
Reformer 模型 - 突破語言建模的極限
Reformer 如何在不到 8GB 的內存上訓練 50 萬個詞元
Kitaev、Kaiser 等人于 20202 年引入的 Reformer 模型 是迄今為止長序列建模領域內存效率最高的 transformer 模型之一。
最近,人們對長序列建模的興趣激增,僅今年一年,就涌現出了大量的工作,如 Beltagy 等人的工作 (2020) 、Roy 等人的工作 (2020) 、Tay 等人的工作 以及 Wang 等人的工作 等等。長序列建模背后的動機是,N??LP 中的許多任務 (例如 摘要、問答 ) 要求模型處理更長的序列,這些序列長度超出了 BERT 等模型的處理能力。在需要模型處理長輸入序列的任務中,長序列模型無需對輸入序列進行裁剪以避免內存溢出,因此已被證明優于標準的 BERT 類模型 ( 見 Beltagy 等人 2020 年的工作)。
Reformer 能夠一次處理多達 50 萬個詞元,從而突破了長序列建模的極限 (具體可參見本 筆記本)。相形之下,傳統的 bert-base-uncased 模型最長僅支持 512 個詞元。在 Reformer 中,標準 transformer 架構的每個部分都經過重新設計,以最小化內存需求,并避免顯著降低性能。
內存的改進來自于 Reformer 作者向 transformer 世界引入的 4 大特性:
- Reformer 自注意力層 - 如何在不受限于本地上下文的情況下高效地實現自注意力機制?
- 分塊前饋層 - 如何更好地對大型前饋層的時間和內存進行權衡?
- 可逆殘差層 - 如何聰明地設計殘差架構以大幅減少訓練中的內存消耗?
- 軸向位置編碼 (Axial Positional Encodings) - 如何使位置編碼可用于超長輸入序列?
本文的目的是 深入 闡述 Reformer 的上述四大特性。雖然這四個特性目前是用在 Reformer 上的,但其方法是通用的。因此,讀者不應被此束縛,而應該多思考在哪些情況下可以把這四個特性中的某一個或某幾個應用于其他的 transformer 模型,以解決其問題。
下文四個部分之間的聯系很松散,因此可以單獨閱讀。
Reformer 已集成入 ??Transformers 庫。對于想使用 Reformer 的用戶,建議大家閱讀本文,以更好地了解該模型的工作原理以及如何正確配置它。文中所有公式都附有其在 transformers 中對應的 Reformer 配置項 ( 例如 config.<param_name> ),以便讀者可以快速關聯到官方文檔和配置文件。
注意: 軸向位置編碼 在官方 Reformer 論文中沒有解釋,但在官方代碼庫中廣泛使用。本文首次深入闡釋了軸向位置編碼。
1. Reformer 自注意力層
Reformer 使用了兩種特殊的自注意力層: 局部 自注意力層和 LSH (Locality Sensitive Hashing,局部敏感哈希, LSH ) 自注意力層。
在介紹新的自注意力層之前,我們先簡要回顧一下傳統的自注意力,其由 Vaswani 等人在其 2017 年的論文 中引入。
本文的符號及配色與 《圖解 transformer》 一文一致,因此強烈建議讀者在閱讀本文之前,先閱讀《圖解 transformer》一文。
重要: 雖然 Reformer 最初是為了因果自注意力而引入的,但它也可以很好地用于雙向自注意力。本文在解釋 Reformer 的自注意力時,將其用于 雙向 自注意力。
全局自注意力回顧
Transformer 模型的核心是 自注意力 層。現在,我們回顧一下傳統的自注意力層,這里稱為 全局自注意力 層。首先我們假設對嵌入向量序列 \(\mathbf{X} = \mathbf{x}_1, \ldots, \mathbf{x}_n\) 執行一個 transformer 層,該序列中的每個向量 \(\mathbf{x}_{i}\) 的維度為 config.hidden_??size , 即 \(d_h\)。
簡而言之,全局自注意力層將 \(\mathbf{X}\) 投影到查詢矩陣、鍵矩陣和值矩陣: \(\mathbf{Q}\)、\(\mathbf{K}\)、\(\mathbf{V}\) 并使用 softmax 計算最終輸出 \(\mathbf{Z}\),如下所示:
\(\mathbf{Z} = \text{SelfAttn}(\mathbf{X}) = \text{softmax}(\mathbf{Q}\mathbf{K}^T) \mathbf{V}\),其中 \(\mathbf{Z}\) 的維度為 \(d_h \times n\) (為簡單起見,此處省略了鍵歸一化因子和輸出映射權重 \(\mathbf{W}^{O}\))。有關完整 transformer 操作的更多詳細信息,請參閱 《圖解 transformer》 一文。
下圖給出了 \(n=16,d_h=3\) 情況下的操作:

請注意,本文所有示意圖都假設 batch_size 和 config.num_attention_heads 為 1。為了便于稍后更好地解釋 LSH 自注意力 ,我們還在圖中標記出了一些向量, 如 \(\mathbf{x_3}\) 及其相應的輸出向量 \(\mathbf{z_3}\)。圖中的邏輯可以輕易擴展至多頭自注意力 ( config.num_attention_heads > 1)。如需了解多頭注意力,建議讀者參閱 《圖解 transformer》。
敲個重點,對于每個輸出向量 \(\mathbf{z}_{i}\),整個輸入序列 \(\mathbf{X}\) 都需要參與其計算。內積張量 \(\mathbf{Q}\mathbf{K}^T\) 的內存復雜度為 \(\mathcal{O}(n^2)\),這事實上使得 transformer 模型的瓶頸在內存。
這也是為什么 bert-base-cased 的 config.max_position_embedding_size 只有 512 的原因。
局部自注意力
局部自注意力 是緩解 \(\mathcal{O}(n^2)\) 內存瓶頸的一個顯然的解決方案,它使我們能夠以更低的計算成本建模更長的序列。在局部自注意力中,輸入 \(\mathbf{X} = \mathbf{X}_{1:n} = \mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\) 被切成 \(n_{c}\) 個塊: \(\mathbf{X} = \left[\mathbf{X}_{1:l_{c}}, \ldots, \mathbf{X} _{(n_{c} - 1) * l_{c} : n_{c} * l_{c}}\right]\),每塊長度為 config.local_chunk_length , 即 \(l_{c}\),隨后,對每個塊分別應用全局自注意力。
繼續以 \(n=16,d_h=3\) 為例:
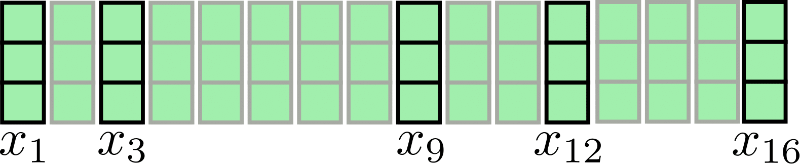
假設 \(l_{c} = 4,n_{c} = 4\),此時,我們將分塊注意力圖示如下:

可以看出,我們對每個塊分別執行了注意力操作 \(\mathbf{X} _{1:4},\mathbf{X}_ {5:8},\mathbf{X} _{9:12 },\mathbf{X}_ {13:16}\)。
該架構的一個明顯的缺點是: 一些輸入向量無法訪問其直接上下文, 例如 ,我們的例子中的 \(\mathbf{x} _9\) 無法訪問 \(\mathbf{x}_ {8}\),反之亦然。這是有問題的,因為這些詞元無法在學習其向量表征時將其直接上下文的納入考量。
