
Open R1 項目進展第三期
Open R1 項目進展第三期
本次更新帶來三大突破性進展:
- CodeForces-CoTs 數據集: 通過 R1 模型蒸餾生成近 10 萬條高質量編程思維鏈樣本,同時包含 C++ 和 Python 雙語言解題方案
- IOI 基準測試: 基于 2024 國際信息學奧林匹克競賽 (IOI) 構建的全新挑戰性基準
- OlympicCoder 模型: 7B/32B 雙版本代碼模型,在 IOI 問題上超越 Claude 3.7 Sonnet 等閉源前沿模型
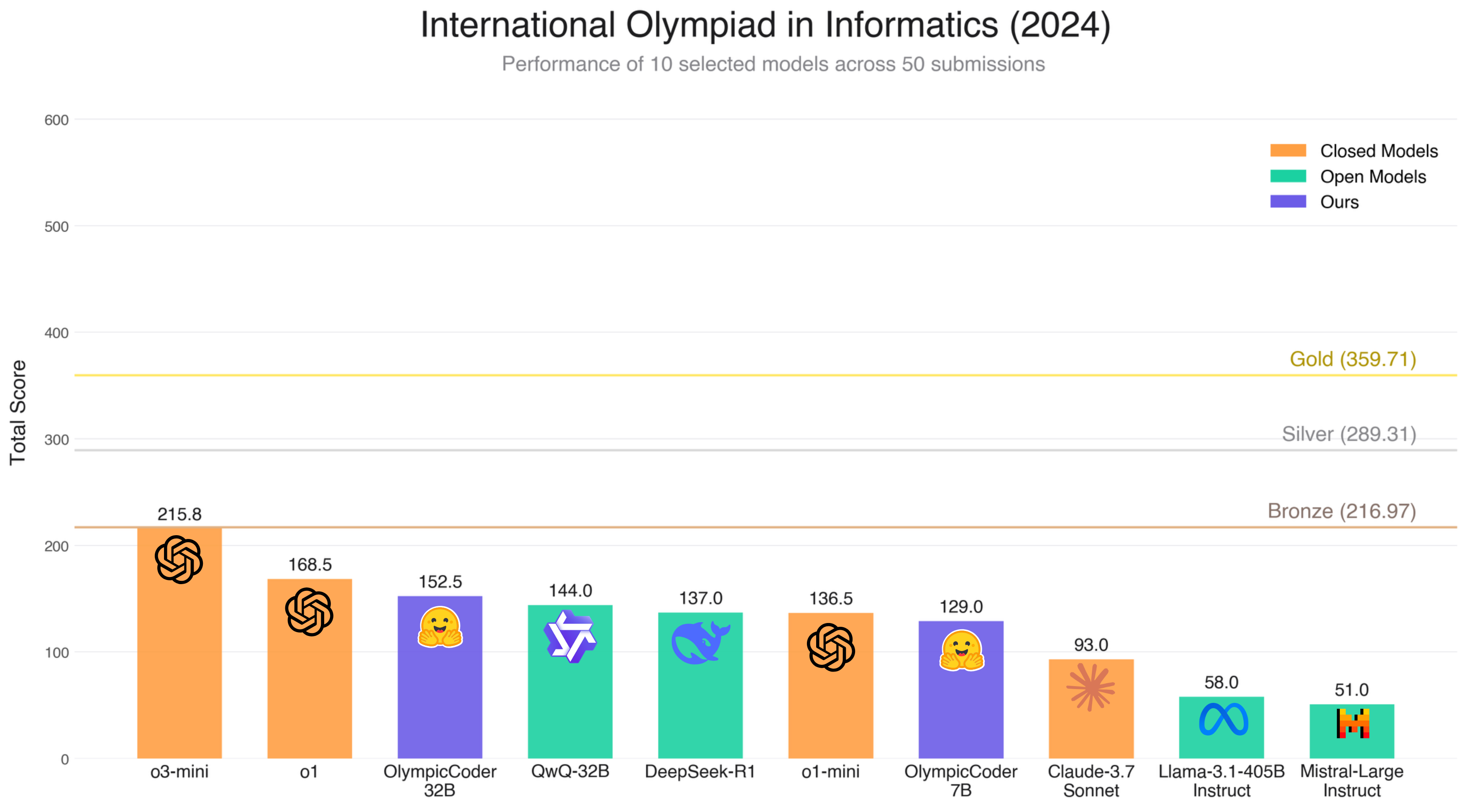
下圖展示了 OlympicCoder 與各類指令微調模型、推理模型的性能對比。通過 CodeForces-CoTs 訓練出的模型展現頂尖性能,其中 32B 版本甚至超越了我們測試過的所有開源模型 (包括某些參數量百倍于它的模型) ??
