn)備
DROP TABLE IF EXISTS `article`;
CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主鍵',
`author_id` INT(10) UNSIGNED NOT NULL COMMENT '作者id',
`category_id` INT(10) UNSIGNED NOT NULL COMMENT '分類id',
`views` INT(10) UNSIGNED NOT NULL COMMENT '被查看的次數(shù)',
`comments` INT(10) UNSIGNED NOT NULL COMMENT '回帖的備注',
`title` VARCHAR(255) NOT NULL COMMENT '標(biāo)題',
`content` VARCHAR(255) NOT NULL COMMENT '正文內(nèi)容'
) COMMENT '文章';
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,1,1,'1','1');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(2,2,2,2,'2','2');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(3,3,3,3,'3','3');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,3,3,'3','3');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,4,4,'4','4');
案例:查詢
category_id為1且comments大于1的情況下,views最多的article_id。
1、編寫SQL語句并查看SQL執(zhí)行計劃。
# 1、sql語句
SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
# 2、sql執(zhí)行計劃
mysql> EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: article
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5
filtered: 20.00
Extra: Using where; Using filesort # 產(chǎn)生了文件內(nèi)排序,需要優(yōu)化SQL
1 row in set, 1 warning (0.00 sec)
2、創(chuàng)建索引idx_article_ccv。
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);
3、查看當(dāng)前索引。

4、查看現(xiàn)在SQL語句的執(zhí)行計劃。

我們發(fā)現(xiàn),創(chuàng)建符合索引idx_article_ccv之后,雖然解決了全表掃描的問題,但是在order by排序的時候沒有用到索引,MySQL居然還是用的Using filesort,為什么?
5、我們試試把SQL修改為SELECT id,author_id FROM article WHERE category_id = 1 AND comments = 1 ORDER BY views DESC LIMIT 1;看看SQL的執(zhí)行計劃。

推論:當(dāng)comments > 1的時候order by排序views字段索引就用不上,但是當(dāng)comments = 1的時候order by排序views字段索引就可以用上!!!所以,范圍之后的索引會失效。
6、我們現(xiàn)在知道范圍之后的索引會失效,原來的索引idx_article_ccv最后一個字段views會失效,那么我們?nèi)绻麆h除這個索引,創(chuàng)建idx_article_cv索引呢????
/* 創(chuàng)建索引 idx_article_cv */
CREATE INDEX idx_article_cv ON article(category_id,views);
查看當(dāng)前的索引

7、當(dāng)前索引是idx_article_cv,來看一下SQL執(zhí)行計劃。

兩表索引分析
數(shù)據(jù)準(zhǔn)備
DROP TABLE IF EXISTS `class`;
DROP TABLE IF EXISTS `book`;
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主鍵',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分類'
) COMMENT '商品類別';
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主鍵',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分類'
) COMMENT '書籍';
兩表連接查詢的SQL執(zhí)行計劃
1、不創(chuàng)建索引的情況下,SQL的執(zhí)行計劃。

book和class兩張表都是沒有使用索引,全表掃描,那么如果進(jìn)行優(yōu)化,索引是創(chuàng)建在book表還是創(chuàng)建在class表呢?下面進(jìn)行大膽的嘗試!
2、左表(book表)創(chuàng)建索引。
創(chuàng)建索引idx_book_card
/* 在book表創(chuàng)建索引 */
CREATE INDEX idx_book_card ON book(card);
在book表中有idx_book_card索引的情況下,查看SQL執(zhí)行計劃

3、刪除book表的索引,右表(class表)創(chuàng)建索引。
創(chuàng)建索引idx_class_card
/* 在class表創(chuàng)建索引 */
CREATE INDEX idx_class_card ON class(card);
在class表中有idx_class_card索引的情況下,查看SQL執(zhí)行計劃

由此可見,左連接將索引創(chuàng)建在右表上更合適,右連接將索引創(chuàng)建在左表上更合適。
三張表索引分析
數(shù)據(jù)準(zhǔn)備
DROP TABLE IF EXISTS `phone`;
CREATE TABLE IF NOT EXISTS `phone`(
`phone_id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主鍵',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分類'
) COMMENT '手機(jī)';
三表連接查詢SQL優(yōu)化
1、不加任何索引,查看SQL執(zhí)行計劃。

2、根據(jù)兩表查詢優(yōu)化的經(jīng)驗,左連接需要在右表上添加索引,所以嘗試在book表和phone表上添加索引。
/* 在book表創(chuàng)建索引 */
CREATE INDEX idx_book_card ON book(card);
/* 在phone表上創(chuàng)建索引 */
CREATE INDEX idx_phone_card ON phone(card);
再次執(zhí)行SQL的執(zhí)行計劃

結(jié)論
JOIN語句的優(yōu)化:
- 盡可能減少
JOIN語句中的NestedLoop(嵌套循環(huán))的總次數(shù):永遠(yuǎn)都是小的結(jié)果集驅(qū)動大的結(jié)果集。 - 優(yōu)先優(yōu)化
NestedLoop的內(nèi)層循環(huán)。 - 保證
JOIN語句中被驅(qū)動表上JOIN條件字段已經(jīng)被索引。 - 當(dāng)無法保證被驅(qū)動表的
JOIN條件字段被索引且內(nèi)存資源充足的前提下,不要太吝惜Join Buffer的設(shè)置。
索引失效
數(shù)據(jù)準(zhǔn)備
CREATE TABLE `staffs`(
`id` INT(10) PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` INT(10) NOT NULL DEFAULT 0 COMMENT '年齡',
`pos` VARCHAR(20) NOT NULL DEFAULT '' COMMENT '職位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入職時間'
)COMMENT '員工記錄表';
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('Ringo', 18, 'manager');
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('張三', 20, 'dev');
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('李四', 21, 'dev');
/* 創(chuàng)建索引 */
CREATE INDEX idx_staffs_name_age_pos ON `staffs`(`name`,`age`,`pos`);
索引失效的情況
- 全值匹配我最愛。
- 最佳左前綴法則。
- 不在索引列上做任何操作(計算、函數(shù)、(自動or手動)類型轉(zhuǎn)換),會導(dǎo)致索引失效而轉(zhuǎn)向全表掃描。
- 索引中范圍條件右邊的字段會全部失效。
- 盡量使用覆蓋索引(只訪問索引的查詢,索引列和查詢列一致),減少
SELECT *。 - MySQL在使用
!=或者<>的時候無法使用索引會導(dǎo)致全表掃描。 is null、is not null也無法使用索引。like以通配符開頭%abc索引失效會變成全表掃描(使用覆蓋索引就不會全表掃描了)。- 字符串不加單引號索引失效。
- 少用
or,用它來連接時會索引失效。
最佳左前綴法則
案例
/* 用到了idx_staffs_name_age_pos索引中的name字段 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo';
/* 用到了idx_staffs_name_age_pos索引中的name, age字段 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18;
/* 用到了idx_staffs_name_age_pos索引中的name,age,pos字段 這是屬于全值匹配的情況!!!*/
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 索引沒用上,ALL全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `age` = 18 AND `pos` = 'manager';
/* 索引沒用上,ALL全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `pos` = 'manager';
/* 用到了idx_staffs_name_age_pos索引中的name字段,pos字段索引失效 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `pos` = 'manager';
概念
最佳左前綴法則:如果索引是多字段的復(fù)合索引,要遵守最佳左前綴法則。指的是查詢從索引的最左前列開始并且不跳過索引中的字段。
口訣:帶頭大哥不能死,中間兄弟不能斷。
索引列上不計算
案例
# 現(xiàn)在要查詢`name` = 'Ringo'的記錄下面有兩種方式來查詢!
# 1、直接使用 字段 = 值的方式來計算
mysql> SELECT * FROM `staffs` WHERE `name` = 'Ringo';
+----+-------+-----+---------+---------------------+
| id | name | age | pos | add_time |
+----+-------+-----+---------+---------------------+
| 1 | Ringo | 18 | manager | 2020-08-03 08:30:39 |
+----+-------+-----+---------+---------------------+
1 row in set (0.00 sec)
# 2、使用MySQL內(nèi)置的函數(shù)
mysql> SELECT * FROM `staffs` WHERE LEFT(`name`, 5) = 'Ringo';
+----+-------+-----+---------+---------------------+
| id | name | age | pos | add_time |
+----+-------+-----+---------+---------------------+
| 1 | Ringo | 18 | manager | 2020-08-03 08:30:39 |
+----+-------+-----+---------+---------------------+
1 row in set (0.00 sec)
我們發(fā)現(xiàn)以上兩條SQL的執(zhí)行結(jié)果都是一樣的,但是執(zhí)行效率有沒有差距呢???
