
SmolVLA: 讓機器人更懂 “看聽說做” 的輕量化解決方案
?? TL;DR
今天,我們介紹了 SmolVLA,這是一個輕量級 (450M 參數) 的開源視覺 - 語言 - 動作 (VLA) 模型,專為機器人領域設計,并且可以在消費級硬件上運行。
- 僅使用開源社區共享的數據集進行預訓練,數據集標簽為 lerobot。
- SmolVLA-450M 的表現優于許多更大的 VLA 模型,并且在仿真任務 (LIBERO,Meta-World) 和實際任務 (SO100, SO101) 上超過了強基線模型,如 ACT。
- 支持 異步推理 ,可提供 30% 更快的響應 和 2 倍的任務吞吐量。
相關鏈接:
- 用于訓練和評估 SO-100/101 的硬件: https://github.com/TheRobotStudio/SO-ARM100
- 基礎模型: https://huggingface.co/lerobot/smolvla_base
- 論文: https://huggingface.co/papers/2506.01844
?? 目錄
介紹
在過去的幾年里,Transformers 技術推動了人工智能的顯著進展,從能夠進行類人推理的語言模型到理解圖像和文本的多模態系統。然而,在實際的機器人領域,進展則相對較慢。機器人仍然難以在各種物體、環境和任務之間進行有效的泛化。這一有限的進展源于 缺乏高質量、多樣化的數據,以及缺乏能夠 像人類一樣在物理世界中進行推理和行動 的模型。
為應對這些挑戰,近期的研究開始轉向 視覺 - 語言 - 動作 (VLA) 模型,旨在將感知、語言理解和動作預測統一到一個架構中。VLA 模型通常以原始視覺觀測和自然語言指令為輸入,輸出相應的機器人動作。盡管前景廣闊,但大部分 VLA 的最新進展仍然被封閉在使用大規模私人數據集訓練的專有模型背后,通常需要昂貴的硬件配置和大量的工程資源。因此,更廣泛的機器人研究社區在復制和擴展這些模型時面臨著重大的障礙。
SmolVLA 填補了這一空白,提供了一個開源、高效的輕量級 VLA 模型,可以在 僅使用公開可用數據集和消費級硬件 的情況下進行訓練。通過發布模型權重并使用非常經濟的開源硬件,SmolVLA 旨在實現視覺 - 語言 - 動作模型的普及,并加速朝著通用機器人代理的研究進展。

圖 1: SmolVLA 在不同任務變體下的對比。從左到右: (1) 異步的拾取 - 放置立方體計數,(2) 同步的拾取 - 放置立方體計數,(3) 在擾動下的拾取 - 放置立方體計數,(4) 在真實世界 SO101 上的樂高積木拾取 - 放置任務泛化。
認識 SmolVLA!
SmolVLA-450M 是我們開源的、功能強大的輕量級視覺 - 語言 - 動作 (VLA) 模型。它具備以下特點:
- 足夠小,可以在 CPU 上運行,單個消費級 GPU 上訓練,甚至可以在 MacBook 上運行!