一個簡單的補救措施是用 config.local_num_chunks_before ( 即 \(n_{p}\)) 以及 config.local_num_chunks_after ( 即 \(n_{a}\)) 來擴充每個塊,以便每個輸入向量至少可以訪問 \(n_{p}\) 個先前輸入塊及 \(n_{a}\) 個后續輸入塊。我們可將其理解為重疊分塊,其中 \(n_{p}\) 和 \(n_{a}\) 定義了每個塊與其先前塊和后續塊的重疊量。我們將這種擴展的局部自注意力表示如下:
其中
好吧,這個公式看起來有點復雜,我們稍微分析一下。在 Reformer 的自注意力層中,\(n_{a}\) 通常設為 0,\(n_{p}\) 設為 1,我們據此重寫 \(i = 1\) 時的公式:
我們注意到這里有一個循環關系,因此第一個塊也可以關注最后一個塊。我們再次圖解一下這種增強的局部關注算法。我們先按塊找到其對應的窗口,并在其上應用自注意力,然后僅保留中心輸出段作為本塊的輸出。
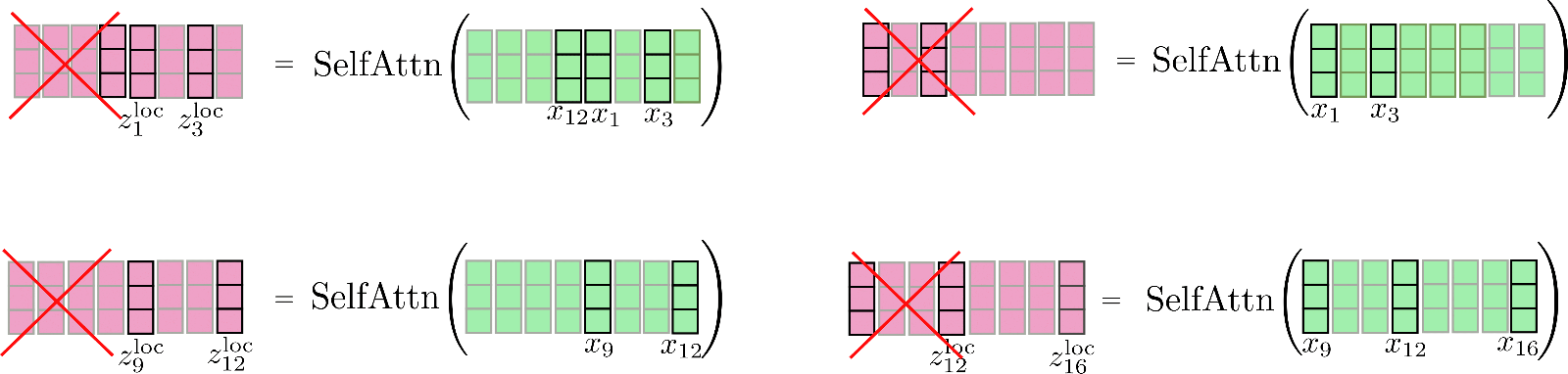
最后,將相應的輸出串接到 \(\mathbf{Z}^{\text{loc}}\) 中,如下所示:

請注意,在實現局部自注意力時,為了計算效率,我們并不會像圖中一樣先計算全部輸出并隨后 丟棄 一部分。圖中紅叉所示的地方僅用于說明,實際并不會產生計算行為。
這里需要注意的是,擴展每個分塊自注意力函數的輸入向量可以使得 每個 輸出向量 \(\mathbf{z}_{i}\) 都能夠學到更好的向量表征。以圖中的向量為例,每個輸出向量 \(\mathbf{z}_{5}^{\text{loc}},\mathbf{z}_{6}^{\text{loc}},\mathbf{z}_{7}^{\text{loc}},\mathbf{z}_{8}^{\text{loc}}\) 都可以將 \(\mathbf{X}_{1:8}\) 的所有輸入向量納入考量以學到更好的表征。
內存消耗上的降低也是顯而易見的: \(\mathcal{O}(n^2)\) 的內存復雜度被分解到段,因此總內存復雜度減少為 \(\mathcal{O}(n_{c} * l_{c}^2) = \mathcal{O}(n * l_{c})\)。
這種增強的局部自注意力比普通的局部自注意力架構更好,但仍然存在一個主要缺陷,因為每個輸入向量只能關注預定義大小的局部上下文。對于不需要 transformer 模型學習輸入向量之間的遠程依賴關系的 NLP 任務 ( 例如 語音識別、命名實體識別以及短句子的因果語言建模) 而言,可能不是一個大問題。但還有許多 NLP 任務需要模型學習遠程依賴關系,因此局部自注意力在這些任務下可能會導致顯著的性能下降, 如 :
- 問答 : 模型必須學習問題詞元和相關答案詞元之間的關系,這些詞元很可能并不相鄰;
- 多項選擇 : 模型必須將多個答案詞元段相互比較,這些答案詞元段通常隔得比較遠;
- 摘要 : 模型必須學習長序列的上下文詞元和較短的摘要詞元序列之間的關系,而上下文和摘要之間的相關關系很可能無法通過局部自注意力來捕獲。
- ……
局部自注意力本身很可能不足以讓 transformer 模型學習輸入向量 (詞元) 彼此之間的相關關系。
因此,Reformer 額外采用了一個近似全局自注意力的高效自注意力層,稱為 LSH 自注意力 。
LSH 自注意力
鑒于我們已經了解了局部自注意力的工作原理,下面我們繼續嘗試一下可能是 Reformer 中最具創新性的算法改進: LSH 自注意力。
LSH 自注意力的設計目標是在效果上接近全局自注意力,而在速度與資源消耗上與局部自注意力一樣高效。
LSH 自注意力因依賴于 Andoni 等人于 2015 年提出的 LSH 算法 而得名。
LSH 自注意力源于以下洞見: 如果 \(n\) 很大,則對每個查詢向量而言,其對應的輸出向量 \(\mathbf{z}_{i}\) 作為所有 \(\mathbf{V}\) 的線性組合,其中應只有極少數幾個 \(\mathbf{v}_{i}\) 的權重比其他大得多。也就是說對 \(\mathbf{Q}\mathbf{K}^T\) 注意力點積作 softmax 產生的權重矩陣的每一行應僅有極少數的值遠大于 0。
我們展開講講: 設 \(\mathbf{k}_{i} \in \mathbf{K} = \left[\mathbf{k}_1, \ldots, \mathbf{k}_n \right]^T\) 和 \(\mathbf{q}_{i} \in \mathbf{Q} = \left[\mathbf{q}_1, \ldots, \mathbf{q}_n\right]^T\) 分別為鍵向量和查詢向量。對于每個 \(\mathbf{q}_{i}\),可以僅用那些與 \(\mathbf{q}_{i}\) 具有高余弦相似度的 \(\mathbf{k}_{j}\) 的鍵向量來近似計算 \(\text{softmax}(\mathbf{q}_{i}^T \mathbf{K}^T)\) 。這是因為 softmax 函數對較大輸入值的輸出會呈指數級增加。聽起來沒毛病,那么下一個問題就變成了如何高效地找到每個 \(\mathbf{q}_{i}\) 的高余弦相似度鍵向量集合。
首先,Reformer 的作者注意到共享查詢投影和鍵投影: \(\mathbf{Q} = \mathbf{K}\) 并不會影響 transformer 模型 \({}^1\)。現在,不必為每個查詢向量 \(q_i\) 找到其高余弦相似度的鍵向量,而只需計算查詢向量彼此之間的余弦相似度。這一簡化很重要,因為查詢向量之間的余弦相似度滿足傳遞性: 如果 \(\mathbf{q}_{i}\) 與 \(\mathbf{q}_{j}\) 和 \(\mathbf{q}_{k}\) 都具有較高的余弦相似度,則 \(\mathbf{q}_{j}\) 與 \(\mathbf{q}_{k}\) 也具有較高的余弦相似度。因此,可以將查詢向量聚類至不同的桶中,使得同一桶中的所有查詢向量彼此的余弦相似度較高。我們將 \(C_{m}\) 定義為第 m 組位置索引,其中裝的是屬于同一個桶的所有查詢向量: \(C_{m} = { i | \mathbf{q}_{i} \in \text{第 m 簇}}\),同時我們定義桶的數量 config.num_buckets , 即 \(n_{b}\)。
對每個索引 \(C_{m}\) 對應的查詢向量桶內的查詢向量 \(\mathbf{q}_{i}\),我們可以用 softmax 函數 \(\text{softmax}(\mathbf{Q}_{i \in C_{m}} \mathbf{Q}^T_{i \in C_{m}})\) 通過共享查詢和鍵投影來近似全局自注意力的 softmax 函數 \(\text{softmax}(\mathbf{q}_{i}^T \mathbf{Q}^T)\)。
其次,作者利用 LSH 算法將查詢向量聚類到預定義的 \(n_{b}\) 個桶 中。這里,LSH 算法是理想之選,因為它非常高效,且可用于近似基于余弦相似度的最近鄰算法。對 LSH 進行解釋超出了本文的范圍,我們只要記住,對向量 \(\mathbf{q}_{i}\),LSH 算法將其索引至 \(n_{b}\) 個預定義桶中的某個桶, 即 \(\text{LSH}(\mathbf{q}_{i}) = m\) 其中 \(i \in {1, \ldots, n}\),\(m \in {1, \ldots, n_{b}}\)。
還用前面的例子,我們有:

接著,可以注意到,將所有查詢向量聚類至 \(n_{b}\) 個桶中后,我們可以將輸入向量 \(\mathbf{x}_1, \ldots, \mathbf{x}_n\) 按其對應的索引 \(C_{m}\) 進行重排 \({}^2\),以便共享查詢 - 鍵自注意力可以像局部注意力一樣分段應用。