通過分析兩條SQL的執(zhí)行計劃來分析性能。

由此可見,在索引列上進(jìn)行計算,會使索引失效。
口訣:索引列上不計算。
范圍之后全失效
案例
/* 用到了idx_staffs_name_age_pos索引中的name,age,pos字段 這是屬于全值匹配的情況!!!*/
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 用到了idx_staffs_name_age_pos索引中的name,age字段,pos字段索引失效 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = '張三' AND `age` > 18 AND `pos` = 'dev';
查看上述SQL的執(zhí)行計劃

由此可知,查詢范圍的字段使用到了索引,但是范圍之后的索引字段會失效。
口訣:范圍之后全失效。
覆蓋索引盡量用
在寫SQL的不要使用SELECT *,用什么字段就查詢什么字段。
/* 沒有用到覆蓋索引 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 用到了覆蓋索引 */
EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';

口訣:查詢一定不用*。
不等有時會失效
/* 會使用到覆蓋索引 */
EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` != 'Ringo';
/* 索引失效 全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` != 'Ringo';
like百分加右邊
/* 索引失效 全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%ing%';
/* 索引失效 全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%ing';
/* 使用索引范圍查詢 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE 'Rin%';
口訣:like百分加右邊。
如果一定要使用%like,而且還要保證索引不失效,那么使用覆蓋索引來編寫SQL。
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `name` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `age` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `pos` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`, `age` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`,`name`, `age`, `pos` FROM `staffs` WHERE `name` LIKE '%in';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `pos` LIKE '%na';
/* 索引失效 全表掃描 */
EXPLAIN SELECT `name`, `age`, `pos`, `add_time` FROM `staffs` WHERE `name` LIKE '%in';

口訣:覆蓋索引保兩邊。
字符要加單引號
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` = 'Ringo';
/* 使用到了覆蓋索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` = 2000;
/* 索引失效 全表掃描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 2000;
這里name = 2000在MySQL中會發(fā)生強(qiáng)制類型轉(zhuǎn)換,將數(shù)字轉(zhuǎn)成字符串。
口訣:字符要加單引號。
索引相關(guān)題目
假設(shè)index(a,b,c)
| Where語句 | 索引是否被使用 |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 | Y,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N,沒有用到a字段 |
| where a = 3 and c = 5 | 使用到a,但是沒有用到c,因為b斷了 |
| where a = 3 and b > 4 and c = 5 | 使用到a,b,但是沒有用到c,因為c在范圍之后 |
| where a = 3 and b like 'kk%' and c = 4 | Y,a,b,c都用到 |
| where a = 3 and b like '%kk' and c = 4 | 只用到a |
| where a = 3 and b like '%kk%' and c = 4 | 只用到a |
| where a = 3 and b like 'k%kk%' and c = 4 | Y,a,b,c都用到 |
面試題分析
數(shù)據(jù)準(zhǔn)備
/* 創(chuàng)建表 */
CREATE TABLE `test03`(
`id` INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
`c1` CHAR(10),
`c2` CHAR(10),
`c3` CHAR(10),
`c4` CHAR(10),
`c5` CHAR(10)
);
/* 插入數(shù)據(jù) */
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('a1','a2','a3','a4','a5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('b1','b22','b3','b4','b5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('c1','c2','c3','c4','c5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('d1','d2','d3','d4','d5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('e1','e2','e3','e4','e5');
/* 創(chuàng)建復(fù)合索引 */
CREATE INDEX idx_test03_c1234 ON `test03`(`c1`,`c2`,`c3`,`c4`);
題目
/* 最好索引怎么創(chuàng)建的,就怎么用,按照順序使用,避免讓MySQL再自己去翻譯一次 */
/* 1.全值匹配 用到索引c1 c2 c3 c4全字段 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` = 'a3' AND `c4` = 'a4';
/* 2.用到索引c1 c2 c3 c4全字段 MySQL的查詢優(yōu)化器會優(yōu)化SQL語句的順序*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' AND `c3` = 'a3';
/* 3.用到索引c1 c2 c3 c4全字段 MySQL的查詢優(yōu)化器會優(yōu)化SQL語句的順序*/
EXPLAIN SELECT * FROM `test03` WHERE `c4` = 'a4' AND `c3` = 'a3' AND `c2` = 'a2' AND `c1` = 'a1';
/* 4.用到索引c1 c2 c3字段,c4字段失效,范圍之后全失效 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` > 'a3' AND `c4` = 'a4';
/* 5.用到索引c1 c2 c3 c4全字段 MySQL的查詢優(yōu)化器會優(yōu)化SQL語句的順序*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` > 'a4' AND `c3` = 'a3';
/*
6.用到了索引c1 c2 c3三個字段, c1和c2兩個字段用于查找, c3字段用于排序了但是沒有統(tǒng)計到key_len中,c4字段失效
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' ORDER BY `c3`;
/* 7.用到了索引c1 c2 c3三個字段,c1和c2兩個字段用于查找, c3字段用于排序了但是沒有統(tǒng)計到key_len中*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c3`;
/*
8.用到了索引c1 c2兩個字段,c4失效,c1和c2兩個字段用于查找,c4字段排序產(chǎn)生了Using filesort說明排序沒有用到c4字段
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c4`;
/* 9.用到了索引c1 c2 c3三個字段,c1用于查找,c2和c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c2`, `c3`;
/* 10.用到了c1一個字段,c1用于查找,c3和c2兩個字段索引失效,產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c3`, `c2`;
/* 11.用到了c1 c2 c3三個字段,c1 c2用于查找,c2 c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY c2, c3;
/* 12.用到了c1 c2 c3三個字段,c1 c2用于查找,c2 c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c2, c3;
/*
13.用到了c1 c2 c3三個字段,c1 c2用于查找,c2 c3用于排序 沒有產(chǎn)生Using filesort
因為之前c2這個字段已經(jīng)確定了是'a2'了,這是一個常量,再去ORDER BY c3,c2 這時候c2已經(jīng)不用排序了!
所以沒有產(chǎn)生Using filesort 和(10)進(jìn)行對比學(xué)習(xí)!