- 訓練使用的是公開的、社區共享的機器人數據
- 發布時附帶完整的訓練和推理方案
- 可以在非常經濟的硬件上進行測試和部署 (如 SO-100、SO-101、LeKiwi 等)
受到大語言模型 (LLMs) 訓練范式的啟發,SmolVLA 先在通用的操控數據上進行預訓練,隨后進行特定任務的后訓練。在架構上,它將 Transformers 與 流匹配解碼器 相結合,并通過以下設計選擇優化速度和低延遲推理:
- 跳過視覺模型的一半層,提升推理速度和減小模型尺寸
- 交替使用自注意力和交叉注意力模塊
- 使用更少的視覺標記
- 利用更小的預訓練視覺 - 語言模型 (VLM)
盡管使用的訓練樣本不到 30k, 比其他 VLA 模型少了一個數量級 , 但 SmolVLA 在仿真和真實世界中的表現 與更大的模型相當,甚至超過它們。
為了讓實時機器人更加易用,我們引入了異步推理堆棧。該技術將機器人執行動作的方式與理解它們所看到和聽到的內容分開。由于這種分離,機器人可以在快速變化的環境中更快速地響應。
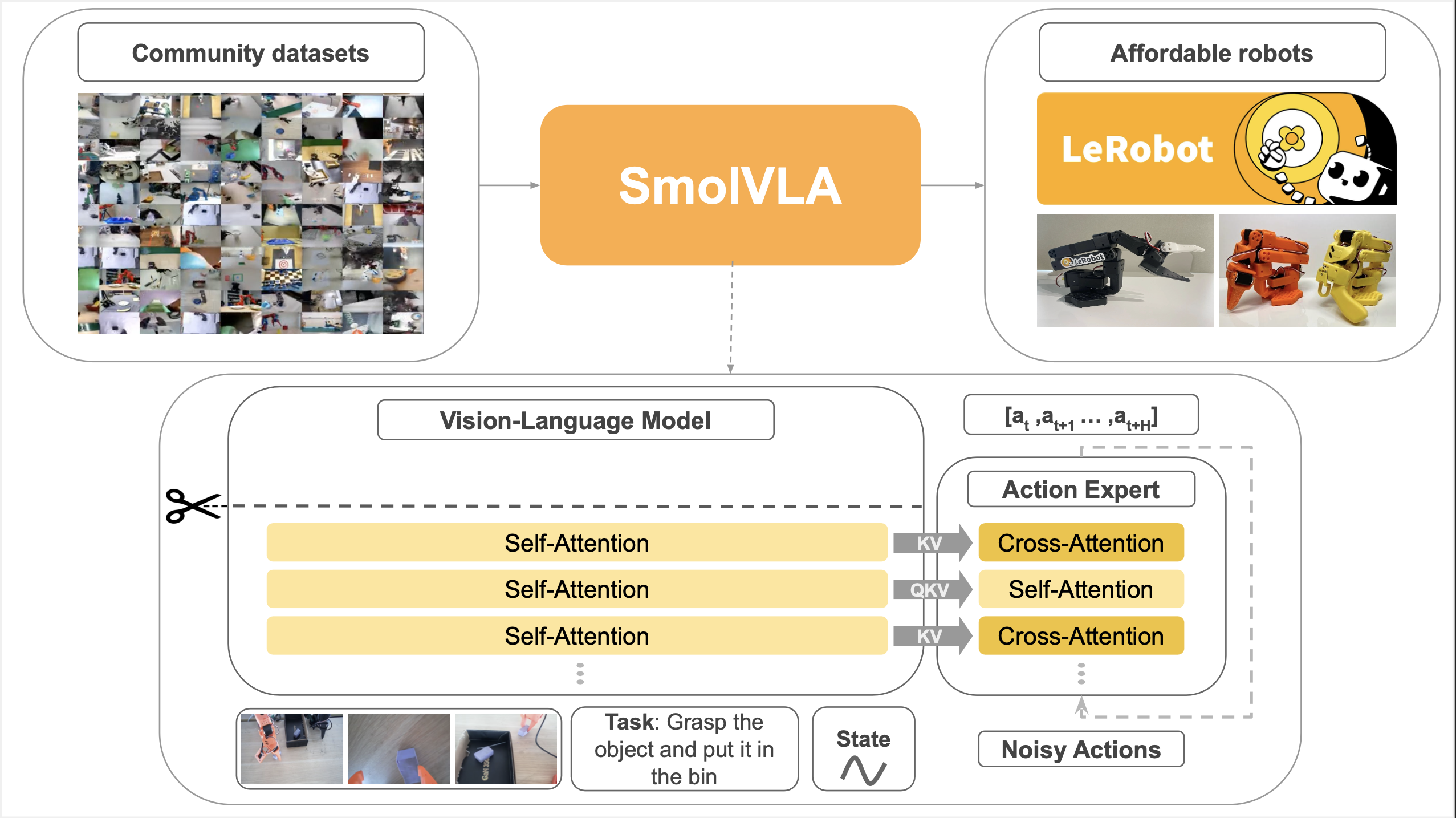
圖 2: SmolVLA 以多個攝像頭拍攝的 RGB 圖像序列、機器人當前的傳感運動狀態以及自然語言指令為輸入。VLM 將這些信息編碼為上下文特征,這些特征為動作專家提供條件,生成連續的動作序列。
?? 如何使用 SmolVLA?
