
Gaia2 與 ARE:賦能社區的智能體評測
在理想情況下,AI 智能體應當是可靠的助手。當接收到任務時,它們能夠輕松處理指令中的歧義,構建逐步執行的計劃,正確識別所需資源,按計劃執行而不被干擾,并在突發事件中靈活適應,同時保持準確性,避免幻覺。
然而,開發智能體并測試這些行為并非易事:如果你曾嘗試過調試自己的智能體,可能會體會到其中的繁瑣和挫敗感。現有的評測環境通常與特定任務緊密耦合,缺乏真實世界的靈活性,也無法反映開放世界中混亂的現實:模擬頁面不會加載失敗,事件不會自發發生,也不存在異步混亂。
因此,我們很高興地介紹 Gaia2 ——智能體基準 GAIA 的后續版本,它能夠分析更復雜的行為。Gaia2 與開放的 Meta Agents Research Environments (ARE) 框架一同發布,用于運行、調試和評測智能體。ARE 可以模擬復雜、接近真實世界的條件,并支持定制化,以便進一步研究智能體行為。Gaia2 數據集以 CC BY 4.0 許可證發布,ARE 框架則以 MIT 許可證開源。

圖 1:Gaia2 的預算擴展曲線(Budget Scaling Curves)。隨著預算增加,智能體在任務上的表現逐漸提升,用于展示在復雜環境中智能體能力隨資源投入的變化趨勢。
Gaia2:真實場景助理任務上的智能體評測
GAIA 是 2023 年發布的一個智能體基準測試,包含三類信息檢索問題,需要工具調用、網頁瀏覽和推理能力才能完成。兩年過去,如今最簡單的題目對模型來說已經過于容易,而社區也逐漸接近攻克最難的部分問題,因此,是時候推出一個全新且更具挑戰性的智能體基準了!
這就是 Gaia2 —— GAIA 的全新升級版本,在能力覆蓋與研究深度上都有大幅拓展!
相比于只讀的 GAIA,Gaia2 升級為可讀寫的評測基準,更加關注交互行為與復雜性管理。
在 Gaia2 中,智能體不僅要完成搜索與檢索任務,還需要在充滿不確定性和時間敏感性的指令下執行操作,并在包含可控故障的嘈雜環境中運行——這一設定比以往任何模擬環境都更接近真實世界。
我們希望測試智能體在以下場景下的表現:
- 當工具或 API 偶爾失效時如何應對;
- 如何在嚴格的時間窗口中規劃一系列動作;
- 如何快速適應突發事件。
這意味著智能體將面臨全新的復雜性挑戰!
為此,我們設計了以下任務組(基于全新創作的 1000 個人工場景):
- 執行能力(Execution):多步驟指令執行與工具使用(如更新聯系人信息)
- 搜索能力(Search):跨來源信息收集(如從 WhatsApp 獲取朋友所在城市)
- 歧義處理(Ambiguity Handling):澄清沖突請求(如解決日程沖突)
- 適應性(Adaptability):應對模擬環境中的變化(如根據后續信息修改郵件)
- 時間/時序推理(Time/Temporal Reasoning):處理時間敏感任務(如延遲 3 分鐘后再叫車)
- 智能體間協作(Agent-to-Agent Collaboration):在無直接 API 訪問的情況下進行智能體間通信
- 噪聲容忍度(Noise Tolerance):在 API 故障和環境不穩定條件下保持穩健
延續 GAIA 的設計理念,這些場景不依賴專業知識 理論上人類可以輕松達到 100% 完成度,從而方便模型開發者進行調試和改進。
想要深入體驗這個基準嗎?歡迎查看我們的 數據集,
你也可以通過我們的 在線演示 更直觀地探索與展示。
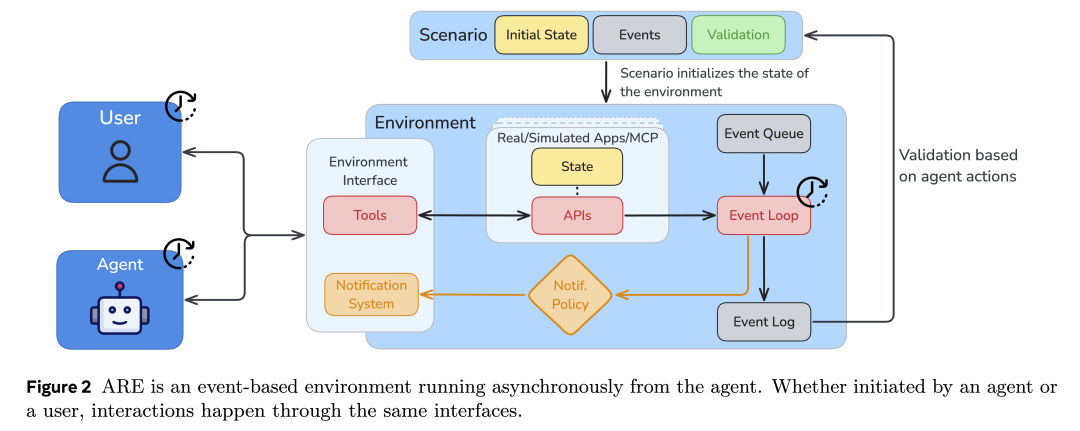
Gaia2 如何運行?