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c3, c2;
/* GROUP BY 表面上是叫做分組,但是分組之前必定排序。 */
/* 14.用到c1 c2 c3三個字段,c1用于查找,c2 c3用于排序,c4失效 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c2`,`c3`;
/* 15.用到c1這一個字段,c4失效,c2和c3排序失效產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c3`,`c2`;
GROUP BY基本上都需要進(jìn)行排序,索引優(yōu)化幾乎和ORDER BY一致,但是GROUP BY會有臨時表的產(chǎn)生。
總結(jié)
索引優(yōu)化的一般性建議:
- 對于單值索引,盡量選擇針對當(dāng)前
query過濾性更好的索引。 - 在選擇復(fù)合索引的時候,當(dāng)前
query中過濾性最好的字段在索引字段順序中,位置越靠前越好。 - 在選擇復(fù)合索引的時候,盡量選擇可以能夠包含當(dāng)前
query中的where子句中更多字段的索引。 - 盡可能通過分析統(tǒng)計信息和調(diào)整
query的寫法來達(dá)到選擇合適索引的目的。
口訣:
- 帶頭大哥不能死。
- 中間兄弟不能斷。
- 索引列上不計算。
- 范圍之后全失效。
- 覆蓋索引盡量用。
- 不等有時會失效。
- like百分加右邊。
- 字符要加單引號。
- 一般SQL少用or。
分析慢SQL的步驟
分析:
1、觀察,至少跑1天,看看生產(chǎn)的慢SQL情況。
2、開啟慢查詢?nèi)罩荆O(shè)置閾值,比如超過5秒鐘的就是慢SQL,并將它抓取出來。
3、explain + 慢SQL分析。
4、show Profile。
5、運(yùn)維經(jīng)理 OR DBA,進(jìn)行MySQL數(shù)據(jù)庫服務(wù)器的參數(shù)調(diào)優(yōu)。
總結(jié)(大綱):
1、慢查詢的開啟并捕獲。
2、explain + 慢SQL分析。
3、show Profile查詢SQL在MySQL數(shù)據(jù)庫中的執(zhí)行細(xì)節(jié)和生命周期情況。
4、MySQL數(shù)據(jù)庫服務(wù)器的參數(shù)調(diào)優(yōu)。
查詢優(yōu)化
小表驅(qū)動大表
優(yōu)化原則:對于MySQL數(shù)據(jù)庫而言,永遠(yuǎn)都是小表驅(qū)動大表。
/**
* 舉個例子:可以使用嵌套的for循環(huán)來理解小表驅(qū)動大表。
* 以下兩個循環(huán)結(jié)果都是一樣的,但是對于MySQL來說不一樣,
* 第一種可以理解為,和MySQL建立5次連接每次查詢1000次。
* 第一種可以理解為,和MySQL建立1000次連接每次查詢5次。
*/
for(int i = 1; i <= 5; i ++){
for(int j = 1; j <= 1000; j++){
}
}
// ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
for(int i = 1; i <= 1000; i ++){
for(int j = 1; j <= 5; j++){
}
}
IN和EXISTS
/* 優(yōu)化原則:小表驅(qū)動大表,即小的數(shù)據(jù)集驅(qū)動大的數(shù)據(jù)集 */
/* IN適合B表比A表數(shù)據(jù)小的情況*/
SELECT * FROM `A` WHERE `id` IN (SELECT `id` FROM `B`)
/* EXISTS適合B表比A表數(shù)據(jù)大的情況 */
SELECT * FROM `A` WHERE EXISTS (SELECT 1 FROM `B` WHERE `B`.id = `A`.id);
EXISTS:
- 語法:
SELECT....FROM tab WHERE EXISTS(subquery);該語法可以理解為: - 該語法可以理解為:將主查詢的數(shù)據(jù),放到子查詢中做條件驗證,根據(jù)驗證結(jié)果(
true或是false)來決定主查詢的數(shù)據(jù)結(jié)果是否得以保留。
提示:
EXISTS(subquery)子查詢只返回true或者false,因此子查詢中的SELECT *可以是SELECT 1 OR SELECT X,它們并沒有區(qū)別。EXISTS(subquery)子查詢的實(shí)際執(zhí)行過程可能經(jīng)過了優(yōu)化而不是我們理解上的逐條對比,如果擔(dān)心效率問題,可進(jìn)行實(shí)際檢驗以確定是否有效率問題。EXISTS(subquery)子查詢往往也可以用條件表達(dá)式,其他子查詢或者JOIN替代,何種最優(yōu)需要具體問題具體分析。
ORDER BY優(yōu)化
數(shù)據(jù)準(zhǔn)備
CREATE TABLE `talA`(
`age` INT,
`birth` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO `talA`(`age`) VALUES(18);
INSERT INTO `talA`(`age`) VALUES(19);
INSERT INTO `talA`(`age`) VALUES(20);
INSERT INTO `talA`(`age`) VALUES(21);
INSERT INTO `talA`(`age`) VALUES(22);
INSERT INTO `talA`(`age`) VALUES(23);
INSERT INTO `talA`(`age`) VALUES(24);
INSERT INTO `talA`(`age`) VALUES(25);
/* 創(chuàng)建索引 */
CREATE INDEX idx_talA_age_birth ON `talA`(`age`, `birth`);
案例
/* 1.使用索引進(jìn)行排序了 不會產(chǎn)生Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `age` > 20 ORDER BY `age`;
/* 2.使用索引進(jìn)行排序了 不會產(chǎn)生Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `age` > 20 ORDER BY `age`,`birth`;
/* 3.沒有使用索引進(jìn)行排序 產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `age` > 20 ORDER BY `birth`;
/* 4.沒有使用索引進(jìn)行排序 產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `age` > 20 ORDER BY `birth`,`age`;
/* 5.沒有使用索引進(jìn)行排序 產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `talA` ORDER BY `birth`;
/* 6.沒有使用索引進(jìn)行排序 產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `birth` > '2020-08-04 07:42:21' ORDER BY `birth`;
/* 7.使用索引進(jìn)行排序了 不會產(chǎn)生Using filesort */
EXPLAIN SELECT * FROM `talA` WHERE `birth` > '2020-08-04 07:42:21' ORDER BY `age`;
/* 8.沒有使用索引進(jìn)行排序 產(chǎn)生了Using filesort */
EXPLAIN SELECT * FROM `talA` ORDER BY `age` ASC, `birth` DESC;
ORDER BY子句,盡量使用索引排序,避免使用Using filesort排序。
MySQL支持兩種方式的排序,FileSort和Index,Index的效率高,它指MySQL掃描索引本身完成排序。FileSort方式效率較低。
ORDER BY滿足兩情況,會使用Index方式排序:
ORDER BY語句使用索引最左前列。- 使用
WHERE子句與ORDER BY子句條件列組合滿足索引最左前列。
結(jié)論:盡可能在索引列上完成排序操作,遵照索引建的最佳左前綴原則。
如果不在索引列上,F(xiàn)ile Sort有兩種算法:MySQL就要啟動雙路排序算法和單路排序算法
1、雙路排序算法:MySQL4.1之前使用雙路排序,字面意思就是兩次掃描磁盤,最終得到數(shù)據(jù),讀取行指針和ORDER BY列,対他們進(jìn)行排序,然后掃描已經(jīng)排序好的列表,按照列表中的值重新從列表中讀取對應(yīng)的數(shù)據(jù)輸出。一句話,從磁盤取排序字段,在buffer中進(jìn)行排序,再從磁盤取其他字段。
取一批數(shù)據(jù),要對磁盤進(jìn)行兩次掃描,眾所周知,IO是很耗時的,所以在MySQL4.1之后,出現(xiàn)了改進(jìn)的算法,就是單路排序算法。
2、單路排序算法:從磁盤讀取查詢需要的所有列,按照ORDER BY列在buffer対它們進(jìn)行排序,然后掃描排序后的列表進(jìn)行輸出,它的效率更快一些,避免了第二次讀取數(shù)據(jù)。并且把隨機(jī)IO變成了順序IO,但是它會使用更多的空間,因為它把每一行都保存在內(nèi)存中了。
由于單路排序算法是后出的,總體而言效率好過雙路排序算法。
但是單路排序算法有問題:如果SortBuffer緩沖區(qū)太小,導(dǎo)致從磁盤中讀取所有的列不能完全保存在SortBuffer緩沖區(qū)中,這時候單路復(fù)用算法就會出現(xiàn)問題,反而性能不如雙路復(fù)用算法。
單路復(fù)用算法的優(yōu)化策略:
- 增大
sort_buffer_size參數(shù)的設(shè)置。 - 增大
max_length_for_sort_data參數(shù)的設(shè)置。
提高ORDER BY排序的速度:
-
ORDER BY時使用SELECT *是大忌,查什么字段就寫什么字段,這點(diǎn)非常重要。在這里的影響是:- 當(dāng)查詢的字段大小總和小于
max_length_for_sort_data而且排序字段不是TEXT|BLOB類型時,會使用單路排序算法,否則使用多路排序算法。 - 兩種排序算法的數(shù)據(jù)都有可能超出
sort_buffer緩沖區(qū)的容量,超出之后,會創(chuàng)建tmp臨時文件進(jìn)行合并排序,導(dǎo)致多次IO,但是單路排序算法的風(fēng)險會更大一些,所以要增大sort_buffer_size參數(shù)的設(shè)置。
- 當(dāng)查詢的字段大小總和小于
-
嘗試提高
sort_buffer_size:不管使用哪種算法,提高這個參數(shù)都會提高效率,當(dāng)然,要根據(jù)系統(tǒng)的能力去提高,因為這個參數(shù)是針對每個進(jìn)程的。 -
嘗試提高
max_length_for_sort_data:提高這個參數(shù),會增加用單路排序算法的概率。但是如果設(shè)置的太高,數(shù)據(jù)總?cè)萘?code>sort_buffer_size的概率就增大,明顯癥狀是高的磁盤IO活動和低的處理器使用率。
GORUP BY優(yōu)化
-
GROUP BY實(shí)質(zhì)是先排序后進(jìn)行分組,遵照索引建的最佳左前綴。 -
當(dāng)無法使用索引列時,會使用
Using filesort進(jìn)行排序,增大max_length_for_sort_data參數(shù)的設(shè)置和增大sort_buffer_size參數(shù)的設(shè)置,會提高性能。 -
WHERE執(zhí)行順序高于HAVING,能寫在WHERE限定條件里的就不要寫在HAVING中了。
總結(jié)
為排序使用索引
- MySQL兩種排序方式:
Using filesort和Index掃描有序索引排序。 - MySQL能為排序與查詢使用相同的索引,創(chuàng)建的索引既可以用于排序也可以用于查詢。
/* 創(chuàng)建a b c三個字段的索引 */
idx_table_a_b_c(a, b, c)
98
/* 1.ORDER BY 能使用索引最左前綴 */
ORDER BY a;
ORDER BY a, b;
ORDER BY a, b, c;
ORDER BY a DESC, b DESC, c DESC;