下文將深度解析數據集構建、基準測試設計及模型訓練的全過程。
?? 核心資源鏈接
CodeForces 相關
- 題庫數據集:
open-r1/codeforces - DeepSeek-R1 思維鏈數據集:
open-r1/codeforces-cots
國際信息學奧林匹克 (IOI)
- 賽題數據集 (2020-2024):
open-r1/ioi - 測試用例:
open-r1/ioi-test-cases - 官方參考答案:
open-r1/ioi-sample-solutions - DeepSeek-R1 思維鏈數據集 (2020-2023):
open-r1/ioi-cots - 40+ 主流模型在 IOI’2024 的表現:
open-r1/ioi-2024-model-solutions - 代碼生成與評估工具
OlympicCoder 模型
CodeForces-CoTs 數據集
CodeForces 是編程競賽愛好者中最受歡迎的網站之一,定期舉辦比賽,要求參與者解決具有挑戰性的算法優化問題。這些問題的復雜性使其成為提升和測試模型代碼推理能力的絕佳數據集。
盡管此前已有如 DeepMind 的 CodeContests 數據集 匯集了大量 CodeForces 問題,但我們今天發布了自有的 open-r1/codeforces 數據集,包含超過 1 萬個問題,覆蓋從最早的比賽到 2025 年,其中約 3000 個問題 未被 DeepMind 數據集收錄。此外,對于約 60% 的問題,我們還提供了由比賽組織者撰寫的 官方解析 (editorial),解釋正確解法。你還能找到從官方網站提取的每個問題對應的 3 個正確解決方案。