Gaia2 運行在 ARE(Agent Research Environments)執行環境中,在這里,用戶可以選擇任意智能體,并賦予其對一系列應用程序及預置數據的訪問能力。
針對 Gaia2,我們打造了一個 智能手機模擬環境,再現人類日常生活中的使用場景。環境中包含真實世界常見的應用,如消息類(電子郵件)、工具類(日歷、聯系人、購物、文件系統等),以及一個與智能體對話的聊天界面。所有應用也都可以通過工具調用的方式被智能體訪問。更有趣的是,演示環境還附帶了一個虛擬用戶的歷史對話與應用交互記錄。
在運行過程中,所有智能體的交互都會被自動記錄為 結構化軌跡(structured traces),以便深入分析。這些軌跡包括:工具調用、API 響應、模型思考過程、時間指標(如響應延遲)、用戶交互等,并可導出為 JSON 文件。
結果展示
作為參考,我們對比了多款開源與閉源的大模型,包括:Llama 3.3-70B Instruct、Llama-4-Maverick、GPT-4o、Qwen3-235B-MoE、Grok-4、Kimi K2、Gemini 2.5 Pro、Claude 4 Sonnet,以及 GPT-5 在不同推理模式下的表現。
所有模型均在相同配置下進行評測:采用統一的 ReAct 循環確保一致性,溫度設定為 0.5,最大生成上限為 16K tokens。根據具體任務類型,評測方式結合了“模型判別(以 Llama 3.3 Instruct 70B 作為評審)”和“嚴格匹配(exact-match)”兩種方法。同時,系統提示中預置了全部 101 個工具及通用環境描述。

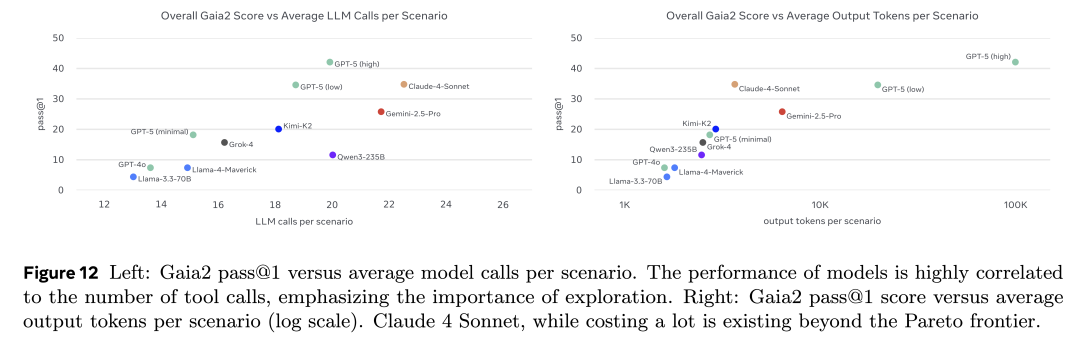
在評測的模型中,截至 2025 年 9 月,整體得分最高的模型是具備強大推理能力的 GPT-5,而表現最好的開源模型則是 Kimi K2。
從能力維度來看,一些任務已經被頂級模型基本解決:例如簡單工具調用與指令執行(execution),以及整體的檢索能力(search)(這一點從 GAIA 的結果中已經有所預期)。然而,歧義處理(ambiguity)、適應性(adaptability)和抗噪性(noise)依舊是所有模型的普遍挑戰。值得注意的是,那些過去被認為復雜的智能體任務(如指令執行與信息檢索),并不能很好預測模型在更貼近真實世界任務上的表現。最后,目前所有模型在 time 維度上的表現最為薄弱:在處理時間敏感型操作上仍然非常困難(不過,未來通過專用工具與更好的時間推理機制可能有所改善)。詳細分析可見論文正文。
同時,我們認為必須超越單純的分數匯報:如果一個模型雖然答對了,但需要消耗數千個 token 或運行數小時才能得出結果,那么它的表現顯然“不如”另一款在更短時間、更低成本下完成任務的模型。
因此,我們對得分進行了成本歸一化:通過平均 LLM 調用次數與輸出 token 數量來量化,并繪制出性能—成本的帕累托前沿(Pareto frontier)。在論文中,你將看到模型得分與實際金錢成本及耗時的對比結果。
與您喜愛的模型對比!在 Gaia2 上進行評測
如果你想在 Gaia2 上評測自己的模型,可以按照以下步驟操作:
首先,在你選擇的 Python 環境(uv、conda、virtualenv 等)中安裝 Meta 的 Agent Research Environment:
pip install meta-agents-research-environments
然后,運行基準測試,覆蓋所有配置:執行(execution)、檢索(search)、適應性(adaptability)、時間(time)以及歧義(ambiguity)。
別忘了使用 hf_upload 參數將結果上傳到 Hugging Face Hub!