/* 2.如果WHERE子句中使用索引的最左前綴定義為常量,則ORDER BY能使用索引 */
WHERE a = 'Ringo' ORDER BY b, c;
WHERE a = 'Ringo' AND b = 'Tangs' ORDER BY c;
WHERE a = 'Ringo' AND b > 2000 ORDER BY b, c;
/* 3.不能使用索引進(jìn)行排序 */
ORDER BY a ASC, b DESC, c DESC; /* 排序不一致 */
WHERE g = const ORDER BY b, c; /* 丟失a字段索引 */
WHERE a = const ORDER BY c; /* 丟失b字段索引 */
WHERE a = const ORDER BY a, d; /* d字段不是索引的一部分 */
WHERE a IN (...) ORDER BY b, c; /* 對于排序來說,多個相等條件(a=1 or a=2)也是范圍查詢 */
基本介紹
慢查詢?nèi)罩臼鞘裁矗?/p>
- MySQL的慢查詢?nèi)罩臼荕ySQL提供的一種日志記錄,它用來記錄在MySQL中響應(yīng)時間超過閾值的語句,具體指運(yùn)行時間超過
long_query_time值的SQL,則會被記錄到慢查詢?nèi)罩局小?/li>
long_query_time的默認(rèn)值為10,意思是運(yùn)行10秒以上的語句。- 由慢查詢?nèi)罩緛聿榭茨男㏒QL超出了我們的最大忍耐時間值,比如一條SQL執(zhí)行超過5秒鐘,我們就算慢SQL,希望能收集超過5秒鐘的SQL,結(jié)合之前
explain進(jìn)行全面分析。
特別說明
慢查詢?nèi)罩臼鞘裁矗?/p>
long_query_time值的SQL,則會被記錄到慢查詢?nèi)罩局小?/li>
long_query_time的默認(rèn)值為10,意思是運(yùn)行10秒以上的語句。explain進(jìn)行全面分析。特別說明
默認(rèn)情況下,MySQL數(shù)據(jù)庫沒有開啟慢查詢?nèi)罩荆?/strong>需要我們手動來設(shè)置這個參數(shù)。
當(dāng)然,如果不是調(diào)優(yōu)需要的話,一般不建議啟動該參數(shù),因為開啟慢查詢?nèi)罩緯蚨嗷蛏賻硪欢ǖ男阅苡绊憽B樵內(nèi)罩局С謱⑷罩居涗泴懭胛募?/p>
查看慢查詢?nèi)罩臼欠耖_以及如何開啟
-
查看慢查詢?nèi)罩臼欠耖_啟:
SHOW VARIABLES LIKE '%slow_query_log%';。 -
開啟慢查詢?nèi)罩荆?code>SET GLOBAL slow_query_log = 1;。使用該方法開啟MySQL的慢查詢?nèi)罩局粚Ξ?dāng)前數(shù)據(jù)庫生效,如果MySQL重啟后會失效。
# 1、查看慢查詢?nèi)罩臼欠耖_啟
mysql> SHOW VARIABLES LIKE '%slow_query_log%';
+---------------------+--------------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/1dcb5644392c-slow.log |
+---------------------+--------------------------------------+
2 rows in set (0.01 sec)
# 2、開啟慢查詢?nèi)罩?mysql> SET GLOBAL slow_query_log = 1;
Query OK, 0 rows affected (0.00 sec)
如果要使慢查詢?nèi)罩居谰瞄_啟,需要修改my.cnf文件,在[mysqld]下增加修改參數(shù)。
# my.cnf
[mysqld]
# 1.這個是開啟慢查詢。注意ON需要大寫
slow_query_log=ON
# 2.這個是存儲慢查詢的日志文件。這個文件不存在的話,需要自己創(chuàng)建
slow_query_log_file=/var/lib/mysql/slow.log
開啟了慢查詢?nèi)罩竞螅裁礃拥腟QL才會被記錄到慢查詢?nèi)罩纠锩婺兀?/p>
這個是由參數(shù)long_query_time控制的,默認(rèn)情況下long_query_time的值為10秒。
MySQL中查看long_query_time的時間:SHOW VARIABLES LIKE 'long_query_time%';。
# 查看long_query_time 默認(rèn)是10秒
# 只有SQL的執(zhí)行時間>10才會被記錄
mysql> SHOW VARIABLES LIKE 'long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
修改long_query_time的時間,需要在my.cnf修改配置文件
[mysqld]
# 這個是設(shè)置慢查詢的時間,我設(shè)置的為1秒
long_query_time=1
查新慢查詢?nèi)罩镜目傆涗洍l數(shù):SHOW GLOBAL STATUS LIKE '%Slow_queries%';。
mysql> SHOW GLOBAL STATUS LIKE '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 3 |
+---------------+-------+
1 row in set (0.00 sec)
日志分析工具
日志分析工具mysqldumpslow:在生產(chǎn)環(huán)境中,如果要手工分析日志,查找、分析SQL,顯然是個體力活,MySQL提供了日志分析工具mysqldumpslow。
# 1、mysqldumpslow --help 來查看mysqldumpslow的幫助信息
root@1dcb5644392c:/usr/bin# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default # 按照何種方式排序
al: average lock time # 平均鎖定時間
ar: average rows sent # 平均返回記錄數(shù)
at: average query time # 平均查詢時間
c: count # 訪問次數(shù)
l: lock time # 鎖定時間
r: rows sent # 返回記錄
t: query time # 查詢時間
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries # 返回前面多少條記錄
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
# 2、 案例
# 2.1、得到返回記錄集最多的10個SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/slow.log
# 2.2、得到訪問次數(shù)最多的10個SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/slow.log
# 2.3、得到按照時間排序的前10條里面含有左連接的查詢語句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/slow.log
# 2.4、另外建議使用這些命令時結(jié)合|和more使用,否則出現(xiàn)爆屏的情況
mysqldumpslow -s r -t 10 /var/lib/mysql/slow.log | more
批量插入數(shù)據(jù)腳本
環(huán)境準(zhǔn)備
1、建表SQL。
/* 1.dept表 */
CREATE TABLE `dept` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`deptno` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '部門id',
`dname` varchar(20) NOT NULL DEFAULT '' COMMENT '部門名字',
`loc` varchar(13) NOT NULL DEFAULT '' COMMENT '部門地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部門表'
/* 2.emp表 */
CREATE TABLE `emp` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`empno` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '員工編號',
`ename` varchar(20) NOT NULL DEFAULT '' COMMENT '員工名字',
`job` varchar(9) NOT NULL DEFAULT '' COMMENT '職位',
`mgr` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '上級編號',
`hiredata` date NOT NULL COMMENT '入職時間',
`sal` decimal(7,2) NOT NULL COMMENT '薪水',
`comm` decimal(7,2) NOT NULL COMMENT '分紅',
`deptno` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '部門id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='員工表'
2、由于開啟過慢查詢?nèi)罩荆_啟了
bin-log,我們就必須為function指定一個參數(shù),否則使用函數(shù)會報錯。
# 在mysql中設(shè)置
# log_bin_trust_function_creators 默認(rèn)是關(guān)閉的 需要手動開啟
mysql> SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin_trust_function_creators | OFF |
+---------------------------------+-------+
1 row in set (0.00 sec)
mysql> SET GLOBAL log_bin_trust_function_creators=1;
Query OK, 0 rows affected (0.00 sec)
上述修改方式MySQL重啟后會失敗,在my.cnf配置文件下修改永久有效。
[mysqld]
log_bin_trust_function_creators=ON
創(chuàng)建函數(shù)
# 1、函數(shù):隨機(jī)產(chǎn)生字符串
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwsyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
# 2、函數(shù):隨機(jī)產(chǎn)生部門編號
DELIMITER $$
CREATE FUNCTION rand_num() RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100 + RAND() * 10);
RETURN i;
END $$
創(chuàng)建存儲過程
# 1、函數(shù):向dept表批量插入
DELIMITER $$
CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept(deptno,dname,loc) VALUES((START + i),rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
# 2、函數(shù):向emp表批量插入
DELIMITER $$
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp(empno,ename,job,mgr,hiredata,sal,comm,deptno) VALUES((START + i),rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
調(diào)用存儲過程
# 1、調(diào)用存儲過程向dept表插入10個部門。
DELIMITER ;
CALL insert_dept(100,10);
# 2、調(diào)用存儲過程向emp表插入50萬條數(shù)據(jù)。
DELIMITER ;
CALL insert_emp(100001,500000);
Show Profile
Show Profile是什么?