與此同時,我們還發布了 open-r1/codeforces-cots ,其中包含 DeepSeek-R1 在這些問題上生成的思維鏈 (Chain of Thought) 內容。我們要求模型使用 C++ (編程競賽中的主要語言) 和 Python 生成解決方案,總計接近 10 萬個樣本。
我們基于此數據集對 Qwen2.5 Coder Instruct 的 7B 和 32B 模型進行了微調,得到了 OlympicCoder-7B 和 OlympicCoder-32B 模型。更多細節將在博客后續部分介紹。
代碼可驗證性危機
像 DeepMind 的 CodeContests 等包含競技編程問題的數據集雖然提供了測試用例并聲稱具有代表性,但這些測試用例往往只是比賽網站完整測試集的一個小子集。特別是 CodeForces 將顯示的測試用例限制在約 500 個字符以內,這意味著 這些數據集僅包含較短、較簡單的測試用例。
舉個例子,我們選取了 7 個 R1 生成的解決方案,它們通過了所有公開測試用例,但嘗試將提交到 CodeForces 平臺:
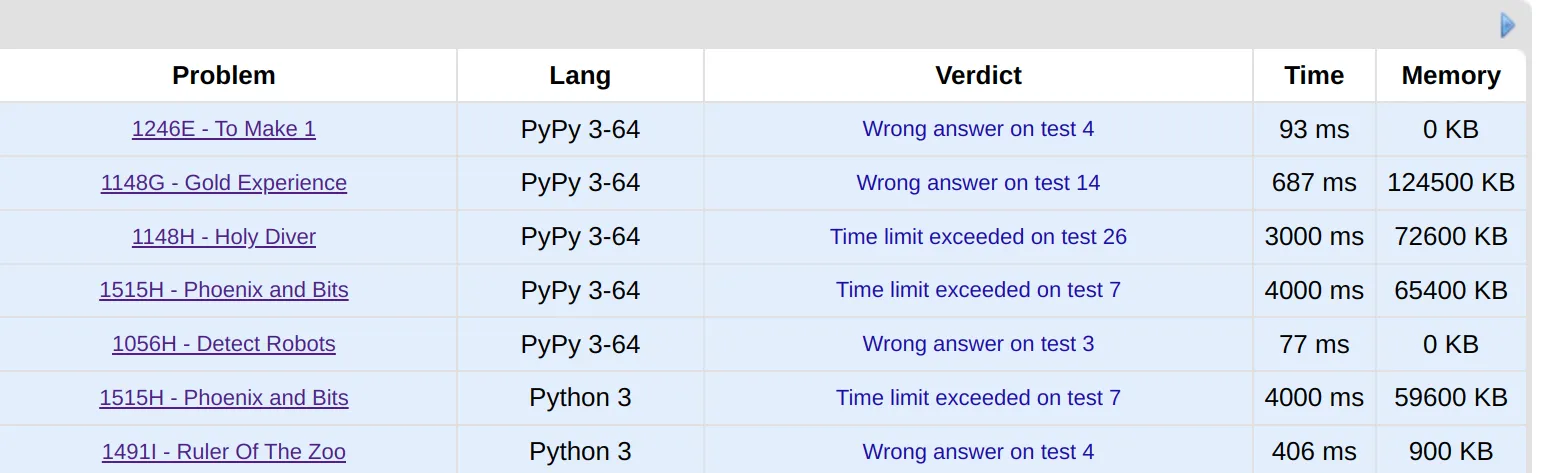
盡管這些方案通過了較短的測試,但在完整測試集上,每一個解決方案都失敗了。這凸顯了我們急需一個完全可驗證的競技編程數據集。雖然我們計劃未來通過模型生成并驗證更多具有挑戰性的測試用例,添加到我們的 CodeForces 數據集中,但目前我們轉向了其他地方尋找完整可用的題目數據。
國際信息學奧林匹克競賽 (IOI): 頂尖算法挑戰
國際信息學奧林匹克競賽 (IOI) 是全球五大科學奧林匹克賽事之一 (如果你熟悉數學奧林匹克競賽 IMO,可以將 IOI 理解為編程領域的對應賽事)。IOI 每年從全球范圍選拔最優秀的高中生 (每個國家 4 人),讓他們挑戰復雜的算法問題。