運行基準測試的示例命令如下:
are-benchmark run --hf meta-agents-research-environments/Gaia2 --split validation --config CONFIGURATION --model YOUR_MODEL --model_provider YOUR_PROVIDER --agent default --max_concurrent_scenarios 2 --scenario_timeout 300 --output_dir ./monitored_test_results --hf_upload YOUR_HUB_DATASET_TO_SAVE_RESULTS
運行 oracle 來生成匯總得分文件。
are-benchmark judge --hf meta-agents-research-environments/Gaia2 --split validation --config CONFIGURATION --agent default --max_concurrent_scenarios 2 --scenario_timeout 300 --output_dir ./monitored_test_results --hf_upload YOUR_HUB_DATASET_TO_SAVE_RESULTS
最后,請在 README 中補充與你的模型相關的所有信息,并將結果分享到排行榜,以便在 這里 集中展示 Gaia2 的運行軌跡!
超越 Gaia2:用 ARE 深入研究你的智能體
除了基準場景外,你還可以在 ARE 中使用 Gaia2 的應用和內容,測試模型是否能夠正確完成一些更難驗證的任務,例如加載郵件、撰寫跟進回復、在日歷中添加事件或預約會議。總之,ARE 提供了一個通過交互來評估 AI 助手的理想環境!
你也可以輕松定制環境:
- 連接你的工具(通過 MCP 或直接接入),在其上測試智能體;
- 實現自定義場景,包括設置 觸發事件或定時事件(例如:2 分鐘后,郵件應用收到來自聯系人的新郵件),從而觀察智能體如何適應動態變化的環境。
(默認情況下,智能體運行在 json agent 模式下,不會對你的本地機器造成影響;除非你將它們連接到具備不安全權限的外部應用。因此,在添加自定義應用或使用不可信的 MCP 時,請務必保持謹慎。)
以下是我們使用 ARE 的一些典型場景:
- 快速評估任意智能體:基于真實或模擬數據,測試不同規則、工具、內容和驗證方式下的表現
- 測試智能體的 工具調用與編排能力:可結合本地應用或 MCP 工具
- 生成自定義的工具調用軌跡,用于 微調具備工具調用能力的模型
- 在統一框架下,輕松收集并 復現現有的智能體基準測試
- 在用戶界面中,實時調試并 研究智能體之間的交互
- 在嘈雜環境中(如 API 超時、任務歧義),研究模型的局限性
我們錄制了 3 段視頻,展示了其中的一些使用場景(當然,我們也希望社區能在 ARE 上發揮更多創造力 :hugging_face:)。
這些視頻基于前文提到的默認演示環境,內容模擬了一位名為 Linda Renne 的機器學習博士生的日常生活。
1) 測試智能體在簡單任務中的表現:活動組織
為了測試默認模型在活動組織上的能力,我們來策劃一場生日派對! ??
首先,我們讓智能體給 Renne 家族的成員群發短信,告知用戶的 30 歲生日派對將在 11 月 7 日舉行。默認的模擬環境中共有 21 個聯系人,其中 5 位屬于 Renne 家族 —— 包括模擬“主人”Linda、她的父母 George 和 Stephie、妹妹 Anna,以及祖父 Morgan。智能體成功遍歷了聯系人列表,找到了這四位家族成員,并向他們發出了通知。
接下來,我們要求智能體創建一個日歷邀請,并將他們添加為受邀者。智能體成功記住了之前的上下文:它在正確的日期創建了日歷事件,并把家族成員正確添加進來。
2) 理解智能體:深入分析軌跡
ARE 還支持我們查看智能體在執行任務時的完整軌跡。
打開左側的 Agent logs 工具后,可以看到系統提示、思維鏈(chain of thought)、通過工具執行的多步操作,以及最終結果——所有內容都被清晰地組織成日志形式。
如果需要離線分析,還可以將所有信息導出為 JSON 文件。

3) 玩轉并擴展演示:將智能體連接到你自己的 MCP
在最后一個示例中,我們通過 MCP 將 ARE 連接到一只遠程機械臂,讓它可以做出手勢。隨后,我們要求智能體通過揮動機械臂來回答我們的是/否問題!以下是演示效果:

但以上這些示例只是非常簡單的起點,我們真正期待的是——看看你們能用它們創造出什么!
(對于更高階的用戶,你甚至可以直接安裝并編輯 Meta-ARE 的代碼,點此查看。)
總結
Gaia2 與 ARE 是全新的研究工具,我們希望它們能夠幫助更多人輕松構建更可靠、更具適應性的 AI 智能體。通過簡化實驗過程,讓真實世界的評測對所有人都更易獲得,并通過透明、可復現的基準與可調試的軌跡來增強信任。
我們非常期待看到大家能用這個項目做出什么!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號