
nanoVLM: 最簡潔、最輕量的純 PyTorch 視覺-語言模型訓(xùn)練代碼庫
nanoVLM 是使用純 PyTorch 訓(xùn)練 你自己的視覺語言模型 (VLM) 的 最簡單 方式。它是一個輕量級 工具包 ,讓你可以在 免費(fèi)的 Colab Notebook 上啟動 VLM 訓(xùn)練。
我們受到了 Andrej Karpathy 的 nanoGPT 的啟發(fā),為視覺領(lǐng)域提供了一個類似的項目。
從本質(zhì)上講,nanoVLM 是一個 工具包,可以幫助你構(gòu)建和訓(xùn)練一個能夠理解圖像和文本,并基于此生成文本的模型。nanoVLM 的魅力在于它的 簡潔性 。整個代碼庫被有意保持 最小化 和 可讀性 ,使其非常適合初學(xué)者或任何想要深入了解 VLM 內(nèi)部機(jī)制而不被復(fù)雜性淹沒的人。
在這篇博客中,我們將介紹該項目背后的核心思想,并提供與代碼庫交互的簡單方法。我們不僅會深入項目細(xì)節(jié),還會將所有內(nèi)容封裝起來,讓你能夠快速上手。
簡要
你可以按照以下步驟使用我們的 nanoVLM 工具包開始訓(xùn)練視覺語言模型:
# 克隆倉庫
git clone https://github.com/huggingface/nanoVLM.git
# 執(zhí)行訓(xùn)練腳本
python train.py
這里有一個 Colab Notebook,可以幫助你在無需本地設(shè)置的情況下啟動訓(xùn)練運(yùn)行!
什么是視覺語言模型?
顧名思義,視覺語言模型 (VLM) 是一種處理兩種模態(tài)的多模態(tài)模型: 視覺和文本。這些模型通常以圖像和/或文本作為輸入,生成文本作為輸出。
基于對圖像和文本 (輸入) 的理解來生成文本 (輸出) 是一個強(qiáng)大的范式。它支持廣泛的應(yīng)用,從圖像字幕生成和目標(biāo)檢測到回答關(guān)于視覺內(nèi)容的問題 (如下表所示)。需要注意的是,nanoVLM 僅專注于視覺問答作為訓(xùn)練目標(biāo)。
 |
為圖像生成標(biāo)題 | 兩只貓?zhí)稍诖采希赃呌羞b控器 | 圖像描述 |
| 檢測圖像中的物體 | <locxx><locxx><locxx><locxx> |
目標(biāo)檢測 | |
| 分割圖像中的物體 | <segxx><segxx><segxx> |
語義分割 | |
| 圖像中有多少只貓? | 2 | 視覺問答 |
如果你有興趣了解更多關(guān)于 VLM 的信息,我們強(qiáng)烈建議閱讀我們關(guān)于該主題的最新博客: 視覺語言模型 (更好、更快、更強(qiáng))
使用代碼庫
“廢話少說,直接看代碼” - 林納斯·托瓦茲
在本節(jié)中,我們將引導(dǎo)你了解代碼庫。在跟隨學(xué)習(xí)時,保持一個 標(biāo)簽頁 開啟以供參考會很有幫助。
以下是我們倉庫的文件夾結(jié)構(gòu)。為簡潔起見,我們刪除了一些輔助文件。
.
├── data
│ ├── collators.py
│ ├── datasets.py
│ └── processors.py
├── generate.py
├── models
│ ├── config.py
│ ├── language_model.py
│ ├── modality_projector.py
│ ├── utils.py
│ ├── vision_language_model.py
│ └── vision_transformer.py
└── train.py
架構(gòu)
.
├── data
│ └── ...
├── models # ?? 你在這里
│ └── ...
