
go筆記
1、Slice和Map的本質
- 切片(Slice)是一個擁有相同類型元素的可變長度的序列。它是基于數組類型做的一層封裝。它非常靈活,支持自動擴容。
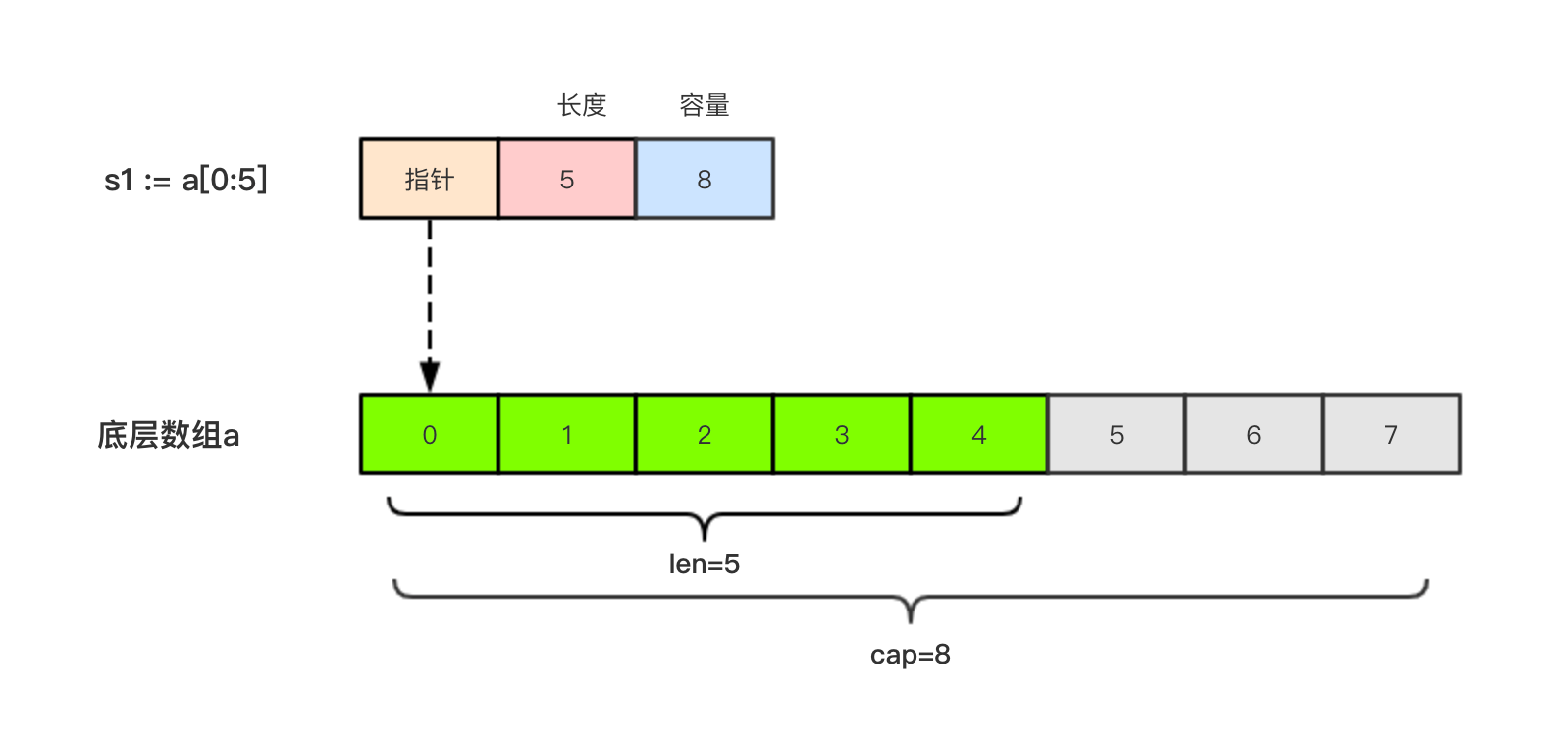
判斷切片是否為空用len(),不能用nil
sort
//切片才能用sort
var a1 = [...]int{3, 7, 8, 9, 1} //屬于數組
a2:=a1[:] //使用后遍切片
sort.Ints(a1[:]) //才可以使用sort
//sort.Ints(a1)
fmt.Println(a,len(a))
fmt.Printf("%#+v",a1)
fmt.Printf("%#+v",a2)
拷貝
-
淺拷貝只復制指向某個對象的指針,而不復制對象本身,新舊對象還是共享同一塊內存。但深拷貝會另外創造一個一模一樣的對象,新對象跟原對象不共享內存,修改新對象不會改到原對象。使用copy才是深拷貝
-
首先go的變量要不在棧上要不在堆上,棧上的變量會在函數銷毀的時候就釋放了,堆上的就要靠gc算法來了,我們一般說從棧逃逸到堆上或者一開始直接就在堆上的變量內存叫做內存逃逸
從切片中刪除元素
Go語言中并沒有刪除切片元素的專用方法,我們可以使用切片本身的特性來刪除元素。 代碼如下:
func main() {
// 從切片中刪除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要刪除索引為2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
}
map
map,鍵值對,使用hash表結合數組和鏈表優點
-
數組:創建需要連續的內存空間,數據類型必須一致,可以索引下表查詢獲取元素O(1),插入需要遍歷每個元素O(n)
-
鏈表:不需要連續的內存空間,數據類型可以不一致,必須包含一個指向下一個數據元素的內存地址指針,查詢要遍歷O(n),插入刪除O(1)
-
hash:使用余數法對key取余數作為數組的索引,落到數組的一個槽中(每個槽并不存放k-v數據,它們都是指針),然后使用鏈表將k-v連接起來。查詢的時候,獲取槽位后,hash余數相同時使用,鏈地址法接在同個鏈表,遍歷鏈表來查詢
-
哈希函數會將傳入的key值進行哈希運算,得到一個唯一的值。go語言把生成的哈希值一分為二,比如一個key經過哈希函數,生成的哈希值為:8423452987653321,go語言會這它拆分為84234529,和87653321。那么,前半部分就叫做高位哈希值,后半部分就叫做低位哈希值。
高位哈希值(bmap):是用來確定當前的bucket(桶)有沒有所存儲的數據的。
低位哈希值(hmap):是用來確定,當前的數據存在了哪個bucket(桶)1.1 根據key計算hash值;