我們用例子再解釋一下,假設在 config.num_buckets=4 , config.lsh_chunk_length=4 時重排輸入向量 \(\mathbf{X} = \mathbf{x}_1, …, \mathbf{x}_{16}\)。上圖已將每個查詢向量 \(\mathbf{q}_1, \ldots, \mathbf{q}_{16}\) 分配給簇 \(\mathcal{C}_{1}、\mathcal{C}_{2}、\mathcal{C}_{3}、\mathcal{C}_{4}\) 中的某一個。現在,對其對應的輸入向量 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 進行重排,并將重排后的輸入記為 \(\mathbf{X'}\):
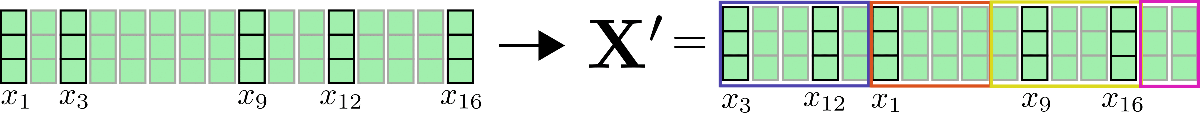
對每個輸入向量,僅需在簇內進行自注意力計算即可,因此每個輸入向量對應的輸出向量可計算如下: \(\mathbf{Z}^{\text{LSH}}_{i \in \mathcal{C}_m} = \text{SelfAttn}_{\mathbf{Q}=\mathbf{K}}(\mathbf{X}_{i \in \mathcal{C}_m})\)。
我們再次圖解一下該過程:
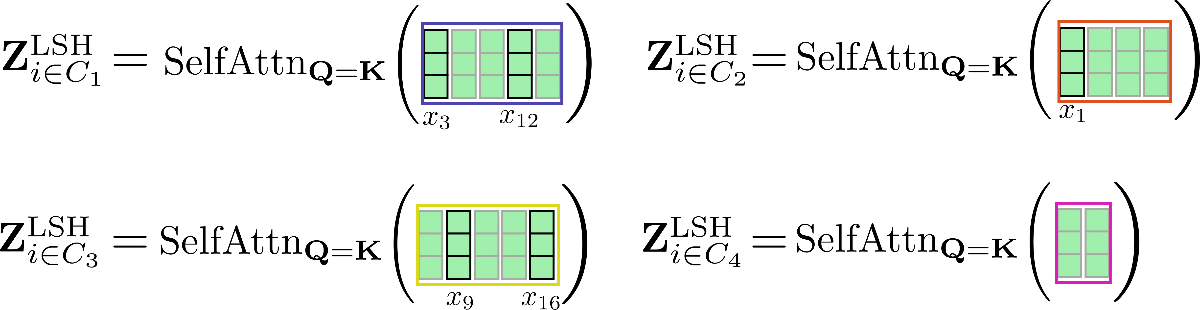
可以看出,自注意力函數的運算矩陣大小各不相同,這種情況比較麻煩,因為 GPU 和 TPU 無法高效并行處理不同尺寸的矩陣運算。
為了進一步解決高效計算的問題,可以借鑒局部注意力的方法,對重排后的輸入進行分塊,以使每個塊的大小均為 config.lsh_chunk_length 。通過對重排后的輸入進行分塊,一個桶可能會被分成兩個不同的塊。為了解決這個問題,與局部自注意力一樣,在 LSH 自注意力中,每個塊除了自身之外還關注其前一個塊 config.lsh_num_chunks_before=1 ( config.lsh_num_chunks_after 通常設置為 0)。這樣,我們就可以大概率確保桶中的所有向量相互關注 \({}^3\)。
總而言之,對于所有塊 \(k \in {1, \ldots, n_{c}}\),LSH 自注意力可以如下表示:
其中 \(\mathbf{X'}\) 和 \(\mathbf{Z'}\) 是按照 LSH 分桶進行重排后的輸入和輸出向量。公式有點復雜,我們還是畫個圖以幫助大家理解。
這里,我們對上圖中的重排向量 \(\mathbf{X'}\) 進行分塊,并分別計算每塊的共享查詢 - 鍵自注意力。
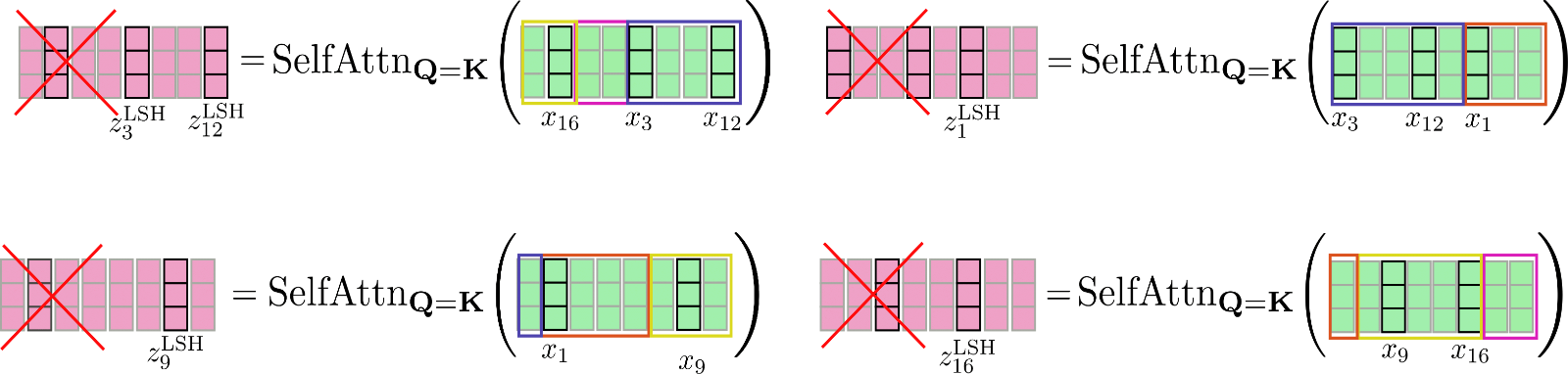
最后,將輸出 \(\mathbf{Z'}^{\text{LSH}}\) 重排回原順序。
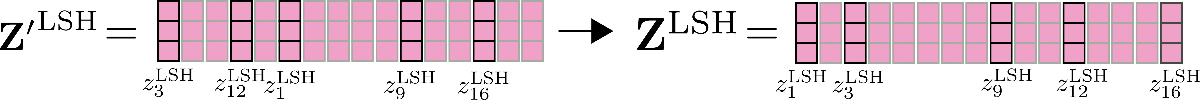
這里還要提到的一個重要特征是,可以通過并行運行 LSH 自注意力 config.num_hashes (即 \(n_{h}\)) 次來提高 LSH 自注意力的準確性,其中每次使用不同的隨機 LSH 哈希。通過設置 config.num_hashes > 1 ,對于每個 \(i\),會計算多個輸出向量 \(\mathbf{z}^{\text{LSH}, 1}_{i}, \ldots , \mathbf{z}^{\text{LSH}, n_{h}}_{i}\)。隨后,可以對它們進行加權求和: \(\mathbf{z}^{\text{LSH}}_{i} = \sum_k^{n_{h}} \mathbf{Z}^{\text{LSH}, k}_{i} * \text{weight}^k_i\),這里 \(\text{weight}^k_i\) 表示第 \(k\) 輪哈希的輸出向量 \(\mathbf{z}^{\text{LSH}, k}_{i}\) 與其他哈希輪次相比的重要度,其應與其對應輸出的 softmax 歸一化系數呈指數正比關系。這一設計背后的直覺是,如果查詢向量 \(\mathbf{q}_{i}^{k}\) 與其對應塊中的所有其他查詢向量具有較高的余弦相似度,則該塊的 softmax 歸一化系數往往很大,因此相應的輸出向量 \(\mathbf{q}_{i}^{k}\) 應該能更好地近似全局注意力,因此其理應比 softmax 歸一化系數較小的哈希輪次所產生的輸出向量獲得更高的權重。更多詳細信息,請參閱 該論文 的附錄 A。在我們的例子中,多輪 LSH 自注意力示意圖如下。
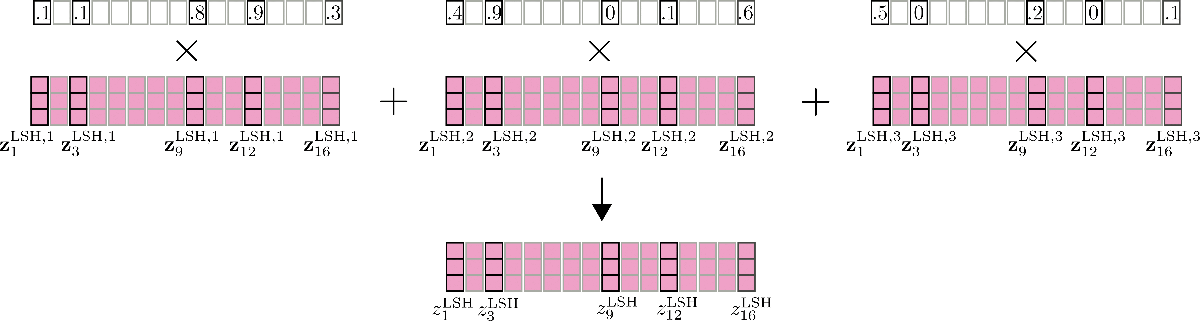
打完收工!至此,我們了解了 LSH 自注意力在 Reformer 中是如何工作的。
說回內存復雜度,該方法有兩個可能的瓶頸點: 點積所需的內存: \(\mathcal{O}(n_{h} * n_{c} * l_{c}^2) = \mathcal{O}(n * n_{h} * l_{c})\) 以及 LSH 分桶所需的內存: \(\mathcal{O}(n * n_{h} * \frac{n_{b}}{2})\) 其中 \(l_{c}\) 是塊長度。因為對于大的 \(n\) 而言,桶的數量 \(\frac{n_{b}}{2}\) 的增長速度遠遠快于塊長度 \(l_{c}\),因此用戶可以繼續對存儲桶的數量 config.num_buckets 進行分解,詳見 此處。
我們快速總結一下:
- 我們希望利用 softmax 運算僅對極少數鍵向量賦予重要權重的先驗知識來對全局注意力進行近似。
- 如果鍵向量等于查詢向量,這意味著 對于每個 查詢向量 \(\mathbf{q}_{i}\),softmax 只需給與其余弦相似度高的其他查詢向量賦予重要權重就行了。
- 這種關系是對稱的,也就是說,如果 \(\mathbf{q}_{j}\) 與 \(\mathbf{q}_{i}\) 相似,則 \(\mathbf{q}_{j}\) 也與 \(\mathbf{q}_{i}\) 相似,因此我們可以在計算自注意力之前對輸入進行全局聚類。
- 我們對輸入按簇進行重排,并對重排后的輸入計算局部自注意力,最后將輸出重新恢復為原順序。
\({}^{1}\) 作者進行了一些初步實驗,確認共享查詢 - 鍵自注意力的表現與標準自注意力大體一致。
\({}^{2}\) 更準確地說,對存儲桶中的查詢向量根據其原始順序進行排序。舉個例子, 假如 向量 \(\mathbf{q}_1, \mathbf{q}_3, \mathbf{q}_7\) 全部散列到存儲桶 2,則存儲桶 2 中向量的順序仍應是先 \(\mathbf{q}_1\),后跟 \(\mathbf{q}_3\) 和 \(\mathbf{q}_7\)。
\({}^3\) 順帶說明一下,作者在查詢向量 \(\mathbf{q}_{i}\) 上放了一個掩碼,以防止向量關注本身。因為向量與其自身的余弦相似度總是大于等于其與其他向量的余弦相似度,所以強烈不建議共享查詢 - 鍵自注意力中的查詢向量關注自身。
基準測試
Transformers 最近增加了基準測試相關的代碼,你可參閱 此處 以獲取更詳細的說明。
為了展示局部 LSH 自注意力可以節省多少內存,我們在不同的 local_attn_chunk_length 和 lsh_attn_chunk_length 上對 Reformer 模型 google/reformer-enwik8 上進行了基準測試。你可以從 此處 找到更詳細的有關 google/reformer-enwik8 模型的默認配置和用法信息。
我們先進行一些必要的導入和安裝。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