SmolVLA 設計時考慮了易用性和集成性——無論您是要在自己的數據上進行微調,還是將其插入現有的機器人堆棧中,都非常方便。
安裝
首先,安裝所需的依賴項:
git clone https://github.com/huggingface/lerobot.git
cd lerobot
pip install -e ".[smolvla]"
微調預訓練模型
使用我們預訓練的 450M 模型 smolvla_base 和 lerobot 訓練框架進行微調:
python lerobot/scripts/train.py \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=200000
從頭開始訓練
如果你想基于架構 (預訓練的 VLM + 動作專家) 進行訓練,而不是從預訓練的檢查點開始:
python lerobot/scripts/train.py \
--policy.type=smolvla \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=200000
你還可以直接加載 SmolVLAPolicy :
policy = SmolVLAPolicy.from_pretrained("lerobot/smolvla_base")
方法
SmolVLA 不僅是一個輕量級但強大的模型,還是一種用于訓練和評估通用機器人策略的方法。在這一部分,我們介紹了 SmolVLA 背后的 模型架構 和用于評估的 異步推理 設置,這一設置已被證明更具適應性,并能更快速地恢復。
SmolVLA 由兩個核心組件組成: 一個處理多模態輸入的 視覺 - 語言模型 (VLM) 和一個輸出機器人控制命令的 動作專家。下面,我們將分享 SmolVLA 架構的主要組件和異步推理的詳細信息。更多細節可以在我們的 技術報告 中找到。
主要架構
視覺 - 語言模型 (VLM)
我們使用 SmolVLM2 作為我們的 VLM 主干。它經過優化,能夠處理多圖像輸入,并包含一個 SigLIP 視覺編碼器和一個 SmolLM2 語言解碼器。
- 圖像標記 通過視覺編碼器提取
- 語言指令 被標記化并直接輸入解碼器
- 傳感運動狀態 通過線性層投影到一個標記上,與語言模型的標記維度對齊
解碼器層處理連接的圖像、語言和狀態標記。得到的特征隨后傳遞給動作專家。
