
第一次個人編程作業
一、作業聲明
這個作業屬于哪個課程 | 信安1912-軟件工程(廣東工業大學 - 計算機學院)
--|--|--
這個作業要求在那里 | 個人項目作業
這個作業的目標 | 論文查重:實現論文查重算法+PSP表格+使用Profiler性能分析)
- 作業github鏈接
https://github.com/litternannan/litternannan
| PSP2.1 | Personal Software Process Stages | 預計耗時(分鐘) | 實際耗時(分鐘) |
|---|---|---|---|
| Planning | 計劃 | 10 | 5 |
| Estimate | 估計這個任務需要多少時間 | 10 | 5 |
| Development | 開發 | 180 | 200 |
| Analysis | 需求分析(包括學習新技術) | 180 | 180 |
| Design Spec | 生成設計文檔 | 30 | 50 |
| Design Review | 設計復審 | 15 | 25 |
| Coding Standard | 代碼規范(為目前的開發制定合適的規范) | 30 | 45 |
| Design | 具體設計 | 30 | 45 |
| Coding | 具體編碼 | 180 | 120 |
| Code Review | 代碼復審 | 30 | 15 |
| Test | 測試(自我測試,修改代碼,提交修改) | 60 | 25 |
| Reporting | 報告 | 30 | 45 |
| Test Reporting | 測試報告 | 30 | 10 |