首先,我們測試一下在 Reformer 模型上使用 全局 自注意力的內存使用情況。這可以通過設置 lsh_attn_chunk_length = local_attn_chunk_length = 8192 來達成,此時,對于所有小于或等于 8192 的輸入序列,模型事實上就回退成全局自注意力了。
config = ReformerConfig.from_pretrained("google/reformer-enwik8", lsh_attn_chunk_length=16386, local_attn_chunk_length=16386, lsh_num_chunks_before=0, local_num_chunks_before=0)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16386], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1279.0, style=ProgressStyle(description…
1 / 1
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 8.87 GiB already allocated; 1.92 GiB free; 8.88 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1465
Reformer 1 4096 2757
Reformer 1 8192 7893
Reformer 1 16386 N/A
--------------------------------------------------------------------------------
輸入序列越長,輸入序列和峰值內存使用之間的平方關系 \(\mathcal{O}(n^2)\) 越明顯。可以看出,實際上,需要更長的輸入序列才能清楚地觀察到輸入序列翻倍會導致峰值內存使用量增加四倍。
對使用全局注意力的 google/reformer-enwik8 模型而言,序列長度超過 16K 內存就溢出了。
現在,我們使用模型的默認參數以使能 局部 LSH 自注意力。
config = ReformerConfig.from_pretrained("google/reformer-enwik8")
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16384, 32768, 65436], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
1 / 1
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.74 GiB free; 9.06 GiB reserved in total by PyTorch)
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 11.17 GiB total capacity; 6.56 GiB already allocated; 3.99 GiB free; 6.81 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1785
Reformer 1 4096 2621
Reformer 1 8192 4281
Reformer 1 16384 7607
Reformer 1 32768 N/A
Reformer 1 65436 N/A
--------------------------------------------------------------------------------
不出所料,對于較長的輸入序列,使用局部 LSH 自注意力機制的內存效率更高,對于本文使用的 11GB 顯存 GPU 而言,模型直到序列長度為 32K 時,內存才耗盡。
2. 分塊前饋層
基于 transformer 的模型通常在自注意力層之后會有一個非常大的前饋層。該層可能會占用大量內存,有時甚至成為模型主要的內存瓶頸。Reformer 論文中首次引入了前饋分塊技術,以用時間換取內存。
Reformer 中的分塊前饋層
在 Reformer 中, LSH 自注意力層或局部自注意力層通常后面跟著一個殘差連接,我們可將其定義為 transformer 塊 的第一部分。更多相關知識,可參閱此 博文。
Transformer 塊 第一部分的輸出,稱為 歸范化自注意力 輸出,可以記為 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}\)。在 Reformer 模型中,\(\mathbf{Z}\) 為 \(\mathbf{Z}^{\text{LSH}}\) 或 \(\mathbf{Z}^\text{loc}\)。
在我們的例子中,輸入 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 的規范化自注意力輸出圖示如下:

Transformer 塊 的第二部分通常由兩個前饋層 \(^{1}\) 組成,其中 \(\text{Linear}_{\text{int}}(\ldots)\) 用于將 \(\mathbf{\overline{Z}}\) 映射到中間輸出 \(\mathbf{Y}_{\text{int}}\),\(\text{Linear}_{\text{out}}(\ldots)\) 用于將中間輸出映射為最終輸出 \(\mathbf{Y}_{\text{out}}\)。我們將兩個前饋層定義如下:
敲重點!在數學上,前饋層在位置 \(i\) 處的輸出 \(\mathbf{y}_{\text{out}, i}\) 僅取決于該位置的輸入 \(\mathbf{\overline{y}}_{i}\)。與自注意力層相反,每個輸出 \(\mathbf{y}_{\text{out}, i}\) 與其他位置的輸入 \(\mathbf{\overline{y}}_{j \ne i}\) 完全獨立。
\(\mathbf{\overline{z}}_1, \ldots, \mathbf{\overline{z}}_{16}\) 的前饋層圖示如下:
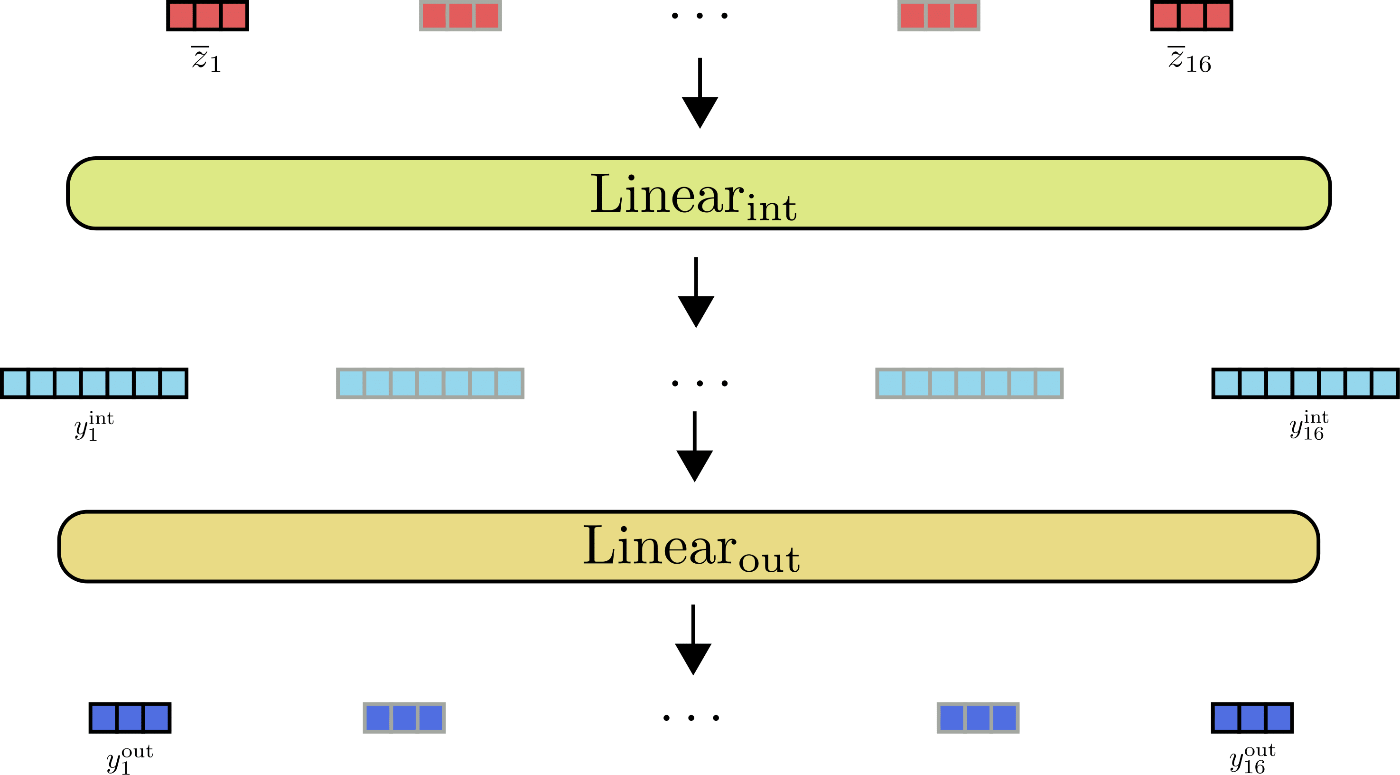
從圖中可以看出,所有輸入向量 \(\mathbf{\overline{z}}_{i}\) 均由同一前饋層并行處理。
我們再觀察一下前饋層的輸出維度,看看有沒有啥有意思的事情。在 Reformer 中,\(\text{Linear}_{\text{int}}\) 的輸出維度為 config.feed_forward_size , 即 \(d_ {f}\); 而 \(\text{Linear}_{\text{out}}\) 的輸出維度為 config.hidden_??size , 即 \(d_ {h}\)。
Reformer 作者觀察到 \(^{2}\),在 transformer 模型中,中間維度 \(d_{f}\) 通常往往比輸出維度 \(d_{h}\) 大許多。這意味著尺寸為 \(d_{f} \times n\) 的張量 \(\mathbf{\mathbf{Y}}_\text{int}\) 占據了大量的內存,甚至可能成為內存瓶頸。
為了更好地感受維度的差異,我們將本文例子中的矩陣 \(\mathbf{Y}_\text{int}\) 和 \(\mathbf{Y}_\text{out}\) 圖示如下:
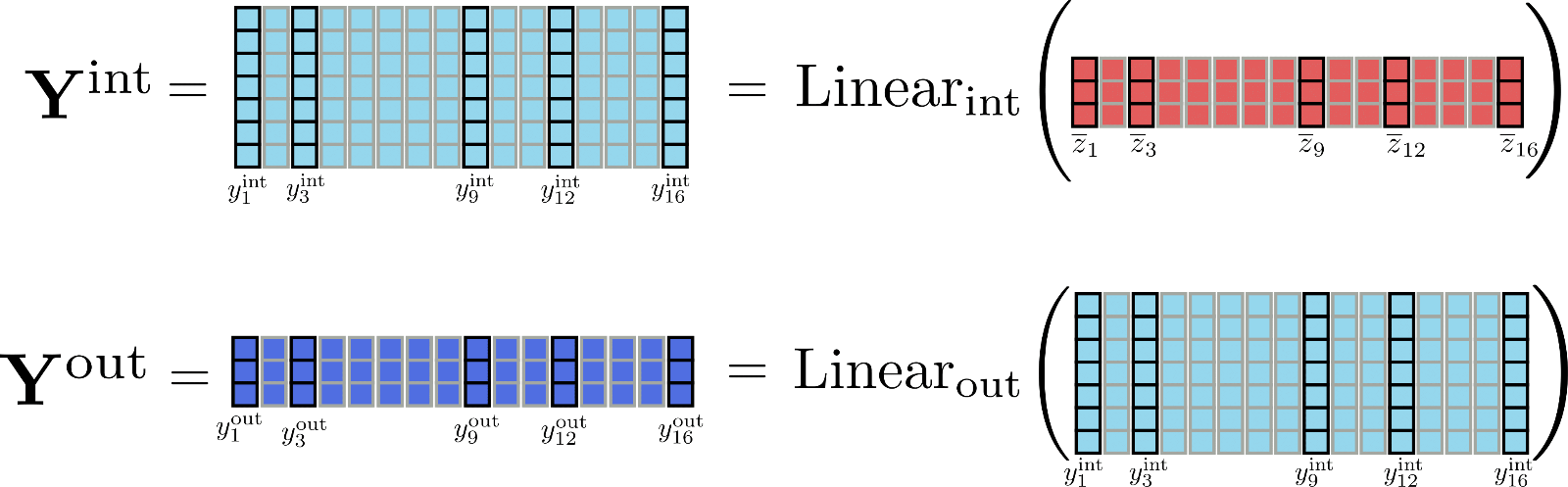