└── train.py
我們按照兩個知名且廣泛使用的架構(gòu)來建模 nanoVLM。我們的視覺主干網(wǎng)絡(luò) ( models/vision_transformer.py ) 是標(biāo)準(zhǔn)的視覺 transformer,更具體地說是谷歌的 SigLIP 視覺編碼器。我們的語言主干網(wǎng)絡(luò)遵循 Llama 3 架構(gòu)。
視覺和文本模態(tài)通過模態(tài)投影模塊進(jìn)行 對齊 。該模塊將視覺主干網(wǎng)絡(luò)產(chǎn)生的圖像嵌入作為輸入,并將它們轉(zhuǎn)換為與語言模型嵌入層的文本嵌入兼容的嵌入。然后將這些嵌入連接起來并輸入到語言解碼器中。模態(tài)投影模塊由像素洗牌操作和線性層組成。
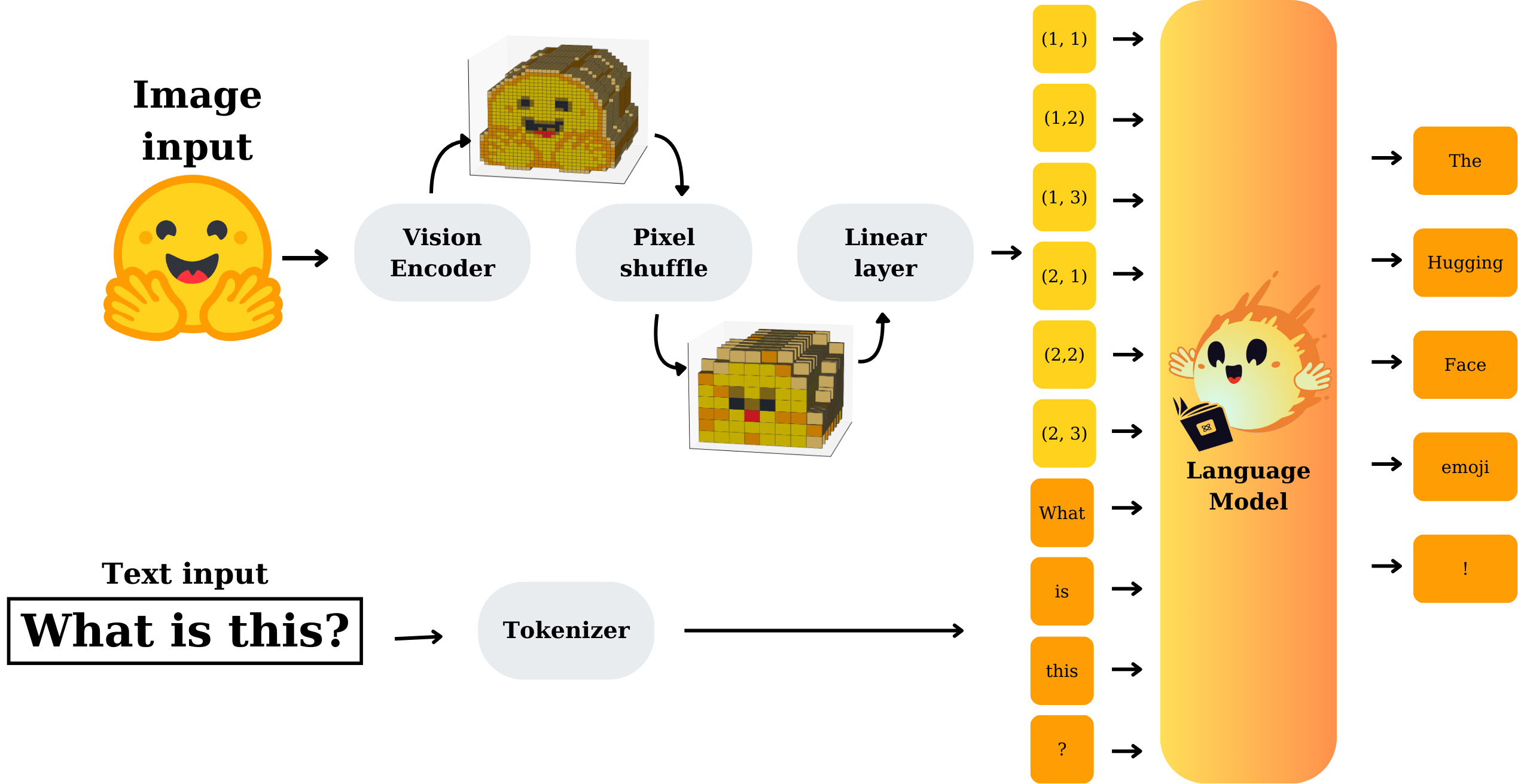 |
|---|
| 模型架構(gòu) (來源: 作者) |
像素洗牌 減少了圖像標(biāo)記的數(shù)量,這有助于降低計算成本并加快訓(xùn)練速度,特別是對于對輸入長度敏感的基于 transformer 的語言解碼器。下圖演示了這個概念。
 |
|---|
| 像素洗牌可視化 (來源: 作者) |
所有文件都非常輕量且有良好的文檔說明。我們強(qiáng)烈建議你逐個查看它們,以更好地理解實(shí)現(xiàn)細(xì)節(jié) ( models/xxx.py )
在訓(xùn)練時,我們使用以下預(yù)訓(xùn)練的主干權(quán)重:
也可以將主干網(wǎng)絡(luò)替換為 SigLIP/SigLIP 2 (用于視覺主干) 和 SmolLM2 (用于語言主干) 的其他變體。
訓(xùn)練你自己的 VLM
現(xiàn)在我們已經(jīng)熟悉了架構(gòu),讓我們換個話題,討論如何使用 train.py 訓(xùn)練你自己的視覺語言模型。
.