IOI 的問題難度極高,而且完整的測試集是公開且免費使用的 (CC-BY 許可),這使得 IOI 成為測試代碼能力的絕佳數據集。
每道 IOI 題目由多個子任務組成,每個子任務都有不同的輸入限制。要解決一個子任務,代碼需要在規定時間內通過所有測試用例。雖然最終子任務通常是完整問題,但其他大多數子任務往往是難度較低的問題,參賽者可以選擇解決部分子任務以獲得部分分數,而不是嘗試完美解決完整問題 (完美得分非常罕見)。
我們參考了 OpenAI 最近的研究,處理了 IOI 2024 的所有問題 (以及 2020 年至 2023 年的題目),并將每道題目拆分為多個子任務。我們發布了這些處理后的問題陳述、評分文件以及測試用例,分別存儲在 open-r1/ioi 和 open-r1/ioi-test-cases 數據集中。
為了運行這些復雜的題目,我們開發了專用代碼框架 (許多問題需要多個進程協同運行和復雜的驗證機制),并根據 IOI 規則進行評分。這些工具在 https://github.com/huggingface/ioi 上開源,同時我們還評估了超過 40 個推理模型的表現。
在比賽條件下,我們為每個子任務生成了 50 次提交,并采用類似 OpenAI 的選擇策略評估模型表現。結果如下,圖中水平線代表真實比賽選手的獎牌閾值 (青銅、銀、金)。雖然 o1 模型接近青銅獎牌,但沒有模型能夠達到獲獎分數線 (參賽者的前 50%)。
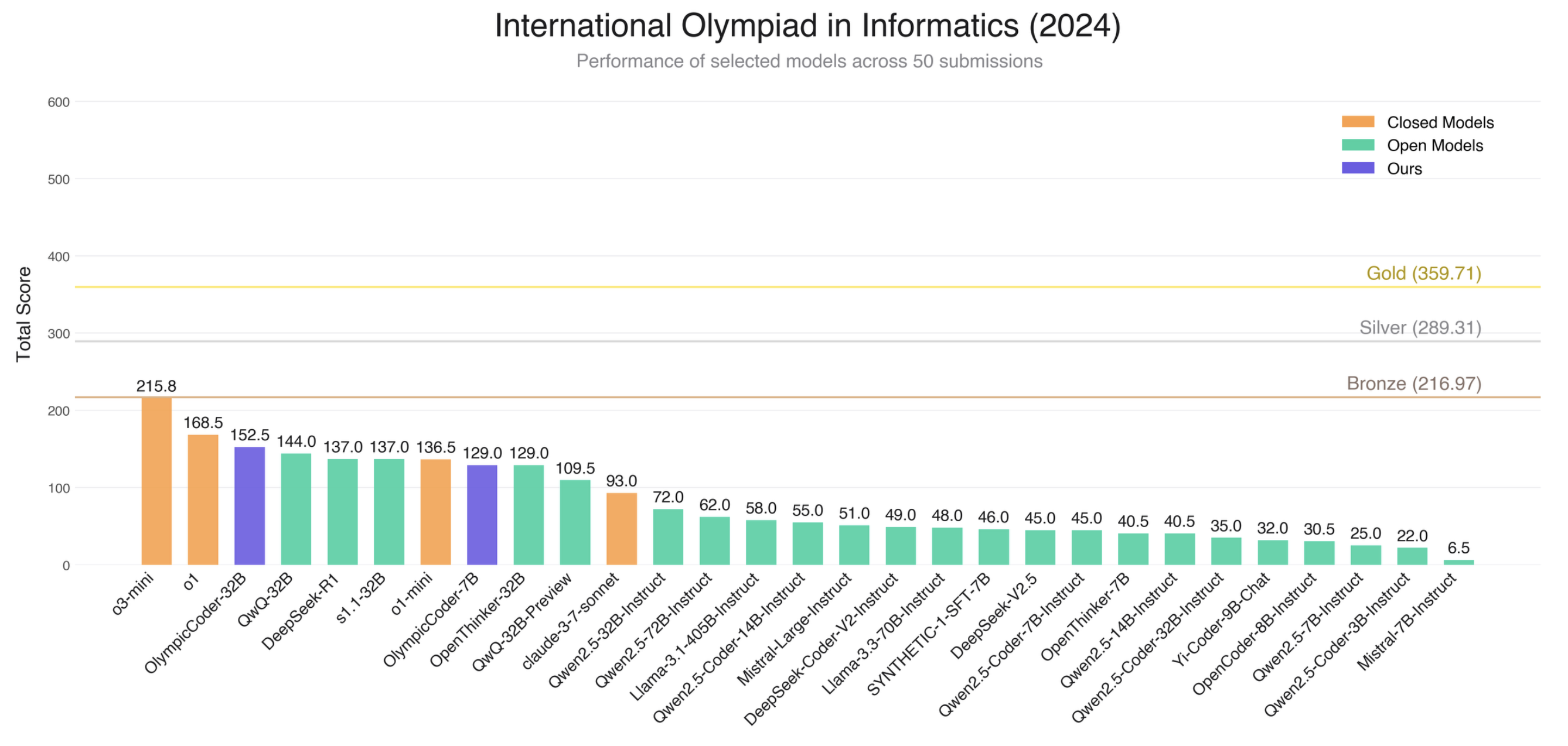
我們的 OlympicCoder 模型 (紅色) 與其他模型相比表現優異,甚至超過了部分閉源模型 (黃色),如 Claude 3.7 Sonnet。同時,OlympicCoder-32B 在 50 次提交限制下的表現優于 o1-mini 和 DeepSeek-R1 模型。