動作專家: 流匹配變換器
SmolVLA 的 動作專家 是一個輕量 Transformer (約 1 億參數),它能基于視覺語言模型 (VLM) 的輸出,生成未來機器人動作序列塊 (action chunks)。它是采用 流匹配目標 進行訓練的,通過引導噪聲樣本回歸真實數據分布來學習動作生成。與離散動作表示 (例如通過標記化) 強大但通常需要自回歸解碼、推理時速度較慢不同,流匹配允許 直接、非自回歸預測連續動作,從而實現高精度的實時控制。
更直觀地說,在訓練過程中,我們將隨機噪聲添加到機器人的真實動作序列中,并要求模型預測將其“修正”回正確軌跡的“修正向量”。這在動作空間上形成了一個平滑的向量場,幫助模型學習準確且穩定的控制策略。
我們使用 Transfomer 架構實現這一目標,并采用 交替注意力塊 (見圖 2),同時將其隱藏層大小減少到 VLM 的 75%,保持模型輕量化,便于部署。
高效性和穩健性的設計選擇
將視覺 - 語言模型與動作預測模塊結合起來,是近期 VLA 系統 (如 Pi0、GR00T、Diffusion Policy) 中的常見設計模式。我們在此過程中識別了幾項架構選擇,這些選擇顯著提高了系統的穩健性和性能。在 SmolVLA 中,我們應用了三項關鍵技術: 減少視覺標記的數量、跳過 VLM 中的高層 以及 在動作專家中交替使用交叉注意力和自注意力層。
視覺標記減少
高分辨率圖像有助于提高感知能力,但也可能顯著減慢推理速度。為了找到平衡,SmolVLA 在訓練和推理過程中每幀限制視覺標記數量為 64。例如,一個 512×512 的圖像被壓縮成僅 64 個標記,而不是 1024 個,使用 PixelShuffle 作為高效的重排技術。雖然底層的視覺 - 語言模型 (VLM) 最初使用圖像平鋪技術進行預訓練,以獲得更廣泛的覆蓋,但 SmolVLA 在運行時僅使用全局圖像,以保持推理的輕量化和快速性。
通過跳過層加速推理
我們并不總是依賴于 VLM 的最終輸出層,這一層成本高且有時效果不佳,我們選擇使用 中間層的特征。先前的研究表明,早期的層通常能提供更好的下游任務表示。
在 SmolVLA 中,動作專家只關注最多配置層 NN 的 VLM 特征進行訓練,配置為 總層數的一半。這 減少了 VLM 和動作專家的計算成本,顯著加速了推理,并且性能損失最小。