├── data
│ └── ...
├── models
│ └── ...
└── train.py # ?? 你在這里
你可以通過以下命令啟動訓(xùn)練:
python train.py
這個腳本是整個訓(xùn)練流程的一站式解決方案,包括:
- 數(shù)據(jù)集加載和預(yù)處理
- 模型初始化
- 優(yōu)化和日志記錄
配置
在任何其他操作之前,腳本從 models/config.py 加載兩個配置類:
TrainConfig: 對訓(xùn)練有用的配置參數(shù),如學(xué)習(xí)率、檢查點(diǎn)路徑等。VLMConfig: 用于初始化 VLM 的配置參數(shù),如隱藏維度、注意力頭數(shù)等。
數(shù)據(jù)加載
數(shù)據(jù)流水線的核心是 get_dataloaders 函數(shù)。它:
- 通過 Hugging Face 的
load_datasetAPI 加載數(shù)據(jù)集。 - 組合和洗牌多個數(shù)據(jù)集 (如果提供)。
- 通過索引應(yīng)用訓(xùn)練/驗證分割。
- 將它們包裝在自定義數(shù)據(jù)集 (
VQADataset、MMStarDataset) 和整理器 (VQACollator、MMStarCollator) 中。
這里一個有用的標(biāo)志是
data_cutoff_idx,對于在小子集上調(diào)試很有用。
模型初始化
模型通過 VisionLanguageModel 類構(gòu)建。如果你從檢查點(diǎn)恢復(fù),操作非常簡單:
from models.vision_language_model import VisionLanguageModel
model = VisionLanguageModel.from_pretrained(model_path)
否則,你將獲得一個全新初始化的模型,可選擇為視覺和語言預(yù)加載主干網(wǎng)絡(luò)。
優(yōu)化器設(shè)置: 兩個學(xué)習(xí)率
由于模態(tài)投影器 ( MP ) 是新初始化的,而主干網(wǎng)絡(luò)是預(yù)訓(xùn)練的,優(yōu)化器被分成兩個參數(shù)組,每個都有自己的學(xué)習(xí)率:
- MP 使用較高的學(xué)習(xí)率
- 編碼器/解碼器堆棧使用較小的學(xué)習(xí)率
這種平衡確保 MP 快速學(xué)習(xí),同時保留視覺和語言主干網(wǎng)絡(luò)中的知識。
訓(xùn)練循環(huán)
這部分相當(dāng)標(biāo)準(zhǔn)但結(jié)構(gòu)合理:
- 使用
torch.autocast進(jìn)行混合精度以提高性能。 - 通過
get_lr實(shí)現(xiàn)帶線性預(yù)熱的余弦學(xué)習(xí)率調(diào)度。 - 每批記錄令牌吞吐量 (令牌/秒) 以進(jìn)行性能監(jiān)控。
每 250 步 (可配置),模型在驗證集和 MMStar 測試數(shù)據(jù)集上進(jìn)行評估。如果準(zhǔn)確率提高,模型將被保存為檢查點(diǎn)。
日志記錄和監(jiān)控
如果啟用了 log_wandb ,訓(xùn)練統(tǒng)計信息如 batch_loss 、val_loss 、accuracy 和 tokens_per_second 將記錄到 Weights & Biases 以進(jìn)行實(shí)時跟蹤。
運(yùn)行使用元數(shù)據(jù)自動命名,如樣本大小、批次大小、epoch 數(shù)、學(xué)習(xí)率和日期,全部由輔助函數(shù) get_run_name 處理。
推送到 Hub
使用以下方法將訓(xùn)練好的模型推送到 Hub,供其他人查找和測試:
model.save_pretrained(save_path)
你可以輕松地使用以下方式推送它們:
model.push_to_hub("hub/id")
在預(yù)訓(xùn)練模型上運(yùn)行推理
使用 nanoVLM 作為工具包,我們訓(xùn)練了一個 模型并將其發(fā)布到 Hub。我們使用了 google/siglip-base-patch16-224 和 HuggingFaceTB/SmolLM2-135M 作為主干網(wǎng)絡(luò)。該模型在單個 H100 GPU 上對 cauldron 的約 170 萬個樣本訓(xùn)練了約 6 小時。
這個模型并不旨在與最先進(jìn)的模型競爭,而是為了揭示 VLM 的組件和訓(xùn)練過程。
.