| Size Measurement | 計算工作量 | 15 | 5 |
| Postmortem & Process Improvement Plan | 事后總結,并提出過程改進計劃 | 15 | 25 |
| 合計 | 845 | 800 |
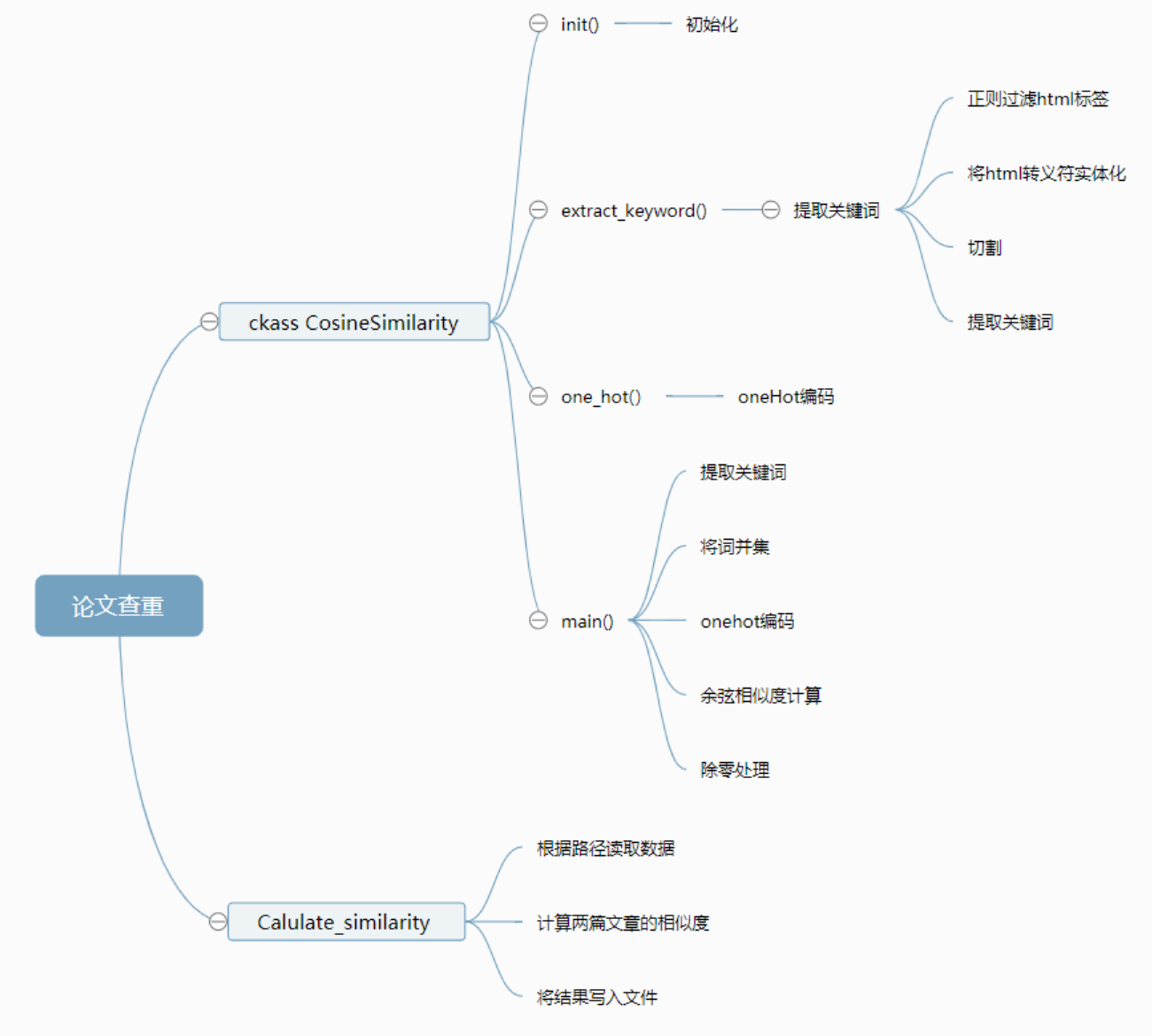
二、計算模塊接口的設計與實現過程
- jieba包
? 中文文本是通過分詞獲得單個的詞語,它的原理是利用一個中文詞庫,確定漢字之間的關聯概率,在這一次項目中,我使用全模式,把文字中所有可能的詞語都掃描出來。
- cosine_similarity包
? 余弦距離使用兩個向量夾角的余弦值作為衡量兩個個體間差異的大小。相比歐氏距離,余弦距離更加注重兩個向量在方向上的差異。余弦值越接近1,就表明夾角越接近0度,也就是兩個向量越相似,夾角等于0,即兩個向量相等,叫"余弦相似性"。
? 我們在設計查重的功能時,使用余弦相似度,通過分詞,列詞,計算詞頻,得到詞頻向量。
所以我處理文本相似度的流程是:
? (1)找出兩篇文章的關鍵詞;
(2)每篇文章各取出若干個關鍵詞,合并成一個集合,計算每篇文章對于這個集合中的詞的詞頻
(3)生成兩篇文章各自的詞頻向量;
(4)計算兩個向量的余弦相似度,值越大就表示越相似。
- 實現過程
三、計算模塊接口部分的性能改進
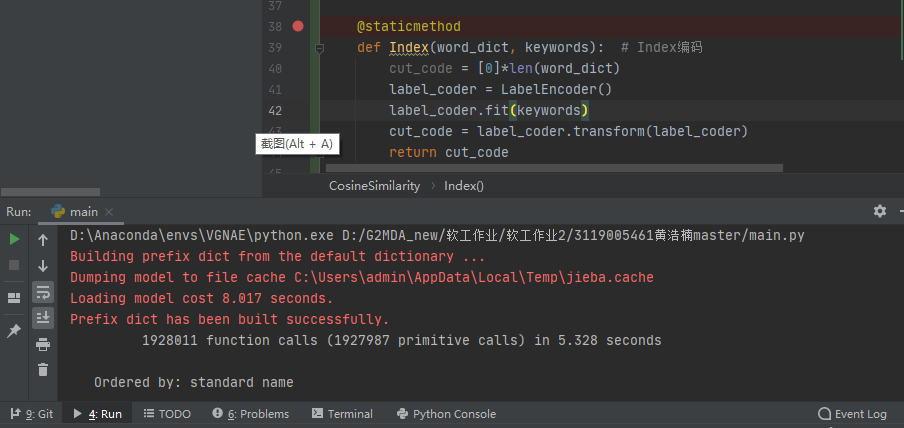
- 一開始在對詞的編碼中,我選擇的是Index編碼,但是通過Index編碼得到得詞向量,在調用模型得時候需要時間長達8秒,并且在提取關鍵詞中報錯。如下圖:
? 