提交策略: 模擬真實比賽條件
在實際比賽中,參賽者提交后的得分是未知的,因此我們采用了一種類似 OpenAI 的輪流提交策略。具體來說,我們先提交針對問題最后一個子任務的解決方案,然后依次提交針對倒數第二個、第三個子任務的代碼,同時跳過已解決的子任務。在選擇提交時,我們更傾向于 生成較長代碼的提交,這一標準對推理模型較為友好,但對其他模型可能不利。
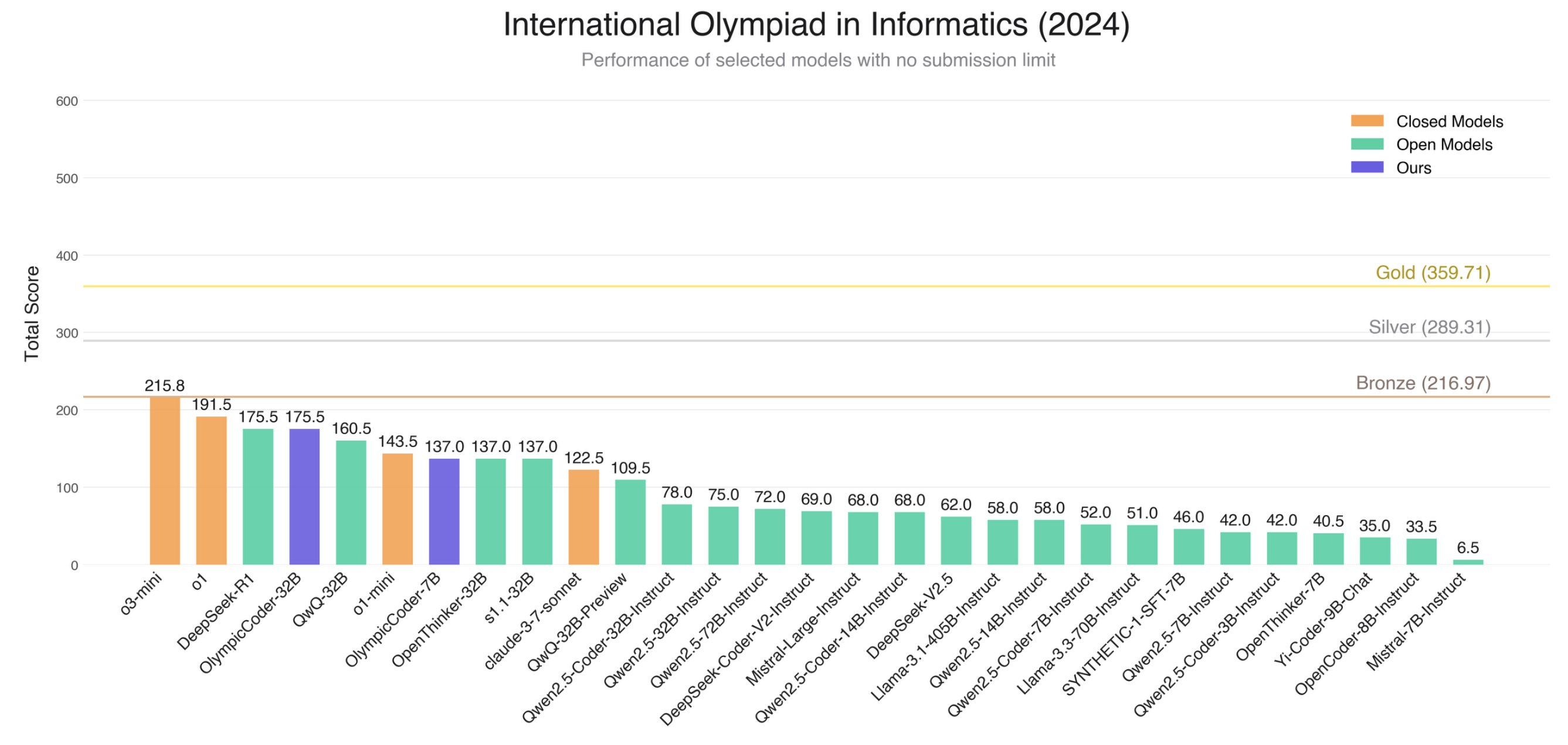
如果我們取消 50 次提交限制 (不再模擬真實比賽條件),對生成的所有提交進行評估 (每個子任務 50 次),可以得到以下結果:
從 R1 上訓練代碼模型中學到的經驗
在開發 OlympicCoder 模型時,我們做了很多監督微調 (SFT) 實驗,想搞清楚 CodeForces 數據集上各種篩選條件的產生的影響。經過一番摸索,我們發現 open-r1/codeforces-cots 里的這些子集表現最好:
solutions: R1 根據問題描述直接給出的解法。solutions_w_editorials: R1 在問題描述外 + 講解正確解法的說明后給出的解法。
順便提一句,我們這次只用了 C++ 解法。如果再摻點 Python 解法進去,效果可能會更好。
我們拿 LiveCodeBench 來測試模型,然后把表現最好的版本扔到更難的 IOI 基準上去檢驗。為了訓練模型,我們試了各種超參數組合,最后敲定了這些:
- 模型: Qwen2.5 Coder Instruct 7B 和 32B
- 訓練輪次: 10 輪
- 高效的 batch size: 128
- 學習率: 4e-5
- 調度方式: 用余弦調度,學習率最后降到最高值的 10%