Show Profile:MySQL提供可以用來分析當(dāng)前會話中語句執(zhí)行的資源消耗情況。可以用于SQL的調(diào)優(yōu)的測量。默認(rèn)情況下,參數(shù)處于關(guān)閉狀態(tài),并保存最近15次的運(yùn)行結(jié)果。
分析步驟
1、是否支持,看看當(dāng)前的MySQL版本是否支持。
# 查看Show Profile功能是否開啟
mysql> SHOW VARIABLES LIKE 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | OFF |
+---------------+-------+
1 row in set (0.00 sec)
2、開啟Show Profile功能,默認(rèn)是關(guān)閉的,使用前需要開啟。
# 開啟Show Profile功能
mysql> SET profiling=ON;
Query OK, 0 rows affected, 1 warning (0.00 sec)
3、運(yùn)行SQL
SELECT * FROM `emp` GROUP BY `id`%10 LIMIT 150000;
SELECT * FROM `emp` GROUP BY `id`%20 ORDER BY 5;
4、查看結(jié)果,執(zhí)行SHOW PROFILES;
Duration:持續(xù)時間。
mysql> SHOW PROFILES;
+----------+------------+---------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------+
| 1 | 0.00156100 | SHOW VARIABLES LIKE 'profiling' |
| 2 | 0.56296725 | SELECT * FROM `emp` GROUP BY `id`%10 LIMIT 150000 |
| 3 | 0.52105825 | SELECT * FROM `emp` GROUP BY `id`%10 LIMIT 150000 |
| 4 | 0.51279775 | SELECT * FROM `emp` GROUP BY `id`%20 ORDER BY 5 |
+----------+------------+---------------------------------------------------+
4 rows in set, 1 warning (0.00 sec)
5、診斷SQL,SHOW PROFILE cpu,block io FOR QUERY Query_ID;
# 這里的3是第四步中的Query_ID。
# 可以在SHOW PROFILE中看到一條SQL中完整的生命周期。
mysql> SHOW PROFILE cpu,block io FOR QUERY 3;
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000097 | 0.000090 | 0.000002 | 0 | 0 |
| checking permissions | 0.000010 | 0.000009 | 0.000000 | 0 | 0 |
| Opening tables | 0.000039 | 0.000058 | 0.000000 | 0 | 0 |
| init | 0.000046 | 0.000046 | 0.000000 | 0 | 0 |
| System lock | 0.000011 | 0.000000 | 0.000000 | 0 | 0 |
| optimizing | 0.000005 | 0.000000 | 0.000000 | 0 | 0 |
| statistics | 0.000023 | 0.000037 | 0.000000 | 0 | 0 |
| preparing | 0.000014 | 0.000000 | 0.000000 | 0 | 0 |
| Creating tmp table | 0.000041 | 0.000053 | 0.000000 | 0 | 0 |
| Sorting result | 0.000005 | 0.000000 | 0.000000 | 0 | 0 |
| executing | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Sending data | 0.520620 | 0.516267 | 0.000000 | 0 | 0 |
| Creating sort index | 0.000060 | 0.000051 | 0.000000 | 0 | 0 |
| end | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| query end | 0.000011 | 0.000000 | 0.000000 | 0 | 0 |
| removing tmp table | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| query end | 0.000004 | 0.000000 | 0.000000 | 0 | 0 |
| closing tables | 0.000009 | 0.000000 | 0.000000 | 0 | 0 |
| freeing items | 0.000032 | 0.000064 | 0.000000 | 0 | 0 |
| cleaning up | 0.000019 | 0.000000 | 0.000000 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+
20 rows in set, 1 warning (0.00 sec)
Show Profile查詢參數(shù)備注:
ALL:顯示所有的開銷信息。BLOCK IO:顯示塊IO相關(guān)開銷(通用)。CONTEXT SWITCHES:上下文切換相關(guān)開銷。CPU:顯示CPU相關(guān)開銷信息(通用)。IPC:顯示發(fā)送和接收相關(guān)開銷信息。MEMORY:顯示內(nèi)存相關(guān)開銷信息。PAGE FAULTS:顯示頁面錯誤相關(guān)開銷信息。SOURCE:顯示和Source_function。SWAPS:顯示交換次數(shù)相關(guān)開銷的信息。
6、Show Profile查詢列表,日常開發(fā)需要注意的結(jié)論:
converting HEAP to MyISAM:查詢結(jié)果太大,內(nèi)存都不夠用了,往磁盤上搬了。Creating tmp table:創(chuàng)建臨時表(拷貝數(shù)據(jù)到臨時表,用完再刪除),非常耗費(fèi)數(shù)據(jù)庫性能。Copying to tmp table on disk:把內(nèi)存中的臨時表復(fù)制到磁盤,危險!!!locked:死鎖。
表鎖(偏讀)
表鎖特點(diǎn):
- 表鎖偏向
MyISAM存儲引擎,開銷小,加鎖快,無死鎖,鎖定粒度大,發(fā)生鎖沖突的概率最高,并發(fā)度最低。
環(huán)境準(zhǔn)備
# 1、創(chuàng)建表
CREATE TABLE `mylock`(
`id` INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20)
)ENGINE=MYISAM DEFAULT CHARSET=utf8 COMMENT='測試表鎖';
# 2、插入數(shù)據(jù)
INSERT INTO `mylock`(`name`) VALUES('ZhangSan');
INSERT INTO `mylock`(`name`) VALUES('LiSi');
INSERT INTO `mylock`(`name`) VALUES('WangWu');
INSERT INTO `mylock`(`name`) VALUES('ZhaoLiu');
鎖表的命令
1、查看數(shù)據(jù)庫表鎖的命令。
# 查看數(shù)據(jù)庫表鎖的命令
SHOW OPEN TABLES;
2、給
mylock表上讀鎖,給book表上寫鎖。
# 給mylock表上讀鎖,給book表上寫鎖
LOCK TABLE `mylock` READ, `book` WRITE;
# 查看當(dāng)前表的狀態(tài)
mysql> SHOW OPEN TABLES;
+--------------------+------------------------------------------------------+--------+-------------+
| Database | Table | In_use | Name_locked |
+--------------------+------------------------------------------------------+--------+-------------+
| sql_analysis | book | 1 | 0 |
| sql_analysis | mylock | 1 | 0 |
+--------------------+------------------------------------------------------+--------+-------------+
3、釋放表鎖。
# 釋放給表添加的鎖
UNLOCK TABLES;
# 查看當(dāng)前表的狀態(tài)
mysql> SHOW OPEN TABLES;
+--------------------+------------------------------------------------------+--------+-------------+
| Database | Table | In_use | Name_locked |
+--------------------+------------------------------------------------------+--------+-------------+
| sql_analysis | book | 0 | 0 |
| sql_analysis | mylock | 0 | 0 |
+--------------------+------------------------------------------------------+--------+-------------+
讀鎖案例
1、打開兩個會話,
SESSION1為mylock表添加讀鎖。
# 為mylock表添加讀鎖
LOCK TABLE `mylock` READ;
2、打開兩個會話,
SESSION1是否可以讀自己鎖的表?是否可以修改自己鎖的表?是否可以讀其他的表?那么SESSION2呢?