交替使用交叉注意力和自注意力
在動作專家內部,注意力層交替進行:
- 交叉注意力 (CA),其中動作標記關注 VLM 的特征
- 自注意力 (SA),其中動作標記關注彼此 (因果性地——只關注過去的標記)
我們發現這種 交替設計 比僅使用完整的注意力塊要輕量且更有效。僅依賴于 CA 或僅依賴于 SA 的模型,往往會犧牲平滑性或基礎性。
在 SmolVLA 中,CA 確保了動作能夠很好地與感知和指令相匹配,而 SA 則提高了 時間平滑性,這對于現實世界中的控制尤其重要,因為抖動的預測可能會導致不安全或不穩定的行為。
異步推理
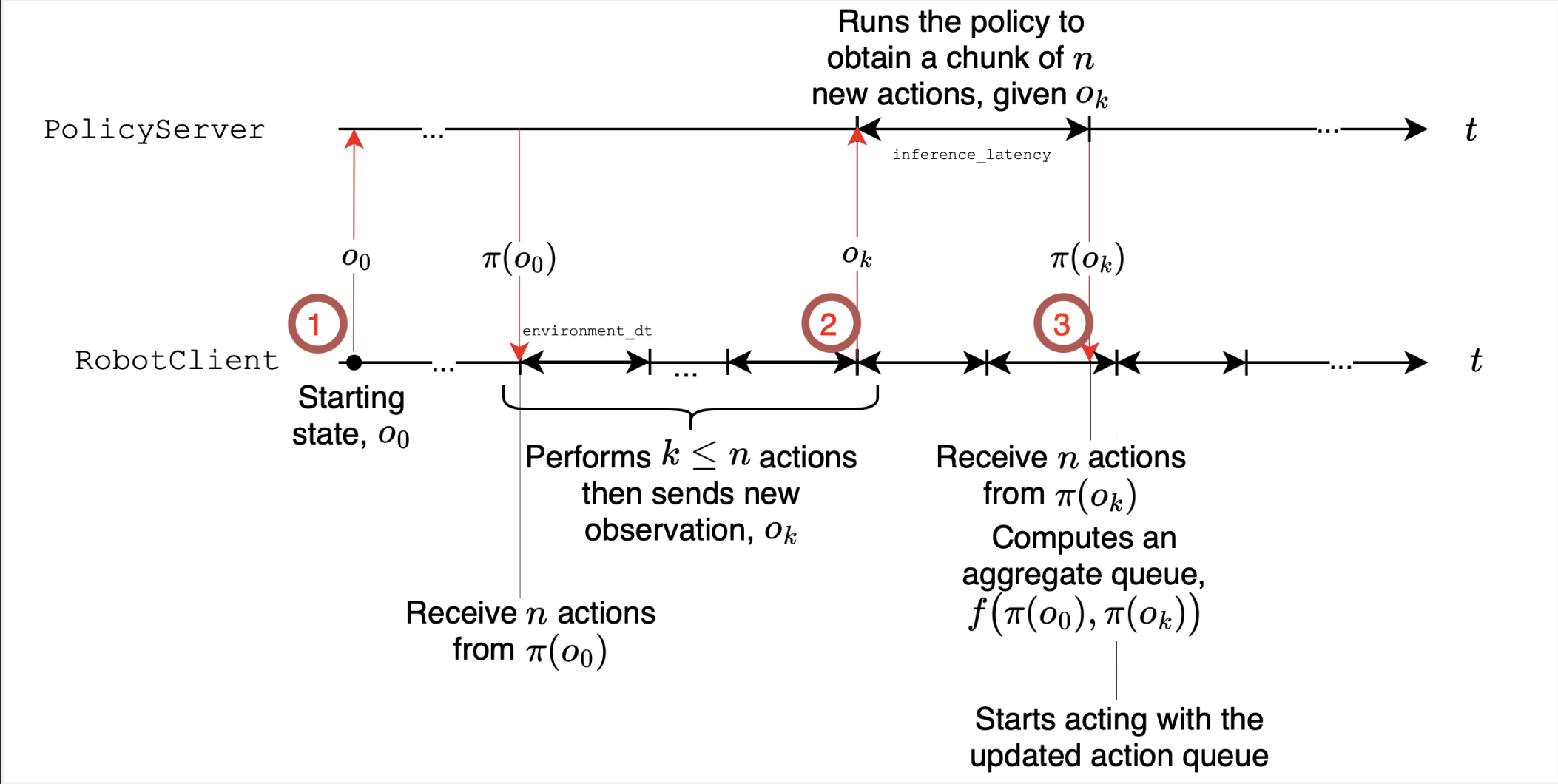
圖 3. 異步推理。異步推理堆棧的示意圖。請注意,策略可以在遠程服務器上運行,可能帶有 GPU。
現代視覺運動策略輸出 動作片段 一系列需要執行的動作。有兩種管理方式:
- 同步 (sync): 機器人執行一個片段,然后暫停,等待下一個片段的計算。這種方式簡單,但會造成延遲,機器人無法響應新的輸入。
- 異步 (async): 在執行當前片段時,機器人已經將最新的觀察結果發送到 策略服務器 (可能托管在 GPU 上) 以獲取下一個片段。這避免了空閑時間,并提高了反應速度。
我們的異步堆棧將動作執行與片段預測解耦,從而提高了適應性,并完全消除了運行時的執行延遲。它依賴以下關鍵機制:
- 1. 早期觸發: 當隊列長度低于某個閾值 (例如,70%) 時,我們會將觀察結果發送到 策略服務器,請求生成新的動作片段。
- 2. 解耦線程: 控制循環持續執行 → 推理并行進行 (非阻塞)。
- 3. 片段融合: 通過簡單的合并規則將連續片段的重疊動作拼接在一起,以避免抖動。
我們非常激動能發布異步推理,因為它保證了更強的適應性和更好的性能,而無需更改模型。簡而言之,異步推理通過重疊執行和遠程預測保持機器人響應迅速。
社區數據集
雖然視覺和語言模型依賴像 LAION、ImageNet 和 Common Crawl 這樣的網絡規模數據集,但機器人學缺乏類似的資源。沒有“機器人互聯網”。相反,數據在不同類型的機器人、傳感器、控制方案和格式之間是碎片化的——形成了不相連的“數據島”。在我們的 上一篇文章 中,我們探討了如何通過開放和協作的努力來解決這種碎片化問題。正如 ImageNet 通過提供一個大而多樣的基準來促進計算機視覺的突破,我們相信 社區驅動的機器人數據集 可以在通用機器人策略中發揮相同的基礎性作用。