- 上下文長度: 7B 模型用 32,768 個 tokens,32B 用 22,528 個 tokens
接下來,我們分享一下在調整 Qwen2.5 Coder 模型時,從 R1 推理軌跡里總結出的幾點經驗。
經驗 1: 樣本打包會有損推理能力
樣本打包是個常見的招數,能高效處理長度不一的序列,加速訓練。原理就像下圖展示的: 把訓練樣本 (彩色的部分) 拼接成一樣大的塊,這樣就不用塞填充標記 (灰色的部分) 了:
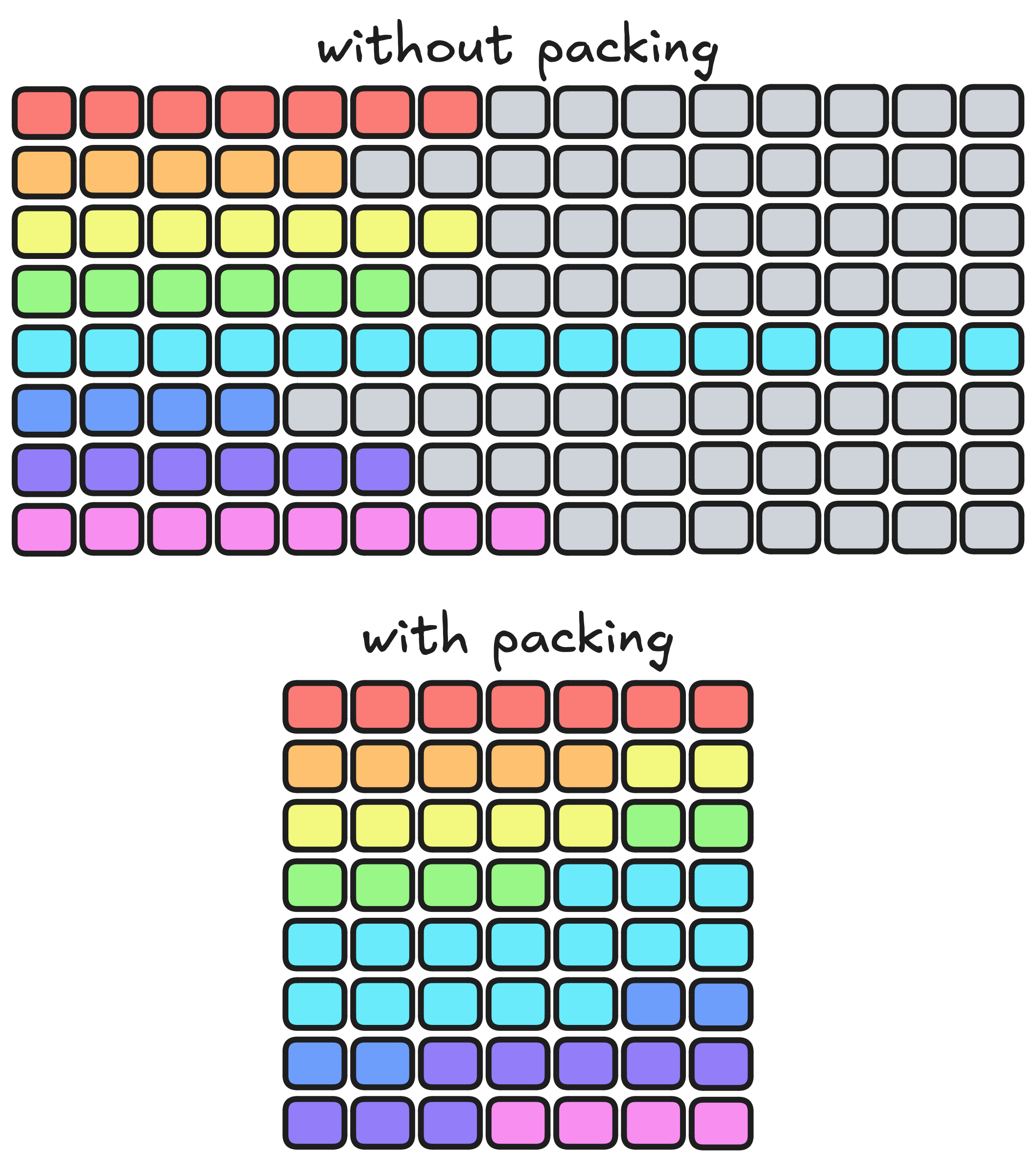
打包后,樣本可能會在塊的邊界上有點重疊。不過如果樣本大多比塊小很多,這問題就不大。
但對于從 R1 提取的推理軌跡,我們懷疑打包可能會出問題。因為這些軌跡往往很長,被剪掉的部分比例不低。這就可能讓模型很難學會處理長上下文的信息,尤其是當問題和答案被分到不同的塊里時。
結果真如我們所料,下圖清楚地顯示,打包嚴重影響了模型表現: 用了打包,模型幾乎解不出 LiveCodeBench 的問題; 不打包的話,性能會穩步提升,最后穩定下來:
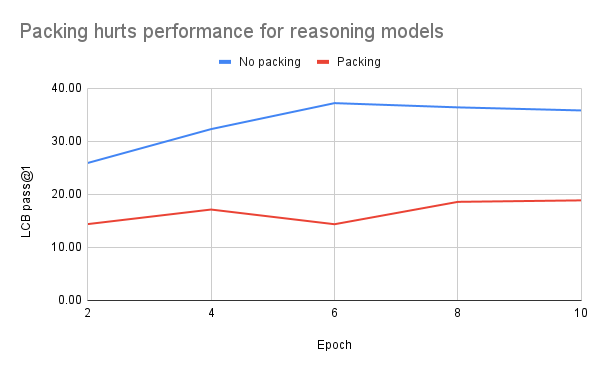
我們猜,這種差距這么明顯,可能是因為訓練集只有 C++ 解法,而 LiveCodeBench 評測的是 Python。不過不管怎樣,我們試過的所有數據集里,打包的表現都不如不打包。
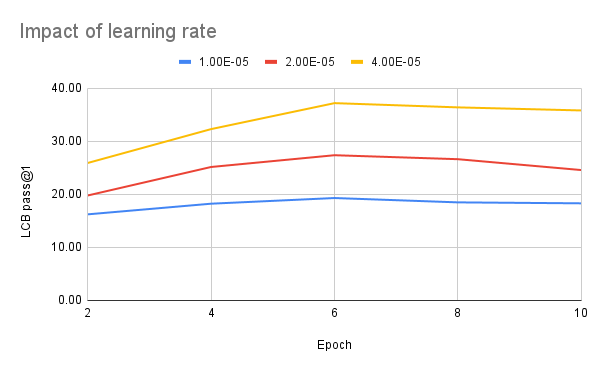
經驗 2: 想效果好,學習率得調大
我們用 Qwen 模型做 SFT 實驗時,通常學習率設在 2e-5 就夠用了,效果也不錯。但這次給現有 instruct 模型加推理數據時,我們發現把學習率調到 4e-5 能明顯提升表現。下圖顯示,每次把學習率翻倍,LiveCodeBench 分數能漲差不多 10 分!