很明顯,張量 \(\mathbf{Y} _\text{int}\) 比 \(\mathbf{Y}_{\text{out}}\) 占用了更多的內存 (準確地說,多占 \(\frac{d_{f}}{d_{h}} \times n\) 字節的內存)。但是,是否有必要存儲完整的中間矩陣 \(\mathbf{Y}_\text{int}\) ?并非如此,因為我們關心的實際上只有輸出矩陣 \(\mathbf{Y}_ \text{out}\)。為了以速度換內存,我們可以對線性層計算進行分塊,一次只處理一個塊。定義 config.chunk_size_feed_forward 為 \(c_{f}\),則分塊線性層定義為 \(\mathbf{Y}_{\text{out}} = \left[\mathbf{Y}_{\text{out}, 1: c_{f}}, \ldots, \mathbf{Y}_{\text{out}, (n - c_{f}): n}\right]\) 即 \(\mathbf{Y}_{\text{out}, (c_{f} * i):(i * c_{f} + i)} = \text{Linear}_{\text{out}}( \text{Linear}_{\text{int}}(\mathbf{\overline{Z}}_{(c_{f} * i):(i * c_{f} + i)}))\)。這么做意味著我們可以增量計算輸出最后再串接在一起,這樣可以避免將整個中間張量 \(\mathbf{Y}_{\text{int}}\) 存儲在內存中。
假設 \(c_{f}=1\),我們把增量計算 \(i=9\) 的過程圖示如下:
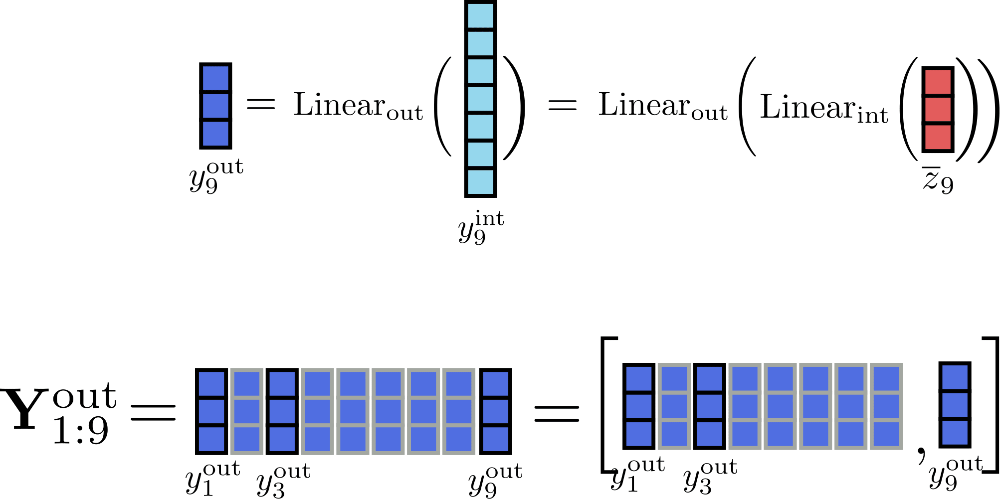
當塊大小為 1 時,必須完整存儲在內存中的唯一張量是大小為 \(16 \times d_{h}\) 的輸入張量 \(\mathbf{\overline{Z}}\),其中 \(d_{h}\) 為 config.hidden_size 。而中間張量只需要存儲大小為 \(d_{f}\) 的 \(\mathbf{y}_{\text{int}, i}\) 就可以了 \(^{3}\)。
最后,重要的是要記住, 分塊線性層 與傳統的完整線性層相比,其輸出在數學上是等效的,因此可以應用于所有 transformer 線性層。因此,在某些場景下,可以考慮使用 config.chunk_size_feed_forward 在內存和速度之間進行更好的權衡。
\({}^1\) 為了簡單起見,我們省略了前饋層之前的層歸一化操作。
\({}^2\) 以 bert-base-uncased 為例,其中間維度 \(d_{f}\) 是 3072,為輸出維度 \(d_{h}\) 的 4 倍。
\({}^3\) 提醒一下,為清晰說明起見,本文假設輸出 config.num_attention_heads 為 1,因此假設自注意力層的輸出大小為 config.hidden_??size 。
讀者也可以在 ??Transformers 的 相應文檔 中找到有關分塊線性/前饋層的更多信息。
基準測試
我們測試一下使用分塊前饋層可以節省多少內存。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
Building wheel for transformers (setup.py) ... [?25l[?25hdone
首先,我們將沒有分塊前饋層的默認 google/reformer-enwik8 模型與有分塊前饋層的模型進行比較。
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8") # no chunk
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1) # feed forward chunk
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.74 GiB free; 9.06 GiB reserved in total by PyTorch)
2 / 2
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.24 GiB free; 9.56 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 4281
Reformer-No-Chunk 8 2048 7607
Reformer-No-Chunk 8 4096 N/A
Reformer-Chunk 8 1024 4309
Reformer-Chunk 8 2048 7669
Reformer-Chunk 8 4096 N/A
--------------------------------------------------------------------------------
有趣的是,分塊前饋層似乎在這里根本沒有幫助。原因是 config.feed_forward_size 不夠大,所以效果不明顯。僅當序列長度較長 (4096) 時,才能看到內存使用量略有下降。
我們再看看如果將前饋層的大小增加 4 倍,并將注意力頭的數量同時減少 4 倍,從而使前饋層成為內存瓶頸,此時峰值內存情形如何。
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=0, num_attention_{h}eads=2, feed_forward_size=16384) # no chuck
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1, num_attention_{h}eads=2, feed_forward_size=16384) # feed forward chunk
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 3743
Reformer-No-Chunk 8 2048 5539
Reformer-No-Chunk 8 4096 9087
Reformer-Chunk 8 1024 2973
Reformer-Chunk 8 2048 3999
Reformer-Chunk 8 4096 6011
--------------------------------------------------------------------------------
現在,對于較長的輸入序列,可以看到峰值內存使用量明顯減少。總之,應該注意的是,分塊前饋層僅對于具有很少注意力頭和較大前饋層的模型才有意義。
3. 可逆殘差層
可逆殘差層由 N. Gomez 等人 首先提出并應用在 ResNet 模型的訓練上以減少內存消耗。從數學上講,可逆殘差層與 真正的 殘差層略有不同,其不需要在前向傳播期間保存激活,因此可以大大減少訓練的內存消耗。
Reformer 中的可逆殘差層
我們首先研究為什么模型訓練比推理需要更多的內存。
在模型推理時,所需的內存差不多等于計算模型中 單個 最大張量所需的內存。而在訓練模型時,所需的內存差不多等于所有可微張量的 總和。
如果讀者已經理解了深度學習框架中的自動微分的工作原理,對此就比較容易理解了。多倫多大學 Roger Grosse 的這些 幻燈片 對大家理解自動微分很有幫助。
簡而言之,為了計算可微函數 ( 如 一層) 的梯度,自動微分需要函數輸出的梯度以及函數的輸入、輸出張量。雖然梯度是可以動態計算并隨后丟棄的,但函數的輸入和輸出張量 ( 又名 激活) 需要在前向傳播過程中被保存下來,以供反向傳播時使用。