# SESSION1
# 問題1:SESSION1為mylock表加了讀鎖,可以讀mylock表!
mysql> SELECT * FROM `mylock`;
+----+----------+
| id | name |
+----+----------+
| 1 | ZhangSan |
| 2 | LiSi |
| 3 | WangWu |
| 4 | ZhaoLiu |
+----+----------+
4 rows in set (0.00 sec)
# 問題2:SESSION1為mylock表加了讀鎖,不可以修改mylock表!
mysql> UPDATE `mylock` SET `name` = 'abc' WHERE `id` = 1;
ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated
# 問題3:SESSION1為mylock表加了讀鎖,不可以讀其他的表!
mysql> SELECT * FROM `book`;
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES
# SESSION2
# 問題1:SESSION1為mylock表加了讀鎖,SESSION2可以讀mylock表!
mysql> SELECT * FROM `mylock`;
+----+----------+
| id | name |
+----+----------+
| 1 | ZhangSan |
| 2 | LiSi |
| 3 | WangWu |
| 4 | ZhaoLiu |
+----+----------+
4 rows in set (0.00 sec)
# 問題2:SESSION1為mylock表加了讀鎖,SESSION2修改mylock表會被阻塞,需要等待SESSION1釋放mylock表!
mysql> UPDATE `mylock` SET `name` = 'abc' WHERE `id` = 1;
^C^C -- query aborted
ERROR 1317 (70100): Query execution was interrupted
# 問題3:SESSION1為mylock表加了讀鎖,SESSION2可以讀其他表!
mysql> SELECT * FROM `book`;
+--------+------+
| bookid | card |
+--------+------+
| 1 | 1 |
| 7 | 4 |
| 8 | 4 |
| 9 | 5 |
| 5 | 6 |
| 17 | 6 |
| 15 | 8 |
+--------+------+
24 rows in set (0.00 sec)
寫鎖案例
1、打開兩個會話,
SESSION1為mylock表添加寫鎖。
# 為mylock表添加寫鎖
LOCK TABLE `mylock` WRITE;
2、打開兩個會話,
SESSION1是否可以讀自己鎖的表?是否可以修改自己鎖的表?是否可以讀其他的表?那么SESSION2呢?
# SESSION1
# 問題1:SESSION1為mylock表加了寫鎖,可以讀mylock的表!
mysql> SELECT * FROM `mylock`;
+----+----------+
| id | name |
+----+----------+
| 1 | ZhangSan |
| 2 | LiSi |
| 3 | WangWu |
| 4 | ZhaoLiu |
+----+----------+
4 rows in set (0.00 sec)
# 問題2:SESSION1為mylock表加了寫鎖,可以修改mylock表!
mysql> UPDATE `mylock` SET `name` = 'abc' WHERE `id` = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 問題3:SESSION1為mylock表加了寫鎖,不能讀其他表!
mysql> SELECT * FROM `book`;
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES
# SESSION2
# 問題1:SESSION1為mylock表加了寫鎖,SESSION2讀mylock表會阻塞,等待SESSION1釋放!
mysql> SELECT * FROM `mylock`;
^C^C -- query aborted
ERROR 1317 (70100): Query execution was interrupted
# 問題2:SESSION1為mylock表加了寫鎖,SESSION2讀mylock表會阻塞,等待SESSION1釋放!
mysql> UPDATE `mylock` SET `name` = 'abc' WHERE `id` = 1;
^C^C -- query aborted
ERROR 1317 (70100): Query execution was interrupted
# 問題3:SESSION1為mylock表加了寫鎖,SESSION2可以讀其他表!
mysql> SELECT * FROM `book`;
+--------+------+
| bookid | card |
+--------+------+
| 1 | 1 |
| 7 | 4 |
| 8 | 4 |
| 9 | 5 |
| 5 | 6 |
| 17 | 6 |
| 15 | 8 |
+--------+------+
24 rows in set (0.00 sec)
案例結(jié)論
MyISAM引擎在執(zhí)行查詢語句SELECT之前,會自動給涉及到的所有表加讀鎖,在執(zhí)行增刪改之前,會自動給涉及的表加寫鎖。
MySQL的表級鎖有兩種模式:
-
表共享讀鎖(Table Read Lock)。
-
表獨(dú)占寫鎖(Table Write Lock)。
対MyISAM表進(jìn)行操作,會有以下情況:
- 対
MyISAM表的讀操作(加讀鎖),不會阻塞其他線程対同一表的讀操作,但是會阻塞其他線程対同一表的寫操作。只有當(dāng)讀鎖釋放之后,才會執(zhí)行其他線程的寫操作。 - 対
MyISAM表的寫操作(加寫鎖),會阻塞其他線程対同一表的讀和寫操作,只有當(dāng)寫鎖釋放之后,才會執(zhí)行其他線程的讀寫操作。
表鎖分析
mysql> SHOW STATUS LIKE 'table%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Table_locks_immediate | 173 |
| Table_locks_waited | 0 |
| Table_open_cache_hits | 5 |
| Table_open_cache_misses | 8 |
| Table_open_cache_overflows | 0 |
+----------------------------+-------+
5 rows in set (0.00 sec)
可以通過Table_locks_immediate和Table_locks_waited狀態(tài)變量來分析系統(tǒng)上的表鎖定。具體說明如下:
Table_locks_immediate:產(chǎn)生表級鎖定的次數(shù),表示可以立即獲取鎖的查詢次數(shù),每立即獲取鎖值加1。
Table_locks_waited:出現(xiàn)表級鎖定爭用而發(fā)生等待的次數(shù)(不能立即獲取鎖的次數(shù),每等待一次鎖值加1),此值高則說明存在較嚴(yán)重的表級鎖爭用情況。
此外,MyISAM的讀寫鎖調(diào)度是寫優(yōu)先,這也是MyISAM不適合作為主表的引擎。因為寫鎖后,其他線程不能進(jìn)行任何操作,大量的寫操作會使查詢很難得到鎖,從而造成永遠(yuǎn)阻塞。
行鎖(偏寫)
行鎖特點(diǎn):
- 偏向
InnoDB存儲引擎,開銷大,加鎖慢;會出現(xiàn)死鎖;鎖定粒度最小,發(fā)生鎖沖突的概率最低,并發(fā)度最高。
InnoDB存儲引擎和MyISAM存儲引擎最大不同有兩點(diǎn):一是支持事務(wù),二是采用行鎖。
事務(wù)的ACID:
Atomicity [??t??m?s?ti]。Consistency [k?n?s?st?nsi]。Isolation [?a?s??le??n]。Durability [?dj??r??b?l?ti]。
環(huán)境準(zhǔn)備
# 建表語句
CREATE TABLE `test_innodb_lock`(
`a` INT,
`b` VARCHAR(16)
)ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='測試行鎖';
# 插入數(shù)據(jù)
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(1, 'b2');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(2, '3');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(3, '4000');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(4, '5000');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(5, '6000');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(6, '7000');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(7, '8000');
INSERT INTO `test_innodb_lock`(`a`, `b`) VALUES(8, '9000');
# 創(chuàng)建索引
CREATE INDEX idx_test_a ON `test_innodb_lock`(a);
CREATE INDEX idx_test_b ON `test_innodb_lock`(b);
行鎖案例
1、開啟手動提交
打開SESSION1和SESSION2兩個會話,都開啟手動提交。
# 開啟MySQL數(shù)據(jù)庫的手動提交
mysql> SET autocommit=0;
Query OK, 0 rows affected (0.00 sec)
2、讀幾知所寫
# SESSION1
# SESSION1対test_innodb_lock表做寫操作,但是沒有commit。
# 執(zhí)行修改SQL之后,查詢一下test_innodb_lock表,發(fā)現(xiàn)數(shù)據(jù)被修改了。
mysql> UPDATE `test_innodb_lock` SET `b` = '88' WHERE `a` = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM `test_innodb_lock`;
+------+------+
| a | b |
+------+------+
| 1 | 88 |
| 2 | 3 |
| 3 | 4000 |
| 4 | 5000 |
| 5 | 6000 |
| 6 | 7000 |
| 7 | 8000 |
| 8 | 9000 |
+------+------+
8 rows in set (0.00 sec)
# SESSION2
# SESSION2這時候來查詢test_innodb_lock表。
# 發(fā)現(xiàn)SESSION2是讀不到SESSION1未提交的數(shù)據(jù)的。
mysql> SELECT * FROM `test_innodb_lock`;
+------+------+
| a | b |
+------+------+
| 1 | b2 |
| 2 | 3 |
| 3 | 4000 |
| 4 | 5000 |
| 5 | 6000 |
| 6 | 7000 |
| 7 | 8000 |
| 8 | 9000 |
+------+------+
8 rows in set (0.00 se
3、行鎖兩個SESSION同時対一條記錄進(jìn)行寫操作
# SESSION1 対test_innodb_lock表的`a`=1這一行進(jìn)行寫操作,但是沒有commit
mysql> UPDATE `test_innodb_lock` SET `b` = '99' WHERE `a` = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# SESSION2 也對test_innodb_lock表的`a`=1這一行進(jìn)行寫操作,但是發(fā)現(xiàn)阻塞了!!!