1.2 hash值低位hmap.B取模來確定bucket的位置;
1.3 取hash值高位在bhmap的tophash數組中查詢;
1.4 當前key的hash值與tophash[i]中存儲的hash值相等的話,就去data里面找key;如果不相等,是因為觸發了hash沖突,,但是key不相同,通過overflow指針就去鏈表中下一個溢出bucket中查找,直到查找到鏈表的末尾
1.5 當前的bucket沒找到,就去overflow中的bucket中去找。
需要主要的是,在發生數據搬遷過程中,查找優先從oldbucket中進行;另外,找不到,會返回對應類型的零值,而不是nil
3、chan
- 通道像一個傳送帶或者隊列,總是遵循先入先出
qcount 當前的隊列,剩余元素個數
dataqsiz 環形隊列可以存放的元素個數,也就是環形隊列的長度
buf 指針,指向環形隊列 //循環隊列
elemsize 指的的隊列中每個元素的大小
closed 具體標識關閉的狀態
elemtype 見名知意,元素的類型
sendx 發送隊列的下標,向隊列中寫入數據的時候,存放在隊列中的位置
recvx 接受隊列的下標,從隊列的 這個位置開始讀取數據
recvq 協程隊列,等待讀取消息的協程隊列
sendq 協程隊列,等待發送消息的協程隊列
lock 互斥鎖,在 chan 中,不可以并發的讀寫數據
寫 入chan
第一張圖說明白向 chan 寫入數據的流程

向通道中寫入數據,
根據圖示可以看出向通道中寫入數據分為 3 種情況:
寫入數據的時候,若recvq 隊列為空,且循環隊列有空位,那么就直接將數據寫入到 循環隊列的隊尾 即可
若recvq 隊列為空,且循環隊列無空位,則將當前的協程放到sendq等待隊列中進行阻塞,等待被喚醒,當被喚醒的時候,需要寫入的數據,已經被讀取出來,且已經完成了寫入操作
若recvq 隊列為不為空,那么可以說明循環隊列中沒有數據,或者循環隊列是空的,即沒有緩沖區(向無緩沖的通道寫入數據),此時,直接將recvq等待隊列中取出一個G,寫入數據,喚醒G,完成寫入操作
讀取chan

向通道中讀取數據,我們會涉及sendq 、 recvq隊列,和循環隊列的資源問題
根據圖示可以看出向通道中讀取數據分為 4 種情況:
若sendq為空,且循環隊列無元素的時候,那就將當前的協程加入recvq等待隊列,把recvq等待隊列對頭的一個協程取出來,喚醒,讀取數據
若sendq為空,且循環隊列有元素的時候,直接讀取循環隊列中的數據即可
若sendq有數據,且循環隊列有元素的時候,直接讀取循環隊列中的數據即可,且把sendq隊列取一個G放到循環隊列中,進行補充
若sendq有數據,且循環隊列無元素的時候,則從sendq取出一個G,并且喚醒他,進行數據讀取操作
上面說了通道的創建,讀寫,那么通道咋關閉?
通道的關閉,我們在應用的時候直接 close 就搞定了,那么對應close的時候,底層的隊列都是做了啥呢?