我們具體看下 transformer 模型中的情況。Transformer 模型是由多個 transformer 層堆疊起來的。每多一個 transformer 層都會迫使模型在前向傳播過程中保存更多的激活,從而增加訓練所需的內存。
我們細看一下 transformer 層。Transformer 層本質上由兩個殘差層組成。第一個殘差層是第 1) 節中解釋的 自注意力 機制,第二個殘差層是第 2) 節中解釋的 線性層 (或前饋層)。
使用與之前相同的符號,transformer 層的輸入 即 \(\mathbf{X}\) 首先被歸一化 \(^{1}\),然后經過自注意力層獲得輸出 \(\mathbf{Z} = \text{SelfAttn}(\text{LayerNorm}(\mathbf{X}))\)。為方便討論,我們將這兩層縮寫為 \(G\),即 \(\mathbf{Z} = G(\mathbf{X})\)。
接下來,將殘差 \(\mathbf{Z}\) 與輸入相加 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}\),得到張量輸入到第二個殘差層 —— 兩個線性層。\(\mathbf{\overline{Z}}\) 經過第二個歸一化層處理后,再經過兩個線性層,得到 \(\mathbf{Y} = \text{Linear}(\text{LayerNorm}(\mathbf{Z} + \mathbf{X}))\)。我們將第二個歸一化層和兩個線性層縮寫為 \(F\) ,得到 \(\mathbf{Y} = F(\mathbf{\overline{Z}})\)。最后,將殘差 \(\mathbf{Y}\) 加到 \(\mathbf{\overline{Z}}\) 上得到 transformer 層的輸出 \(\mathbf{\overline{Y}} = \mathbf{Y} + \mathbf{\overline{Z}}\)。
我們仍以 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 為例對完整的 transformer 層進行圖解。
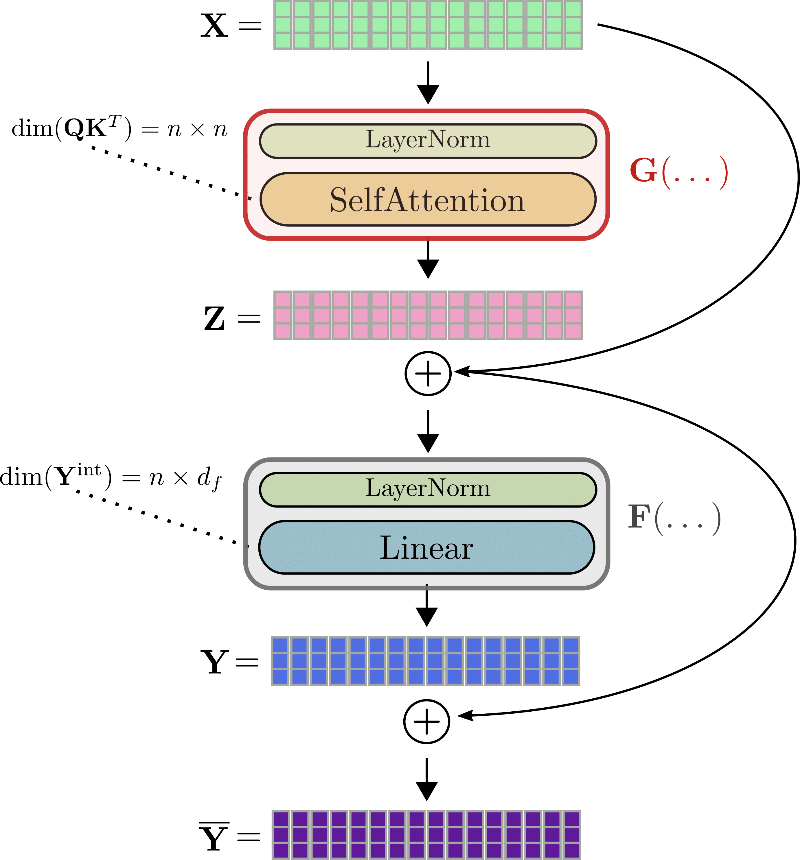
比如 ,要計算自注意力塊 \(G\) 的梯度,必須事先知道三個張量: 梯度 \(\partial \mathbf{Z}\)、輸出 \(\mathbf{Z}\) 以及輸入 \(\mathbf{X}\)。雖然 \(\partial \mathbf{Z}\) 可以即時計算并隨后丟棄,但 \(\mathbf{Z}\) 和 \(\mathbf{X}\) 必須在前向傳播期間計算并保存下來,因為在反向傳播期間比較難輕松地即時重新計算它們。因此,在前向傳播過程中,大張量輸出 (如查詢 - 鍵點積矩陣 \(\mathbf{Q}\mathbf{K}^T\) 或線性層的中間輸出 \(\mathbf{Y}^{\text{int}}\)) 必須保存在內存中 \(^{2}\)。
此時,可逆殘差層就有用了。它的想法相對簡單: 殘差塊的設計方式使得不必保存函數的輸入和輸出張量,而在反向傳播期間就輕松地對二者進行重新計算,這樣的話在前向傳播期間就無需將這些張量保存在內存中了。
這是通過兩個輸入流 \(\mathbf{X}^{(1)}、\mathbf{X}^{(2)}\) 及兩個輸出流 \(\mathbf{\overline {Y}}^{(1)}、\mathbf{\overline{Y}}^{(2)}\) 來實現的。第一個殘差 \(\mathbf{Z}\) 由第一個輸出流 \(\mathbf{Z} = G(\mathbf{X}^{(1)})\) 算得,然后其加到第二個輸入流的輸入上,即 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}^{(2)}\)。類似地,再將殘差 \(\mathbf{Y} = F(\mathbf{\overline{Z}})\) 與第一個輸入流相加。最終,兩個輸出流即為 \(\mathbf{Y}^{(1)} = \mathbf{Y} + \mathbf{X}^{(1)}\)、\(\mathbf{Y}^{(2)} = \mathbf{ X}^{(2)} + \mathbf{Z} = \mathbf{\overline{Z}}\)。
以 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 為例來圖示可逆 transformer 層,如下:
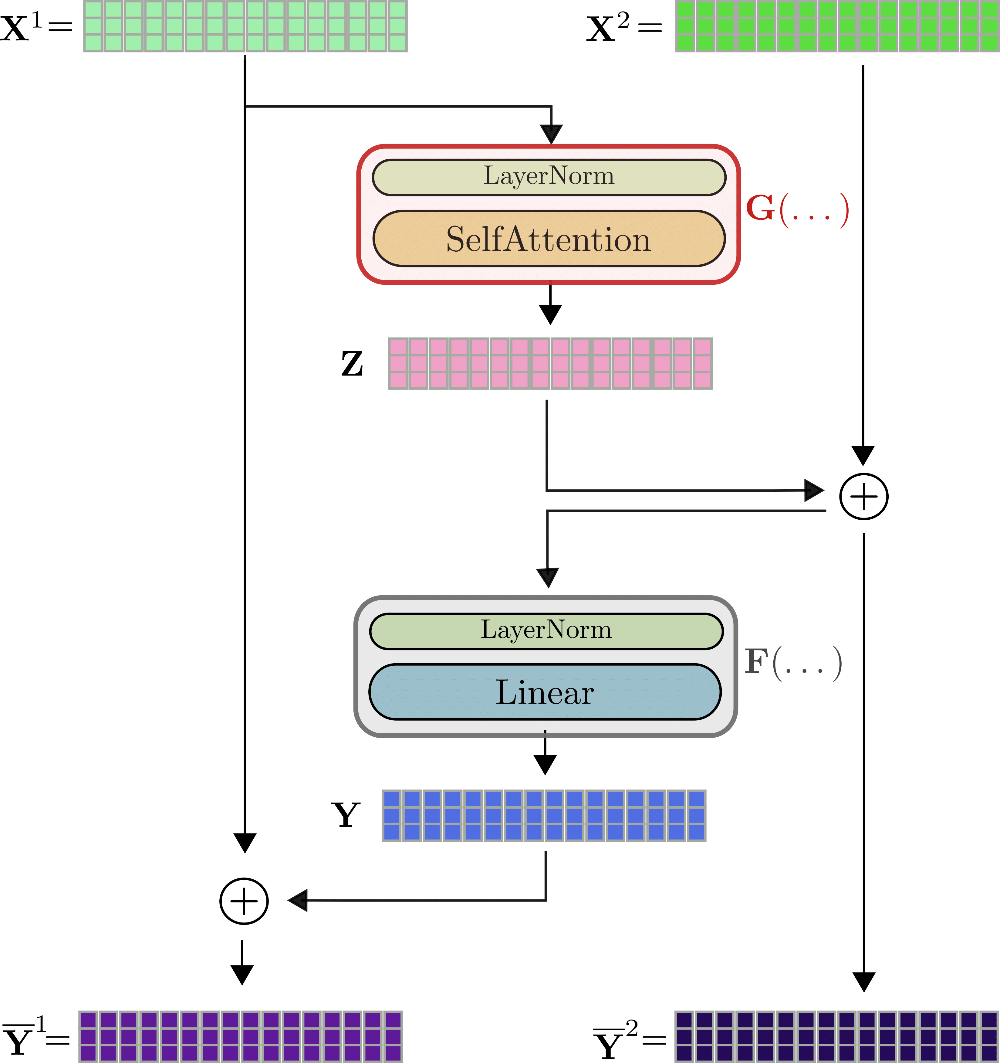
可以看出,輸出 \(\mathbf{\overline{Y}}^{(1)}、\mathbf{\overline{Y}}^{(2)}\) 的計算方式與不可逆層 \(\mathbf{\overline{Y}}\) 的計算方式非常相似,但在數學上又不同。Reformer 的作者在一些初步實驗中觀察到,可逆 transformer 模型的性能與標準 transformer 模型的性能相當。與標準 transformer 層的一個明顯區別是有兩個輸入流和輸出流 \(^{3}\),這一開始反而稍微增加了前向傳播所需的內存。但即使如此,我們還是強調雙流架構至關重要,因為其在前向傳播過程中無需保存任何激活。我們解釋一下: 對于反向傳播,可逆 treansformer 層必須計算梯度 \(\partial G\) 和 \(\partial F\)。除了可即時計算的梯度 \(\partial \mathbf{Y}\) 和 \(\partial \mathbf{Z}\) 之外,為了計算 \(\partial F\) 必須已知張量值 \(\mathbf{Y}\)、\(\mathbf{\overline{Z}}\),為了計算 \(\partial G\) 必須已知 \(\mathbf{Z}\) 和 \(\mathbf{X}^{(1)}\)。
假設我們知道 \(\mathbf{\overline{Y}}^{(1)},\mathbf{\overline{Y}}^{(2)}\),則從圖中可以很容易看出,我們可以如下計算出 \(\mathbf{X}^{(1)},\mathbf{X}^{(2)}\) 。\(\mathbf{X}^{(1)} = F(\mathbf{\overline{Y}}^{(1)}) - \mathbf{\overline{Y}}^{(1)}\)。\(\mathbf{X}^{(1)}\) 計算出來了!然后,\(\mathbf{X}^{(2)}\) 可以通過 \(\mathbf {X}^{(2)} = \mathbf{\overline{Y}}^{(1)} - G(\mathbf{X}^{(1)})\) 算出。之后,\(\mathbf{Z}\) 和 \(\mathbf{Y}\) 的計算就簡單了,可以通過 \(\mathbf{Y} = \mathbf{\overline{Y}}^{(1)} - \mathbf{X}^{(1)}\) 和 \(\mathbf{Z} = \mathbf{\overline{Y}}^{(2)} - \mathbf{X }^{(2)} 算出\)。總結一下,僅需在前向傳播期間存儲 最后一個 可逆 transformer 層的輸出 \(\mathbf{\overline{Y}}^{(1)},\mathbf{\overline{Y}}^{(2)}\),所有其他層的激活就可以通過在反向傳播期間使用 \(G\) 和 \(F\) 以及 \(\mathbf {X}^{(1)}\) 和 \(\mathbf{X}^{(2)}\) 推導而得。在反向傳播期間,每個可逆 transformer 層用兩次前向傳播 \(G\) 和 \(F\) 的計算開銷換取前向傳播時不必保存任何激活。好買賣!