# 等SESSION1執(zhí)行commit語句之后,SESSION2的SQL就會執(zhí)行了
mysql> UPDATE `test_innodb_lock` SET `b` = 'asdasd' WHERE `a` = 1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
4、行鎖兩個SESSION同時對不同記錄進(jìn)行寫操作
# SESSION1 対test_innodb_lock表的`a`=6這一行進(jìn)行寫操作,但是沒有commit
mysql> UPDATE `test_innodb_lock` SET `b` = '8976' WHERE `a` = 6;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# SESSION2 対test_innodb_lock表的`a`=4這一行進(jìn)行寫操作,沒有阻塞!!!
# SESSION1和SESSION2同時對不同的行進(jìn)行寫操作互不影響
mysql> UPDATE `test_innodb_lock` SET `b` = 'Ringo' WHERE `a` = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
索引失效行鎖變表鎖
# SESSION1 執(zhí)行SQL語句,沒有執(zhí)行commit。
# 由于`b`字段是字符串,但是沒有加單引號導(dǎo)致索引失效
mysql> UPDATE `test_innodb_lock` SET `a` = 888 WHERE `b` = 8000;
Query OK, 1 row affected, 1 warning (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 1
# SESSION2 和SESSION1操作的并不是同一行,但是也被阻塞了???
# 由于SESSION1執(zhí)行的SQL索引失效,導(dǎo)致行鎖升級為表鎖。
mysql> UPDATE `test_innodb_lock` SET `b` = '1314' WHERE `a` = 1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
間隙鎖的危害
什么是間隙鎖?
當(dāng)我們用范圍條件而不是相等條件檢索數(shù)據(jù),并請求共享或者排他鎖時,InnoDB會給符合條件的已有數(shù)據(jù)記錄的索引項加鎖,對于鍵值在條件范文內(nèi)但并不存在的記錄,叫做"間隙(GAP)"。
InnoDB也會對這個"間隙"加鎖,這種鎖的機(jī)制就是所謂的"間隙鎖"。
間隙鎖的危害
因為Query執(zhí)行過程中通過范圍查找的話,他會鎖定整個范圍內(nèi)所有的索引鍵值,即使這個鍵值不存在。
間隙鎖有一個比較致命的缺點(diǎn),就是當(dāng)鎖定一個范圍的鍵值后,即使某些不存在的鍵值也會被無辜的鎖定,而造成在鎖定的時候無法插入鎖定鍵值范圍內(nèi)的任何數(shù)據(jù)。在某些場景下這可能會対性能造成很大的危害。
如何鎖定一行
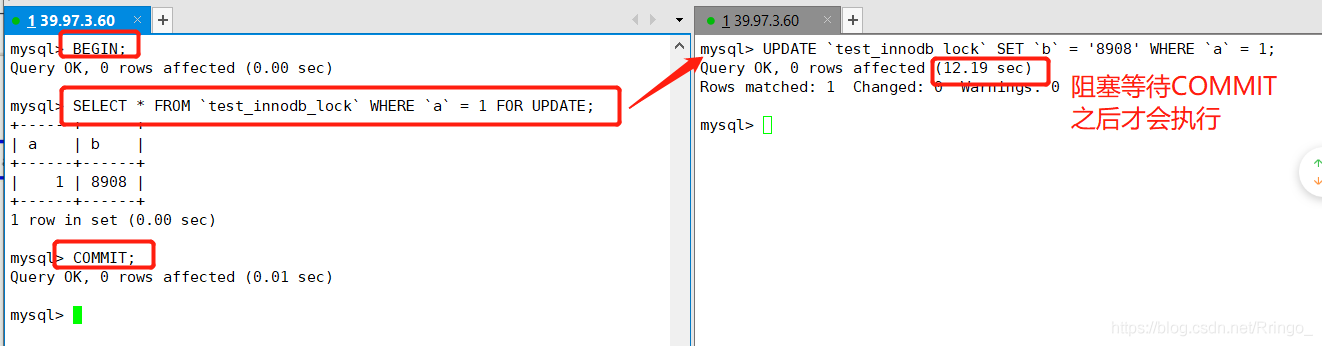
SELECT .....FOR UPDATE在鎖定某一行后,其他寫操作會被阻塞,直到鎖定的行被COMMIT。
mysql InnoDB引擎默認(rèn)的修改數(shù)據(jù)語句,update,delete,insert都會自動給涉及到的數(shù)據(jù)加上排他鎖,select語句默認(rèn)不會加任何鎖類型,如果加排他鎖可以使用select ...for update語句,加共享鎖可以使用select ... lock in share mode語句。所以加過排他鎖的數(shù)據(jù)行在其他事務(wù)種是不能修改數(shù)據(jù)的,也不能通過for update和lock in share mode鎖的方式查詢數(shù)據(jù),但可以直接通過select ...from...查詢數(shù)據(jù),因為普通查詢沒有任何鎖機(jī)制。
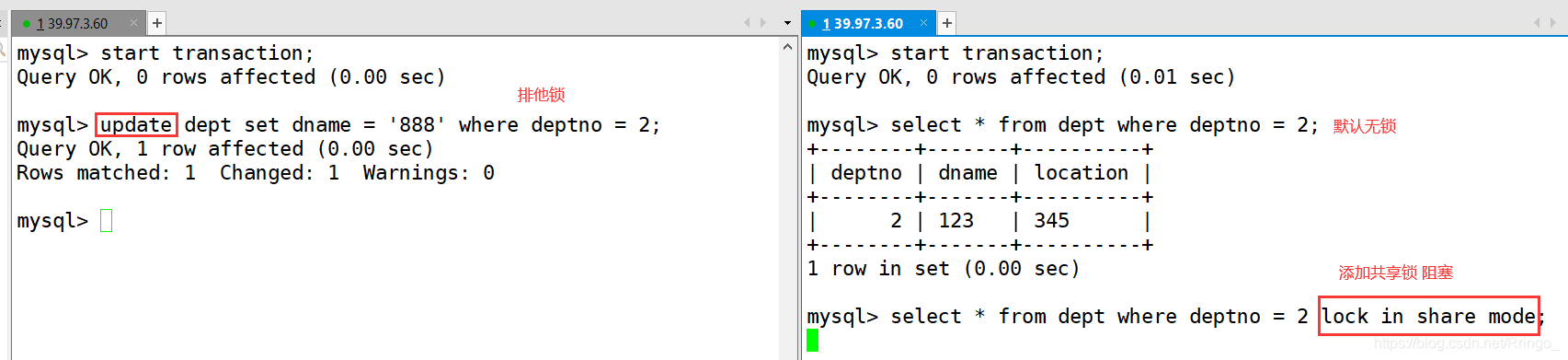
案例結(jié)論
InnoDB存儲引擎由于實(shí)現(xiàn)了行級鎖定,雖然在鎖定機(jī)制的實(shí)現(xiàn)方面所帶來的性能損耗可能比表級鎖定會要更高一些,但是在整體并發(fā)處理能力方面要遠(yuǎn)遠(yuǎn)優(yōu)于MyISAM的表級鎖定的。當(dāng)系統(tǒng)并發(fā)量較高的時候,InnoDB的整體性能和MyISAM相比就會有比較明顯的優(yōu)勢了。
但是,InnoDB的行級鎖定同樣也有其脆弱的一面,當(dāng)我們使用不當(dāng)?shù)臅r候,可能會讓InnoDB的整體性能表現(xiàn)不僅不能比MyISAM高,甚至可能會更差。
行鎖分析
mysql> SHOW STATUS LIKE 'innodb_row_lock%';
+-------------------------------+--------+
| Variable_name | Value |
+-------------------------------+--------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 124150 |
| Innodb_row_lock_time_avg | 31037 |
| Innodb_row_lock_time_max | 51004 |
| Innodb_row_lock_waits | 4 |
+-------------------------------+--------+
5 rows in set (0.00 sec)
対各個狀態(tài)量的說明如下:
Innodb_row_lock_current_waits:當(dāng)前正在等待鎖定的數(shù)量。Innodb_row_lock_time:從系統(tǒng)啟動到現(xiàn)在鎖定總時間長度(重要)。Innodb_row_lock_time_avg:每次等待所花的平均時間(重要)。Innodb_row_lock_time_max:從系統(tǒng)啟動到現(xiàn)在等待最長的一次所花的時間。Innodb_row_lock_waits:系統(tǒng)啟動后到現(xiàn)在總共等待的次數(shù)(重要)。
尤其是當(dāng)?shù)却螖?shù)很高,而且每次等待時長也不小的時候,我們就需要分析系統(tǒng)中為什么會有如此多的等待,然后根據(jù)分析結(jié)果著手制定優(yōu)化策略。
主從復(fù)制
復(fù)制基本原理
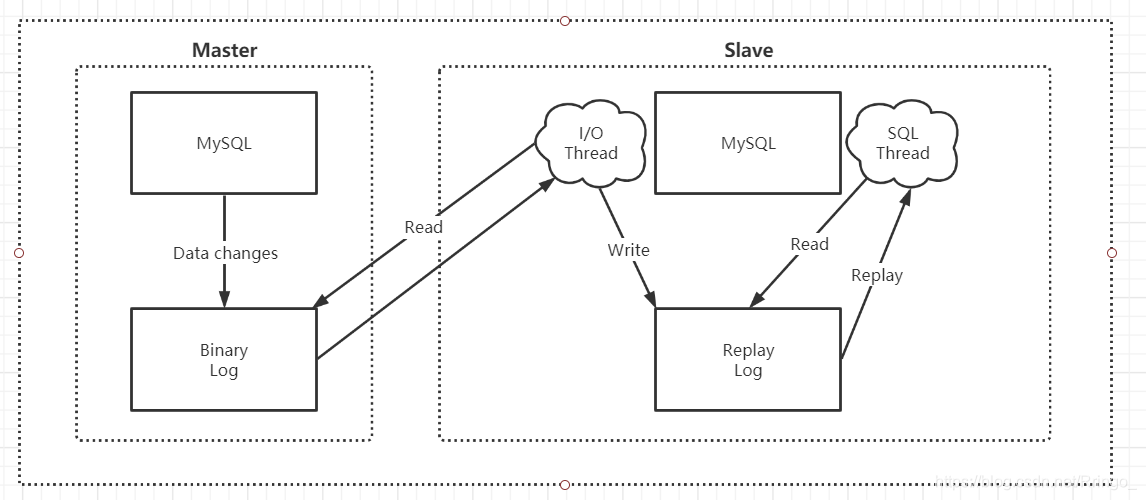
MySQL復(fù)制過程分為三步:
- Master將改變記錄到二進(jìn)制日志(Binary Log)。這些記錄過程叫做二進(jìn)制日志事件,
Binary Log Events; - Slave將Master的