若關閉了當前的通道,那么系統會把recvq 讀取數據的等待隊列里面的所有協程,全部喚醒,這里面的每一個G 寫入的數據 默認就寫個 nil,因為通道關閉了,從關閉的通道里面讀取數據,讀到的是nil
4、RPC
在本地調用中,函數主體通過函數指針函數指定,然后調用 add 函數,編譯器通過函數指針函數自動確定 add 函數在內存中的位置。但是在 RPC 中,調用不能通過函數指針完成,因為它們的內存地址可能完全不同。因此,調用方和被調用方都需要維護一個{ function <-> ID }映射表,以確保調用正確的函數,并且基于RESTful API通常是基于HTTP協議,傳輸數據采用JSON等文本協議,相較于RPC 直接使用TCP協議,傳輸數據多采用二進制協議來說,RPC通常相比RESTful API性能會更好。
5、GRPC
-
https://www.liwenzhou.com/posts/Go/gRPC/#autoid-0-3-4
gRPC幫你解決了不同語言及環境間通信的復雜性。使用
protocol buffers還能獲得其他好處,包括高效的序列化,簡單的IDL以及容易進行接口更新。總之一句話,使用gRPC能讓我們更容易編寫跨語言的分布式代碼。
服務方法
- 普通 rpc,客戶端向服務器發送一個請求,然后得到一個響應,就像普通的函數調用一樣。
rpc SayHello(HelloRequest) returns (HelloResponse);
- 服務器流式 rpc,其中客戶端向服務器發送請求,并獲得一個流來讀取一系列消息。客戶端從返回的流中讀取,直到沒有更多的消息。gRPC 保證在單個 RPC 調用中的消息是有序的。
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse);
- 客戶端流式 rpc,其中客戶端寫入一系列消息并將其發送到服務器,同樣使用提供的流。一旦客戶端完成了消息的寫入,它就等待服務器讀取消息并返回響應。同樣,gRPC 保證在單個 RPC 調用中對消息進行排序。
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse);
- 雙向流式 rpc,其中雙方使用讀寫流發送一系列消息。這兩個流獨立運行,因此客戶端和服務器可以按照自己喜歡的順序讀寫: 例如,服務器可以等待接收所有客戶端消息后再寫響應,或者可以交替讀取消息然后寫入消息,或者其他讀寫組合。每個流中的消息是有序的。
6、 context 結構原理
4.1 用途
Context(上下文)是 Golang 應用開發常用的并發控制技術 ,它可以控制一組呈樹狀結構的 goroutine,每個 goroutine 擁有相同的上下文。Context 是并發安全的,主要是用于控制多個協程之間的協作、取消操作。