SmolVLA 是我們朝著這個愿景邁出的第一步: 它在精心挑選的公開可用、社區貢獻的數據集上進行預訓練,這些數據集旨在反映現實世界中的變化。我們并不是單純地優化數據集的大小,而是關注多樣性: 各種行為、攝像頭視角和體現方式,促進轉移和泛化。
SmolVLA 使用的所有訓練數據來自 LeRobot Community Datasets,這是在 Hugging Face Hub 上通過 lerobot 標簽共享的機器人數據集。數據集來自各種不同的環境,從實驗室到客廳,這些數據集代表了一種開放、去中心化的努力,旨在擴展現實世界的機器人數據。

圖 4. 社區數據集的概覽。特別感謝 Ville Kuosmanen 創建了該可視化圖像。
與學術基準不同,社區數據集自然地捕捉到了雜亂、現實的互動: 多變的光照、不完美的演示、非常規物體和異質的控制方案。這種多樣性將對學習穩健、通用的表示非常有用。
我們使用了由 Alexandre Chapin 和 Ville Kuosmanen 創建的自定義 過濾工具,根據幀數、視覺質量和任務覆蓋范圍來選擇數據集。在經過細致的人工審核后 (特別感謝 Marina Barannikov),我們策劃了一個由 487 個高質量數據集 組成的集合,聚焦于 SO100 機器人臂,并統一標準為 30 FPS。這產生了大約 1000 萬幀 ——至少是 其他流行基準數據集的一個數量級小,但其多樣性顯著更高。
改進任務標注
社區數據集中的一個常見問題是任務描述的噪聲或缺失。許多樣本缺少標注,或者包含像“task desc”或“Move”、“Pick”等模糊的標簽。為了提高質量并標準化數據集之間的文本輸入,我們使用了 Qwen2.5-VL-3B-Instruct 來生成簡潔、面向動作的描述。
給定樣本幀和原始標簽,模型被提示在 30 個字符以內重寫指令,從動詞開始 (例如,“Pick”,“Place”,“Open”)。
使用的提示語如下:
以下是當前的任務描述: {current_task}。生成一個非常簡短、清晰且完整的一句話,描述機器人臂執行的動作 (最多 30 個字符)。不要包含不必要的詞語。
簡潔明了。
以下是一些示例: 拾取立方體并將其放入盒子,打開抽屜等等。
直接以動詞開始,如“Pick”、“Place”、“Open”等。