注意: 最近,主要的深度學習框架都支持了梯度檢查點技術,以允許僅保存某些激活并在反向傳播期間重計算尺寸較大的激活 (Tensoflow 代碼見 此處,PyTorch 代碼見 此處)。對于標準可逆層,這仍然意味著必須為每個 transformer 層保存至少一個激活,但通過定義哪些激活可以動態重新計算,能夠節省大量內存。
\(^{1}\) 在前兩節中,我們省略了自注意力層和線性層之前的層歸一化操作。讀者應該知道 \(\mathbf{X}\) 和 \(\mathbf{\overline{Z}}\) 在輸入自注意力層和線性層之前都分別經過層歸一化處理。
\(^{2}\) 在原始自注意力中,\(\mathbf{Q}\mathbf{K}\) 的維度為 \(n \times n\); 而在 LSH 自注意力 或 局部自注意力 層的維度為 \(n \times l_{c} \times n_{h}\) 或 \(n \times l_{c}\) 其中 \(l_{c}\) 為塊長度,\(n_{h}\) 為哈希數。
\(^{3}\) 第一個可逆 transformer 層的 \(\mathbf{X}^{(2)}\) 等于 \(\mathbf{X}^{(1)}\)。
測試基準
為了測量可逆殘差層的效果,我們將增加模型層數的同時比較 BERT 和 Reformer 的內存消耗。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, BertConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
我們把標準 bert-base-uncased BERT 模型的層數從 4 增加到 12 ,同時測量其所需內存。
config_4_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=4)
config_8_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=8)
config_12_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=12)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Bert-4-Layers", "Bert-8-Layers", "Bert-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_bert, config_8_layers_bert, config_12_layers_bert], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=433.0, style=ProgressStyle(description_…
1 / 3
2 / 3
3 / 3
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Bert-4-Layers 8 512 4103
Bert-8-Layers 8 512 5759
Bert-12-Layers 8 512 7415
--------------------------------------------------------------------------------
可以看出,BERT 層數每增加 1,其所需內存就會有超 400MB 的線性增長。
config_4_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=4, num_hashes=1)
config_8_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=8, num_hashes=1)
config_12_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=12, num_hashes=1)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-4-Layers", "Reformer-8-Layers", "Reformer-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_reformer, config_8_layers_reformer, config_12_layers_reformer], args=benchmark_args)
result = benchmark.run()
1 / 3
2 / 3
3 / 3
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-4-Layers 8 512 4607
Reformer-8-Layers 8 512 4987
Reformer-12-Layers 8 512 5367
--------------------------------------------------------------------------------
另一方面,對于 Reformer 而言,每增加一層所帶來的內存增量會顯著減少,平均不到 100MB。因此 12 層的 reformer-enwik8 模型比 12 層的 bert-base-uncased 模型的內存需求更少。
4. 軸向位置編碼
Reformer 使得處理超長輸入序列成為可能。然而,對于如此長的輸入序列,僅存儲標準位置編碼權重矩陣就需要超過 1GB 內存。為了避免如此大的位置編碼矩陣,官方 Reformer 代碼引入了 軸向位置編碼 。
重要: 官方論文中沒有解釋軸向位置編碼,但通過閱讀代碼以及與作者討論我們很好地理解了它。
Reformer 中的軸向位置編碼
Transformer 需要位置編碼來對輸入序列中的單詞順序進行編碼,因為自注意力層 沒有順序的概念 。位置編碼通常由一個簡單的查找矩陣 \(\mathbf{E} = \left[\mathbf{e}_1, \ldots, \mathbf{e}_{n_\text{max}}\right]\) 來定義,然后將位置編碼向量 \(\mathbf{e}_{i}\) 簡單地加到 第 i 個 輸入向量上,即 \(\mathbf{x}_{i} + \mathbf{e}_{i}\),以便模型可以區分輸入向量 ( 即 詞元) 位于位置 \(i\) 還是位置\(j\)。對于每個輸入位置,模型需要能夠查找到相應的位置編碼向量,因此 \(\mathbf{E}\) 的維度由模型可以處理的最大輸入序列長度 config.max_position_embeddings ( 即 \(n_\text{max}\)) 以及輸入向量的維度 config.hidden_??size ( 即 \(d_{h}\)) 共同決定。
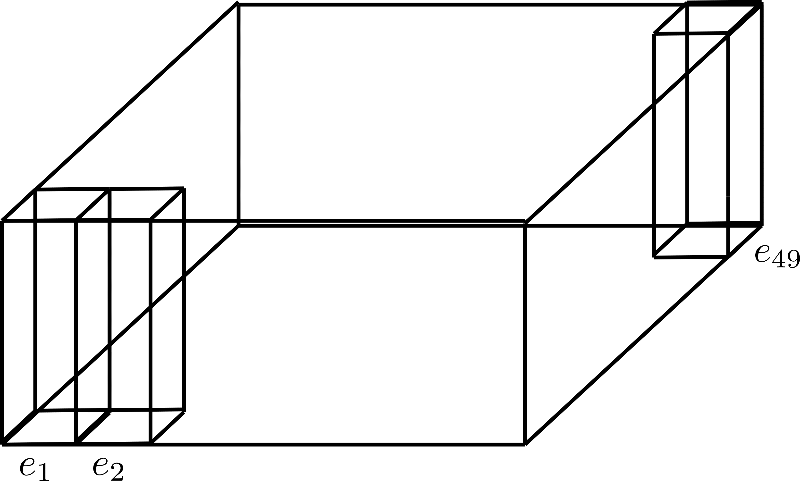
假設 \(d_{h}=4\),\(n_\text{max}=49\),其位置編碼矩陣如下圖所示:

此處,我們僅展示位置編碼 \(\mathbf{e}_{1}\)、\(\mathbf{e}_{2}\) 及 \(\mathbf{e}_{49}\),其維度 ( 即 高度) 為 4。
想象一下,我們想要在長度最長為 0.5M 個詞元,輸入向量維度 config.hidden_??size 為 1024 的序列上訓練 Reformer 模型 (請參閱 此筆記本)。其對應的位置嵌入的參數量為 \(0.5M \times 1024 \sim 512M\),大小為 2GB。
在將模型加載到內存中或將其保存在硬盤上時,所需要的內存是很大且很沒必要的。
Reformer 作者通過將 config.hidden_??size 維度一分為二,并巧妙地對 \(n_\text{max}\) 維進行分解,從而成功地大幅縮小了位置編碼的大小。在 transformers 中,用戶可以將 config.axis_pos_shape 設置為一個含有兩個值的列表: \(n_\text{max}^ 1\)、\(n_\text{max}^2\),其中 \(n_\text{max}^1 \times n_\text{max}^2 = n_\text{max}\),從而對 \(n_\text{max}\) 維度進行分解。同時,用戶可以把 config.axis_pos_embds_dim 設置為一個含有兩個值 \(d_{h}^{1}\) 和 \(d_{h}^2\) 的列表,其中 \(d_{h} ^1 + d_{h}^2 = d_{h}\),從而決定隱藏維度應該如何切割。下面用圖示來直觀解釋一下。
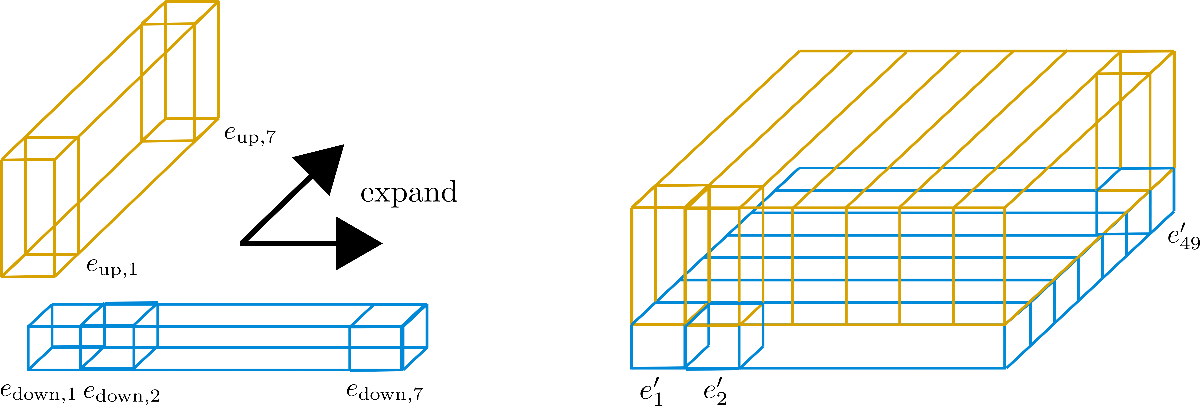
大家可以將對 \(n_{\text{max}}\) 的分解視為將其維度折疊到第三個軸,下圖所示為 config.axis_pos_shape = [7, 7] 分解:
三個直立矩形棱柱分別對應于編碼向量 \(\mathbf{e}_{1}, \mathbf{e}_{2}, \mathbf{e}_{49}\),我們可以看到 49 個編碼向量被分為 7 行,每行 7 個向量。現在的想法是僅使用 7 個編碼向量中的一行,并將這些向量擴展到其他 6 行。本質上是想讓七行重用一行的值,但是又不能讓不同位置的編碼向量的值相同,所以要將每個維度 ( 或稱 高度) 為 config.hidden_size=4 的向量切割成兩個部分: 大小為 \(1\) 的低區編碼向量 \(\mathbf{e}_\text{down}\) 以及大小為 \(3\) 的高區編碼向量 \(\mathbf{e}_\text{up}\),這樣低區就可以沿行擴展而高區可以沿列擴展。為了講清楚,我們還是畫個圖。