4.2 數據結構
Context 只定義了接口,凡是實現該接口的類都可稱為是一種 context。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
復制代碼
- 「Deadline」 方法:可以獲取設置的截止時間,返回值 deadline 是截止時間,到了這個時間,Context 會自動發起取消請求,返回值 ok 表示是否設置了截止時間。
- 「Done」 方法:返回一個只讀的 channel ,類型為 struct{}。如果這個 chan 可以讀取,說明已經發出了取消信號,可以做清理操作,然后退出協程,釋放資源。
- 「Err」 方法:返回 Context 被取消的原因。
- 「Value」 方法:獲取 Context 上綁定的值,是一個鍵值對,通過 key 來獲取對應的值。
7、內存
內存與堆內存的區別
棧內存一般由操作系統分配與釋放;堆內存一般由程序自身申請與釋放
棧內存一般存放函數參數、函數返回值、局部變量、函數調用時的臨時上下文等;堆內存一般存放全局變量
棧內存比堆內存訪問速度更快
每個線程分配一個棧內存;每個進程分配一個堆內存
棧內存創建時,內存大小是固定的,越界則會發生stack overflow錯誤;堆內存創建時,內存大小不固定,可隨程序運行增加或減少
棧內存是由高地址向低地址增長;堆內存是由低地址向高地址增長
Golang內存管理
基礎信息
Golang是自己管理內存,不依賴操作系統,即向操作系統申請一塊較大內存,然后自己決定將變量分配到棧空間或對空間
分配選擇:基本同上面的分配原則,但對于函數的引用參數會有一些特殊。如果編譯器無法證明函數返回之后變量是否仍然被引用,此時就必須在堆空間分配該變量,隨后采用垃圾回收機制管理,而從避免指針懸空。此外,如果局部變量過大,也會選擇分配在堆空間
總結:最終的分配空間在于編譯器的選擇,編譯器分析變量的生存周期的過程就叫做逃逸分析
棧內存
棧內存的分配與釋放全權由操作系統決定,開發者無法控制。一般棧內存會自動創建,函數返回的時候內存會被自動釋放。棧內存的分配與釋放速度較快
堆內存
對存有由于不確定大小,因此代價就是分配速度較慢且會形成內存碎片。堆內存不能自動被編譯器釋放,只能通過垃圾回收器才能釋放
內存逃逸
把函數內的局部變量通過指針形式 返回
發送指針或帶有指針的值到channel中
在切片中存儲指針或帶指針的值
Slice的底層數組被重新分配。比如使用append向容量已滿的Slice追加元素,會重新為Slice分配底層數組
在interface類型上調用方法。因為interface類型調用方法都是動態調度,只有在運行的時候才能知道真正的實現
優化
盡可能避免內存逃逸,因為棧內存的效率遠高于堆內存
無法避免的逃逸現象,對于頻繁的內存申請操作,可以試著重用內存。比如通過sync.Pool
8、協程和線程和進程的區別?