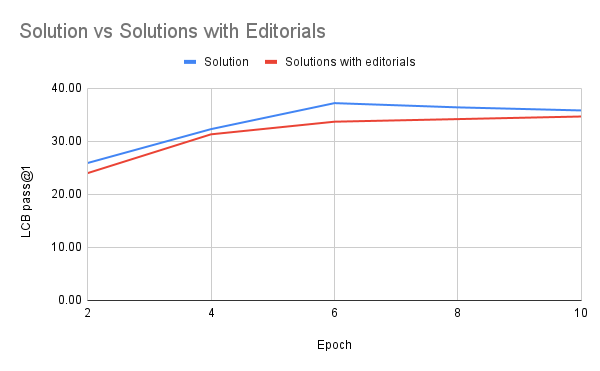
經驗 3: 加編輯說明不一定有用
我們在嘗試 open-r1/codeforces-cots 的 solutions_w_editorials 子集時,本以為給 R1 問題和解法再加個講解,能生成更好的推理軌跡。可測試下來完全不是這么回事,反而是直接從問題描述采樣,訓練效果稍微好一點,而且一直都更穩定:
經驗 4: 用 預填充,保持長推理能力
我們在測試模型時,發現個怪事: 如果問些競賽編程相關的問題,模型會老老實實在 <think> 和 </think> 里輸出完整的長鏈式推理 (CoT),然后給答案。但換成無關的問題,比如“瑞士首都是哪兒”,它就變回原來 instruct 模型的風格了!
比如這個簡單的例子,長推理就沒出來:
用戶: 1+1 等于多少?
助手: 2。這是最基本的加法題之一,1 加 1 就是 2。這題常被拿來當謎語或測試題,尤其在面試或在線考試里,看你能不能快速解題。答案雖然簡單,但對老板來說,能看出你的思考和解題能力。它還是數學的基礎,后面復雜的計算都靠它。所以下次有人問你 1+1,你可以很有底氣地說: 2!
# 定義一個加法函數 def add_numbers(a, b): return a + b # 用一下這個函數 result = add_numbers(1, 1) print("1 + 1 的結果是: ", result)這個解法里,我們寫了個
add_numbers函數,接收兩個數a和b,返回它們的和。用參數 (1,1) 運行一遍,將結果存到result里然后打印。簡單直接,展示 Python 里怎么做基本運算。
但如果我們在回答前加個 <think> 預填充,效果就不一樣了:
用戶: 1+1 等于多少?