可以看到,我們已將嵌入向量切為 \(\mathbf{e}_\text{down}\) ( 藍色 ) 和 \(\mathbf{e}_\text{up}\) ( 黃色 ) 兩個部分。現在對 子 向量 \(\mathbf{E} _\text{down} = \left[\mathbf{e}_ {\text{down},1}, \ldots, \mathbf{e} _{\text{down},49}\right]\) 僅保留第一行的 7 個子向量, 即 圖中寬度,并將其沿列 ( 又名 深度) 擴展。相反,對 子 向量 \(\mathbf{E}_\text{up} = \left[\mathbf{e}_{\text{up},1}, \ldots, \mathbf{e }_{\text{up},49}\right]\) 僅保留第一列的 \(7\) 個子向量并沿行擴展。此時,得到的嵌入向量 \(\mathbf{e'}_{i}\) 如下:
本例中,\(n_\text{max}^1 = 7\),\(n_\text{max}^2 = 7\) 。這些新編碼 \(\mathbf{E'} = \left[\mathbf{e'}_{1}, \ldots, \mathbf{e'}_{n_\text{max}}\right]\) 稱為 軸向位置編碼。
下圖針對我們的例子對軸向位置編碼進行了更詳細的說明。
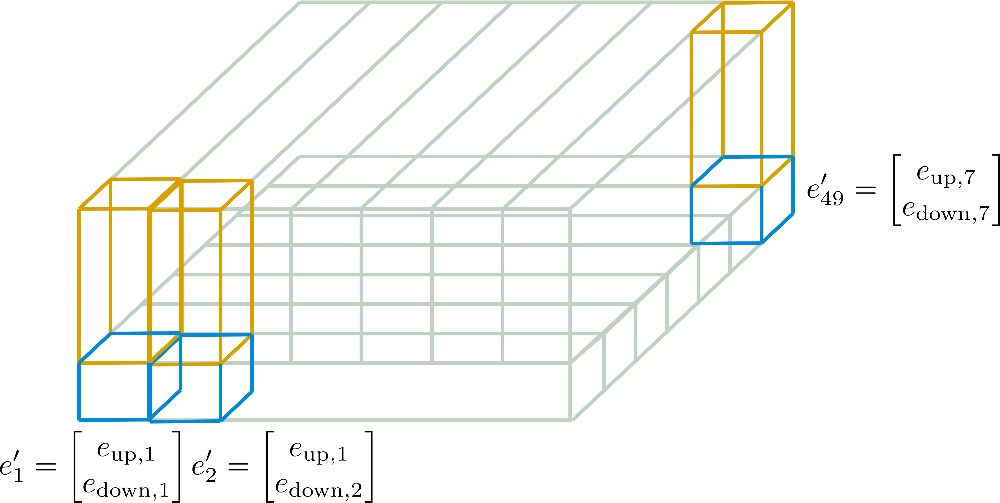
現在應該很清楚如何僅根據維度為 \(d_{h}^1 \times n_{\text{max}^1}\) 的 \(\mathbf{E}_{\text{down}}\) 及維度為 \(d_{h}^2 \times n_{\text{max}}^2\) 的 \(\mathbf{E}_{\text{up}}\) 計算最終位置編碼向量 \(\mathbf{E'}\) 了。
這里的關鍵是,軸向位置編碼能夠從設計上確保向量 \(\left[\mathbf{e'}_1, \ldots, \mathbf{e'}_{n_{\text{max} }}\right]\) 之間各不相等,并且使編碼矩陣的大小從 \(n_{\text{max}} \times d_{h}\) 減小到 \(n_{\text{max}}^1 \times d_{h}^1 + n_\text{max}^2 \times d_{h}^2\)。因為設計上允許每個軸向位置編碼向量不同,所以一旦模型中的軸向位置編碼訓出來后,模型就可以靈活高效地獲取位置編碼。
為了證明位置編碼矩陣的尺寸得到了大幅減小,假設我們為 Reformer 模型設置了參數 config.axis_pos_shape = [1024, 512] 以及 config.axis_pos_embds_dim = [512, 512] ,且該模型支持的最長輸入序列長度為 0.5M 詞元。此時,生成的軸向位置編碼矩陣的參數量僅為 \(1024 \times 512 + 512 \times 512 \sim 800K\),即大約 3MB。這個數字與標準位置編碼矩陣所需的 2GB 相比,簡直是小巫見大巫。
如需更簡潔、更數學化的解釋,請參閱 此處 的 ??Transformers 文檔。
基準測試
最后,我們對傳統位置嵌入與 軸向位置嵌入 的峰值內存消耗進行比較。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments, ReformerModel
位置嵌入僅取決于兩個配置參數: 輸入序列允許的最大長度 config.max_position_embeddings 以及 config.hidden_??size 。我們使用一個模型,其支持的輸入序列的最大允許長度為 50 萬個詞元,即 google/reformer-crime-and-punishment ,來看看使用軸向位置嵌入后的效果。
首先,我們比較軸向位置編碼與標準位置編碼的參數形狀,及其相應模型的總參數量。
config_no_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=False) # disable axial positional embeddings
config_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=True, axial_pos_embds_dim=(64, 192), axial_pos_shape=(512, 1024)) # enable axial positional embeddings
print("Default Positional Encodings")
print(20 *'-')
model = ReformerModel(config_no_pos_axial_embeds)
print(f"Positional embeddings shape: {model.embeddings.position_embeddings}")
print(f"Num parameters of model: {model.num_parameters()}")
print(20 *'-' + '\n\n')
print("Axial Positional Encodings")
print(20 *'-')
model = ReformerModel(config_pos_axial_embeds)
print(f"Positional embeddings shape: {model.embeddings.position_embeddings}")
print(f"Num parameters of model: {model.num_parameters()}")
print(20 *'-' + '\n\n')
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1151.0, style=ProgressStyle(description…
Default Positional Encodings
--------------------
Positional embeddings shape: PositionEmbeddings(
(embedding): Embedding(524288, 256)
)
Num parameters of model: 136572416
--------------------
Axial Positional Encodings
--------------------
Positional embeddings shape: AxialPositionEmbeddings(
(weights): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 512x1x64]
(1): Parameter containing: [torch.FloatTensor of size 1x1024x192]
)
)
Num parameters of model: 2584064
--------------------
理解了相應的理論后,讀者應該不會對軸向位置編碼權重的形狀感到驚訝。
從結果中可以看出,對于需要處理如此長輸入序列的模型,使用標準位置編碼是不切實際的。以 google/reformer-crime-and-punishment 為例,僅標準位置編碼自身參數量就超過 100M。軸向位置編碼可以將這個數字減少到略高于 200K。
最后,我們比較一下推理所需內存。
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-No-Axial-Pos-Embeddings", "Reformer-Axial-Pos-Embeddings"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_pos_axial_embeds, config_pos_axial_embeds], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Axial-Pos-Embeddin 8 512 959
Reformer-Axial-Pos-Embeddings 8 512 447
--------------------------------------------------------------------------------
可以看出,在 google/reformer-crime-and-punishment 模型上,使用軸向位置嵌入可減少大約一半的內存需求。
英文原文: https://hf.co/blog/reformer
原文作者: Patrick von Platen
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態數據上的應用及大規模模型的訓練推理。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號