- 進程:進程是具有一定獨立功能的程序,進程是系統資源分配和調度的最小單位。 每個進程都有自己的獨立內存空間,不同進程通過進程間通信來通信。由于進程比較重量,占據獨立的內存,所以上下文進程間的切換開銷(棧、寄存器、虛擬內存、文件句柄等)比較大,但相對比較穩定安全。
- 進程間通信:管道、消息隊列、共享內存、信號量、socket
- 線程:線程是進程的一個實體,線程是內核態,而且是 CPU 調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位。線程間通信主要通過共享內存,上下文切換很快,資源開銷較少,但相比進程不夠穩定容易丟失數據。
- 協程:協程是一種用戶態的輕量級線程,協程的調度完全是由用戶來控制的。協程擁有自己的寄存器上下文和棧。 協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧,直接操作棧則基本沒有內核切換的開銷,可以不加鎖的訪問全局變量,所以上下文的切換非常快。
9. GPM 調度 和 CSP 模型
GPM模型是Golang目前正在使用的模型
內核空間:創建多個操作系統內核線程 (這個是底層實現的,我們改變不了,只能進行使用)
用戶空間:創建多個協程 (語言層面,不同的語言做出來的協程調度器是不一樣的)
此時就引入了協程與線程比例數
-
協程:線程 = M :1,就是多個協程對應一個線程,此時如果一個協程阻塞了,那么其他協程還是會進行等待,這樣解決不了問題
-
協程:線程 = 1 : 1,就是一個協程對應一個線程,此時還不如不要協程,創建一個協程就得創建一個線程,這樣的直接用線程是一樣的
-
協程:線程 = M : N,就是多個協程對應多個線程,協程的數量肯定是比線程多得多,所以GPM模型就采用的M :N的方式
-
————————————————
-
版權聲明:本文為CSDN博主「鋼鋼鋼很不爽」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
-
原文鏈接:https://blog.csdn.net/weixin_45672178/article/details/113767196
2.1 CSP 模型?
CSP 模型是“以通信的方式來共享內存”,不同于傳統的多線程通過共享內存來通信。用于描述兩個獨立的并發實體通過共享的通訊 channel (管道)進行通信的并發模型。
2.2 GPM 分別是什么、分別有多少數量?
- G(Goroutine): 即 Go 協程,每個 go 關鍵字都會創建一個協程。
- 8M(Machine):工作線程,在 Go 中稱為 Machine,數量對應真實的 CPU 數(真正干活的對象)默認10000.。runtime/debug中的SetMaxThreads函數,設置M的最大數量
- P(Processor): 處理器(Go 中定義的一個摡念,非 CPU),包含運行 Go 代碼的必要資源,用來調度 G 和 M 之間的關聯關系,其數量可通過 GOMAXPROCS() 來設置,默認為CPU核心數。由啟動時環境變量
$GOMAXPROCS或者是由runtime的方法`GOMAXPROCS()
3.GPM調度流程
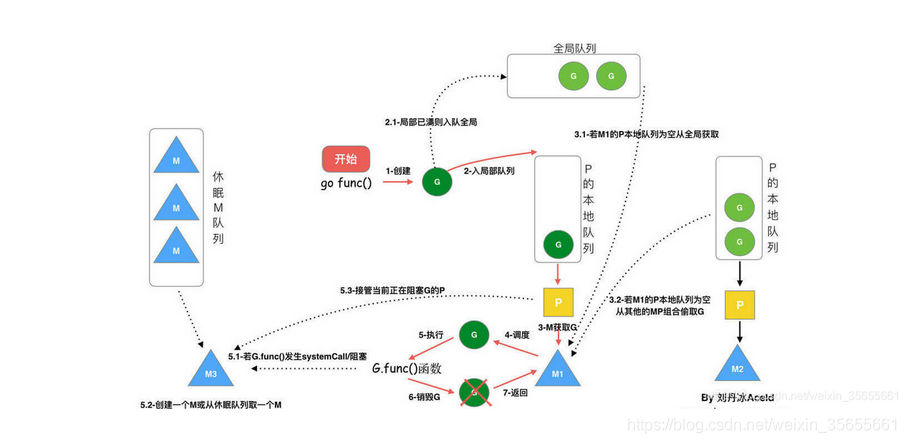
從上圖我們可以分析出幾個結論:
1)我們通過 go func () 來創建一個 goroutine;