-
經過查閱資料學習到,Index編碼適用于不連續的文本編碼。而我們的測試文本是連續文本,最后我采用了獨熱編碼oneHot,將離散特征的取值擴展到了歐式空間,離散特征的某個取值就對應歐式空間的某個點。
-
將Index編碼改成oneHot編碼,編程如下:
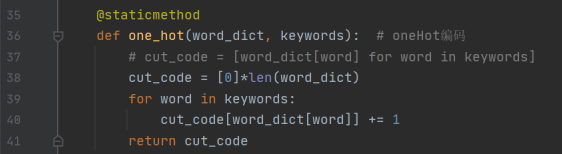
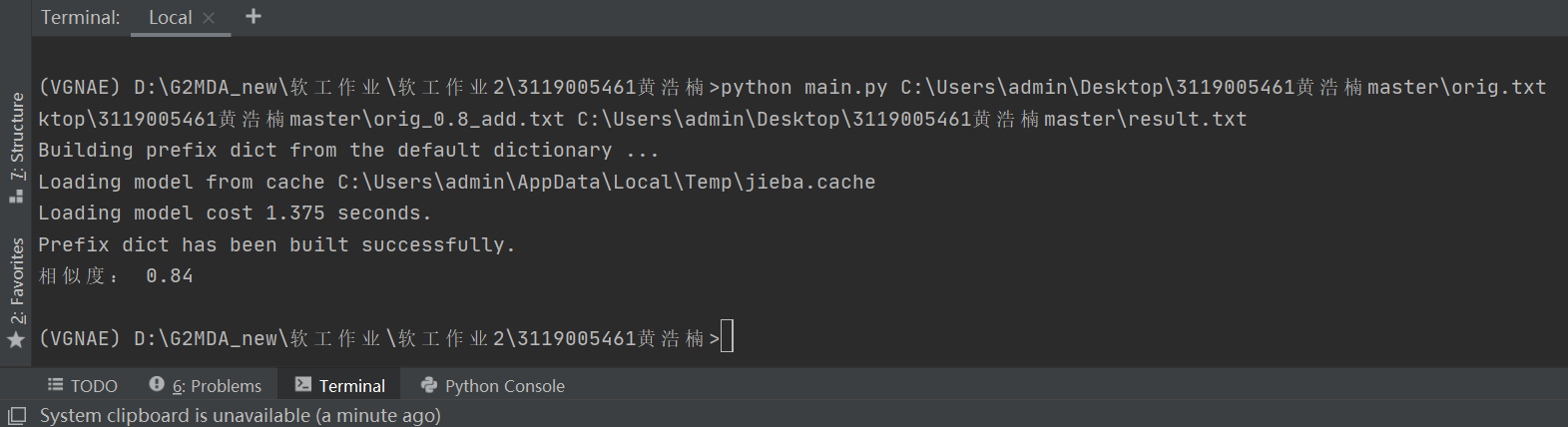