Binary Log Events拷貝到它的中繼日志(Replay Log); - Slave重做中繼日志中的事件,將改變應(yīng)用到自己的數(shù)據(jù)庫中。MySQL復(fù)制是異步且串行化的。
復(fù)制基本原則
- 每個Slave只有一個Master。
- 每個Slave只能有一個唯一的服務(wù)器ID。
- 每個Master可以有多個Salve。
一主一從配置
1、基本要求:Master和Slave的MySQL服務(wù)器版本一致且后臺以服務(wù)運(yùn)行。
# 創(chuàng)建mysql-slave1實(shí)例
docker run -p 3307:3306 --name mysql-slave1 \
-v /root/mysql-slave1/log:/var/log/mysql \
-v /root/mysql-slave1/data:/var/lib/mysql \
-v /root/mysql-slave1/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=333 \
-d mysql:5.7
2、主從配置都是配在[mysqld]節(jié)點(diǎn)下,都是小寫
# Master配置
[mysqld]
server-id=1 # 必須
log-bin=/var/lib/mysql/mysql-bin # 必須
read-only=0
binlog-ignore-db=mysql
# Slave配置
[mysqld]
server-id=2 # 必須
log-bin=/var/lib/mysql/mysql-bin
3、Master配置
# 1、GRANT REPLICATION SLAVE ON *.* TO 'username'@'從機(jī)IP地址' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'zhangsan'@'172.18.0.3' IDENTIFIED BY '123456';
Query OK, 0 rows affected, 1 warning (0.01 sec)
# 2、刷新命令
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
# 3、記錄下File和Position
# 每次配從機(jī)的時候都要SHOW MASTER STATUS;查看最新的File和Position
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 602 | | mysql | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
4、Slave從機(jī)配置
CHANGE MASTER TO MASTER_HOST='172.18.0.4',
MASTER_USER='zhangsan',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.File的編號',
MASTER_LOG_POS=Position的最新值;
# 1、使用用戶名密碼登錄進(jìn)Master
mysql> CHANGE MASTER TO MASTER_HOST='172.18.0.4',
-> MASTER_USER='zhangsan',
-> MASTER_PASSWORD='123456',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=602;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
# 2、開啟Slave從機(jī)的復(fù)制
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)
# 3、查看Slave狀態(tài)
# Slave_IO_Running 和 Slave_SQL_Running 必須同時為Yes 說明主從復(fù)制配置成功!
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event # Slave待命狀態(tài)
Master_Host: 172.18.0.4
Master_User: zhangsan
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 602
Relay_Log_File: b030ad25d5fe-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 602
Relay_Log_Space: 534
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: bd047557-b20c-11ea-9961-0242ac120002
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
5、測試主從復(fù)制
# Master創(chuàng)建數(shù)據(jù)庫
mysql> create database test_replication;
Query OK, 1 row affected (0.01 sec)
# Slave查詢數(shù)據(jù)庫
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test_replication |
+--------------------+
5 rows in set (0.00 sec)
6、停止主從復(fù)制功能
# 1、停止Slave
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
# 2、重新配置主從
# MASTER_LOG_FILE 和 MASTER_LOG_POS一定要根據(jù)最新的數(shù)據(jù)來配
mysql> CHANGE MASTER TO MASTER_HOST='172.18.0.4',
-> MASTER_USER='zhangsan',
-> MASTER_PASSWORD='123456',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=797;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.18.0.4
Master_User: zhangsan
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 797
Relay_Log_File: b030ad25d5fe-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 797
Relay_Log_Space: 534
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: bd047557-b20c-11ea-9961-0242ac120002
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號