2)有兩種存儲 G 的隊列,一個是局部調度器 P 的本地隊列、一個是全局 G 隊列;新創建的 G 會先保存在 P 的本地隊列中,如果 P 的本地隊列已經滿了就會保存在全局的隊列中;
3)G 只能運行在 M 中,一個 M 必須持有一個 P,M 與 P 是 1:1 的關系;M 會從 P 的本地隊列彈出一個 G 來執行,如果 P 的本地隊列為空,就會想其他的 MP 組合偷取一個可執行的 G;
4) 一個 M 調度 G 執行的過程是一個循環機制;
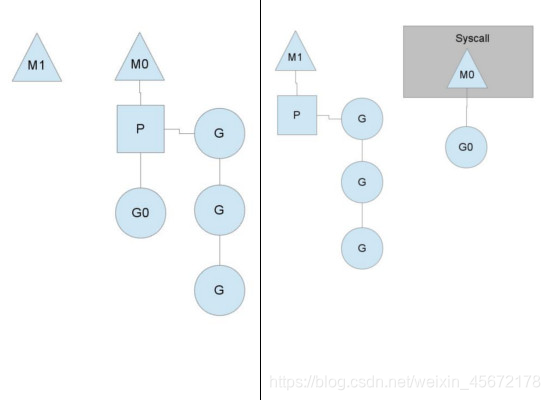
1.系統調度引起阻塞:
當 M 執行某一個 G 時候如果發生了 syscall 如GC,M 會阻塞;M就會繼續處理這個進入系統調用的G協程,但是他會釋放掉自己關聯的P本地隊列,同時會有新的M去接替執行這個P本地隊列如果當前有一些 G 在執行,當 M 系統調用結束時候,這個 G 會嘗試獲取一個空閑的 P 執行,并放入到這個 P 的本地隊列;如果獲取不到 P,那么這個線程 M 變成休眠狀態, 加入到空閑線程中,然后這個 G 會被放入全局隊列中。
2.用戶態的阻塞:
當goroutine因為管道操作或者系統IO、網絡IO而阻塞時,對應的G會被放置到某個等待隊列,該G的狀態由運行時變為等待狀態,而M會跳過該G嘗試獲取并執行下一個G,如果此時沒有可運行的G供M運行,那么M將解綁P,并進入休眠狀態;當阻塞的G被另一端的G2喚醒時,如管道通知-=0G又被標記為可運行狀態,嘗試加入G2所在P局部隊列的隊頭,然后再是G全局隊列。
6)當存在空閑的P時,竊取其他隊列的G:當P維護的局部隊列全部運行完畢,它會嘗試在全局隊列獲取G,直到全局隊列為空,再向其他局部隊列竊取一般的G。
————————————————
版權聲明:本文為CSDN博主「良中子」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/weixin_35655661/article/details/119573864
(2)調度器的設計策略
復用線程:避免頻繁的創建、銷毀線程,而是對線程的復用。
1)work stealing機制
當本線程無可運行的G時,嘗試從其他線程綁定的P偷取G,而不是銷毀線程。
2)hand off機制
當本線程因為G進行系統調用阻塞時,線程釋放綁定的P,把P轉移給其他空閑的線程執行。
利用并行:GOMAXPROCS設置P的數量,最多有GOMAXPROCS個線程分布在多個CPU上同時運行。GOMAXPROCS也限制了并發的程度,比如GOMAXPROCS = 核數/2,則最多利用了一半的CPU核進行并行。
搶占:在coroutine中要等待一個協程主動讓出CPU才執行下一個協程,在Go中,一個goroutine最多占用CPU 10ms,防止其他goroutine被餓死,這就是goroutine不同于coroutine的一個地方。
全局和本地隊列:在新的調度器中依然有全局G隊列,但功能已經被弱化了,當M執行work stealing從其他P偷不到G時,它可以從全局G隊列獲取G。
10. 垃圾回收
https://www.jianshu.com/p/8b0c0f7772da
1.1 常見的垃圾回收算法:
- 引用計數:每個對象維護一個引用計數,當被引用對象被創建或被賦值給其他對象時引用計數自動加 +1;如果這個對象被銷毀,則計數 -1 ,當計數為 0 時,回收該對象。
- 優點:對象可以很快被回收,不會出現內存耗盡或到達閥值才回收。