├── data
│ └── ...
├── generate.py # ?? 你在這里
├── models
│ └── ...
└── ...
讓我們使用 generate.py 腳本在訓(xùn)練好的模型上運(yùn)行推理。你可以使用以下命令運(yùn)行生成腳本:
python generate.py
這將使用默認(rèn)參數(shù)并在圖像 assets/image.png 上運(yùn)行查詢 "What is this?"。
你可以在自己的圖像和提示上使用此腳本,如下所示:
python generate.py --image path/to/image.png --prompt "你的提示在這里"
如果你想可視化腳本的核心,就是這些行:
model = VisionLanguageModel.from_pretrained(source).to(device)
model.eval()
tokenizer = get_tokenizer(model.cfg.lm_tokenizer)
image_processor = get_image_processor(model.cfg.vit_img_size)
template = f"Question: {args.prompt} Answer:"
encoded = tokenizer.batch_encode_plus([template], return_tensors="pt")
tokens = encoded["input_ids"].to(device)
img = Image.open(args.image).convert("RGB")
img_t = image_processor(img).unsqueeze(0).to(device)
print("\nInput:\n ", args.prompt, "\n\nOutputs:")
for i in range(args.generations):
gen = model.generate(tokens, img_t, max_new_tokens=args.max_new_tokens)
out = tokenizer.batch_decode(gen, skip_special_tokens=True)[0]
print(f" >> Generation {i+1}: {out}")
我們創(chuàng)建模型并將其設(shè)置為 eval 。初始化分詞器 (用于對文本提示進(jìn)行分詞) 和圖像處理器 (用于處理圖像)。下一步是處理輸入并運(yùn)行 model.generate 以生成輸出文本。最后,使用 batch_decode 解碼輸出。
| 圖像 | 提示 | 生成結(jié)果 |
|---|---|---|
|
What is this? | In the picture I can see the pink color bed sheet. I can see two cats lying on the bed sheet. |
 |
What is the woman doing? | Here in the middle she is performing yoga |
如果你想在 UI 界面中對訓(xùn)練好的模型運(yùn)行推理,這里 有一個 Hugging Face Space 供你與模型交互。
結(jié)論
在這篇博客中,我們介紹了什么是 VLM,探討了支撐 nanoVLM 的架構(gòu)選擇,并詳細(xì)解釋了訓(xùn)練和推理工作流程。
通過保持代碼庫輕量級和可讀性,nanoVLM 旨在既作為學(xué)習(xí)工具,又作為你可以在此基礎(chǔ)上構(gòu)建的基礎(chǔ)。無論你是想了解多模態(tài)輸入如何對齊,還是想在自己的數(shù)據(jù)集上訓(xùn)練 VLM,這個倉庫都能讓你快速入門。
如果你嘗試了它,并在它的基礎(chǔ)上嘗試構(gòu)建,或者你只是有問題,我們都很樂意聽到你的反饋。祝你探索愉快!
參考文獻(xiàn)
- GitHub - huggingface/nanoVLM: 用于訓(xùn)練/微調(diào)小型 VLM 的最簡單、最快速的代碼庫。
- 視覺語言模型 (更好、更快、更強(qiáng))
- 視覺語言模型詳解
- 深入視覺語言預(yù)訓(xùn)練
- SmolVLM: 重新定義小型高效多模態(tài)模型
英文原文: https://hf.co/blog/nanovlm
原文作者: Aritra Roy Gosthipaty, Luis Wiedmann, Andres Marafioti, Sergio Paniego, Merve Noyan, Pedro Cuenca, Vaibhav Srivastav
翻譯: innovation64

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號