- 測試結果如下,運行時間和運行結果符合預期。
? 
四、計算模塊部分單元測試
- 運行程序,采用profile的模塊進行單元測試
運行結果如圖:
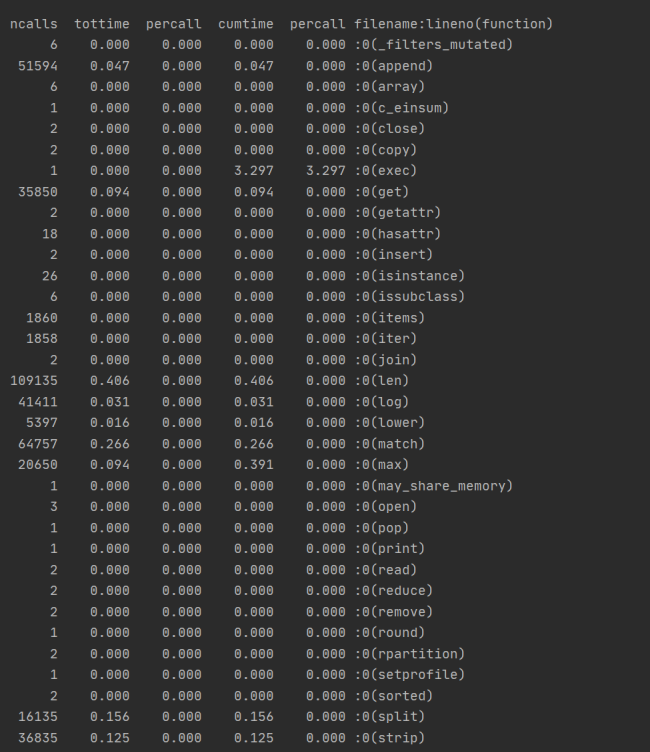
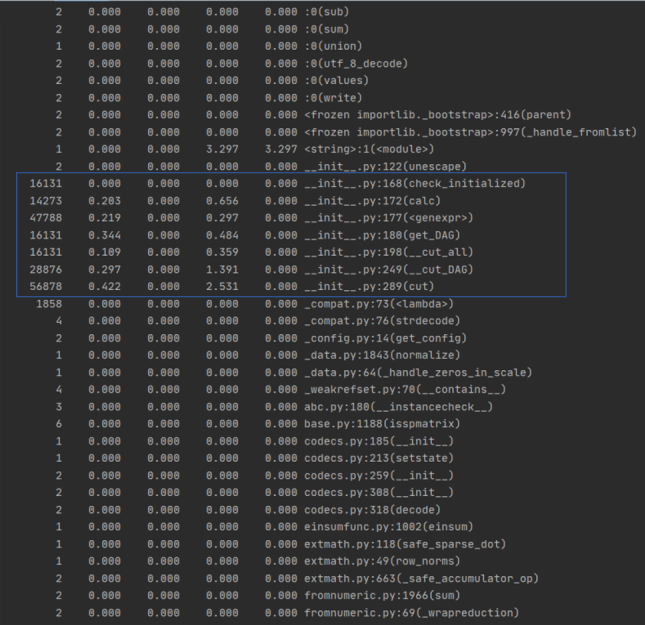
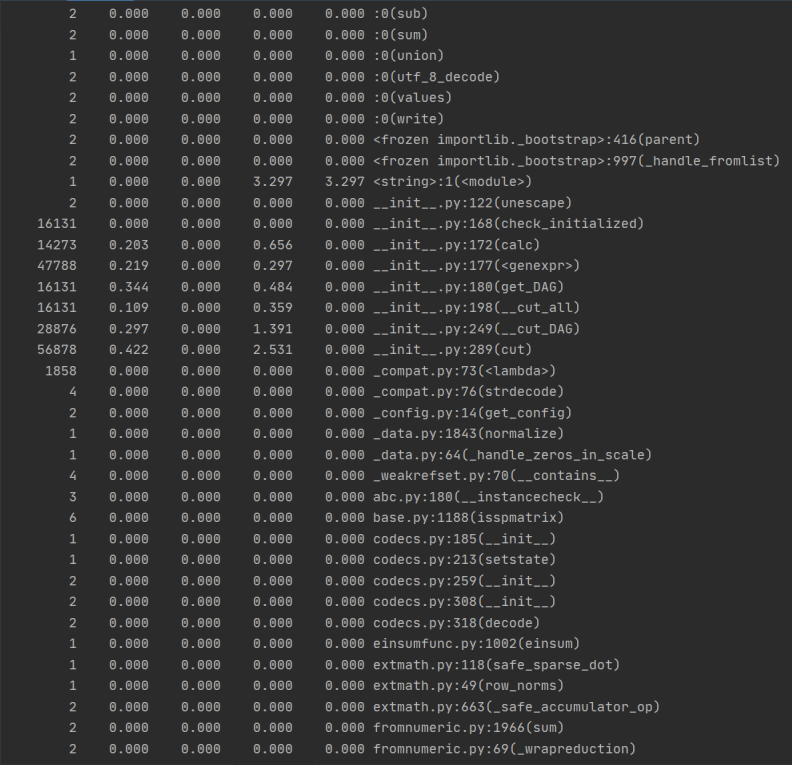
?