- 缺點:不能很好的處理循環引用
- 標記-清除:從根變量開始遍歷所有引用的對象,引用的對象標記“被引用”,沒有被標記的則進行回收。
- 優點:解決了引用計數的缺點。
- 缺點:需要 STW(stop the world),暫時停止程序運行。
- 分代收集:按照對象生命周期長短劃分不同的代空間,生命周期長的放入老年代,短的放入新生代,不同代有不同的回收算法和 回收頻率。
- 優點:回收性能好
- 缺點:算法復雜
- 對于 Go 而言,Go 的 GC 目前使用的是無分代(對象沒有代際之分)、不整理(回收過程中不對對象進行移動與整理)、并發(與用戶代碼并發執行)的三色標記清掃算法。
1.2 三色標記法
- 初始狀態下所有對象都是白色的。
- 從根節點開始遍歷所有對象,把遍歷到的對象變成灰色對象
- 遍歷灰色對象,將灰色對象引用的對象也變成灰色對象,然后將遍歷過的灰色對象變成黑色對象。
- 循環步驟 3,直到灰色對象全部變黑色。
- 通過寫屏障(write-barrier)檢測對象有變化,重復以上操作
- 收集所有白色對象(垃圾)。
1.3 STW(Stop The World)
- 為了避免在 GC 的過程中,對象之間的引用關系發生新的變更,使得 GC 的結果發生錯誤(如 GC 過程中新增了一個引用,但是由于未掃描到該引用導致將被引用的對象清除了),停止所有正在運行的協程。
- STW 對性能有一些影響,Golang 目前已經可以做到 1ms 以下的 STW。
1.4 寫屏障(Write Barrier)
- 為了避免 GC 的過程中新修改的引用關系到 GC 的結果發生錯誤,我們需要進行 STW。但是 STW 會影響程序的性能,所以我們要通過寫屏障技術盡可能地縮短 STW 的時間。
造成引用對象丟失的條件
- 一個黑色的節點A新增了指向白色節點C的引用
- 并且白色節點C沒有除了A之外的其他灰色節點的引用,或者存在但是在GC過程中被刪除了
以上兩個條件需要同時滿足:滿足條件1時說明節點A已掃描完畢,A指向C的引用無法再被掃描到;滿足條件2時說明白色節點C無其他灰色節點的引用了,即掃描結束后會被忽略 。
寫屏障破壞兩個條件其一即可
- 破壞條件1 => Dijistra寫屏障
- 滿足強三色不變性:黑色節點不允許引用白色節點
- 當黑色節點新增了白色節點的引用時,將對應的白色節點改為灰色
- 不足:結束時需要使用STW來重新掃描棧
- 破壞條件2 => Yuasa寫屏障
- 滿足弱三色不變性:黑色節點允許引用白色節點,但是該白色節點有其他灰色節點間接的引用(確保不會被遺漏)
- 當白色節點被刪除了一個引用時,悲觀地認為它一定會被一個黑色節點新增引用,所以將它置為灰色
- 刪除屏障的不足:回收精度低,一個對象即使被刪除了最后一個指向它的指針也依舊可以活過這一輪,在下一輪GC中被清理掉。
11、mutext、rwmutext
mutex 狀態標志位
mutex 的 state 有 32 位,它的低 3 位分別表示 3 種狀態:喚醒狀態、上鎖狀態、饑餓狀態,剩下的位數則表示當前阻塞等待的 goroutine 數量。
mutex 會根據當前的 state 狀態來進入正常模式、饑餓模式或者是自旋。
mutex 正常模式
當 mutex 調用 Unlock() 方法釋放鎖資源時,如果發現有等待喚起的 Goroutine 隊列時,則會將隊頭的 Goroutine 喚起。