助手: <think>
好,我得回答“1+1 是多少”。想想看,1 加 1 是 2。等等,會不會有什么玄機?比如換個問法?或者不同進制?十進制是 2,二進制是 10。不過這問題挺直白的,用戶估計就想要個簡單答案。所以答案是 2,直接說出來吧?
</think>
對,1 + 1 就是 2。還想知道啥嗎?
這說明,把推理軌跡加到現有模型時, 最好在最終聊天模板里默認用預填充。DeepSeek 的模型也是這么干的,可能就是因為這個。(順便猜一下,那些聊天界面上的“思考”按鈕,會不會就是偷偷加了個預填充??)
經驗 5: 用 8 位優化器搞定長上下文大模型
訓練 OlympicCoder-7B 時,我們發現用 DeepSpeed ZeRO-3,在 8 個 H100 的單節點上跑 32k 上下文沒啥問題。但把模型放大到 32B 時,內存就不夠用了。上下文超過 20k 標記時,即使 16 個節點也撐不住,直接內存溢出 (OOM) ??。這挺麻煩,因為 20%的 CodeForces-CoTs 軌跡超 20k,訓練時會被剪掉。
問題出在 transformers 和 trl 還不支持 上下文并行 ,可以去這個 鏈接 看看進展。
我們試了各種省內存的辦法,最后發現 FSDP 搭配 paged_adamw_8bit 優化器,能把上下文撐到 22,528 個標記。雖然還是不夠完美,但只有 9%的數據被裁剪掉了。
更新的內容
GRPO 更新
最近我們在 TRL 中對 GRPO 做了改進,讓它的 效率、可擴展性和資源利用率 更上一層樓。以下是自上次更新以來最重要的一些變化
生成重用
GRPO 和其他在線方法有個共同的“痛點”: 生成東西太費時間。為了讓 GRPO 用更少的樣本干更多活,一個聰明辦法就是把生成的樣本反復利用,而不是用一次就扔。這招其實老早就有了,出自 PPO 的“遺產”。
在 GRPO 里,樣本重復使用的次數有個專有名詞,叫 μ 。
現在我們能多次“榨干”這些樣本的價值,速度快了不少。
from trl import GRPOConfig
training_args = GRPOConfig(..., num_iterations=...)
不過得悠著點——如果 μ 定得太大,反而會拖學習的后腿。我們試下來, 2 到 4 是個不錯的范圍。
獎勵加權
訓練模型時,不是每個獎勵都一樣重要。比如,我們可能更希望模型把 答案正確性 放在首位,而不是太糾結 格式漂不漂亮。
為了解決這個,現在可以給不同的獎勵“打分”, 加個權重,這樣就能更靈活地掌控優化方向。調調這些權重,就能讓模型把精力集中在任務的關鍵點上。
from trl import GRPOConfig, GRPOTrainer
def very_important_reward(completions, **kwargs):
...
def less_important_reward(completions, **kwargs):
...
training_args = GRPOConfig(
...,
reward_weights=[0.9, 0.1],
)
trainer = GRPOTrainer(
...,
reward_funcs=[very_important_reward, less_important_reward],
args=training_args,
)
其他小升級
GRPO 還順手做了幾個“小而美”的改進:
- PEFT + vLLM 聯手 – 現在能把 PEFT (高效微調) 和 vLLM (優化推理) 搭配起來,既省力又好用,擴展性更強。
- 梯度檢查點 – 加了個新功能,通過動態算一些東西而不是全存著,訓練時能少吃點內存,大模型也能跑得動。
- 優化 Log Softmax – 換了個新辦法算 Log Softmax,訓練時內存占用不會“爆表”了。
下一步計劃
現在我們將向下面兩個重點發力:
- 生成再提速 – 在試著用一些新招 (比如靜態緩存),讓生成過程更快。
- GRPO 上多節點 – 想讓 GRPO 在多個節點上跑起來,這樣就能搞定更大的模型。
英文原文:
https://hf.co/blog/open-r1/update-3 原文作者: Loubna Ben Allal, Lewis Tunstall, Anton Lozhkov, Elie Bakouch, Guilherme Penedo, Hynek Kydlicek, Gabriel Martín Blázquez
譯者: yaoqih

 浙公網安備 33010602011771號
浙公網安備 33010602011771號