與提供的示例類似,機器人臂執行的主要動作是什么?
標準化攝像頭視角
另一個挑戰是攝像頭命名不一致。一些數據集使用了清晰的名稱,如 top 或 wrist.right ,而其他一些則使用了模糊的標簽,如 images.laptop ,其含義有所不同。
為了解決這個問題,我們手動檢查了數據集,并將每個攝像頭視角映射到標準化的方案:
OBS_IMAGE_1 : 從上往下的視角
OBS_IMAGE_2 : 腕部安裝視角
OBS_IMAGE_3+ : 其他視角
我們進一步隔離了社區數據集預訓練和多任務微調的貢獻。沒有在 LeRobot 社區數據集上進行預訓練,SmolVLA 在 SO100 上最初的成功率為 51.7%。在社區收集的數據上進行預訓練后,性能躍升至 78.3%,提高了 +26.6%。多任務微調進一步提升了性能,甚至在低數據環境下也表現出強大的任務遷移能力。
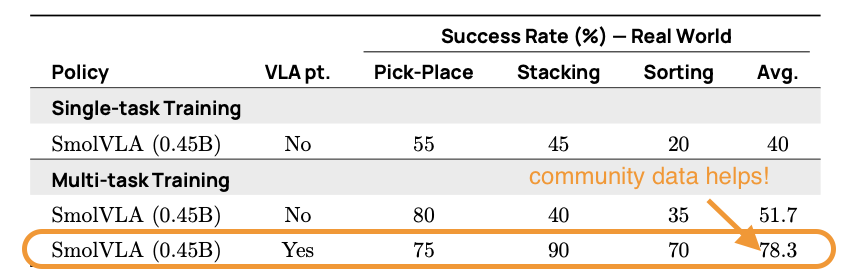
表 1. 在社區數據集預訓練和多任務微調上的影響。
結果
我們在仿真和真實世界的基準測試中評估了 SmolVLA,以測試其泛化能力、效率和穩健性。盡管 SmolVLA 是緊湊的,但它在性能上始終超越或與顯著更大的模型和基于更大規模機器人數據預訓練的策略相匹配。
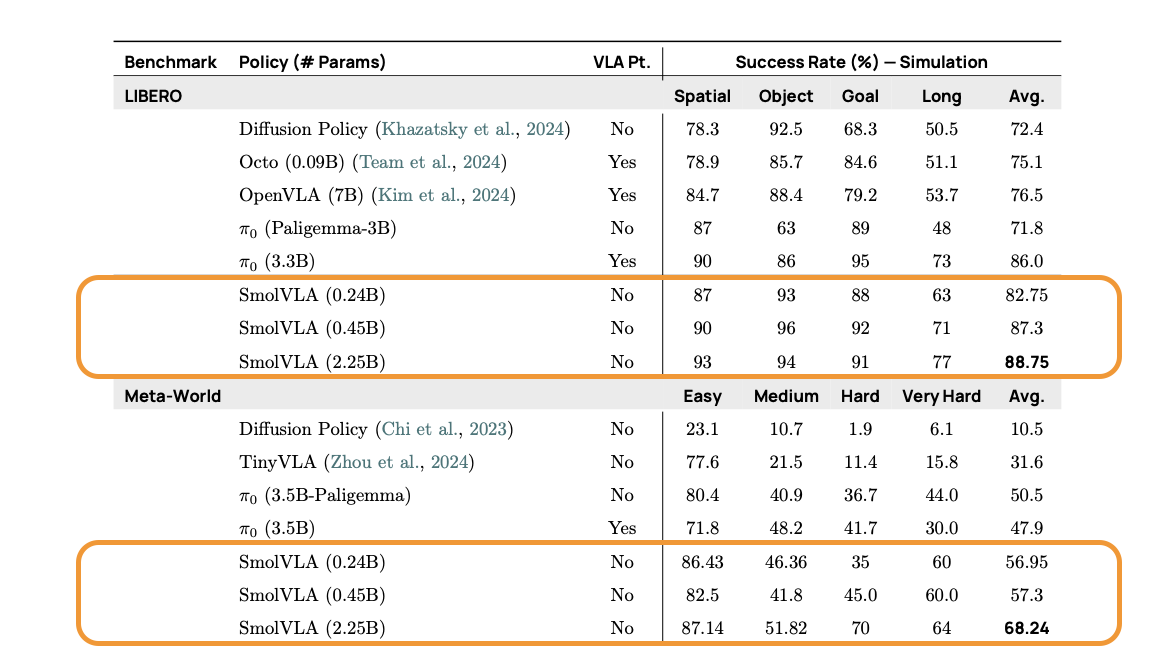
表 2. SmolVLA 在仿真基準測試中的表現。
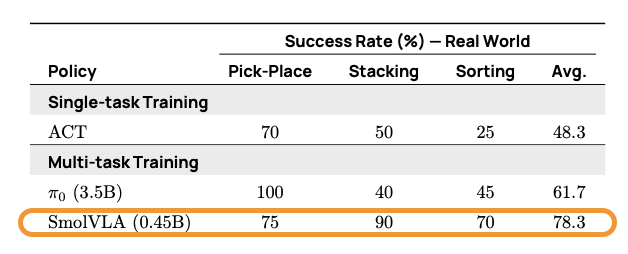
表 3. SmolVLA 與基線在真實世界任務 (SO100) 上的對比。
在真實世界環境中,SmolVLA 在兩個不同的任務套件上進行了評估: SO100 和 SO101。這些任務包括拾取 - 放置、堆疊和排序,涵蓋了分布內和分布外的物體配置。
在 SO101 上,SmolVLA 還在泛化能力上表現出色:
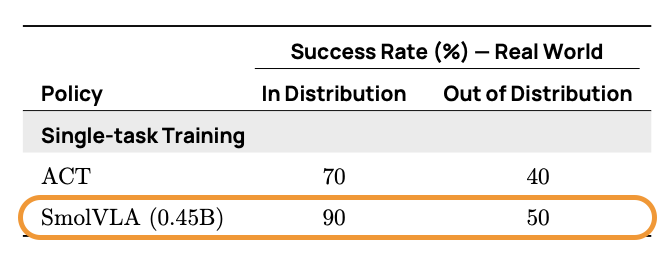
表 4. SmolVLA 在新體現 (SO101) 上的泛化能力與 ACT 的對比。
最后,我們在同步和異步推理模式下評估了 SmolVLA。異步推理將動作執行與模型推理解耦,使得策略在機器人移動時也能作出反應。
- 兩種模式的任務成功率相似 (約 78%),但異步推理:
- 使任務完成時間 快約 30% (9.7 秒 vs 13.75 秒)
- 在固定時間設置下 完成任務數量翻倍 (19 個 vs 9 個立方體)
這使得在動態環境中,尤其是在物體變化或外部干擾的情況下,SmolVLA 具有更高的響應性和穩健的真實世界表現。

圖 4. 真實世界任務中的異步推理與同步推理。(a) 任務成功率 (%),(b) 平均完成時間 (秒),以及 (c) 在固定時間窗口內完成的任務數量。
結論
SmolVLA 是我們為構建開放、高效、可重復的機器人基礎模型所做的貢獻。盡管它體積小,但在一系列真實世界和仿真任務中,它的表現與更大、更專有的模型相當,甚至超越了它們。通過完全依賴社區貢獻的數據集和經濟實惠的硬件,SmolVLA 降低了研究人員、教育工作者和愛好者的入門門檻。
但這僅僅是開始。SmolVLA 不僅僅是一個模型——它是朝著可擴展、協作機器人方向發展的開源運動的一部分。
行動號召:
- ?? 試試看! 在自己的數據上微調 SmolVLA,將其部署到經濟實惠的硬件上,或者與當前的堆棧進行基準測試,并在 Twitter/LinkedIn 上分享。
- ?? 上傳數據集! 有機器人嗎?使用 lerobot 格式收集并共享你的數據。幫助擴展支持 SmolVLA 的社區數據集。
- ?? 加入博客討論。 在下面的討論中留下你的問題、想法或反饋。我們很樂意幫助集成、訓練或部署。
- ?? 貢獻。 改進數據集,報告問題,提出新想法。每一份貢獻都很有幫助。
- ?? 傳播這個消息。 與其他對高效、實時機器人策略感興趣的研究人員、開發人員或教育者分享 SmolVLA。
- ?? 保持聯系: 關注 LeRobot 組織 和 Discord 服務器,獲取更新、教程和新版本。
我們一起可以讓現實世界的機器人性能更強、成本更低、 開放度更高。?
英文原文: https://hf.co/blog/smolvla
原文作者: Dana Aubakirova, Andres Marafioti, Merve Noyan, Aritra Roy Gosthipaty, Francesco Capuano, Loubna Ben Allal, Pedro Cuenca, Mustafa Shukor, Remi Cadene
翻譯: Adeena

 浙公網安備 33010602011771號
浙公網安備 33010602011771號