隊頭的 goroutine 被喚起后,會調用 CAS 方法去嘗試性的修改 state 狀態,如果修改成功,則表示占有鎖資源成功。
(注:CAS 在 Go 里用 atomic.CompareAndSwapInt32(addr *int32, old, new int32) 方法實現,CAS 類似于樂觀鎖作用,修改前會先判斷地址值是否還是 old 值,只有還是 old 值,才會繼續修改成 new 值,否則會返回 false 表示修改失敗。)
mutex 饑餓模式
由于上面的 Goroutine 喚起后并不是直接的占用資源,還需要調用 CAS 方法去嘗試性占有鎖資源。如果此時有新來的 Goroutine,那么它也會調用 CAS 方法去嘗試性的占有資源。
但對于 Go 的調度機制來講,會比較偏向于 CPU 占有時間較短的 Goroutine 先運行,而這將造成一定的幾率讓新來的 Goroutine 一直獲取到鎖資源,此時隊頭的 Goroutine 將一直占用不到,導致餓死。
針對這種情況,Go 采用了饑餓模式。即通過判斷隊頭 Goroutine 在超過一定時間后還是得不到資源時,會在 Unlock 釋放鎖資源時,直接將鎖資源交給隊頭 Goroutine,并且將當前狀態改為饑餓模式。
后面如果有新來的 Goroutine 發現是饑餓模式時, 則會直接添加到等待隊列的隊尾。
mutex 自旋
如果 Goroutine 占用鎖資源的時間比較短,那么每次都調用信號量來阻塞喚起 goroutine,將會很浪費資源。
因此在符合一定條件后,mutex 會讓當前的 Goroutine 去空轉 CPU,在空轉完后再次調用 CAS 方法去嘗試性的占有鎖資源,直到不滿足自旋條件,則最終會加入到等待隊列里。
自旋的條件如下:
- 還沒自旋超過 4 次
- 多核處理器
- GOMAXPROCS > 1
- p 上本地 Goroutine 隊列為空
可以看出,自旋條件還是比較嚴格的,畢竟這會消耗 CPU 的運算能力。
mutex 的 Lock() 過程
首先,如果 mutex 的 state = 0,即沒有誰在占有資源,也沒有阻塞等待喚起的 goroutine。則會調用 CAS 方法去嘗試性占有鎖,不做其他動作。
如果不符合 m.state = 0,則進一步判斷是否需要自旋。
當不需要自旋又或者自旋后還是得不到資源時,此時會調用 runtime_SemacquireMutex 信號量函數,將當前的 goroutine 阻塞并加入等待喚起隊列里。
當有鎖資源釋放,mutex 在喚起了隊頭的 goroutine 后,隊頭 goroutine 會嘗試性的占有鎖資源,而此時也有可能會和新到來的 goroutine 一起競爭。
當隊頭 goroutine 一直得不到資源時,則會進入饑餓模式,直接將鎖資源交給隊頭 goroutine,讓新來的 goroutine 阻塞并加入到等待隊列的隊尾里。
對于饑餓模式將會持續到沒有阻塞等待喚起的 goroutine 隊列時,才會解除。
Unlock 過程
mutex 的 Unlock() 則相對簡單。同樣的,會先進行快速的解鎖,即沒有等待喚起的 goroutine,則不需要繼續做其他動作。
如果當前是正常模式,則簡單的喚起隊頭 Goroutine。如果是饑餓模式,則會直接將鎖交給隊頭 Goroutine,然后喚起隊頭 Goroutine,讓它繼續運行。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號