? 由times可得運行時間最長的部分用于文本的分詞,構建DAG這一模塊,以及列詞,計算詞頻,構建詞向量。
五、計算模塊部分單元測試展
-
代碼提交
-
原文本與測試文本orig_0.8_add.txt:相似度為0.84,符合預期
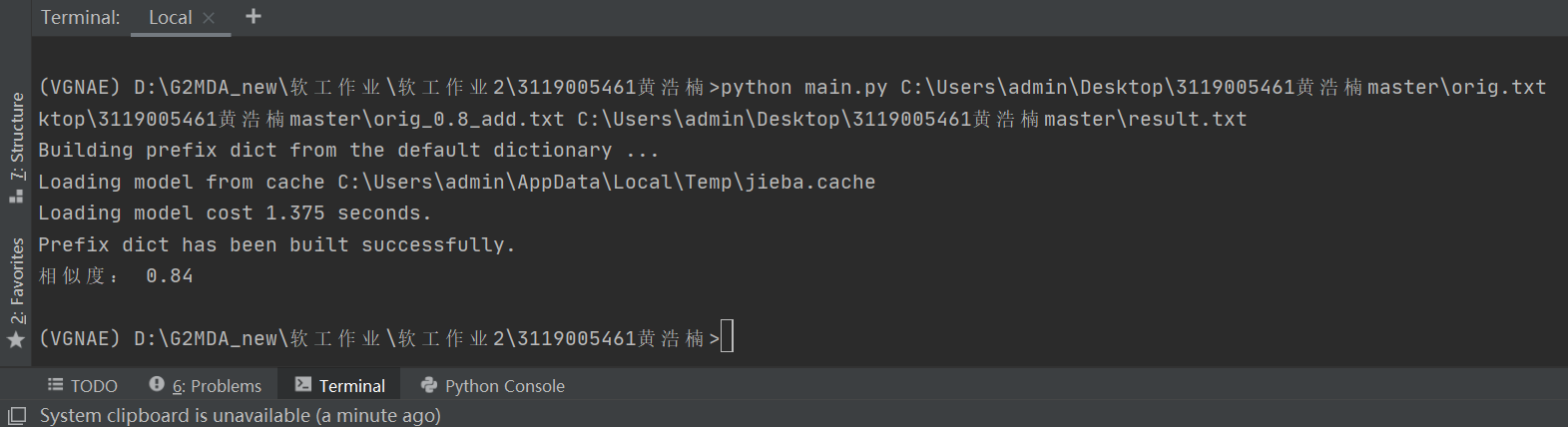
- 原文本與測試文本orig_0.8_del.txt:相似度為0.73,符合預期

-
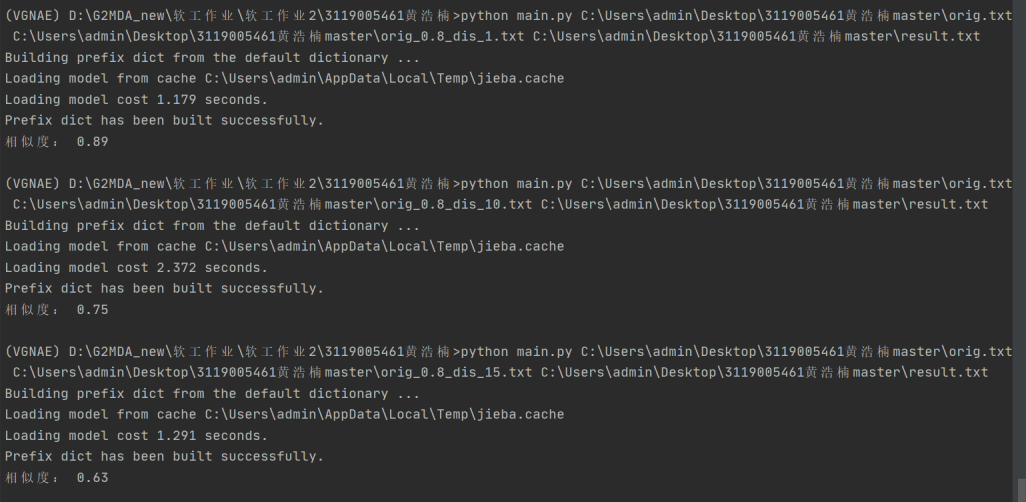
原文本分別與測試文本orig_0.8_dis_1.txt, orig_0.8_dis_10.txt, orig_0.8_dis_15.txt進行實驗,
相似度分別是:0.89,0.75,0.63,均符合預期
六、計算模塊部分異常處理說明
- 當測試文檔為空白文檔時,本程序仍能得出文本相似度為:0.0

七、總結
? 由于之前自學過NLP的相關內容,于是看到項目題目之后自然選擇了python來處理。python的好處在于本身有很強大的庫功能,大大減少代碼量。但是除此之外,在github上傳代碼的學習,profile做單元測試的學習也投入了不少的時間,通過本次學習,我熟悉了開發一個項目需要做好規劃,確保自己按照進度進行,除此之外,github上的代碼管理也尤為重要,可以讓我們在代碼出錯時回溯,更方便地管理自己的代碼,知道自己每一次上交更新了什么功能。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號